Merge branch 'perf-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip
Pull perf updates from Ingo Molnar:
"The main kernel side changes were:
- uprobes enhancements (Masami Hiramatsu)
- Uncore group events enhancements (David Carrillo-Cisneros)
- x86 Intel: Add support for Skylake server uncore PMUs (Kan Liang)
- x86 Intel: LBR cleanups and enhancements, for better branch
annotation tracking (Peter Zijlstra)
- x86 Intel: Add support for PTWRITE and power event tracing
(Alexander Shishkin)
- ... various fixes, cleanups and smaller enhancements.
Lots of tooling changes - a couple of highlights:
- Support event group view with hierarchy mode in 'perf top' and
'perf report' (Namhyung Kim)
e.g.:
$ perf record -e '{cycles,instructions}' make
$ perf report --hierarchy --stdio
...
# Overhead Command / Shared Object / Symbol
# ...................... ..................................
...
25.74% 27.18%sh
19.96% 24.14%libc-2.24.so
9.55% 14.64%[.] __strcmp_sse2
1.54% 0.00%[.] __tfind
1.07% 1.13%[.] _int_malloc
0.95% 0.00%[.] __strchr_sse2
0.89% 1.39%[.] __tsearch
0.76% 0.00%[.] strlen
- Add branch stack / basic block info to 'perf annotate --stdio',
where for each branch, we add an asm comment after the instruction
with information on how often it was taken and predicted. See
example with color output at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
(Peter Zijlstra)
- Add support for using symbols in address filters with Intel PT and
ARM CoreSight (hardware assisted tracing facilities) (Adrian
Hunter, Mathieu Poirier)
- Add support for interacting with Coresight PMU ETMs/PTMs, that are
IP blocks to perform hardware assisted tracing on a ARM CPU core
(Mathieu Poirier)
- Support generating cross arch probes, i.e. if you specify a vmlinux
file for different arch than the one in the host machine,
$ perf probe --definition function_name args
will generate the probe definition string needed to append to the
target machine /sys/kernel/debug/tracing/kprobes_events file, using
scripting (Masami Hiramatsu).
- Allow configuring the default 'perf report -s' sort order in
~/.perfconfig, for instance, "sym,dso" may be more fitting for
kernel developers. (Arnaldo Carvalho de Melo)
- ... plus lots of other changes, refactorings, features and fixes"
* 'perf-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (149 commits)
perf tests: Add dwarf unwind test for powerpc
perf probe: Match linkage name with mangled name
perf probe: Fix to cut off incompatible chars from group name
perf probe: Skip if the function address is 0
perf probe: Ignore the error of finding inline instance
perf intel-pt: Fix decoding when there are address filters
perf intel-pt: Enable decoder to handle TIP.PGD with missing IP
perf intel-pt: Read address filter from AUXTRACE_INFO event
perf intel-pt: Record address filter in AUXTRACE_INFO event
perf intel-pt: Add a helper function for processing AUXTRACE_INFO
perf intel-pt: Fix missing error codes processing auxtrace_info
perf intel-pt: Add support for recording the max non-turbo ratio
perf intel-pt: Fix snapshot overlap detection decoder errors
perf probe: Increase debug level of SDT debug messages
perf record: Add support for using symbols in address filters
perf symbols: Add dso__last_symbol()
perf record: Fix error paths
perf record: Rename label 'out_symbol_exit'
perf script: Fix vanished idle symbols
perf evsel: Add support for address filters
...
diff --git a/.mailmap b/.mailmap
index de22dae..1dab0a1 100644
--- a/.mailmap
+++ b/.mailmap
@@ -69,6 +69,7 @@
James Bottomley <jejb@titanic.il.steeleye.com>
James E Wilson <wilson@specifix.com>
James Ketrenos <jketreno@io.(none)>
+Javi Merino <javi.merino@kernel.org> <javi.merino@arm.com>
<javier@osg.samsung.com> <javier.martinez@collabora.co.uk>
Jean Tourrilhes <jt@hpl.hp.com>
Jeff Garzik <jgarzik@pretzel.yyz.us>
diff --git a/Documentation/RCU/Design/Requirements/Requirements.html b/Documentation/RCU/Design/Requirements/Requirements.html
index ece410f..a4d3838 100644
--- a/Documentation/RCU/Design/Requirements/Requirements.html
+++ b/Documentation/RCU/Design/Requirements/Requirements.html
@@ -2493,6 +2493,28 @@
variant of <tt>call_rcu()</tt> that might one day be created for
energy-efficiency purposes.
+<p>
+That said, there are limits.
+RCU requires that the <tt>rcu_head</tt> structure be aligned to a
+two-byte boundary, and passing a misaligned <tt>rcu_head</tt>
+structure to one of the <tt>call_rcu()</tt> family of functions
+will result in a splat.
+It is therefore necessary to exercise caution when packing
+structures containing fields of type <tt>rcu_head</tt>.
+Why not a four-byte or even eight-byte alignment requirement?
+Because the m68k architecture provides only two-byte alignment,
+and thus acts as alignment's least common denominator.
+
+<p>
+The reason for reserving the bottom bit of pointers to
+<tt>rcu_head</tt> structures is to leave the door open to
+“lazy” callbacks whose invocations can safely be deferred.
+Deferring invocation could potentially have energy-efficiency
+benefits, but only if the rate of non-lazy callbacks decreases
+significantly for some important workload.
+In the meantime, reserving the bottom bit keeps this option open
+in case it one day becomes useful.
+
<h3><a name="Performance, Scalability, Response Time, and Reliability">
Performance, Scalability, Response Time, and Reliability</a></h3>
diff --git a/Documentation/RCU/torture.txt b/Documentation/RCU/torture.txt
index 118e7c1..278f6a9 100644
--- a/Documentation/RCU/torture.txt
+++ b/Documentation/RCU/torture.txt
@@ -10,21 +10,6 @@
command (perhaps grepping for "torture"). The test is started
when the module is loaded, and stops when the module is unloaded.
-CONFIG_RCU_TORTURE_TEST_RUNNABLE
-
-It is also possible to specify CONFIG_RCU_TORTURE_TEST=y, which will
-result in the tests being loaded into the base kernel. In this case,
-the CONFIG_RCU_TORTURE_TEST_RUNNABLE config option is used to specify
-whether the RCU torture tests are to be started immediately during
-boot or whether the /proc/sys/kernel/rcutorture_runnable file is used
-to enable them. This /proc file can be used to repeatedly pause and
-restart the tests, regardless of the initial state specified by the
-CONFIG_RCU_TORTURE_TEST_RUNNABLE config option.
-
-You will normally -not- want to start the RCU torture tests during boot
-(and thus the default is CONFIG_RCU_TORTURE_TEST_RUNNABLE=n), but doing
-this can sometimes be useful in finding boot-time bugs.
-
MODULE PARAMETERS
diff --git a/Documentation/acpi/acpi-lid.txt b/Documentation/acpi/acpi-lid.txt
new file mode 100644
index 0000000..effe7af
--- /dev/null
+++ b/Documentation/acpi/acpi-lid.txt
@@ -0,0 +1,96 @@
+Special Usage Model of the ACPI Control Method Lid Device
+
+Copyright (C) 2016, Intel Corporation
+Author: Lv Zheng <lv.zheng@intel.com>
+
+
+Abstract:
+
+Platforms containing lids convey lid state (open/close) to OSPMs using a
+control method lid device. To implement this, the AML tables issue
+Notify(lid_device, 0x80) to notify the OSPMs whenever the lid state has
+changed. The _LID control method for the lid device must be implemented to
+report the "current" state of the lid as either "opened" or "closed".
+
+For most platforms, both the _LID method and the lid notifications are
+reliable. However, there are exceptions. In order to work with these
+exceptional buggy platforms, special restrictions and expections should be
+taken into account. This document describes the restrictions and the
+expections of the Linux ACPI lid device driver.
+
+
+1. Restrictions of the returning value of the _LID control method
+
+The _LID control method is described to return the "current" lid state.
+However the word of "current" has ambiguity, some buggy AML tables return
+the lid state upon the last lid notification instead of returning the lid
+state upon the last _LID evaluation. There won't be difference when the
+_LID control method is evaluated during the runtime, the problem is its
+initial returning value. When the AML tables implement this control method
+with cached value, the initial returning value is likely not reliable.
+There are platforms always retun "closed" as initial lid state.
+
+2. Restrictions of the lid state change notifications
+
+There are buggy AML tables never notifying when the lid device state is
+changed to "opened". Thus the "opened" notification is not guaranteed. But
+it is guaranteed that the AML tables always notify "closed" when the lid
+state is changed to "closed". The "closed" notification is normally used to
+trigger some system power saving operations on Windows. Since it is fully
+tested, it is reliable from all AML tables.
+
+3. Expections for the userspace users of the ACPI lid device driver
+
+The ACPI button driver exports the lid state to the userspace via the
+following file:
+ /proc/acpi/button/lid/LID0/state
+This file actually calls the _LID control method described above. And given
+the previous explanation, it is not reliable enough on some platforms. So
+it is advised for the userspace program to not to solely rely on this file
+to determine the actual lid state.
+
+The ACPI button driver emits the following input event to the userspace:
+ SW_LID
+The ACPI lid device driver is implemented to try to deliver the platform
+triggered events to the userspace. However, given the fact that the buggy
+firmware cannot make sure "opened"/"closed" events are paired, the ACPI
+button driver uses the following 3 modes in order not to trigger issues.
+
+If the userspace hasn't been prepared to ignore the unreliable "opened"
+events and the unreliable initial state notification, Linux users can use
+the following kernel parameters to handle the possible issues:
+A. button.lid_init_state=method:
+ When this option is specified, the ACPI button driver reports the
+ initial lid state using the returning value of the _LID control method
+ and whether the "opened"/"closed" events are paired fully relies on the
+ firmware implementation.
+ This option can be used to fix some platforms where the returning value
+ of the _LID control method is reliable but the initial lid state
+ notification is missing.
+ This option is the default behavior during the period the userspace
+ isn't ready to handle the buggy AML tables.
+B. button.lid_init_state=open:
+ When this option is specified, the ACPI button driver always reports the
+ initial lid state as "opened" and whether the "opened"/"closed" events
+ are paired fully relies on the firmware implementation.
+ This may fix some platforms where the returning value of the _LID
+ control method is not reliable and the initial lid state notification is
+ missing.
+
+If the userspace has been prepared to ignore the unreliable "opened" events
+and the unreliable initial state notification, Linux users should always
+use the following kernel parameter:
+C. button.lid_init_state=ignore:
+ When this option is specified, the ACPI button driver never reports the
+ initial lid state and there is a compensation mechanism implemented to
+ ensure that the reliable "closed" notifications can always be delievered
+ to the userspace by always pairing "closed" input events with complement
+ "opened" input events. But there is still no guarantee that the "opened"
+ notifications can be delivered to the userspace when the lid is actually
+ opens given that some AML tables do not send "opened" notifications
+ reliably.
+ In this mode, if everything is correctly implemented by the platform
+ firmware, the old userspace programs should still work. Otherwise, the
+ new userspace programs are required to work with the ACPI button driver.
+ This option will be the default behavior after the userspace is ready to
+ handle the buggy AML tables.
diff --git a/Documentation/acpi/gpio-properties.txt b/Documentation/acpi/gpio-properties.txt
index f35dad1..5aafe0b3 100644
--- a/Documentation/acpi/gpio-properties.txt
+++ b/Documentation/acpi/gpio-properties.txt
@@ -28,8 +28,8 @@
ToUUID("daffd814-6eba-4d8c-8a91-bc9bbf4aa301"),
Package ()
{
- Package () {"reset-gpio", Package() {^BTH, 1, 1, 0 }},
- Package () {"shutdown-gpio", Package() {^BTH, 0, 0, 0 }},
+ Package () {"reset-gpios", Package() {^BTH, 1, 1, 0 }},
+ Package () {"shutdown-gpios", Package() {^BTH, 0, 0, 0 }},
}
})
}
@@ -48,7 +48,7 @@
active low or high, the "active_low" argument can be used here. Setting
it to 1 marks the GPIO as active low.
-In our Bluetooth example the "reset-gpio" refers to the second GpioIo()
+In our Bluetooth example the "reset-gpios" refers to the second GpioIo()
resource, second pin in that resource with the GPIO number of 31.
ACPI GPIO Mappings Provided by Drivers
@@ -83,8 +83,8 @@
static const struct acpi_gpio_params shutdown_gpio = { 0, 0, false };
static const struct acpi_gpio_mapping bluetooth_acpi_gpios[] = {
- { "reset-gpio", &reset_gpio, 1 },
- { "shutdown-gpio", &shutdown_gpio, 1 },
+ { "reset-gpios", &reset_gpio, 1 },
+ { "shutdown-gpios", &shutdown_gpio, 1 },
{ },
};
diff --git a/Documentation/arm64/silicon-errata.txt b/Documentation/arm64/silicon-errata.txt
index ccc6032..405da11 100644
--- a/Documentation/arm64/silicon-errata.txt
+++ b/Documentation/arm64/silicon-errata.txt
@@ -61,3 +61,5 @@
| Cavium | ThunderX GICv3 | #23154 | CAVIUM_ERRATUM_23154 |
| Cavium | ThunderX Core | #27456 | CAVIUM_ERRATUM_27456 |
| Cavium | ThunderX SMMUv2 | #27704 | N/A |
+| | | | |
+| Freescale/NXP | LS2080A/LS1043A | A-008585 | FSL_ERRATUM_A008585 |
diff --git a/Documentation/devicetree/bindings/arm/arch_timer.txt b/Documentation/devicetree/bindings/arm/arch_timer.txt
index e774128..ef5fbe9 100644
--- a/Documentation/devicetree/bindings/arm/arch_timer.txt
+++ b/Documentation/devicetree/bindings/arm/arch_timer.txt
@@ -25,6 +25,12 @@
- always-on : a boolean property. If present, the timer is powered through an
always-on power domain, therefore it never loses context.
+- fsl,erratum-a008585 : A boolean property. Indicates the presence of
+ QorIQ erratum A-008585, which says that reading the counter is
+ unreliable unless the same value is returned by back-to-back reads.
+ This also affects writes to the tval register, due to the implicit
+ counter read.
+
** Optional properties:
- arm,cpu-registers-not-fw-configured : Firmware does not initialize
diff --git a/Documentation/devicetree/bindings/devfreq/event/rockchip-dfi.txt b/Documentation/devicetree/bindings/devfreq/event/rockchip-dfi.txt
new file mode 100644
index 0000000..f223313
--- /dev/null
+++ b/Documentation/devicetree/bindings/devfreq/event/rockchip-dfi.txt
@@ -0,0 +1,19 @@
+
+* Rockchip rk3399 DFI device
+
+Required properties:
+- compatible: Must be "rockchip,rk3399-dfi".
+- reg: physical base address of each DFI and length of memory mapped region
+- rockchip,pmu: phandle to the syscon managing the "pmu general register files"
+- clocks: phandles for clock specified in "clock-names" property
+- clock-names : the name of clock used by the DFI, must be "pclk_ddr_mon";
+
+Example:
+ dfi: dfi@0xff630000 {
+ compatible = "rockchip,rk3399-dfi";
+ reg = <0x00 0xff630000 0x00 0x4000>;
+ rockchip,pmu = <&pmugrf>;
+ clocks = <&cru PCLK_DDR_MON>;
+ clock-names = "pclk_ddr_mon";
+ status = "disabled";
+ };
diff --git a/Documentation/devicetree/bindings/devfreq/rk3399_dmc.txt b/Documentation/devicetree/bindings/devfreq/rk3399_dmc.txt
new file mode 100644
index 0000000..7a9e860
--- /dev/null
+++ b/Documentation/devicetree/bindings/devfreq/rk3399_dmc.txt
@@ -0,0 +1,209 @@
+* Rockchip rk3399 DMC(Dynamic Memory Controller) device
+
+Required properties:
+- compatible: Must be "rockchip,rk3399-dmc".
+- devfreq-events: Node to get DDR loading, Refer to
+ Documentation/devicetree/bindings/devfreq/
+ rockchip-dfi.txt
+- interrupts: The interrupt number to the CPU. The interrupt
+ specifier format depends on the interrupt controller.
+ It should be DCF interrupts, when DDR dvfs finish,
+ it will happen.
+- clocks: Phandles for clock specified in "clock-names" property
+- clock-names : The name of clock used by the DFI, must be
+ "pclk_ddr_mon";
+- operating-points-v2: Refer to Documentation/devicetree/bindings/power/opp.txt
+ for details.
+- center-supply: DMC supply node.
+- status: Marks the node enabled/disabled.
+
+Following properties are ddr timing:
+
+- rockchip,dram_speed_bin : Value reference include/dt-bindings/clock/ddr.h,
+ it select ddr3 cl-trp-trcd type, default value
+ "DDR3_DEFAULT".it must selected according to
+ "Speed Bin" in ddr3 datasheet, DO NOT use
+ smaller "Speed Bin" than ddr3 exactly is.
+
+- rockchip,pd_idle : Config the PD_IDLE value, defined the power-down
+ idle period, memories are places into power-down
+ mode if bus is idle for PD_IDLE DFI clocks.
+
+- rockchip,sr_idle : Configure the SR_IDLE value, defined the
+ selfrefresh idle period, memories are places
+ into self-refresh mode if bus is idle for
+ SR_IDLE*1024 DFI clocks (DFI clocks freq is
+ half of dram's clocks), defaule value is "0".
+
+- rockchip,sr_mc_gate_idle : Defined the self-refresh with memory and
+ controller clock gating idle period, memories
+ are places into self-refresh mode and memory
+ controller clock arg gating if bus is idle for
+ sr_mc_gate_idle*1024 DFI clocks.
+
+- rockchip,srpd_lite_idle : Defined the self-refresh power down idle
+ period, memories are places into self-refresh
+ power down mode if bus is idle for
+ srpd_lite_idle*1024 DFI clocks. This parameter
+ is for LPDDR4 only.
+
+- rockchip,standby_idle : Defined the standby idle period, memories are
+ places into self-refresh than controller, pi,
+ phy and dram clock will gating if bus is idle
+ for standby_idle * DFI clocks.
+
+- rockchip,dram_dll_disb_freq : It's defined the DDR3 dll bypass frequency in
+ MHz, when ddr freq less than DRAM_DLL_DISB_FREQ,
+ ddr3 dll will bypssed note: if dll was bypassed,
+ the odt also stop working.
+
+- rockchip,phy_dll_disb_freq : Defined the PHY dll bypass frequency in
+ MHz (Mega Hz), when ddr freq less than
+ DRAM_DLL_DISB_FREQ, phy dll will bypssed.
+ note: phy dll and phy odt are independent.
+
+- rockchip,ddr3_odt_disb_freq : When dram type is DDR3, this parameter defined
+ the odt disable frequency in MHz (Mega Hz),
+ when ddr frequency less then ddr3_odt_disb_freq,
+ the odt on dram side and controller side are
+ both disabled.
+
+- rockchip,ddr3_drv : When dram type is DDR3, this parameter define
+ the dram side driver stength in ohm, default
+ value is DDR3_DS_40ohm.
+
+- rockchip,ddr3_odt : When dram type is DDR3, this parameter define
+ the dram side ODT stength in ohm, default value
+ is DDR3_ODT_120ohm.
+
+- rockchip,phy_ddr3_ca_drv : When dram type is DDR3, this parameter define
+ the phy side CA line(incluing command line,
+ address line and clock line) driver strength.
+ Default value is PHY_DRV_ODT_40.
+
+- rockchip,phy_ddr3_dq_drv : When dram type is DDR3, this parameter define
+ the phy side DQ line(incluing DQS/DQ/DM line)
+ driver strength. default value is PHY_DRV_ODT_40.
+
+- rockchip,phy_ddr3_odt : When dram type is DDR3, this parameter define the
+ phy side odt strength, default value is
+ PHY_DRV_ODT_240.
+
+- rockchip,lpddr3_odt_disb_freq : When dram type is LPDDR3, this parameter defined
+ then odt disable frequency in MHz (Mega Hz),
+ when ddr frequency less then ddr3_odt_disb_freq,
+ the odt on dram side and controller side are
+ both disabled.
+
+- rockchip,lpddr3_drv : When dram type is LPDDR3, this parameter define
+ the dram side driver stength in ohm, default
+ value is LP3_DS_34ohm.
+
+- rockchip,lpddr3_odt : When dram type is LPDDR3, this parameter define
+ the dram side ODT stength in ohm, default value
+ is LP3_ODT_240ohm.
+
+- rockchip,phy_lpddr3_ca_drv : When dram type is LPDDR3, this parameter define
+ the phy side CA line(incluing command line,
+ address line and clock line) driver strength.
+ default value is PHY_DRV_ODT_40.
+
+- rockchip,phy_lpddr3_dq_drv : When dram type is LPDDR3, this parameter define
+ the phy side DQ line(incluing DQS/DQ/DM line)
+ driver strength. default value is
+ PHY_DRV_ODT_40.
+
+- rockchip,phy_lpddr3_odt : When dram type is LPDDR3, this parameter define
+ the phy side odt strength, default value is
+ PHY_DRV_ODT_240.
+
+- rockchip,lpddr4_odt_disb_freq : When dram type is LPDDR4, this parameter
+ defined the odt disable frequency in
+ MHz (Mega Hz), when ddr frequency less then
+ ddr3_odt_disb_freq, the odt on dram side and
+ controller side are both disabled.
+
+- rockchip,lpddr4_drv : When dram type is LPDDR4, this parameter define
+ the dram side driver stength in ohm, default
+ value is LP4_PDDS_60ohm.
+
+- rockchip,lpddr4_dq_odt : When dram type is LPDDR4, this parameter define
+ the dram side ODT on dqs/dq line stength in ohm,
+ default value is LP4_DQ_ODT_40ohm.
+
+- rockchip,lpddr4_ca_odt : When dram type is LPDDR4, this parameter define
+ the dram side ODT on ca line stength in ohm,
+ default value is LP4_CA_ODT_40ohm.
+
+- rockchip,phy_lpddr4_ca_drv : When dram type is LPDDR4, this parameter define
+ the phy side CA line(incluing command address
+ line) driver strength. default value is
+ PHY_DRV_ODT_40.
+
+- rockchip,phy_lpddr4_ck_cs_drv : When dram type is LPDDR4, this parameter define
+ the phy side clock line and cs line driver
+ strength. default value is PHY_DRV_ODT_80.
+
+- rockchip,phy_lpddr4_dq_drv : When dram type is LPDDR4, this parameter define
+ the phy side DQ line(incluing DQS/DQ/DM line)
+ driver strength. default value is PHY_DRV_ODT_80.
+
+- rockchip,phy_lpddr4_odt : When dram type is LPDDR4, this parameter define
+ the phy side odt strength, default value is
+ PHY_DRV_ODT_60.
+
+Example:
+ dmc_opp_table: dmc_opp_table {
+ compatible = "operating-points-v2";
+
+ opp00 {
+ opp-hz = /bits/ 64 <300000000>;
+ opp-microvolt = <900000>;
+ };
+ opp01 {
+ opp-hz = /bits/ 64 <666000000>;
+ opp-microvolt = <900000>;
+ };
+ };
+
+ dmc: dmc {
+ compatible = "rockchip,rk3399-dmc";
+ devfreq-events = <&dfi>;
+ interrupts = <GIC_SPI 1 IRQ_TYPE_LEVEL_HIGH>;
+ clocks = <&cru SCLK_DDRCLK>;
+ clock-names = "dmc_clk";
+ operating-points-v2 = <&dmc_opp_table>;
+ center-supply = <&ppvar_centerlogic>;
+ upthreshold = <15>;
+ downdifferential = <10>;
+ rockchip,ddr3_speed_bin = <21>;
+ rockchip,pd_idle = <0x40>;
+ rockchip,sr_idle = <0x2>;
+ rockchip,sr_mc_gate_idle = <0x3>;
+ rockchip,srpd_lite_idle = <0x4>;
+ rockchip,standby_idle = <0x2000>;
+ rockchip,dram_dll_dis_freq = <300>;
+ rockchip,phy_dll_dis_freq = <125>;
+ rockchip,auto_pd_dis_freq = <666>;
+ rockchip,ddr3_odt_dis_freq = <333>;
+ rockchip,ddr3_drv = <DDR3_DS_40ohm>;
+ rockchip,ddr3_odt = <DDR3_ODT_120ohm>;
+ rockchip,phy_ddr3_ca_drv = <PHY_DRV_ODT_40>;
+ rockchip,phy_ddr3_dq_drv = <PHY_DRV_ODT_40>;
+ rockchip,phy_ddr3_odt = <PHY_DRV_ODT_240>;
+ rockchip,lpddr3_odt_dis_freq = <333>;
+ rockchip,lpddr3_drv = <LP3_DS_34ohm>;
+ rockchip,lpddr3_odt = <LP3_ODT_240ohm>;
+ rockchip,phy_lpddr3_ca_drv = <PHY_DRV_ODT_40>;
+ rockchip,phy_lpddr3_dq_drv = <PHY_DRV_ODT_40>;
+ rockchip,phy_lpddr3_odt = <PHY_DRV_ODT_240>;
+ rockchip,lpddr4_odt_dis_freq = <333>;
+ rockchip,lpddr4_drv = <LP4_PDDS_60ohm>;
+ rockchip,lpddr4_dq_odt = <LP4_DQ_ODT_40ohm>;
+ rockchip,lpddr4_ca_odt = <LP4_CA_ODT_40ohm>;
+ rockchip,phy_lpddr4_ca_drv = <PHY_DRV_ODT_40>;
+ rockchip,phy_lpddr4_ck_cs_drv = <PHY_DRV_ODT_80>;
+ rockchip,phy_lpddr4_dq_drv = <PHY_DRV_ODT_80>;
+ rockchip,phy_lpddr4_odt = <PHY_DRV_ODT_60>;
+ status = "disabled";
+ };
diff --git a/Documentation/devicetree/bindings/input/touchscreen/silead_gsl1680.txt b/Documentation/devicetree/bindings/input/touchscreen/silead_gsl1680.txt
index 1112e0d..820fee4 100644
--- a/Documentation/devicetree/bindings/input/touchscreen/silead_gsl1680.txt
+++ b/Documentation/devicetree/bindings/input/touchscreen/silead_gsl1680.txt
@@ -13,6 +13,7 @@
- touchscreen-size-y : See touchscreen.txt
Optional properties:
+- firmware-name : File basename (string) for board specific firmware
- touchscreen-inverted-x : See touchscreen.txt
- touchscreen-inverted-y : See touchscreen.txt
- touchscreen-swapped-x-y : See touchscreen.txt
diff --git a/Documentation/kernel-parameters.txt b/Documentation/kernel-parameters.txt
index a4f4d69..25037de 100644
--- a/Documentation/kernel-parameters.txt
+++ b/Documentation/kernel-parameters.txt
@@ -698,6 +698,15 @@
loops can be debugged more effectively on production
systems.
+ clocksource.arm_arch_timer.fsl-a008585=
+ [ARM64]
+ Format: <bool>
+ Enable/disable the workaround of Freescale/NXP
+ erratum A-008585. This can be useful for KVM
+ guests, if the guest device tree doesn't show the
+ erratum. If unspecified, the workaround is
+ enabled based on the device tree.
+
clearcpuid=BITNUM [X86]
Disable CPUID feature X for the kernel. See
arch/x86/include/asm/cpufeatures.h for the valid bit
diff --git a/Documentation/ko_KR/memory-barriers.txt b/Documentation/ko_KR/memory-barriers.txt
new file mode 100644
index 0000000..34d3d38
--- /dev/null
+++ b/Documentation/ko_KR/memory-barriers.txt
@@ -0,0 +1,3135 @@
+NOTE:
+This is a version of Documentation/memory-barriers.txt translated into Korean.
+This document is maintained by SeongJae Park <sj38.park@gmail.com>.
+If you find any difference between this document and the original file or
+a problem with the translation, please contact the maintainer of this file.
+
+Please also note that the purpose of this file is to be easier to
+read for non English (read: Korean) speakers and is not intended as
+a fork. So if you have any comments or updates for this file please
+update the original English file first. The English version is
+definitive, and readers should look there if they have any doubt.
+
+===================================
+이 문서는
+Documentation/memory-barriers.txt
+의 한글 번역입니다.
+
+역자: 박성재 <sj38.park@gmail.com>
+===================================
+
+
+ =========================
+ 리눅스 커널 메모리 배리어
+ =========================
+
+저자: David Howells <dhowells@redhat.com>
+ Paul E. McKenney <paulmck@linux.vnet.ibm.com>
+ Will Deacon <will.deacon@arm.com>
+ Peter Zijlstra <peterz@infradead.org>
+
+========
+면책조항
+========
+
+이 문서는 명세서가 아닙니다; 이 문서는 완벽하지 않은데, 간결성을 위해 의도된
+부분도 있고, 의도하진 않았지만 사람에 의해 쓰였다보니 불완전한 부분도 있습니다.
+이 문서는 리눅스에서 제공하는 다양한 메모리 배리어들을 사용하기 위한
+안내서입니다만, 뭔가 이상하다 싶으면 (그런게 많을 겁니다) 질문을 부탁드립니다.
+
+다시 말하지만, 이 문서는 리눅스가 하드웨어에 기대하는 사항에 대한 명세서가
+아닙니다.
+
+이 문서의 목적은 두가지입니다:
+
+ (1) 어떤 특정 배리어에 대해 기대할 수 있는 최소한의 기능을 명세하기 위해서,
+ 그리고
+
+ (2) 사용 가능한 배리어들에 대해 어떻게 사용해야 하는지에 대한 안내를 제공하기
+ 위해서.
+
+어떤 아키텍쳐는 특정한 배리어들에 대해서는 여기서 이야기하는 최소한의
+요구사항들보다 많은 기능을 제공할 수도 있습니다만, 여기서 이야기하는
+요구사항들을 충족하지 않는 아키텍쳐가 있다면 그 아키텍쳐가 잘못된 것이란 점을
+알아두시기 바랍니다.
+
+또한, 특정 아키텍쳐에서 일부 배리어는 해당 아키텍쳐의 특수한 동작 방식으로 인해
+해당 배리어의 명시적 사용이 불필요해서 no-op 이 될수도 있음을 알아두시기
+바랍니다.
+
+역자: 본 번역 역시 완벽하지 않은데, 이 역시 부분적으로는 의도된 것이기도
+합니다. 여타 기술 문서들이 그렇듯 완벽한 이해를 위해서는 번역문과 원문을 함께
+읽으시되 번역문을 하나의 가이드로 활용하시길 추천드리며, 발견되는 오역 등에
+대해서는 언제든 의견을 부탁드립니다. 과한 번역으로 인한 오해를 최소화하기 위해
+애매한 부분이 있을 경우에는 어색함이 있더라도 원래의 용어를 차용합니다.
+
+
+=====
+목차:
+=====
+
+ (*) 추상 메모리 액세스 모델.
+
+ - 디바이스 오퍼레이션.
+ - 보장사항.
+
+ (*) 메모리 배리어란 무엇인가?
+
+ - 메모리 배리어의 종류.
+ - 메모리 배리어에 대해 가정해선 안될 것.
+ - 데이터 의존성 배리어.
+ - 컨트롤 의존성.
+ - SMP 배리어 짝맞추기.
+ - 메모리 배리어 시퀀스의 예.
+ - 읽기 메모리 배리어 vs 로드 예측.
+ - 이행성
+
+ (*) 명시적 커널 배리어.
+
+ - 컴파일러 배리어.
+ - CPU 메모리 배리어.
+ - MMIO 쓰기 배리어.
+
+ (*) 암묵적 커널 메모리 배리어.
+
+ - 락 Acquisition 함수.
+ - 인터럽트 비활성화 함수.
+ - 슬립과 웨이크업 함수.
+ - 그외의 함수들.
+
+ (*) CPU 간 ACQUIRING 배리어의 효과.
+
+ - Acquire vs 메모리 액세스.
+ - Acquire vs I/O 액세스.
+
+ (*) 메모리 배리어가 필요한 곳
+
+ - 프로세서간 상호 작용.
+ - 어토믹 오퍼레이션.
+ - 디바이스 액세스.
+ - 인터럽트.
+
+ (*) 커널 I/O 배리어의 효과.
+
+ (*) 가정되는 가장 완화된 실행 순서 모델.
+
+ (*) CPU 캐시의 영향.
+
+ - 캐시 일관성.
+ - 캐시 일관성 vs DMA.
+ - 캐시 일관성 vs MMIO.
+
+ (*) CPU 들이 저지르는 일들.
+
+ - 그리고, Alpha 가 있다.
+ - 가상 머신 게스트.
+
+ (*) 사용 예.
+
+ - 순환식 버퍼.
+
+ (*) 참고 문헌.
+
+
+=======================
+추상 메모리 액세스 모델
+=======================
+
+다음과 같이 추상화된 시스템 모델을 생각해 봅시다:
+
+ : :
+ : :
+ : :
+ +-------+ : +--------+ : +-------+
+ | | : | | : | |
+ | | : | | : | |
+ | CPU 1 |<----->| Memory |<----->| CPU 2 |
+ | | : | | : | |
+ | | : | | : | |
+ +-------+ : +--------+ : +-------+
+ ^ : ^ : ^
+ | : | : |
+ | : | : |
+ | : v : |
+ | : +--------+ : |
+ | : | | : |
+ | : | | : |
+ +---------->| Device |<----------+
+ : | | :
+ : | | :
+ : +--------+ :
+ : :
+
+프로그램은 여러 메모리 액세스 오퍼레이션을 발생시키고, 각각의 CPU 는 그런
+프로그램들을 실행합니다. 추상화된 CPU 모델에서 메모리 오퍼레이션들의 순서는
+매우 완화되어 있고, CPU 는 프로그램이 인과관계를 어기지 않는 상태로 관리된다고
+보일 수만 있다면 메모리 오퍼레이션을 자신이 원하는 어떤 순서대로든 재배치해
+동작시킬 수 있습니다. 비슷하게, 컴파일러 또한 프로그램의 정상적 동작을 해치지
+않는 한도 내에서는 어떤 순서로든 자신이 원하는 대로 인스트럭션을 재배치 할 수
+있습니다.
+
+따라서 위의 다이어그램에서 한 CPU가 동작시키는 메모리 오퍼레이션이 만들어내는
+변화는 해당 오퍼레이션이 CPU 와 시스템의 다른 부분들 사이의 인터페이스(점선)를
+지나가면서 시스템의 나머지 부분들에 인지됩니다.
+
+
+예를 들어, 다음의 일련의 이벤트들을 생각해 봅시다:
+
+ CPU 1 CPU 2
+ =============== ===============
+ { A == 1; B == 2 }
+ A = 3; x = B;
+ B = 4; y = A;
+
+다이어그램의 가운데에 위치한 메모리 시스템에 보여지게 되는 액세스들은 다음의 총
+24개의 조합으로 재구성될 수 있습니다:
+
+ STORE A=3, STORE B=4, y=LOAD A->3, x=LOAD B->4
+ STORE A=3, STORE B=4, x=LOAD B->4, y=LOAD A->3
+ STORE A=3, y=LOAD A->3, STORE B=4, x=LOAD B->4
+ STORE A=3, y=LOAD A->3, x=LOAD B->2, STORE B=4
+ STORE A=3, x=LOAD B->2, STORE B=4, y=LOAD A->3
+ STORE A=3, x=LOAD B->2, y=LOAD A->3, STORE B=4
+ STORE B=4, STORE A=3, y=LOAD A->3, x=LOAD B->4
+ STORE B=4, ...
+ ...
+
+따라서 다음의 네가지 조합의 값들이 나올 수 있습니다:
+
+ x == 2, y == 1
+ x == 2, y == 3
+ x == 4, y == 1
+ x == 4, y == 3
+
+
+한발 더 나아가서, 한 CPU 가 메모리 시스템에 반영한 스토어 오퍼레이션들의 결과는
+다른 CPU 에서의 로드 오퍼레이션을 통해 인지되는데, 이 때 스토어가 반영된 순서와
+다른 순서로 인지될 수도 있습니다.
+
+
+예로, 아래의 일련의 이벤트들을 생각해 봅시다:
+
+ CPU 1 CPU 2
+ =============== ===============
+ { A == 1, B == 2, C == 3, P == &A, Q == &C }
+ B = 4; Q = P;
+ P = &B D = *Q;
+
+D 로 읽혀지는 값은 CPU 2 에서 P 로부터 읽혀진 주소값에 의존적이기 때문에 여기엔
+분명한 데이터 의존성이 있습니다. 하지만 이 이벤트들의 실행 결과로는 아래의
+결과들이 모두 나타날 수 있습니다:
+
+ (Q == &A) and (D == 1)
+ (Q == &B) and (D == 2)
+ (Q == &B) and (D == 4)
+
+CPU 2 는 *Q 의 로드를 요청하기 전에 P 를 Q 에 넣기 때문에 D 에 C 를 집어넣는
+일은 없음을 알아두세요.
+
+
+디바이스 오퍼레이션
+-------------------
+
+일부 디바이스는 자신의 컨트롤 인터페이스를 메모리의 특정 영역으로 매핑해서
+제공하는데(Memory mapped I/O), 해당 컨트롤 레지스터에 접근하는 순서는 매우
+중요합니다. 예를 들어, 어드레스 포트 레지스터 (A) 와 데이터 포트 레지스터 (D)
+를 통해 접근되는 내부 레지스터 집합을 갖는 이더넷 카드를 생각해 봅시다. 내부의
+5번 레지스터를 읽기 위해 다음의 코드가 사용될 수 있습니다:
+
+ *A = 5;
+ x = *D;
+
+하지만, 이건 다음의 두 조합 중 하나로 만들어질 수 있습니다:
+
+ STORE *A = 5, x = LOAD *D
+ x = LOAD *D, STORE *A = 5
+
+두번째 조합은 데이터를 읽어온 _후에_ 주소를 설정하므로, 오동작을 일으킬 겁니다.
+
+
+보장사항
+--------
+
+CPU 에게 기대할 수 있는 최소한의 보장사항 몇가지가 있습니다:
+
+ (*) 어떤 CPU 든, 의존성이 존재하는 메모리 액세스들은 해당 CPU 자신에게
+ 있어서는 순서대로 메모리 시스템에 수행 요청됩니다. 즉, 다음에 대해서:
+
+ Q = READ_ONCE(P); smp_read_barrier_depends(); D = READ_ONCE(*Q);
+
+ CPU 는 다음과 같은 메모리 오퍼레이션 시퀀스를 수행 요청합니다:
+
+ Q = LOAD P, D = LOAD *Q
+
+ 그리고 그 시퀀스 내에서의 순서는 항상 지켜집니다. 대부분의 시스템에서
+ smp_read_barrier_depends() 는 아무일도 안하지만 DEC Alpha 에서는
+ 명시적으로 사용되어야 합니다. 보통의 경우에는 smp_read_barrier_depends()
+ 를 직접 사용하는 대신 rcu_dereference() 같은 것들을 사용해야 함을
+ 알아두세요.
+
+ (*) 특정 CPU 내에서 겹치는 영역의 메모리에 행해지는 로드와 스토어 들은 해당
+ CPU 안에서는 순서가 바뀌지 않은 것으로 보여집니다. 즉, 다음에 대해서:
+
+ a = READ_ONCE(*X); WRITE_ONCE(*X, b);
+
+ CPU 는 다음의 메모리 오퍼레이션 시퀀스만을 메모리에 요청할 겁니다:
+
+ a = LOAD *X, STORE *X = b
+
+ 그리고 다음에 대해서는:
+
+ WRITE_ONCE(*X, c); d = READ_ONCE(*X);
+
+ CPU 는 다음의 수행 요청만을 만들어 냅니다:
+
+ STORE *X = c, d = LOAD *X
+
+ (로드 오퍼레이션과 스토어 오퍼레이션이 겹치는 메모리 영역에 대해
+ 수행된다면 해당 오퍼레이션들은 겹친다고 표현됩니다).
+
+그리고 _반드시_ 또는 _절대로_ 가정하거나 가정하지 말아야 하는 것들이 있습니다:
+
+ (*) 컴파일러가 READ_ONCE() 나 WRITE_ONCE() 로 보호되지 않은 메모리 액세스를
+ 당신이 원하는 대로 할 것이라는 가정은 _절대로_ 해선 안됩니다. 그것들이
+ 없다면, 컴파일러는 컴파일러 배리어 섹션에서 다루게 될, 모든 "창의적인"
+ 변경들을 만들어낼 권한을 갖게 됩니다.
+
+ (*) 개별적인 로드와 스토어들이 주어진 순서대로 요청될 것이라는 가정은 _절대로_
+ 하지 말아야 합니다. 이 말은 곧:
+
+ X = *A; Y = *B; *D = Z;
+
+ 는 다음의 것들 중 어느 것으로든 만들어질 수 있다는 의미입니다:
+
+ X = LOAD *A, Y = LOAD *B, STORE *D = Z
+ X = LOAD *A, STORE *D = Z, Y = LOAD *B
+ Y = LOAD *B, X = LOAD *A, STORE *D = Z
+ Y = LOAD *B, STORE *D = Z, X = LOAD *A
+ STORE *D = Z, X = LOAD *A, Y = LOAD *B
+ STORE *D = Z, Y = LOAD *B, X = LOAD *A
+
+ (*) 겹치는 메모리 액세스들은 합쳐지거나 버려질 수 있음을 _반드시_ 가정해야
+ 합니다. 다음의 코드는:
+
+ X = *A; Y = *(A + 4);
+
+ 다음의 것들 중 뭐든 될 수 있습니다:
+
+ X = LOAD *A; Y = LOAD *(A + 4);
+ Y = LOAD *(A + 4); X = LOAD *A;
+ {X, Y} = LOAD {*A, *(A + 4) };
+
+ 그리고:
+
+ *A = X; *(A + 4) = Y;
+
+ 는 다음 중 뭐든 될 수 있습니다:
+
+ STORE *A = X; STORE *(A + 4) = Y;
+ STORE *(A + 4) = Y; STORE *A = X;
+ STORE {*A, *(A + 4) } = {X, Y};
+
+그리고 보장사항에 반대되는 것들(anti-guarantees)이 있습니다:
+
+ (*) 이 보장사항들은 bitfield 에는 적용되지 않는데, 컴파일러들은 bitfield 를
+ 수정하는 코드를 생성할 때 원자성 없는(non-atomic) 읽고-수정하고-쓰는
+ 인스트럭션들의 조합을 만드는 경우가 많기 때문입니다. 병렬 알고리즘의
+ 동기화에 bitfield 를 사용하려 하지 마십시오.
+
+ (*) bitfield 들이 여러 락으로 보호되는 경우라 하더라도, 하나의 bitfield 의
+ 모든 필드들은 하나의 락으로 보호되어야 합니다. 만약 한 bitfield 의 두
+ 필드가 서로 다른 락으로 보호된다면, 컴파일러의 원자성 없는
+ 읽고-수정하고-쓰는 인스트럭션 조합은 한 필드에의 업데이트가 근처의
+ 필드에도 영향을 끼치게 할 수 있습니다.
+
+ (*) 이 보장사항들은 적절하게 정렬되고 크기가 잡힌 스칼라 변수들에 대해서만
+ 적용됩니다. "적절하게 크기가 잡힌" 이라함은 현재로써는 "char", "short",
+ "int" 그리고 "long" 과 같은 크기의 변수들을 의미합니다. "적절하게 정렬된"
+ 은 자연스런 정렬을 의미하는데, 따라서 "char" 에 대해서는 아무 제약이 없고,
+ "short" 에 대해서는 2바이트 정렬을, "int" 에는 4바이트 정렬을, 그리고
+ "long" 에 대해서는 32-bit 시스템인지 64-bit 시스템인지에 따라 4바이트 또는
+ 8바이트 정렬을 의미합니다. 이 보장사항들은 C11 표준에서 소개되었으므로,
+ C11 전의 오래된 컴파일러(예를 들어, gcc 4.6) 를 사용할 때엔 주의하시기
+ 바랍니다. 표준에 이 보장사항들은 "memory location" 을 정의하는 3.14
+ 섹션에 다음과 같이 설명되어 있습니다:
+ (역자: 인용문이므로 번역하지 않습니다)
+
+ memory location
+ either an object of scalar type, or a maximal sequence
+ of adjacent bit-fields all having nonzero width
+
+ NOTE 1: Two threads of execution can update and access
+ separate memory locations without interfering with
+ each other.
+
+ NOTE 2: A bit-field and an adjacent non-bit-field member
+ are in separate memory locations. The same applies
+ to two bit-fields, if one is declared inside a nested
+ structure declaration and the other is not, or if the two
+ are separated by a zero-length bit-field declaration,
+ or if they are separated by a non-bit-field member
+ declaration. It is not safe to concurrently update two
+ bit-fields in the same structure if all members declared
+ between them are also bit-fields, no matter what the
+ sizes of those intervening bit-fields happen to be.
+
+
+=========================
+메모리 배리어란 무엇인가?
+=========================
+
+앞에서 봤듯이, 상호간 의존성이 없는 메모리 오퍼레이션들은 실제로는 무작위적
+순서로 수행될 수 있으며, 이는 CPU 와 CPU 간의 상호작용이나 I/O 에 문제가 될 수
+있습니다. 따라서 컴파일러와 CPU 가 순서를 바꾸는데 제약을 걸 수 있도록 개입할
+수 있는 어떤 방법이 필요합니다.
+
+메모리 배리어는 그런 개입 수단입니다. 메모리 배리어는 배리어를 사이에 둔 앞과
+뒤 양측의 메모리 오퍼레이션들 간에 부분적 순서가 존재하도록 하는 효과를 줍니다.
+
+시스템의 CPU 들과 여러 디바이스들은 성능을 올리기 위해 명령어 재배치, 실행
+유예, 메모리 오퍼레이션들의 조합, 예측적 로드(speculative load), 브랜치
+예측(speculative branch prediction), 다양한 종류의 캐싱(caching) 등의 다양한
+트릭을 사용할 수 있기 때문에 이런 강제력은 중요합니다. 메모리 배리어들은 이런
+트릭들을 무효로 하거나 억제하는 목적으로 사용되어져서 코드가 여러 CPU 와
+디바이스들 간의 상호작용을 정상적으로 제어할 수 있게 해줍니다.
+
+
+메모리 배리어의 종류
+--------------------
+
+메모리 배리어는 네개의 기본 타입으로 분류됩니다:
+
+ (1) 쓰기 (또는 스토어) 메모리 배리어.
+
+ 쓰기 메모리 배리어는 시스템의 다른 컴포넌트들에 해당 배리어보다 앞서
+ 명시된 모든 STORE 오퍼레이션들이 해당 배리어 뒤에 명시된 모든 STORE
+ 오퍼레이션들보다 먼저 수행된 것으로 보일 것을 보장합니다.
+
+ 쓰기 배리어는 스토어 오퍼레이션들에 대한 부분적 순서 세우기입니다; 로드
+ 오퍼레이션들에 대해서는 어떤 영향도 끼치지 않습니다.
+
+ CPU 는 시간의 흐름에 따라 메모리 시스템에 일련의 스토어 오퍼레이션들을
+ 하나씩 요청해 집어넣습니다. 쓰기 배리어 앞의 모든 스토어 오퍼레이션들은
+ 쓰기 배리어 뒤의 모든 스토어 오퍼레이션들보다 _앞서_ 수행될 겁니다.
+
+ [!] 쓰기 배리어들은 읽기 또는 데이터 의존성 배리어와 함께 짝을 맞춰
+ 사용되어야만 함을 알아두세요; "SMP 배리어 짝맞추기" 서브섹션을 참고하세요.
+
+
+ (2) 데이터 의존성 배리어.
+
+ 데이터 의존성 배리어는 읽기 배리어의 보다 완화된 형태입니다. 두개의 로드
+ 오퍼레이션이 있고 두번째 것이 첫번째 것의 결과에 의존하고 있을 때(예:
+ 두번째 로드가 참조할 주소를 첫번째 로드가 읽는 경우), 두번째 로드가 읽어올
+ 데이터는 첫번째 로드에 의해 그 주소가 얻어지기 전에 업데이트 되어 있음을
+ 보장하기 위해서 데이터 의존성 배리어가 필요할 수 있습니다.
+
+ 데이터 의존성 배리어는 상호 의존적인 로드 오퍼레이션들 사이의 부분적 순서
+ 세우기입니다; 스토어 오퍼레이션들이나 독립적인 로드들, 또는 중복되는
+ 로드들에 대해서는 어떤 영향도 끼치지 않습니다.
+
+ (1) 에서 언급했듯이, 시스템의 CPU 들은 메모리 시스템에 일련의 스토어
+ 오퍼레이션들을 던져 넣고 있으며, 거기에 관심이 있는 다른 CPU 는 그
+ 오퍼레이션들을 메모리 시스템이 실행한 결과를 인지할 수 있습니다. 이처럼
+ 다른 CPU 의 스토어 오퍼레이션의 결과에 관심을 두고 있는 CPU 가 수행 요청한
+ 데이터 의존성 배리어는, 배리어 앞의 어떤 로드 오퍼레이션이 다른 CPU 에서
+ 던져 넣은 스토어 오퍼레이션과 같은 영역을 향했다면, 그런 스토어
+ 오퍼레이션들이 만들어내는 결과가 데이터 의존성 배리어 뒤의 로드
+ 오퍼레이션들에게는 보일 것을 보장합니다.
+
+ 이 순서 세우기 제약에 대한 그림을 보기 위해선 "메모리 배리어 시퀀스의 예"
+ 서브섹션을 참고하시기 바랍니다.
+
+ [!] 첫번째 로드는 반드시 _데이터_ 의존성을 가져야지 컨트롤 의존성을 가져야
+ 하는게 아님을 알아두십시오. 만약 두번째 로드를 위한 주소가 첫번째 로드에
+ 의존적이지만 그 의존성은 조건적이지 그 주소 자체를 가져오는게 아니라면,
+ 그것은 _컨트롤_ 의존성이고, 이 경우에는 읽기 배리어나 그보다 강력한
+ 무언가가 필요합니다. 더 자세한 내용을 위해서는 "컨트롤 의존성" 서브섹션을
+ 참고하시기 바랍니다.
+
+ [!] 데이터 의존성 배리어는 보통 쓰기 배리어들과 함께 짝을 맞춰 사용되어야
+ 합니다; "SMP 배리어 짝맞추기" 서브섹션을 참고하세요.
+
+
+ (3) 읽기 (또는 로드) 메모리 배리어.
+
+ 읽기 배리어는 데이터 의존성 배리어 기능의 보장사항에 더해서 배리어보다
+ 앞서 명시된 모든 LOAD 오퍼레이션들이 배리어 뒤에 명시되는 모든 LOAD
+ 오퍼레이션들보다 먼저 행해진 것으로 시스템의 다른 컴포넌트들에 보여질 것을
+ 보장합니다.
+
+ 읽기 배리어는 로드 오퍼레이션에 행해지는 부분적 순서 세우기입니다; 스토어
+ 오퍼레이션에 대해서는 어떤 영향도 끼치지 않습니다.
+
+ 읽기 메모리 배리어는 데이터 의존성 배리어를 내장하므로 데이터 의존성
+ 배리어를 대신할 수 있습니다.
+
+ [!] 읽기 배리어는 일반적으로 쓰기 배리어들과 함께 짝을 맞춰 사용되어야
+ 합니다; "SMP 배리어 짝맞추기" 서브섹션을 참고하세요.
+
+
+ (4) 범용 메모리 배리어.
+
+ 범용(general) 메모리 배리어는 배리어보다 앞서 명시된 모든 LOAD 와 STORE
+ 오퍼레이션들이 배리어 뒤에 명시된 모든 LOAD 와 STORE 오퍼레이션들보다
+ 먼저 수행된 것으로 시스템의 나머지 컴포넌트들에 보이게 됨을 보장합니다.
+
+ 범용 메모리 배리어는 로드와 스토어 모두에 대한 부분적 순서 세우기입니다.
+
+ 범용 메모리 배리어는 읽기 메모리 배리어, 쓰기 메모리 배리어 모두를
+ 내장하므로, 두 배리어를 모두 대신할 수 있습니다.
+
+
+그리고 두개의 명시적이지 않은 타입이 있습니다:
+
+ (5) ACQUIRE 오퍼레이션.
+
+ 이 타입의 오퍼레이션은 단방향의 투과성 배리어처럼 동작합니다. ACQUIRE
+ 오퍼레이션 뒤의 모든 메모리 오퍼레이션들이 ACQUIRE 오퍼레이션 후에
+ 일어난 것으로 시스템의 나머지 컴포넌트들에 보이게 될 것이 보장됩니다.
+ LOCK 오퍼레이션과 smp_load_acquire(), smp_cond_acquire() 오퍼레이션도
+ ACQUIRE 오퍼레이션에 포함됩니다. smp_cond_acquire() 오퍼레이션은 컨트롤
+ 의존성과 smp_rmb() 를 사용해서 ACQUIRE 의 의미적 요구사항(semantic)을
+ 충족시킵니다.
+
+ ACQUIRE 오퍼레이션 앞의 메모리 오퍼레이션들은 ACQUIRE 오퍼레이션 완료 후에
+ 수행된 것처럼 보일 수 있습니다.
+
+ ACQUIRE 오퍼레이션은 거의 항상 RELEASE 오퍼레이션과 짝을 지어 사용되어야
+ 합니다.
+
+
+ (6) RELEASE 오퍼레이션.
+
+ 이 타입의 오퍼레이션들도 단방향 투과성 배리어처럼 동작합니다. RELEASE
+ 오퍼레이션 앞의 모든 메모리 오퍼레이션들은 RELEASE 오퍼레이션 전에 완료된
+ 것으로 시스템의 다른 컴포넌트들에 보여질 것이 보장됩니다. UNLOCK 류의
+ 오퍼레이션들과 smp_store_release() 오퍼레이션도 RELEASE 오퍼레이션의
+ 일종입니다.
+
+ RELEASE 오퍼레이션 뒤의 메모리 오퍼레이션들은 RELEASE 오퍼레이션이
+ 완료되기 전에 행해진 것처럼 보일 수 있습니다.
+
+ ACQUIRE 와 RELEASE 오퍼레이션의 사용은 일반적으로 다른 메모리 배리어의
+ 필요성을 없앱니다 (하지만 "MMIO 쓰기 배리어" 서브섹션에서 설명되는 예외를
+ 알아두세요). 또한, RELEASE+ACQUIRE 조합은 범용 메모리 배리어처럼 동작할
+ 것을 보장하지 -않습니다-. 하지만, 어떤 변수에 대한 RELEASE 오퍼레이션을
+ 앞서는 메모리 액세스들의 수행 결과는 이 RELEASE 오퍼레이션을 뒤이어 같은
+ 변수에 대해 수행된 ACQUIRE 오퍼레이션을 뒤따르는 메모리 액세스에는 보여질
+ 것이 보장됩니다. 다르게 말하자면, 주어진 변수의 크리티컬 섹션에서는, 해당
+ 변수에 대한 앞의 크리티컬 섹션에서의 모든 액세스들이 완료되었을 것을
+ 보장합니다.
+
+ 즉, ACQUIRE 는 최소한의 "취득" 동작처럼, 그리고 RELEASE 는 최소한의 "공개"
+ 처럼 동작한다는 의미입니다.
+
+atomic_ops.txt 에서 설명되는 어토믹 오퍼레이션들 중에는 완전히 순서잡힌 것들과
+(배리어를 사용하지 않는) 완화된 순서의 것들 외에 ACQUIRE 와 RELEASE 부류의
+것들도 존재합니다. 로드와 스토어를 모두 수행하는 조합된 어토믹 오퍼레이션에서,
+ACQUIRE 는 해당 오퍼레이션의 로드 부분에만 적용되고 RELEASE 는 해당
+오퍼레이션의 스토어 부분에만 적용됩니다.
+
+메모리 배리어들은 두 CPU 간, 또는 CPU 와 디바이스 간에 상호작용의 가능성이 있을
+때에만 필요합니다. 만약 어떤 코드에 그런 상호작용이 없을 것이 보장된다면, 해당
+코드에서는 메모리 배리어를 사용할 필요가 없습니다.
+
+
+이것들은 _최소한의_ 보장사항들임을 알아두세요. 다른 아키텍쳐에서는 더 강력한
+보장사항을 제공할 수도 있습니다만, 그런 보장사항은 아키텍쳐 종속적 코드 이외의
+부분에서는 신뢰되지 _않을_ 겁니다.
+
+
+메모리 배리어에 대해 가정해선 안될 것
+-------------------------------------
+
+리눅스 커널 메모리 배리어들이 보장하지 않는 것들이 있습니다:
+
+ (*) 메모리 배리어 앞에서 명시된 어떤 메모리 액세스도 메모리 배리어 명령의 수행
+ 완료 시점까지 _완료_ 될 것이란 보장은 없습니다; 배리어가 하는 일은 CPU 의
+ 액세스 큐에 특정 타입의 액세스들은 넘을 수 없는 선을 긋는 것으로 생각될 수
+ 있습니다.
+
+ (*) 한 CPU 에서 메모리 배리어를 수행하는게 시스템의 다른 CPU 나 하드웨어에
+ 어떤 직접적인 영향을 끼친다는 보장은 존재하지 않습니다. 배리어 수행이
+ 만드는 간접적 영향은 두번째 CPU 가 첫번째 CPU 의 액세스들의 결과를
+ 바라보는 순서가 됩니다만, 다음 항목을 보세요:
+
+ (*) 첫번째 CPU 가 두번째 CPU 의 메모리 액세스들의 결과를 바라볼 때, _설령_
+ 두번째 CPU 가 메모리 배리어를 사용한다 해도, 첫번째 CPU _또한_ 그에 맞는
+ 메모리 배리어를 사용하지 않는다면 ("SMP 배리어 짝맞추기" 서브섹션을
+ 참고하세요) 그 결과가 올바른 순서로 보여진다는 보장은 없습니다.
+
+ (*) CPU 바깥의 하드웨어[*] 가 메모리 액세스들의 순서를 바꾸지 않는다는 보장은
+ 존재하지 않습니다. CPU 캐시 일관성 메커니즘은 메모리 배리어의 간접적
+ 영향을 CPU 사이에 전파하긴 하지만, 순서대로 전파하지는 않을 수 있습니다.
+
+ [*] 버스 마스터링 DMA 와 일관성에 대해서는 다음을 참고하시기 바랍니다:
+
+ Documentation/PCI/pci.txt
+ Documentation/DMA-API-HOWTO.txt
+ Documentation/DMA-API.txt
+
+
+데이터 의존성 배리어
+--------------------
+
+데이터 의존성 배리어의 사용에 있어 지켜야 하는 사항들은 약간 미묘하고, 데이터
+의존성 배리어가 사용되어야 하는 상황도 항상 명백하지는 않습니다. 설명을 위해
+다음의 이벤트 시퀀스를 생각해 봅시다:
+
+ CPU 1 CPU 2
+ =============== ===============
+ { A == 1, B == 2, C == 3, P == &A, Q == &C }
+ B = 4;
+ <쓰기 배리어>
+ WRITE_ONCE(P, &B)
+ Q = READ_ONCE(P);
+ D = *Q;
+
+여기엔 분명한 데이터 의존성이 존재하므로, 이 시퀀스가 끝났을 때 Q 는 &A 또는 &B
+일 것이고, 따라서:
+
+ (Q == &A) 는 (D == 1) 를,
+ (Q == &B) 는 (D == 4) 를 의미합니다.
+
+하지만! CPU 2 는 B 의 업데이트를 인식하기 전에 P 의 업데이트를 인식할 수 있고,
+따라서 다음의 결과가 가능합니다:
+
+ (Q == &B) and (D == 2) ????
+
+이런 결과는 일관성이나 인과 관계 유지가 실패한 것처럼 보일 수도 있겠지만,
+그렇지 않습니다, 그리고 이 현상은 (DEC Alpha 와 같은) 여러 CPU 에서 실제로
+발견될 수 있습니다.
+
+이 문제 상황을 제대로 해결하기 위해, 데이터 의존성 배리어나 그보다 강화된
+무언가가 주소를 읽어올 때와 데이터를 읽어올 때 사이에 추가되어야만 합니다:
+
+ CPU 1 CPU 2
+ =============== ===============
+ { A == 1, B == 2, C == 3, P == &A, Q == &C }
+ B = 4;
+ <쓰기 배리어>
+ WRITE_ONCE(P, &B);
+ Q = READ_ONCE(P);
+ <데이터 의존성 배리어>
+ D = *Q;
+
+이 변경은 앞의 처음 두가지 결과 중 하나만이 발생할 수 있고, 세번째의 결과는
+발생할 수 없도록 합니다.
+
+데이터 의존성 배리어는 의존적 쓰기에 대해서도 순서를 잡아줍니다:
+
+ CPU 1 CPU 2
+ =============== ===============
+ { A == 1, B == 2, C = 3, P == &A, Q == &C }
+ B = 4;
+ <쓰기 배리어>
+ WRITE_ONCE(P, &B);
+ Q = READ_ONCE(P);
+ <데이터 의존성 배리어>
+ *Q = 5;
+
+이 데이터 의존성 배리어는 Q 로의 읽기가 *Q 로의 스토어와 순서를 맞추게
+해줍니다. 이는 다음과 같은 결과를 막습니다:
+
+ (Q == &B) && (B == 4)
+
+이런 패턴은 드물게 사용되어야 함을 알아 두시기 바랍니다. 무엇보다도, 의존성
+순서 규칙의 의도는 쓰기 작업을 -예방- 해서 그로 인해 발생하는 비싼 캐시 미스도
+없애려는 것입니다. 이 패턴은 드물게 발생하는 에러 조건 같은것들을 기록하는데
+사용될 수 있고, 이렇게 배리어를 사용해 순서를 지키게 함으로써 그런 기록이
+사라지는 것을 막습니다.
+
+
+[!] 상당히 비직관적인 이 상황은 분리된 캐시를 가진 기계, 예를 들어 한 캐시
+뱅크가 짝수번 캐시 라인을 처리하고 다른 뱅크는 홀수번 캐시 라인을 처리하는 기계
+등에서 가장 잘 발생합니다. 포인터 P 는 홀수 번호의 캐시 라인에 있고, 변수 B 는
+짝수 번호 캐시 라인에 있다고 생각해 봅시다. 그런 상태에서 읽기 작업을 하는 CPU
+의 짝수번 뱅크는 할 일이 쌓여 매우 바쁘지만 홀수번 뱅크는 할 일이 없어 아무
+일도 하지 않고 있었다면, 포인터 P 는 새 값 (&B) 을, 그리고 변수 B 는 옛날 값
+(2) 을 가지고 있는 상태가 보여질 수도 있습니다.
+
+
+데이터 의존성 배리어는 매우 중요한데, 예를 들어 RCU 시스템에서 그렇습니다.
+include/linux/rcupdate.h 의 rcu_assign_pointer() 와 rcu_dereference() 를
+참고하세요. 여기서 데이터 의존성 배리어는 RCU 로 관리되는 포인터의 타겟을 현재
+타겟에서 수정된 새로운 타겟으로 바꾸는 작업에서 새로 수정된 타겟이 초기화가
+완료되지 않은 채로 보여지는 일이 일어나지 않게 해줍니다.
+
+더 많은 예를 위해선 "캐시 일관성" 서브섹션을 참고하세요.
+
+
+컨트롤 의존성
+-------------
+
+로드-로드 컨트롤 의존성은 데이터 의존성 배리어만으로는 정확히 동작할 수가
+없어서 읽기 메모리 배리어를 필요로 합니다. 아래의 코드를 봅시다:
+
+ q = READ_ONCE(a);
+ if (q) {
+ <데이터 의존성 배리어> /* BUG: No data dependency!!! */
+ p = READ_ONCE(b);
+ }
+
+이 코드는 원하는 대로의 효과를 내지 못할 수 있는데, 이 코드에는 데이터 의존성이
+아니라 컨트롤 의존성이 존재하기 때문으로, 이런 상황에서 CPU 는 실행 속도를 더
+빠르게 하기 위해 분기 조건의 결과를 예측하고 코드를 재배치 할 수 있어서 다른
+CPU 는 b 로부터의 로드 오퍼레이션이 a 로부터의 로드 오퍼레이션보다 먼저 발생한
+걸로 인식할 수 있습니다. 여기에 정말로 필요했던 건 다음과 같습니다:
+
+ q = READ_ONCE(a);
+ if (q) {
+ <읽기 배리어>
+ p = READ_ONCE(b);
+ }
+
+하지만, 스토어 오퍼레이션은 예측적으로 수행되지 않습니다. 즉, 다음 예에서와
+같이 로드-스토어 컨트롤 의존성이 존재하는 경우에는 순서가 -지켜진다-는
+의미입니다.
+
+ q = READ_ONCE(a);
+ if (q) {
+ WRITE_ONCE(b, p);
+ }
+
+컨트롤 의존성은 보통 다른 타입의 배리어들과 짝을 맞춰 사용됩니다. 그렇다곤
+하나, READ_ONCE() 는 반드시 사용해야 함을 부디 명심하세요! READ_ONCE() 가
+없다면, 컴파일러가 'a' 로부터의 로드를 'a' 로부터의 또다른 로드와, 'b' 로의
+스토어를 'b' 로의 또다른 스토어와 조합해 버려 매우 비직관적인 결과를 초래할 수
+있습니다.
+
+이걸로 끝이 아닌게, 컴파일러가 변수 'a' 의 값이 항상 0이 아니라고 증명할 수
+있다면, 앞의 예에서 "if" 문을 없애서 다음과 같이 최적화 할 수도 있습니다:
+
+ q = a;
+ b = p; /* BUG: Compiler and CPU can both reorder!!! */
+
+그러니 READ_ONCE() 를 반드시 사용하세요.
+
+다음과 같이 "if" 문의 양갈래 브랜치에 모두 존재하는 동일한 스토어에 대해 순서를
+강제하고 싶은 경우가 있을 수 있습니다:
+
+ q = READ_ONCE(a);
+ if (q) {
+ barrier();
+ WRITE_ONCE(b, p);
+ do_something();
+ } else {
+ barrier();
+ WRITE_ONCE(b, p);
+ do_something_else();
+ }
+
+안타깝게도, 현재의 컴파일러들은 높은 최적화 레벨에서는 이걸 다음과 같이
+바꿔버립니다:
+
+ q = READ_ONCE(a);
+ barrier();
+ WRITE_ONCE(b, p); /* BUG: No ordering vs. load from a!!! */
+ if (q) {
+ /* WRITE_ONCE(b, p); -- moved up, BUG!!! */
+ do_something();
+ } else {
+ /* WRITE_ONCE(b, p); -- moved up, BUG!!! */
+ do_something_else();
+ }
+
+이제 'a' 에서의 로드와 'b' 로의 스토어 사이에는 조건적 관계가 없기 때문에 CPU
+는 이들의 순서를 바꿀 수 있게 됩니다: 이런 경우에 조건적 관계는 반드시
+필요한데, 모든 컴파일러 최적화가 이루어지고 난 후의 어셈블리 코드에서도
+마찬가지입니다. 따라서, 이 예에서 순서를 지키기 위해서는 smp_store_release()
+와 같은 명시적 메모리 배리어가 필요합니다:
+
+ q = READ_ONCE(a);
+ if (q) {
+ smp_store_release(&b, p);
+ do_something();
+ } else {
+ smp_store_release(&b, p);
+ do_something_else();
+ }
+
+반면에 명시적 메모리 배리어가 없다면, 이런 경우의 순서는 스토어 오퍼레이션들이
+서로 다를 때에만 보장되는데, 예를 들면 다음과 같은 경우입니다:
+
+ q = READ_ONCE(a);
+ if (q) {
+ WRITE_ONCE(b, p);
+ do_something();
+ } else {
+ WRITE_ONCE(b, r);
+ do_something_else();
+ }
+
+처음의 READ_ONCE() 는 컴파일러가 'a' 의 값을 증명해내는 것을 막기 위해 여전히
+필요합니다.
+
+또한, 로컬 변수 'q' 를 가지고 하는 일에 대해 주의해야 하는데, 그러지 않으면
+컴파일러는 그 값을 추측하고 또다시 필요한 조건관계를 없애버릴 수 있습니다.
+예를 들면:
+
+ q = READ_ONCE(a);
+ if (q % MAX) {
+ WRITE_ONCE(b, p);
+ do_something();
+ } else {
+ WRITE_ONCE(b, r);
+ do_something_else();
+ }
+
+만약 MAX 가 1 로 정의된 상수라면, 컴파일러는 (q % MAX) 는 0이란 것을 알아채고,
+위의 코드를 아래와 같이 바꿔버릴 수 있습니다:
+
+ q = READ_ONCE(a);
+ WRITE_ONCE(b, p);
+ do_something_else();
+
+이렇게 되면, CPU 는 변수 'a' 로부터의 로드와 변수 'b' 로의 스토어 사이의 순서를
+지켜줄 필요가 없어집니다. barrier() 를 추가해 해결해 보고 싶겠지만, 그건
+도움이 안됩니다. 조건 관계는 사라졌고, barrier() 는 이를 되돌리지 못합니다.
+따라서, 이 순서를 지켜야 한다면, MAX 가 1 보다 크다는 것을, 다음과 같은 방법을
+사용해 분명히 해야 합니다:
+
+ q = READ_ONCE(a);
+ BUILD_BUG_ON(MAX <= 1); /* Order load from a with store to b. */
+ if (q % MAX) {
+ WRITE_ONCE(b, p);
+ do_something();
+ } else {
+ WRITE_ONCE(b, r);
+ do_something_else();
+ }
+
+'b' 로의 스토어들은 여전히 서로 다름을 알아두세요. 만약 그것들이 동일하면,
+앞에서 이야기했듯, 컴파일러가 그 스토어 오퍼레이션들을 'if' 문 바깥으로
+끄집어낼 수 있습니다.
+
+또한 이진 조건문 평가에 너무 의존하지 않도록 조심해야 합니다. 다음의 예를
+봅시다:
+
+ q = READ_ONCE(a);
+ if (q || 1 > 0)
+ WRITE_ONCE(b, 1);
+
+첫번째 조건만으로는 브랜치 조건 전체를 거짓으로 만들 수 없고 두번째 조건은 항상
+참이기 때문에, 컴파일러는 이 예를 다음과 같이 바꿔서 컨트롤 의존성을 없애버릴
+수 있습니다:
+
+ q = READ_ONCE(a);
+ WRITE_ONCE(b, 1);
+
+이 예는 컴파일러가 코드를 추측으로 수정할 수 없도록 분명히 해야 한다는 점을
+강조합니다. 조금 더 일반적으로 말해서, READ_ONCE() 는 컴파일러에게 주어진 로드
+오퍼레이션을 위한 코드를 정말로 만들도록 하지만, 컴파일러가 그렇게 만들어진
+코드의 수행 결과를 사용하도록 강제하지는 않습니다.
+
+마지막으로, 컨트롤 의존성은 이행성 (transitivity) 을 제공하지 -않습니다-. 이건
+x 와 y 가 둘 다 0 이라는 초기값을 가졌다는 가정 하의 두개의 예제로
+보이겠습니다:
+
+ CPU 0 CPU 1
+ ======================= =======================
+ r1 = READ_ONCE(x); r2 = READ_ONCE(y);
+ if (r1 > 0) if (r2 > 0)
+ WRITE_ONCE(y, 1); WRITE_ONCE(x, 1);
+
+ assert(!(r1 == 1 && r2 == 1));
+
+이 두 CPU 예제에서 assert() 의 조건은 항상 참일 것입니다. 그리고, 만약 컨트롤
+의존성이 이행성을 (실제로는 그러지 않지만) 보장한다면, 다음의 CPU 가 추가되어도
+아래의 assert() 조건은 참이 될것입니다:
+
+ CPU 2
+ =====================
+ WRITE_ONCE(x, 2);
+
+ assert(!(r1 == 2 && r2 == 1 && x == 2)); /* FAILS!!! */
+
+하지만 컨트롤 의존성은 이행성을 제공하지 -않기- 때문에, 세개의 CPU 예제가 실행
+완료된 후에 위의 assert() 의 조건은 거짓으로 평가될 수 있습니다. 세개의 CPU
+예제가 순서를 지키길 원한다면, CPU 0 와 CPU 1 코드의 로드와 스토어 사이, "if"
+문 바로 다음에 smp_mb()를 넣어야 합니다. 더 나아가서, 최초의 두 CPU 예제는
+매우 위험하므로 사용되지 않아야 합니다.
+
+이 두개의 예제는 다음 논문:
+http://www.cl.cam.ac.uk/users/pes20/ppc-supplemental/test6.pdf 와
+이 사이트: https://www.cl.cam.ac.uk/~pes20/ppcmem/index.html 에 나온 LB 와 WWC
+리트머스 테스트입니다.
+
+요약하자면:
+
+ (*) 컨트롤 의존성은 앞의 로드들을 뒤의 스토어들에 대해 순서를 맞춰줍니다.
+ 하지만, 그 외의 어떤 순서도 보장하지 -않습니다-: 앞의 로드와 뒤의 로드들
+ 사이에도, 앞의 스토어와 뒤의 스토어들 사이에도요. 이런 다른 형태의
+ 순서가 필요하다면 smp_rmb() 나 smp_wmb()를, 또는, 앞의 스토어들과 뒤의
+ 로드들 사이의 순서를 위해서는 smp_mb() 를 사용하세요.
+
+ (*) "if" 문의 양갈래 브랜치가 같은 변수에의 동일한 스토어로 시작한다면, 그
+ 스토어들은 각 스토어 앞에 smp_mb() 를 넣거나 smp_store_release() 를
+ 사용해서 스토어를 하는 식으로 순서를 맞춰줘야 합니다. 이 문제를 해결하기
+ 위해 "if" 문의 양갈래 브랜치의 시작 지점에 barrier() 를 넣는 것만으로는
+ 충분한 해결이 되지 않는데, 이는 앞의 예에서 본것과 같이, 컴파일러의
+ 최적화는 barrier() 가 의미하는 바를 지키면서도 컨트롤 의존성을 손상시킬
+ 수 있기 때문이라는 점을 부디 알아두시기 바랍니다.
+
+ (*) 컨트롤 의존성은 앞의 로드와 뒤의 스토어 사이에 최소 하나의, 실행
+ 시점에서의 조건관계를 필요로 하며, 이 조건관계는 앞의 로드와 관계되어야
+ 합니다. 만약 컴파일러가 조건 관계를 최적화로 없앨수 있다면, 순서도
+ 최적화로 없애버렸을 겁니다. READ_ONCE() 와 WRITE_ONCE() 의 주의 깊은
+ 사용은 주어진 조건 관계를 유지하는데 도움이 될 수 있습니다.
+
+ (*) 컨트롤 의존성을 위해선 컴파일러가 조건관계를 없애버리는 것을 막아야
+ 합니다. 주의 깊은 READ_ONCE() 나 atomic{,64}_read() 의 사용이 컨트롤
+ 의존성이 사라지지 않게 하는데 도움을 줄 수 있습니다. 더 많은 정보를
+ 위해선 "컴파일러 배리어" 섹션을 참고하시기 바랍니다.
+
+ (*) 컨트롤 의존성은 보통 다른 타입의 배리어들과 짝을 맞춰 사용됩니다.
+
+ (*) 컨트롤 의존성은 이행성을 제공하지 -않습니다-. 이행성이 필요하다면,
+ smp_mb() 를 사용하세요.
+
+
+SMP 배리어 짝맞추기
+--------------------
+
+CPU 간 상호작용을 다룰 때에 일부 타입의 메모리 배리어는 항상 짝을 맞춰
+사용되어야 합니다. 적절하게 짝을 맞추지 않은 코드는 사실상 에러에 가깝습니다.
+
+범용 배리어들은 범용 배리어끼리도 짝을 맞추지만 이행성이 없는 대부분의 다른
+타입의 배리어들과도 짝을 맞춥니다. ACQUIRE 배리어는 RELEASE 배리어와 짝을
+맞춥니다만, 둘 다 범용 배리어를 포함해 다른 배리어들과도 짝을 맞출 수 있습니다.
+쓰기 배리어는 데이터 의존성 배리어나 컨트롤 의존성, ACQUIRE 배리어, RELEASE
+배리어, 읽기 배리어, 또는 범용 배리어와 짝을 맞춥니다. 비슷하게 읽기 배리어나
+컨트롤 의존성, 또는 데이터 의존성 배리어는 쓰기 배리어나 ACQUIRE 배리어,
+RELEASE 배리어, 또는 범용 배리어와 짝을 맞추는데, 다음과 같습니다:
+
+ CPU 1 CPU 2
+ =============== ===============
+ WRITE_ONCE(a, 1);
+ <쓰기 배리어>
+ WRITE_ONCE(b, 2); x = READ_ONCE(b);
+ <읽기 배리어>
+ y = READ_ONCE(a);
+
+또는:
+
+ CPU 1 CPU 2
+ =============== ===============================
+ a = 1;
+ <쓰기 배리어>
+ WRITE_ONCE(b, &a); x = READ_ONCE(b);
+ <데이터 의존성 배리어>
+ y = *x;
+
+또는:
+
+ CPU 1 CPU 2
+ =============== ===============================
+ r1 = READ_ONCE(y);
+ <범용 배리어>
+ WRITE_ONCE(y, 1); if (r2 = READ_ONCE(x)) {
+ <묵시적 컨트롤 의존성>
+ WRITE_ONCE(y, 1);
+ }
+
+ assert(r1 == 0 || r2 == 0);
+
+기본적으로, 여기서의 읽기 배리어는 "더 완화된" 타입일 순 있어도 항상 존재해야
+합니다.
+
+[!] 쓰기 배리어 앞의 스토어 오퍼레이션은 일반적으로 읽기 배리어나 데이터
+의존성 배리어 뒤의 로드 오퍼레이션과 매치될 것이고, 반대도 마찬가지입니다:
+
+ CPU 1 CPU 2
+ =================== ===================
+ WRITE_ONCE(a, 1); }---- --->{ v = READ_ONCE(c);
+ WRITE_ONCE(b, 2); } \ / { w = READ_ONCE(d);
+ <쓰기 배리어> \ <읽기 배리어>
+ WRITE_ONCE(c, 3); } / \ { x = READ_ONCE(a);
+ WRITE_ONCE(d, 4); }---- --->{ y = READ_ONCE(b);
+
+
+메모리 배리어 시퀀스의 예
+-------------------------
+
+첫째, 쓰기 배리어는 스토어 오퍼레이션들의 부분적 순서 세우기로 동작합니다.
+아래의 이벤트 시퀀스를 보세요:
+
+ CPU 1
+ =======================
+ STORE A = 1
+ STORE B = 2
+ STORE C = 3
+ <쓰기 배리어>
+ STORE D = 4
+ STORE E = 5
+
+이 이벤트 시퀀스는 메모리 일관성 시스템에 원소끼리의 순서가 존재하지 않는 집합
+{ STORE A, STORE B, STORE C } 가 역시 원소끼리의 순서가 존재하지 않는 집합
+{ STORE D, STORE E } 보다 먼저 일어난 것으로 시스템의 나머지 요소들에 보이도록
+전달됩니다:
+
+ +-------+ : :
+ | | +------+
+ | |------>| C=3 | } /\
+ | | : +------+ }----- \ -----> 시스템의 나머지 요소에
+ | | : | A=1 | } \/ 보여질 수 있는 이벤트들
+ | | : +------+ }
+ | CPU 1 | : | B=2 | }
+ | | +------+ }
+ | | wwwwwwwwwwwwwwww } <--- 여기서 쓰기 배리어는 배리어 앞의
+ | | +------+ } 모든 스토어가 배리어 뒤의 스토어
+ | | : | E=5 | } 전에 메모리 시스템에 전달되도록
+ | | : +------+ } 합니다
+ | |------>| D=4 | }
+ | | +------+
+ +-------+ : :
+ |
+ | CPU 1 에 의해 메모리 시스템에 전달되는
+ | 일련의 스토어 오퍼레이션들
+ V
+
+
+둘째, 데이터 의존성 배리어는 데이터 의존적 로드 오퍼레이션들의 부분적 순서
+세우기로 동작합니다. 다음 일련의 이벤트들을 보세요:
+
+ CPU 1 CPU 2
+ ======================= =======================
+ { B = 7; X = 9; Y = 8; C = &Y }
+ STORE A = 1
+ STORE B = 2
+ <쓰기 배리어>
+ STORE C = &B LOAD X
+ STORE D = 4 LOAD C (gets &B)
+ LOAD *C (reads B)
+
+여기에 별다른 개입이 없다면, CPU 1 의 쓰기 배리어에도 불구하고 CPU 2 는 CPU 1
+의 이벤트들을 완전히 무작위적 순서로 인지하게 됩니다:
+
+ +-------+ : : : :
+ | | +------+ +-------+ | CPU 2 에 인지되는
+ | |------>| B=2 |----- --->| Y->8 | | 업데이트 이벤트
+ | | : +------+ \ +-------+ | 시퀀스
+ | CPU 1 | : | A=1 | \ --->| C->&Y | V
+ | | +------+ | +-------+
+ | | wwwwwwwwwwwwwwww | : :
+ | | +------+ | : :
+ | | : | C=&B |--- | : : +-------+
+ | | : +------+ \ | +-------+ | |
+ | |------>| D=4 | ----------->| C->&B |------>| |
+ | | +------+ | +-------+ | |
+ +-------+ : : | : : | |
+ | : : | |
+ | : : | CPU 2 |
+ | +-------+ | |
+ 분명히 잘못된 ---> | | B->7 |------>| |
+ B 의 값 인지 (!) | +-------+ | |
+ | : : | |
+ | +-------+ | |
+ X 의 로드가 B 의 ---> \ | X->9 |------>| |
+ 일관성 유지를 \ +-------+ | |
+ 지연시킴 ----->| B->2 | +-------+
+ +-------+
+ : :
+
+
+앞의 예에서, CPU 2 는 (B 의 값이 될) *C 의 값 읽기가 C 의 LOAD 뒤에 이어짐에도
+B 가 7 이라는 결과를 얻습니다.
+
+하지만, 만약 데이터 의존성 배리어가 C 의 로드와 *C (즉, B) 의 로드 사이에
+있었다면:
+
+ CPU 1 CPU 2
+ ======================= =======================
+ { B = 7; X = 9; Y = 8; C = &Y }
+ STORE A = 1
+ STORE B = 2
+ <쓰기 배리어>
+ STORE C = &B LOAD X
+ STORE D = 4 LOAD C (gets &B)
+ <데이터 의존성 배리어>
+ LOAD *C (reads B)
+
+다음과 같이 됩니다:
+
+ +-------+ : : : :
+ | | +------+ +-------+
+ | |------>| B=2 |----- --->| Y->8 |
+ | | : +------+ \ +-------+
+ | CPU 1 | : | A=1 | \ --->| C->&Y |
+ | | +------+ | +-------+
+ | | wwwwwwwwwwwwwwww | : :
+ | | +------+ | : :
+ | | : | C=&B |--- | : : +-------+
+ | | : +------+ \ | +-------+ | |
+ | |------>| D=4 | ----------->| C->&B |------>| |
+ | | +------+ | +-------+ | |
+ +-------+ : : | : : | |
+ | : : | |
+ | : : | CPU 2 |
+ | +-------+ | |
+ | | X->9 |------>| |
+ | +-------+ | |
+ C 로의 스토어 앞의 ---> \ ddddddddddddddddd | |
+ 모든 이벤트 결과가 \ +-------+ | |
+ 뒤의 로드에게 ----->| B->2 |------>| |
+ 보이게 강제한다 +-------+ | |
+ : : +-------+
+
+
+셋째, 읽기 배리어는 로드 오퍼레이션들에의 부분적 순서 세우기로 동작합니다.
+아래의 일련의 이벤트를 봅시다:
+
+ CPU 1 CPU 2
+ ======================= =======================
+ { A = 0, B = 9 }
+ STORE A=1
+ <쓰기 배리어>
+ STORE B=2
+ LOAD B
+ LOAD A
+
+CPU 1 은 쓰기 배리어를 쳤지만, 별다른 개입이 없다면 CPU 2 는 CPU 1 에서 행해진
+이벤트의 결과를 무작위적 순서로 인지하게 됩니다.
+
+ +-------+ : : : :
+ | | +------+ +-------+
+ | |------>| A=1 |------ --->| A->0 |
+ | | +------+ \ +-------+
+ | CPU 1 | wwwwwwwwwwwwwwww \ --->| B->9 |
+ | | +------+ | +-------+
+ | |------>| B=2 |--- | : :
+ | | +------+ \ | : : +-------+
+ +-------+ : : \ | +-------+ | |
+ ---------->| B->2 |------>| |
+ | +-------+ | CPU 2 |
+ | | A->0 |------>| |
+ | +-------+ | |
+ | : : +-------+
+ \ : :
+ \ +-------+
+ ---->| A->1 |
+ +-------+
+ : :
+
+
+하지만, 만약 읽기 배리어가 B 의 로드와 A 의 로드 사이에 존재한다면:
+
+ CPU 1 CPU 2
+ ======================= =======================
+ { A = 0, B = 9 }
+ STORE A=1
+ <쓰기 배리어>
+ STORE B=2
+ LOAD B
+ <읽기 배리어>
+ LOAD A
+
+CPU 1 에 의해 만들어진 부분적 순서가 CPU 2 에도 그대로 인지됩니다:
+
+ +-------+ : : : :
+ | | +------+ +-------+
+ | |------>| A=1 |------ --->| A->0 |
+ | | +------+ \ +-------+
+ | CPU 1 | wwwwwwwwwwwwwwww \ --->| B->9 |
+ | | +------+ | +-------+
+ | |------>| B=2 |--- | : :
+ | | +------+ \ | : : +-------+
+ +-------+ : : \ | +-------+ | |
+ ---------->| B->2 |------>| |
+ | +-------+ | CPU 2 |
+ | : : | |
+ | : : | |
+ 여기서 읽기 배리어는 ----> \ rrrrrrrrrrrrrrrrr | |
+ B 로의 스토어 전의 \ +-------+ | |
+ 모든 결과를 CPU 2 에 ---->| A->1 |------>| |
+ 보이도록 한다 +-------+ | |
+ : : +-------+
+
+
+더 완벽한 설명을 위해, A 의 로드가 읽기 배리어 앞과 뒤에 있으면 어떻게 될지
+생각해 봅시다:
+
+ CPU 1 CPU 2
+ ======================= =======================
+ { A = 0, B = 9 }
+ STORE A=1
+ <쓰기 배리어>
+ STORE B=2
+ LOAD B
+ LOAD A [first load of A]
+ <읽기 배리어>
+ LOAD A [second load of A]
+
+A 의 로드 두개가 모두 B 의 로드 뒤에 있지만, 서로 다른 값을 얻어올 수
+있습니다:
+
+ +-------+ : : : :
+ | | +------+ +-------+
+ | |------>| A=1 |------ --->| A->0 |
+ | | +------+ \ +-------+
+ | CPU 1 | wwwwwwwwwwwwwwww \ --->| B->9 |
+ | | +------+ | +-------+
+ | |------>| B=2 |--- | : :
+ | | +------+ \ | : : +-------+
+ +-------+ : : \ | +-------+ | |
+ ---------->| B->2 |------>| |
+ | +-------+ | CPU 2 |
+ | : : | |
+ | : : | |
+ | +-------+ | |
+ | | A->0 |------>| 1st |
+ | +-------+ | |
+ 여기서 읽기 배리어는 ----> \ rrrrrrrrrrrrrrrrr | |
+ B 로의 스토어 전의 \ +-------+ | |
+ 모든 결과를 CPU 2 에 ---->| A->1 |------>| 2nd |
+ 보이도록 한다 +-------+ | |
+ : : +-------+
+
+
+하지만 CPU 1 에서의 A 업데이트는 읽기 배리어가 완료되기 전에도 보일 수도
+있긴 합니다:
+
+ +-------+ : : : :
+ | | +------+ +-------+
+ | |------>| A=1 |------ --->| A->0 |
+ | | +------+ \ +-------+
+ | CPU 1 | wwwwwwwwwwwwwwww \ --->| B->9 |
+ | | +------+ | +-------+
+ | |------>| B=2 |--- | : :
+ | | +------+ \ | : : +-------+
+ +-------+ : : \ | +-------+ | |
+ ---------->| B->2 |------>| |
+ | +-------+ | CPU 2 |
+ | : : | |
+ \ : : | |
+ \ +-------+ | |
+ ---->| A->1 |------>| 1st |
+ +-------+ | |
+ rrrrrrrrrrrrrrrrr | |
+ +-------+ | |
+ | A->1 |------>| 2nd |
+ +-------+ | |
+ : : +-------+
+
+
+여기서 보장되는 건, 만약 B 의 로드가 B == 2 라는 결과를 봤다면, A 에의 두번째
+로드는 항상 A == 1 을 보게 될 것이라는 겁니다. A 에의 첫번째 로드에는 그런
+보장이 없습니다; A == 0 이거나 A == 1 이거나 둘 중 하나의 결과를 보게 될겁니다.
+
+
+읽기 메모리 배리어 VS 로드 예측
+-------------------------------
+
+많은 CPU들이 로드를 예측적으로 (speculatively) 합니다: 어떤 데이터를 메모리에서
+로드해야 하게 될지 예측을 했다면, 해당 데이터를 로드하는 인스트럭션을 실제로는
+아직 만나지 않았더라도 다른 로드 작업이 없어 버스 (bus) 가 아무 일도 하고 있지
+않다면, 그 데이터를 로드합니다. 이후에 실제 로드 인스트럭션이 실행되면 CPU 가
+이미 그 값을 가지고 있기 때문에 그 로드 인스트럭션은 즉시 완료됩니다.
+
+해당 CPU 는 실제로는 그 값이 필요치 않았다는 사실이 나중에 드러날 수도 있는데 -
+해당 로드 인스트럭션이 브랜치로 우회되거나 했을 수 있겠죠 - , 그렇게 되면 앞서
+읽어둔 값을 버리거나 나중의 사용을 위해 캐시에 넣어둘 수 있습니다.
+
+다음을 생각해 봅시다:
+
+ CPU 1 CPU 2
+ ======================= =======================
+ LOAD B
+ DIVIDE } 나누기 명령은 일반적으로
+ DIVIDE } 긴 시간을 필요로 합니다
+ LOAD A
+
+는 이렇게 될 수 있습니다:
+
+ : : +-------+
+ +-------+ | |
+ --->| B->2 |------>| |
+ +-------+ | CPU 2 |
+ : :DIVIDE | |
+ +-------+ | |
+ 나누기 하느라 바쁜 ---> --->| A->0 |~~~~ | |
+ CPU 는 A 의 LOAD 를 +-------+ ~ | |
+ 예측해서 수행한다 : : ~ | |
+ : :DIVIDE | |
+ : : ~ | |
+ 나누기가 끝나면 ---> ---> : : ~-->| |
+ CPU 는 해당 LOAD 를 : : | |
+ 즉각 완료한다 : : +-------+
+
+
+읽기 배리어나 데이터 의존성 배리어를 두번째 로드 직전에 놓는다면:
+
+ CPU 1 CPU 2
+ ======================= =======================
+ LOAD B
+ DIVIDE
+ DIVIDE
+ <읽기 배리어>
+ LOAD A
+
+예측으로 얻어진 값은 사용된 배리어의 타입에 따라서 해당 값이 옳은지 검토되게
+됩니다. 만약 해당 메모리 영역에 변화가 없었다면, 예측으로 얻어두었던 값이
+사용됩니다:
+
+ : : +-------+
+ +-------+ | |
+ --->| B->2 |------>| |
+ +-------+ | CPU 2 |
+ : :DIVIDE | |
+ +-------+ | |
+ 나누기 하느라 바쁜 ---> --->| A->0 |~~~~ | |
+ CPU 는 A 의 LOAD 를 +-------+ ~ | |
+ 예측한다 : : ~ | |
+ : :DIVIDE | |
+ : : ~ | |
+ : : ~ | |
+ rrrrrrrrrrrrrrrr~ | |
+ : : ~ | |
+ : : ~-->| |
+ : : | |
+ : : +-------+
+
+
+하지만 다른 CPU 에서 업데이트나 무효화가 있었다면, 그 예측은 무효화되고 그 값은
+다시 읽혀집니다:
+
+ : : +-------+
+ +-------+ | |
+ --->| B->2 |------>| |
+ +-------+ | CPU 2 |
+ : :DIVIDE | |
+ +-------+ | |
+ 나누기 하느라 바쁜 ---> --->| A->0 |~~~~ | |
+ CPU 는 A 의 LOAD 를 +-------+ ~ | |
+ 예측한다 : : ~ | |
+ : :DIVIDE | |
+ : : ~ | |
+ : : ~ | |
+ rrrrrrrrrrrrrrrrr | |
+ +-------+ | |
+ 예측성 동작은 무효화 되고 ---> --->| A->1 |------>| |
+ 업데이트된 값이 다시 읽혀진다 +-------+ | |
+ : : +-------+
+
+
+이행성
+------
+
+이행성(transitivity)은 실제의 컴퓨터 시스템에서 항상 제공되지는 않는, 순서
+맞추기에 대한 상당히 직관적인 개념입니다. 다음의 예가 이행성을 보여줍니다:
+
+ CPU 1 CPU 2 CPU 3
+ ======================= ======================= =======================
+ { X = 0, Y = 0 }
+ STORE X=1 LOAD X STORE Y=1
+ <범용 배리어> <범용 배리어>
+ LOAD Y LOAD X
+
+CPU 2 의 X 로드가 1을 리턴했고 Y 로드가 0을 리턴했다고 해봅시다. 이는 CPU 2 의
+X 로드가 CPU 1 의 X 스토어 뒤에 이루어졌고 CPU 2 의 Y 로드는 CPU 3 의 Y 스토어
+전에 이루어졌음을 의미합니다. 그럼 "CPU 3 의 X 로드는 0을 리턴할 수 있나요?"
+
+CPU 2 의 X 로드는 CPU 1 의 스토어 후에 이루어졌으니, CPU 3 의 X 로드는 1을
+리턴하는게 자연스럽습니다. 이런 생각이 이행성의 한 예입니다: CPU A 에서 실행된
+로드가 CPU B 에서의 같은 변수에 대한 로드를 뒤따른다면, CPU A 의 로드는 CPU B
+의 로드가 내놓은 값과 같거나 그 후의 값을 내놓아야 합니다.
+
+리눅스 커널에서 범용 배리어의 사용은 이행성을 보장합니다. 따라서, 앞의 예에서
+CPU 2 의 X 로드가 1을, Y 로드는 0을 리턴했다면, CPU 3 의 X 로드는 반드시 1을
+리턴합니다.
+
+하지만, 읽기나 쓰기 배리어에 대해서는 이행성이 보장되지 -않습니다-. 예를 들어,
+앞의 예에서 CPU 2 의 범용 배리어가 아래처럼 읽기 배리어로 바뀐 경우를 생각해
+봅시다:
+
+ CPU 1 CPU 2 CPU 3
+ ======================= ======================= =======================
+ { X = 0, Y = 0 }
+ STORE X=1 LOAD X STORE Y=1
+ <읽기 배리어> <범용 배리어>
+ LOAD Y LOAD X
+
+이 코드는 이행성을 갖지 않습니다: 이 예에서는, CPU 2 의 X 로드가 1을
+리턴하고, Y 로드는 0을 리턴하지만 CPU 3 의 X 로드가 0을 리턴하는 것도 완전히
+합법적입니다.
+
+CPU 2 의 읽기 배리어가 자신의 읽기는 순서를 맞춰줘도, CPU 1 의 스토어와의
+순서를 맞춰준다고는 보장할 수 없다는게 핵심입니다. 따라서, CPU 1 과 CPU 2 가
+버퍼나 캐시를 공유하는 시스템에서 이 예제 코드가 실행된다면, CPU 2 는 CPU 1 이
+쓴 값에 좀 빨리 접근할 수 있을 것입니다. 따라서 CPU 1 과 CPU 2 의 접근으로
+조합된 순서를 모든 CPU 가 동의할 수 있도록 하기 위해 범용 배리어가 필요합니다.
+
+범용 배리어는 "글로벌 이행성"을 제공해서, 모든 CPU 들이 오퍼레이션들의 순서에
+동의하게 할 것입니다. 반면, release-acquire 조합은 "로컬 이행성" 만을
+제공해서, 해당 조합이 사용된 CPU 들만이 해당 액세스들의 조합된 순서에 동의함이
+보장됩니다. 예를 들어, 존경스런 Herman Hollerith 의 C 코드로 보면:
+
+ int u, v, x, y, z;
+
+ void cpu0(void)
+ {
+ r0 = smp_load_acquire(&x);
+ WRITE_ONCE(u, 1);
+ smp_store_release(&y, 1);
+ }
+
+ void cpu1(void)
+ {
+ r1 = smp_load_acquire(&y);
+ r4 = READ_ONCE(v);
+ r5 = READ_ONCE(u);
+ smp_store_release(&z, 1);
+ }
+
+ void cpu2(void)
+ {
+ r2 = smp_load_acquire(&z);
+ smp_store_release(&x, 1);
+ }
+
+ void cpu3(void)
+ {
+ WRITE_ONCE(v, 1);
+ smp_mb();
+ r3 = READ_ONCE(u);
+ }
+
+cpu0(), cpu1(), 그리고 cpu2() 는 smp_store_release()/smp_load_acquire() 쌍의
+연결을 통한 로컬 이행성에 동참하고 있으므로, 다음과 같은 결과는 나오지 않을
+겁니다:
+
+ r0 == 1 && r1 == 1 && r2 == 1
+
+더 나아가서, cpu0() 와 cpu1() 사이의 release-acquire 관계로 인해, cpu1() 은
+cpu0() 의 쓰기를 봐야만 하므로, 다음과 같은 결과도 없을 겁니다:
+
+ r1 == 1 && r5 == 0
+
+하지만, release-acquire 타동성은 동참한 CPU 들에만 적용되므로 cpu3() 에는
+적용되지 않습니다. 따라서, 다음과 같은 결과가 가능합니다:
+
+ r0 == 0 && r1 == 1 && r2 == 1 && r3 == 0 && r4 == 0
+
+비슷하게, 다음과 같은 결과도 가능합니다:
+
+ r0 == 0 && r1 == 1 && r2 == 1 && r3 == 0 && r4 == 0 && r5 == 1
+
+cpu0(), cpu1(), 그리고 cpu2() 는 그들의 읽기와 쓰기를 순서대로 보게 되지만,
+release-acquire 체인에 관여되지 않은 CPU 들은 그 순서에 이견을 가질 수
+있습니다. 이런 이견은 smp_load_acquire() 와 smp_store_release() 의 구현에
+사용되는 완화된 메모리 배리어 인스트럭션들은 항상 배리어 앞의 스토어들을 뒤의
+로드들에 앞세울 필요는 없다는 사실에서 기인합니다. 이 말은 cpu3() 는 cpu0() 의
+u 로의 스토어를 cpu1() 의 v 로부터의 로드 뒤에 일어난 것으로 볼 수 있다는
+뜻입니다, cpu0() 와 cpu1() 은 이 두 오퍼레이션이 의도된 순서대로 일어났음에
+모두 동의하는데도 말입니다.
+
+하지만, smp_load_acquire() 는 마술이 아님을 명심하시기 바랍니다. 구체적으로,
+이 함수는 단순히 순서 규칙을 지키며 인자로부터의 읽기를 수행합니다. 이것은
+어떤 특정한 값이 읽힐 것인지는 보장하지 -않습니다-. 따라서, 다음과 같은 결과도
+가능합니다:
+
+ r0 == 0 && r1 == 0 && r2 == 0 && r5 == 0
+
+이런 결과는 어떤 것도 재배치 되지 않는, 순차적 일관성을 가진 가상의
+시스템에서도 일어날 수 있음을 기억해 두시기 바랍니다.
+
+다시 말하지만, 당신의 코드가 글로벌 이행성을 필요로 한다면, 범용 배리어를
+사용하십시오.
+
+
+==================
+명시적 커널 배리어
+==================
+
+리눅스 커널은 서로 다른 단계에서 동작하는 다양한 배리어들을 가지고 있습니다:
+
+ (*) 컴파일러 배리어.
+
+ (*) CPU 메모리 배리어.
+
+ (*) MMIO 쓰기 배리어.
+
+
+컴파일러 배리어
+---------------
+
+리눅스 커널은 컴파일러가 메모리 액세스를 재배치 하는 것을 막아주는 명시적인
+컴파일러 배리어를 가지고 있습니다:
+
+ barrier();
+
+이건 범용 배리어입니다 -- barrier() 의 읽기-읽기 나 쓰기-쓰기 변종은 없습니다.
+하지만, READ_ONCE() 와 WRITE_ONCE() 는 특정 액세스들에 대해서만 동작하는
+barrier() 의 완화된 형태로 볼 수 있습니다.
+
+barrier() 함수는 다음과 같은 효과를 갖습니다:
+
+ (*) 컴파일러가 barrier() 뒤의 액세스들이 barrier() 앞의 액세스보다 앞으로
+ 재배치되지 못하게 합니다. 예를 들어, 인터럽트 핸들러 코드와 인터럽트 당한
+ 코드 사이의 통신을 신중히 하기 위해 사용될 수 있습니다.
+
+ (*) 루프에서, 컴파일러가 루프 조건에 사용된 변수를 매 이터레이션마다
+ 메모리에서 로드하지 않아도 되도록 최적화 하는걸 방지합니다.
+
+READ_ONCE() 와 WRITE_ONCE() 함수는 싱글 쓰레드 코드에서는 문제 없지만 동시성이
+있는 코드에서는 문제가 될 수 있는 모든 최적화를 막습니다. 이런 류의 최적화에
+대한 예를 몇가지 들어보면 다음과 같습니다:
+
+ (*) 컴파일러는 같은 변수에 대한 로드와 스토어를 재배치 할 수 있고, 어떤
+ 경우에는 CPU가 같은 변수로부터의 로드들을 재배치할 수도 있습니다. 이는
+ 다음의 코드가:
+
+ a[0] = x;
+ a[1] = x;
+
+ x 의 예전 값이 a[1] 에, 새 값이 a[0] 에 있게 할 수 있다는 뜻입니다.
+ 컴파일러와 CPU가 이런 일을 못하게 하려면 다음과 같이 해야 합니다:
+
+ a[0] = READ_ONCE(x);
+ a[1] = READ_ONCE(x);
+
+ 즉, READ_ONCE() 와 WRITE_ONCE() 는 여러 CPU 에서 하나의 변수에 가해지는
+ 액세스들에 캐시 일관성을 제공합니다.
+
+ (*) 컴파일러는 같은 변수에 대한 연속적인 로드들을 병합할 수 있습니다. 그런
+ 병합 작업으로 컴파일러는 다음의 코드를:
+
+ while (tmp = a)
+ do_something_with(tmp);
+
+ 다음과 같이, 싱글 쓰레드 코드에서는 말이 되지만 개발자의 의도와 전혀 맞지
+ 않는 방향으로 "최적화" 할 수 있습니다:
+
+ if (tmp = a)
+ for (;;)
+ do_something_with(tmp);
+
+ 컴파일러가 이런 짓을 하지 못하게 하려면 READ_ONCE() 를 사용하세요:
+
+ while (tmp = READ_ONCE(a))
+ do_something_with(tmp);
+
+ (*) 예컨대 레지스터 사용량이 많아 컴파일러가 모든 데이터를 레지스터에 담을 수
+ 없는 경우, 컴파일러는 변수를 다시 로드할 수 있습니다. 따라서 컴파일러는
+ 앞의 예에서 변수 'tmp' 사용을 최적화로 없애버릴 수 있습니다:
+
+ while (tmp = a)
+ do_something_with(tmp);
+
+ 이 코드는 다음과 같이 싱글 쓰레드에서는 완벽하지만 동시성이 존재하는
+ 경우엔 치명적인 코드로 바뀔 수 있습니다:
+
+ while (a)
+ do_something_with(a);
+
+ 예를 들어, 최적화된 이 코드는 변수 a 가 다른 CPU 에 의해 "while" 문과
+ do_something_with() 호출 사이에 바뀌어 do_something_with() 에 0을 넘길
+ 수도 있습니다.
+
+ 이번에도, 컴파일러가 그런 짓을 하는걸 막기 위해 READ_ONCE() 를 사용하세요:
+
+ while (tmp = READ_ONCE(a))
+ do_something_with(tmp);
+
+ 레지스터가 부족한 상황을 겪는 경우, 컴파일러는 tmp 를 스택에 저장해둘 수도
+ 있습니다. 컴파일러가 변수를 다시 읽어들이는건 이렇게 저장해두고 후에 다시
+ 읽어들이는데 드는 오버헤드 때문입니다. 그렇게 하는게 싱글 쓰레드
+ 코드에서는 안전하므로, 안전하지 않은 경우에는 컴파일러에게 직접 알려줘야
+ 합니다.
+
+ (*) 컴파일러는 그 값이 무엇일지 알고 있다면 로드를 아예 안할 수도 있습니다.
+ 예를 들어, 다음의 코드는 변수 'a' 의 값이 항상 0임을 증명할 수 있다면:
+
+ while (tmp = a)
+ do_something_with(tmp);
+
+ 이렇게 최적화 되어버릴 수 있습니다:
+
+ do { } while (0);
+
+ 이 변환은 싱글 쓰레드 코드에서는 도움이 되는데 로드와 브랜치를 제거했기
+ 때문입니다. 문제는 컴파일러가 'a' 의 값을 업데이트 하는건 현재의 CPU 하나
+ 뿐이라는 가정 위에서 증명을 했다는데 있습니다. 만약 변수 'a' 가 공유되어
+ 있다면, 컴파일러의 증명은 틀린 것이 될겁니다. 컴파일러는 그 자신이
+ 생각하는 것만큼 많은 것을 알고 있지 못함을 컴파일러에게 알리기 위해
+ READ_ONCE() 를 사용하세요:
+
+ while (tmp = READ_ONCE(a))
+ do_something_with(tmp);
+
+ 하지만 컴파일러는 READ_ONCE() 뒤에 나오는 값에 대해서도 눈길을 두고 있음을
+ 기억하세요. 예를 들어, 다음의 코드에서 MAX 는 전처리기 매크로로, 1의 값을
+ 갖는다고 해봅시다:
+
+ while ((tmp = READ_ONCE(a)) % MAX)
+ do_something_with(tmp);
+
+ 이렇게 되면 컴파일러는 MAX 를 가지고 수행되는 "%" 오퍼레이터의 결과가 항상
+ 0이라는 것을 알게 되고, 컴파일러가 코드를 실질적으로는 존재하지 않는
+ 것처럼 최적화 하는 것이 허용되어 버립니다. ('a' 변수의 로드는 여전히
+ 행해질 겁니다.)
+
+ (*) 비슷하게, 컴파일러는 변수가 저장하려 하는 값을 이미 가지고 있다는 것을
+ 알면 스토어 자체를 제거할 수 있습니다. 이번에도, 컴파일러는 현재의 CPU
+ 만이 그 변수에 값을 쓰는 오로지 하나의 존재라고 생각하여 공유된 변수에
+ 대해서는 잘못된 일을 하게 됩니다. 예를 들어, 다음과 같은 경우가 있을 수
+ 있습니다:
+
+ a = 0;
+ ... 변수 a 에 스토어를 하지 않는 코드 ...
+ a = 0;
+
+ 컴파일러는 변수 'a' 의 값은 이미 0이라는 것을 알고, 따라서 두번째 스토어를
+ 삭제할 겁니다. 만약 다른 CPU 가 그 사이 변수 'a' 에 다른 값을 썼다면
+ 황당한 결과가 나올 겁니다.
+
+ 컴파일러가 그런 잘못된 추측을 하지 않도록 WRITE_ONCE() 를 사용하세요:
+
+ WRITE_ONCE(a, 0);
+ ... 변수 a 에 스토어를 하지 않는 코드 ...
+ WRITE_ONCE(a, 0);
+
+ (*) 컴파일러는 하지 말라고 하지 않으면 메모리 액세스들을 재배치 할 수
+ 있습니다. 예를 들어, 다음의 프로세스 레벨 코드와 인터럽트 핸들러 사이의
+ 상호작용을 생각해 봅시다:
+
+ void process_level(void)
+ {
+ msg = get_message();
+ flag = true;
+ }
+
+ void interrupt_handler(void)
+ {
+ if (flag)
+ process_message(msg);
+ }
+
+ 이 코드에는 컴파일러가 process_level() 을 다음과 같이 변환하는 것을 막을
+ 수단이 없고, 이런 변환은 싱글쓰레드에서라면 실제로 훌륭한 선택일 수
+ 있습니다:
+
+ void process_level(void)
+ {
+ flag = true;
+ msg = get_message();
+ }
+
+ 이 두개의 문장 사이에 인터럽트가 발생한다면, interrupt_handler() 는 의미를
+ 알 수 없는 메세지를 받을 수도 있습니다. 이걸 막기 위해 다음과 같이
+ WRITE_ONCE() 를 사용하세요:
+
+ void process_level(void)
+ {
+ WRITE_ONCE(msg, get_message());
+ WRITE_ONCE(flag, true);
+ }
+
+ void interrupt_handler(void)
+ {
+ if (READ_ONCE(flag))
+ process_message(READ_ONCE(msg));
+ }
+
+ interrupt_handler() 안에서도 중첩된 인터럽트나 NMI 와 같이 인터럽트 핸들러
+ 역시 'flag' 와 'msg' 에 접근하는 또다른 무언가에 인터럽트 될 수 있다면
+ READ_ONCE() 와 WRITE_ONCE() 를 사용해야 함을 기억해 두세요. 만약 그런
+ 가능성이 없다면, interrupt_handler() 안에서는 문서화 목적이 아니라면
+ READ_ONCE() 와 WRITE_ONCE() 는 필요치 않습니다. (근래의 리눅스 커널에서
+ 중첩된 인터럽트는 보통 잘 일어나지 않음도 기억해 두세요, 실제로, 어떤
+ 인터럽트 핸들러가 인터럽트가 활성화된 채로 리턴하면 WARN_ONCE() 가
+ 실행됩니다.)
+
+ 컴파일러는 READ_ONCE() 와 WRITE_ONCE() 뒤의 READ_ONCE() 나 WRITE_ONCE(),
+ barrier(), 또는 비슷한 것들을 담고 있지 않은 코드를 움직일 수 있을 것으로
+ 가정되어야 합니다.
+
+ 이 효과는 barrier() 를 통해서도 만들 수 있지만, READ_ONCE() 와
+ WRITE_ONCE() 가 좀 더 안목 높은 선택입니다: READ_ONCE() 와 WRITE_ONCE()는
+ 컴파일러에 주어진 메모리 영역에 대해서만 최적화 가능성을 포기하도록
+ 하지만, barrier() 는 컴파일러가 지금까지 기계의 레지스터에 캐시해 놓은
+ 모든 메모리 영역의 값을 버려야 하게 하기 때문입니다. 물론, 컴파일러는
+ READ_ONCE() 와 WRITE_ONCE() 가 일어난 순서도 지켜줍니다, CPU 는 당연히
+ 그 순서를 지킬 의무가 없지만요.
+
+ (*) 컴파일러는 다음의 예에서와 같이 변수에의 스토어를 날조해낼 수도 있습니다:
+
+ if (a)
+ b = a;
+ else
+ b = 42;
+
+ 컴파일러는 아래와 같은 최적화로 브랜치를 줄일 겁니다:
+
+ b = 42;
+ if (a)
+ b = a;
+
+ 싱글 쓰레드 코드에서 이 최적화는 안전할 뿐 아니라 브랜치 갯수를
+ 줄여줍니다. 하지만 안타깝게도, 동시성이 있는 코드에서는 이 최적화는 다른
+ CPU 가 'b' 를 로드할 때, -- 'a' 가 0이 아닌데도 -- 가짜인 값, 42를 보게
+ 되는 경우를 가능하게 합니다. 이걸 방지하기 위해 WRITE_ONCE() 를
+ 사용하세요:
+
+ if (a)
+ WRITE_ONCE(b, a);
+ else
+ WRITE_ONCE(b, 42);
+
+ 컴파일러는 로드를 만들어낼 수도 있습니다. 일반적으로는 문제를 일으키지
+ 않지만, 캐시 라인 바운싱을 일으켜 성능과 확장성을 떨어뜨릴 수 있습니다.
+ 날조된 로드를 막기 위해선 READ_ONCE() 를 사용하세요.
+
+ (*) 정렬된 메모리 주소에 위치한, 한번의 메모리 참조 인스트럭션으로 액세스
+ 가능한 크기의 데이터는 하나의 큰 액세스가 여러개의 작은 액세스들로
+ 대체되는 "로드 티어링(load tearing)" 과 "스토어 티어링(store tearing)" 을
+ 방지합니다. 예를 들어, 주어진 아키텍쳐가 7-bit imeediate field 를 갖는
+ 16-bit 스토어 인스트럭션을 제공한다면, 컴파일러는 다음의 32-bit 스토어를
+ 구현하는데에 두개의 16-bit store-immediate 명령을 사용하려 할겁니다:
+
+ p = 0x00010002;
+
+ 스토어 할 상수를 만들고 그 값을 스토어 하기 위해 두개가 넘는 인스트럭션을
+ 사용하게 되는, 이런 종류의 최적화를 GCC 는 실제로 함을 부디 알아 두십시오.
+ 이 최적화는 싱글 쓰레드 코드에서는 성공적인 최적화 입니다. 실제로, 근래에
+ 발생한 (그리고 고쳐진) 버그는 GCC 가 volatile 스토어에 비정상적으로 이
+ 최적화를 사용하게 했습니다. 그런 버그가 없다면, 다음의 예에서
+ WRITE_ONCE() 의 사용은 스토어 티어링을 방지합니다:
+
+ WRITE_ONCE(p, 0x00010002);
+
+ Packed 구조체의 사용 역시 다음의 예처럼 로드 / 스토어 티어링을 유발할 수
+ 있습니다:
+
+ struct __attribute__((__packed__)) foo {
+ short a;
+ int b;
+ short c;
+ };
+ struct foo foo1, foo2;
+ ...
+
+ foo2.a = foo1.a;
+ foo2.b = foo1.b;
+ foo2.c = foo1.c;
+
+ READ_ONCE() 나 WRITE_ONCE() 도 없고 volatile 마킹도 없기 때문에,
+ 컴파일러는 이 세개의 대입문을 두개의 32-bit 로드와 두개의 32-bit 스토어로
+ 변환할 수 있습니다. 이는 'foo1.b' 의 값의 로드 티어링과 'foo2.b' 의
+ 스토어 티어링을 초래할 겁니다. 이 예에서도 READ_ONCE() 와 WRITE_ONCE()
+ 가 티어링을 막을 수 있습니다:
+
+ foo2.a = foo1.a;
+ WRITE_ONCE(foo2.b, READ_ONCE(foo1.b));
+ foo2.c = foo1.c;
+
+그렇지만, volatile 로 마크된 변수에 대해서는 READ_ONCE() 와 WRITE_ONCE() 가
+필요치 않습니다. 예를 들어, 'jiffies' 는 volatile 로 마크되어 있기 때문에,
+READ_ONCE(jiffies) 라고 할 필요가 없습니다. READ_ONCE() 와 WRITE_ONCE() 가
+실은 volatile 캐스팅으로 구현되어 있어서 인자가 이미 volatile 로 마크되어
+있다면 또다른 효과를 내지는 않기 때문입니다.
+
+이 컴파일러 배리어들은 CPU 에는 직접적 효과를 전혀 만들지 않기 때문에, 결국은
+재배치가 일어날 수도 있음을 부디 기억해 두십시오.
+
+
+CPU 메모리 배리어
+-----------------
+
+리눅스 커널은 다음의 여덟개 기본 CPU 메모리 배리어를 가지고 있습니다:
+
+ TYPE MANDATORY SMP CONDITIONAL
+ =============== ======================= ===========================
+ 범용 mb() smp_mb()
+ 쓰기 wmb() smp_wmb()
+ 읽기 rmb() smp_rmb()
+ 데이터 의존성 read_barrier_depends() smp_read_barrier_depends()
+
+
+데이터 의존성 배리어를 제외한 모든 메모리 배리어는 컴파일러 배리어를
+포함합니다. 데이터 의존성은 컴파일러에의 추가적인 순서 보장을 포함하지
+않습니다.
+
+방백: 데이터 의존성이 있는 경우, 컴파일러는 해당 로드를 올바른 순서로 일으킬
+것으로 (예: `a[b]` 는 a[b] 를 로드 하기 전에 b 의 값을 먼저 로드한다)
+기대되지만, C 언어 사양에는 컴파일러가 b 의 값을 추측 (예: 1 과 같음) 해서
+b 로드 전에 a 로드를 하는 코드 (예: tmp = a[1]; if (b != 1) tmp = a[b]; ) 를
+만들지 않아야 한다는 내용 같은 건 없습니다. 또한 컴파일러는 a[b] 를 로드한
+후에 b 를 또다시 로드할 수도 있어서, a[b] 보다 최신 버전의 b 값을 가질 수도
+있습니다. 이런 문제들의 해결책에 대한 의견 일치는 아직 없습니다만, 일단
+READ_ONCE() 매크로부터 보기 시작하는게 좋은 시작이 될겁니다.
+
+SMP 메모리 배리어들은 유니프로세서로 컴파일된 시스템에서는 컴파일러 배리어로
+바뀌는데, 하나의 CPU 는 스스로 일관성을 유지하고, 겹치는 액세스들 역시 올바른
+순서로 행해질 것으로 생각되기 때문입니다. 하지만, 아래의 "Virtual Machine
+Guests" 서브섹션을 참고하십시오.
+
+[!] SMP 시스템에서 공유메모리로의 접근들을 순서 세워야 할 때, SMP 메모리
+배리어는 _반드시_ 사용되어야 함을 기억하세요, 그대신 락을 사용하는 것으로도
+충분하긴 하지만 말이죠.
+
+Mandatory 배리어들은 SMP 시스템에서도 UP 시스템에서도 SMP 효과만 통제하기에는
+불필요한 오버헤드를 갖기 때문에 SMP 효과만 통제하면 되는 곳에는 사용되지 않아야
+합니다. 하지만, 느슨한 순서 규칙의 메모리 I/O 윈도우를 통한 MMIO 의 효과를
+통제할 때에는 mandatory 배리어들이 사용될 수 있습니다. 이 배리어들은
+컴파일러와 CPU 모두 재배치를 못하도록 함으로써 메모리 오퍼레이션들이 디바이스에
+보여지는 순서에도 영향을 주기 때문에, SMP 가 아닌 시스템이라 할지라도 필요할 수
+있습니다.
+
+
+일부 고급 배리어 함수들도 있습니다:
+
+ (*) smp_store_mb(var, value)
+
+ 이 함수는 특정 변수에 특정 값을 대입하고 범용 메모리 배리어를 칩니다.
+ UP 컴파일에서는 컴파일러 배리어보다 더한 것을 친다고는 보장되지 않습니다.
+
+
+ (*) smp_mb__before_atomic();
+ (*) smp_mb__after_atomic();
+
+ 이것들은 값을 리턴하지 않는 (더하기, 빼기, 증가, 감소와 같은) 어토믹
+ 함수들을 위한, 특히 그것들이 레퍼런스 카운팅에 사용될 때를 위한
+ 함수들입니다. 이 함수들은 메모리 배리어를 내포하고 있지는 않습니다.
+
+ 이것들은 값을 리턴하지 않으며 어토믹한 (set_bit 과 clear_bit 같은) 비트
+ 연산에도 사용될 수 있습니다.
+
+ 한 예로, 객체 하나를 무효한 것으로 표시하고 그 객체의 레퍼런스 카운트를
+ 감소시키는 다음 코드를 보세요:
+
+ obj->dead = 1;
+ smp_mb__before_atomic();
+ atomic_dec(&obj->ref_count);
+
+ 이 코드는 객체의 업데이트된 death 마크가 레퍼런스 카운터 감소 동작
+ *전에* 보일 것을 보장합니다.
+
+ 더 많은 정보를 위해선 Documentation/atomic_ops.txt 문서를 참고하세요.
+ 어디서 이것들을 사용해야 할지 궁금하다면 "어토믹 오퍼레이션" 서브섹션을
+ 참고하세요.
+
+
+ (*) lockless_dereference();
+
+ 이 함수는 smp_read_barrier_depends() 데이터 의존성 배리어를 사용하는
+ 포인터 읽어오기 래퍼(wrapper) 함수로 생각될 수 있습니다.
+
+ 객체의 라이프타임이 RCU 외의 메커니즘으로 관리된다는 점을 제외하면
+ rcu_dereference() 와도 유사한데, 예를 들면 객체가 시스템이 꺼질 때에만
+ 제거되는 경우 등입니다. 또한, lockless_dereference() 은 RCU 와 함께
+ 사용될수도, RCU 없이 사용될 수도 있는 일부 데이터 구조에 사용되고
+ 있습니다.
+
+
+ (*) dma_wmb();
+ (*) dma_rmb();
+
+ 이것들은 CPU 와 DMA 가능한 디바이스에서 모두 액세스 가능한 공유 메모리의
+ 읽기, 쓰기 작업들의 순서를 보장하기 위해 consistent memory 에서 사용하기
+ 위한 것들입니다.
+
+ 예를 들어, 디바이스와 메모리를 공유하며, 디스크립터 상태 값을 사용해
+ 디스크립터가 디바이스에 속해 있는지 아니면 CPU 에 속해 있는지 표시하고,
+ 공지용 초인종(doorbell) 을 사용해 업데이트된 디스크립터가 디바이스에 사용
+ 가능해졌음을 공지하는 디바이스 드라이버를 생각해 봅시다:
+
+ if (desc->status != DEVICE_OWN) {
+ /* 디스크립터를 소유하기 전에는 데이터를 읽지 않음 */
+ dma_rmb();
+
+ /* 데이터를 읽고 씀 */
+ read_data = desc->data;
+ desc->data = write_data;
+
+ /* 상태 업데이트 전 수정사항을 반영 */
+ dma_wmb();
+
+ /* 소유권을 수정 */
+ desc->status = DEVICE_OWN;
+
+ /* MMIO 를 통해 디바이스에 공지를 하기 전에 메모리를 동기화 */
+ wmb();
+
+ /* 업데이트된 디스크립터의 디바이스에 공지 */
+ writel(DESC_NOTIFY, doorbell);
+ }
+
+ dma_rmb() 는 디스크립터로부터 데이터를 읽어오기 전에 디바이스가 소유권을
+ 내놓았음을 보장하게 하고, dma_wmb() 는 디바이스가 자신이 소유권을 다시
+ 가졌음을 보기 전에 디스크립터에 데이터가 쓰였음을 보장합니다. wmb() 는
+ 캐시 일관성이 없는 (cache incoherent) MMIO 영역에 쓰기를 시도하기 전에
+ 캐시 일관성이 있는 메모리 (cache coherent memory) 쓰기가 완료되었음을
+ 보장해주기 위해 필요합니다.
+
+ consistent memory 에 대한 자세한 내용을 위해선 Documentation/DMA-API.txt
+ 문서를 참고하세요.
+
+
+MMIO 쓰기 배리어
+----------------
+
+리눅스 커널은 또한 memory-mapped I/O 쓰기를 위한 특별한 배리어도 가지고
+있습니다:
+
+ mmiowb();
+
+이것은 mandatory 쓰기 배리어의 변종으로, 완화된 순서 규칙의 I/O 영역에으로의
+쓰기가 부분적으로 순서를 맞추도록 해줍니다. 이 함수는 CPU->하드웨어 사이를
+넘어서 실제 하드웨어에까지 일부 수준의 영향을 끼칩니다.
+
+더 많은 정보를 위해선 "Acquire vs I/O 액세스" 서브섹션을 참고하세요.
+
+
+=========================
+암묵적 커널 메모리 배리어
+=========================
+
+리눅스 커널의 일부 함수들은 메모리 배리어를 내장하고 있는데, 락(lock)과
+스케쥴링 관련 함수들이 대부분입니다.
+
+여기선 _최소한의_ 보장을 설명합니다; 특정 아키텍쳐에서는 이 설명보다 더 많은
+보장을 제공할 수도 있습니다만 해당 아키텍쳐에 종속적인 코드 외의 부분에서는
+그런 보장을 기대해선 안될겁니다.
+
+
+락 ACQUISITION 함수
+-------------------
+
+리눅스 커널은 다양한 락 구성체를 가지고 있습니다:
+
+ (*) 스핀 락
+ (*) R/W 스핀 락
+ (*) 뮤텍스
+ (*) 세마포어
+ (*) R/W 세마포어
+
+각 구성체마다 모든 경우에 "ACQUIRE" 오퍼레이션과 "RELEASE" 오퍼레이션의 변종이
+존재합니다. 이 오퍼레이션들은 모두 적절한 배리어를 내포하고 있습니다:
+
+ (1) ACQUIRE 오퍼레이션의 영향:
+
+ ACQUIRE 뒤에서 요청된 메모리 오퍼레이션은 ACQUIRE 오퍼레이션이 완료된
+ 뒤에 완료됩니다.
+
+ ACQUIRE 앞에서 요청된 메모리 오퍼레이션은 ACQUIRE 오퍼레이션이 완료된 후에
+ 완료될 수 있습니다. smp_mb__before_spinlock() 뒤에 ACQUIRE 가 실행되는
+ 코드 블록은 블록 앞의 스토어를 블록 뒤의 로드와 스토어에 대해 순서
+ 맞춥니다. 이건 smp_mb() 보다 완화된 것임을 기억하세요! 많은 아키텍쳐에서
+ smp_mb__before_spinlock() 은 사실 아무일도 하지 않습니다.
+
+ (2) RELEASE 오퍼레이션의 영향:
+
+ RELEASE 앞에서 요청된 메모리 오퍼레이션은 RELEASE 오퍼레이션이 완료되기
+ 전에 완료됩니다.
+
+ RELEASE 뒤에서 요청된 메모리 오퍼레이션은 RELEASE 오퍼레이션 완료 전에
+ 완료될 수 있습니다.
+
+ (3) ACQUIRE vs ACQUIRE 영향:
+
+ 어떤 ACQUIRE 오퍼레이션보다 앞에서 요청된 모든 ACQUIRE 오퍼레이션은 그
+ ACQUIRE 오퍼레이션 전에 완료됩니다.
+
+ (4) ACQUIRE vs RELEASE implication:
+
+ 어떤 RELEASE 오퍼레이션보다 앞서 요청된 ACQUIRE 오퍼레이션은 그 RELEASE
+ 오퍼레이션보다 먼저 완료됩니다.
+
+ (5) 실패한 조건적 ACQUIRE 영향:
+
+ ACQUIRE 오퍼레이션의 일부 락(lock) 변종은 락이 곧바로 획득하기에는
+ 불가능한 상태이거나 락이 획득 가능해지도록 기다리는 도중 시그널을 받거나
+ 해서 실패할 수 있습니다. 실패한 락은 어떤 배리어도 내포하지 않습니다.
+
+[!] 참고: 락 ACQUIRE 와 RELEASE 가 단방향 배리어여서 나타나는 현상 중 하나는
+크리티컬 섹션 바깥의 인스트럭션의 영향이 크리티컬 섹션 내부로도 들어올 수
+있다는 것입니다.
+
+RELEASE 후에 요청되는 ACQUIRE 는 전체 메모리 배리어라 여겨지면 안되는데,
+ACQUIRE 앞의 액세스가 ACQUIRE 후에 수행될 수 있고, RELEASE 후의 액세스가
+RELEASE 전에 수행될 수도 있으며, 그 두개의 액세스가 서로를 지나칠 수도 있기
+때문입니다:
+
+ *A = a;
+ ACQUIRE M
+ RELEASE M
+ *B = b;
+
+는 다음과 같이 될 수도 있습니다:
+
+ ACQUIRE M, STORE *B, STORE *A, RELEASE M
+
+ACQUIRE 와 RELEASE 가 락 획득과 해제라면, 그리고 락의 ACQUIRE 와 RELEASE 가
+같은 락 변수에 대한 것이라면, 해당 락을 쥐고 있지 않은 다른 CPU 의 시야에는
+이와 같은 재배치가 일어나는 것으로 보일 수 있습니다. 요약하자면, ACQUIRE 에
+이어 RELEASE 오퍼레이션을 순차적으로 실행하는 행위가 전체 메모리 배리어로
+생각되어선 -안됩니다-.
+
+비슷하게, 앞의 반대 케이스인 RELEASE 와 ACQUIRE 두개 오퍼레이션의 순차적 실행
+역시 전체 메모리 배리어를 내포하지 않습니다. 따라서, RELEASE, ACQUIRE 로
+규정되는 크리티컬 섹션의 CPU 수행은 RELEASE 와 ACQUIRE 를 가로지를 수 있으므로,
+다음과 같은 코드는:
+
+ *A = a;
+ RELEASE M
+ ACQUIRE N
+ *B = b;
+
+다음과 같이 수행될 수 있습니다:
+
+ ACQUIRE N, STORE *B, STORE *A, RELEASE M
+
+이런 재배치는 데드락을 일으킬 수도 있을 것처럼 보일 수 있습니다. 하지만, 그런
+데드락의 조짐이 있다면 RELEASE 는 단순히 완료될 것이므로 데드락은 존재할 수
+없습니다.
+
+ 이게 어떻게 올바른 동작을 할 수 있을까요?
+
+ 우리가 이야기 하고 있는건 재배치를 하는 CPU 에 대한 이야기이지,
+ 컴파일러에 대한 것이 아니란 점이 핵심입니다. 컴파일러 (또는, 개발자)
+ 가 오퍼레이션들을 이렇게 재배치하면, 데드락이 일어날 수 -있습-니다.
+
+ 하지만 CPU 가 오퍼레이션들을 재배치 했다는걸 생각해 보세요. 이 예에서,
+ 어셈블리 코드 상으로는 언락이 락을 앞서게 되어 있습니다. CPU 가 이를
+ 재배치해서 뒤의 락 오퍼레이션을 먼저 실행하게 됩니다. 만약 데드락이
+ 존재한다면, 이 락 오퍼레이션은 그저 스핀을 하며 계속해서 락을
+ 시도합니다 (또는, 한참 후에겠지만, 잠듭니다). CPU 는 언젠가는
+ (어셈블리 코드에서는 락을 앞서는) 언락 오퍼레이션을 실행하는데, 이 언락
+ 오퍼레이션이 잠재적 데드락을 해결하고, 락 오퍼레이션도 뒤이어 성공하게
+ 됩니다.
+
+ 하지만 만약 락이 잠을 자는 타입이었다면요? 그런 경우에 코드는
+ 스케쥴러로 들어가려 할 거고, 여기서 결국은 메모리 배리어를 만나게
+ 되는데, 이 메모리 배리어는 앞의 언락 오퍼레이션이 완료되도록 만들고,
+ 데드락은 이번에도 해결됩니다. 잠을 자는 행위와 언락 사이의 경주 상황
+ (race) 도 있을 수 있겠습니다만, 락 관련 기능들은 그런 경주 상황을 모든
+ 경우에 제대로 해결할 수 있어야 합니다.
+
+락과 세마포어는 UP 컴파일된 시스템에서의 순서에 대해 보장을 하지 않기 때문에,
+그런 상황에서 인터럽트 비활성화 오퍼레이션과 함께가 아니라면 어떤 일에도 - 특히
+I/O 액세스와 관련해서는 - 제대로 사용될 수 없을 겁니다.
+
+"CPU 간 ACQUIRING 배리어 효과" 섹션도 참고하시기 바랍니다.
+
+
+예를 들어, 다음과 같은 코드를 생각해 봅시다:
+
+ *A = a;
+ *B = b;
+ ACQUIRE
+ *C = c;
+ *D = d;
+ RELEASE
+ *E = e;
+ *F = f;
+
+여기선 다음의 이벤트 시퀀스가 생길 수 있습니다:
+
+ ACQUIRE, {*F,*A}, *E, {*C,*D}, *B, RELEASE
+
+ [+] {*F,*A} 는 조합된 액세스를 의미합니다.
+
+하지만 다음과 같은 건 불가능하죠:
+
+ {*F,*A}, *B, ACQUIRE, *C, *D, RELEASE, *E
+ *A, *B, *C, ACQUIRE, *D, RELEASE, *E, *F
+ *A, *B, ACQUIRE, *C, RELEASE, *D, *E, *F
+ *B, ACQUIRE, *C, *D, RELEASE, {*F,*A}, *E
+
+
+
+인터럽트 비활성화 함수
+----------------------
+
+인터럽트를 비활성화 하는 함수 (ACQUIRE 와 동일) 와 인터럽트를 활성화 하는 함수
+(RELEASE 와 동일) 는 컴파일러 배리어처럼만 동작합니다. 따라서, 별도의 메모리
+배리어나 I/O 배리어가 필요한 상황이라면 그 배리어들은 인터럽트 비활성화 함수
+외의 방법으로 제공되어야만 합니다.
+
+
+슬립과 웨이크업 함수
+--------------------
+
+글로벌 데이터에 표시된 이벤트에 의해 프로세스를 잠에 빠트리는 것과 깨우는 것은
+해당 이벤트를 기다리는 태스크의 태스크 상태와 그 이벤트를 알리기 위해 사용되는
+글로벌 데이터, 두 데이터간의 상호작용으로 볼 수 있습니다. 이것이 옳은 순서대로
+일어남을 분명히 하기 위해, 프로세스를 잠에 들게 하는 기능과 깨우는 기능은
+몇가지 배리어를 내포합니다.
+
+먼저, 잠을 재우는 쪽은 일반적으로 다음과 같은 이벤트 시퀀스를 따릅니다:
+
+ for (;;) {
+ set_current_state(TASK_UNINTERRUPTIBLE);
+ if (event_indicated)
+ break;
+ schedule();
+ }
+
+set_current_state() 에 의해, 태스크 상태가 바뀐 후 범용 메모리 배리어가
+자동으로 삽입됩니다:
+
+ CPU 1
+ ===============================
+ set_current_state();
+ smp_store_mb();
+ STORE current->state
+ <범용 배리어>
+ LOAD event_indicated
+
+set_current_state() 는 다음의 것들로 감싸질 수도 있습니다:
+
+ prepare_to_wait();
+ prepare_to_wait_exclusive();
+
+이것들 역시 상태를 설정한 후 범용 메모리 배리어를 삽입합니다.
+앞의 전체 시퀀스는 다음과 같은 함수들로 한번에 수행 가능한데, 이것들은 모두
+올바른 장소에 메모리 배리어를 삽입합니다:
+
+ wait_event();
+ wait_event_interruptible();
+ wait_event_interruptible_exclusive();
+ wait_event_interruptible_timeout();
+ wait_event_killable();
+ wait_event_timeout();
+ wait_on_bit();
+ wait_on_bit_lock();
+
+
+두번째로, 깨우기를 수행하는 코드는 일반적으로 다음과 같을 겁니다:
+
+ event_indicated = 1;
+ wake_up(&event_wait_queue);
+
+또는:
+
+ event_indicated = 1;
+ wake_up_process(event_daemon);
+
+wake_up() 류에 의해 쓰기 메모리 배리어가 내포됩니다. 만약 그것들이 뭔가를
+깨운다면요. 이 배리어는 태스크 상태가 지워지기 전에 수행되므로, 이벤트를
+알리기 위한 STORE 와 태스크 상태를 TASK_RUNNING 으로 설정하는 STORE 사이에
+위치하게 됩니다.
+
+ CPU 1 CPU 2
+ =============================== ===============================
+ set_current_state(); STORE event_indicated
+ smp_store_mb(); wake_up();
+ STORE current->state <쓰기 배리어>
+ <범용 배리어> STORE current->state
+ LOAD event_indicated
+
+한번더 말합니다만, 이 쓰기 메모리 배리어는 이 코드가 정말로 뭔가를 깨울 때에만
+실행됩니다. 이걸 설명하기 위해, X 와 Y 는 모두 0 으로 초기화 되어 있다는 가정
+하에 아래의 이벤트 시퀀스를 생각해 봅시다:
+
+ CPU 1 CPU 2
+ =============================== ===============================
+ X = 1; STORE event_indicated
+ smp_mb(); wake_up();
+ Y = 1; wait_event(wq, Y == 1);
+ wake_up(); load from Y sees 1, no memory barrier
+ load from X might see 0
+
+위 예제에서의 경우와 달리 깨우기가 정말로 행해졌다면, CPU 2 의 X 로드는 1 을
+본다고 보장될 수 있을 겁니다.
+
+사용 가능한 깨우기류 함수들로 다음과 같은 것들이 있습니다:
+
+ complete();
+ wake_up();
+ wake_up_all();
+ wake_up_bit();
+ wake_up_interruptible();
+ wake_up_interruptible_all();
+ wake_up_interruptible_nr();
+ wake_up_interruptible_poll();
+ wake_up_interruptible_sync();
+ wake_up_interruptible_sync_poll();
+ wake_up_locked();
+ wake_up_locked_poll();
+ wake_up_nr();
+ wake_up_poll();
+ wake_up_process();
+
+
+[!] 잠재우는 코드와 깨우는 코드에 내포되는 메모리 배리어들은 깨우기 전에
+이루어진 스토어를 잠재우는 코드가 set_current_state() 를 호출한 후에 행하는
+로드에 대해 순서를 맞추지 _않는다는_ 점을 기억하세요. 예를 들어, 잠재우는
+코드가 다음과 같고:
+
+ set_current_state(TASK_INTERRUPTIBLE);
+ if (event_indicated)
+ break;
+ __set_current_state(TASK_RUNNING);
+ do_something(my_data);
+
+깨우는 코드는 다음과 같다면:
+
+ my_data = value;
+ event_indicated = 1;
+ wake_up(&event_wait_queue);
+
+event_indecated 에의 변경이 잠재우는 코드에게 my_data 에의 변경 후에 이루어진
+것으로 인지될 것이라는 보장이 없습니다. 이런 경우에는 양쪽 코드 모두 각각의
+데이터 액세스 사이에 메모리 배리어를 직접 쳐야 합니다. 따라서 앞의 재우는
+코드는 다음과 같이:
+
+ set_current_state(TASK_INTERRUPTIBLE);
+ if (event_indicated) {
+ smp_rmb();
+ do_something(my_data);
+ }
+
+그리고 깨우는 코드는 다음과 같이 되어야 합니다:
+
+ my_data = value;
+ smp_wmb();
+ event_indicated = 1;
+ wake_up(&event_wait_queue);
+
+
+그외의 함수들
+-------------
+
+그외의 배리어를 내포하는 함수들은 다음과 같습니다:
+
+ (*) schedule() 과 그 유사한 것들이 완전한 메모리 배리어를 내포합니다.
+
+
+==============================
+CPU 간 ACQUIRING 배리어의 효과
+==============================
+
+SMP 시스템에서의 락 기능들은 더욱 강력한 형태의 배리어를 제공합니다: 이
+배리어는 동일한 락을 사용하는 다른 CPU 들의 메모리 액세스 순서에도 영향을
+끼칩니다.
+
+
+ACQUIRE VS 메모리 액세스
+------------------------
+
+다음의 예를 생각해 봅시다: 시스템은 두개의 스핀락 (M) 과 (Q), 그리고 세개의 CPU
+를 가지고 있습니다; 여기에 다음의 이벤트 시퀀스가 발생합니다:
+
+ CPU 1 CPU 2
+ =============================== ===============================
+ WRITE_ONCE(*A, a); WRITE_ONCE(*E, e);
+ ACQUIRE M ACQUIRE Q
+ WRITE_ONCE(*B, b); WRITE_ONCE(*F, f);
+ WRITE_ONCE(*C, c); WRITE_ONCE(*G, g);
+ RELEASE M RELEASE Q
+ WRITE_ONCE(*D, d); WRITE_ONCE(*H, h);
+
+*A 로의 액세스부터 *H 로의 액세스까지가 어떤 순서로 CPU 3 에게 보여질지에
+대해서는 각 CPU 에서의 락 사용에 의해 내포되어 있는 제약을 제외하고는 어떤
+보장도 존재하지 않습니다. 예를 들어, CPU 3 에게 다음과 같은 순서로 보여지는
+것이 가능합니다:
+
+ *E, ACQUIRE M, ACQUIRE Q, *G, *C, *F, *A, *B, RELEASE Q, *D, *H, RELEASE M
+
+하지만 다음과 같이 보이지는 않을 겁니다:
+
+ *B, *C or *D preceding ACQUIRE M
+ *A, *B or *C following RELEASE M
+ *F, *G or *H preceding ACQUIRE Q
+ *E, *F or *G following RELEASE Q
+
+
+
+ACQUIRE VS I/O 액세스
+----------------------
+
+특정한 (특히 NUMA 가 관련된) 환경 하에서 두개의 CPU 에서 동일한 스핀락으로
+보호되는 두개의 크리티컬 섹션 안의 I/O 액세스는 PCI 브릿지에 겹쳐진 I/O
+액세스로 보일 수 있는데, PCI 브릿지는 캐시 일관성 프로토콜과 합을 맞춰야 할
+의무가 없으므로, 필요한 읽기 메모리 배리어가 요청되지 않기 때문입니다.
+
+예를 들어서:
+
+ CPU 1 CPU 2
+ =============================== ===============================
+ spin_lock(Q)
+ writel(0, ADDR)
+ writel(1, DATA);
+ spin_unlock(Q);
+ spin_lock(Q);
+ writel(4, ADDR);
+ writel(5, DATA);
+ spin_unlock(Q);
+
+는 PCI 브릿지에 다음과 같이 보일 수 있습니다:
+
+ STORE *ADDR = 0, STORE *ADDR = 4, STORE *DATA = 1, STORE *DATA = 5
+
+이렇게 되면 하드웨어의 오동작을 일으킬 수 있습니다.
+
+
+이런 경우엔 잡아둔 스핀락을 내려놓기 전에 mmiowb() 를 수행해야 하는데, 예를
+들면 다음과 같습니다:
+
+ CPU 1 CPU 2
+ =============================== ===============================
+ spin_lock(Q)
+ writel(0, ADDR)
+ writel(1, DATA);
+ mmiowb();
+ spin_unlock(Q);
+ spin_lock(Q);
+ writel(4, ADDR);
+ writel(5, DATA);
+ mmiowb();
+ spin_unlock(Q);
+
+이 코드는 CPU 1 에서 요청된 두개의 스토어가 PCI 브릿지에 CPU 2 에서 요청된
+스토어들보다 먼저 보여짐을 보장합니다.
+
+
+또한, 같은 디바이스에서 스토어를 이어 로드가 수행되면 이 로드는 로드가 수행되기
+전에 스토어가 완료되기를 강제하므로 mmiowb() 의 필요가 없어집니다:
+
+ CPU 1 CPU 2
+ =============================== ===============================
+ spin_lock(Q)
+ writel(0, ADDR)
+ a = readl(DATA);
+ spin_unlock(Q);
+ spin_lock(Q);
+ writel(4, ADDR);
+ b = readl(DATA);
+ spin_unlock(Q);
+
+
+더 많은 정보를 위해선 Documenataion/DocBook/deviceiobook.tmpl 을 참고하세요.
+
+
+=========================
+메모리 배리어가 필요한 곳
+=========================
+
+설령 SMP 커널을 사용하더라도 싱글 쓰레드로 동작하는 코드는 올바르게 동작하는
+것으로 보여질 것이기 때문에, 평범한 시스템 운영중에 메모리 오퍼레이션 재배치는
+일반적으로 문제가 되지 않습니다. 하지만, 재배치가 문제가 _될 수 있는_ 네가지
+환경이 있습니다:
+
+ (*) 프로세서간 상호 작용.
+
+ (*) 어토믹 오퍼레이션.
+
+ (*) 디바이스 액세스.
+
+ (*) 인터럽트.
+
+
+프로세서간 상호 작용
+--------------------
+
+두개 이상의 프로세서를 가진 시스템이 있다면, 시스템의 두개 이상의 CPU 는 동시에
+같은 데이터에 대한 작업을 할 수 있습니다. 이는 동기화 문제를 일으킬 수 있고,
+이 문제를 해결하는 일반적 방법은 락을 사용하는 것입니다. 하지만, 락은 상당히
+비용이 비싸서 가능하면 락을 사용하지 않고 일을 처리하는 것이 낫습니다. 이런
+경우, 두 CPU 모두에 영향을 끼치는 오퍼레이션들은 오동작을 막기 위해 신중하게
+순서가 맞춰져야 합니다.
+
+예를 들어, R/W 세마포어의 느린 수행경로 (slow path) 를 생각해 봅시다.
+세마포어를 위해 대기를 하는 하나의 프로세스가 자신의 스택 중 일부를 이
+세마포어의 대기 프로세스 리스트에 링크한 채로 있습니다:
+
+ struct rw_semaphore {
+ ...
+ spinlock_t lock;
+ struct list_head waiters;
+ };
+
+ struct rwsem_waiter {
+ struct list_head list;
+ struct task_struct *task;
+ };
+
+특정 대기 상태 프로세스를 깨우기 위해, up_read() 나 up_write() 함수는 다음과
+같은 일을 합니다:
+
+ (1) 다음 대기 상태 프로세스 레코드는 어디있는지 알기 위해 이 대기 상태
+ 프로세스 레코드의 next 포인터를 읽습니다;
+
+ (2) 이 대기 상태 프로세스의 task 구조체로의 포인터를 읽습니다;
+
+ (3) 이 대기 상태 프로세스가 세마포어를 획득했음을 알리기 위해 task
+ 포인터를 초기화 합니다;
+
+ (4) 해당 태스크에 대해 wake_up_process() 를 호출합니다; 그리고
+
+ (5) 해당 대기 상태 프로세스의 task 구조체를 잡고 있던 레퍼런스를 해제합니다.
+
+달리 말하자면, 다음 이벤트 시퀀스를 수행해야 합니다:
+
+ LOAD waiter->list.next;
+ LOAD waiter->task;
+ STORE waiter->task;
+ CALL wakeup
+ RELEASE task
+
+그리고 이 이벤트들이 다른 순서로 수행된다면, 오동작이 일어날 수 있습니다.
+
+한번 세마포어의 대기줄에 들어갔고 세마포어 락을 놓았다면, 해당 대기 프로세스는
+락을 다시는 잡지 않습니다; 대신 자신의 task 포인터가 초기화 되길 기다립니다.
+그 레코드는 대기 프로세스의 스택에 있기 때문에, 리스트의 next 포인터가 읽혀지기
+_전에_ task 포인터가 지워진다면, 다른 CPU 는 해당 대기 프로세스를 시작해 버리고
+up*() 함수가 next 포인터를 읽기 전에 대기 프로세스의 스택을 마구 건드릴 수
+있습니다.
+
+그렇게 되면 위의 이벤트 시퀀스에 어떤 일이 일어나는지 생각해 보죠:
+
+ CPU 1 CPU 2
+ =============================== ===============================
+ down_xxx()
+ Queue waiter
+ Sleep
+ up_yyy()
+ LOAD waiter->task;
+ STORE waiter->task;
+ Woken up by other event
+ <preempt>
+ Resume processing
+ down_xxx() returns
+ call foo()
+ foo() clobbers *waiter
+ </preempt>
+ LOAD waiter->list.next;
+ --- OOPS ---
+
+이 문제는 세마포어 락의 사용으로 해결될 수도 있겠지만, 그렇게 되면 깨어난 후에
+down_xxx() 함수가 불필요하게 스핀락을 또다시 얻어야만 합니다.
+
+이 문제를 해결하는 방법은 범용 SMP 메모리 배리어를 추가하는 겁니다:
+
+ LOAD waiter->list.next;
+ LOAD waiter->task;
+ smp_mb();
+ STORE waiter->task;
+ CALL wakeup
+ RELEASE task
+
+이 경우에, 배리어는 시스템의 나머지 CPU 들에게 모든 배리어 앞의 메모리 액세스가
+배리어 뒤의 메모리 액세스보다 앞서 일어난 것으로 보이게 만듭니다. 배리어 앞의
+메모리 액세스들이 배리어 명령 자체가 완료되는 시점까지 완료된다고는 보장하지
+_않습니다_.
+
+(이게 문제가 되지 않을) 단일 프로세서 시스템에서 smp_mb() 는 실제로는 그저
+컴파일러가 CPU 안에서의 순서를 바꾸거나 하지 않고 주어진 순서대로 명령을
+내리도록 하는 컴파일러 배리어일 뿐입니다. 오직 하나의 CPU 만 있으니, CPU 의
+의존성 순서 로직이 그 외의 모든것을 알아서 처리할 겁니다.
+
+
+어토믹 오퍼레이션
+-----------------
+
+어토믹 오퍼레이션은 기술적으로 프로세서간 상호작용으로 분류되며 그 중 일부는
+전체 메모리 배리어를 내포하고 또 일부는 내포하지 않지만, 커널에서 상당히
+의존적으로 사용하는 기능 중 하나입니다.
+
+메모리의 어떤 상태를 수정하고 해당 상태에 대한 (예전의 또는 최신의) 정보를
+리턴하는 어토믹 오퍼레이션은 모두 SMP-조건적 범용 메모리 배리어(smp_mb())를
+실제 오퍼레이션의 앞과 뒤에 내포합니다. 이런 오퍼레이션은 다음의 것들을
+포함합니다:
+
+ xchg();
+ atomic_xchg(); atomic_long_xchg();
+ atomic_inc_return(); atomic_long_inc_return();
+ atomic_dec_return(); atomic_long_dec_return();
+ atomic_add_return(); atomic_long_add_return();
+ atomic_sub_return(); atomic_long_sub_return();
+ atomic_inc_and_test(); atomic_long_inc_and_test();
+ atomic_dec_and_test(); atomic_long_dec_and_test();
+ atomic_sub_and_test(); atomic_long_sub_and_test();
+ atomic_add_negative(); atomic_long_add_negative();
+ test_and_set_bit();
+ test_and_clear_bit();
+ test_and_change_bit();
+
+ /* exchange 조건이 성공할 때 */
+ cmpxchg();
+ atomic_cmpxchg(); atomic_long_cmpxchg();
+ atomic_add_unless(); atomic_long_add_unless();
+
+이것들은 메모리 배리어 효과가 필요한 ACQUIRE 부류와 RELEASE 부류 오퍼레이션들을
+구현할 때, 그리고 객체 해제를 위해 레퍼런스 카운터를 조정할 때, 암묵적 메모리
+배리어 효과가 필요한 곳 등에 사용됩니다.
+
+
+다음의 오퍼레이션들은 메모리 배리어를 내포하지 _않기_ 때문에 문제가 될 수
+있지만, RELEASE 부류의 오퍼레이션들과 같은 것들을 구현할 때 사용될 수도
+있습니다:
+
+ atomic_set();
+ set_bit();
+ clear_bit();
+ change_bit();
+
+이것들을 사용할 때에는 필요하다면 적절한 (예를 들면 smp_mb__before_atomic()
+같은) 메모리 배리어가 명시적으로 함께 사용되어야 합니다.
+
+
+아래의 것들도 메모리 배리어를 내포하지 _않기_ 때문에, 일부 환경에서는 (예를
+들면 smp_mb__before_atomic() 과 같은) 명시적인 메모리 배리어 사용이 필요합니다.
+
+ atomic_add();
+ atomic_sub();
+ atomic_inc();
+ atomic_dec();
+
+이것들이 통계 생성을 위해 사용된다면, 그리고 통계 데이터 사이에 관계가 존재하지
+않는다면 메모리 배리어는 필요치 않을 겁니다.
+
+객체의 수명을 관리하기 위해 레퍼런스 카운팅 목적으로 사용된다면, 레퍼런스
+카운터는 락으로 보호되는 섹션에서만 조정되거나 호출하는 쪽이 이미 충분한
+레퍼런스를 잡고 있을 것이기 때문에 메모리 배리어는 아마 필요 없을 겁니다.
+
+만약 어떤 락을 구성하기 위해 사용된다면, 락 관련 동작은 일반적으로 작업을 특정
+순서대로 진행해야 하므로 메모리 배리어가 필요할 수 있습니다.
+
+기본적으로, 각 사용처에서는 메모리 배리어가 필요한지 아닌지 충분히 고려해야
+합니다.
+
+아래의 오퍼레이션들은 특별한 락 관련 동작들입니다:
+
+ test_and_set_bit_lock();
+ clear_bit_unlock();
+ __clear_bit_unlock();
+
+이것들은 ACQUIRE 류와 RELEASE 류의 오퍼레이션들을 구현합니다. 락 관련 도구를
+구현할 때에는 이것들을 좀 더 선호하는 편이 나은데, 이것들의 구현은 많은
+아키텍쳐에서 최적화 될 수 있기 때문입니다.
+
+[!] 이런 상황에 사용할 수 있는 특수한 메모리 배리어 도구들이 있습니다만, 일부
+CPU 에서는 사용되는 어토믹 인스트럭션 자체에 메모리 배리어가 내포되어 있어서
+어토믹 오퍼레이션과 메모리 배리어를 함께 사용하는 게 불필요한 일이 될 수
+있는데, 그런 경우에 이 특수 메모리 배리어 도구들은 no-op 이 되어 실질적으로
+아무일도 하지 않습니다.
+
+더 많은 내용을 위해선 Documentation/atomic_ops.txt 를 참고하세요.
+
+
+디바이스 액세스
+---------------
+
+많은 디바이스가 메모리 매핑 기법으로 제어될 수 있는데, 그렇게 제어되는
+디바이스는 CPU 에는 단지 특정 메모리 영역의 집합처럼 보이게 됩니다. 드라이버는
+그런 디바이스를 제어하기 위해 정확히 올바른 순서로 올바른 메모리 액세스를
+만들어야 합니다.
+
+하지만, 액세스들을 재배치 하거나 조합하거나 병합하는게 더 효율적이라 판단하는
+영리한 CPU 나 컴파일러들을 사용하면 드라이버 코드의 조심스럽게 순서 맞춰진
+액세스들이 디바이스에는 요청된 순서대로 도착하지 못하게 할 수 있는 - 디바이스가
+오동작을 하게 할 - 잠재적 문제가 생길 수 있습니다.
+
+리눅스 커널 내부에서, I/O 는 어떻게 액세스들을 적절히 순차적이게 만들 수 있는지
+알고 있는, - inb() 나 writel() 과 같은 - 적절한 액세스 루틴을 통해 이루어져야만
+합니다. 이것들은 대부분의 경우에는 명시적 메모리 배리어 와 함께 사용될 필요가
+없습니다만, 다음의 두가지 상황에서는 명시적 메모리 배리어가 필요할 수 있습니다:
+
+ (1) 일부 시스템에서 I/O 스토어는 모든 CPU 에 일관되게 순서 맞춰지지 않는데,
+ 따라서 _모든_ 일반적인 드라이버들에 락이 사용되어야만 하고 이 크리티컬
+ 섹션을 빠져나오기 전에 mmiowb() 가 꼭 호출되어야 합니다.
+
+ (2) 만약 액세스 함수들이 완화된 메모리 액세스 속성을 갖는 I/O 메모리 윈도우를
+ 사용한다면, 순서를 강제하기 위해선 _mandatory_ 메모리 배리어가 필요합니다.
+
+더 많은 정보를 위해선 Documentation/DocBook/deviceiobook.tmpl 을 참고하십시오.
+
+
+인터럽트
+--------
+
+드라이버는 자신의 인터럽트 서비스 루틴에 의해 인터럽트 당할 수 있기 때문에
+드라이버의 이 두 부분은 서로의 디바이스 제어 또는 액세스 부분과 상호 간섭할 수
+있습니다.
+
+스스로에게 인터럽트 당하는 걸 불가능하게 하고, 드라이버의 크리티컬한
+오퍼레이션들을 모두 인터럽트가 불가능하게 된 영역에 집어넣거나 하는 방법 (락의
+한 형태) 으로 이런 상호 간섭을 - 최소한 부분적으로라도 - 줄일 수 있습니다.
+드라이버의 인터럽트 루틴이 실행 중인 동안, 해당 드라이버의 코어는 같은 CPU 에서
+수행되지 않을 것이며, 현재의 인터럽트가 처리되는 중에는 또다시 인터럽트가
+일어나지 못하도록 되어 있으니 인터럽트 핸들러는 그에 대해서는 락을 잡지 않아도
+됩니다.
+
+하지만, 어드레스 레지스터와 데이터 레지스터를 갖는 이더넷 카드를 다루는
+드라이버를 생각해 봅시다. 만약 이 드라이버의 코어가 인터럽트를 비활성화시킨
+채로 이더넷 카드와 대화하고 드라이버의 인터럽트 핸들러가 호출되었다면:
+
+ LOCAL IRQ DISABLE
+ writew(ADDR, 3);
+ writew(DATA, y);
+ LOCAL IRQ ENABLE
+ <interrupt>
+ writew(ADDR, 4);
+ q = readw(DATA);
+ </interrupt>
+
+만약 순서 규칙이 충분히 완화되어 있다면 데이터 레지스터에의 스토어는 어드레스
+레지스터에 두번째로 행해지는 스토어 뒤에 일어날 수도 있습니다:
+
+ STORE *ADDR = 3, STORE *ADDR = 4, STORE *DATA = y, q = LOAD *DATA
+
+
+만약 순서 규칙이 충분히 완화되어 있고 묵시적으로든 명시적으로든 배리어가
+사용되지 않았다면 인터럽트 비활성화 섹션에서 일어난 액세스가 바깥으로 새어서
+인터럽트 내에서 일어난 액세스와 섞일 수 있다고 - 그리고 그 반대도 - 가정해야만
+합니다.
+
+그런 영역 안에서 일어나는 I/O 액세스들은 엄격한 순서 규칙의 I/O 레지스터에
+묵시적 I/O 배리어를 형성하는 동기적 (synchronous) 로드 오퍼레이션을 포함하기
+때문에 일반적으로는 이런게 문제가 되지 않습니다. 만약 이걸로는 충분치 않다면
+mmiowb() 가 명시적으로 사용될 필요가 있습니다.
+
+
+하나의 인터럽트 루틴과 별도의 CPU 에서 수행중이며 서로 통신을 하는 두 루틴
+사이에도 비슷한 상황이 일어날 수 있습니다. 만약 그런 경우가 발생할 가능성이
+있다면, 순서를 보장하기 위해 인터럽트 비활성화 락이 사용되어져야만 합니다.
+
+
+======================
+커널 I/O 배리어의 효과
+======================
+
+I/O 메모리에 액세스할 때, 드라이버는 적절한 액세스 함수를 사용해야 합니다:
+
+ (*) inX(), outX():
+
+ 이것들은 메모리 공간보다는 I/O 공간에 이야기를 하려는 의도로
+ 만들어졌습니다만, 그건 기본적으로 CPU 마다 다른 컨셉입니다. i386 과
+ x86_64 프로세서들은 특별한 I/O 공간 액세스 사이클과 명령어를 실제로 가지고
+ 있지만, 다른 많은 CPU 들에는 그런 컨셉이 존재하지 않습니다.
+
+ 다른 것들 중에서도 PCI 버스가 I/O 공간 컨셉을 정의하는데, 이는 - i386 과
+ x86_64 같은 CPU 에서 - CPU 의 I/O 공간 컨셉으로 쉽게 매치됩니다. 하지만,
+ 대체할 I/O 공간이 없는 CPU 에서는 CPU 의 메모리 맵의 가상 I/O 공간으로
+ 매핑될 수도 있습니다.
+
+ 이 공간으로의 액세스는 (i386 등에서는) 완전하게 동기화 됩니다만, 중간의
+ (PCI 호스트 브리지와 같은) 브리지들은 이를 완전히 보장하진 않을수도
+ 있습니다.
+
+ 이것들의 상호간의 순서는 완전하게 보장됩니다.
+
+ 다른 타입의 메모리 오퍼레이션, I/O 오퍼레이션에 대한 순서는 완전하게
+ 보장되지는 않습니다.
+
+ (*) readX(), writeX():
+
+ 이것들이 수행 요청되는 CPU 에서 서로에게 완전히 순서가 맞춰지고 독립적으로
+ 수행되는지에 대한 보장 여부는 이들이 액세스 하는 메모리 윈도우에 정의된
+ 특성에 의해 결정됩니다. 예를 들어, 최신의 i386 아키텍쳐 머신에서는 MTRR
+ 레지스터로 이 특성이 조정됩니다.
+
+ 일반적으로는, 프리페치 (prefetch) 가능한 디바이스를 액세스 하는게
+ 아니라면, 이것들은 완전히 순서가 맞춰지고 결합되지 않게 보장될 겁니다.
+
+ 하지만, (PCI 브리지와 같은) 중간의 하드웨어는 자신이 원한다면 집행을
+ 연기시킬 수 있습니다; 스토어 명령을 실제로 하드웨어로 내려보내기(flush)
+ 위해서는 같은 위치로부터 로드를 하는 방법이 있습니다만[*], PCI 의 경우는
+ 같은 디바이스나 환경 구성 영역에서의 로드만으로도 충분할 겁니다.
+
+ [*] 주의! 쓰여진 것과 같은 위치로부터의 로드를 시도하는 것은 오동작을
+ 일으킬 수도 있습니다 - 예로 16650 Rx/Tx 시리얼 레지스터를 생각해
+ 보세요.
+
+ 프리페치 가능한 I/O 메모리가 사용되면, 스토어 명령들이 순서를 지키도록
+ 하기 위해 mmiowb() 배리어가 필요할 수 있습니다.
+
+ PCI 트랜잭션 사이의 상호작용에 대해 더 많은 정보를 위해선 PCI 명세서를
+ 참고하시기 바랍니다.
+
+ (*) readX_relaxed(), writeX_relaxed()
+
+ 이것들은 readX() 와 writeX() 랑 비슷하지만, 더 완화된 메모리 순서 보장을
+ 제공합니다. 구체적으로, 이것들은 일반적 메모리 액세스 (예: DMA 버퍼) 에도
+ LOCK 이나 UNLOCK 오퍼레이션들에도 순서를 보장하지 않습니다. LOCK 이나
+ UNLOCK 오퍼레이션들에 맞춰지는 순서가 필요하다면, mmiowb() 배리어가 사용될
+ 수 있습니다. 같은 주변 장치에의 완화된 액세스끼리는 순서가 지켜짐을 알아
+ 두시기 바랍니다.
+
+ (*) ioreadX(), iowriteX()
+
+ 이것들은 inX()/outX() 나 readX()/writeX() 처럼 실제로 수행하는 액세스의
+ 종류에 따라 적절하게 수행될 것입니다.
+
+
+===================================
+가정되는 가장 완화된 실행 순서 모델
+===================================
+
+컨셉적으로 CPU 는 주어진 프로그램에 대해 프로그램 그 자체에는 인과성 (program
+causality) 을 지키는 것처럼 보이게 하지만 일반적으로는 순서를 거의 지켜주지
+않는다고 가정되어야만 합니다. (i386 이나 x86_64 같은) 일부 CPU 들은 코드
+재배치에 (powerpc 나 frv 와 같은) 다른 것들에 비해 강한 제약을 갖지만, 아키텍쳐
+종속적 코드 이외의 코드에서는 순서에 대한 제약이 가장 완화된 경우 (DEC Alpha)
+를 가정해야 합니다.
+
+이 말은, CPU 에게 주어지는 인스트럭션 스트림 내의 한 인스트럭션이 앞의
+인스트럭션에 종속적이라면 앞의 인스트럭션은 뒤의 종속적 인스트럭션이 실행되기
+전에 완료[*]될 수 있어야 한다는 제약 (달리 말해서, 인과성이 지켜지는 것으로
+보이게 함) 외에는 자신이 원하는 순서대로 - 심지어 병렬적으로도 - 그 스트림을
+실행할 수 있음을 의미합니다
+
+ [*] 일부 인스트럭션은 하나 이상의 영향 - 조건 코드를 바꾼다던지, 레지스터나
+ 메모리를 바꾼다던지 - 을 만들어내며, 다른 인스트럭션은 다른 효과에
+ 종속적일 수 있습니다.
+
+CPU 는 최종적으로 아무 효과도 만들지 않는 인스트럭션 시퀀스는 없애버릴 수도
+있습니다. 예를 들어, 만약 두개의 연속되는 인스트럭션이 둘 다 같은 레지스터에
+직접적인 값 (immediate value) 을 집어넣는다면, 첫번째 인스트럭션은 버려질 수도
+있습니다.
+
+
+비슷하게, 컴파일러 역시 프로그램의 인과성만 지켜준다면 인스트럭션 스트림을
+자신이 보기에 올바르다 생각되는대로 재배치 할 수 있습니다.
+
+
+===============
+CPU 캐시의 영향
+===============
+
+캐시된 메모리 오퍼레이션들이 시스템 전체에 어떻게 인지되는지는 CPU 와 메모리
+사이에 존재하는 캐시들, 그리고 시스템 상태의 일관성을 관리하는 메모리 일관성
+시스템에 상당 부분 영향을 받습니다.
+
+한 CPU 가 시스템의 다른 부분들과 캐시를 통해 상호작용한다면, 메모리 시스템은
+CPU 의 캐시들을 포함해야 하며, CPU 와 CPU 자신의 캐시 사이에서의 동작을 위한
+메모리 배리어를 가져야 합니다. (메모리 배리어는 논리적으로는 다음 그림의
+점선에서 동작합니다):
+
+ <--- CPU ---> : <----------- Memory ----------->
+ :
+ +--------+ +--------+ : +--------+ +-----------+
+ | | | | : | | | | +--------+
+ | CPU | | Memory | : | CPU | | | | |
+ | Core |--->| Access |----->| Cache |<-->| | | |
+ | | | Queue | : | | | |--->| Memory |
+ | | | | : | | | | | |
+ +--------+ +--------+ : +--------+ | | | |
+ : | Cache | +--------+
+ : | Coherency |
+ : | Mechanism | +--------+
+ +--------+ +--------+ : +--------+ | | | |
+ | | | | : | | | | | |
+ | CPU | | Memory | : | CPU | | |--->| Device |
+ | Core |--->| Access |----->| Cache |<-->| | | |
+ | | | Queue | : | | | | | |
+ | | | | : | | | | +--------+
+ +--------+ +--------+ : +--------+ +-----------+
+ :
+ :
+
+특정 로드나 스토어는 해당 오퍼레이션을 요청한 CPU 의 캐시 내에서 동작을 완료할
+수도 있기 때문에 해당 CPU 의 바깥에는 보이지 않을 수 있지만, 다른 CPU 가 관심을
+갖는다면 캐시 일관성 메커니즘이 해당 캐시라인을 해당 CPU 에게 전달하고, 해당
+메모리 영역에 대한 오퍼레이션이 발생할 때마다 그 영향을 전파시키기 때문에, 해당
+오퍼레이션은 메모리에 실제로 액세스를 한것처럼 나타날 것입니다.
+
+CPU 코어는 프로그램의 인과성이 유지된다고만 여겨진다면 인스트럭션들을 어떤
+순서로든 재배치해서 수행할 수 있습니다. 일부 인스트럭션들은 로드나 스토어
+오퍼레이션을 만드는데 이 오퍼레이션들은 이후 수행될 메모리 액세스 큐에 들어가게
+됩니다. 코어는 이 오퍼레이션들을 해당 큐에 어떤 순서로든 원하는대로 넣을 수
+있고, 다른 인스트럭션의 완료를 기다리도록 강제되기 전까지는 수행을 계속합니다.
+
+메모리 배리어가 하는 일은 CPU 쪽에서 메모리 쪽으로 넘어가는 액세스들의 순서,
+그리고 그 액세스의 결과가 시스템의 다른 관찰자들에게 인지되는 순서를 제어하는
+것입니다.
+
+[!] CPU 들은 항상 그들 자신의 로드와 스토어는 프로그램 순서대로 일어난 것으로
+보기 때문에, 주어진 CPU 내에서는 메모리 배리어를 사용할 필요가 _없습니다_.
+
+[!] MMIO 나 다른 디바이스 액세스들은 캐시 시스템을 우회할 수도 있습니다. 우회
+여부는 디바이스가 액세스 되는 메모리 윈도우의 특성에 의해 결정될 수도 있고, CPU
+가 가지고 있을 수 있는 특수한 디바이스 통신 인스트럭션의 사용에 의해서 결정될
+수도 있습니다.
+
+
+캐시 일관성
+-----------
+
+하지만 삶은 앞에서 이야기한 것처럼 단순하지 않습니다: 캐시들은 일관적일 것으로
+기대되지만, 그 일관성이 순서에도 적용될 거라는 보장은 없습니다. 한 CPU 에서
+만들어진 변경 사항은 최종적으로는 시스템의 모든 CPU 에게 보여지게 되지만, 다른
+CPU 들에게도 같은 순서로 보이게 될 거라는 보장은 없다는 뜻입니다.
+
+
+두개의 CPU (1 & 2) 가 달려 있고, 각 CPU 에 두개의 데이터 캐시(CPU 1 은 A/B 를,
+CPU 2 는 C/D 를 갖습니다)가 병렬로 연결되어 있는 시스템을 다룬다고 생각해
+봅시다:
+
+ :
+ : +--------+
+ : +---------+ | |
+ +--------+ : +--->| Cache A |<------->| |
+ | | : | +---------+ | |
+ | CPU 1 |<---+ | |
+ | | : | +---------+ | |
+ +--------+ : +--->| Cache B |<------->| |
+ : +---------+ | |
+ : | Memory |
+ : +---------+ | System |
+ +--------+ : +--->| Cache C |<------->| |
+ | | : | +---------+ | |
+ | CPU 2 |<---+ | |
+ | | : | +---------+ | |
+ +--------+ : +--->| Cache D |<------->| |
+ : +---------+ | |
+ : +--------+
+ :
+
+이 시스템이 다음과 같은 특성을 갖는다 생각해 봅시다:
+
+ (*) 홀수번 캐시라인은 캐시 A, 캐시 C 또는 메모리에 위치할 수 있음;
+
+ (*) 짝수번 캐시라인은 캐시 B, 캐시 D 또는 메모리에 위치할 수 있음;
+
+ (*) CPU 코어가 한개의 캐시에 접근하는 동안, 다른 캐시는 - 더티 캐시라인을
+ 메모리에 내리거나 추측성 로드를 하거나 하기 위해 - 시스템의 다른 부분에
+ 액세스 하기 위해 버스를 사용할 수 있음;
+
+ (*) 각 캐시는 시스템의 나머지 부분들과 일관성을 맞추기 위해 해당 캐시에
+ 적용되어야 할 오퍼레이션들의 큐를 가짐;
+
+ (*) 이 일관성 큐는 캐시에 이미 존재하는 라인에 가해지는 평범한 로드에 의해서는
+ 비워지지 않는데, 큐의 오퍼레이션들이 이 로드의 결과에 영향을 끼칠 수 있다
+ 할지라도 그러함.
+
+이제, 첫번째 CPU 에서 두개의 쓰기 오퍼레이션을 만드는데, 해당 CPU 의 캐시에
+요청된 순서로 오퍼레이션이 도달됨을 보장하기 위해 두 오퍼레이션 사이에 쓰기
+배리어를 사용하는 상황을 상상해 봅시다:
+
+ CPU 1 CPU 2 COMMENT
+ =============== =============== =======================================
+ u == 0, v == 1 and p == &u, q == &u
+ v = 2;
+ smp_wmb(); v 의 변경이 p 의 변경 전에 보일 것을
+ 분명히 함
+ <A:modify v=2> v 는 이제 캐시 A 에 독점적으로 존재함
+ p = &v;
+ <B:modify p=&v> p 는 이제 캐시 B 에 독점적으로 존재함
+
+여기서의 쓰기 메모리 배리어는 CPU 1 의 캐시가 올바른 순서로 업데이트 된 것으로
+시스템의 다른 CPU 들이 인지하게 만듭니다. 하지만, 이제 두번째 CPU 가 그 값들을
+읽으려 하는 상황을 생각해 봅시다:
+
+ CPU 1 CPU 2 COMMENT
+ =============== =============== =======================================
+ ...
+ q = p;
+ x = *q;
+
+위의 두개의 읽기 오퍼레이션은 예상된 순서로 일어나지 못할 수 있는데, 두번째 CPU
+의 한 캐시에 다른 캐시 이벤트가 발생해 v 를 담고 있는 캐시라인의 해당 캐시에의
+업데이트가 지연되는 사이, p 를 담고 있는 캐시라인은 두번째 CPU 의 다른 캐시에
+업데이트 되어버렸을 수 있기 때문입니다.
+
+ CPU 1 CPU 2 COMMENT
+ =============== =============== =======================================
+ u == 0, v == 1 and p == &u, q == &u
+ v = 2;
+ smp_wmb();
+ <A:modify v=2> <C:busy>
+ <C:queue v=2>
+ p = &v; q = p;
+ <D:request p>
+ <B:modify p=&v> <D:commit p=&v>
+ <D:read p>
+ x = *q;
+ <C:read *q> 캐시에 업데이트 되기 전의 v 를 읽음
+ <C:unbusy>
+ <C:commit v=2>
+
+기본적으로, 두개의 캐시라인 모두 CPU 2 에 최종적으로는 업데이트 될 것이지만,
+별도의 개입 없이는, 업데이트의 순서가 CPU 1 에서 만들어진 순서와 동일할
+것이라는 보장이 없습니다.
+
+
+여기에 개입하기 위해선, 데이터 의존성 배리어나 읽기 배리어를 로드 오퍼레이션들
+사이에 넣어야 합니다. 이렇게 함으로써 캐시가 다음 요청을 처리하기 전에 일관성
+큐를 처리하도록 강제하게 됩니다.
+
+ CPU 1 CPU 2 COMMENT
+ =============== =============== =======================================
+ u == 0, v == 1 and p == &u, q == &u
+ v = 2;
+ smp_wmb();
+ <A:modify v=2> <C:busy>
+ <C:queue v=2>
+ p = &v; q = p;
+ <D:request p>
+ <B:modify p=&v> <D:commit p=&v>
+ <D:read p>
+ smp_read_barrier_depends()
+ <C:unbusy>
+ <C:commit v=2>
+ x = *q;
+ <C:read *q> 캐시에 업데이트 된 v 를 읽음
+
+
+이런 부류의 문제는 DEC Alpha 계열 프로세서들에서 발견될 수 있는데, 이들은
+데이터 버스를 좀 더 잘 사용해 성능을 개선할 수 있는, 분할된 캐시를 가지고 있기
+때문입니다. 대부분의 CPU 는 하나의 읽기 오퍼레이션의 메모리 액세스가 다른 읽기
+오퍼레이션에 의존적이라면 데이터 의존성 배리어를 내포시킵니다만, 모두가 그런건
+아니기 때문에 이점에 의존해선 안됩니다.
+
+다른 CPU 들도 분할된 캐시를 가지고 있을 수 있지만, 그런 CPU 들은 평범한 메모리
+액세스를 위해서도 이 분할된 캐시들 사이의 조정을 해야만 합니다. Alpha 는 가장
+약한 메모리 순서 시맨틱 (semantic) 을 선택함으로써 메모리 배리어가 명시적으로
+사용되지 않았을 때에는 그런 조정이 필요하지 않게 했습니다.
+
+
+캐시 일관성 VS DMA
+------------------
+
+모든 시스템이 DMA 를 하는 디바이스에 대해서까지 캐시 일관성을 유지하지는
+않습니다. 그런 경우, DMA 를 시도하는 디바이스는 RAM 으로부터 잘못된 데이터를
+읽을 수 있는데, 더티 캐시 라인이 CPU 의 캐시에 머무르고 있고, 바뀐 값이 아직
+RAM 에 써지지 않았을 수 있기 때문입니다. 이 문제를 해결하기 위해선, 커널의
+적절한 부분에서 각 CPU 캐시의 문제되는 비트들을 플러시 (flush) 시켜야만 합니다
+(그리고 그것들을 무효화 - invalidation - 시킬 수도 있겠죠).
+
+또한, 디바이스에 의해 RAM 에 DMA 로 쓰여진 값은 디바이스가 쓰기를 완료한 후에
+CPU 의 캐시에서 RAM 으로 쓰여지는 더티 캐시 라인에 의해 덮어써질 수도 있고, CPU
+의 캐시에 존재하는 캐시 라인이 해당 캐시에서 삭제되고 다시 값을 읽어들이기
+전까지는 RAM 이 업데이트 되었다는 사실 자체가 숨겨져 버릴 수도 있습니다. 이
+문제를 해결하기 위해선, 커널의 적절한 부분에서 각 CPU 의 캐시 안의 문제가 되는
+비트들을 무효화 시켜야 합니다.
+
+캐시 관리에 대한 더 많은 정보를 위해선 Documentation/cachetlb.txt 를
+참고하세요.
+
+
+캐시 일관성 VS MMIO
+-------------------
+
+Memory mapped I/O 는 일반적으로 CPU 의 메모리 공간 내의 한 윈도우의 특정 부분
+내의 메모리 지역에 이루어지는데, 이 윈도우는 일반적인, RAM 으로 향하는
+윈도우와는 다른 특성을 갖습니다.
+
+그런 특성 가운데 하나는, 일반적으로 그런 액세스는 캐시를 완전히 우회하고
+디바이스 버스로 곧바로 향한다는 것입니다. 이 말은 MMIO 액세스는 먼저
+시작되어서 캐시에서 완료된 메모리 액세스를 추월할 수 있다는 뜻입니다. 이런
+경우엔 메모리 배리어만으로는 충분치 않고, 만약 캐시된 메모리 쓰기 오퍼레이션과
+MMIO 액세스가 어떤 방식으로든 의존적이라면 해당 캐시는 두 오퍼레이션 사이에
+비워져(flush)야만 합니다.
+
+
+======================
+CPU 들이 저지르는 일들
+======================
+
+프로그래머는 CPU 가 메모리 오퍼레이션들을 정확히 요청한대로 수행해 줄 것이라고
+생각하는데, 예를 들어 다음과 같은 코드를 CPU 에게 넘긴다면:
+
+ a = READ_ONCE(*A);
+ WRITE_ONCE(*B, b);
+ c = READ_ONCE(*C);
+ d = READ_ONCE(*D);
+ WRITE_ONCE(*E, e);
+
+CPU 는 다음 인스트럭션을 처리하기 전에 현재의 인스트럭션을 위한 메모리
+오퍼레이션을 완료할 것이라 생각하고, 따라서 시스템 외부에서 관찰하기에도 정해진
+순서대로 오퍼레이션이 수행될 것으로 예상합니다:
+
+ LOAD *A, STORE *B, LOAD *C, LOAD *D, STORE *E.
+
+
+당연하지만, 실제로는 훨씬 엉망입니다. 많은 CPU 와 컴파일러에서 앞의 가정은
+성립하지 못하는데 그 이유는 다음과 같습니다:
+
+ (*) 로드 오퍼레이션들은 실행을 계속 해나가기 위해 곧바로 완료될 필요가 있는
+ 경우가 많은 반면, 스토어 오퍼레이션들은 종종 별다른 문제 없이 유예될 수
+ 있습니다;
+
+ (*) 로드 오퍼레이션들은 예측적으로 수행될 수 있으며, 필요없는 로드였다고
+ 증명된 예측적 로드의 결과는 버려집니다;
+
+ (*) 로드 오퍼레이션들은 예측적으로 수행될 수 있으므로, 예상된 이벤트의
+ 시퀀스와 다른 시간에 로드가 이뤄질 수 있습니다;
+
+ (*) 메모리 액세스 순서는 CPU 버스와 캐시를 좀 더 잘 사용할 수 있도록 재배치
+ 될 수 있습니다;
+
+ (*) 로드와 스토어는 인접한 위치에의 액세스들을 일괄적으로 처리할 수 있는
+ 메모리나 I/O 하드웨어 (메모리와 PCI 디바이스 둘 다 이게 가능할 수
+ 있습니다) 에 대해 요청되는 경우, 개별 오퍼레이션을 위한 트랜잭션 설정
+ 비용을 아끼기 위해 조합되어 실행될 수 있습니다; 그리고
+
+ (*) 해당 CPU 의 데이터 캐시가 순서에 영향을 끼칠 수도 있고, 캐시 일관성
+ 메커니즘이 - 스토어가 실제로 캐시에 도달한다면 - 이 문제를 완화시킬 수는
+ 있지만 이 일관성 관리가 다른 CPU 들에도 같은 순서로 전달된다는 보장은
+ 없습니다.
+
+따라서, 앞의 코드에 대해 다른 CPU 가 보는 결과는 다음과 같을 수 있습니다:
+
+ LOAD *A, ..., LOAD {*C,*D}, STORE *E, STORE *B
+
+ ("LOAD {*C,*D}" 는 조합된 로드입니다)
+
+
+하지만, CPU 는 스스로는 일관적일 것을 보장합니다: CPU _자신_ 의 액세스들은
+자신에게는 메모리 배리어가 없음에도 불구하고 정확히 순서 세워진 것으로 보여질
+것입니다. 예를 들어 다음의 코드가 주어졌다면:
+
+ U = READ_ONCE(*A);
+ WRITE_ONCE(*A, V);
+ WRITE_ONCE(*A, W);
+ X = READ_ONCE(*A);
+ WRITE_ONCE(*A, Y);
+ Z = READ_ONCE(*A);
+
+그리고 외부의 영향에 의한 간섭이 없다고 가정하면, 최종 결과는 다음과 같이
+나타날 것이라고 예상될 수 있습니다:
+
+ U == *A 의 최초 값
+ X == W
+ Z == Y
+ *A == Y
+
+앞의 코드는 CPU 가 다음의 메모리 액세스 시퀀스를 만들도록 할겁니다:
+
+ U=LOAD *A, STORE *A=V, STORE *A=W, X=LOAD *A, STORE *A=Y, Z=LOAD *A
+
+하지만, 별다른 개입이 없고 프로그램의 시야에 이 세상이 여전히 일관적이라고
+보인다는 보장만 지켜진다면 이 시퀀스는 어떤 조합으로든 재구성될 수 있으며, 각
+액세스들은 합쳐지거나 버려질 수 있습니다. 일부 아키텍쳐에서 CPU 는 같은 위치에
+대한 연속적인 로드 오퍼레이션들을 재배치 할 수 있기 때문에 앞의 예에서의
+READ_ONCE() 와 WRITE_ONCE() 는 반드시 존재해야 함을 알아두세요. 그런 종류의
+아키텍쳐에서 READ_ONCE() 와 WRITE_ONCE() 는 이 문제를 막기 위해 필요한 일을
+뭐가 됐든지 하게 되는데, 예를 들어 Itanium 에서는 READ_ONCE() 와 WRITE_ONCE()
+가 사용하는 volatile 캐스팅은 GCC 가 그런 재배치를 방지하는 특수 인스트럭션인
+ld.acq 와 stl.rel 인스트럭션을 각각 만들어 내도록 합니다.
+
+컴파일러 역시 이 시퀀스의 액세스들을 CPU 가 보기도 전에 합치거나 버리거나 뒤로
+미뤄버릴 수 있습니다.
+
+예를 들어:
+
+ *A = V;
+ *A = W;
+
+는 다음과 같이 변형될 수 있습니다:
+
+ *A = W;
+
+따라서, 쓰기 배리어나 WRITE_ONCE() 가 없다면 *A 로의 V 값의 저장의 효과는
+사라진다고 가정될 수 있습니다. 비슷하게:
+
+ *A = Y;
+ Z = *A;
+
+는, 메모리 배리어나 READ_ONCE() 와 WRITE_ONCE() 없이는 다음과 같이 변형될 수
+있습니다:
+
+ *A = Y;
+ Z = Y;
+
+그리고 이 LOAD 오퍼레이션은 CPU 바깥에는 아예 보이지 않습니다.
+
+
+그리고, ALPHA 가 있다
+---------------------
+
+DEC Alpha CPU 는 가장 완화된 메모리 순서의 CPU 중 하나입니다. 뿐만 아니라,
+Alpha CPU 의 일부 버전은 분할된 데이터 캐시를 가지고 있어서, 의미적으로
+관계되어 있는 두개의 캐시 라인이 서로 다른 시간에 업데이트 되는게 가능합니다.
+이게 데이터 의존성 배리어가 정말 필요해지는 부분인데, 데이터 의존성 배리어는
+메모리 일관성 시스템과 함께 두개의 캐시를 동기화 시켜서, 포인터 변경과 새로운
+데이터의 발견을 올바른 순서로 일어나게 하기 때문입니다.
+
+리눅스 커널의 메모리 배리어 모델은 Alpha 에 기초해서 정의되었습니다.
+
+위의 "캐시 일관성" 서브섹션을 참고하세요.
+
+
+가상 머신 게스트
+----------------
+
+가상 머신에서 동작하는 게스트들은 게스트 자체는 SMP 지원 없이 컴파일 되었다
+해도 SMP 영향을 받을 수 있습니다. 이건 UP 커널을 사용하면서 SMP 호스트와
+결부되어 발생하는 부작용입니다. 이 경우에는 mandatory 배리어를 사용해서 문제를
+해결할 수 있겠지만 그런 해결은 대부분의 경우 최적의 해결책이 아닙니다.
+
+이 문제를 완벽하게 해결하기 위해, 로우 레벨의 virt_mb() 등의 매크로를 사용할 수
+있습니다. 이것들은 SMP 가 활성화 되어 있다면 smp_mb() 등과 동일한 효과를
+갖습니다만, SMP 와 SMP 아닌 시스템 모두에 대해 동일한 코드를 만들어냅니다.
+예를 들어, 가상 머신 게스트들은 (SMP 일 수 있는) 호스트와 동기화를 할 때에는
+smp_mb() 가 아니라 virt_mb() 를 사용해야 합니다.
+
+이것들은 smp_mb() 류의 것들과 모든 부분에서 동일하며, 특히, MMIO 의 영향에
+대해서는 간여하지 않습니다: MMIO 의 영향을 제어하려면, mandatory 배리어를
+사용하시기 바랍니다.
+
+
+=======
+사용 예
+=======
+
+순환식 버퍼
+-----------
+
+메모리 배리어는 순환식 버퍼를 생성자(producer)와 소비자(consumer) 사이의
+동기화에 락을 사용하지 않고 구현하는데에 사용될 수 있습니다. 더 자세한 내용을
+위해선 다음을 참고하세요:
+
+ Documentation/circular-buffers.txt
+
+
+=========
+참고 문헌
+=========
+
+Alpha AXP Architecture Reference Manual, Second Edition (Sites & Witek,
+Digital Press)
+ Chapter 5.2: Physical Address Space Characteristics
+ Chapter 5.4: Caches and Write Buffers
+ Chapter 5.5: Data Sharing
+ Chapter 5.6: Read/Write Ordering
+
+AMD64 Architecture Programmer's Manual Volume 2: System Programming
+ Chapter 7.1: Memory-Access Ordering
+ Chapter 7.4: Buffering and Combining Memory Writes
+
+IA-32 Intel Architecture Software Developer's Manual, Volume 3:
+System Programming Guide
+ Chapter 7.1: Locked Atomic Operations
+ Chapter 7.2: Memory Ordering
+ Chapter 7.4: Serializing Instructions
+
+The SPARC Architecture Manual, Version 9
+ Chapter 8: Memory Models
+ Appendix D: Formal Specification of the Memory Models
+ Appendix J: Programming with the Memory Models
+
+UltraSPARC Programmer Reference Manual
+ Chapter 5: Memory Accesses and Cacheability
+ Chapter 15: Sparc-V9 Memory Models
+
+UltraSPARC III Cu User's Manual
+ Chapter 9: Memory Models
+
+UltraSPARC IIIi Processor User's Manual
+ Chapter 8: Memory Models
+
+UltraSPARC Architecture 2005
+ Chapter 9: Memory
+ Appendix D: Formal Specifications of the Memory Models
+
+UltraSPARC T1 Supplement to the UltraSPARC Architecture 2005
+ Chapter 8: Memory Models
+ Appendix F: Caches and Cache Coherency
+
+Solaris Internals, Core Kernel Architecture, p63-68:
+ Chapter 3.3: Hardware Considerations for Locks and
+ Synchronization
+
+Unix Systems for Modern Architectures, Symmetric Multiprocessing and Caching
+for Kernel Programmers:
+ Chapter 13: Other Memory Models
+
+Intel Itanium Architecture Software Developer's Manual: Volume 1:
+ Section 2.6: Speculation
+ Section 4.4: Memory Access
diff --git a/Documentation/locking/lglock.txt b/Documentation/locking/lglock.txt
deleted file mode 100644
index a6971e3..0000000
--- a/Documentation/locking/lglock.txt
+++ /dev/null
@@ -1,166 +0,0 @@
-lglock - local/global locks for mostly local access patterns
-------------------------------------------------------------
-
-Origin: Nick Piggin's VFS scalability series introduced during
- 2.6.35++ [1] [2]
-Location: kernel/locking/lglock.c
- include/linux/lglock.h
-Users: currently only the VFS and stop_machine related code
-
-Design Goal:
-------------
-
-Improve scalability of globally used large data sets that are
-distributed over all CPUs as per_cpu elements.
-
-To manage global data structures that are partitioned over all CPUs
-as per_cpu elements but can be mostly handled by CPU local actions
-lglock will be used where the majority of accesses are cpu local
-reading and occasional cpu local writing with very infrequent
-global write access.
-
-
-* deal with things locally whenever possible
- - very fast access to the local per_cpu data
- - reasonably fast access to specific per_cpu data on a different
- CPU
-* while making global action possible when needed
- - by expensive access to all CPUs locks - effectively
- resulting in a globally visible critical section.
-
-Design:
--------
-
-Basically it is an array of per_cpu spinlocks with the
-lg_local_lock/unlock accessing the local CPUs lock object and the
-lg_local_lock_cpu/unlock_cpu accessing a remote CPUs lock object
-the lg_local_lock has to disable preemption as migration protection so
-that the reference to the local CPUs lock does not go out of scope.
-Due to the lg_local_lock/unlock only touching cpu-local resources it
-is fast. Taking the local lock on a different CPU will be more
-expensive but still relatively cheap.
-
-One can relax the migration constraints by acquiring the current
-CPUs lock with lg_local_lock_cpu, remember the cpu, and release that
-lock at the end of the critical section even if migrated. This should
-give most of the performance benefits without inhibiting migration
-though needs careful considerations for nesting of lglocks and
-consideration of deadlocks with lg_global_lock.
-
-The lg_global_lock/unlock locks all underlying spinlocks of all
-possible CPUs (including those off-line). The preemption disable/enable
-are needed in the non-RT kernels to prevent deadlocks like:
-
- on cpu 1
-
- task A task B
- lg_global_lock
- got cpu 0 lock
- <<<< preempt <<<<
- lg_local_lock_cpu for cpu 0
- spin on cpu 0 lock
-
-On -RT this deadlock scenario is resolved by the arch_spin_locks in the
-lglocks being replaced by rt_mutexes which resolve the above deadlock
-by boosting the lock-holder.
-
-
-Implementation:
----------------
-
-The initial lglock implementation from Nick Piggin used some complex
-macros to generate the lglock/brlock in lglock.h - they were later
-turned into a set of functions by Andi Kleen [7]. The change to functions
-was motivated by the presence of multiple lock users and also by them
-being easier to maintain than the generating macros. This change to
-functions is also the basis to eliminated the restriction of not
-being initializeable in kernel modules (the remaining problem is that
-locks are not explicitly initialized - see lockdep-design.txt)
-
-Declaration and initialization:
--------------------------------
-
- #include <linux/lglock.h>
-
- DEFINE_LGLOCK(name)
- or:
- DEFINE_STATIC_LGLOCK(name);
-
- lg_lock_init(&name, "lockdep_name_string");
-
- on UP this is mapped to DEFINE_SPINLOCK(name) in both cases, note
- also that as of 3.18-rc6 all declaration in use are of the _STATIC_
- variant (and it seems that the non-static was never in use).
- lg_lock_init is initializing the lockdep map only.
-
-Usage:
-------
-
-From the locking semantics it is a spinlock. It could be called a
-locality aware spinlock. lg_local_* behaves like a per_cpu
-spinlock and lg_global_* like a global spinlock.
-No surprises in the API.
-
- lg_local_lock(*lglock);
- access to protected per_cpu object on this CPU
- lg_local_unlock(*lglock);
-
- lg_local_lock_cpu(*lglock, cpu);
- access to protected per_cpu object on other CPU cpu
- lg_local_unlock_cpu(*lglock, cpu);
-
- lg_global_lock(*lglock);
- access all protected per_cpu objects on all CPUs
- lg_global_unlock(*lglock);
-
- There are no _trylock variants of the lglocks.
-
-Note that the lg_global_lock/unlock has to iterate over all possible
-CPUs rather than the actually present CPUs or a CPU could go off-line
-with a held lock [4] and that makes it very expensive. A discussion on
-these issues can be found at [5]
-
-Constraints:
-------------
-
- * currently the declaration of lglocks in kernel modules is not
- possible, though this should be doable with little change.
- * lglocks are not recursive.
- * suitable for code that can do most operations on the CPU local
- data and will very rarely need the global lock
- * lg_global_lock/unlock is *very* expensive and does not scale
- * on UP systems all lg_* primitives are simply spinlocks
- * in PREEMPT_RT the spinlock becomes an rt-mutex and can sleep but
- does not change the tasks state while sleeping [6].
- * in PREEMPT_RT the preempt_disable/enable in lg_local_lock/unlock
- is downgraded to a migrate_disable/enable, the other
- preempt_disable/enable are downgraded to barriers [6].
- The deadlock noted for non-RT above is resolved due to rt_mutexes
- boosting the lock-holder in this case which arch_spin_locks do
- not do.
-
-lglocks were designed for very specific problems in the VFS and probably
-only are the right answer in these corner cases. Any new user that looks
-at lglocks probably wants to look at the seqlock and RCU alternatives as
-her first choice. There are also efforts to resolve the RCU issues that
-currently prevent using RCU in place of view remaining lglocks.
-
-Note on brlock history:
------------------------
-
-The 'Big Reader' read-write spinlocks were originally introduced by
-Ingo Molnar in 2000 (2.4/2.5 kernel series) and removed in 2003. They
-later were introduced by the VFS scalability patch set in 2.6 series
-again as the "big reader lock" brlock [2] variant of lglock which has
-been replaced by seqlock primitives or by RCU based primitives in the
-3.13 kernel series as was suggested in [3] in 2003. The brlock was
-entirely removed in the 3.13 kernel series.
-
-Link: 1 http://lkml.org/lkml/2010/8/2/81
-Link: 2 http://lwn.net/Articles/401738/
-Link: 3 http://lkml.org/lkml/2003/3/9/205
-Link: 4 https://lkml.org/lkml/2011/8/24/185
-Link: 5 http://lkml.org/lkml/2011/12/18/189
-Link: 6 https://www.kernel.org/pub/linux/kernel/projects/rt/
- patch series - lglocks-rt.patch.patch
-Link: 7 http://lkml.org/lkml/2012/3/5/26
diff --git a/Documentation/media/uapi/cec/cec-ioc-adap-g-log-addrs.rst b/Documentation/media/uapi/cec/cec-ioc-adap-g-log-addrs.rst
index 04ee900..201d483 100644
--- a/Documentation/media/uapi/cec/cec-ioc-adap-g-log-addrs.rst
+++ b/Documentation/media/uapi/cec/cec-ioc-adap-g-log-addrs.rst
@@ -144,7 +144,7 @@
- ``flags``
- - Flags. No flags are defined yet, so set this to 0.
+ - Flags. See :ref:`cec-log-addrs-flags` for a list of available flags.
- .. row 7
@@ -201,6 +201,25 @@
give the CEC framework more information about the device type, even
though the framework won't use it directly in the CEC message.
+.. _cec-log-addrs-flags:
+
+.. flat-table:: Flags for struct cec_log_addrs
+ :header-rows: 0
+ :stub-columns: 0
+ :widths: 3 1 4
+
+
+ - .. _`CEC-LOG-ADDRS-FL-ALLOW-UNREG-FALLBACK`:
+
+ - ``CEC_LOG_ADDRS_FL_ALLOW_UNREG_FALLBACK``
+
+ - 1
+
+ - By default if no logical address of the requested type can be claimed, then
+ it will go back to the unconfigured state. If this flag is set, then it will
+ fallback to the Unregistered logical address. Note that if the Unregistered
+ logical address was explicitly requested, then this flag has no effect.
+
.. _cec-versions:
.. flat-table:: CEC Versions
diff --git a/Documentation/media/uapi/cec/cec-ioc-dqevent.rst b/Documentation/media/uapi/cec/cec-ioc-dqevent.rst
index 7a6d6d0..2e1e7392 100644
--- a/Documentation/media/uapi/cec/cec-ioc-dqevent.rst
+++ b/Documentation/media/uapi/cec/cec-ioc-dqevent.rst
@@ -64,7 +64,8 @@
- ``phys_addr``
- - The current physical address.
+ - The current physical address. This is ``CEC_PHYS_ADDR_INVALID`` if no
+ valid physical address is set.
- .. row 2
@@ -72,7 +73,10 @@
- ``log_addr_mask``
- - The current set of claimed logical addresses.
+ - The current set of claimed logical addresses. This is 0 if no logical
+ addresses are claimed or if ``phys_addr`` is ``CEC_PHYS_ADDR_INVALID``.
+ If bit 15 is set (``1 << CEC_LOG_ADDR_UNREGISTERED``) then this device
+ has the unregistered logical address. In that case all other bits are 0.
diff --git a/Documentation/memory-barriers.txt b/Documentation/memory-barriers.txt
index a4d0a99..ba818ec 100644
--- a/Documentation/memory-barriers.txt
+++ b/Documentation/memory-barriers.txt
@@ -609,7 +609,7 @@
The data-dependency barrier must order the read into Q with the store
into *Q. This prohibits this outcome:
- (Q == B) && (B == 4)
+ (Q == &B) && (B == 4)
Please note that this pattern should be rare. After all, the whole point
of dependency ordering is to -prevent- writes to the data structure, along
@@ -1928,6 +1928,7 @@
See Documentation/DMA-API.txt for more information on consistent memory.
+
MMIO WRITE BARRIER
------------------
@@ -2075,7 +2076,7 @@
anything at all - especially with respect to I/O accesses - unless combined
with interrupt disabling operations.
-See also the section on "Inter-CPU locking barrier effects".
+See also the section on "Inter-CPU acquiring barrier effects".
As an example, consider the following:
diff --git a/Documentation/static-keys.txt b/Documentation/static-keys.txt
index 477927b..ea8d7b4 100644
--- a/Documentation/static-keys.txt
+++ b/Documentation/static-keys.txt
@@ -15,6 +15,8 @@
DEFINE_STATIC_KEY_TRUE(key);
DEFINE_STATIC_KEY_FALSE(key);
+DEFINE_STATIC_KEY_ARRAY_TRUE(keys, count);
+DEFINE_STATIC_KEY_ARRAY_FALSE(keys, count);
static_branch_likely()
static_branch_unlikely()
@@ -140,6 +142,13 @@
key is initialized false, a 'static_branch_inc()', will change the branch to
true. And then a 'static_branch_dec()', will again make the branch false.
+Where an array of keys is required, it can be defined as:
+
+ DEFINE_STATIC_KEY_ARRAY_TRUE(keys, count);
+
+or:
+
+ DEFINE_STATIC_KEY_ARRAY_FALSE(keys, count);
4) Architecture level code patching interface, 'jump labels'
diff --git a/MAINTAINERS b/MAINTAINERS
index c420ea3..9a7a9c6 100644
--- a/MAINTAINERS
+++ b/MAINTAINERS
@@ -913,15 +913,17 @@
ARM PMU PROFILING AND DEBUGGING
M: Will Deacon <will.deacon@arm.com>
-R: Mark Rutland <mark.rutland@arm.com>
+M: Mark Rutland <mark.rutland@arm.com>
S: Maintained
+L: linux-arm-kernel@lists.infradead.org (moderated for non-subscribers)
F: arch/arm*/kernel/perf_*
F: arch/arm/oprofile/common.c
F: arch/arm*/kernel/hw_breakpoint.c
F: arch/arm*/include/asm/hw_breakpoint.h
F: arch/arm*/include/asm/perf_event.h
-F: drivers/perf/arm_pmu.c
+F: drivers/perf/*
F: include/linux/perf/arm_pmu.h
+F: Documentation/devicetree/bindings/arm/pmu.txt
ARM PORT
M: Russell King <linux@armlinux.org.uk>
@@ -2506,7 +2508,7 @@
F: kernel/bpf/
BROADCOM B44 10/100 ETHERNET DRIVER
-M: Gary Zambrano <zambrano@broadcom.com>
+M: Michael Chan <michael.chan@broadcom.com>
L: netdev@vger.kernel.org
S: Supported
F: drivers/net/ethernet/broadcom/b44.*
@@ -3287,6 +3289,7 @@
S: Maintained
T: git git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git
T: git git://git.linaro.org/people/vireshk/linux.git (For ARM Updates)
+F: Documentation/cpu-freq/
F: drivers/cpufreq/
F: include/linux/cpufreq.h
@@ -4589,6 +4592,13 @@
S: Maintained
F: drivers/video/fbdev/efifb.c
+EFI TEST DRIVER
+L: linux-efi@vger.kernel.org
+M: Ivan Hu <ivan.hu@canonical.com>
+M: Matt Fleming <matt@codeblueprint.co.uk>
+S: Maintained
+F: drivers/firmware/efi/test/
+
EFS FILESYSTEM
W: http://aeschi.ch.eu.org/efs/
S: Orphan
@@ -6108,7 +6118,7 @@
F: drivers/cpufreq/intel_pstate.c
INTEL FRAMEBUFFER DRIVER (excluding 810 and 815)
-M: Maik Broemme <mbroemme@plusserver.de>
+M: Maik Broemme <mbroemme@libmpq.org>
L: linux-fbdev@vger.kernel.org
S: Maintained
F: Documentation/fb/intelfb.txt
@@ -8166,6 +8176,15 @@
W: https://fedorahosted.org/dropwatch/
F: net/core/drop_monitor.c
+NETWORKING [DSA]
+M: Andrew Lunn <andrew@lunn.ch>
+M: Vivien Didelot <vivien.didelot@savoirfairelinux.com>
+M: Florian Fainelli <f.fainelli@gmail.com>
+S: Maintained
+F: net/dsa/
+F: include/net/dsa.h
+F: drivers/net/dsa/
+
NETWORKING [GENERAL]
M: "David S. Miller" <davem@davemloft.net>
L: netdev@vger.kernel.org
@@ -8741,7 +8760,7 @@
F: include/linux/oprofile.h
ORACLE CLUSTER FILESYSTEM 2 (OCFS2)
-M: Mark Fasheh <mfasheh@suse.com>
+M: Mark Fasheh <mfasheh@versity.com>
M: Joel Becker <jlbec@evilplan.org>
L: ocfs2-devel@oss.oracle.com (moderated for non-subscribers)
W: http://ocfs2.wiki.kernel.org
@@ -8853,6 +8872,7 @@
F: Documentation/virtual/paravirt_ops.txt
F: arch/*/kernel/paravirt*
F: arch/*/include/asm/paravirt.h
+F: include/linux/hypervisor.h
PARIDE DRIVERS FOR PARALLEL PORT IDE DEVICES
M: Tim Waugh <tim@cyberelk.net>
@@ -11622,7 +11642,7 @@
THERMAL/CPU_COOLING
M: Amit Daniel Kachhap <amit.kachhap@gmail.com>
M: Viresh Kumar <viresh.kumar@linaro.org>
-M: Javi Merino <javi.merino@arm.com>
+M: Javi Merino <javi.merino@kernel.org>
L: linux-pm@vger.kernel.org
S: Supported
F: Documentation/thermal/cpu-cooling-api.txt
@@ -12574,7 +12594,7 @@
F: net/8021q/
VLYNQ BUS
-M: Florian Fainelli <florian@openwrt.org>
+M: Florian Fainelli <f.fainelli@gmail.com>
L: openwrt-devel@lists.openwrt.org (subscribers-only)
S: Maintained
F: drivers/vlynq/vlynq.c
diff --git a/Makefile b/Makefile
index 74e22c2..80b8671 100644
--- a/Makefile
+++ b/Makefile
@@ -1,7 +1,7 @@
VERSION = 4
PATCHLEVEL = 8
SUBLEVEL = 0
-EXTRAVERSION = -rc7
+EXTRAVERSION =
NAME = Psychotic Stoned Sheep
# *DOCUMENTATION*
diff --git a/arch/arm/Kconfig b/arch/arm/Kconfig
index a9c4e48..b2113c2 100644
--- a/arch/arm/Kconfig
+++ b/arch/arm/Kconfig
@@ -1,6 +1,7 @@
config ARM
bool
default y
+ select ARCH_CLOCKSOURCE_DATA
select ARCH_HAS_ATOMIC64_DEC_IF_POSITIVE
select ARCH_HAS_DEVMEM_IS_ALLOWED
select ARCH_HAS_ELF_RANDOMIZE
diff --git a/arch/arm/boot/compressed/head.S b/arch/arm/boot/compressed/head.S
index af11c2f..fc6d541 100644
--- a/arch/arm/boot/compressed/head.S
+++ b/arch/arm/boot/compressed/head.S
@@ -779,7 +779,7 @@
orrne r0, r0, #1 @ MMU enabled
movne r1, #0xfffffffd @ domain 0 = client
bic r6, r6, #1 << 31 @ 32-bit translation system
- bic r6, r6, #3 << 0 @ use only ttbr0
+ bic r6, r6, #(7 << 0) | (1 << 4) @ use only ttbr0
mcrne p15, 0, r3, c2, c0, 0 @ load page table pointer
mcrne p15, 0, r1, c3, c0, 0 @ load domain access control
mcrne p15, 0, r6, c2, c0, 2 @ load ttb control
diff --git a/arch/arm/configs/exynos_defconfig b/arch/arm/configs/exynos_defconfig
index 01986de..36cc7cc 100644
--- a/arch/arm/configs/exynos_defconfig
+++ b/arch/arm/configs/exynos_defconfig
@@ -28,7 +28,7 @@
CONFIG_CPU_FREQ_GOV_POWERSAVE=m
CONFIG_CPU_FREQ_GOV_USERSPACE=m
CONFIG_CPU_FREQ_GOV_CONSERVATIVE=m
-CONFIG_CPU_FREQ_GOV_SCHEDUTIL=m
+CONFIG_CPU_FREQ_GOV_SCHEDUTIL=y
CONFIG_CPUFREQ_DT=y
CONFIG_CPU_IDLE=y
CONFIG_ARM_EXYNOS_CPUIDLE=y
diff --git a/arch/arm/configs/multi_v7_defconfig b/arch/arm/configs/multi_v7_defconfig
index ea3566f..5845910 100644
--- a/arch/arm/configs/multi_v7_defconfig
+++ b/arch/arm/configs/multi_v7_defconfig
@@ -135,7 +135,7 @@
CONFIG_CPU_FREQ_GOV_POWERSAVE=m
CONFIG_CPU_FREQ_GOV_USERSPACE=m
CONFIG_CPU_FREQ_GOV_CONSERVATIVE=m
-CONFIG_CPU_FREQ_GOV_SCHEDUTIL=m
+CONFIG_CPU_FREQ_GOV_SCHEDUTIL=y
CONFIG_QORIQ_CPUFREQ=y
CONFIG_CPU_IDLE=y
CONFIG_ARM_CPUIDLE=y
diff --git a/arch/arm/crypto/aes-ce-glue.c b/arch/arm/crypto/aes-ce-glue.c
index da3c042..aef022a 100644
--- a/arch/arm/crypto/aes-ce-glue.c
+++ b/arch/arm/crypto/aes-ce-glue.c
@@ -284,7 +284,7 @@
err = blkcipher_walk_done(desc, &walk,
walk.nbytes % AES_BLOCK_SIZE);
}
- if (nbytes) {
+ if (walk.nbytes % AES_BLOCK_SIZE) {
u8 *tdst = walk.dst.virt.addr + blocks * AES_BLOCK_SIZE;
u8 *tsrc = walk.src.virt.addr + blocks * AES_BLOCK_SIZE;
u8 __aligned(8) tail[AES_BLOCK_SIZE];
diff --git a/arch/arm/include/asm/clocksource.h b/arch/arm/include/asm/clocksource.h
new file mode 100644
index 0000000..0b350a7
--- /dev/null
+++ b/arch/arm/include/asm/clocksource.h
@@ -0,0 +1,8 @@
+#ifndef _ASM_CLOCKSOURCE_H
+#define _ASM_CLOCKSOURCE_H
+
+struct arch_clocksource_data {
+ bool vdso_direct; /* Usable for direct VDSO access? */
+};
+
+#endif
diff --git a/arch/arm/include/asm/dma-mapping.h b/arch/arm/include/asm/dma-mapping.h
index d009f79..bf02dbd 100644
--- a/arch/arm/include/asm/dma-mapping.h
+++ b/arch/arm/include/asm/dma-mapping.h
@@ -111,7 +111,7 @@
/* The ARM override for dma_max_pfn() */
static inline unsigned long dma_max_pfn(struct device *dev)
{
- return PHYS_PFN_OFFSET + dma_to_pfn(dev, *dev->dma_mask);
+ return dma_to_pfn(dev, *dev->dma_mask);
}
#define dma_max_pfn(dev) dma_max_pfn(dev)
diff --git a/arch/arm/kernel/devtree.c b/arch/arm/kernel/devtree.c
index 40ecd5f..f676feb 100644
--- a/arch/arm/kernel/devtree.c
+++ b/arch/arm/kernel/devtree.c
@@ -88,6 +88,8 @@
return;
for_each_child_of_node(cpus, cpu) {
+ const __be32 *cell;
+ int prop_bytes;
u32 hwid;
if (of_node_cmp(cpu->type, "cpu"))
@@ -99,7 +101,8 @@
* properties is considered invalid to build the
* cpu_logical_map.
*/
- if (of_property_read_u32(cpu, "reg", &hwid)) {
+ cell = of_get_property(cpu, "reg", &prop_bytes);
+ if (!cell || prop_bytes < sizeof(*cell)) {
pr_debug(" * %s missing reg property\n",
cpu->full_name);
of_node_put(cpu);
@@ -107,10 +110,15 @@
}
/*
- * 8 MSBs must be set to 0 in the DT since the reg property
+ * Bits n:24 must be set to 0 in the DT since the reg property
* defines the MPIDR[23:0].
*/
- if (hwid & ~MPIDR_HWID_BITMASK) {
+ do {
+ hwid = be32_to_cpu(*cell++);
+ prop_bytes -= sizeof(*cell);
+ } while (!hwid && prop_bytes > 0);
+
+ if (prop_bytes || (hwid & ~MPIDR_HWID_BITMASK)) {
of_node_put(cpu);
return;
}
diff --git a/arch/arm/kernel/perf_event_v7.c b/arch/arm/kernel/perf_event_v7.c
index 1506385..b942349 100644
--- a/arch/arm/kernel/perf_event_v7.c
+++ b/arch/arm/kernel/perf_event_v7.c
@@ -596,12 +596,6 @@
.attrs = armv7_pmuv1_event_attrs,
};
-static const struct attribute_group *armv7_pmuv1_attr_groups[] = {
- &armv7_pmuv1_events_attr_group,
- &armv7_pmu_format_attr_group,
- NULL,
-};
-
ARMV7_EVENT_ATTR(mem_access, ARMV7_PERFCTR_MEM_ACCESS);
ARMV7_EVENT_ATTR(l1i_cache, ARMV7_PERFCTR_L1_ICACHE_ACCESS);
ARMV7_EVENT_ATTR(l1d_cache_wb, ARMV7_PERFCTR_L1_DCACHE_WB);
@@ -653,12 +647,6 @@
.attrs = armv7_pmuv2_event_attrs,
};
-static const struct attribute_group *armv7_pmuv2_attr_groups[] = {
- &armv7_pmuv2_events_attr_group,
- &armv7_pmu_format_attr_group,
- NULL,
-};
-
/*
* Perf Events' indices
*/
@@ -1208,7 +1196,10 @@
armv7pmu_init(cpu_pmu);
cpu_pmu->name = "armv7_cortex_a8";
cpu_pmu->map_event = armv7_a8_map_event;
- cpu_pmu->pmu.attr_groups = armv7_pmuv1_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv7_pmuv1_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv7_pmu_format_attr_group;
return armv7_probe_num_events(cpu_pmu);
}
@@ -1217,7 +1208,10 @@
armv7pmu_init(cpu_pmu);
cpu_pmu->name = "armv7_cortex_a9";
cpu_pmu->map_event = armv7_a9_map_event;
- cpu_pmu->pmu.attr_groups = armv7_pmuv1_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv7_pmuv1_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv7_pmu_format_attr_group;
return armv7_probe_num_events(cpu_pmu);
}
@@ -1226,7 +1220,10 @@
armv7pmu_init(cpu_pmu);
cpu_pmu->name = "armv7_cortex_a5";
cpu_pmu->map_event = armv7_a5_map_event;
- cpu_pmu->pmu.attr_groups = armv7_pmuv1_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv7_pmuv1_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv7_pmu_format_attr_group;
return armv7_probe_num_events(cpu_pmu);
}
@@ -1236,7 +1233,10 @@
cpu_pmu->name = "armv7_cortex_a15";
cpu_pmu->map_event = armv7_a15_map_event;
cpu_pmu->set_event_filter = armv7pmu_set_event_filter;
- cpu_pmu->pmu.attr_groups = armv7_pmuv2_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv7_pmuv2_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv7_pmu_format_attr_group;
return armv7_probe_num_events(cpu_pmu);
}
@@ -1246,7 +1246,10 @@
cpu_pmu->name = "armv7_cortex_a7";
cpu_pmu->map_event = armv7_a7_map_event;
cpu_pmu->set_event_filter = armv7pmu_set_event_filter;
- cpu_pmu->pmu.attr_groups = armv7_pmuv2_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv7_pmuv2_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv7_pmu_format_attr_group;
return armv7_probe_num_events(cpu_pmu);
}
@@ -1256,7 +1259,10 @@
cpu_pmu->name = "armv7_cortex_a12";
cpu_pmu->map_event = armv7_a12_map_event;
cpu_pmu->set_event_filter = armv7pmu_set_event_filter;
- cpu_pmu->pmu.attr_groups = armv7_pmuv2_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv7_pmuv2_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv7_pmu_format_attr_group;
return armv7_probe_num_events(cpu_pmu);
}
@@ -1264,7 +1270,10 @@
{
int ret = armv7_a12_pmu_init(cpu_pmu);
cpu_pmu->name = "armv7_cortex_a17";
- cpu_pmu->pmu.attr_groups = armv7_pmuv2_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv7_pmuv2_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv7_pmu_format_attr_group;
return ret;
}
diff --git a/arch/arm/kernel/vdso.c b/arch/arm/kernel/vdso.c
index 994e971..a0affd1 100644
--- a/arch/arm/kernel/vdso.c
+++ b/arch/arm/kernel/vdso.c
@@ -270,7 +270,7 @@
if (!IS_ENABLED(CONFIG_ARM_ARCH_TIMER))
return false;
- if (strcmp(tk->tkr_mono.clock->name, "arch_sys_counter") != 0)
+ if (!tk->tkr_mono.clock->archdata.vdso_direct)
return false;
return true;
diff --git a/arch/arm64/Kconfig b/arch/arm64/Kconfig
index bc3f00f..17c14a1d 100644
--- a/arch/arm64/Kconfig
+++ b/arch/arm64/Kconfig
@@ -4,6 +4,7 @@
select ACPI_GENERIC_GSI if ACPI
select ACPI_REDUCED_HARDWARE_ONLY if ACPI
select ACPI_MCFG if ACPI
+ select ARCH_CLOCKSOURCE_DATA
select ARCH_HAS_DEVMEM_IS_ALLOWED
select ARCH_HAS_ACPI_TABLE_UPGRADE if ACPI
select ARCH_HAS_ATOMIC64_DEC_IF_POSITIVE
@@ -102,10 +103,8 @@
select NO_BOOTMEM
select OF
select OF_EARLY_FLATTREE
- select OF_NUMA if NUMA && OF
select OF_RESERVED_MEM
select PCI_ECAM if ACPI
- select PERF_USE_VMALLOC
select POWER_RESET
select POWER_SUPPLY
select SPARSE_IRQ
@@ -122,6 +121,9 @@
config MMU
def_bool y
+config DEBUG_RODATA
+ def_bool y
+
config ARM64_PAGE_SHIFT
int
default 16 if ARM64_64K_PAGES
@@ -415,18 +417,13 @@
config ARM64_ERRATUM_843419
bool "Cortex-A53: 843419: A load or store might access an incorrect address"
- depends on MODULES
default y
- select ARM64_MODULE_CMODEL_LARGE
+ select ARM64_MODULE_CMODEL_LARGE if MODULES
help
- This option builds kernel modules using the large memory model in
- order to avoid the use of the ADRP instruction, which can cause
- a subsequent memory access to use an incorrect address on Cortex-A53
- parts up to r0p4.
-
- Note that the kernel itself must be linked with a version of ld
- which fixes potentially affected ADRP instructions through the
- use of veneers.
+ This option links the kernel with '--fix-cortex-a53-843419' and
+ builds modules using the large memory model in order to avoid the use
+ of the ADRP instruction, which can cause a subsequent memory access
+ to use an incorrect address on Cortex-A53 parts up to r0p4.
If unsure, say Y.
@@ -582,7 +579,8 @@
# Common NUMA Features
config NUMA
bool "Numa Memory Allocation and Scheduler Support"
- depends on SMP
+ select ACPI_NUMA if ACPI
+ select OF_NUMA
help
Enable NUMA (Non Uniform Memory Access) support.
@@ -603,11 +601,18 @@
def_bool y
depends on NUMA
+config HAVE_SETUP_PER_CPU_AREA
+ def_bool y
+ depends on NUMA
+
+config NEED_PER_CPU_EMBED_FIRST_CHUNK
+ def_bool y
+ depends on NUMA
+
source kernel/Kconfig.preempt
source kernel/Kconfig.hz
config ARCH_SUPPORTS_DEBUG_PAGEALLOC
- depends on !HIBERNATION
def_bool y
config ARCH_HAS_HOLES_MEMORYMODEL
diff --git a/arch/arm64/Kconfig.debug b/arch/arm64/Kconfig.debug
index 0cc758c..b661fe7 100644
--- a/arch/arm64/Kconfig.debug
+++ b/arch/arm64/Kconfig.debug
@@ -49,16 +49,6 @@
If in doubt, say Y.
-config DEBUG_RODATA
- bool "Make kernel text and rodata read-only"
- default y
- help
- If this is set, kernel text and rodata will be made read-only. This
- is to help catch accidental or malicious attempts to change the
- kernel's executable code.
-
- If in doubt, say Y.
-
config DEBUG_ALIGN_RODATA
depends on DEBUG_RODATA
bool "Align linker sections up to SECTION_SIZE"
diff --git a/arch/arm64/Kconfig.platforms b/arch/arm64/Kconfig.platforms
index be5d824..4a4318b 100644
--- a/arch/arm64/Kconfig.platforms
+++ b/arch/arm64/Kconfig.platforms
@@ -159,7 +159,6 @@
select CLKSRC_MMIO
select CLKSRC_OF
select GENERIC_CLOCKEVENTS
- select HAVE_CLK
select PINCTRL
select RESET_CONTROLLER
help
diff --git a/arch/arm64/Makefile b/arch/arm64/Makefile
index 5b54f8c..ab51aed 100644
--- a/arch/arm64/Makefile
+++ b/arch/arm64/Makefile
@@ -18,6 +18,14 @@
LDFLAGS_vmlinux += -pie -Bsymbolic
endif
+ifeq ($(CONFIG_ARM64_ERRATUM_843419),y)
+ ifeq ($(call ld-option, --fix-cortex-a53-843419),)
+$(warning ld does not support --fix-cortex-a53-843419; kernel may be susceptible to erratum)
+ else
+LDFLAGS_vmlinux += --fix-cortex-a53-843419
+ endif
+endif
+
KBUILD_DEFCONFIG := defconfig
# Check for binutils support for specific extensions
@@ -38,10 +46,12 @@
KBUILD_CPPFLAGS += -mbig-endian
AS += -EB
LD += -EB
+UTS_MACHINE := aarch64_be
else
KBUILD_CPPFLAGS += -mlittle-endian
AS += -EL
LD += -EL
+UTS_MACHINE := aarch64
endif
CHECKFLAGS += -D__aarch64__
diff --git a/arch/arm64/crypto/aes-glue.c b/arch/arm64/crypto/aes-glue.c
index 5c88804..6b2aa0f 100644
--- a/arch/arm64/crypto/aes-glue.c
+++ b/arch/arm64/crypto/aes-glue.c
@@ -216,7 +216,7 @@
err = blkcipher_walk_done(desc, &walk,
walk.nbytes % AES_BLOCK_SIZE);
}
- if (nbytes) {
+ if (walk.nbytes % AES_BLOCK_SIZE) {
u8 *tdst = walk.dst.virt.addr + blocks * AES_BLOCK_SIZE;
u8 *tsrc = walk.src.virt.addr + blocks * AES_BLOCK_SIZE;
u8 __aligned(8) tail[AES_BLOCK_SIZE];
diff --git a/arch/arm64/include/asm/Kbuild b/arch/arm64/include/asm/Kbuild
index f43d2c4..44e1d7f 100644
--- a/arch/arm64/include/asm/Kbuild
+++ b/arch/arm64/include/asm/Kbuild
@@ -1,4 +1,3 @@
-generic-y += bug.h
generic-y += bugs.h
generic-y += clkdev.h
generic-y += cputime.h
@@ -10,7 +9,6 @@
generic-y += early_ioremap.h
generic-y += emergency-restart.h
generic-y += errno.h
-generic-y += ftrace.h
generic-y += hw_irq.h
generic-y += ioctl.h
generic-y += ioctls.h
@@ -27,12 +25,10 @@
generic-y += msgbuf.h
generic-y += msi.h
generic-y += mutex.h
-generic-y += pci.h
generic-y += poll.h
generic-y += preempt.h
generic-y += resource.h
generic-y += rwsem.h
-generic-y += sections.h
generic-y += segment.h
generic-y += sembuf.h
generic-y += serial.h
@@ -45,7 +41,6 @@
generic-y += switch_to.h
generic-y += termbits.h
generic-y += termios.h
-generic-y += topology.h
generic-y += trace_clock.h
generic-y += types.h
generic-y += unaligned.h
diff --git a/arch/arm64/include/asm/acpi.h b/arch/arm64/include/asm/acpi.h
index 5420cb0..e517088 100644
--- a/arch/arm64/include/asm/acpi.h
+++ b/arch/arm64/include/asm/acpi.h
@@ -12,7 +12,7 @@
#ifndef _ASM_ACPI_H
#define _ASM_ACPI_H
-#include <linux/mm.h>
+#include <linux/memblock.h>
#include <linux/psci.h>
#include <asm/cputype.h>
@@ -32,7 +32,11 @@
static inline void __iomem *acpi_os_ioremap(acpi_physical_address phys,
acpi_size size)
{
- if (!page_is_ram(phys >> PAGE_SHIFT))
+ /*
+ * EFI's reserve_regions() call adds memory with the WB attribute
+ * to memblock via early_init_dt_add_memory_arch().
+ */
+ if (!memblock_is_memory(phys))
return ioremap(phys, size);
return ioremap_cache(phys, size);
diff --git a/arch/arm64/include/asm/alternative.h b/arch/arm64/include/asm/alternative.h
index 8746ff6..55101bd 100644
--- a/arch/arm64/include/asm/alternative.h
+++ b/arch/arm64/include/asm/alternative.h
@@ -2,6 +2,7 @@
#define __ASM_ALTERNATIVE_H
#include <asm/cpufeature.h>
+#include <asm/insn.h>
#ifndef __ASSEMBLY__
@@ -90,24 +91,15 @@
.endm
/*
- * Begin an alternative code sequence.
+ * Alternative sequences
*
- * The code that follows this macro will be assembled and linked as
- * normal. There are no restrictions on this code.
- */
-.macro alternative_if_not cap
- .pushsection .altinstructions, "a"
- altinstruction_entry 661f, 663f, \cap, 662f-661f, 664f-663f
- .popsection
-661:
-.endm
-
-/*
- * Provide the alternative code sequence.
+ * The code for the case where the capability is not present will be
+ * assembled and linked as normal. There are no restrictions on this
+ * code.
*
- * The code that follows this macro is assembled into a special
- * section to be used for dynamic patching. Code that follows this
- * macro must:
+ * The code for the case where the capability is present will be
+ * assembled into a special section to be used for dynamic patching.
+ * Code for that case must:
*
* 1. Be exactly the same length (in bytes) as the default code
* sequence.
@@ -116,8 +108,38 @@
* alternative sequence it is defined in (branches into an
* alternative sequence are not fixed up).
*/
+
+/*
+ * Begin an alternative code sequence.
+ */
+.macro alternative_if_not cap
+ .set .Lasm_alt_mode, 0
+ .pushsection .altinstructions, "a"
+ altinstruction_entry 661f, 663f, \cap, 662f-661f, 664f-663f
+ .popsection
+661:
+.endm
+
+.macro alternative_if cap
+ .set .Lasm_alt_mode, 1
+ .pushsection .altinstructions, "a"
+ altinstruction_entry 663f, 661f, \cap, 664f-663f, 662f-661f
+ .popsection
+ .pushsection .altinstr_replacement, "ax"
+ .align 2 /* So GAS knows label 661 is suitably aligned */
+661:
+.endm
+
+/*
+ * Provide the other half of the alternative code sequence.
+ */
.macro alternative_else
-662: .pushsection .altinstr_replacement, "ax"
+662:
+ .if .Lasm_alt_mode==0
+ .pushsection .altinstr_replacement, "ax"
+ .else
+ .popsection
+ .endif
663:
.endm
@@ -125,11 +147,25 @@
* Complete an alternative code sequence.
*/
.macro alternative_endif
-664: .popsection
+664:
+ .if .Lasm_alt_mode==0
+ .popsection
+ .endif
.org . - (664b-663b) + (662b-661b)
.org . - (662b-661b) + (664b-663b)
.endm
+/*
+ * Provides a trivial alternative or default sequence consisting solely
+ * of NOPs. The number of NOPs is chosen automatically to match the
+ * previous case.
+ */
+.macro alternative_else_nop_endif
+alternative_else
+ nops (662b-661b) / AARCH64_INSN_SIZE
+alternative_endif
+.endm
+
#define _ALTERNATIVE_CFG(insn1, insn2, cap, cfg, ...) \
alternative_insn insn1, insn2, cap, IS_ENABLED(cfg)
diff --git a/arch/arm64/include/asm/arch_timer.h b/arch/arm64/include/asm/arch_timer.h
index fbe0ca3..eaa5bbe 100644
--- a/arch/arm64/include/asm/arch_timer.h
+++ b/arch/arm64/include/asm/arch_timer.h
@@ -20,13 +20,55 @@
#define __ASM_ARCH_TIMER_H
#include <asm/barrier.h>
+#include <asm/sysreg.h>
#include <linux/bug.h>
#include <linux/init.h>
+#include <linux/jump_label.h>
#include <linux/types.h>
#include <clocksource/arm_arch_timer.h>
+#if IS_ENABLED(CONFIG_FSL_ERRATUM_A008585)
+extern struct static_key_false arch_timer_read_ool_enabled;
+#define needs_fsl_a008585_workaround() \
+ static_branch_unlikely(&arch_timer_read_ool_enabled)
+#else
+#define needs_fsl_a008585_workaround() false
+#endif
+
+u32 __fsl_a008585_read_cntp_tval_el0(void);
+u32 __fsl_a008585_read_cntv_tval_el0(void);
+u64 __fsl_a008585_read_cntvct_el0(void);
+
+/*
+ * The number of retries is an arbitrary value well beyond the highest number
+ * of iterations the loop has been observed to take.
+ */
+#define __fsl_a008585_read_reg(reg) ({ \
+ u64 _old, _new; \
+ int _retries = 200; \
+ \
+ do { \
+ _old = read_sysreg(reg); \
+ _new = read_sysreg(reg); \
+ _retries--; \
+ } while (unlikely(_old != _new) && _retries); \
+ \
+ WARN_ON_ONCE(!_retries); \
+ _new; \
+})
+
+#define arch_timer_reg_read_stable(reg) \
+({ \
+ u64 _val; \
+ if (needs_fsl_a008585_workaround()) \
+ _val = __fsl_a008585_read_##reg(); \
+ else \
+ _val = read_sysreg(reg); \
+ _val; \
+})
+
/*
* These register accessors are marked inline so the compiler can
* nicely work out which register we want, and chuck away the rest of
@@ -38,19 +80,19 @@
if (access == ARCH_TIMER_PHYS_ACCESS) {
switch (reg) {
case ARCH_TIMER_REG_CTRL:
- asm volatile("msr cntp_ctl_el0, %0" : : "r" (val));
+ write_sysreg(val, cntp_ctl_el0);
break;
case ARCH_TIMER_REG_TVAL:
- asm volatile("msr cntp_tval_el0, %0" : : "r" (val));
+ write_sysreg(val, cntp_tval_el0);
break;
}
} else if (access == ARCH_TIMER_VIRT_ACCESS) {
switch (reg) {
case ARCH_TIMER_REG_CTRL:
- asm volatile("msr cntv_ctl_el0, %0" : : "r" (val));
+ write_sysreg(val, cntv_ctl_el0);
break;
case ARCH_TIMER_REG_TVAL:
- asm volatile("msr cntv_tval_el0, %0" : : "r" (val));
+ write_sysreg(val, cntv_tval_el0);
break;
}
}
@@ -61,48 +103,38 @@
static __always_inline
u32 arch_timer_reg_read_cp15(int access, enum arch_timer_reg reg)
{
- u32 val;
-
if (access == ARCH_TIMER_PHYS_ACCESS) {
switch (reg) {
case ARCH_TIMER_REG_CTRL:
- asm volatile("mrs %0, cntp_ctl_el0" : "=r" (val));
- break;
+ return read_sysreg(cntp_ctl_el0);
case ARCH_TIMER_REG_TVAL:
- asm volatile("mrs %0, cntp_tval_el0" : "=r" (val));
- break;
+ return arch_timer_reg_read_stable(cntp_tval_el0);
}
} else if (access == ARCH_TIMER_VIRT_ACCESS) {
switch (reg) {
case ARCH_TIMER_REG_CTRL:
- asm volatile("mrs %0, cntv_ctl_el0" : "=r" (val));
- break;
+ return read_sysreg(cntv_ctl_el0);
case ARCH_TIMER_REG_TVAL:
- asm volatile("mrs %0, cntv_tval_el0" : "=r" (val));
- break;
+ return arch_timer_reg_read_stable(cntv_tval_el0);
}
}
- return val;
+ BUG();
}
static inline u32 arch_timer_get_cntfrq(void)
{
- u32 val;
- asm volatile("mrs %0, cntfrq_el0" : "=r" (val));
- return val;
+ return read_sysreg(cntfrq_el0);
}
static inline u32 arch_timer_get_cntkctl(void)
{
- u32 cntkctl;
- asm volatile("mrs %0, cntkctl_el1" : "=r" (cntkctl));
- return cntkctl;
+ return read_sysreg(cntkctl_el1);
}
static inline void arch_timer_set_cntkctl(u32 cntkctl)
{
- asm volatile("msr cntkctl_el1, %0" : : "r" (cntkctl));
+ write_sysreg(cntkctl, cntkctl_el1);
}
static inline u64 arch_counter_get_cntpct(void)
@@ -116,12 +148,8 @@
static inline u64 arch_counter_get_cntvct(void)
{
- u64 cval;
-
isb();
- asm volatile("mrs %0, cntvct_el0" : "=r" (cval));
-
- return cval;
+ return arch_timer_reg_read_stable(cntvct_el0);
}
static inline int arch_timer_arch_init(void)
diff --git a/arch/arm64/include/asm/assembler.h b/arch/arm64/include/asm/assembler.h
index d5025c6..28bfe61 100644
--- a/arch/arm64/include/asm/assembler.h
+++ b/arch/arm64/include/asm/assembler.h
@@ -87,6 +87,15 @@
.endm
/*
+ * NOP sequence
+ */
+ .macro nops, num
+ .rept \num
+ nop
+ .endr
+ .endm
+
+/*
* Emit an entry into the exception table
*/
.macro _asm_extable, from, to
@@ -216,11 +225,26 @@
.macro mmid, rd, rn
ldr \rd, [\rn, #MM_CONTEXT_ID]
.endm
+/*
+ * read_ctr - read CTR_EL0. If the system has mismatched
+ * cache line sizes, provide the system wide safe value
+ * from arm64_ftr_reg_ctrel0.sys_val
+ */
+ .macro read_ctr, reg
+alternative_if_not ARM64_MISMATCHED_CACHE_LINE_SIZE
+ mrs \reg, ctr_el0 // read CTR
+ nop
+alternative_else
+ ldr_l \reg, arm64_ftr_reg_ctrel0 + ARM64_FTR_SYSVAL
+alternative_endif
+ .endm
+
/*
- * dcache_line_size - get the minimum D-cache line size from the CTR register.
+ * raw_dcache_line_size - get the minimum D-cache line size on this CPU
+ * from the CTR register.
*/
- .macro dcache_line_size, reg, tmp
+ .macro raw_dcache_line_size, reg, tmp
mrs \tmp, ctr_el0 // read CTR
ubfm \tmp, \tmp, #16, #19 // cache line size encoding
mov \reg, #4 // bytes per word
@@ -228,9 +252,20 @@
.endm
/*
- * icache_line_size - get the minimum I-cache line size from the CTR register.
+ * dcache_line_size - get the safe D-cache line size across all CPUs
*/
- .macro icache_line_size, reg, tmp
+ .macro dcache_line_size, reg, tmp
+ read_ctr \tmp
+ ubfm \tmp, \tmp, #16, #19 // cache line size encoding
+ mov \reg, #4 // bytes per word
+ lsl \reg, \reg, \tmp // actual cache line size
+ .endm
+
+/*
+ * raw_icache_line_size - get the minimum I-cache line size on this CPU
+ * from the CTR register.
+ */
+ .macro raw_icache_line_size, reg, tmp
mrs \tmp, ctr_el0 // read CTR
and \tmp, \tmp, #0xf // cache line size encoding
mov \reg, #4 // bytes per word
@@ -238,6 +273,16 @@
.endm
/*
+ * icache_line_size - get the safe I-cache line size across all CPUs
+ */
+ .macro icache_line_size, reg, tmp
+ read_ctr \tmp
+ and \tmp, \tmp, #0xf // cache line size encoding
+ mov \reg, #4 // bytes per word
+ lsl \reg, \reg, \tmp // actual cache line size
+ .endm
+
+/*
* tcr_set_idmap_t0sz - update TCR.T0SZ so that we can load the ID map
*/
.macro tcr_set_idmap_t0sz, valreg, tmpreg
diff --git a/arch/arm64/include/asm/atomic_lse.h b/arch/arm64/include/asm/atomic_lse.h
index b5890be..7457ce0 100644
--- a/arch/arm64/include/asm/atomic_lse.h
+++ b/arch/arm64/include/asm/atomic_lse.h
@@ -86,8 +86,8 @@
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
- " nop\n" \
- __LL_SC_ATOMIC(add_return##name), \
+ __LL_SC_ATOMIC(add_return##name) \
+ __nops(1), \
/* LSE atomics */ \
" ldadd" #mb " %w[i], w30, %[v]\n" \
" add %w[i], %w[i], w30") \
@@ -112,8 +112,8 @@
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
- " nop\n"
- __LL_SC_ATOMIC(and),
+ __LL_SC_ATOMIC(and)
+ __nops(1),
/* LSE atomics */
" mvn %w[i], %w[i]\n"
" stclr %w[i], %[v]")
@@ -130,8 +130,8 @@
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
- " nop\n" \
- __LL_SC_ATOMIC(fetch_and##name), \
+ __LL_SC_ATOMIC(fetch_and##name) \
+ __nops(1), \
/* LSE atomics */ \
" mvn %w[i], %w[i]\n" \
" ldclr" #mb " %w[i], %w[i], %[v]") \
@@ -156,8 +156,8 @@
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
- " nop\n"
- __LL_SC_ATOMIC(sub),
+ __LL_SC_ATOMIC(sub)
+ __nops(1),
/* LSE atomics */
" neg %w[i], %w[i]\n"
" stadd %w[i], %[v]")
@@ -174,9 +174,8 @@
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
- " nop\n" \
__LL_SC_ATOMIC(sub_return##name) \
- " nop", \
+ __nops(2), \
/* LSE atomics */ \
" neg %w[i], %w[i]\n" \
" ldadd" #mb " %w[i], w30, %[v]\n" \
@@ -203,8 +202,8 @@
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
- " nop\n" \
- __LL_SC_ATOMIC(fetch_sub##name), \
+ __LL_SC_ATOMIC(fetch_sub##name) \
+ __nops(1), \
/* LSE atomics */ \
" neg %w[i], %w[i]\n" \
" ldadd" #mb " %w[i], %w[i], %[v]") \
@@ -284,8 +283,8 @@
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
- " nop\n" \
- __LL_SC_ATOMIC64(add_return##name), \
+ __LL_SC_ATOMIC64(add_return##name) \
+ __nops(1), \
/* LSE atomics */ \
" ldadd" #mb " %[i], x30, %[v]\n" \
" add %[i], %[i], x30") \
@@ -310,8 +309,8 @@
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
- " nop\n"
- __LL_SC_ATOMIC64(and),
+ __LL_SC_ATOMIC64(and)
+ __nops(1),
/* LSE atomics */
" mvn %[i], %[i]\n"
" stclr %[i], %[v]")
@@ -328,8 +327,8 @@
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
- " nop\n" \
- __LL_SC_ATOMIC64(fetch_and##name), \
+ __LL_SC_ATOMIC64(fetch_and##name) \
+ __nops(1), \
/* LSE atomics */ \
" mvn %[i], %[i]\n" \
" ldclr" #mb " %[i], %[i], %[v]") \
@@ -354,8 +353,8 @@
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
- " nop\n"
- __LL_SC_ATOMIC64(sub),
+ __LL_SC_ATOMIC64(sub)
+ __nops(1),
/* LSE atomics */
" neg %[i], %[i]\n"
" stadd %[i], %[v]")
@@ -372,9 +371,8 @@
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
- " nop\n" \
__LL_SC_ATOMIC64(sub_return##name) \
- " nop", \
+ __nops(2), \
/* LSE atomics */ \
" neg %[i], %[i]\n" \
" ldadd" #mb " %[i], x30, %[v]\n" \
@@ -401,8 +399,8 @@
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
- " nop\n" \
- __LL_SC_ATOMIC64(fetch_sub##name), \
+ __LL_SC_ATOMIC64(fetch_sub##name) \
+ __nops(1), \
/* LSE atomics */ \
" neg %[i], %[i]\n" \
" ldadd" #mb " %[i], %[i], %[v]") \
@@ -426,13 +424,8 @@
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
- " nop\n"
__LL_SC_ATOMIC64(dec_if_positive)
- " nop\n"
- " nop\n"
- " nop\n"
- " nop\n"
- " nop",
+ __nops(6),
/* LSE atomics */
"1: ldr x30, %[v]\n"
" subs %[ret], x30, #1\n"
@@ -464,9 +457,8 @@
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
- " nop\n" \
- __LL_SC_CMPXCHG(name) \
- " nop", \
+ __LL_SC_CMPXCHG(name) \
+ __nops(2), \
/* LSE atomics */ \
" mov " #w "30, %" #w "[old]\n" \
" cas" #mb #sz "\t" #w "30, %" #w "[new], %[v]\n" \
@@ -517,10 +509,8 @@
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
- " nop\n" \
- " nop\n" \
- " nop\n" \
- __LL_SC_CMPXCHG_DBL(name), \
+ __LL_SC_CMPXCHG_DBL(name) \
+ __nops(3), \
/* LSE atomics */ \
" casp" #mb "\t%[old1], %[old2], %[new1], %[new2], %[v]\n"\
" eor %[old1], %[old1], %[oldval1]\n" \
diff --git a/arch/arm64/include/asm/barrier.h b/arch/arm64/include/asm/barrier.h
index 4eea7f6..4e0497f 100644
--- a/arch/arm64/include/asm/barrier.h
+++ b/arch/arm64/include/asm/barrier.h
@@ -20,6 +20,9 @@
#ifndef __ASSEMBLY__
+#define __nops(n) ".rept " #n "\nnop\n.endr\n"
+#define nops(n) asm volatile(__nops(n))
+
#define sev() asm volatile("sev" : : : "memory")
#define wfe() asm volatile("wfe" : : : "memory")
#define wfi() asm volatile("wfi" : : : "memory")
diff --git a/arch/arm64/include/asm/cacheflush.h b/arch/arm64/include/asm/cacheflush.h
index c64268d..2e5fb97 100644
--- a/arch/arm64/include/asm/cacheflush.h
+++ b/arch/arm64/include/asm/cacheflush.h
@@ -68,6 +68,7 @@
extern void flush_cache_range(struct vm_area_struct *vma, unsigned long start, unsigned long end);
extern void flush_icache_range(unsigned long start, unsigned long end);
extern void __flush_dcache_area(void *addr, size_t len);
+extern void __clean_dcache_area_poc(void *addr, size_t len);
extern void __clean_dcache_area_pou(void *addr, size_t len);
extern long __flush_cache_user_range(unsigned long start, unsigned long end);
@@ -85,7 +86,7 @@
*/
extern void __dma_map_area(const void *, size_t, int);
extern void __dma_unmap_area(const void *, size_t, int);
-extern void __dma_flush_range(const void *, const void *);
+extern void __dma_flush_area(const void *, size_t);
/*
* Copy user data from/to a page which is mapped into a different
diff --git a/arch/arm64/include/asm/clocksource.h b/arch/arm64/include/asm/clocksource.h
new file mode 100644
index 0000000..0b350a7
--- /dev/null
+++ b/arch/arm64/include/asm/clocksource.h
@@ -0,0 +1,8 @@
+#ifndef _ASM_CLOCKSOURCE_H
+#define _ASM_CLOCKSOURCE_H
+
+struct arch_clocksource_data {
+ bool vdso_direct; /* Usable for direct VDSO access? */
+};
+
+#endif
diff --git a/arch/arm64/include/asm/cmpxchg.h b/arch/arm64/include/asm/cmpxchg.h
index bd86a79..91b26d2 100644
--- a/arch/arm64/include/asm/cmpxchg.h
+++ b/arch/arm64/include/asm/cmpxchg.h
@@ -43,10 +43,8 @@
" cbnz %w1, 1b\n" \
" " #mb, \
/* LSE atomics */ \
- " nop\n" \
- " nop\n" \
" swp" #acq_lse #rel #sz "\t%" #w "3, %" #w "0, %2\n" \
- " nop\n" \
+ __nops(3) \
" " #nop_lse) \
: "=&r" (ret), "=&r" (tmp), "+Q" (*(u8 *)ptr) \
: "r" (x) \
diff --git a/arch/arm64/include/asm/cpufeature.h b/arch/arm64/include/asm/cpufeature.h
index 7099f26..758d74f 100644
--- a/arch/arm64/include/asm/cpufeature.h
+++ b/arch/arm64/include/asm/cpufeature.h
@@ -9,6 +9,8 @@
#ifndef __ASM_CPUFEATURE_H
#define __ASM_CPUFEATURE_H
+#include <linux/jump_label.h>
+
#include <asm/hwcap.h>
#include <asm/sysreg.h>
@@ -37,8 +39,9 @@
#define ARM64_WORKAROUND_CAVIUM_27456 12
#define ARM64_HAS_32BIT_EL0 13
#define ARM64_HYP_OFFSET_LOW 14
+#define ARM64_MISMATCHED_CACHE_LINE_SIZE 15
-#define ARM64_NCAPS 15
+#define ARM64_NCAPS 16
#ifndef __ASSEMBLY__
@@ -63,7 +66,7 @@
enum ftr_type type;
u8 shift;
u8 width;
- s64 safe_val; /* safe value for discrete features */
+ s64 safe_val; /* safe value for FTR_EXACT features */
};
/*
@@ -72,13 +75,14 @@
* @sys_val Safe value across the CPUs (system view)
*/
struct arm64_ftr_reg {
- u32 sys_id;
- const char *name;
- u64 strict_mask;
- u64 sys_val;
- struct arm64_ftr_bits *ftr_bits;
+ const char *name;
+ u64 strict_mask;
+ u64 sys_val;
+ const struct arm64_ftr_bits *ftr_bits;
};
+extern struct arm64_ftr_reg arm64_ftr_reg_ctrel0;
+
/* scope of capability check */
enum {
SCOPE_SYSTEM,
@@ -109,6 +113,7 @@
};
extern DECLARE_BITMAP(cpu_hwcaps, ARM64_NCAPS);
+extern struct static_key_false cpu_hwcap_keys[ARM64_NCAPS];
bool this_cpu_has_cap(unsigned int cap);
@@ -121,16 +126,21 @@
{
if (num >= ARM64_NCAPS)
return false;
- return test_bit(num, cpu_hwcaps);
+ if (__builtin_constant_p(num))
+ return static_branch_unlikely(&cpu_hwcap_keys[num]);
+ else
+ return test_bit(num, cpu_hwcaps);
}
static inline void cpus_set_cap(unsigned int num)
{
- if (num >= ARM64_NCAPS)
+ if (num >= ARM64_NCAPS) {
pr_warn("Attempt to set an illegal CPU capability (%d >= %d)\n",
num, ARM64_NCAPS);
- else
+ } else {
__set_bit(num, cpu_hwcaps);
+ static_branch_enable(&cpu_hwcap_keys[num]);
+ }
}
static inline int __attribute_const__
@@ -157,7 +167,7 @@
return cpuid_feature_extract_unsigned_field_width(features, field, 4);
}
-static inline u64 arm64_ftr_mask(struct arm64_ftr_bits *ftrp)
+static inline u64 arm64_ftr_mask(const struct arm64_ftr_bits *ftrp)
{
return (u64)GENMASK(ftrp->shift + ftrp->width - 1, ftrp->shift);
}
@@ -170,7 +180,7 @@
cpuid_feature_extract_unsigned_field(features, field);
}
-static inline s64 arm64_ftr_value(struct arm64_ftr_bits *ftrp, u64 val)
+static inline s64 arm64_ftr_value(const struct arm64_ftr_bits *ftrp, u64 val)
{
return (s64)cpuid_feature_extract_field(val, ftrp->shift, ftrp->sign);
}
@@ -193,11 +203,11 @@
void update_cpu_capabilities(const struct arm64_cpu_capabilities *caps,
const char *info);
void enable_cpu_capabilities(const struct arm64_cpu_capabilities *caps);
-void check_local_cpu_errata(void);
-void __init enable_errata_workarounds(void);
+void check_local_cpu_capabilities(void);
-void verify_local_cpu_errata(void);
-void verify_local_cpu_capabilities(void);
+void update_cpu_errata_workarounds(void);
+void __init enable_errata_workarounds(void);
+void verify_local_cpu_errata_workarounds(void);
u64 read_system_reg(u32 id);
diff --git a/arch/arm64/include/asm/cputype.h b/arch/arm64/include/asm/cputype.h
index 9d9fd4b..26a68dd 100644
--- a/arch/arm64/include/asm/cputype.h
+++ b/arch/arm64/include/asm/cputype.h
@@ -93,11 +93,7 @@
#include <asm/sysreg.h>
-#define read_cpuid(reg) ({ \
- u64 __val; \
- asm("mrs_s %0, " __stringify(SYS_ ## reg) : "=r" (__val)); \
- __val; \
-})
+#define read_cpuid(reg) read_sysreg_s(SYS_ ## reg)
/*
* The CPU ID never changes at run time, so we might as well tell the
diff --git a/arch/arm64/include/asm/dcc.h b/arch/arm64/include/asm/dcc.h
index 65e0190..836b056 100644
--- a/arch/arm64/include/asm/dcc.h
+++ b/arch/arm64/include/asm/dcc.h
@@ -21,21 +21,16 @@
#define __ASM_DCC_H
#include <asm/barrier.h>
+#include <asm/sysreg.h>
static inline u32 __dcc_getstatus(void)
{
- u32 ret;
-
- asm volatile("mrs %0, mdccsr_el0" : "=r" (ret));
-
- return ret;
+ return read_sysreg(mdccsr_el0);
}
static inline char __dcc_getchar(void)
{
- char c;
-
- asm volatile("mrs %0, dbgdtrrx_el0" : "=r" (c));
+ char c = read_sysreg(dbgdtrrx_el0);
isb();
return c;
@@ -47,8 +42,7 @@
* The typecast is to make absolutely certain that 'c' is
* zero-extended.
*/
- asm volatile("msr dbgdtrtx_el0, %0"
- : : "r" ((unsigned long)(unsigned char)c));
+ write_sysreg((unsigned char)c, dbgdtrtx_el0);
isb();
}
diff --git a/arch/arm64/include/asm/debug-monitors.h b/arch/arm64/include/asm/debug-monitors.h
index 4b6b3f7..b71420a 100644
--- a/arch/arm64/include/asm/debug-monitors.h
+++ b/arch/arm64/include/asm/debug-monitors.h
@@ -61,8 +61,6 @@
#define AARCH64_BREAK_KGDB_DYN_DBG \
(AARCH64_BREAK_MON | (KGDB_DYN_DBG_BRK_IMM << 5))
-#define KGDB_DYN_BRK_INS_BYTE(x) \
- ((AARCH64_BREAK_KGDB_DYN_DBG >> (8 * (x))) & 0xff)
#define CACHE_FLUSH_IS_SAFE 1
diff --git a/arch/arm64/include/asm/esr.h b/arch/arm64/include/asm/esr.h
index f772e15..d14c478 100644
--- a/arch/arm64/include/asm/esr.h
+++ b/arch/arm64/include/asm/esr.h
@@ -78,6 +78,23 @@
#define ESR_ELx_IL (UL(1) << 25)
#define ESR_ELx_ISS_MASK (ESR_ELx_IL - 1)
+
+/* ISS field definitions shared by different classes */
+#define ESR_ELx_WNR (UL(1) << 6)
+
+/* Shared ISS field definitions for Data/Instruction aborts */
+#define ESR_ELx_EA (UL(1) << 9)
+#define ESR_ELx_S1PTW (UL(1) << 7)
+
+/* Shared ISS fault status code(IFSC/DFSC) for Data/Instruction aborts */
+#define ESR_ELx_FSC (0x3F)
+#define ESR_ELx_FSC_TYPE (0x3C)
+#define ESR_ELx_FSC_EXTABT (0x10)
+#define ESR_ELx_FSC_ACCESS (0x08)
+#define ESR_ELx_FSC_FAULT (0x04)
+#define ESR_ELx_FSC_PERM (0x0C)
+
+/* ISS field definitions for Data Aborts */
#define ESR_ELx_ISV (UL(1) << 24)
#define ESR_ELx_SAS_SHIFT (22)
#define ESR_ELx_SAS (UL(3) << ESR_ELx_SAS_SHIFT)
@@ -86,16 +103,9 @@
#define ESR_ELx_SRT_MASK (UL(0x1F) << ESR_ELx_SRT_SHIFT)
#define ESR_ELx_SF (UL(1) << 15)
#define ESR_ELx_AR (UL(1) << 14)
-#define ESR_ELx_EA (UL(1) << 9)
#define ESR_ELx_CM (UL(1) << 8)
-#define ESR_ELx_S1PTW (UL(1) << 7)
-#define ESR_ELx_WNR (UL(1) << 6)
-#define ESR_ELx_FSC (0x3F)
-#define ESR_ELx_FSC_TYPE (0x3C)
-#define ESR_ELx_FSC_EXTABT (0x10)
-#define ESR_ELx_FSC_ACCESS (0x08)
-#define ESR_ELx_FSC_FAULT (0x04)
-#define ESR_ELx_FSC_PERM (0x0C)
+
+/* ISS field definitions for exceptions taken in to Hyp */
#define ESR_ELx_CV (UL(1) << 24)
#define ESR_ELx_COND_SHIFT (20)
#define ESR_ELx_COND_MASK (UL(0xF) << ESR_ELx_COND_SHIFT)
@@ -109,6 +119,62 @@
((ESR_ELx_EC_BRK64 << ESR_ELx_EC_SHIFT) | ESR_ELx_IL | \
((imm) & 0xffff))
+/* ISS field definitions for System instruction traps */
+#define ESR_ELx_SYS64_ISS_RES0_SHIFT 22
+#define ESR_ELx_SYS64_ISS_RES0_MASK (UL(0x7) << ESR_ELx_SYS64_ISS_RES0_SHIFT)
+#define ESR_ELx_SYS64_ISS_DIR_MASK 0x1
+#define ESR_ELx_SYS64_ISS_DIR_READ 0x1
+#define ESR_ELx_SYS64_ISS_DIR_WRITE 0x0
+
+#define ESR_ELx_SYS64_ISS_RT_SHIFT 5
+#define ESR_ELx_SYS64_ISS_RT_MASK (UL(0x1f) << ESR_ELx_SYS64_ISS_RT_SHIFT)
+#define ESR_ELx_SYS64_ISS_CRM_SHIFT 1
+#define ESR_ELx_SYS64_ISS_CRM_MASK (UL(0xf) << ESR_ELx_SYS64_ISS_CRM_SHIFT)
+#define ESR_ELx_SYS64_ISS_CRN_SHIFT 10
+#define ESR_ELx_SYS64_ISS_CRN_MASK (UL(0xf) << ESR_ELx_SYS64_ISS_CRN_SHIFT)
+#define ESR_ELx_SYS64_ISS_OP1_SHIFT 14
+#define ESR_ELx_SYS64_ISS_OP1_MASK (UL(0x7) << ESR_ELx_SYS64_ISS_OP1_SHIFT)
+#define ESR_ELx_SYS64_ISS_OP2_SHIFT 17
+#define ESR_ELx_SYS64_ISS_OP2_MASK (UL(0x7) << ESR_ELx_SYS64_ISS_OP2_SHIFT)
+#define ESR_ELx_SYS64_ISS_OP0_SHIFT 20
+#define ESR_ELx_SYS64_ISS_OP0_MASK (UL(0x3) << ESR_ELx_SYS64_ISS_OP0_SHIFT)
+#define ESR_ELx_SYS64_ISS_SYS_MASK (ESR_ELx_SYS64_ISS_OP0_MASK | \
+ ESR_ELx_SYS64_ISS_OP1_MASK | \
+ ESR_ELx_SYS64_ISS_OP2_MASK | \
+ ESR_ELx_SYS64_ISS_CRN_MASK | \
+ ESR_ELx_SYS64_ISS_CRM_MASK)
+#define ESR_ELx_SYS64_ISS_SYS_VAL(op0, op1, op2, crn, crm) \
+ (((op0) << ESR_ELx_SYS64_ISS_OP0_SHIFT) | \
+ ((op1) << ESR_ELx_SYS64_ISS_OP1_SHIFT) | \
+ ((op2) << ESR_ELx_SYS64_ISS_OP2_SHIFT) | \
+ ((crn) << ESR_ELx_SYS64_ISS_CRN_SHIFT) | \
+ ((crm) << ESR_ELx_SYS64_ISS_CRM_SHIFT))
+
+#define ESR_ELx_SYS64_ISS_SYS_OP_MASK (ESR_ELx_SYS64_ISS_SYS_MASK | \
+ ESR_ELx_SYS64_ISS_DIR_MASK)
+/*
+ * User space cache operations have the following sysreg encoding
+ * in System instructions.
+ * op0=1, op1=3, op2=1, crn=7, crm={ 5, 10, 11, 14 }, WRITE (L=0)
+ */
+#define ESR_ELx_SYS64_ISS_CRM_DC_CIVAC 14
+#define ESR_ELx_SYS64_ISS_CRM_DC_CVAU 11
+#define ESR_ELx_SYS64_ISS_CRM_DC_CVAC 10
+#define ESR_ELx_SYS64_ISS_CRM_IC_IVAU 5
+
+#define ESR_ELx_SYS64_ISS_EL0_CACHE_OP_MASK (ESR_ELx_SYS64_ISS_OP0_MASK | \
+ ESR_ELx_SYS64_ISS_OP1_MASK | \
+ ESR_ELx_SYS64_ISS_OP2_MASK | \
+ ESR_ELx_SYS64_ISS_CRN_MASK | \
+ ESR_ELx_SYS64_ISS_DIR_MASK)
+#define ESR_ELx_SYS64_ISS_EL0_CACHE_OP_VAL \
+ (ESR_ELx_SYS64_ISS_SYS_VAL(1, 3, 1, 7, 0) | \
+ ESR_ELx_SYS64_ISS_DIR_WRITE)
+
+#define ESR_ELx_SYS64_ISS_SYS_CTR ESR_ELx_SYS64_ISS_SYS_VAL(3, 3, 1, 0, 0)
+#define ESR_ELx_SYS64_ISS_SYS_CTR_READ (ESR_ELx_SYS64_ISS_SYS_CTR | \
+ ESR_ELx_SYS64_ISS_DIR_READ)
+
#ifndef __ASSEMBLY__
#include <asm/types.h>
diff --git a/arch/arm64/include/asm/hw_breakpoint.h b/arch/arm64/include/asm/hw_breakpoint.h
index 115ea2a..9510ace 100644
--- a/arch/arm64/include/asm/hw_breakpoint.h
+++ b/arch/arm64/include/asm/hw_breakpoint.h
@@ -18,6 +18,7 @@
#include <asm/cputype.h>
#include <asm/cpufeature.h>
+#include <asm/sysreg.h>
#include <asm/virt.h>
#ifdef __KERNEL__
@@ -98,18 +99,18 @@
#define AARCH64_DBG_REG_WCR (AARCH64_DBG_REG_WVR + ARM_MAX_WRP)
/* Debug register names. */
-#define AARCH64_DBG_REG_NAME_BVR "bvr"
-#define AARCH64_DBG_REG_NAME_BCR "bcr"
-#define AARCH64_DBG_REG_NAME_WVR "wvr"
-#define AARCH64_DBG_REG_NAME_WCR "wcr"
+#define AARCH64_DBG_REG_NAME_BVR bvr
+#define AARCH64_DBG_REG_NAME_BCR bcr
+#define AARCH64_DBG_REG_NAME_WVR wvr
+#define AARCH64_DBG_REG_NAME_WCR wcr
/* Accessor macros for the debug registers. */
#define AARCH64_DBG_READ(N, REG, VAL) do {\
- asm volatile("mrs %0, dbg" REG #N "_el1" : "=r" (VAL));\
+ VAL = read_sysreg(dbg##REG##N##_el1);\
} while (0)
#define AARCH64_DBG_WRITE(N, REG, VAL) do {\
- asm volatile("msr dbg" REG #N "_el1, %0" :: "r" (VAL));\
+ write_sysreg(VAL, dbg##REG##N##_el1);\
} while (0)
struct task_struct;
@@ -141,8 +142,6 @@
}
#endif
-extern struct pmu perf_ops_bp;
-
/* Determine number of BRP registers available. */
static inline int get_num_brps(void)
{
diff --git a/arch/arm64/include/asm/insn.h b/arch/arm64/include/asm/insn.h
index 1dbaa90..bc85366 100644
--- a/arch/arm64/include/asm/insn.h
+++ b/arch/arm64/include/asm/insn.h
@@ -246,7 +246,8 @@
static __always_inline u32 aarch64_insn_get_##abbr##_value(void) \
{ return (val); }
-__AARCH64_INSN_FUNCS(adr_adrp, 0x1F000000, 0x10000000)
+__AARCH64_INSN_FUNCS(adr, 0x9F000000, 0x10000000)
+__AARCH64_INSN_FUNCS(adrp, 0x9F000000, 0x90000000)
__AARCH64_INSN_FUNCS(prfm_lit, 0xFF000000, 0xD8000000)
__AARCH64_INSN_FUNCS(str_reg, 0x3FE0EC00, 0x38206800)
__AARCH64_INSN_FUNCS(ldr_reg, 0x3FE0EC00, 0x38606800)
@@ -318,6 +319,11 @@
bool aarch64_insn_is_nop(u32 insn);
bool aarch64_insn_is_branch_imm(u32 insn);
+static inline bool aarch64_insn_is_adr_adrp(u32 insn)
+{
+ return aarch64_insn_is_adr(insn) || aarch64_insn_is_adrp(insn);
+}
+
int aarch64_insn_read(void *addr, u32 *insnp);
int aarch64_insn_write(void *addr, u32 insn);
enum aarch64_insn_encoding_class aarch64_get_insn_class(u32 insn);
@@ -398,6 +404,9 @@
int aarch64_insn_patch_text_sync(void *addrs[], u32 insns[], int cnt);
int aarch64_insn_patch_text(void *addrs[], u32 insns[], int cnt);
+s32 aarch64_insn_adrp_get_offset(u32 insn);
+u32 aarch64_insn_adrp_set_offset(u32 insn, s32 offset);
+
bool aarch32_insn_is_wide(u32 insn);
#define A32_RN_OFFSET 16
diff --git a/arch/arm64/include/asm/io.h b/arch/arm64/include/asm/io.h
index 9b6e408..0bba427 100644
--- a/arch/arm64/include/asm/io.h
+++ b/arch/arm64/include/asm/io.h
@@ -40,25 +40,25 @@
#define __raw_writeb __raw_writeb
static inline void __raw_writeb(u8 val, volatile void __iomem *addr)
{
- asm volatile("strb %w0, [%1]" : : "r" (val), "r" (addr));
+ asm volatile("strb %w0, [%1]" : : "rZ" (val), "r" (addr));
}
#define __raw_writew __raw_writew
static inline void __raw_writew(u16 val, volatile void __iomem *addr)
{
- asm volatile("strh %w0, [%1]" : : "r" (val), "r" (addr));
+ asm volatile("strh %w0, [%1]" : : "rZ" (val), "r" (addr));
}
#define __raw_writel __raw_writel
static inline void __raw_writel(u32 val, volatile void __iomem *addr)
{
- asm volatile("str %w0, [%1]" : : "r" (val), "r" (addr));
+ asm volatile("str %w0, [%1]" : : "rZ" (val), "r" (addr));
}
#define __raw_writeq __raw_writeq
static inline void __raw_writeq(u64 val, volatile void __iomem *addr)
{
- asm volatile("str %0, [%1]" : : "r" (val), "r" (addr));
+ asm volatile("str %x0, [%1]" : : "rZ" (val), "r" (addr));
}
#define __raw_readb __raw_readb
@@ -184,17 +184,6 @@
#define iowrite32be(v,p) ({ __iowmb(); __raw_writel((__force __u32)cpu_to_be32(v), p); })
#define iowrite64be(v,p) ({ __iowmb(); __raw_writeq((__force __u64)cpu_to_be64(v), p); })
-/*
- * Convert a physical pointer to a virtual kernel pointer for /dev/mem
- * access
- */
-#define xlate_dev_mem_ptr(p) __va(p)
-
-/*
- * Convert a virtual cached pointer to an uncached pointer
- */
-#define xlate_dev_kmem_ptr(p) p
-
#include <asm-generic/io.h>
/*
diff --git a/arch/arm64/include/asm/kvm_mmu.h b/arch/arm64/include/asm/kvm_mmu.h
index b6bb834..dff1098 100644
--- a/arch/arm64/include/asm/kvm_mmu.h
+++ b/arch/arm64/include/asm/kvm_mmu.h
@@ -99,14 +99,10 @@
.macro kern_hyp_va reg
alternative_if_not ARM64_HAS_VIRT_HOST_EXTN
and \reg, \reg, #HYP_PAGE_OFFSET_HIGH_MASK
-alternative_else
- nop
-alternative_endif
-alternative_if_not ARM64_HYP_OFFSET_LOW
- nop
-alternative_else
+alternative_else_nop_endif
+alternative_if ARM64_HYP_OFFSET_LOW
and \reg, \reg, #HYP_PAGE_OFFSET_LOW_MASK
-alternative_endif
+alternative_else_nop_endif
.endm
#else
diff --git a/arch/arm64/include/asm/memory.h b/arch/arm64/include/asm/memory.h
index 31b7322..ba62df8 100644
--- a/arch/arm64/include/asm/memory.h
+++ b/arch/arm64/include/asm/memory.h
@@ -214,7 +214,7 @@
#ifndef CONFIG_SPARSEMEM_VMEMMAP
#define virt_to_page(kaddr) pfn_to_page(__pa(kaddr) >> PAGE_SHIFT)
-#define virt_addr_valid(kaddr) pfn_valid(__pa(kaddr) >> PAGE_SHIFT)
+#define _virt_addr_valid(kaddr) pfn_valid(__pa(kaddr) >> PAGE_SHIFT)
#else
#define __virt_to_pgoff(kaddr) (((u64)(kaddr) & ~PAGE_OFFSET) / PAGE_SIZE * sizeof(struct page))
#define __page_to_voff(kaddr) (((u64)(page) & ~VMEMMAP_START) * PAGE_SIZE / sizeof(struct page))
@@ -222,11 +222,15 @@
#define page_to_virt(page) ((void *)((__page_to_voff(page)) | PAGE_OFFSET))
#define virt_to_page(vaddr) ((struct page *)((__virt_to_pgoff(vaddr)) | VMEMMAP_START))
-#define virt_addr_valid(kaddr) pfn_valid((((u64)(kaddr) & ~PAGE_OFFSET) \
+#define _virt_addr_valid(kaddr) pfn_valid((((u64)(kaddr) & ~PAGE_OFFSET) \
+ PHYS_OFFSET) >> PAGE_SHIFT)
#endif
#endif
+#define _virt_addr_is_linear(kaddr) (((u64)(kaddr)) >= PAGE_OFFSET)
+#define virt_addr_valid(kaddr) (_virt_addr_is_linear(kaddr) && \
+ _virt_addr_valid(kaddr))
+
#include <asm-generic/memory_model.h>
#endif
diff --git a/arch/arm64/include/asm/mmu_context.h b/arch/arm64/include/asm/mmu_context.h
index b1892a0..a501853 100644
--- a/arch/arm64/include/asm/mmu_context.h
+++ b/arch/arm64/include/asm/mmu_context.h
@@ -27,22 +27,17 @@
#include <asm-generic/mm_hooks.h>
#include <asm/cputype.h>
#include <asm/pgtable.h>
+#include <asm/sysreg.h>
#include <asm/tlbflush.h>
-#ifdef CONFIG_PID_IN_CONTEXTIDR
static inline void contextidr_thread_switch(struct task_struct *next)
{
- asm(
- " msr contextidr_el1, %0\n"
- " isb"
- :
- : "r" (task_pid_nr(next)));
+ if (!IS_ENABLED(CONFIG_PID_IN_CONTEXTIDR))
+ return;
+
+ write_sysreg(task_pid_nr(next), contextidr_el1);
+ isb();
}
-#else
-static inline void contextidr_thread_switch(struct task_struct *next)
-{
-}
-#endif
/*
* Set TTBR0 to empty_zero_page. No translations will be possible via TTBR0.
@@ -51,11 +46,8 @@
{
unsigned long ttbr = virt_to_phys(empty_zero_page);
- asm(
- " msr ttbr0_el1, %0 // set TTBR0\n"
- " isb"
- :
- : "r" (ttbr));
+ write_sysreg(ttbr, ttbr0_el1);
+ isb();
}
/*
@@ -81,13 +73,11 @@
if (!__cpu_uses_extended_idmap())
return;
- asm volatile (
- " mrs %0, tcr_el1 ;"
- " bfi %0, %1, %2, %3 ;"
- " msr tcr_el1, %0 ;"
- " isb"
- : "=&r" (tcr)
- : "r"(t0sz), "I"(TCR_T0SZ_OFFSET), "I"(TCR_TxSZ_WIDTH));
+ tcr = read_sysreg(tcr_el1);
+ tcr &= ~TCR_T0SZ_MASK;
+ tcr |= t0sz << TCR_T0SZ_OFFSET;
+ write_sysreg(tcr, tcr_el1);
+ isb();
}
#define cpu_set_default_tcr_t0sz() __cpu_set_tcr_t0sz(TCR_T0SZ(VA_BITS))
diff --git a/arch/arm64/include/asm/pgtable-hwdef.h b/arch/arm64/include/asm/pgtable-hwdef.h
index c3ae239..eb0c2bd 100644
--- a/arch/arm64/include/asm/pgtable-hwdef.h
+++ b/arch/arm64/include/asm/pgtable-hwdef.h
@@ -208,6 +208,7 @@
#define TCR_T1SZ(x) ((UL(64) - (x)) << TCR_T1SZ_OFFSET)
#define TCR_TxSZ(x) (TCR_T0SZ(x) | TCR_T1SZ(x))
#define TCR_TxSZ_WIDTH 6
+#define TCR_T0SZ_MASK (((UL(1) << TCR_TxSZ_WIDTH) - 1) << TCR_T0SZ_OFFSET)
#define TCR_IRGN0_SHIFT 8
#define TCR_IRGN0_MASK (UL(3) << TCR_IRGN0_SHIFT)
diff --git a/arch/arm64/include/asm/pgtable-prot.h b/arch/arm64/include/asm/pgtable-prot.h
index 39f5252..2142c77 100644
--- a/arch/arm64/include/asm/pgtable-prot.h
+++ b/arch/arm64/include/asm/pgtable-prot.h
@@ -70,12 +70,13 @@
#define PAGE_COPY_EXEC __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_PXN)
#define PAGE_READONLY __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_PXN | PTE_UXN)
#define PAGE_READONLY_EXEC __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_PXN)
+#define PAGE_EXECONLY __pgprot(_PAGE_DEFAULT | PTE_NG | PTE_PXN)
#define __P000 PAGE_NONE
#define __P001 PAGE_READONLY
#define __P010 PAGE_COPY
#define __P011 PAGE_COPY
-#define __P100 PAGE_READONLY_EXEC
+#define __P100 PAGE_EXECONLY
#define __P101 PAGE_READONLY_EXEC
#define __P110 PAGE_COPY_EXEC
#define __P111 PAGE_COPY_EXEC
@@ -84,7 +85,7 @@
#define __S001 PAGE_READONLY
#define __S010 PAGE_SHARED
#define __S011 PAGE_SHARED
-#define __S100 PAGE_READONLY_EXEC
+#define __S100 PAGE_EXECONLY
#define __S101 PAGE_READONLY_EXEC
#define __S110 PAGE_SHARED_EXEC
#define __S111 PAGE_SHARED_EXEC
diff --git a/arch/arm64/include/asm/pgtable.h b/arch/arm64/include/asm/pgtable.h
index e20bd43..ffbb9a5 100644
--- a/arch/arm64/include/asm/pgtable.h
+++ b/arch/arm64/include/asm/pgtable.h
@@ -73,7 +73,7 @@
#define pte_write(pte) (!!(pte_val(pte) & PTE_WRITE))
#define pte_exec(pte) (!(pte_val(pte) & PTE_UXN))
#define pte_cont(pte) (!!(pte_val(pte) & PTE_CONT))
-#define pte_user(pte) (!!(pte_val(pte) & PTE_USER))
+#define pte_ng(pte) (!!(pte_val(pte) & PTE_NG))
#ifdef CONFIG_ARM64_HW_AFDBM
#define pte_hw_dirty(pte) (pte_write(pte) && !(pte_val(pte) & PTE_RDONLY))
@@ -84,8 +84,8 @@
#define pte_dirty(pte) (pte_sw_dirty(pte) || pte_hw_dirty(pte))
#define pte_valid(pte) (!!(pte_val(pte) & PTE_VALID))
-#define pte_valid_not_user(pte) \
- ((pte_val(pte) & (PTE_VALID | PTE_USER)) == PTE_VALID)
+#define pte_valid_global(pte) \
+ ((pte_val(pte) & (PTE_VALID | PTE_NG)) == PTE_VALID)
#define pte_valid_young(pte) \
((pte_val(pte) & (PTE_VALID | PTE_AF)) == (PTE_VALID | PTE_AF))
@@ -155,6 +155,16 @@
return clear_pte_bit(pte, __pgprot(PTE_CONT));
}
+static inline pte_t pte_clear_rdonly(pte_t pte)
+{
+ return clear_pte_bit(pte, __pgprot(PTE_RDONLY));
+}
+
+static inline pte_t pte_mkpresent(pte_t pte)
+{
+ return set_pte_bit(pte, __pgprot(PTE_VALID));
+}
+
static inline pmd_t pmd_mkcont(pmd_t pmd)
{
return __pmd(pmd_val(pmd) | PMD_SECT_CONT);
@@ -168,7 +178,7 @@
* Only if the new pte is valid and kernel, otherwise TLB maintenance
* or update_mmu_cache() have the necessary barriers.
*/
- if (pte_valid_not_user(pte)) {
+ if (pte_valid_global(pte)) {
dsb(ishst);
isb();
}
@@ -202,7 +212,7 @@
pte_val(pte) &= ~PTE_RDONLY;
else
pte_val(pte) |= PTE_RDONLY;
- if (pte_user(pte) && pte_exec(pte) && !pte_special(pte))
+ if (pte_ng(pte) && pte_exec(pte) && !pte_special(pte))
__sync_icache_dcache(pte, addr);
}
diff --git a/arch/arm64/include/asm/processor.h b/arch/arm64/include/asm/processor.h
index ace0a96..df2e53d 100644
--- a/arch/arm64/include/asm/processor.h
+++ b/arch/arm64/include/asm/processor.h
@@ -37,7 +37,6 @@
#include <asm/ptrace.h>
#include <asm/types.h>
-#ifdef __KERNEL__
#define STACK_TOP_MAX TASK_SIZE_64
#ifdef CONFIG_COMPAT
#define AARCH32_VECTORS_BASE 0xffff0000
@@ -49,7 +48,6 @@
extern phys_addr_t arm64_dma_phys_limit;
#define ARCH_LOW_ADDRESS_LIMIT (arm64_dma_phys_limit - 1)
-#endif /* __KERNEL__ */
struct debug_info {
/* Have we suspended stepping by a debugger? */
diff --git a/arch/arm64/include/asm/sections.h b/arch/arm64/include/asm/sections.h
new file mode 100644
index 0000000..4e7e706
--- /dev/null
+++ b/arch/arm64/include/asm/sections.h
@@ -0,0 +1,30 @@
+/*
+ * Copyright (C) 2016 ARM Limited
+ *
+ * This program is free software; you can redistribute it and/or modify
+ * it under the terms of the GNU General Public License version 2 as
+ * published by the Free Software Foundation.
+ *
+ * This program is distributed in the hope that it will be useful,
+ * but WITHOUT ANY WARRANTY; without even the implied warranty of
+ * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ * GNU General Public License for more details.
+ *
+ * You should have received a copy of the GNU General Public License
+ * along with this program. If not, see <http://www.gnu.org/licenses/>.
+ */
+#ifndef __ASM_SECTIONS_H
+#define __ASM_SECTIONS_H
+
+#include <asm-generic/sections.h>
+
+extern char __alt_instructions[], __alt_instructions_end[];
+extern char __exception_text_start[], __exception_text_end[];
+extern char __hibernate_exit_text_start[], __hibernate_exit_text_end[];
+extern char __hyp_idmap_text_start[], __hyp_idmap_text_end[];
+extern char __hyp_text_start[], __hyp_text_end[];
+extern char __idmap_text_start[], __idmap_text_end[];
+extern char __irqentry_text_start[], __irqentry_text_end[];
+extern char __mmuoff_data_start[], __mmuoff_data_end[];
+
+#endif /* __ASM_SECTIONS_H */
diff --git a/arch/arm64/include/asm/spinlock.h b/arch/arm64/include/asm/spinlock.h
index 89206b5..cae331d 100644
--- a/arch/arm64/include/asm/spinlock.h
+++ b/arch/arm64/include/asm/spinlock.h
@@ -66,8 +66,7 @@
ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" stxr %w1, %w0, %2\n"
-" nop\n"
-" nop\n",
+ __nops(2),
/* LSE atomics */
" mov %w1, %w0\n"
" cas %w0, %w0, %2\n"
@@ -99,9 +98,7 @@
/* LSE atomics */
" mov %w2, %w5\n"
" ldadda %w2, %w0, %3\n"
-" nop\n"
-" nop\n"
-" nop\n"
+ __nops(3)
)
/* Did we get the lock? */
@@ -165,8 +162,8 @@
" stlrh %w1, %0",
/* LSE atomics */
" mov %w1, #1\n"
- " nop\n"
- " staddlh %w1, %0")
+ " staddlh %w1, %0\n"
+ __nops(1))
: "=Q" (lock->owner), "=&r" (tmp)
:
: "memory");
@@ -212,7 +209,7 @@
" cbnz %w0, 1b\n"
" stxr %w0, %w2, %1\n"
" cbnz %w0, 2b\n"
- " nop",
+ __nops(1),
/* LSE atomics */
"1: mov %w0, wzr\n"
"2: casa %w0, %w2, %1\n"
@@ -241,8 +238,7 @@
/* LSE atomics */
" mov %w0, wzr\n"
" casa %w0, %w2, %1\n"
- " nop\n"
- " nop")
+ __nops(2))
: "=&r" (tmp), "+Q" (rw->lock)
: "r" (0x80000000)
: "memory");
@@ -290,8 +286,8 @@
" add %w0, %w0, #1\n"
" tbnz %w0, #31, 1b\n"
" stxr %w1, %w0, %2\n"
- " nop\n"
- " cbnz %w1, 2b",
+ " cbnz %w1, 2b\n"
+ __nops(1),
/* LSE atomics */
"1: wfe\n"
"2: ldxr %w0, %2\n"
@@ -317,9 +313,8 @@
" cbnz %w1, 1b",
/* LSE atomics */
" movn %w0, #0\n"
- " nop\n"
- " nop\n"
- " staddl %w0, %2")
+ " staddl %w0, %2\n"
+ __nops(2))
: "=&r" (tmp), "=&r" (tmp2), "+Q" (rw->lock)
:
: "memory");
@@ -344,7 +339,7 @@
" tbnz %w1, #31, 1f\n"
" casa %w0, %w1, %2\n"
" sbc %w1, %w1, %w0\n"
- " nop\n"
+ __nops(1)
"1:")
: "=&r" (tmp), "=&r" (tmp2), "+Q" (rw->lock)
:
diff --git a/arch/arm64/include/asm/suspend.h b/arch/arm64/include/asm/suspend.h
index 024d623..b8a313f 100644
--- a/arch/arm64/include/asm/suspend.h
+++ b/arch/arm64/include/asm/suspend.h
@@ -47,4 +47,7 @@
int arch_hibernation_header_save(void *addr, unsigned int max_size);
int arch_hibernation_header_restore(void *addr);
+/* Used to resume on the CPU we hibernated on */
+int hibernate_resume_nonboot_cpu_disable(void);
+
#endif
diff --git a/arch/arm64/include/asm/sysreg.h b/arch/arm64/include/asm/sysreg.h
index cc06794..e8d46e8 100644
--- a/arch/arm64/include/asm/sysreg.h
+++ b/arch/arm64/include/asm/sysreg.h
@@ -100,6 +100,7 @@
/* SCTLR_EL1 specific flags. */
#define SCTLR_EL1_UCI (1 << 26)
#define SCTLR_EL1_SPAN (1 << 23)
+#define SCTLR_EL1_UCT (1 << 15)
#define SCTLR_EL1_SED (1 << 8)
#define SCTLR_EL1_CP15BEN (1 << 5)
@@ -253,16 +254,6 @@
" .endm\n"
);
-static inline void config_sctlr_el1(u32 clear, u32 set)
-{
- u32 val;
-
- asm volatile("mrs %0, sctlr_el1" : "=r" (val));
- val &= ~clear;
- val |= set;
- asm volatile("msr sctlr_el1, %0" : : "r" (val));
-}
-
/*
* Unlike read_cpuid, calls to read_sysreg are never expected to be
* optimized away or replaced with synthetic values.
@@ -273,12 +264,41 @@
__val; \
})
+/*
+ * The "Z" constraint normally means a zero immediate, but when combined with
+ * the "%x0" template means XZR.
+ */
#define write_sysreg(v, r) do { \
u64 __val = (u64)v; \
- asm volatile("msr " __stringify(r) ", %0" \
- : : "r" (__val)); \
+ asm volatile("msr " __stringify(r) ", %x0" \
+ : : "rZ" (__val)); \
} while (0)
+/*
+ * For registers without architectural names, or simply unsupported by
+ * GAS.
+ */
+#define read_sysreg_s(r) ({ \
+ u64 __val; \
+ asm volatile("mrs_s %0, " __stringify(r) : "=r" (__val)); \
+ __val; \
+})
+
+#define write_sysreg_s(v, r) do { \
+ u64 __val = (u64)v; \
+ asm volatile("msr_s " __stringify(r) ", %0" : : "rZ" (__val)); \
+} while (0)
+
+static inline void config_sctlr_el1(u32 clear, u32 set)
+{
+ u32 val;
+
+ val = read_sysreg(sctlr_el1);
+ val &= ~clear;
+ val |= set;
+ write_sysreg(val, sctlr_el1);
+}
+
#endif
#endif /* __ASM_SYSREG_H */
diff --git a/arch/arm64/include/asm/system_misc.h b/arch/arm64/include/asm/system_misc.h
index 57f110b..bc81243 100644
--- a/arch/arm64/include/asm/system_misc.h
+++ b/arch/arm64/include/asm/system_misc.h
@@ -56,12 +56,6 @@
__show_ratelimited; \
})
-#define UDBG_UNDEFINED (1 << 0)
-#define UDBG_SYSCALL (1 << 1)
-#define UDBG_BADABORT (1 << 2)
-#define UDBG_SEGV (1 << 3)
-#define UDBG_BUS (1 << 4)
-
#endif /* __ASSEMBLY__ */
#endif /* __ASM_SYSTEM_MISC_H */
diff --git a/arch/arm64/include/asm/thread_info.h b/arch/arm64/include/asm/thread_info.h
index abd64bd..e9ea5a6 100644
--- a/arch/arm64/include/asm/thread_info.h
+++ b/arch/arm64/include/asm/thread_info.h
@@ -75,6 +75,9 @@
/*
* struct thread_info can be accessed directly via sp_el0.
+ *
+ * We don't use read_sysreg() as we want the compiler to cache the value where
+ * possible.
*/
static inline struct thread_info *current_thread_info(void)
{
diff --git a/arch/arm64/include/asm/tlbflush.h b/arch/arm64/include/asm/tlbflush.h
index b460ae2..deab523 100644
--- a/arch/arm64/include/asm/tlbflush.h
+++ b/arch/arm64/include/asm/tlbflush.h
@@ -25,6 +25,24 @@
#include <asm/cputype.h>
/*
+ * Raw TLBI operations.
+ *
+ * Where necessary, use the __tlbi() macro to avoid asm()
+ * boilerplate. Drivers and most kernel code should use the TLB
+ * management routines in preference to the macro below.
+ *
+ * The macro can be used as __tlbi(op) or __tlbi(op, arg), depending
+ * on whether a particular TLBI operation takes an argument or
+ * not. The macros handles invoking the asm with or without the
+ * register argument as appropriate.
+ */
+#define __TLBI_0(op, arg) asm ("tlbi " #op)
+#define __TLBI_1(op, arg) asm ("tlbi " #op ", %0" : : "r" (arg))
+#define __TLBI_N(op, arg, n, ...) __TLBI_##n(op, arg)
+
+#define __tlbi(op, ...) __TLBI_N(op, ##__VA_ARGS__, 1, 0)
+
+/*
* TLB Management
* ==============
*
@@ -66,7 +84,7 @@
static inline void local_flush_tlb_all(void)
{
dsb(nshst);
- asm("tlbi vmalle1");
+ __tlbi(vmalle1);
dsb(nsh);
isb();
}
@@ -74,7 +92,7 @@
static inline void flush_tlb_all(void)
{
dsb(ishst);
- asm("tlbi vmalle1is");
+ __tlbi(vmalle1is);
dsb(ish);
isb();
}
@@ -84,7 +102,7 @@
unsigned long asid = ASID(mm) << 48;
dsb(ishst);
- asm("tlbi aside1is, %0" : : "r" (asid));
+ __tlbi(aside1is, asid);
dsb(ish);
}
@@ -94,7 +112,7 @@
unsigned long addr = uaddr >> 12 | (ASID(vma->vm_mm) << 48);
dsb(ishst);
- asm("tlbi vale1is, %0" : : "r" (addr));
+ __tlbi(vale1is, addr);
dsb(ish);
}
@@ -122,9 +140,9 @@
dsb(ishst);
for (addr = start; addr < end; addr += 1 << (PAGE_SHIFT - 12)) {
if (last_level)
- asm("tlbi vale1is, %0" : : "r"(addr));
+ __tlbi(vale1is, addr);
else
- asm("tlbi vae1is, %0" : : "r"(addr));
+ __tlbi(vae1is, addr);
}
dsb(ish);
}
@@ -149,7 +167,7 @@
dsb(ishst);
for (addr = start; addr < end; addr += 1 << (PAGE_SHIFT - 12))
- asm("tlbi vaae1is, %0" : : "r"(addr));
+ __tlbi(vaae1is, addr);
dsb(ish);
isb();
}
@@ -163,7 +181,7 @@
{
unsigned long addr = uaddr >> 12 | (ASID(mm) << 48);
- asm("tlbi vae1is, %0" : : "r" (addr));
+ __tlbi(vae1is, addr);
dsb(ish);
}
diff --git a/arch/arm64/include/asm/traps.h b/arch/arm64/include/asm/traps.h
index 9cd03f3..02e9035 100644
--- a/arch/arm64/include/asm/traps.h
+++ b/arch/arm64/include/asm/traps.h
@@ -19,6 +19,7 @@
#define __ASM_TRAP_H
#include <linux/list.h>
+#include <asm/sections.h>
struct pt_regs;
@@ -39,9 +40,6 @@
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
static inline int __in_irqentry_text(unsigned long ptr)
{
- extern char __irqentry_text_start[];
- extern char __irqentry_text_end[];
-
return ptr >= (unsigned long)&__irqentry_text_start &&
ptr < (unsigned long)&__irqentry_text_end;
}
@@ -54,8 +52,6 @@
static inline int in_exception_text(unsigned long ptr)
{
- extern char __exception_text_start[];
- extern char __exception_text_end[];
int in;
in = ptr >= (unsigned long)&__exception_text_start &&
diff --git a/arch/arm64/include/asm/virt.h b/arch/arm64/include/asm/virt.h
index 1788545..fea1073 100644
--- a/arch/arm64/include/asm/virt.h
+++ b/arch/arm64/include/asm/virt.h
@@ -45,6 +45,8 @@
#ifndef __ASSEMBLY__
#include <asm/ptrace.h>
+#include <asm/sections.h>
+#include <asm/sysreg.h>
/*
* __boot_cpu_mode records what mode CPUs were booted in.
@@ -75,10 +77,7 @@
static inline bool is_kernel_in_hyp_mode(void)
{
- u64 el;
-
- asm("mrs %0, CurrentEL" : "=r" (el));
- return el == CurrentEL_EL2;
+ return read_sysreg(CurrentEL) == CurrentEL_EL2;
}
#ifdef CONFIG_ARM64_VHE
@@ -87,14 +86,6 @@
static inline void verify_cpu_run_el(void) {}
#endif
-/* The section containing the hypervisor idmap text */
-extern char __hyp_idmap_text_start[];
-extern char __hyp_idmap_text_end[];
-
-/* The section containing the hypervisor text */
-extern char __hyp_text_start[];
-extern char __hyp_text_end[];
-
#endif /* __ASSEMBLY__ */
#endif /* ! __ASM__VIRT_H */
diff --git a/arch/arm64/kernel/Makefile b/arch/arm64/kernel/Makefile
index 14f7b65..7d66bba 100644
--- a/arch/arm64/kernel/Makefile
+++ b/arch/arm64/kernel/Makefile
@@ -10,6 +10,8 @@
CFLAGS_REMOVE_insn.o = -pg
CFLAGS_REMOVE_return_address.o = -pg
+CFLAGS_setup.o = -DUTS_MACHINE='"$(UTS_MACHINE)"'
+
# Object file lists.
arm64-obj-y := debug-monitors.o entry.o irq.o fpsimd.o \
entry-fpsimd.o process.o ptrace.o setup.o signal.o \
diff --git a/arch/arm64/kernel/acpi_numa.c b/arch/arm64/kernel/acpi_numa.c
index f85149c..f01fab6 100644
--- a/arch/arm64/kernel/acpi_numa.c
+++ b/arch/arm64/kernel/acpi_numa.c
@@ -105,8 +105,10 @@
int ret;
ret = acpi_numa_init();
- if (ret)
+ if (ret) {
+ pr_info("Failed to initialise from firmware\n");
return ret;
+ }
return srat_disabled() ? -EINVAL : 0;
}
diff --git a/arch/arm64/kernel/alternative.c b/arch/arm64/kernel/alternative.c
index d2ee1b2..06d650f 100644
--- a/arch/arm64/kernel/alternative.c
+++ b/arch/arm64/kernel/alternative.c
@@ -25,14 +25,13 @@
#include <asm/alternative.h>
#include <asm/cpufeature.h>
#include <asm/insn.h>
+#include <asm/sections.h>
#include <linux/stop_machine.h>
#define __ALT_PTR(a,f) (u32 *)((void *)&(a)->f + (a)->f)
#define ALT_ORIG_PTR(a) __ALT_PTR(a, orig_offset)
#define ALT_REPL_PTR(a) __ALT_PTR(a, alt_offset)
-extern struct alt_instr __alt_instructions[], __alt_instructions_end[];
-
struct alt_region {
struct alt_instr *begin;
struct alt_instr *end;
@@ -59,6 +58,8 @@
BUG();
}
+#define align_down(x, a) ((unsigned long)(x) & ~(((unsigned long)(a)) - 1))
+
static u32 get_alt_insn(struct alt_instr *alt, u32 *insnptr, u32 *altinsnptr)
{
u32 insn;
@@ -80,6 +81,25 @@
offset = target - (unsigned long)insnptr;
insn = aarch64_set_branch_offset(insn, offset);
}
+ } else if (aarch64_insn_is_adrp(insn)) {
+ s32 orig_offset, new_offset;
+ unsigned long target;
+
+ /*
+ * If we're replacing an adrp instruction, which uses PC-relative
+ * immediate addressing, adjust the offset to reflect the new
+ * PC. adrp operates on 4K aligned addresses.
+ */
+ orig_offset = aarch64_insn_adrp_get_offset(insn);
+ target = align_down(altinsnptr, SZ_4K) + orig_offset;
+ new_offset = target - align_down(insnptr, SZ_4K);
+ insn = aarch64_insn_adrp_set_offset(insn, new_offset);
+ } else if (aarch64_insn_uses_literal(insn)) {
+ /*
+ * Disallow patching unhandled instructions using PC relative
+ * literal addresses
+ */
+ BUG();
}
return insn;
@@ -124,8 +144,8 @@
{
static int patched = 0;
struct alt_region region = {
- .begin = __alt_instructions,
- .end = __alt_instructions_end,
+ .begin = (struct alt_instr *)__alt_instructions,
+ .end = (struct alt_instr *)__alt_instructions_end,
};
/* We always have a CPU 0 at this point (__init) */
diff --git a/arch/arm64/kernel/asm-offsets.c b/arch/arm64/kernel/asm-offsets.c
index 05070b7..4a2f0f0 100644
--- a/arch/arm64/kernel/asm-offsets.c
+++ b/arch/arm64/kernel/asm-offsets.c
@@ -23,6 +23,7 @@
#include <linux/dma-mapping.h>
#include <linux/kvm_host.h>
#include <linux/suspend.h>
+#include <asm/cpufeature.h>
#include <asm/thread_info.h>
#include <asm/memory.h>
#include <asm/smp_plat.h>
@@ -145,5 +146,6 @@
DEFINE(HIBERN_PBE_ORIG, offsetof(struct pbe, orig_address));
DEFINE(HIBERN_PBE_ADDR, offsetof(struct pbe, address));
DEFINE(HIBERN_PBE_NEXT, offsetof(struct pbe, next));
+ DEFINE(ARM64_FTR_SYSVAL, offsetof(struct arm64_ftr_reg, sys_val));
return 0;
}
diff --git a/arch/arm64/kernel/cacheinfo.c b/arch/arm64/kernel/cacheinfo.c
index b8629d5..9617301 100644
--- a/arch/arm64/kernel/cacheinfo.c
+++ b/arch/arm64/kernel/cacheinfo.c
@@ -39,7 +39,7 @@
if (level > MAX_CACHE_LEVEL)
return CACHE_TYPE_NOCACHE;
- asm volatile ("mrs %x0, clidr_el1" : "=r" (clidr));
+ clidr = read_sysreg(clidr_el1);
return CLIDR_CTYPE(clidr, level);
}
@@ -55,11 +55,9 @@
WARN_ON(preemptible());
- /* Put value into CSSELR */
- asm volatile("msr csselr_el1, %x0" : : "r" (csselr));
+ write_sysreg(csselr, csselr_el1);
isb();
- /* Read result out of CCSIDR */
- asm volatile("mrs %x0, ccsidr_el1" : "=r" (ccsidr));
+ ccsidr = read_sysreg(ccsidr_el1);
return ccsidr;
}
diff --git a/arch/arm64/kernel/cpu_errata.c b/arch/arm64/kernel/cpu_errata.c
index 82b0fc2..0150394 100644
--- a/arch/arm64/kernel/cpu_errata.c
+++ b/arch/arm64/kernel/cpu_errata.c
@@ -30,6 +30,21 @@
entry->midr_range_max);
}
+static bool
+has_mismatched_cache_line_size(const struct arm64_cpu_capabilities *entry,
+ int scope)
+{
+ WARN_ON(scope != SCOPE_LOCAL_CPU || preemptible());
+ return (read_cpuid_cachetype() & arm64_ftr_reg_ctrel0.strict_mask) !=
+ (arm64_ftr_reg_ctrel0.sys_val & arm64_ftr_reg_ctrel0.strict_mask);
+}
+
+static void cpu_enable_trap_ctr_access(void *__unused)
+{
+ /* Clear SCTLR_EL1.UCT */
+ config_sctlr_el1(SCTLR_EL1_UCT, 0);
+}
+
#define MIDR_RANGE(model, min, max) \
.def_scope = SCOPE_LOCAL_CPU, \
.matches = is_affected_midr_range, \
@@ -108,6 +123,13 @@
},
#endif
{
+ .desc = "Mismatched cache line size",
+ .capability = ARM64_MISMATCHED_CACHE_LINE_SIZE,
+ .matches = has_mismatched_cache_line_size,
+ .def_scope = SCOPE_LOCAL_CPU,
+ .enable = cpu_enable_trap_ctr_access,
+ },
+ {
}
};
@@ -116,7 +138,7 @@
* and the related information is freed soon after. If the new CPU requires
* an errata not detected at boot, fail this CPU.
*/
-void verify_local_cpu_errata(void)
+void verify_local_cpu_errata_workarounds(void)
{
const struct arm64_cpu_capabilities *caps = arm64_errata;
@@ -131,7 +153,7 @@
}
}
-void check_local_cpu_errata(void)
+void update_cpu_errata_workarounds(void)
{
update_cpu_capabilities(arm64_errata, "enabling workaround for");
}
diff --git a/arch/arm64/kernel/cpu_ops.c b/arch/arm64/kernel/cpu_ops.c
index c7cfb8f..e137cea 100644
--- a/arch/arm64/kernel/cpu_ops.c
+++ b/arch/arm64/kernel/cpu_ops.c
@@ -17,6 +17,7 @@
*/
#include <linux/acpi.h>
+#include <linux/cache.h>
#include <linux/errno.h>
#include <linux/of.h>
#include <linux/string.h>
@@ -28,7 +29,7 @@
extern const struct cpu_operations acpi_parking_protocol_ops;
extern const struct cpu_operations cpu_psci_ops;
-const struct cpu_operations *cpu_ops[NR_CPUS];
+const struct cpu_operations *cpu_ops[NR_CPUS] __ro_after_init;
static const struct cpu_operations *dt_supported_cpu_ops[] __initconst = {
&smp_spin_table_ops,
diff --git a/arch/arm64/kernel/cpufeature.c b/arch/arm64/kernel/cpufeature.c
index 62272ea..d577f26 100644
--- a/arch/arm64/kernel/cpufeature.c
+++ b/arch/arm64/kernel/cpufeature.c
@@ -46,6 +46,9 @@
DECLARE_BITMAP(cpu_hwcaps, ARM64_NCAPS);
+DEFINE_STATIC_KEY_ARRAY_FALSE(cpu_hwcap_keys, ARM64_NCAPS);
+EXPORT_SYMBOL(cpu_hwcap_keys);
+
#define __ARM64_FTR_BITS(SIGNED, STRICT, TYPE, SHIFT, WIDTH, SAFE_VAL) \
{ \
.sign = SIGNED, \
@@ -74,7 +77,7 @@
cpufeature_pan_not_uao(const struct arm64_cpu_capabilities *entry, int __unused);
-static struct arm64_ftr_bits ftr_id_aa64isar0[] = {
+static const struct arm64_ftr_bits ftr_id_aa64isar0[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 32, 32, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, ID_AA64ISAR0_RDM_SHIFT, 4, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 24, 4, 0),
@@ -87,7 +90,7 @@
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_id_aa64pfr0[] = {
+static const struct arm64_ftr_bits ftr_id_aa64pfr0[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 32, 32, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 28, 4, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, ID_AA64PFR0_GIC_SHIFT, 4, 0),
@@ -101,7 +104,7 @@
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_id_aa64mmfr0[] = {
+static const struct arm64_ftr_bits ftr_id_aa64mmfr0[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 32, 32, 0),
S_ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, ID_AA64MMFR0_TGRAN4_SHIFT, 4, ID_AA64MMFR0_TGRAN4_NI),
S_ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, ID_AA64MMFR0_TGRAN64_SHIFT, 4, ID_AA64MMFR0_TGRAN64_NI),
@@ -119,7 +122,7 @@
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_id_aa64mmfr1[] = {
+static const struct arm64_ftr_bits ftr_id_aa64mmfr1[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 32, 32, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, ID_AA64MMFR1_PAN_SHIFT, 4, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, ID_AA64MMFR1_LOR_SHIFT, 4, 0),
@@ -130,7 +133,7 @@
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_id_aa64mmfr2[] = {
+static const struct arm64_ftr_bits ftr_id_aa64mmfr2[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, ID_AA64MMFR2_LVA_SHIFT, 4, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, ID_AA64MMFR2_IESB_SHIFT, 4, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, ID_AA64MMFR2_LSM_SHIFT, 4, 0),
@@ -139,7 +142,7 @@
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_ctr[] = {
+static const struct arm64_ftr_bits ftr_ctr[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 31, 1, 1), /* RAO */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 28, 3, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_HIGHER_SAFE, 24, 4, 0), /* CWG */
@@ -147,15 +150,21 @@
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, 16, 4, 1), /* DminLine */
/*
* Linux can handle differing I-cache policies. Userspace JITs will
- * make use of *minLine
+ * make use of *minLine.
+ * If we have differing I-cache policies, report it as the weakest - AIVIVT.
*/
- ARM64_FTR_BITS(FTR_NONSTRICT, FTR_EXACT, 14, 2, 0), /* L1Ip */
+ ARM64_FTR_BITS(FTR_NONSTRICT, FTR_EXACT, 14, 2, ICACHE_POLICY_AIVIVT), /* L1Ip */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 4, 10, 0), /* RAZ */
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, 0, 4, 0), /* IminLine */
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_id_mmfr0[] = {
+struct arm64_ftr_reg arm64_ftr_reg_ctrel0 = {
+ .name = "SYS_CTR_EL0",
+ .ftr_bits = ftr_ctr
+};
+
+static const struct arm64_ftr_bits ftr_id_mmfr0[] = {
S_ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 28, 4, 0xf), /* InnerShr */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 24, 4, 0), /* FCSE */
ARM64_FTR_BITS(FTR_NONSTRICT, FTR_LOWER_SAFE, 20, 4, 0), /* AuxReg */
@@ -167,7 +176,7 @@
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_id_aa64dfr0[] = {
+static const struct arm64_ftr_bits ftr_id_aa64dfr0[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 32, 32, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, ID_AA64DFR0_CTX_CMPS_SHIFT, 4, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, ID_AA64DFR0_WRPS_SHIFT, 4, 0),
@@ -178,14 +187,14 @@
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_mvfr2[] = {
+static const struct arm64_ftr_bits ftr_mvfr2[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 8, 24, 0), /* RAZ */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 4, 4, 0), /* FPMisc */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 0, 4, 0), /* SIMDMisc */
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_dczid[] = {
+static const struct arm64_ftr_bits ftr_dczid[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 5, 27, 0), /* RAZ */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 4, 1, 1), /* DZP */
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, 0, 4, 0), /* BS */
@@ -193,7 +202,7 @@
};
-static struct arm64_ftr_bits ftr_id_isar5[] = {
+static const struct arm64_ftr_bits ftr_id_isar5[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, ID_ISAR5_RDM_SHIFT, 4, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 20, 4, 0), /* RAZ */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, ID_ISAR5_CRC32_SHIFT, 4, 0),
@@ -204,14 +213,14 @@
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_id_mmfr4[] = {
+static const struct arm64_ftr_bits ftr_id_mmfr4[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 8, 24, 0), /* RAZ */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 4, 4, 0), /* ac2 */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 0, 4, 0), /* RAZ */
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_id_pfr0[] = {
+static const struct arm64_ftr_bits ftr_id_pfr0[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 16, 16, 0), /* RAZ */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 12, 4, 0), /* State3 */
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 8, 4, 0), /* State2 */
@@ -220,7 +229,7 @@
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_id_dfr0[] = {
+static const struct arm64_ftr_bits ftr_id_dfr0[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, 28, 4, 0),
S_ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, 24, 4, 0xf), /* PerfMon */
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, 20, 4, 0),
@@ -238,7 +247,7 @@
* 0. Covers the following 32bit registers:
* id_isar[0-4], id_mmfr[1-3], id_pfr1, mvfr[0-1]
*/
-static struct arm64_ftr_bits ftr_generic_32bits[] = {
+static const struct arm64_ftr_bits ftr_generic_32bits[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, 28, 4, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, 24, 4, 0),
ARM64_FTR_BITS(FTR_STRICT, FTR_LOWER_SAFE, 20, 4, 0),
@@ -250,29 +259,32 @@
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_generic[] = {
+static const struct arm64_ftr_bits ftr_generic[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 0, 64, 0),
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_generic32[] = {
+static const struct arm64_ftr_bits ftr_generic32[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 0, 32, 0),
ARM64_FTR_END,
};
-static struct arm64_ftr_bits ftr_aa64raz[] = {
+static const struct arm64_ftr_bits ftr_aa64raz[] = {
ARM64_FTR_BITS(FTR_STRICT, FTR_EXACT, 0, 64, 0),
ARM64_FTR_END,
};
-#define ARM64_FTR_REG(id, table) \
- { \
- .sys_id = id, \
+#define ARM64_FTR_REG(id, table) { \
+ .sys_id = id, \
+ .reg = &(struct arm64_ftr_reg){ \
.name = #id, \
.ftr_bits = &((table)[0]), \
- }
+ }}
-static struct arm64_ftr_reg arm64_ftr_regs[] = {
+static const struct __ftr_reg_entry {
+ u32 sys_id;
+ struct arm64_ftr_reg *reg;
+} arm64_ftr_regs[] = {
/* Op1 = 0, CRn = 0, CRm = 1 */
ARM64_FTR_REG(SYS_ID_PFR0_EL1, ftr_id_pfr0),
@@ -315,7 +327,7 @@
ARM64_FTR_REG(SYS_ID_AA64MMFR2_EL1, ftr_id_aa64mmfr2),
/* Op1 = 3, CRn = 0, CRm = 0 */
- ARM64_FTR_REG(SYS_CTR_EL0, ftr_ctr),
+ { SYS_CTR_EL0, &arm64_ftr_reg_ctrel0 },
ARM64_FTR_REG(SYS_DCZID_EL0, ftr_dczid),
/* Op1 = 3, CRn = 14, CRm = 0 */
@@ -324,7 +336,7 @@
static int search_cmp_ftr_reg(const void *id, const void *regp)
{
- return (int)(unsigned long)id - (int)((const struct arm64_ftr_reg *)regp)->sys_id;
+ return (int)(unsigned long)id - (int)((const struct __ftr_reg_entry *)regp)->sys_id;
}
/*
@@ -339,14 +351,20 @@
*/
static struct arm64_ftr_reg *get_arm64_ftr_reg(u32 sys_id)
{
- return bsearch((const void *)(unsigned long)sys_id,
+ const struct __ftr_reg_entry *ret;
+
+ ret = bsearch((const void *)(unsigned long)sys_id,
arm64_ftr_regs,
ARRAY_SIZE(arm64_ftr_regs),
sizeof(arm64_ftr_regs[0]),
search_cmp_ftr_reg);
+ if (ret)
+ return ret->reg;
+ return NULL;
}
-static u64 arm64_ftr_set_value(struct arm64_ftr_bits *ftrp, s64 reg, s64 ftr_val)
+static u64 arm64_ftr_set_value(const struct arm64_ftr_bits *ftrp, s64 reg,
+ s64 ftr_val)
{
u64 mask = arm64_ftr_mask(ftrp);
@@ -355,7 +373,8 @@
return reg;
}
-static s64 arm64_ftr_safe_value(struct arm64_ftr_bits *ftrp, s64 new, s64 cur)
+static s64 arm64_ftr_safe_value(const struct arm64_ftr_bits *ftrp, s64 new,
+ s64 cur)
{
s64 ret = 0;
@@ -376,27 +395,13 @@
return ret;
}
-static int __init sort_cmp_ftr_regs(const void *a, const void *b)
-{
- return ((const struct arm64_ftr_reg *)a)->sys_id -
- ((const struct arm64_ftr_reg *)b)->sys_id;
-}
-
-static void __init swap_ftr_regs(void *a, void *b, int size)
-{
- struct arm64_ftr_reg tmp = *(struct arm64_ftr_reg *)a;
- *(struct arm64_ftr_reg *)a = *(struct arm64_ftr_reg *)b;
- *(struct arm64_ftr_reg *)b = tmp;
-}
-
static void __init sort_ftr_regs(void)
{
- /* Keep the array sorted so that we can do the binary search */
- sort(arm64_ftr_regs,
- ARRAY_SIZE(arm64_ftr_regs),
- sizeof(arm64_ftr_regs[0]),
- sort_cmp_ftr_regs,
- swap_ftr_regs);
+ int i;
+
+ /* Check that the array is sorted so that we can do the binary search */
+ for (i = 1; i < ARRAY_SIZE(arm64_ftr_regs); i++)
+ BUG_ON(arm64_ftr_regs[i].sys_id < arm64_ftr_regs[i - 1].sys_id);
}
/*
@@ -407,7 +412,7 @@
{
u64 val = 0;
u64 strict_mask = ~0x0ULL;
- struct arm64_ftr_bits *ftrp;
+ const struct arm64_ftr_bits *ftrp;
struct arm64_ftr_reg *reg = get_arm64_ftr_reg(sys_reg);
BUG_ON(!reg);
@@ -464,7 +469,7 @@
static void update_cpu_ftr_reg(struct arm64_ftr_reg *reg, u64 new)
{
- struct arm64_ftr_bits *ftrp;
+ const struct arm64_ftr_bits *ftrp;
for (ftrp = reg->ftr_bits; ftrp->width; ftrp++) {
s64 ftr_cur = arm64_ftr_value(ftrp, reg->sys_val);
@@ -1004,25 +1009,35 @@
* cannot do anything to fix it up and could cause unexpected failures. So
* we park the CPU.
*/
-void verify_local_cpu_capabilities(void)
+static void verify_local_cpu_capabilities(void)
{
-
- check_early_cpu_features();
-
- /*
- * If we haven't computed the system capabilities, there is nothing
- * to verify.
- */
- if (!sys_caps_initialised)
- return;
-
- verify_local_cpu_errata();
+ verify_local_cpu_errata_workarounds();
verify_local_cpu_features(arm64_features);
verify_local_elf_hwcaps(arm64_elf_hwcaps);
if (system_supports_32bit_el0())
verify_local_elf_hwcaps(compat_elf_hwcaps);
}
+void check_local_cpu_capabilities(void)
+{
+ /*
+ * All secondary CPUs should conform to the early CPU features
+ * in use by the kernel based on boot CPU.
+ */
+ check_early_cpu_features();
+
+ /*
+ * If we haven't finalised the system capabilities, this CPU gets
+ * a chance to update the errata work arounds.
+ * Otherwise, this CPU should verify that it has all the system
+ * advertised capabilities.
+ */
+ if (!sys_caps_initialised)
+ update_cpu_errata_workarounds();
+ else
+ verify_local_cpu_capabilities();
+}
+
static void __init setup_feature_capabilities(void)
{
update_cpu_capabilities(arm64_features, "detected feature:");
diff --git a/arch/arm64/kernel/cpuinfo.c b/arch/arm64/kernel/cpuinfo.c
index ed1b84f..b3d5b3e 100644
--- a/arch/arm64/kernel/cpuinfo.c
+++ b/arch/arm64/kernel/cpuinfo.c
@@ -363,8 +363,6 @@
}
cpuinfo_detect_icache_policy(info);
-
- check_local_cpu_errata();
}
void cpuinfo_store_cpu(void)
diff --git a/arch/arm64/kernel/debug-monitors.c b/arch/arm64/kernel/debug-monitors.c
index 91fff48..73ae90e 100644
--- a/arch/arm64/kernel/debug-monitors.c
+++ b/arch/arm64/kernel/debug-monitors.c
@@ -46,16 +46,14 @@
{
unsigned long flags;
local_dbg_save(flags);
- asm volatile("msr mdscr_el1, %0" :: "r" (mdscr));
+ write_sysreg(mdscr, mdscr_el1);
local_dbg_restore(flags);
}
NOKPROBE_SYMBOL(mdscr_write);
static u32 mdscr_read(void)
{
- u32 mdscr;
- asm volatile("mrs %0, mdscr_el1" : "=r" (mdscr));
- return mdscr;
+ return read_sysreg(mdscr_el1);
}
NOKPROBE_SYMBOL(mdscr_read);
@@ -132,36 +130,18 @@
/*
* OS lock clearing.
*/
-static void clear_os_lock(void *unused)
+static int clear_os_lock(unsigned int cpu)
{
- asm volatile("msr oslar_el1, %0" : : "r" (0));
+ write_sysreg(0, oslar_el1);
+ isb();
+ return 0;
}
-static int os_lock_notify(struct notifier_block *self,
- unsigned long action, void *data)
-{
- if ((action & ~CPU_TASKS_FROZEN) == CPU_ONLINE)
- clear_os_lock(NULL);
- return NOTIFY_OK;
-}
-
-static struct notifier_block os_lock_nb = {
- .notifier_call = os_lock_notify,
-};
-
static int debug_monitors_init(void)
{
- cpu_notifier_register_begin();
-
- /* Clear the OS lock. */
- on_each_cpu(clear_os_lock, NULL, 1);
- isb();
-
- /* Register hotplug handler. */
- __register_cpu_notifier(&os_lock_nb);
-
- cpu_notifier_register_done();
- return 0;
+ return cpuhp_setup_state(CPUHP_AP_ARM64_DEBUG_MONITORS_STARTING,
+ "CPUHP_AP_ARM64_DEBUG_MONITORS_STARTING",
+ clear_os_lock, NULL);
}
postcore_initcall(debug_monitors_init);
@@ -254,7 +234,7 @@
return 0;
if (user_mode(regs)) {
- send_user_sigtrap(TRAP_HWBKPT);
+ send_user_sigtrap(TRAP_TRACE);
/*
* ptrace will disable single step unless explicitly
@@ -382,7 +362,7 @@
static int __init debug_traps_init(void)
{
hook_debug_fault_code(DBG_ESR_EVT_HWSS, single_step_handler, SIGTRAP,
- TRAP_HWBKPT, "single-step handler");
+ TRAP_TRACE, "single-step handler");
hook_debug_fault_code(DBG_ESR_EVT_BRK, brk_handler, SIGTRAP,
TRAP_BRKPT, "ptrace BRK handler");
return 0;
@@ -435,8 +415,10 @@
/* ptrace API */
void user_enable_single_step(struct task_struct *task)
{
- set_ti_thread_flag(task_thread_info(task), TIF_SINGLESTEP);
- set_regs_spsr_ss(task_pt_regs(task));
+ struct thread_info *ti = task_thread_info(task);
+
+ if (!test_and_set_ti_thread_flag(ti, TIF_SINGLESTEP))
+ set_regs_spsr_ss(task_pt_regs(task));
}
NOKPROBE_SYMBOL(user_enable_single_step);
diff --git a/arch/arm64/kernel/entry.S b/arch/arm64/kernel/entry.S
index 441420c..223d54a 100644
--- a/arch/arm64/kernel/entry.S
+++ b/arch/arm64/kernel/entry.S
@@ -104,7 +104,7 @@
str x20, [sp, #S_ORIG_ADDR_LIMIT]
mov x20, #TASK_SIZE_64
str x20, [tsk, #TI_ADDR_LIMIT]
- ALTERNATIVE(nop, SET_PSTATE_UAO(0), ARM64_HAS_UAO, CONFIG_ARM64_UAO)
+ /* No need to reset PSTATE.UAO, hardware's already set it to 0 for us */
.endif /* \el == 0 */
mrs x22, elr_el1
mrs x23, spsr_el1
@@ -150,13 +150,7 @@
ldr x23, [sp, #S_SP] // load return stack pointer
msr sp_el0, x23
#ifdef CONFIG_ARM64_ERRATUM_845719
-alternative_if_not ARM64_WORKAROUND_845719
- nop
- nop
-#ifdef CONFIG_PID_IN_CONTEXTIDR
- nop
-#endif
-alternative_else
+alternative_if ARM64_WORKAROUND_845719
tbz x22, #4, 1f
#ifdef CONFIG_PID_IN_CONTEXTIDR
mrs x29, contextidr_el1
@@ -165,7 +159,7 @@
msr contextidr_el1, xzr
#endif
1:
-alternative_endif
+alternative_else_nop_endif
#endif
.endif
msr elr_el1, x21 // set up the return data
@@ -707,18 +701,13 @@
* Ok, we need to do extra processing, enter the slow path.
*/
work_pending:
- tbnz x1, #TIF_NEED_RESCHED, work_resched
- /* TIF_SIGPENDING, TIF_NOTIFY_RESUME or TIF_FOREIGN_FPSTATE case */
mov x0, sp // 'regs'
- enable_irq // enable interrupts for do_notify_resume()
bl do_notify_resume
- b ret_to_user
-work_resched:
#ifdef CONFIG_TRACE_IRQFLAGS
- bl trace_hardirqs_off // the IRQs are off here, inform the tracing code
+ bl trace_hardirqs_on // enabled while in userspace
#endif
- bl schedule
-
+ ldr x1, [tsk, #TI_FLAGS] // re-check for single-step
+ b finish_ret_to_user
/*
* "slow" syscall return path.
*/
@@ -727,6 +716,7 @@
ldr x1, [tsk, #TI_FLAGS]
and x2, x1, #_TIF_WORK_MASK
cbnz x2, work_pending
+finish_ret_to_user:
enable_step_tsk x1, x2
kernel_exit 0
ENDPROC(ret_to_user)
diff --git a/arch/arm64/kernel/head.S b/arch/arm64/kernel/head.S
index 3e7b050..427f6d3 100644
--- a/arch/arm64/kernel/head.S
+++ b/arch/arm64/kernel/head.S
@@ -208,13 +208,23 @@
__INIT
+ /*
+ * The following callee saved general purpose registers are used on the
+ * primary lowlevel boot path:
+ *
+ * Register Scope Purpose
+ * x21 stext() .. start_kernel() FDT pointer passed at boot in x0
+ * x23 stext() .. start_kernel() physical misalignment/KASLR offset
+ * x28 __create_page_tables() callee preserved temp register
+ * x19/x20 __primary_switch() callee preserved temp registers
+ */
ENTRY(stext)
bl preserve_boot_args
- bl el2_setup // Drop to EL1, w20=cpu_boot_mode
- adrp x24, __PHYS_OFFSET
- and x23, x24, MIN_KIMG_ALIGN - 1 // KASLR offset, defaults to 0
+ bl el2_setup // Drop to EL1, w0=cpu_boot_mode
+ adrp x23, __PHYS_OFFSET
+ and x23, x23, MIN_KIMG_ALIGN - 1 // KASLR offset, defaults to 0
bl set_cpu_boot_mode_flag
- bl __create_page_tables // x25=TTBR0, x26=TTBR1
+ bl __create_page_tables
/*
* The following calls CPU setup code, see arch/arm64/mm/proc.S for
* details.
@@ -222,9 +232,7 @@
* the TCR will have been set.
*/
bl __cpu_setup // initialise processor
- adr_l x27, __primary_switch // address to jump to after
- // MMU has been enabled
- b __enable_mmu
+ b __primary_switch
ENDPROC(stext)
/*
@@ -311,23 +319,21 @@
* been enabled
*/
__create_page_tables:
- adrp x25, idmap_pg_dir
- adrp x26, swapper_pg_dir
mov x28, lr
/*
* Invalidate the idmap and swapper page tables to avoid potential
* dirty cache lines being evicted.
*/
- mov x0, x25
- add x1, x26, #SWAPPER_DIR_SIZE
+ adrp x0, idmap_pg_dir
+ adrp x1, swapper_pg_dir + SWAPPER_DIR_SIZE
bl __inval_cache_range
/*
* Clear the idmap and swapper page tables.
*/
- mov x0, x25
- add x6, x26, #SWAPPER_DIR_SIZE
+ adrp x0, idmap_pg_dir
+ adrp x6, swapper_pg_dir + SWAPPER_DIR_SIZE
1: stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
@@ -340,7 +346,7 @@
/*
* Create the identity mapping.
*/
- mov x0, x25 // idmap_pg_dir
+ adrp x0, idmap_pg_dir
adrp x3, __idmap_text_start // __pa(__idmap_text_start)
#ifndef CONFIG_ARM64_VA_BITS_48
@@ -390,7 +396,7 @@
/*
* Map the kernel image (starting with PHYS_OFFSET).
*/
- mov x0, x26 // swapper_pg_dir
+ adrp x0, swapper_pg_dir
mov_q x5, KIMAGE_VADDR + TEXT_OFFSET // compile time __va(_text)
add x5, x5, x23 // add KASLR displacement
create_pgd_entry x0, x5, x3, x6
@@ -405,8 +411,8 @@
* accesses (MMU disabled), invalidate the idmap and swapper page
* tables again to remove any speculatively loaded cache lines.
*/
- mov x0, x25
- add x1, x26, #SWAPPER_DIR_SIZE
+ adrp x0, idmap_pg_dir
+ adrp x1, swapper_pg_dir + SWAPPER_DIR_SIZE
dmb sy
bl __inval_cache_range
@@ -416,14 +422,27 @@
/*
* The following fragment of code is executed with the MMU enabled.
+ *
+ * x0 = __PHYS_OFFSET
*/
- .set initial_sp, init_thread_union + THREAD_START_SP
__primary_switched:
- mov x28, lr // preserve LR
+ adrp x4, init_thread_union
+ add sp, x4, #THREAD_SIZE
+ msr sp_el0, x4 // Save thread_info
+
adr_l x8, vectors // load VBAR_EL1 with virtual
msr vbar_el1, x8 // vector table address
isb
+ stp xzr, x30, [sp, #-16]!
+ mov x29, sp
+
+ str_l x21, __fdt_pointer, x5 // Save FDT pointer
+
+ ldr_l x4, kimage_vaddr // Save the offset between
+ sub x4, x4, x0 // the kernel virtual and
+ str_l x4, kimage_voffset, x5 // physical mappings
+
// Clear BSS
adr_l x0, __bss_start
mov x1, xzr
@@ -432,17 +451,6 @@
bl __pi_memset
dsb ishst // Make zero page visible to PTW
- adr_l sp, initial_sp, x4
- mov x4, sp
- and x4, x4, #~(THREAD_SIZE - 1)
- msr sp_el0, x4 // Save thread_info
- str_l x21, __fdt_pointer, x5 // Save FDT pointer
-
- ldr_l x4, kimage_vaddr // Save the offset between
- sub x4, x4, x24 // the kernel virtual and
- str_l x4, kimage_voffset, x5 // physical mappings
-
- mov x29, #0
#ifdef CONFIG_KASAN
bl kasan_early_init
#endif
@@ -454,8 +462,8 @@
bl kaslr_early_init // parse FDT for KASLR options
cbz x0, 0f // KASLR disabled? just proceed
orr x23, x23, x0 // record KASLR offset
- ret x28 // we must enable KASLR, return
- // to __enable_mmu()
+ ldp x29, x30, [sp], #16 // we must enable KASLR, return
+ ret // to __primary_switch()
0:
#endif
b start_kernel
@@ -465,7 +473,7 @@
* end early head section, begin head code that is also used for
* hotplug and needs to have the same protections as the text region
*/
- .section ".text","ax"
+ .section ".idmap.text","ax"
ENTRY(kimage_vaddr)
.quad _text - TEXT_OFFSET
@@ -490,7 +498,7 @@
CPU_BE( orr x0, x0, #(3 << 24) ) // Set the EE and E0E bits for EL1
CPU_LE( bic x0, x0, #(3 << 24) ) // Clear the EE and E0E bits for EL1
msr sctlr_el1, x0
- mov w20, #BOOT_CPU_MODE_EL1 // This cpu booted in EL1
+ mov w0, #BOOT_CPU_MODE_EL1 // This cpu booted in EL1
isb
ret
@@ -586,7 +594,7 @@
cbz x2, install_el2_stub
- mov w20, #BOOT_CPU_MODE_EL2 // This CPU booted in EL2
+ mov w0, #BOOT_CPU_MODE_EL2 // This CPU booted in EL2
isb
ret
@@ -601,7 +609,7 @@
PSR_MODE_EL1h)
msr spsr_el2, x0
msr elr_el2, lr
- mov w20, #BOOT_CPU_MODE_EL2 // This CPU booted in EL2
+ mov w0, #BOOT_CPU_MODE_EL2 // This CPU booted in EL2
eret
ENDPROC(el2_setup)
@@ -611,27 +619,39 @@
*/
set_cpu_boot_mode_flag:
adr_l x1, __boot_cpu_mode
- cmp w20, #BOOT_CPU_MODE_EL2
+ cmp w0, #BOOT_CPU_MODE_EL2
b.ne 1f
add x1, x1, #4
-1: str w20, [x1] // This CPU has booted in EL1
+1: str w0, [x1] // This CPU has booted in EL1
dmb sy
dc ivac, x1 // Invalidate potentially stale cache line
ret
ENDPROC(set_cpu_boot_mode_flag)
/*
+ * These values are written with the MMU off, but read with the MMU on.
+ * Writers will invalidate the corresponding address, discarding up to a
+ * 'Cache Writeback Granule' (CWG) worth of data. The linker script ensures
+ * sufficient alignment that the CWG doesn't overlap another section.
+ */
+ .pushsection ".mmuoff.data.write", "aw"
+/*
* We need to find out the CPU boot mode long after boot, so we need to
* store it in a writable variable.
*
* This is not in .bss, because we set it sufficiently early that the boot-time
* zeroing of .bss would clobber it.
*/
- .pushsection .data..cacheline_aligned
- .align L1_CACHE_SHIFT
ENTRY(__boot_cpu_mode)
.long BOOT_CPU_MODE_EL2
.long BOOT_CPU_MODE_EL1
+/*
+ * The booting CPU updates the failed status @__early_cpu_boot_status,
+ * with MMU turned off.
+ */
+ENTRY(__early_cpu_boot_status)
+ .long 0
+
.popsection
/*
@@ -639,7 +659,7 @@
* cores are held until we're ready for them to initialise.
*/
ENTRY(secondary_holding_pen)
- bl el2_setup // Drop to EL1, w20=cpu_boot_mode
+ bl el2_setup // Drop to EL1, w0=cpu_boot_mode
bl set_cpu_boot_mode_flag
mrs x0, mpidr_el1
mov_q x1, MPIDR_HWID_BITMASK
@@ -666,12 +686,10 @@
/*
* Common entry point for secondary CPUs.
*/
- adrp x25, idmap_pg_dir
- adrp x26, swapper_pg_dir
bl __cpu_setup // initialise processor
-
- adr_l x27, __secondary_switch // address to jump to after enabling the MMU
- b __enable_mmu
+ bl __enable_mmu
+ ldr x8, =__secondary_switched
+ br x8
ENDPROC(secondary_startup)
__secondary_switched:
@@ -706,33 +724,27 @@
dc ivac, \tmp1 // Invalidate potentially stale cache line
.endm
- .pushsection .data..cacheline_aligned
- .align L1_CACHE_SHIFT
-ENTRY(__early_cpu_boot_status)
- .long 0
- .popsection
-
/*
* Enable the MMU.
*
* x0 = SCTLR_EL1 value for turning on the MMU.
- * x27 = *virtual* address to jump to upon completion
*
- * Other registers depend on the function called upon completion.
+ * Returns to the caller via x30/lr. This requires the caller to be covered
+ * by the .idmap.text section.
*
* Checks if the selected granule size is supported by the CPU.
* If it isn't, park the CPU
*/
- .section ".idmap.text", "ax"
ENTRY(__enable_mmu)
- mrs x22, sctlr_el1 // preserve old SCTLR_EL1 value
mrs x1, ID_AA64MMFR0_EL1
ubfx x2, x1, #ID_AA64MMFR0_TGRAN_SHIFT, 4
cmp x2, #ID_AA64MMFR0_TGRAN_SUPPORTED
b.ne __no_granule_support
update_early_cpu_boot_status 0, x1, x2
- msr ttbr0_el1, x25 // load TTBR0
- msr ttbr1_el1, x26 // load TTBR1
+ adrp x1, idmap_pg_dir
+ adrp x2, swapper_pg_dir
+ msr ttbr0_el1, x1 // load TTBR0
+ msr ttbr1_el1, x2 // load TTBR1
isb
msr sctlr_el1, x0
isb
@@ -744,29 +756,7 @@
ic iallu
dsb nsh
isb
-#ifdef CONFIG_RANDOMIZE_BASE
- mov x19, x0 // preserve new SCTLR_EL1 value
- blr x27
-
- /*
- * If we return here, we have a KASLR displacement in x23 which we need
- * to take into account by discarding the current kernel mapping and
- * creating a new one.
- */
- msr sctlr_el1, x22 // disable the MMU
- isb
- bl __create_page_tables // recreate kernel mapping
-
- tlbi vmalle1 // Remove any stale TLB entries
- dsb nsh
-
- msr sctlr_el1, x19 // re-enable the MMU
- isb
- ic iallu // flush instructions fetched
- dsb nsh // via old mapping
- isb
-#endif
- br x27
+ ret
ENDPROC(__enable_mmu)
__no_granule_support:
@@ -775,11 +765,11 @@
1:
wfe
wfi
- b 1b
+ b 1b
ENDPROC(__no_granule_support)
-__primary_switch:
#ifdef CONFIG_RELOCATABLE
+__relocate_kernel:
/*
* Iterate over each entry in the relocation table, and apply the
* relocations in place.
@@ -801,14 +791,46 @@
add x13, x13, x23 // relocate
str x13, [x11, x23]
b 0b
+1: ret
+ENDPROC(__relocate_kernel)
+#endif
-1:
+__primary_switch:
+#ifdef CONFIG_RANDOMIZE_BASE
+ mov x19, x0 // preserve new SCTLR_EL1 value
+ mrs x20, sctlr_el1 // preserve old SCTLR_EL1 value
+#endif
+
+ bl __enable_mmu
+#ifdef CONFIG_RELOCATABLE
+ bl __relocate_kernel
+#ifdef CONFIG_RANDOMIZE_BASE
+ ldr x8, =__primary_switched
+ adrp x0, __PHYS_OFFSET
+ blr x8
+
+ /*
+ * If we return here, we have a KASLR displacement in x23 which we need
+ * to take into account by discarding the current kernel mapping and
+ * creating a new one.
+ */
+ msr sctlr_el1, x20 // disable the MMU
+ isb
+ bl __create_page_tables // recreate kernel mapping
+
+ tlbi vmalle1 // Remove any stale TLB entries
+ dsb nsh
+
+ msr sctlr_el1, x19 // re-enable the MMU
+ isb
+ ic iallu // flush instructions fetched
+ dsb nsh // via old mapping
+ isb
+
+ bl __relocate_kernel
+#endif
#endif
ldr x8, =__primary_switched
+ adrp x0, __PHYS_OFFSET
br x8
ENDPROC(__primary_switch)
-
-__secondary_switch:
- ldr x8, =__secondary_switched
- br x8
-ENDPROC(__secondary_switch)
diff --git a/arch/arm64/kernel/hibernate-asm.S b/arch/arm64/kernel/hibernate-asm.S
index 46f29b6..e56d848 100644
--- a/arch/arm64/kernel/hibernate-asm.S
+++ b/arch/arm64/kernel/hibernate-asm.S
@@ -36,8 +36,8 @@
.macro break_before_make_ttbr_switch zero_page, page_table
msr ttbr1_el1, \zero_page
isb
- tlbi vmalle1is
- dsb ish
+ tlbi vmalle1
+ dsb nsh
msr ttbr1_el1, \page_table
isb
.endm
@@ -96,7 +96,7 @@
add x1, x10, #PAGE_SIZE
/* Clean the copied page to PoU - based on flush_icache_range() */
- dcache_line_size x2, x3
+ raw_dcache_line_size x2, x3
sub x3, x2, #1
bic x4, x10, x3
2: dc cvau, x4 /* clean D line / unified line */
diff --git a/arch/arm64/kernel/hibernate.c b/arch/arm64/kernel/hibernate.c
index 65d81f9..d55a7b0 100644
--- a/arch/arm64/kernel/hibernate.c
+++ b/arch/arm64/kernel/hibernate.c
@@ -15,9 +15,9 @@
* License terms: GNU General Public License (GPL) version 2
*/
#define pr_fmt(x) "hibernate: " x
+#include <linux/cpu.h>
#include <linux/kvm_host.h>
#include <linux/mm.h>
-#include <linux/notifier.h>
#include <linux/pm.h>
#include <linux/sched.h>
#include <linux/suspend.h>
@@ -26,6 +26,7 @@
#include <asm/barrier.h>
#include <asm/cacheflush.h>
+#include <asm/cputype.h>
#include <asm/irqflags.h>
#include <asm/memory.h>
#include <asm/mmu_context.h>
@@ -34,6 +35,7 @@
#include <asm/pgtable-hwdef.h>
#include <asm/sections.h>
#include <asm/smp.h>
+#include <asm/smp_plat.h>
#include <asm/suspend.h>
#include <asm/sysreg.h>
#include <asm/virt.h>
@@ -54,12 +56,6 @@
/* Do we need to reset el2? */
#define el2_reset_needed() (is_hyp_mode_available() && !is_kernel_in_hyp_mode())
-/*
- * Start/end of the hibernate exit code, this must be copied to a 'safe'
- * location in memory, and executed from there.
- */
-extern char __hibernate_exit_text_start[], __hibernate_exit_text_end[];
-
/* temporary el2 vectors in the __hibernate_exit_text section. */
extern char hibernate_el2_vectors[];
@@ -67,6 +63,12 @@
extern char __hyp_stub_vectors[];
/*
+ * The logical cpu number we should resume on, initialised to a non-cpu
+ * number.
+ */
+static int sleep_cpu = -EINVAL;
+
+/*
* Values that may not change over hibernate/resume. We put the build number
* and date in here so that we guarantee not to resume with a different
* kernel.
@@ -88,6 +90,8 @@
* re-configure el2.
*/
phys_addr_t __hyp_stub_vectors;
+
+ u64 sleep_cpu_mpidr;
} resume_hdr;
static inline void arch_hdr_invariants(struct arch_hibernate_hdr_invariants *i)
@@ -130,12 +134,22 @@
else
hdr->__hyp_stub_vectors = 0;
+ /* Save the mpidr of the cpu we called cpu_suspend() on... */
+ if (sleep_cpu < 0) {
+ pr_err("Failing to hibernate on an unkown CPU.\n");
+ return -ENODEV;
+ }
+ hdr->sleep_cpu_mpidr = cpu_logical_map(sleep_cpu);
+ pr_info("Hibernating on CPU %d [mpidr:0x%llx]\n", sleep_cpu,
+ hdr->sleep_cpu_mpidr);
+
return 0;
}
EXPORT_SYMBOL(arch_hibernation_header_save);
int arch_hibernation_header_restore(void *addr)
{
+ int ret;
struct arch_hibernate_hdr_invariants invariants;
struct arch_hibernate_hdr *hdr = addr;
@@ -145,6 +159,24 @@
return -EINVAL;
}
+ sleep_cpu = get_logical_index(hdr->sleep_cpu_mpidr);
+ pr_info("Hibernated on CPU %d [mpidr:0x%llx]\n", sleep_cpu,
+ hdr->sleep_cpu_mpidr);
+ if (sleep_cpu < 0) {
+ pr_crit("Hibernated on a CPU not known to this kernel!\n");
+ sleep_cpu = -EINVAL;
+ return -EINVAL;
+ }
+ if (!cpu_online(sleep_cpu)) {
+ pr_info("Hibernated on a CPU that is offline! Bringing CPU up.\n");
+ ret = cpu_up(sleep_cpu);
+ if (ret) {
+ pr_err("Failed to bring hibernate-CPU up!\n");
+ sleep_cpu = -EINVAL;
+ return ret;
+ }
+ }
+
resume_hdr = *hdr;
return 0;
@@ -241,6 +273,7 @@
return rc;
}
+#define dcache_clean_range(start, end) __flush_dcache_area(start, (end - start))
int swsusp_arch_suspend(void)
{
@@ -256,10 +289,16 @@
local_dbg_save(flags);
if (__cpu_suspend_enter(&state)) {
+ sleep_cpu = smp_processor_id();
ret = swsusp_save();
} else {
- /* Clean kernel to PoC for secondary core startup */
- __flush_dcache_area(LMADDR(KERNEL_START), KERNEL_END - KERNEL_START);
+ /* Clean kernel core startup/idle code to PoC*/
+ dcache_clean_range(__mmuoff_data_start, __mmuoff_data_end);
+ dcache_clean_range(__idmap_text_start, __idmap_text_end);
+
+ /* Clean kvm setup code to PoC? */
+ if (el2_reset_needed())
+ dcache_clean_range(__hyp_idmap_text_start, __hyp_idmap_text_end);
/*
* Tell the hibernation core that we've just restored
@@ -267,6 +306,7 @@
*/
in_suspend = 0;
+ sleep_cpu = -EINVAL;
__cpu_suspend_exit();
}
@@ -275,6 +315,33 @@
return ret;
}
+static void _copy_pte(pte_t *dst_pte, pte_t *src_pte, unsigned long addr)
+{
+ pte_t pte = *src_pte;
+
+ if (pte_valid(pte)) {
+ /*
+ * Resume will overwrite areas that may be marked
+ * read only (code, rodata). Clear the RDONLY bit from
+ * the temporary mappings we use during restore.
+ */
+ set_pte(dst_pte, pte_clear_rdonly(pte));
+ } else if (debug_pagealloc_enabled() && !pte_none(pte)) {
+ /*
+ * debug_pagealloc will removed the PTE_VALID bit if
+ * the page isn't in use by the resume kernel. It may have
+ * been in use by the original kernel, in which case we need
+ * to put it back in our copy to do the restore.
+ *
+ * Before marking this entry valid, check the pfn should
+ * be mapped.
+ */
+ BUG_ON(!pfn_valid(pte_pfn(pte)));
+
+ set_pte(dst_pte, pte_mkpresent(pte_clear_rdonly(pte)));
+ }
+}
+
static int copy_pte(pmd_t *dst_pmd, pmd_t *src_pmd, unsigned long start,
unsigned long end)
{
@@ -290,13 +357,7 @@
src_pte = pte_offset_kernel(src_pmd, start);
do {
- if (!pte_none(*src_pte))
- /*
- * Resume will overwrite areas that may be marked
- * read only (code, rodata). Clear the RDONLY bit from
- * the temporary mappings we use during restore.
- */
- set_pte(dst_pte, __pte(pte_val(*src_pte) & ~PTE_RDONLY));
+ _copy_pte(dst_pte, src_pte, addr);
} while (dst_pte++, src_pte++, addr += PAGE_SIZE, addr != end);
return 0;
@@ -483,27 +544,12 @@
return rc;
}
-static int check_boot_cpu_online_pm_callback(struct notifier_block *nb,
- unsigned long action, void *ptr)
+int hibernate_resume_nonboot_cpu_disable(void)
{
- if (action == PM_HIBERNATION_PREPARE &&
- cpumask_first(cpu_online_mask) != 0) {
- pr_warn("CPU0 is offline.\n");
- return notifier_from_errno(-ENODEV);
+ if (sleep_cpu < 0) {
+ pr_err("Failing to resume from hibernate on an unkown CPU.\n");
+ return -ENODEV;
}
- return NOTIFY_OK;
+ return freeze_secondary_cpus(sleep_cpu);
}
-
-static int __init check_boot_cpu_online_init(void)
-{
- /*
- * Set this pm_notifier callback with a lower priority than
- * cpu_hotplug_pm_callback, so that cpu_hotplug_pm_callback will be
- * called earlier to disable cpu hotplug before the cpu online check.
- */
- pm_notifier(check_boot_cpu_online_pm_callback, -INT_MAX);
-
- return 0;
-}
-core_initcall(check_boot_cpu_online_init);
diff --git a/arch/arm64/kernel/hw_breakpoint.c b/arch/arm64/kernel/hw_breakpoint.c
index 26a6bf7..948b731 100644
--- a/arch/arm64/kernel/hw_breakpoint.c
+++ b/arch/arm64/kernel/hw_breakpoint.c
@@ -857,7 +857,7 @@
/*
* CPU initialisation.
*/
-static void hw_breakpoint_reset(void *unused)
+static int hw_breakpoint_reset(unsigned int cpu)
{
int i;
struct perf_event **slots;
@@ -888,28 +888,14 @@
write_wb_reg(AARCH64_DBG_REG_WVR, i, 0UL);
}
}
-}
-static int hw_breakpoint_reset_notify(struct notifier_block *self,
- unsigned long action,
- void *hcpu)
-{
- if ((action & ~CPU_TASKS_FROZEN) == CPU_ONLINE) {
- local_irq_disable();
- hw_breakpoint_reset(NULL);
- local_irq_enable();
- }
- return NOTIFY_OK;
+ return 0;
}
-static struct notifier_block hw_breakpoint_reset_nb = {
- .notifier_call = hw_breakpoint_reset_notify,
-};
-
#ifdef CONFIG_CPU_PM
-extern void cpu_suspend_set_dbg_restorer(void (*hw_bp_restore)(void *));
+extern void cpu_suspend_set_dbg_restorer(int (*hw_bp_restore)(unsigned int));
#else
-static inline void cpu_suspend_set_dbg_restorer(void (*hw_bp_restore)(void *))
+static inline void cpu_suspend_set_dbg_restorer(int (*hw_bp_restore)(unsigned int))
{
}
#endif
@@ -919,36 +905,34 @@
*/
static int __init arch_hw_breakpoint_init(void)
{
+ int ret;
+
core_num_brps = get_num_brps();
core_num_wrps = get_num_wrps();
pr_info("found %d breakpoint and %d watchpoint registers.\n",
core_num_brps, core_num_wrps);
- cpu_notifier_register_begin();
-
- /*
- * Reset the breakpoint resources. We assume that a halting
- * debugger will leave the world in a nice state for us.
- */
- smp_call_function(hw_breakpoint_reset, NULL, 1);
- hw_breakpoint_reset(NULL);
-
/* Register debug fault handlers. */
hook_debug_fault_code(DBG_ESR_EVT_HWBP, breakpoint_handler, SIGTRAP,
TRAP_HWBKPT, "hw-breakpoint handler");
hook_debug_fault_code(DBG_ESR_EVT_HWWP, watchpoint_handler, SIGTRAP,
TRAP_HWBKPT, "hw-watchpoint handler");
- /* Register hotplug notifier. */
- __register_cpu_notifier(&hw_breakpoint_reset_nb);
-
- cpu_notifier_register_done();
+ /*
+ * Reset the breakpoint resources. We assume that a halting
+ * debugger will leave the world in a nice state for us.
+ */
+ ret = cpuhp_setup_state(CPUHP_AP_PERF_ARM_HW_BREAKPOINT_STARTING,
+ "CPUHP_AP_PERF_ARM_HW_BREAKPOINT_STARTING",
+ hw_breakpoint_reset, NULL);
+ if (ret)
+ pr_err("failed to register CPU hotplug notifier: %d\n", ret);
/* Register cpu_suspend hw breakpoint restore hook */
cpu_suspend_set_dbg_restorer(hw_breakpoint_reset);
- return 0;
+ return ret;
}
arch_initcall(arch_hw_breakpoint_init);
diff --git a/arch/arm64/kernel/insn.c b/arch/arm64/kernel/insn.c
index 63f9432..6f2ac4f 100644
--- a/arch/arm64/kernel/insn.c
+++ b/arch/arm64/kernel/insn.c
@@ -96,7 +96,7 @@
if (module && IS_ENABLED(CONFIG_DEBUG_SET_MODULE_RONX))
page = vmalloc_to_page(addr);
- else if (!module && IS_ENABLED(CONFIG_DEBUG_RODATA))
+ else if (!module)
page = pfn_to_page(PHYS_PFN(__pa(addr)));
else
return addr;
@@ -1202,6 +1202,19 @@
BUG();
}
+s32 aarch64_insn_adrp_get_offset(u32 insn)
+{
+ BUG_ON(!aarch64_insn_is_adrp(insn));
+ return aarch64_insn_decode_immediate(AARCH64_INSN_IMM_ADR, insn) << 12;
+}
+
+u32 aarch64_insn_adrp_set_offset(u32 insn, s32 offset)
+{
+ BUG_ON(!aarch64_insn_is_adrp(insn));
+ return aarch64_insn_encode_immediate(AARCH64_INSN_IMM_ADR, insn,
+ offset >> 12);
+}
+
/*
* Extract the Op/CR data from a msr/mrs instruction.
*/
diff --git a/arch/arm64/kernel/kaslr.c b/arch/arm64/kernel/kaslr.c
index b054691..769f24e 100644
--- a/arch/arm64/kernel/kaslr.c
+++ b/arch/arm64/kernel/kaslr.c
@@ -6,6 +6,7 @@
* published by the Free Software Foundation.
*/
+#include <linux/cache.h>
#include <linux/crc32.h>
#include <linux/init.h>
#include <linux/libfdt.h>
@@ -20,7 +21,7 @@
#include <asm/pgtable.h>
#include <asm/sections.h>
-u64 __read_mostly module_alloc_base;
+u64 __ro_after_init module_alloc_base;
u16 __initdata memstart_offset_seed;
static __init u64 get_kaslr_seed(void *fdt)
diff --git a/arch/arm64/kernel/kgdb.c b/arch/arm64/kernel/kgdb.c
index 8c57f64..e017a94 100644
--- a/arch/arm64/kernel/kgdb.c
+++ b/arch/arm64/kernel/kgdb.c
@@ -19,10 +19,13 @@
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
+#include <linux/bug.h>
#include <linux/irq.h>
#include <linux/kdebug.h>
#include <linux/kgdb.h>
#include <linux/kprobes.h>
+#include <asm/debug-monitors.h>
+#include <asm/insn.h>
#include <asm/traps.h>
struct dbg_reg_def_t dbg_reg_def[DBG_MAX_REG_NUM] = {
@@ -338,15 +341,24 @@
unregister_die_notifier(&kgdb_notifier);
}
-/*
- * ARM instructions are always in LE.
- * Break instruction is encoded in LE format
- */
-struct kgdb_arch arch_kgdb_ops = {
- .gdb_bpt_instr = {
- KGDB_DYN_BRK_INS_BYTE(0),
- KGDB_DYN_BRK_INS_BYTE(1),
- KGDB_DYN_BRK_INS_BYTE(2),
- KGDB_DYN_BRK_INS_BYTE(3),
- }
-};
+struct kgdb_arch arch_kgdb_ops;
+
+int kgdb_arch_set_breakpoint(struct kgdb_bkpt *bpt)
+{
+ int err;
+
+ BUILD_BUG_ON(AARCH64_INSN_SIZE != BREAK_INSTR_SIZE);
+
+ err = aarch64_insn_read((void *)bpt->bpt_addr, (u32 *)bpt->saved_instr);
+ if (err)
+ return err;
+
+ return aarch64_insn_write((void *)bpt->bpt_addr,
+ (u32)AARCH64_BREAK_KGDB_DYN_DBG);
+}
+
+int kgdb_arch_remove_breakpoint(struct kgdb_bkpt *bpt)
+{
+ return aarch64_insn_write((void *)bpt->bpt_addr,
+ *(u32 *)bpt->saved_instr);
+}
diff --git a/arch/arm64/kernel/perf_event.c b/arch/arm64/kernel/perf_event.c
index 838ccf1..a9310a6 100644
--- a/arch/arm64/kernel/perf_event.c
+++ b/arch/arm64/kernel/perf_event.c
@@ -24,6 +24,7 @@
#include <asm/sysreg.h>
#include <asm/virt.h>
+#include <linux/acpi.h>
#include <linux/of.h>
#include <linux/perf/arm_pmu.h>
#include <linux/platform_device.h>
@@ -190,13 +191,23 @@
#define ARMV8_THUNDER_PERFCTR_L1I_CACHE_PREF_MISS 0xED
/* PMUv3 HW events mapping. */
+
+/*
+ * ARMv8 Architectural defined events, not all of these may
+ * be supported on any given implementation. Undefined events will
+ * be disabled at run-time.
+ */
static const unsigned armv8_pmuv3_perf_map[PERF_COUNT_HW_MAX] = {
PERF_MAP_ALL_UNSUPPORTED,
[PERF_COUNT_HW_CPU_CYCLES] = ARMV8_PMUV3_PERFCTR_CPU_CYCLES,
[PERF_COUNT_HW_INSTRUCTIONS] = ARMV8_PMUV3_PERFCTR_INST_RETIRED,
[PERF_COUNT_HW_CACHE_REFERENCES] = ARMV8_PMUV3_PERFCTR_L1D_CACHE,
[PERF_COUNT_HW_CACHE_MISSES] = ARMV8_PMUV3_PERFCTR_L1D_CACHE_REFILL,
+ [PERF_COUNT_HW_BRANCH_INSTRUCTIONS] = ARMV8_PMUV3_PERFCTR_PC_WRITE_RETIRED,
[PERF_COUNT_HW_BRANCH_MISSES] = ARMV8_PMUV3_PERFCTR_BR_MIS_PRED,
+ [PERF_COUNT_HW_BUS_CYCLES] = ARMV8_PMUV3_PERFCTR_BUS_CYCLES,
+ [PERF_COUNT_HW_STALLED_CYCLES_FRONTEND] = ARMV8_PMUV3_PERFCTR_STALL_FRONTEND,
+ [PERF_COUNT_HW_STALLED_CYCLES_BACKEND] = ARMV8_PMUV3_PERFCTR_STALL_BACKEND,
};
/* ARM Cortex-A53 HW events mapping. */
@@ -258,6 +269,15 @@
[C(L1D)][C(OP_WRITE)][C(RESULT_ACCESS)] = ARMV8_PMUV3_PERFCTR_L1D_CACHE,
[C(L1D)][C(OP_WRITE)][C(RESULT_MISS)] = ARMV8_PMUV3_PERFCTR_L1D_CACHE_REFILL,
+ [C(L1I)][C(OP_READ)][C(RESULT_ACCESS)] = ARMV8_PMUV3_PERFCTR_L1I_CACHE,
+ [C(L1I)][C(OP_READ)][C(RESULT_MISS)] = ARMV8_PMUV3_PERFCTR_L1I_CACHE_REFILL,
+
+ [C(DTLB)][C(OP_READ)][C(RESULT_MISS)] = ARMV8_PMUV3_PERFCTR_L1D_TLB_REFILL,
+ [C(DTLB)][C(OP_READ)][C(RESULT_ACCESS)] = ARMV8_PMUV3_PERFCTR_L1D_TLB,
+
+ [C(ITLB)][C(OP_READ)][C(RESULT_MISS)] = ARMV8_PMUV3_PERFCTR_L1I_TLB_REFILL,
+ [C(ITLB)][C(OP_READ)][C(RESULT_ACCESS)] = ARMV8_PMUV3_PERFCTR_L1I_TLB,
+
[C(BPU)][C(OP_READ)][C(RESULT_ACCESS)] = ARMV8_PMUV3_PERFCTR_BR_PRED,
[C(BPU)][C(OP_READ)][C(RESULT_MISS)] = ARMV8_PMUV3_PERFCTR_BR_MIS_PRED,
[C(BPU)][C(OP_WRITE)][C(RESULT_ACCESS)] = ARMV8_PMUV3_PERFCTR_BR_PRED,
@@ -523,12 +543,6 @@
.attrs = armv8_pmuv3_format_attrs,
};
-static const struct attribute_group *armv8_pmuv3_attr_groups[] = {
- &armv8_pmuv3_events_attr_group,
- &armv8_pmuv3_format_attr_group,
- NULL,
-};
-
/*
* Perf Events' indices
*/
@@ -905,9 +919,22 @@
static int armv8_pmuv3_map_event(struct perf_event *event)
{
- return armpmu_map_event(event, &armv8_pmuv3_perf_map,
- &armv8_pmuv3_perf_cache_map,
- ARMV8_PMU_EVTYPE_EVENT);
+ int hw_event_id;
+ struct arm_pmu *armpmu = to_arm_pmu(event->pmu);
+
+ hw_event_id = armpmu_map_event(event, &armv8_pmuv3_perf_map,
+ &armv8_pmuv3_perf_cache_map,
+ ARMV8_PMU_EVTYPE_EVENT);
+ if (hw_event_id < 0)
+ return hw_event_id;
+
+ /* disable micro/arch events not supported by this PMU */
+ if ((hw_event_id < ARMV8_PMUV3_MAX_COMMON_EVENTS) &&
+ !test_bit(hw_event_id, armpmu->pmceid_bitmap)) {
+ return -EOPNOTSUPP;
+ }
+
+ return hw_event_id;
}
static int armv8_a53_map_event(struct perf_event *event)
@@ -985,7 +1012,10 @@
armv8_pmu_init(cpu_pmu);
cpu_pmu->name = "armv8_pmuv3";
cpu_pmu->map_event = armv8_pmuv3_map_event;
- cpu_pmu->pmu.attr_groups = armv8_pmuv3_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv8_pmuv3_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv8_pmuv3_format_attr_group;
return armv8pmu_probe_pmu(cpu_pmu);
}
@@ -994,7 +1024,10 @@
armv8_pmu_init(cpu_pmu);
cpu_pmu->name = "armv8_cortex_a53";
cpu_pmu->map_event = armv8_a53_map_event;
- cpu_pmu->pmu.attr_groups = armv8_pmuv3_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv8_pmuv3_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv8_pmuv3_format_attr_group;
return armv8pmu_probe_pmu(cpu_pmu);
}
@@ -1003,7 +1036,10 @@
armv8_pmu_init(cpu_pmu);
cpu_pmu->name = "armv8_cortex_a57";
cpu_pmu->map_event = armv8_a57_map_event;
- cpu_pmu->pmu.attr_groups = armv8_pmuv3_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv8_pmuv3_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv8_pmuv3_format_attr_group;
return armv8pmu_probe_pmu(cpu_pmu);
}
@@ -1012,7 +1048,10 @@
armv8_pmu_init(cpu_pmu);
cpu_pmu->name = "armv8_cortex_a72";
cpu_pmu->map_event = armv8_a57_map_event;
- cpu_pmu->pmu.attr_groups = armv8_pmuv3_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv8_pmuv3_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv8_pmuv3_format_attr_group;
return armv8pmu_probe_pmu(cpu_pmu);
}
@@ -1021,7 +1060,10 @@
armv8_pmu_init(cpu_pmu);
cpu_pmu->name = "armv8_cavium_thunder";
cpu_pmu->map_event = armv8_thunder_map_event;
- cpu_pmu->pmu.attr_groups = armv8_pmuv3_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv8_pmuv3_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv8_pmuv3_format_attr_group;
return armv8pmu_probe_pmu(cpu_pmu);
}
@@ -1030,7 +1072,10 @@
armv8_pmu_init(cpu_pmu);
cpu_pmu->name = "armv8_brcm_vulcan";
cpu_pmu->map_event = armv8_vulcan_map_event;
- cpu_pmu->pmu.attr_groups = armv8_pmuv3_attr_groups;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_EVENTS] =
+ &armv8_pmuv3_events_attr_group;
+ cpu_pmu->attr_groups[ARMPMU_ATTR_GROUP_FORMATS] =
+ &armv8_pmuv3_format_attr_group;
return armv8pmu_probe_pmu(cpu_pmu);
}
@@ -1044,21 +1089,32 @@
{},
};
+/*
+ * Non DT systems have their micro/arch events probed at run-time.
+ * A fairly complete list of generic events are provided and ones that
+ * aren't supported by the current PMU are disabled.
+ */
+static const struct pmu_probe_info armv8_pmu_probe_table[] = {
+ PMU_PROBE(0, 0, armv8_pmuv3_init), /* enable all defined counters */
+ { /* sentinel value */ }
+};
+
static int armv8_pmu_device_probe(struct platform_device *pdev)
{
- return arm_pmu_device_probe(pdev, armv8_pmu_of_device_ids, NULL);
+ if (acpi_disabled)
+ return arm_pmu_device_probe(pdev, armv8_pmu_of_device_ids,
+ NULL);
+
+ return arm_pmu_device_probe(pdev, armv8_pmu_of_device_ids,
+ armv8_pmu_probe_table);
}
static struct platform_driver armv8_pmu_driver = {
.driver = {
- .name = "armv8-pmu",
+ .name = ARMV8_PMU_PDEV_NAME,
.of_match_table = armv8_pmu_of_device_ids,
},
.probe = armv8_pmu_device_probe,
};
-static int __init register_armv8_pmu_driver(void)
-{
- return platform_driver_register(&armv8_pmu_driver);
-}
-device_initcall(register_armv8_pmu_driver);
+builtin_platform_driver(armv8_pmu_driver);
diff --git a/arch/arm64/kernel/probes/decode-insn.c b/arch/arm64/kernel/probes/decode-insn.c
index 37e47a9..d1731bf 100644
--- a/arch/arm64/kernel/probes/decode-insn.c
+++ b/arch/arm64/kernel/probes/decode-insn.c
@@ -16,6 +16,7 @@
#include <linux/kernel.h>
#include <linux/kprobes.h>
#include <linux/module.h>
+#include <linux/kallsyms.h>
#include <asm/kprobes.h>
#include <asm/insn.h>
#include <asm/sections.h>
@@ -122,7 +123,7 @@
static bool __kprobes
is_probed_address_atomic(kprobe_opcode_t *scan_start, kprobe_opcode_t *scan_end)
{
- while (scan_start > scan_end) {
+ while (scan_start >= scan_end) {
/*
* atomic region starts from exclusive load and ends with
* exclusive store.
@@ -142,33 +143,30 @@
{
enum kprobe_insn decoded;
kprobe_opcode_t insn = le32_to_cpu(*addr);
- kprobe_opcode_t *scan_start = addr - 1;
- kprobe_opcode_t *scan_end = addr - MAX_ATOMIC_CONTEXT_SIZE;
-#if defined(CONFIG_MODULES) && defined(MODULES_VADDR)
- struct module *mod;
-#endif
+ kprobe_opcode_t *scan_end = NULL;
+ unsigned long size = 0, offset = 0;
- if (addr >= (kprobe_opcode_t *)_text &&
- scan_end < (kprobe_opcode_t *)_text)
- scan_end = (kprobe_opcode_t *)_text;
-#if defined(CONFIG_MODULES) && defined(MODULES_VADDR)
- else {
- preempt_disable();
- mod = __module_address((unsigned long)addr);
- if (mod && within_module_init((unsigned long)addr, mod) &&
- !within_module_init((unsigned long)scan_end, mod))
- scan_end = (kprobe_opcode_t *)mod->init_layout.base;
- else if (mod && within_module_core((unsigned long)addr, mod) &&
- !within_module_core((unsigned long)scan_end, mod))
- scan_end = (kprobe_opcode_t *)mod->core_layout.base;
- preempt_enable();
+ /*
+ * If there's a symbol defined in front of and near enough to
+ * the probe address assume it is the entry point to this
+ * code and use it to further limit how far back we search
+ * when determining if we're in an atomic sequence. If we could
+ * not find any symbol skip the atomic test altogether as we
+ * could otherwise end up searching irrelevant text/literals.
+ * KPROBES depends on KALLSYMS so this last case should never
+ * happen.
+ */
+ if (kallsyms_lookup_size_offset((unsigned long) addr, &size, &offset)) {
+ if (offset < (MAX_ATOMIC_CONTEXT_SIZE*sizeof(kprobe_opcode_t)))
+ scan_end = addr - (offset / sizeof(kprobe_opcode_t));
+ else
+ scan_end = addr - MAX_ATOMIC_CONTEXT_SIZE;
}
-#endif
decoded = arm_probe_decode_insn(insn, asi);
- if (decoded == INSN_REJECTED ||
- is_probed_address_atomic(scan_start, scan_end))
- return INSN_REJECTED;
+ if (decoded != INSN_REJECTED && scan_end)
+ if (is_probed_address_atomic(addr - 1, scan_end))
+ return INSN_REJECTED;
return decoded;
}
diff --git a/arch/arm64/kernel/probes/kprobes.c b/arch/arm64/kernel/probes/kprobes.c
index c6b0f40..f5077ea 100644
--- a/arch/arm64/kernel/probes/kprobes.c
+++ b/arch/arm64/kernel/probes/kprobes.c
@@ -19,7 +19,7 @@
#include <linux/kasan.h>
#include <linux/kernel.h>
#include <linux/kprobes.h>
-#include <linux/module.h>
+#include <linux/extable.h>
#include <linux/slab.h>
#include <linux/stop_machine.h>
#include <linux/stringify.h>
@@ -31,7 +31,7 @@
#include <asm/insn.h>
#include <asm/uaccess.h>
#include <asm/irq.h>
-#include <asm-generic/sections.h>
+#include <asm/sections.h>
#include "decode-insn.h"
@@ -166,13 +166,18 @@
}
/*
- * The D-flag (Debug mask) is set (masked) upon debug exception entry.
- * Kprobes needs to clear (unmask) D-flag -ONLY- in case of recursive
- * probe i.e. when probe hit from kprobe handler context upon
- * executing the pre/post handlers. In this case we return with
- * D-flag clear so that single-stepping can be carried-out.
- *
- * Leave D-flag set in all other cases.
+ * When PSTATE.D is set (masked), then software step exceptions can not be
+ * generated.
+ * SPSR's D bit shows the value of PSTATE.D immediately before the
+ * exception was taken. PSTATE.D is set while entering into any exception
+ * mode, however software clears it for any normal (none-debug-exception)
+ * mode in the exception entry. Therefore, when we are entering into kprobe
+ * breakpoint handler from any normal mode then SPSR.D bit is already
+ * cleared, however it is set when we are entering from any debug exception
+ * mode.
+ * Since we always need to generate single step exception after a kprobe
+ * breakpoint exception therefore we need to clear it unconditionally, when
+ * we become sure that the current breakpoint exception is for kprobe.
*/
static void __kprobes
spsr_set_debug_flag(struct pt_regs *regs, int mask)
@@ -245,10 +250,7 @@
set_ss_context(kcb, slot); /* mark pending ss */
- if (kcb->kprobe_status == KPROBE_REENTER)
- spsr_set_debug_flag(regs, 0);
- else
- WARN_ON(regs->pstate & PSR_D_BIT);
+ spsr_set_debug_flag(regs, 0);
/* IRQs and single stepping do not mix well. */
kprobes_save_local_irqflag(kcb, regs);
@@ -333,8 +335,6 @@
BUG();
kernel_disable_single_step();
- if (kcb->kprobe_status == KPROBE_REENTER)
- spsr_set_debug_flag(regs, 1);
if (kcb->kprobe_status == KPROBE_REENTER)
restore_previous_kprobe(kcb);
@@ -457,9 +457,6 @@
kprobes_restore_local_irqflag(kcb, regs);
kernel_disable_single_step();
- if (kcb->kprobe_status == KPROBE_REENTER)
- spsr_set_debug_flag(regs, 1);
-
post_kprobe_handler(kcb, regs);
}
@@ -543,9 +540,6 @@
bool arch_within_kprobe_blacklist(unsigned long addr)
{
- extern char __idmap_text_start[], __idmap_text_end[];
- extern char __hyp_idmap_text_start[], __hyp_idmap_text_end[];
-
if ((addr >= (unsigned long)__kprobes_text_start &&
addr < (unsigned long)__kprobes_text_end) ||
(addr >= (unsigned long)__entry_text_start &&
diff --git a/arch/arm64/kernel/process.c b/arch/arm64/kernel/process.c
index 6cd2612..a4f5f76 100644
--- a/arch/arm64/kernel/process.c
+++ b/arch/arm64/kernel/process.c
@@ -202,7 +202,7 @@
static void tls_thread_flush(void)
{
- asm ("msr tpidr_el0, xzr");
+ write_sysreg(0, tpidr_el0);
if (is_compat_task()) {
current->thread.tp_value = 0;
@@ -213,7 +213,7 @@
* with a stale shadow state during context switch.
*/
barrier();
- asm ("msr tpidrro_el0, xzr");
+ write_sysreg(0, tpidrro_el0);
}
}
@@ -253,7 +253,7 @@
* Read the current TLS pointer from tpidr_el0 as it may be
* out-of-sync with the saved value.
*/
- asm("mrs %0, tpidr_el0" : "=r" (*task_user_tls(p)));
+ *task_user_tls(p) = read_sysreg(tpidr_el0);
if (stack_start) {
if (is_compat_thread(task_thread_info(p)))
@@ -289,17 +289,15 @@
{
unsigned long tpidr, tpidrro;
- asm("mrs %0, tpidr_el0" : "=r" (tpidr));
+ tpidr = read_sysreg(tpidr_el0);
*task_user_tls(current) = tpidr;
tpidr = *task_user_tls(next);
tpidrro = is_compat_thread(task_thread_info(next)) ?
next->thread.tp_value : 0;
- asm(
- " msr tpidr_el0, %0\n"
- " msr tpidrro_el0, %1"
- : : "r" (tpidr), "r" (tpidrro));
+ write_sysreg(tpidr, tpidr_el0);
+ write_sysreg(tpidrro, tpidrro_el0);
}
/* Restore the UAO state depending on next's addr_limit */
diff --git a/arch/arm64/kernel/relocate_kernel.S b/arch/arm64/kernel/relocate_kernel.S
index 51b73cd..ce704a4 100644
--- a/arch/arm64/kernel/relocate_kernel.S
+++ b/arch/arm64/kernel/relocate_kernel.S
@@ -34,7 +34,7 @@
/* Setup the list loop variables. */
mov x17, x1 /* x17 = kimage_start */
mov x16, x0 /* x16 = kimage_head */
- dcache_line_size x15, x0 /* x15 = dcache line size */
+ raw_dcache_line_size x15, x0 /* x15 = dcache line size */
mov x14, xzr /* x14 = entry ptr */
mov x13, xzr /* x13 = copy dest */
diff --git a/arch/arm64/kernel/setup.c b/arch/arm64/kernel/setup.c
index 536dce2..f534f49 100644
--- a/arch/arm64/kernel/setup.c
+++ b/arch/arm64/kernel/setup.c
@@ -206,10 +206,15 @@
for_each_memblock(memory, region) {
res = alloc_bootmem_low(sizeof(*res));
- res->name = "System RAM";
+ if (memblock_is_nomap(region)) {
+ res->name = "reserved";
+ res->flags = IORESOURCE_MEM | IORESOURCE_BUSY;
+ } else {
+ res->name = "System RAM";
+ res->flags = IORESOURCE_SYSTEM_RAM | IORESOURCE_BUSY;
+ }
res->start = __pfn_to_phys(memblock_region_memory_base_pfn(region));
res->end = __pfn_to_phys(memblock_region_memory_end_pfn(region)) - 1;
- res->flags = IORESOURCE_SYSTEM_RAM | IORESOURCE_BUSY;
request_resource(&iomem_resource, res);
@@ -228,7 +233,7 @@
{
pr_info("Boot CPU: AArch64 Processor [%08x]\n", read_cpuid_id());
- sprintf(init_utsname()->machine, ELF_PLATFORM);
+ sprintf(init_utsname()->machine, UTS_MACHINE);
init_mm.start_code = (unsigned long) _text;
init_mm.end_code = (unsigned long) _etext;
init_mm.end_data = (unsigned long) _edata;
diff --git a/arch/arm64/kernel/signal.c b/arch/arm64/kernel/signal.c
index a8eafdb..404dd67 100644
--- a/arch/arm64/kernel/signal.c
+++ b/arch/arm64/kernel/signal.c
@@ -402,15 +402,31 @@
asmlinkage void do_notify_resume(struct pt_regs *regs,
unsigned int thread_flags)
{
- if (thread_flags & _TIF_SIGPENDING)
- do_signal(regs);
+ /*
+ * The assembly code enters us with IRQs off, but it hasn't
+ * informed the tracing code of that for efficiency reasons.
+ * Update the trace code with the current status.
+ */
+ trace_hardirqs_off();
+ do {
+ if (thread_flags & _TIF_NEED_RESCHED) {
+ schedule();
+ } else {
+ local_irq_enable();
- if (thread_flags & _TIF_NOTIFY_RESUME) {
- clear_thread_flag(TIF_NOTIFY_RESUME);
- tracehook_notify_resume(regs);
- }
+ if (thread_flags & _TIF_SIGPENDING)
+ do_signal(regs);
- if (thread_flags & _TIF_FOREIGN_FPSTATE)
- fpsimd_restore_current_state();
+ if (thread_flags & _TIF_NOTIFY_RESUME) {
+ clear_thread_flag(TIF_NOTIFY_RESUME);
+ tracehook_notify_resume(regs);
+ }
+ if (thread_flags & _TIF_FOREIGN_FPSTATE)
+ fpsimd_restore_current_state();
+ }
+
+ local_irq_disable();
+ thread_flags = READ_ONCE(current_thread_info()->flags);
+ } while (thread_flags & _TIF_WORK_MASK);
}
diff --git a/arch/arm64/kernel/sleep.S b/arch/arm64/kernel/sleep.S
index ccf79d8..b8799e7 100644
--- a/arch/arm64/kernel/sleep.S
+++ b/arch/arm64/kernel/sleep.S
@@ -73,10 +73,9 @@
str x2, [x0, #SLEEP_STACK_DATA_SYSTEM_REGS + CPU_CTX_SP]
/* find the mpidr_hash */
- ldr x1, =sleep_save_stash
- ldr x1, [x1]
+ ldr_l x1, sleep_save_stash
mrs x7, mpidr_el1
- ldr x9, =mpidr_hash
+ adr_l x9, mpidr_hash
ldr x10, [x9, #MPIDR_HASH_MASK]
/*
* Following code relies on the struct mpidr_hash
@@ -95,36 +94,30 @@
mov x0, #1
ret
ENDPROC(__cpu_suspend_enter)
- .ltorg
+ .pushsection ".idmap.text", "ax"
ENTRY(cpu_resume)
bl el2_setup // if in EL2 drop to EL1 cleanly
+ bl __cpu_setup
/* enable the MMU early - so we can access sleep_save_stash by va */
- adr_l lr, __enable_mmu /* __cpu_setup will return here */
- adr_l x27, _resume_switched /* __enable_mmu will branch here */
- adrp x25, idmap_pg_dir
- adrp x26, swapper_pg_dir
- b __cpu_setup
-ENDPROC(cpu_resume)
-
- .pushsection ".idmap.text", "ax"
-_resume_switched:
+ bl __enable_mmu
ldr x8, =_cpu_resume
br x8
-ENDPROC(_resume_switched)
+ENDPROC(cpu_resume)
.ltorg
.popsection
ENTRY(_cpu_resume)
mrs x1, mpidr_el1
- adrp x8, mpidr_hash
- add x8, x8, #:lo12:mpidr_hash // x8 = struct mpidr_hash phys address
- /* retrieve mpidr_hash members to compute the hash */
+ adr_l x8, mpidr_hash // x8 = struct mpidr_hash virt address
+
+ /* retrieve mpidr_hash members to compute the hash */
ldr x2, [x8, #MPIDR_HASH_MASK]
ldp w3, w4, [x8, #MPIDR_HASH_SHIFTS]
ldp w5, w6, [x8, #(MPIDR_HASH_SHIFTS + 8)]
compute_mpidr_hash x7, x3, x4, x5, x6, x1, x2
- /* x7 contains hash index, let's use it to grab context pointer */
+
+ /* x7 contains hash index, let's use it to grab context pointer */
ldr_l x0, sleep_save_stash
ldr x0, [x0, x7, lsl #3]
add x29, x0, #SLEEP_STACK_DATA_CALLEE_REGS
diff --git a/arch/arm64/kernel/smp.c b/arch/arm64/kernel/smp.c
index d93d433..d3f151c 100644
--- a/arch/arm64/kernel/smp.c
+++ b/arch/arm64/kernel/smp.c
@@ -201,12 +201,6 @@
return ret;
}
-static void smp_store_cpu_info(unsigned int cpuid)
-{
- store_cpu_topology(cpuid);
- numa_store_cpu_info(cpuid);
-}
-
/*
* This is the secondary CPU boot entry. We're using this CPUs
* idle thread stack, but a set of temporary page tables.
@@ -239,7 +233,7 @@
* this CPU ticks all of those. If it doesn't, the CPU will
* fail to come online.
*/
- verify_local_cpu_capabilities();
+ check_local_cpu_capabilities();
if (cpu_ops[cpu]->cpu_postboot)
cpu_ops[cpu]->cpu_postboot();
@@ -254,7 +248,7 @@
*/
notify_cpu_starting(cpu);
- smp_store_cpu_info(cpu);
+ store_cpu_topology(cpu);
/*
* OK, now it's safe to let the boot CPU continue. Wait for
@@ -437,8 +431,19 @@
void __init smp_prepare_boot_cpu(void)
{
set_my_cpu_offset(per_cpu_offset(smp_processor_id()));
+ /*
+ * Initialise the static keys early as they may be enabled by the
+ * cpufeature code.
+ */
+ jump_label_init();
cpuinfo_store_boot_cpu();
save_boot_cpu_run_el();
+ /*
+ * Run the errata work around checks on the boot CPU, once we have
+ * initialised the cpu feature infrastructure from
+ * cpuinfo_store_boot_cpu() above.
+ */
+ update_cpu_errata_workarounds();
}
static u64 __init of_get_cpu_mpidr(struct device_node *dn)
@@ -619,6 +624,7 @@
}
bootcpu_valid = true;
+ early_map_cpu_to_node(0, of_node_to_nid(dn));
/*
* cpu_logical_map has already been
@@ -689,10 +695,13 @@
{
int err;
unsigned int cpu;
+ unsigned int this_cpu;
init_cpu_topology();
- smp_store_cpu_info(smp_processor_id());
+ this_cpu = smp_processor_id();
+ store_cpu_topology(this_cpu);
+ numa_store_cpu_info(this_cpu);
/*
* If UP is mandated by "nosmp" (which implies "maxcpus=0"), don't set
@@ -719,6 +728,7 @@
continue;
set_cpu_present(cpu, true);
+ numa_store_cpu_info(cpu);
}
}
diff --git a/arch/arm64/kernel/smp_spin_table.c b/arch/arm64/kernel/smp_spin_table.c
index 18a71bc..9a00eee 100644
--- a/arch/arm64/kernel/smp_spin_table.c
+++ b/arch/arm64/kernel/smp_spin_table.c
@@ -29,7 +29,8 @@
#include <asm/smp_plat.h>
extern void secondary_holding_pen(void);
-volatile unsigned long secondary_holding_pen_release = INVALID_HWID;
+volatile unsigned long __section(".mmuoff.data.read")
+secondary_holding_pen_release = INVALID_HWID;
static phys_addr_t cpu_release_addr[NR_CPUS];
diff --git a/arch/arm64/kernel/stacktrace.c b/arch/arm64/kernel/stacktrace.c
index d9751a4..c2efddf 100644
--- a/arch/arm64/kernel/stacktrace.c
+++ b/arch/arm64/kernel/stacktrace.c
@@ -43,6 +43,9 @@
unsigned long fp = frame->fp;
unsigned long irq_stack_ptr;
+ if (!tsk)
+ tsk = current;
+
/*
* Switching between stacks is valid when tracing current and in
* non-preemptible context.
@@ -67,7 +70,7 @@
frame->pc = READ_ONCE_NOCHECK(*(unsigned long *)(fp + 8));
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
- if (tsk && tsk->ret_stack &&
+ if (tsk->ret_stack &&
(frame->pc == (unsigned long)return_to_handler)) {
/*
* This is a case where function graph tracer has
@@ -152,6 +155,27 @@
return trace->nr_entries >= trace->max_entries;
}
+void save_stack_trace_regs(struct pt_regs *regs, struct stack_trace *trace)
+{
+ struct stack_trace_data data;
+ struct stackframe frame;
+
+ data.trace = trace;
+ data.skip = trace->skip;
+ data.no_sched_functions = 0;
+
+ frame.fp = regs->regs[29];
+ frame.sp = regs->sp;
+ frame.pc = regs->pc;
+#ifdef CONFIG_FUNCTION_GRAPH_TRACER
+ frame.graph = current->curr_ret_stack;
+#endif
+
+ walk_stackframe(current, &frame, save_trace, &data);
+ if (trace->nr_entries < trace->max_entries)
+ trace->entries[trace->nr_entries++] = ULONG_MAX;
+}
+
void save_stack_trace_tsk(struct task_struct *tsk, struct stack_trace *trace)
{
struct stack_trace_data data;
diff --git a/arch/arm64/kernel/suspend.c b/arch/arm64/kernel/suspend.c
index b616e36..ad73414 100644
--- a/arch/arm64/kernel/suspend.c
+++ b/arch/arm64/kernel/suspend.c
@@ -23,8 +23,8 @@
* time the notifier runs debug exceptions might have been enabled already,
* with HW breakpoints registers content still in an unknown state.
*/
-static void (*hw_breakpoint_restore)(void *);
-void __init cpu_suspend_set_dbg_restorer(void (*hw_bp_restore)(void *))
+static int (*hw_breakpoint_restore)(unsigned int);
+void __init cpu_suspend_set_dbg_restorer(int (*hw_bp_restore)(unsigned int))
{
/* Prevent multiple restore hook initializations */
if (WARN_ON(hw_breakpoint_restore))
@@ -34,6 +34,8 @@
void notrace __cpu_suspend_exit(void)
{
+ unsigned int cpu = smp_processor_id();
+
/*
* We are resuming from reset with the idmap active in TTBR0_EL1.
* We must uninstall the idmap and restore the expected MMU
@@ -45,7 +47,7 @@
* Restore per-cpu offset before any kernel
* subsystem relying on it has a chance to run.
*/
- set_my_cpu_offset(per_cpu_offset(smp_processor_id()));
+ set_my_cpu_offset(per_cpu_offset(cpu));
/*
* Restore HW breakpoint registers to sane values
@@ -53,7 +55,7 @@
* through local_dbg_restore.
*/
if (hw_breakpoint_restore)
- hw_breakpoint_restore(NULL);
+ hw_breakpoint_restore(cpu);
}
/*
diff --git a/arch/arm64/kernel/sys_compat.c b/arch/arm64/kernel/sys_compat.c
index 28c511b..abaf582 100644
--- a/arch/arm64/kernel/sys_compat.c
+++ b/arch/arm64/kernel/sys_compat.c
@@ -94,7 +94,7 @@
* See comment in tls_thread_flush.
*/
barrier();
- asm ("msr tpidrro_el0, %0" : : "r" (regs->regs[0]));
+ write_sysreg(regs->regs[0], tpidrro_el0);
return 0;
default:
diff --git a/arch/arm64/kernel/traps.c b/arch/arm64/kernel/traps.c
index e04f838..5ff020f 100644
--- a/arch/arm64/kernel/traps.c
+++ b/arch/arm64/kernel/traps.c
@@ -142,6 +142,11 @@
unsigned long irq_stack_ptr;
int skip;
+ pr_debug("%s(regs = %p tsk = %p)\n", __func__, regs, tsk);
+
+ if (!tsk)
+ tsk = current;
+
/*
* Switching between stacks is valid when tracing current and in
* non-preemptible context.
@@ -151,11 +156,6 @@
else
irq_stack_ptr = 0;
- pr_debug("%s(regs = %p tsk = %p)\n", __func__, regs, tsk);
-
- if (!tsk)
- tsk = current;
-
if (tsk == current) {
frame.fp = (unsigned long)__builtin_frame_address(0);
frame.sp = current_stack_pointer;
@@ -447,36 +447,29 @@
: "=r" (res) \
: "r" (address), "i" (-EFAULT) )
-asmlinkage void __exception do_sysinstr(unsigned int esr, struct pt_regs *regs)
+static void user_cache_maint_handler(unsigned int esr, struct pt_regs *regs)
{
unsigned long address;
- int ret;
+ int rt = (esr & ESR_ELx_SYS64_ISS_RT_MASK) >> ESR_ELx_SYS64_ISS_RT_SHIFT;
+ int crm = (esr & ESR_ELx_SYS64_ISS_CRM_MASK) >> ESR_ELx_SYS64_ISS_CRM_SHIFT;
+ int ret = 0;
- /* if this is a write with: Op0=1, Op2=1, Op1=3, CRn=7 */
- if ((esr & 0x01fffc01) == 0x0012dc00) {
- int rt = (esr >> 5) & 0x1f;
- int crm = (esr >> 1) & 0x0f;
+ address = (rt == 31) ? 0 : regs->regs[rt];
- address = (rt == 31) ? 0 : regs->regs[rt];
-
- switch (crm) {
- case 11: /* DC CVAU, gets promoted */
- __user_cache_maint("dc civac", address, ret);
- break;
- case 10: /* DC CVAC, gets promoted */
- __user_cache_maint("dc civac", address, ret);
- break;
- case 14: /* DC CIVAC */
- __user_cache_maint("dc civac", address, ret);
- break;
- case 5: /* IC IVAU */
- __user_cache_maint("ic ivau", address, ret);
- break;
- default:
- force_signal_inject(SIGILL, ILL_ILLOPC, regs, 0);
- return;
- }
- } else {
+ switch (crm) {
+ case ESR_ELx_SYS64_ISS_CRM_DC_CVAU: /* DC CVAU, gets promoted */
+ __user_cache_maint("dc civac", address, ret);
+ break;
+ case ESR_ELx_SYS64_ISS_CRM_DC_CVAC: /* DC CVAC, gets promoted */
+ __user_cache_maint("dc civac", address, ret);
+ break;
+ case ESR_ELx_SYS64_ISS_CRM_DC_CIVAC: /* DC CIVAC */
+ __user_cache_maint("dc civac", address, ret);
+ break;
+ case ESR_ELx_SYS64_ISS_CRM_IC_IVAU: /* IC IVAU */
+ __user_cache_maint("ic ivau", address, ret);
+ break;
+ default:
force_signal_inject(SIGILL, ILL_ILLOPC, regs, 0);
return;
}
@@ -487,6 +480,48 @@
regs->pc += 4;
}
+static void ctr_read_handler(unsigned int esr, struct pt_regs *regs)
+{
+ int rt = (esr & ESR_ELx_SYS64_ISS_RT_MASK) >> ESR_ELx_SYS64_ISS_RT_SHIFT;
+
+ regs->regs[rt] = arm64_ftr_reg_ctrel0.sys_val;
+ regs->pc += 4;
+}
+
+struct sys64_hook {
+ unsigned int esr_mask;
+ unsigned int esr_val;
+ void (*handler)(unsigned int esr, struct pt_regs *regs);
+};
+
+static struct sys64_hook sys64_hooks[] = {
+ {
+ .esr_mask = ESR_ELx_SYS64_ISS_EL0_CACHE_OP_MASK,
+ .esr_val = ESR_ELx_SYS64_ISS_EL0_CACHE_OP_VAL,
+ .handler = user_cache_maint_handler,
+ },
+ {
+ /* Trap read access to CTR_EL0 */
+ .esr_mask = ESR_ELx_SYS64_ISS_SYS_OP_MASK,
+ .esr_val = ESR_ELx_SYS64_ISS_SYS_CTR_READ,
+ .handler = ctr_read_handler,
+ },
+ {},
+};
+
+asmlinkage void __exception do_sysinstr(unsigned int esr, struct pt_regs *regs)
+{
+ struct sys64_hook *hook;
+
+ for (hook = sys64_hooks; hook->handler; hook++)
+ if ((hook->esr_mask & esr) == hook->esr_val) {
+ hook->handler(esr, regs);
+ return;
+ }
+
+ force_signal_inject(SIGILL, ILL_ILLOPC, regs, 0);
+}
+
long compat_arm_syscall(struct pt_regs *regs);
asmlinkage long do_ni_syscall(struct pt_regs *regs)
diff --git a/arch/arm64/kernel/vdso.c b/arch/arm64/kernel/vdso.c
index 076312b..a2c2478 100644
--- a/arch/arm64/kernel/vdso.c
+++ b/arch/arm64/kernel/vdso.c
@@ -18,12 +18,13 @@
* Author: Will Deacon <will.deacon@arm.com>
*/
-#include <linux/kernel.h>
+#include <linux/cache.h>
#include <linux/clocksource.h>
#include <linux/elf.h>
#include <linux/err.h>
#include <linux/errno.h>
#include <linux/gfp.h>
+#include <linux/kernel.h>
#include <linux/mm.h>
#include <linux/sched.h>
#include <linux/signal.h>
@@ -37,8 +38,7 @@
#include <asm/vdso_datapage.h>
extern char vdso_start, vdso_end;
-static unsigned long vdso_pages;
-static struct page **vdso_pagelist;
+static unsigned long vdso_pages __ro_after_init;
/*
* The vDSO data page.
@@ -53,9 +53,9 @@
/*
* Create and map the vectors page for AArch32 tasks.
*/
-static struct page *vectors_page[1];
+static struct page *vectors_page[1] __ro_after_init;
-static int alloc_vectors_page(void)
+static int __init alloc_vectors_page(void)
{
extern char __kuser_helper_start[], __kuser_helper_end[];
extern char __aarch32_sigret_code_start[], __aarch32_sigret_code_end[];
@@ -88,7 +88,7 @@
{
struct mm_struct *mm = current->mm;
unsigned long addr = AARCH32_VECTORS_BASE;
- static struct vm_special_mapping spec = {
+ static const struct vm_special_mapping spec = {
.name = "[vectors]",
.pages = vectors_page,
@@ -110,11 +110,19 @@
}
#endif /* CONFIG_COMPAT */
-static struct vm_special_mapping vdso_spec[2];
+static struct vm_special_mapping vdso_spec[2] __ro_after_init = {
+ {
+ .name = "[vvar]",
+ },
+ {
+ .name = "[vdso]",
+ },
+};
static int __init vdso_init(void)
{
int i;
+ struct page **vdso_pagelist;
if (memcmp(&vdso_start, "\177ELF", 4)) {
pr_err("vDSO is not a valid ELF object!\n");
@@ -138,16 +146,8 @@
for (i = 0; i < vdso_pages; i++)
vdso_pagelist[i + 1] = pfn_to_page(PHYS_PFN(__pa(&vdso_start)) + i);
- /* Populate the special mapping structures */
- vdso_spec[0] = (struct vm_special_mapping) {
- .name = "[vvar]",
- .pages = vdso_pagelist,
- };
-
- vdso_spec[1] = (struct vm_special_mapping) {
- .name = "[vdso]",
- .pages = &vdso_pagelist[1],
- };
+ vdso_spec[0].pages = &vdso_pagelist[0];
+ vdso_spec[1].pages = &vdso_pagelist[1];
return 0;
}
@@ -201,7 +201,7 @@
*/
void update_vsyscall(struct timekeeper *tk)
{
- u32 use_syscall = strcmp(tk->tkr_mono.clock->name, "arch_sys_counter");
+ u32 use_syscall = !tk->tkr_mono.clock->archdata.vdso_direct;
++vdso_data->tb_seq_count;
smp_wmb();
diff --git a/arch/arm64/kernel/vmlinux.lds.S b/arch/arm64/kernel/vmlinux.lds.S
index 659963d..5ce9b29 100644
--- a/arch/arm64/kernel/vmlinux.lds.S
+++ b/arch/arm64/kernel/vmlinux.lds.S
@@ -185,6 +185,25 @@
_data = .;
_sdata = .;
RW_DATA_SECTION(L1_CACHE_BYTES, PAGE_SIZE, THREAD_SIZE)
+
+ /*
+ * Data written with the MMU off but read with the MMU on requires
+ * cache lines to be invalidated, discarding up to a Cache Writeback
+ * Granule (CWG) of data from the cache. Keep the section that
+ * requires this type of maintenance to be in its own Cache Writeback
+ * Granule (CWG) area so the cache maintenance operations don't
+ * interfere with adjacent data.
+ */
+ .mmuoff.data.write : ALIGN(SZ_2K) {
+ __mmuoff_data_start = .;
+ *(.mmuoff.data.write)
+ }
+ . = ALIGN(SZ_2K);
+ .mmuoff.data.read : {
+ *(.mmuoff.data.read)
+ __mmuoff_data_end = .;
+ }
+
PECOFF_EDATA_PADDING
_edata = .;
diff --git a/arch/arm64/kvm/hyp.S b/arch/arm64/kvm/hyp.S
index 7ce9315..2726635 100644
--- a/arch/arm64/kvm/hyp.S
+++ b/arch/arm64/kvm/hyp.S
@@ -46,10 +46,6 @@
hvc #0
ldr lr, [sp], #16
ret
-alternative_else
+alternative_else_nop_endif
b __vhe_hyp_call
- nop
- nop
- nop
-alternative_endif
ENDPROC(__kvm_call_hyp)
diff --git a/arch/arm64/kvm/sys_regs.c b/arch/arm64/kvm/sys_regs.c
index e51367d..f302fdb 100644
--- a/arch/arm64/kvm/sys_regs.c
+++ b/arch/arm64/kvm/sys_regs.c
@@ -36,6 +36,7 @@
#include <asm/kvm_host.h>
#include <asm/kvm_mmu.h>
#include <asm/perf_event.h>
+#include <asm/sysreg.h>
#include <trace/events/kvm.h>
@@ -67,11 +68,9 @@
/* Make sure noone else changes CSSELR during this! */
local_irq_disable();
- /* Put value into CSSELR */
- asm volatile("msr csselr_el1, %x0" : : "r" (csselr));
+ write_sysreg(csselr, csselr_el1);
isb();
- /* Read result out of CCSIDR */
- asm volatile("mrs %0, ccsidr_el1" : "=r" (ccsidr));
+ ccsidr = read_sysreg(ccsidr_el1);
local_irq_enable();
return ccsidr;
@@ -174,9 +173,7 @@
if (p->is_write) {
return ignore_write(vcpu, p);
} else {
- u32 val;
- asm volatile("mrs %0, dbgauthstatus_el1" : "=r" (val));
- p->regval = val;
+ p->regval = read_sysreg(dbgauthstatus_el1);
return true;
}
}
@@ -429,10 +426,7 @@
static void reset_amair_el1(struct kvm_vcpu *vcpu, const struct sys_reg_desc *r)
{
- u64 amair;
-
- asm volatile("mrs %0, amair_el1\n" : "=r" (amair));
- vcpu_sys_reg(vcpu, AMAIR_EL1) = amair;
+ vcpu_sys_reg(vcpu, AMAIR_EL1) = read_sysreg(amair_el1);
}
static void reset_mpidr(struct kvm_vcpu *vcpu, const struct sys_reg_desc *r)
@@ -456,8 +450,9 @@
{
u64 pmcr, val;
- asm volatile("mrs %0, pmcr_el0\n" : "=r" (pmcr));
- /* Writable bits of PMCR_EL0 (ARMV8_PMU_PMCR_MASK) is reset to UNKNOWN
+ pmcr = read_sysreg(pmcr_el0);
+ /*
+ * Writable bits of PMCR_EL0 (ARMV8_PMU_PMCR_MASK) are reset to UNKNOWN
* except PMCR.E resetting to zero.
*/
val = ((pmcr & ~ARMV8_PMU_PMCR_MASK)
@@ -557,9 +552,9 @@
return false;
if (!(p->Op2 & 1))
- asm volatile("mrs %0, pmceid0_el0\n" : "=r" (pmceid));
+ pmceid = read_sysreg(pmceid0_el0);
else
- asm volatile("mrs %0, pmceid1_el0\n" : "=r" (pmceid));
+ pmceid = read_sysreg(pmceid1_el0);
p->regval = pmceid;
@@ -1833,11 +1828,7 @@
static void get_##reg(struct kvm_vcpu *v, \
const struct sys_reg_desc *r) \
{ \
- u64 val; \
- \
- asm volatile("mrs %0, " __stringify(reg) "\n" \
- : "=r" (val)); \
- ((struct sys_reg_desc *)r)->val = val; \
+ ((struct sys_reg_desc *)r)->val = read_sysreg(reg); \
}
FUNCTION_INVARIANT(midr_el1)
diff --git a/arch/arm64/kvm/sys_regs_generic_v8.c b/arch/arm64/kvm/sys_regs_generic_v8.c
index ed90578..46af718 100644
--- a/arch/arm64/kvm/sys_regs_generic_v8.c
+++ b/arch/arm64/kvm/sys_regs_generic_v8.c
@@ -26,6 +26,7 @@
#include <asm/kvm_host.h>
#include <asm/kvm_emulate.h>
#include <asm/kvm_coproc.h>
+#include <asm/sysreg.h>
#include <linux/init.h>
#include "sys_regs.h"
@@ -43,10 +44,7 @@
static void reset_actlr(struct kvm_vcpu *vcpu, const struct sys_reg_desc *r)
{
- u64 actlr;
-
- asm volatile("mrs %0, actlr_el1\n" : "=r" (actlr));
- vcpu_sys_reg(vcpu, ACTLR_EL1) = actlr;
+ vcpu_sys_reg(vcpu, ACTLR_EL1) = read_sysreg(actlr_el1);
}
/*
diff --git a/arch/arm64/lib/copy_page.S b/arch/arm64/lib/copy_page.S
index 4c1e700..c3cd65e 100644
--- a/arch/arm64/lib/copy_page.S
+++ b/arch/arm64/lib/copy_page.S
@@ -29,14 +29,11 @@
* x1 - src
*/
ENTRY(copy_page)
-alternative_if_not ARM64_HAS_NO_HW_PREFETCH
- nop
- nop
-alternative_else
+alternative_if ARM64_HAS_NO_HW_PREFETCH
# Prefetch two cache lines ahead.
prfm pldl1strm, [x1, #128]
prfm pldl1strm, [x1, #256]
-alternative_endif
+alternative_else_nop_endif
ldp x2, x3, [x1]
ldp x4, x5, [x1, #16]
@@ -52,11 +49,9 @@
1:
subs x18, x18, #128
-alternative_if_not ARM64_HAS_NO_HW_PREFETCH
- nop
-alternative_else
+alternative_if ARM64_HAS_NO_HW_PREFETCH
prfm pldl1strm, [x1, #384]
-alternative_endif
+alternative_else_nop_endif
stnp x2, x3, [x0]
ldp x2, x3, [x1]
diff --git a/arch/arm64/mm/cache.S b/arch/arm64/mm/cache.S
index 07d7352..58b5a90 100644
--- a/arch/arm64/mm/cache.S
+++ b/arch/arm64/mm/cache.S
@@ -105,19 +105,20 @@
ENDPROC(__clean_dcache_area_pou)
/*
+ * __dma_inv_area(start, size)
+ * - start - virtual start address of region
+ * - size - size in question
+ */
+__dma_inv_area:
+ add x1, x1, x0
+ /* FALLTHROUGH */
+
+/*
* __inval_cache_range(start, end)
* - start - start address of region
* - end - end address of region
*/
ENTRY(__inval_cache_range)
- /* FALLTHROUGH */
-
-/*
- * __dma_inv_range(start, end)
- * - start - virtual start address of region
- * - end - virtual end address of region
- */
-__dma_inv_range:
dcache_line_size x2, x3
sub x3, x2, #1
tst x1, x3 // end cache line aligned?
@@ -136,46 +137,43 @@
dsb sy
ret
ENDPIPROC(__inval_cache_range)
-ENDPROC(__dma_inv_range)
+ENDPROC(__dma_inv_area)
/*
- * __dma_clean_range(start, end)
- * - start - virtual start address of region
- * - end - virtual end address of region
+ * __clean_dcache_area_poc(kaddr, size)
+ *
+ * Ensure that any D-cache lines for the interval [kaddr, kaddr+size)
+ * are cleaned to the PoC.
+ *
+ * - kaddr - kernel address
+ * - size - size in question
*/
-__dma_clean_range:
- dcache_line_size x2, x3
- sub x3, x2, #1
- bic x0, x0, x3
-1:
-alternative_if_not ARM64_WORKAROUND_CLEAN_CACHE
- dc cvac, x0
-alternative_else
- dc civac, x0
-alternative_endif
- add x0, x0, x2
- cmp x0, x1
- b.lo 1b
- dsb sy
- ret
-ENDPROC(__dma_clean_range)
+ENTRY(__clean_dcache_area_poc)
+ /* FALLTHROUGH */
/*
- * __dma_flush_range(start, end)
+ * __dma_clean_area(start, size)
* - start - virtual start address of region
- * - end - virtual end address of region
+ * - size - size in question
*/
-ENTRY(__dma_flush_range)
- dcache_line_size x2, x3
- sub x3, x2, #1
- bic x0, x0, x3
-1: dc civac, x0 // clean & invalidate D / U line
- add x0, x0, x2
- cmp x0, x1
- b.lo 1b
- dsb sy
+__dma_clean_area:
+ dcache_by_line_op cvac, sy, x0, x1, x2, x3
ret
-ENDPIPROC(__dma_flush_range)
+ENDPIPROC(__clean_dcache_area_poc)
+ENDPROC(__dma_clean_area)
+
+/*
+ * __dma_flush_area(start, size)
+ *
+ * clean & invalidate D / U line
+ *
+ * - start - virtual start address of region
+ * - size - size in question
+ */
+ENTRY(__dma_flush_area)
+ dcache_by_line_op civac, sy, x0, x1, x2, x3
+ ret
+ENDPIPROC(__dma_flush_area)
/*
* __dma_map_area(start, size, dir)
@@ -184,10 +182,9 @@
* - dir - DMA direction
*/
ENTRY(__dma_map_area)
- add x1, x1, x0
cmp w2, #DMA_FROM_DEVICE
- b.eq __dma_inv_range
- b __dma_clean_range
+ b.eq __dma_inv_area
+ b __dma_clean_area
ENDPIPROC(__dma_map_area)
/*
@@ -197,8 +194,7 @@
* - dir - DMA direction
*/
ENTRY(__dma_unmap_area)
- add x1, x1, x0
cmp w2, #DMA_TO_DEVICE
- b.ne __dma_inv_range
+ b.ne __dma_inv_area
ret
ENDPIPROC(__dma_unmap_area)
diff --git a/arch/arm64/mm/dma-mapping.c b/arch/arm64/mm/dma-mapping.c
index c4284c4..bdacead 100644
--- a/arch/arm64/mm/dma-mapping.c
+++ b/arch/arm64/mm/dma-mapping.c
@@ -20,6 +20,7 @@
#include <linux/gfp.h>
#include <linux/acpi.h>
#include <linux/bootmem.h>
+#include <linux/cache.h>
#include <linux/export.h>
#include <linux/slab.h>
#include <linux/genalloc.h>
@@ -30,7 +31,7 @@
#include <asm/cacheflush.h>
-static int swiotlb __read_mostly;
+static int swiotlb __ro_after_init;
static pgprot_t __get_dma_pgprot(unsigned long attrs, pgprot_t prot,
bool coherent)
@@ -168,7 +169,7 @@
return ptr;
/* remove any dirty cache lines on the kernel alias */
- __dma_flush_range(ptr, ptr + size);
+ __dma_flush_area(ptr, size);
/* create a coherent mapping */
page = virt_to_page(ptr);
@@ -387,7 +388,7 @@
void *page_addr = page_address(page);
memset(page_addr, 0, atomic_pool_size);
- __dma_flush_range(page_addr, page_addr + atomic_pool_size);
+ __dma_flush_area(page_addr, atomic_pool_size);
atomic_pool = gen_pool_create(PAGE_SHIFT, -1);
if (!atomic_pool)
@@ -548,7 +549,7 @@
/* Thankfully, all cache ops are by VA so we can ignore phys here */
static void flush_page(struct device *dev, const void *virt, phys_addr_t phys)
{
- __dma_flush_range(virt, virt + PAGE_SIZE);
+ __dma_flush_area(virt, PAGE_SIZE);
}
static void *__iommu_alloc_attrs(struct device *dev, size_t size,
diff --git a/arch/arm64/mm/extable.c b/arch/arm64/mm/extable.c
index 81acd47..c9f118c 100644
--- a/arch/arm64/mm/extable.c
+++ b/arch/arm64/mm/extable.c
@@ -2,7 +2,7 @@
* Based on arch/arm/mm/extable.c
*/
-#include <linux/module.h>
+#include <linux/extable.h>
#include <linux/uaccess.h>
int fixup_exception(struct pt_regs *regs)
diff --git a/arch/arm64/mm/fault.c b/arch/arm64/mm/fault.c
index 05d2bd7..53d9159 100644
--- a/arch/arm64/mm/fault.c
+++ b/arch/arm64/mm/fault.c
@@ -18,7 +18,7 @@
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
-#include <linux/module.h>
+#include <linux/extable.h>
#include <linux/signal.h>
#include <linux/mm.h>
#include <linux/hardirq.h>
@@ -251,8 +251,7 @@
good_area:
/*
* Check that the permissions on the VMA allow for the fault which
- * occurred. If we encountered a write or exec fault, we must have
- * appropriate permissions, otherwise we allow any permission.
+ * occurred.
*/
if (!(vma->vm_flags & vm_flags)) {
fault = VM_FAULT_BADACCESS;
@@ -288,7 +287,7 @@
struct task_struct *tsk;
struct mm_struct *mm;
int fault, sig, code;
- unsigned long vm_flags = VM_READ | VM_WRITE | VM_EXEC;
+ unsigned long vm_flags = VM_READ | VM_WRITE;
unsigned int mm_flags = FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE;
if (notify_page_fault(regs, esr))
diff --git a/arch/arm64/mm/flush.c b/arch/arm64/mm/flush.c
index 43a76b0..8377329 100644
--- a/arch/arm64/mm/flush.c
+++ b/arch/arm64/mm/flush.c
@@ -25,8 +25,6 @@
#include <asm/cachetype.h>
#include <asm/tlbflush.h>
-#include "mm.h"
-
void flush_cache_range(struct vm_area_struct *vma, unsigned long start,
unsigned long end)
{
diff --git a/arch/arm64/mm/init.c b/arch/arm64/mm/init.c
index bbb7ee7..21c489b 100644
--- a/arch/arm64/mm/init.c
+++ b/arch/arm64/mm/init.c
@@ -23,6 +23,7 @@
#include <linux/swap.h>
#include <linux/init.h>
#include <linux/bootmem.h>
+#include <linux/cache.h>
#include <linux/mman.h>
#include <linux/nodemask.h>
#include <linux/initrd.h>
@@ -34,6 +35,7 @@
#include <linux/dma-contiguous.h>
#include <linux/efi.h>
#include <linux/swiotlb.h>
+#include <linux/vmalloc.h>
#include <asm/boot.h>
#include <asm/fixmap.h>
@@ -47,16 +49,14 @@
#include <asm/tlb.h>
#include <asm/alternative.h>
-#include "mm.h"
-
/*
* We need to be able to catch inadvertent references to memstart_addr
* that occur (potentially in generic code) before arm64_memblock_init()
* executes, which assigns it its actual value. So use a default value
* that cannot be mistaken for a real physical address.
*/
-s64 memstart_addr __read_mostly = -1;
-phys_addr_t arm64_dma_phys_limit __read_mostly;
+s64 memstart_addr __ro_after_init = -1;
+phys_addr_t arm64_dma_phys_limit __ro_after_init;
#ifdef CONFIG_BLK_DEV_INITRD
static int __init early_initrd(char *p)
@@ -485,7 +485,12 @@
{
free_reserved_area(__va(__pa(__init_begin)), __va(__pa(__init_end)),
0, "unused kernel");
- fixup_init();
+ /*
+ * Unmap the __init region but leave the VM area in place. This
+ * prevents the region from being reused for kernel modules, which
+ * is not supported by kallsyms.
+ */
+ unmap_kernel_range((u64)__init_begin, (u64)(__init_end - __init_begin));
}
#ifdef CONFIG_BLK_DEV_INITRD
diff --git a/arch/arm64/mm/mm.h b/arch/arm64/mm/mm.h
deleted file mode 100644
index 71fe9898..0000000
--- a/arch/arm64/mm/mm.h
+++ /dev/null
@@ -1,2 +0,0 @@
-
-void fixup_init(void);
diff --git a/arch/arm64/mm/mmu.c b/arch/arm64/mm/mmu.c
index 4989948..05615a3 100644
--- a/arch/arm64/mm/mmu.c
+++ b/arch/arm64/mm/mmu.c
@@ -17,6 +17,7 @@
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
+#include <linux/cache.h>
#include <linux/export.h>
#include <linux/kernel.h>
#include <linux/errno.h>
@@ -42,11 +43,9 @@
#include <asm/memblock.h>
#include <asm/mmu_context.h>
-#include "mm.h"
-
u64 idmap_t0sz = TCR_T0SZ(VA_BITS);
-u64 kimage_voffset __read_mostly;
+u64 kimage_voffset __ro_after_init;
EXPORT_SYMBOL(kimage_voffset);
/*
@@ -399,16 +398,6 @@
section_size, PAGE_KERNEL_RO);
}
-void fixup_init(void)
-{
- /*
- * Unmap the __init region but leave the VM area in place. This
- * prevents the region from being reused for kernel modules, which
- * is not supported by kallsyms.
- */
- unmap_kernel_range((u64)__init_begin, (u64)(__init_end - __init_begin));
-}
-
static void __init map_kernel_segment(pgd_t *pgd, void *va_start, void *va_end,
pgprot_t prot, struct vm_struct *vma)
{
diff --git a/arch/arm64/mm/numa.c b/arch/arm64/mm/numa.c
index 5bb15ea..778a985 100644
--- a/arch/arm64/mm/numa.c
+++ b/arch/arm64/mm/numa.c
@@ -17,6 +17,8 @@
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
+#define pr_fmt(fmt) "NUMA: " fmt
+
#include <linux/acpi.h>
#include <linux/bootmem.h>
#include <linux/memblock.h>
@@ -24,6 +26,7 @@
#include <linux/of.h>
#include <asm/acpi.h>
+#include <asm/sections.h>
struct pglist_data *node_data[MAX_NUMNODES] __read_mostly;
EXPORT_SYMBOL(node_data);
@@ -38,10 +41,9 @@
{
if (!opt)
return -EINVAL;
- if (!strncmp(opt, "off", 3)) {
- pr_info("%s\n", "NUMA turned off");
+ if (!strncmp(opt, "off", 3))
numa_off = true;
- }
+
return 0;
}
early_param("numa", numa_parse_early_param);
@@ -93,7 +95,6 @@
*/
static void __init setup_node_to_cpumask_map(void)
{
- unsigned int cpu;
int node;
/* setup nr_node_ids if not done yet */
@@ -106,11 +107,8 @@
cpumask_clear(node_to_cpumask_map[node]);
}
- for_each_possible_cpu(cpu)
- set_cpu_numa_node(cpu, NUMA_NO_NODE);
-
/* cpumask_of_node() will now work */
- pr_debug("NUMA: Node to cpumask map for %d nodes\n", nr_node_ids);
+ pr_debug("Node to cpumask map for %d nodes\n", nr_node_ids);
}
/*
@@ -118,18 +116,77 @@
*/
void numa_store_cpu_info(unsigned int cpu)
{
- map_cpu_to_node(cpu, numa_off ? 0 : cpu_to_node_map[cpu]);
+ map_cpu_to_node(cpu, cpu_to_node_map[cpu]);
}
void __init early_map_cpu_to_node(unsigned int cpu, int nid)
{
/* fallback to node 0 */
- if (nid < 0 || nid >= MAX_NUMNODES)
+ if (nid < 0 || nid >= MAX_NUMNODES || numa_off)
nid = 0;
cpu_to_node_map[cpu] = nid;
+
+ /*
+ * We should set the numa node of cpu0 as soon as possible, because it
+ * has already been set up online before. cpu_to_node(0) will soon be
+ * called.
+ */
+ if (!cpu)
+ set_cpu_numa_node(cpu, nid);
}
+#ifdef CONFIG_HAVE_SETUP_PER_CPU_AREA
+unsigned long __per_cpu_offset[NR_CPUS] __read_mostly;
+EXPORT_SYMBOL(__per_cpu_offset);
+
+static int __init early_cpu_to_node(int cpu)
+{
+ return cpu_to_node_map[cpu];
+}
+
+static int __init pcpu_cpu_distance(unsigned int from, unsigned int to)
+{
+ return node_distance(from, to);
+}
+
+static void * __init pcpu_fc_alloc(unsigned int cpu, size_t size,
+ size_t align)
+{
+ int nid = early_cpu_to_node(cpu);
+
+ return memblock_virt_alloc_try_nid(size, align,
+ __pa(MAX_DMA_ADDRESS), MEMBLOCK_ALLOC_ACCESSIBLE, nid);
+}
+
+static void __init pcpu_fc_free(void *ptr, size_t size)
+{
+ memblock_free_early(__pa(ptr), size);
+}
+
+void __init setup_per_cpu_areas(void)
+{
+ unsigned long delta;
+ unsigned int cpu;
+ int rc;
+
+ /*
+ * Always reserve area for module percpu variables. That's
+ * what the legacy allocator did.
+ */
+ rc = pcpu_embed_first_chunk(PERCPU_MODULE_RESERVE,
+ PERCPU_DYNAMIC_RESERVE, PAGE_SIZE,
+ pcpu_cpu_distance,
+ pcpu_fc_alloc, pcpu_fc_free);
+ if (rc < 0)
+ panic("Failed to initialize percpu areas.");
+
+ delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
+ for_each_possible_cpu(cpu)
+ __per_cpu_offset[cpu] = delta + pcpu_unit_offsets[cpu];
+}
+#endif
+
/**
* numa_add_memblk - Set node id to memblk
* @nid: NUMA node ID of the new memblk
@@ -145,13 +202,13 @@
ret = memblock_set_node(start, (end - start), &memblock.memory, nid);
if (ret < 0) {
- pr_err("NUMA: memblock [0x%llx - 0x%llx] failed to add on node %d\n",
+ pr_err("memblock [0x%llx - 0x%llx] failed to add on node %d\n",
start, (end - 1), nid);
return ret;
}
node_set(nid, numa_nodes_parsed);
- pr_info("NUMA: Adding memblock [0x%llx - 0x%llx] on node %d\n",
+ pr_info("Adding memblock [0x%llx - 0x%llx] on node %d\n",
start, (end - 1), nid);
return ret;
}
@@ -166,19 +223,18 @@
void *nd;
int tnid;
- pr_info("NUMA: Initmem setup node %d [mem %#010Lx-%#010Lx]\n",
- nid, start_pfn << PAGE_SHIFT,
- (end_pfn << PAGE_SHIFT) - 1);
+ pr_info("Initmem setup node %d [mem %#010Lx-%#010Lx]\n",
+ nid, start_pfn << PAGE_SHIFT, (end_pfn << PAGE_SHIFT) - 1);
nd_pa = memblock_alloc_try_nid(nd_size, SMP_CACHE_BYTES, nid);
nd = __va(nd_pa);
/* report and initialize */
- pr_info("NUMA: NODE_DATA [mem %#010Lx-%#010Lx]\n",
+ pr_info("NODE_DATA [mem %#010Lx-%#010Lx]\n",
nd_pa, nd_pa + nd_size - 1);
tnid = early_pfn_to_nid(nd_pa >> PAGE_SHIFT);
if (tnid != nid)
- pr_info("NUMA: NODE_DATA(%d) on node %d\n", nid, tnid);
+ pr_info("NODE_DATA(%d) on node %d\n", nid, tnid);
node_data[nid] = nd;
memset(NODE_DATA(nid), 0, sizeof(pg_data_t));
@@ -235,8 +291,7 @@
numa_distance[i * numa_distance_cnt + j] = i == j ?
LOCAL_DISTANCE : REMOTE_DISTANCE;
- pr_debug("NUMA: Initialized distance table, cnt=%d\n",
- numa_distance_cnt);
+ pr_debug("Initialized distance table, cnt=%d\n", numa_distance_cnt);
return 0;
}
@@ -257,20 +312,20 @@
void __init numa_set_distance(int from, int to, int distance)
{
if (!numa_distance) {
- pr_warn_once("NUMA: Warning: distance table not allocated yet\n");
+ pr_warn_once("Warning: distance table not allocated yet\n");
return;
}
if (from >= numa_distance_cnt || to >= numa_distance_cnt ||
from < 0 || to < 0) {
- pr_warn_once("NUMA: Warning: node ids are out of bound, from=%d to=%d distance=%d\n",
+ pr_warn_once("Warning: node ids are out of bound, from=%d to=%d distance=%d\n",
from, to, distance);
return;
}
if ((u8)distance != distance ||
(from == to && distance != LOCAL_DISTANCE)) {
- pr_warn_once("NUMA: Warning: invalid distance parameter, from=%d to=%d distance=%d\n",
+ pr_warn_once("Warning: invalid distance parameter, from=%d to=%d distance=%d\n",
from, to, distance);
return;
}
@@ -297,7 +352,7 @@
/* Check that valid nid is set to memblks */
for_each_memblock(memory, mblk)
if (mblk->nid == NUMA_NO_NODE || mblk->nid >= MAX_NUMNODES) {
- pr_warn("NUMA: Warning: invalid memblk node %d [mem %#010Lx-%#010Lx]\n",
+ pr_warn("Warning: invalid memblk node %d [mem %#010Lx-%#010Lx]\n",
mblk->nid, mblk->base,
mblk->base + mblk->size - 1);
return -EINVAL;
@@ -335,8 +390,10 @@
if (ret < 0)
return ret;
- if (nodes_empty(numa_nodes_parsed))
+ if (nodes_empty(numa_nodes_parsed)) {
+ pr_info("No NUMA configuration found\n");
return -EINVAL;
+ }
ret = numa_register_nodes();
if (ret < 0)
@@ -344,10 +401,6 @@
setup_node_to_cpumask_map();
- /* init boot processor */
- cpu_to_node_map[0] = 0;
- map_cpu_to_node(0, 0);
-
return 0;
}
@@ -367,10 +420,8 @@
if (numa_off)
pr_info("NUMA disabled\n"); /* Forced off on command line. */
- else
- pr_info("No NUMA configuration found\n");
- pr_info("NUMA: Faking a node at [mem %#018Lx-%#018Lx]\n",
- 0LLU, PFN_PHYS(max_pfn) - 1);
+ pr_info("Faking a node at [mem %#018Lx-%#018Lx]\n",
+ 0LLU, PFN_PHYS(max_pfn) - 1);
for_each_memblock(memory, mblk) {
ret = numa_add_memblk(0, mblk->base, mblk->base + mblk->size);
diff --git a/arch/arm64/mm/pageattr.c b/arch/arm64/mm/pageattr.c
index ca6d268..8def55e 100644
--- a/arch/arm64/mm/pageattr.c
+++ b/arch/arm64/mm/pageattr.c
@@ -139,4 +139,43 @@
__pgprot(0),
__pgprot(PTE_VALID));
}
-#endif
+#ifdef CONFIG_HIBERNATION
+/*
+ * When built with CONFIG_DEBUG_PAGEALLOC and CONFIG_HIBERNATION, this function
+ * is used to determine if a linear map page has been marked as not-valid by
+ * CONFIG_DEBUG_PAGEALLOC. Walk the page table and check the PTE_VALID bit.
+ * This is based on kern_addr_valid(), which almost does what we need.
+ *
+ * Because this is only called on the kernel linear map, p?d_sect() implies
+ * p?d_present(). When debug_pagealloc is enabled, sections mappings are
+ * disabled.
+ */
+bool kernel_page_present(struct page *page)
+{
+ pgd_t *pgd;
+ pud_t *pud;
+ pmd_t *pmd;
+ pte_t *pte;
+ unsigned long addr = (unsigned long)page_address(page);
+
+ pgd = pgd_offset_k(addr);
+ if (pgd_none(*pgd))
+ return false;
+
+ pud = pud_offset(pgd, addr);
+ if (pud_none(*pud))
+ return false;
+ if (pud_sect(*pud))
+ return true;
+
+ pmd = pmd_offset(pud, addr);
+ if (pmd_none(*pmd))
+ return false;
+ if (pmd_sect(*pmd))
+ return true;
+
+ pte = pte_offset_kernel(pmd, addr);
+ return pte_valid(*pte);
+}
+#endif /* CONFIG_HIBERNATION */
+#endif /* CONFIG_DEBUG_PAGEALLOC */
diff --git a/arch/arm64/mm/pgd.c b/arch/arm64/mm/pgd.c
index ae11d4e..371c5f0 100644
--- a/arch/arm64/mm/pgd.c
+++ b/arch/arm64/mm/pgd.c
@@ -26,8 +26,6 @@
#include <asm/page.h>
#include <asm/tlbflush.h>
-#include "mm.h"
-
static struct kmem_cache *pgd_cache;
pgd_t *pgd_alloc(struct mm_struct *mm)
diff --git a/arch/arm64/mm/proc.S b/arch/arm64/mm/proc.S
index 9d37e96..352c73b 100644
--- a/arch/arm64/mm/proc.S
+++ b/arch/arm64/mm/proc.S
@@ -83,6 +83,7 @@
*
* x0: Address of context pointer
*/
+ .pushsection ".idmap.text", "ax"
ENTRY(cpu_do_resume)
ldp x2, x3, [x0]
ldp x4, x5, [x0, #16]
@@ -120,6 +121,7 @@
isb
ret
ENDPROC(cpu_do_resume)
+ .popsection
#endif
/*
@@ -134,17 +136,12 @@
bfi x0, x1, #48, #16 // set the ASID
msr ttbr0_el1, x0 // set TTBR0
isb
-alternative_if_not ARM64_WORKAROUND_CAVIUM_27456
- ret
- nop
- nop
- nop
-alternative_else
+alternative_if ARM64_WORKAROUND_CAVIUM_27456
ic iallu
dsb nsh
isb
+alternative_else_nop_endif
ret
-alternative_endif
ENDPROC(cpu_do_switch_mm)
.pushsection ".idmap.text", "ax"
@@ -181,6 +178,7 @@
* Initialise the processor for turning the MMU on. Return in x0 the
* value of the SCTLR_EL1 register.
*/
+ .pushsection ".idmap.text", "ax"
ENTRY(__cpu_setup)
tlbi vmalle1 // Invalidate local TLB
dsb nsh
@@ -266,3 +264,4 @@
crval:
.word 0xfcffffff // clear
.word 0x34d5d91d // set
+ .popsection
diff --git a/arch/mips/Kconfig b/arch/mips/Kconfig
index 2638856..212ff92 100644
--- a/arch/mips/Kconfig
+++ b/arch/mips/Kconfig
@@ -65,6 +65,7 @@
select ARCH_CLOCKSOURCE_DATA
select HANDLE_DOMAIN_IRQ
select HAVE_EXIT_THREAD
+ select HAVE_REGS_AND_STACK_ACCESS_API
menu "Machine selection"
diff --git a/arch/mips/Kconfig.debug b/arch/mips/Kconfig.debug
index f0e314c..7f975b2 100644
--- a/arch/mips/Kconfig.debug
+++ b/arch/mips/Kconfig.debug
@@ -113,42 +113,6 @@
help
Add several files to the debugfs to test spinlock speed.
-if CPU_MIPSR6
-
-choice
- prompt "Compact branch policy"
- default MIPS_COMPACT_BRANCHES_OPTIMAL
-
-config MIPS_COMPACT_BRANCHES_NEVER
- bool "Never (force delay slot branches)"
- help
- Pass the -mcompact-branches=never flag to the compiler in order to
- force it to always emit branches with delay slots, and make no use
- of the compact branch instructions introduced by MIPSr6. This is
- useful if you suspect there may be an issue with compact branches in
- either the compiler or the CPU.
-
-config MIPS_COMPACT_BRANCHES_OPTIMAL
- bool "Optimal (use where beneficial)"
- help
- Pass the -mcompact-branches=optimal flag to the compiler in order for
- it to make use of compact branch instructions where it deems them
- beneficial, and use branches with delay slots elsewhere. This is the
- default compiler behaviour, and should be used unless you have a
- reason to choose otherwise.
-
-config MIPS_COMPACT_BRANCHES_ALWAYS
- bool "Always (force compact branches)"
- help
- Pass the -mcompact-branches=always flag to the compiler in order to
- force it to always emit compact branches, making no use of branch
- instructions with delay slots. This can result in more compact code
- which may be beneficial in some scenarios.
-
-endchoice
-
-endif # CPU_MIPSR6
-
config SCACHE_DEBUGFS
bool "L2 cache debugfs entries"
depends on DEBUG_FS
diff --git a/arch/mips/Makefile b/arch/mips/Makefile
index efd7a9d..598ab29 100644
--- a/arch/mips/Makefile
+++ b/arch/mips/Makefile
@@ -203,10 +203,6 @@
toolchain-virt := $(call cc-option-yn,$(mips-cflags) -mvirt)
cflags-$(toolchain-virt) += -DTOOLCHAIN_SUPPORTS_VIRT
-cflags-$(CONFIG_MIPS_COMPACT_BRANCHES_NEVER) += -mcompact-branches=never
-cflags-$(CONFIG_MIPS_COMPACT_BRANCHES_OPTIMAL) += -mcompact-branches=optimal
-cflags-$(CONFIG_MIPS_COMPACT_BRANCHES_ALWAYS) += -mcompact-branches=always
-
#
# Firmware support
#
diff --git a/arch/mips/ath79/clock.c b/arch/mips/ath79/clock.c
index 2e73784..cc3a1e3 100644
--- a/arch/mips/ath79/clock.c
+++ b/arch/mips/ath79/clock.c
@@ -96,7 +96,7 @@
struct clk *clk;
clk = clk_register_fixed_factor(NULL, name, parent_name, 0, mult, div);
- if (!clk)
+ if (IS_ERR(clk))
panic("failed to allocate %s clock structure", name);
return clk;
diff --git a/arch/mips/cavium-octeon/octeon-irq.c b/arch/mips/cavium-octeon/octeon-irq.c
index 5a9b87b..c1eb1ff 100644
--- a/arch/mips/cavium-octeon/octeon-irq.c
+++ b/arch/mips/cavium-octeon/octeon-irq.c
@@ -1619,6 +1619,12 @@
return -ENOMEM;
}
+ /*
+ * Clear the OF_POPULATED flag that was set by of_irq_init()
+ * so that all GPIO devices will be probed.
+ */
+ of_node_clear_flag(gpio_node, OF_POPULATED);
+
return 0;
}
/*
diff --git a/arch/mips/cavium-octeon/octeon-platform.c b/arch/mips/cavium-octeon/octeon-platform.c
index b31fbc9..37a932d 100644
--- a/arch/mips/cavium-octeon/octeon-platform.c
+++ b/arch/mips/cavium-octeon/octeon-platform.c
@@ -1059,7 +1059,7 @@
{
return of_platform_bus_probe(NULL, octeon_ids, NULL);
}
-device_initcall(octeon_publish_devices);
+arch_initcall(octeon_publish_devices);
MODULE_AUTHOR("David Daney <ddaney@caviumnetworks.com>");
MODULE_LICENSE("GPL");
diff --git a/arch/mips/dec/int-handler.S b/arch/mips/dec/int-handler.S
index d7b9918..1910223 100644
--- a/arch/mips/dec/int-handler.S
+++ b/arch/mips/dec/int-handler.S
@@ -146,7 +146,25 @@
/*
* Find irq with highest priority
*/
- PTR_LA t1,cpu_mask_nr_tbl
+ # open coded PTR_LA t1, cpu_mask_nr_tbl
+#if (_MIPS_SZPTR == 32)
+ # open coded la t1, cpu_mask_nr_tbl
+ lui t1, %hi(cpu_mask_nr_tbl)
+ addiu t1, %lo(cpu_mask_nr_tbl)
+
+#endif
+#if (_MIPS_SZPTR == 64)
+ # open coded dla t1, cpu_mask_nr_tbl
+ .set push
+ .set noat
+ lui t1, %highest(cpu_mask_nr_tbl)
+ lui AT, %hi(cpu_mask_nr_tbl)
+ daddiu t1, t1, %higher(cpu_mask_nr_tbl)
+ daddiu AT, AT, %lo(cpu_mask_nr_tbl)
+ dsll t1, 32
+ daddu t1, t1, AT
+ .set pop
+#endif
1: lw t2,(t1)
nop
and t2,t0
@@ -195,7 +213,25 @@
/*
* Find irq with highest priority
*/
- PTR_LA t1,asic_mask_nr_tbl
+ # open coded PTR_LA t1,asic_mask_nr_tbl
+#if (_MIPS_SZPTR == 32)
+ # open coded la t1, asic_mask_nr_tbl
+ lui t1, %hi(asic_mask_nr_tbl)
+ addiu t1, %lo(asic_mask_nr_tbl)
+
+#endif
+#if (_MIPS_SZPTR == 64)
+ # open coded dla t1, asic_mask_nr_tbl
+ .set push
+ .set noat
+ lui t1, %highest(asic_mask_nr_tbl)
+ lui AT, %hi(asic_mask_nr_tbl)
+ daddiu t1, t1, %higher(asic_mask_nr_tbl)
+ daddiu AT, AT, %lo(asic_mask_nr_tbl)
+ dsll t1, 32
+ daddu t1, t1, AT
+ .set pop
+#endif
2: lw t2,(t1)
nop
and t2,t0
diff --git a/arch/mips/include/asm/asmmacro.h b/arch/mips/include/asm/asmmacro.h
index 56584a6..83054f7 100644
--- a/arch/mips/include/asm/asmmacro.h
+++ b/arch/mips/include/asm/asmmacro.h
@@ -157,6 +157,7 @@
ldc1 $f28, THREAD_FPR28(\thread)
ldc1 $f30, THREAD_FPR30(\thread)
ctc1 \tmp, fcr31
+ .set pop
.endm
.macro fpu_restore_16odd thread
diff --git a/arch/mips/include/asm/mach-cavium-octeon/mangle-port.h b/arch/mips/include/asm/mach-cavium-octeon/mangle-port.h
index 0cf5ac1..8ff2cbdf 100644
--- a/arch/mips/include/asm/mach-cavium-octeon/mangle-port.h
+++ b/arch/mips/include/asm/mach-cavium-octeon/mangle-port.h
@@ -15,8 +15,8 @@
static inline bool __should_swizzle_bits(volatile void *a)
{
extern const bool octeon_should_swizzle_table[];
+ u64 did = ((u64)(uintptr_t)a >> 40) & 0xff;
- unsigned long did = ((unsigned long)a >> 40) & 0xff;
return octeon_should_swizzle_table[did];
}
@@ -29,7 +29,7 @@
#define __should_swizzle_bits(a) false
-static inline bool __should_swizzle_addr(unsigned long p)
+static inline bool __should_swizzle_addr(u64 p)
{
/* boot bus? */
return ((p >> 40) & 0xff) == 0;
diff --git a/arch/mips/include/asm/mach-paravirt/kernel-entry-init.h b/arch/mips/include/asm/mach-paravirt/kernel-entry-init.h
index 2f82bfa..c9f5769 100644
--- a/arch/mips/include/asm/mach-paravirt/kernel-entry-init.h
+++ b/arch/mips/include/asm/mach-paravirt/kernel-entry-init.h
@@ -11,11 +11,13 @@
#define CP0_EBASE $15, 1
.macro kernel_entry_setup
+#ifdef CONFIG_SMP
mfc0 t0, CP0_EBASE
andi t0, t0, 0x3ff # CPUNum
beqz t0, 1f
# CPUs other than zero goto smp_bootstrap
j smp_bootstrap
+#endif /* CONFIG_SMP */
1:
.endm
diff --git a/arch/mips/include/asm/mips-cm.h b/arch/mips/include/asm/mips-cm.h
index 58e7874..4fafeef 100644
--- a/arch/mips/include/asm/mips-cm.h
+++ b/arch/mips/include/asm/mips-cm.h
@@ -458,10 +458,21 @@
static inline unsigned int mips_cm_max_vp_width(void)
{
extern int smp_num_siblings;
+ uint32_t cfg;
if (mips_cm_revision() >= CM_REV_CM3)
return read_gcr_sys_config2() & CM_GCR_SYS_CONFIG2_MAXVPW_MSK;
+ if (mips_cm_present()) {
+ /*
+ * We presume that all cores in the system will have the same
+ * number of VP(E)s, and if that ever changes then this will
+ * need revisiting.
+ */
+ cfg = read_gcr_cl_config() & CM_GCR_Cx_CONFIG_PVPE_MSK;
+ return (cfg >> CM_GCR_Cx_CONFIG_PVPE_SHF) + 1;
+ }
+
if (IS_ENABLED(CONFIG_SMP))
return smp_num_siblings;
diff --git a/arch/mips/include/asm/mipsregs.h b/arch/mips/include/asm/mipsregs.h
index def9d8d..7dd2dd4 100644
--- a/arch/mips/include/asm/mipsregs.h
+++ b/arch/mips/include/asm/mipsregs.h
@@ -660,8 +660,6 @@
#define MIPS_CONF7_IAR (_ULCAST_(1) << 10)
#define MIPS_CONF7_AR (_ULCAST_(1) << 16)
-/* FTLB probability bits for R6 */
-#define MIPS_CONF7_FTLBP_SHIFT (18)
/* WatchLo* register definitions */
#define MIPS_WATCHLO_IRW (_ULCAST_(0x7) << 0)
diff --git a/arch/mips/include/asm/uprobes.h b/arch/mips/include/asm/uprobes.h
index 34c325c..70a4a2f 100644
--- a/arch/mips/include/asm/uprobes.h
+++ b/arch/mips/include/asm/uprobes.h
@@ -36,7 +36,6 @@
unsigned long resume_epc;
u32 insn[2];
u32 ixol[2];
- union mips_instruction orig_inst[MAX_UINSN_BYTES / 4];
};
struct arch_uprobe_task {
diff --git a/arch/mips/kernel/cpu-probe.c b/arch/mips/kernel/cpu-probe.c
index a88d442..dd31754 100644
--- a/arch/mips/kernel/cpu-probe.c
+++ b/arch/mips/kernel/cpu-probe.c
@@ -352,7 +352,12 @@
static int mips_ftlb_disabled;
static int mips_has_ftlb_configured;
-static int set_ftlb_enable(struct cpuinfo_mips *c, int enable);
+enum ftlb_flags {
+ FTLB_EN = 1 << 0,
+ FTLB_SET_PROB = 1 << 1,
+};
+
+static int set_ftlb_enable(struct cpuinfo_mips *c, enum ftlb_flags flags);
static int __init ftlb_disable(char *s)
{
@@ -371,8 +376,6 @@
return 1;
}
- back_to_back_c0_hazard();
-
config4 = read_c0_config4();
/* Check that FTLB has been disabled */
@@ -531,7 +534,7 @@
return 3;
}
-static int set_ftlb_enable(struct cpuinfo_mips *c, int enable)
+static int set_ftlb_enable(struct cpuinfo_mips *c, enum ftlb_flags flags)
{
unsigned int config;
@@ -542,33 +545,33 @@
case CPU_P6600:
/* proAptiv & related cores use Config6 to enable the FTLB */
config = read_c0_config6();
- /* Clear the old probability value */
- config &= ~(3 << MIPS_CONF6_FTLBP_SHIFT);
- if (enable)
- /* Enable FTLB */
- write_c0_config6(config |
- (calculate_ftlb_probability(c)
- << MIPS_CONF6_FTLBP_SHIFT)
- | MIPS_CONF6_FTLBEN);
+
+ if (flags & FTLB_EN)
+ config |= MIPS_CONF6_FTLBEN;
else
- /* Disable FTLB */
- write_c0_config6(config & ~MIPS_CONF6_FTLBEN);
+ config &= ~MIPS_CONF6_FTLBEN;
+
+ if (flags & FTLB_SET_PROB) {
+ config &= ~(3 << MIPS_CONF6_FTLBP_SHIFT);
+ config |= calculate_ftlb_probability(c)
+ << MIPS_CONF6_FTLBP_SHIFT;
+ }
+
+ write_c0_config6(config);
+ back_to_back_c0_hazard();
break;
case CPU_I6400:
- /* I6400 & related cores use Config7 to configure FTLB */
- config = read_c0_config7();
- /* Clear the old probability value */
- config &= ~(3 << MIPS_CONF7_FTLBP_SHIFT);
- write_c0_config7(config | (calculate_ftlb_probability(c)
- << MIPS_CONF7_FTLBP_SHIFT));
- break;
+ /* There's no way to disable the FTLB */
+ if (!(flags & FTLB_EN))
+ return 1;
+ return 0;
case CPU_LOONGSON3:
/* Flush ITLB, DTLB, VTLB and FTLB */
write_c0_diag(LOONGSON_DIAG_ITLB | LOONGSON_DIAG_DTLB |
LOONGSON_DIAG_VTLB | LOONGSON_DIAG_FTLB);
/* Loongson-3 cores use Config6 to enable the FTLB */
config = read_c0_config6();
- if (enable)
+ if (flags & FTLB_EN)
/* Enable FTLB */
write_c0_config6(config & ~MIPS_CONF6_FTLBDIS);
else
@@ -788,6 +791,7 @@
PAGE_SIZE, config4);
/* Switch FTLB off */
set_ftlb_enable(c, 0);
+ mips_ftlb_disabled = 1;
break;
}
c->tlbsizeftlbsets = 1 <<
@@ -852,7 +856,7 @@
c->scache.flags = MIPS_CACHE_NOT_PRESENT;
/* Enable FTLB if present and not disabled */
- set_ftlb_enable(c, !mips_ftlb_disabled);
+ set_ftlb_enable(c, mips_ftlb_disabled ? 0 : FTLB_EN);
ok = decode_config0(c); /* Read Config registers. */
BUG_ON(!ok); /* Arch spec violation! */
@@ -902,6 +906,9 @@
}
}
+ /* configure the FTLB write probability */
+ set_ftlb_enable(c, (mips_ftlb_disabled ? 0 : FTLB_EN) | FTLB_SET_PROB);
+
mips_probe_watch_registers(c);
#ifndef CONFIG_MIPS_CPS
diff --git a/arch/mips/kernel/genex.S b/arch/mips/kernel/genex.S
index 17326a9..dc0b296 100644
--- a/arch/mips/kernel/genex.S
+++ b/arch/mips/kernel/genex.S
@@ -142,9 +142,8 @@
PTR_LA k1, __r4k_wait
ori k0, 0x1f /* 32 byte rollback region */
xori k0, 0x1f
- bne k0, k1, 9f
+ bne k0, k1, \handler
MTC0 k0, CP0_EPC
-9:
.set pop
.endm
diff --git a/arch/mips/kernel/mips-r2-to-r6-emul.c b/arch/mips/kernel/mips-r2-to-r6-emul.c
index c3372ca..0a7e10b 100644
--- a/arch/mips/kernel/mips-r2-to-r6-emul.c
+++ b/arch/mips/kernel/mips-r2-to-r6-emul.c
@@ -1164,7 +1164,9 @@
regs->regs[31] = r31;
regs->cp0_epc = epc;
if (!used_math()) { /* First time FPU user. */
+ preempt_disable();
err = init_fpu();
+ preempt_enable();
set_used_math();
}
lose_fpu(1); /* Save FPU state for the emulator. */
diff --git a/arch/mips/kernel/process.c b/arch/mips/kernel/process.c
index 7429ad0..d2d0615 100644
--- a/arch/mips/kernel/process.c
+++ b/arch/mips/kernel/process.c
@@ -605,14 +605,14 @@
return -EOPNOTSUPP;
/* Avoid inadvertently triggering emulation */
- if ((value & PR_FP_MODE_FR) && cpu_has_fpu &&
- !(current_cpu_data.fpu_id & MIPS_FPIR_F64))
+ if ((value & PR_FP_MODE_FR) && raw_cpu_has_fpu &&
+ !(raw_current_cpu_data.fpu_id & MIPS_FPIR_F64))
return -EOPNOTSUPP;
- if ((value & PR_FP_MODE_FRE) && cpu_has_fpu && !cpu_has_fre)
+ if ((value & PR_FP_MODE_FRE) && raw_cpu_has_fpu && !cpu_has_fre)
return -EOPNOTSUPP;
/* FR = 0 not supported in MIPS R6 */
- if (!(value & PR_FP_MODE_FR) && cpu_has_fpu && cpu_has_mips_r6)
+ if (!(value & PR_FP_MODE_FR) && raw_cpu_has_fpu && cpu_has_mips_r6)
return -EOPNOTSUPP;
/* Proceed with the mode switch */
diff --git a/arch/mips/kernel/setup.c b/arch/mips/kernel/setup.c
index 36cf8d6..0d57909 100644
--- a/arch/mips/kernel/setup.c
+++ b/arch/mips/kernel/setup.c
@@ -87,6 +87,13 @@
int x = boot_mem_map.nr_map;
int i;
+ /*
+ * If the region reaches the top of the physical address space, adjust
+ * the size slightly so that (start + size) doesn't overflow
+ */
+ if (start + size - 1 == (phys_addr_t)ULLONG_MAX)
+ --size;
+
/* Sanity check */
if (start + size < start) {
pr_warn("Trying to add an invalid memory region, skipped\n");
@@ -757,7 +764,6 @@
device_tree_init();
sparse_init();
plat_swiotlb_setup();
- paging_init();
dma_contiguous_reserve(PFN_PHYS(max_low_pfn));
/* Tell bootmem about cma reserved memblock section */
@@ -870,6 +876,7 @@
prefill_possible_map();
cpu_cache_init();
+ paging_init();
}
unsigned long kernelsp[NR_CPUS];
diff --git a/arch/mips/kernel/smp-cps.c b/arch/mips/kernel/smp-cps.c
index e9d9fc6..6183ad8 100644
--- a/arch/mips/kernel/smp-cps.c
+++ b/arch/mips/kernel/smp-cps.c
@@ -513,7 +513,7 @@
* in which case the CPC will refuse to power down the core.
*/
do {
- mips_cm_lock_other(core, vpe_id);
+ mips_cm_lock_other(core, 0);
mips_cpc_lock_other(core);
stat = read_cpc_co_stat_conf();
stat &= CPC_Cx_STAT_CONF_SEQSTATE_MSK;
diff --git a/arch/mips/kernel/smp.c b/arch/mips/kernel/smp.c
index f95f094..b0baf48 100644
--- a/arch/mips/kernel/smp.c
+++ b/arch/mips/kernel/smp.c
@@ -322,6 +322,9 @@
cpumask_set_cpu(cpu, &cpu_coherent_mask);
notify_cpu_starting(cpu);
+ cpumask_set_cpu(cpu, &cpu_callin_map);
+ synchronise_count_slave(cpu);
+
set_cpu_online(cpu, true);
set_cpu_sibling_map(cpu);
@@ -329,10 +332,6 @@
calculate_cpu_foreign_map();
- cpumask_set_cpu(cpu, &cpu_callin_map);
-
- synchronise_count_slave(cpu);
-
/*
* irq will be enabled in ->smp_finish(), enabling it too early
* is dangerous.
diff --git a/arch/mips/kernel/uprobes.c b/arch/mips/kernel/uprobes.c
index 8452d93..4c7c155 100644
--- a/arch/mips/kernel/uprobes.c
+++ b/arch/mips/kernel/uprobes.c
@@ -157,7 +157,6 @@
int arch_uprobe_pre_xol(struct arch_uprobe *aup, struct pt_regs *regs)
{
struct uprobe_task *utask = current->utask;
- union mips_instruction insn;
/*
* Now find the EPC where to resume after the breakpoint has been
@@ -168,10 +167,10 @@
unsigned long epc;
epc = regs->cp0_epc;
- __compute_return_epc_for_insn(regs, insn);
+ __compute_return_epc_for_insn(regs,
+ (union mips_instruction) aup->insn[0]);
aup->resume_epc = regs->cp0_epc;
}
-
utask->autask.saved_trap_nr = current->thread.trap_nr;
current->thread.trap_nr = UPROBE_TRAP_NR;
regs->cp0_epc = current->utask->xol_vaddr;
@@ -222,7 +221,7 @@
return NOTIFY_DONE;
switch (val) {
- case DIE_BREAK:
+ case DIE_UPROBE:
if (uprobe_pre_sstep_notifier(regs))
return NOTIFY_STOP;
break;
@@ -257,7 +256,7 @@
ra = regs->regs[31];
/* Replace the return address with the trampoline address */
- regs->regs[31] = ra;
+ regs->regs[31] = trampoline_vaddr;
return ra;
}
@@ -280,24 +279,6 @@
return uprobe_write_opcode(mm, vaddr, UPROBE_SWBP_INSN);
}
-/**
- * set_orig_insn - Restore the original instruction.
- * @mm: the probed process address space.
- * @auprobe: arch specific probepoint information.
- * @vaddr: the virtual address to insert the opcode.
- *
- * For mm @mm, restore the original opcode (opcode) at @vaddr.
- * Return 0 (success) or a negative errno.
- *
- * This overrides the weak version in kernel/events/uprobes.c.
- */
-int set_orig_insn(struct arch_uprobe *auprobe, struct mm_struct *mm,
- unsigned long vaddr)
-{
- return uprobe_write_opcode(mm, vaddr,
- *(uprobe_opcode_t *)&auprobe->orig_inst[0].word);
-}
-
void __weak arch_uprobe_copy_ixol(struct page *page, unsigned long vaddr,
void *src, unsigned long len)
{
diff --git a/arch/mips/kernel/vdso.c b/arch/mips/kernel/vdso.c
index 9abe447..f9dbfb1 100644
--- a/arch/mips/kernel/vdso.c
+++ b/arch/mips/kernel/vdso.c
@@ -39,16 +39,16 @@
static void __init init_vdso_image(struct mips_vdso_image *image)
{
unsigned long num_pages, i;
+ unsigned long data_pfn;
BUG_ON(!PAGE_ALIGNED(image->data));
BUG_ON(!PAGE_ALIGNED(image->size));
num_pages = image->size / PAGE_SIZE;
- for (i = 0; i < num_pages; i++) {
- image->mapping.pages[i] =
- virt_to_page(image->data + (i * PAGE_SIZE));
- }
+ data_pfn = __phys_to_pfn(__pa_symbol(image->data));
+ for (i = 0; i < num_pages; i++)
+ image->mapping.pages[i] = pfn_to_page(data_pfn + i);
}
static int __init init_vdso(void)
diff --git a/arch/mips/math-emu/dsemul.c b/arch/mips/math-emu/dsemul.c
index 72a4642..4a094f7 100644
--- a/arch/mips/math-emu/dsemul.c
+++ b/arch/mips/math-emu/dsemul.c
@@ -298,5 +298,6 @@
/* Set EPC to return to post-branch instruction */
xcp->cp0_epc = current->thread.bd_emu_cont_pc;
pr_debug("dsemulret to 0x%08lx\n", xcp->cp0_epc);
+ MIPS_FPU_EMU_INC_STATS(ds_emul);
return true;
}
diff --git a/arch/mips/mm/c-r4k.c b/arch/mips/mm/c-r4k.c
index cd72805..fa7d8d3 100644
--- a/arch/mips/mm/c-r4k.c
+++ b/arch/mips/mm/c-r4k.c
@@ -800,7 +800,7 @@
* If address-based cache ops don't require an SMP call, then
* use them exclusively for small flushes.
*/
- size = start - end;
+ size = end - start;
cache_size = icache_size;
if (!cpu_has_ic_fills_f_dc) {
size *= 2;
diff --git a/arch/mips/mm/init.c b/arch/mips/mm/init.c
index a5509e7..72f7478 100644
--- a/arch/mips/mm/init.c
+++ b/arch/mips/mm/init.c
@@ -261,7 +261,6 @@
{
struct maar_config cfg[BOOT_MEM_MAP_MAX];
unsigned i, num_configured, num_cfg = 0;
- phys_addr_t skip;
for (i = 0; i < boot_mem_map.nr_map; i++) {
switch (boot_mem_map.map[i].type) {
@@ -272,14 +271,14 @@
continue;
}
- skip = 0x10000 - (boot_mem_map.map[i].addr & 0xffff);
-
+ /* Round lower up */
cfg[num_cfg].lower = boot_mem_map.map[i].addr;
- cfg[num_cfg].lower += skip;
+ cfg[num_cfg].lower = (cfg[num_cfg].lower + 0xffff) & ~0xffff;
- cfg[num_cfg].upper = cfg[num_cfg].lower;
- cfg[num_cfg].upper += boot_mem_map.map[i].size - 1;
- cfg[num_cfg].upper -= skip;
+ /* Round upper down */
+ cfg[num_cfg].upper = boot_mem_map.map[i].addr +
+ boot_mem_map.map[i].size;
+ cfg[num_cfg].upper = (cfg[num_cfg].upper & ~0xffff) - 1;
cfg[num_cfg].attrs = MIPS_MAAR_S;
num_cfg++;
@@ -441,6 +440,9 @@
#ifdef CONFIG_HIGHMEM
unsigned long tmp;
+ if (cpu_has_dc_aliases)
+ return;
+
for (tmp = highstart_pfn; tmp < highend_pfn; tmp++) {
struct page *page = pfn_to_page(tmp);
diff --git a/arch/mips/mti-malta/malta-setup.c b/arch/mips/mti-malta/malta-setup.c
index ec5b216..7e7364b 100644
--- a/arch/mips/mti-malta/malta-setup.c
+++ b/arch/mips/mti-malta/malta-setup.c
@@ -39,6 +39,9 @@
#include <linux/console.h>
#endif
+#define ROCIT_CONFIG_GEN0 0x1f403000
+#define ROCIT_CONFIG_GEN0_PCI_IOCU BIT(7)
+
extern void malta_be_init(void);
extern int malta_be_handler(struct pt_regs *regs, int is_fixup);
@@ -107,6 +110,8 @@
static int __init plat_enable_iocoherency(void)
{
int supported = 0;
+ u32 cfg;
+
if (mips_revision_sconid == MIPS_REVISION_SCON_BONITO) {
if (BONITO_PCICACHECTRL & BONITO_PCICACHECTRL_CPUCOH_PRES) {
BONITO_PCICACHECTRL |= BONITO_PCICACHECTRL_CPUCOH_EN;
@@ -129,7 +134,8 @@
} else if (mips_cm_numiocu() != 0) {
/* Nothing special needs to be done to enable coherency */
pr_info("CMP IOCU detected\n");
- if ((*(unsigned int *)0xbf403000 & 0x81) != 0x81) {
+ cfg = __raw_readl((u32 *)CKSEG1ADDR(ROCIT_CONFIG_GEN0));
+ if (!(cfg & ROCIT_CONFIG_GEN0_PCI_IOCU)) {
pr_crit("IOCU OPERATION DISABLED BY SWITCH - DEFAULTING TO SW IO COHERENCY\n");
return 0;
}
diff --git a/arch/powerpc/platforms/powernv/pci-ioda.c b/arch/powerpc/platforms/powernv/pci-ioda.c
index bc0c91e..38a5c65 100644
--- a/arch/powerpc/platforms/powernv/pci-ioda.c
+++ b/arch/powerpc/platforms/powernv/pci-ioda.c
@@ -124,6 +124,13 @@
r->start < (phb->ioda.m64_base + phb->ioda.m64_size));
}
+static inline bool pnv_pci_is_m64_flags(unsigned long resource_flags)
+{
+ unsigned long flags = (IORESOURCE_MEM_64 | IORESOURCE_PREFETCH);
+
+ return (resource_flags & flags) == flags;
+}
+
static struct pnv_ioda_pe *pnv_ioda_init_pe(struct pnv_phb *phb, int pe_no)
{
phb->ioda.pe_array[pe_no].phb = phb;
@@ -2871,7 +2878,7 @@
res = &pdev->resource[i + PCI_IOV_RESOURCES];
if (!res->flags || res->parent)
continue;
- if (!pnv_pci_is_m64(phb, res)) {
+ if (!pnv_pci_is_m64_flags(res->flags)) {
dev_warn(&pdev->dev, "Don't support SR-IOV with"
" non M64 VF BAR%d: %pR. \n",
i, res);
@@ -3096,7 +3103,7 @@
* alignment for any 64-bit resource, PCIe doesn't care and
* bridges only do 64-bit prefetchable anyway.
*/
- if (phb->ioda.m64_segsize && (type & IORESOURCE_MEM_64))
+ if (phb->ioda.m64_segsize && pnv_pci_is_m64_flags(type))
return phb->ioda.m64_segsize;
if (type & IORESOURCE_MEM)
return phb->ioda.m32_segsize;
diff --git a/arch/sh/include/asm/atomic-llsc.h b/arch/sh/include/asm/atomic-llsc.h
index caea2c4..1d159ce 100644
--- a/arch/sh/include/asm/atomic-llsc.h
+++ b/arch/sh/include/asm/atomic-llsc.h
@@ -60,7 +60,7 @@
" movco.l %0, @%3 \n" \
" bf 1b \n" \
" synco \n" \
- : "=&z" (temp), "=&z" (res) \
+ : "=&z" (temp), "=&r" (res) \
: "r" (i), "r" (&v->counter) \
: "t"); \
\
diff --git a/arch/sparc/include/asm/page_64.h b/arch/sparc/include/asm/page_64.h
index 8c2a8c9..c1263fc 100644
--- a/arch/sparc/include/asm/page_64.h
+++ b/arch/sparc/include/asm/page_64.h
@@ -25,6 +25,7 @@
#define HPAGE_MASK (~(HPAGE_SIZE - 1UL))
#define HUGETLB_PAGE_ORDER (HPAGE_SHIFT - PAGE_SHIFT)
#define HAVE_ARCH_HUGETLB_UNMAPPED_AREA
+#define REAL_HPAGE_PER_HPAGE (_AC(1,UL) << (HPAGE_SHIFT - REAL_HPAGE_SHIFT))
#endif
#ifndef __ASSEMBLY__
diff --git a/arch/sparc/include/asm/smp_64.h b/arch/sparc/include/asm/smp_64.h
index 26d9e77..ce2233f 100644
--- a/arch/sparc/include/asm/smp_64.h
+++ b/arch/sparc/include/asm/smp_64.h
@@ -43,6 +43,7 @@
int hard_smp_processor_id(void);
#define raw_smp_processor_id() (current_thread_info()->cpu)
+void smp_fill_in_cpu_possible_map(void);
void smp_fill_in_sib_core_maps(void);
void cpu_play_dead(void);
@@ -72,6 +73,7 @@
#define smp_fill_in_sib_core_maps() do { } while (0)
#define smp_fetch_global_regs() do { } while (0)
#define smp_fetch_global_pmu() do { } while (0)
+#define smp_fill_in_cpu_possible_map() do { } while (0)
#endif /* !(CONFIG_SMP) */
diff --git a/arch/sparc/kernel/setup_64.c b/arch/sparc/kernel/setup_64.c
index 599f120..6b7331d 100644
--- a/arch/sparc/kernel/setup_64.c
+++ b/arch/sparc/kernel/setup_64.c
@@ -31,6 +31,7 @@
#include <linux/initrd.h>
#include <linux/module.h>
#include <linux/start_kernel.h>
+#include <linux/bootmem.h>
#include <asm/io.h>
#include <asm/processor.h>
@@ -50,6 +51,8 @@
#include <asm/elf.h>
#include <asm/mdesc.h>
#include <asm/cacheflush.h>
+#include <asm/dma.h>
+#include <asm/irq.h>
#ifdef CONFIG_IP_PNP
#include <net/ipconfig.h>
@@ -590,6 +593,22 @@
pause_patch();
}
+void __init alloc_irqstack_bootmem(void)
+{
+ unsigned int i, node;
+
+ for_each_possible_cpu(i) {
+ node = cpu_to_node(i);
+
+ softirq_stack[i] = __alloc_bootmem_node(NODE_DATA(node),
+ THREAD_SIZE,
+ THREAD_SIZE, 0);
+ hardirq_stack[i] = __alloc_bootmem_node(NODE_DATA(node),
+ THREAD_SIZE,
+ THREAD_SIZE, 0);
+ }
+}
+
void __init setup_arch(char **cmdline_p)
{
/* Initialize PROM console and command line. */
@@ -650,6 +669,13 @@
paging_init();
init_sparc64_elf_hwcap();
+ smp_fill_in_cpu_possible_map();
+ /*
+ * Once the OF device tree and MDESC have been setup and nr_cpus has
+ * been parsed, we know the list of possible cpus. Therefore we can
+ * allocate the IRQ stacks.
+ */
+ alloc_irqstack_bootmem();
}
extern int stop_a_enabled;
diff --git a/arch/sparc/kernel/smp_64.c b/arch/sparc/kernel/smp_64.c
index 8a6151a..d3035ba 100644
--- a/arch/sparc/kernel/smp_64.c
+++ b/arch/sparc/kernel/smp_64.c
@@ -1227,6 +1227,20 @@
xcall_deliver_impl = hypervisor_xcall_deliver;
}
+void __init smp_fill_in_cpu_possible_map(void)
+{
+ int possible_cpus = num_possible_cpus();
+ int i;
+
+ if (possible_cpus > nr_cpu_ids)
+ possible_cpus = nr_cpu_ids;
+
+ for (i = 0; i < possible_cpus; i++)
+ set_cpu_possible(i, true);
+ for (; i < NR_CPUS; i++)
+ set_cpu_possible(i, false);
+}
+
void smp_fill_in_sib_core_maps(void)
{
unsigned int i;
diff --git a/arch/sparc/mm/fault_64.c b/arch/sparc/mm/fault_64.c
index e16fdd2..3f291d8 100644
--- a/arch/sparc/mm/fault_64.c
+++ b/arch/sparc/mm/fault_64.c
@@ -484,6 +484,7 @@
tsb_grow(mm, MM_TSB_BASE, mm_rss);
#if defined(CONFIG_HUGETLB_PAGE) || defined(CONFIG_TRANSPARENT_HUGEPAGE)
mm_rss = mm->context.hugetlb_pte_count + mm->context.thp_pte_count;
+ mm_rss *= REAL_HPAGE_PER_HPAGE;
if (unlikely(mm_rss >
mm->context.tsb_block[MM_TSB_HUGE].tsb_rss_limit)) {
if (mm->context.tsb_block[MM_TSB_HUGE].tsb)
diff --git a/arch/sparc/mm/init_64.c b/arch/sparc/mm/init_64.c
index 65457c9..7ac6b62 100644
--- a/arch/sparc/mm/init_64.c
+++ b/arch/sparc/mm/init_64.c
@@ -1160,7 +1160,7 @@
return numa_latency[from][to];
}
-static int find_best_numa_node_for_mlgroup(struct mdesc_mlgroup *grp)
+static int __init find_best_numa_node_for_mlgroup(struct mdesc_mlgroup *grp)
{
int i;
@@ -1173,8 +1173,8 @@
return i;
}
-static void find_numa_latencies_for_group(struct mdesc_handle *md, u64 grp,
- int index)
+static void __init find_numa_latencies_for_group(struct mdesc_handle *md,
+ u64 grp, int index)
{
u64 arc;
@@ -2081,7 +2081,6 @@
{
unsigned long end_pfn, shift, phys_base;
unsigned long real_end, i;
- int node;
setup_page_offset();
@@ -2250,21 +2249,6 @@
/* Setup bootmem... */
last_valid_pfn = end_pfn = bootmem_init(phys_base);
- /* Once the OF device tree and MDESC have been setup, we know
- * the list of possible cpus. Therefore we can allocate the
- * IRQ stacks.
- */
- for_each_possible_cpu(i) {
- node = cpu_to_node(i);
-
- softirq_stack[i] = __alloc_bootmem_node(NODE_DATA(node),
- THREAD_SIZE,
- THREAD_SIZE, 0);
- hardirq_stack[i] = __alloc_bootmem_node(NODE_DATA(node),
- THREAD_SIZE,
- THREAD_SIZE, 0);
- }
-
kernel_physical_mapping_init();
{
diff --git a/arch/sparc/mm/tlb.c b/arch/sparc/mm/tlb.c
index 3659d37..c56a195 100644
--- a/arch/sparc/mm/tlb.c
+++ b/arch/sparc/mm/tlb.c
@@ -174,10 +174,25 @@
return;
if ((pmd_val(pmd) ^ pmd_val(orig)) & _PAGE_PMD_HUGE) {
- if (pmd_val(pmd) & _PAGE_PMD_HUGE)
- mm->context.thp_pte_count++;
- else
- mm->context.thp_pte_count--;
+ /*
+ * Note that this routine only sets pmds for THP pages.
+ * Hugetlb pages are handled elsewhere. We need to check
+ * for huge zero page. Huge zero pages are like hugetlb
+ * pages in that there is no RSS, but there is the need
+ * for TSB entries. So, huge zero page counts go into
+ * hugetlb_pte_count.
+ */
+ if (pmd_val(pmd) & _PAGE_PMD_HUGE) {
+ if (is_huge_zero_page(pmd_page(pmd)))
+ mm->context.hugetlb_pte_count++;
+ else
+ mm->context.thp_pte_count++;
+ } else {
+ if (is_huge_zero_page(pmd_page(orig)))
+ mm->context.hugetlb_pte_count--;
+ else
+ mm->context.thp_pte_count--;
+ }
/* Do not try to allocate the TSB hash table if we
* don't have one already. We have various locks held
@@ -204,6 +219,9 @@
}
}
+/*
+ * This routine is only called when splitting a THP
+ */
void pmdp_invalidate(struct vm_area_struct *vma, unsigned long address,
pmd_t *pmdp)
{
@@ -213,6 +231,15 @@
set_pmd_at(vma->vm_mm, address, pmdp, entry);
flush_tlb_range(vma, address, address + HPAGE_PMD_SIZE);
+
+ /*
+ * set_pmd_at() will not be called in a way to decrement
+ * thp_pte_count when splitting a THP, so do it now.
+ * Sanity check pmd before doing the actual decrement.
+ */
+ if ((pmd_val(entry) & _PAGE_PMD_HUGE) &&
+ !is_huge_zero_page(pmd_page(entry)))
+ (vma->vm_mm)->context.thp_pte_count--;
}
void pgtable_trans_huge_deposit(struct mm_struct *mm, pmd_t *pmdp,
diff --git a/arch/sparc/mm/tsb.c b/arch/sparc/mm/tsb.c
index 6725ed4..f2b7711 100644
--- a/arch/sparc/mm/tsb.c
+++ b/arch/sparc/mm/tsb.c
@@ -469,8 +469,10 @@
int init_new_context(struct task_struct *tsk, struct mm_struct *mm)
{
+ unsigned long mm_rss = get_mm_rss(mm);
#if defined(CONFIG_HUGETLB_PAGE) || defined(CONFIG_TRANSPARENT_HUGEPAGE)
- unsigned long total_huge_pte_count;
+ unsigned long saved_hugetlb_pte_count;
+ unsigned long saved_thp_pte_count;
#endif
unsigned int i;
@@ -483,10 +485,12 @@
* will re-increment the counters as the parent PTEs are
* copied into the child address space.
*/
- total_huge_pte_count = mm->context.hugetlb_pte_count +
- mm->context.thp_pte_count;
+ saved_hugetlb_pte_count = mm->context.hugetlb_pte_count;
+ saved_thp_pte_count = mm->context.thp_pte_count;
mm->context.hugetlb_pte_count = 0;
mm->context.thp_pte_count = 0;
+
+ mm_rss -= saved_thp_pte_count * (HPAGE_SIZE / PAGE_SIZE);
#endif
/* copy_mm() copies over the parent's mm_struct before calling
@@ -499,11 +503,13 @@
/* If this is fork, inherit the parent's TSB size. We would
* grow it to that size on the first page fault anyways.
*/
- tsb_grow(mm, MM_TSB_BASE, get_mm_rss(mm));
+ tsb_grow(mm, MM_TSB_BASE, mm_rss);
#if defined(CONFIG_HUGETLB_PAGE) || defined(CONFIG_TRANSPARENT_HUGEPAGE)
- if (unlikely(total_huge_pte_count))
- tsb_grow(mm, MM_TSB_HUGE, total_huge_pte_count);
+ if (unlikely(saved_hugetlb_pte_count + saved_thp_pte_count))
+ tsb_grow(mm, MM_TSB_HUGE,
+ (saved_hugetlb_pte_count + saved_thp_pte_count) *
+ REAL_HPAGE_PER_HPAGE);
#endif
if (unlikely(!mm->context.tsb_block[MM_TSB_BASE].tsb))
diff --git a/arch/x86/Kconfig b/arch/x86/Kconfig
index 2a1f0ce..0cc8811 100644
--- a/arch/x86/Kconfig
+++ b/arch/x86/Kconfig
@@ -705,7 +705,6 @@
config PARAVIRT_SPINLOCKS
bool "Paravirtualization layer for spinlocks"
depends on PARAVIRT && SMP
- select UNINLINE_SPIN_UNLOCK if !QUEUED_SPINLOCKS
---help---
Paravirtualized spinlocks allow a pvops backend to replace the
spinlock implementation with something virtualization-friendly
@@ -718,7 +717,7 @@
config QUEUED_LOCK_STAT
bool "Paravirt queued spinlock statistics"
- depends on PARAVIRT_SPINLOCKS && DEBUG_FS && QUEUED_SPINLOCKS
+ depends on PARAVIRT_SPINLOCKS && DEBUG_FS
---help---
Enable the collection of statistical data on the slowpath
behavior of paravirtualized queued spinlocks and report
diff --git a/arch/x86/boot/compressed/eboot.c b/arch/x86/boot/compressed/eboot.c
index 94dd4a3..cc69e37 100644
--- a/arch/x86/boot/compressed/eboot.c
+++ b/arch/x86/boot/compressed/eboot.c
@@ -29,22 +29,11 @@
static void setup_boot_services##bits(struct efi_config *c) \
{ \
efi_system_table_##bits##_t *table; \
- efi_boot_services_##bits##_t *bt; \
\
table = (typeof(table))sys_table; \
\
+ c->boot_services = table->boottime; \
c->text_output = table->con_out; \
- \
- bt = (typeof(bt))(unsigned long)(table->boottime); \
- \
- c->allocate_pool = bt->allocate_pool; \
- c->allocate_pages = bt->allocate_pages; \
- c->get_memory_map = bt->get_memory_map; \
- c->free_pool = bt->free_pool; \
- c->free_pages = bt->free_pages; \
- c->locate_handle = bt->locate_handle; \
- c->handle_protocol = bt->handle_protocol; \
- c->exit_boot_services = bt->exit_boot_services; \
}
BOOT_SERVICES(32);
BOOT_SERVICES(64);
@@ -286,29 +275,6 @@
}
}
-static void find_bits(unsigned long mask, u8 *pos, u8 *size)
-{
- u8 first, len;
-
- first = 0;
- len = 0;
-
- if (mask) {
- while (!(mask & 0x1)) {
- mask = mask >> 1;
- first++;
- }
-
- while (mask & 0x1) {
- mask = mask >> 1;
- len++;
- }
- }
-
- *pos = first;
- *size = len;
-}
-
static efi_status_t
__setup_efi_pci32(efi_pci_io_protocol_32 *pci, struct pci_setup_rom **__rom)
{
@@ -578,7 +544,7 @@
efi_guid_t uga_proto = EFI_UGA_PROTOCOL_GUID;
unsigned long nr_ugas;
u32 *handles = (u32 *)uga_handle;;
- efi_status_t status;
+ efi_status_t status = EFI_INVALID_PARAMETER;
int i;
first_uga = NULL;
@@ -623,7 +589,7 @@
efi_guid_t uga_proto = EFI_UGA_PROTOCOL_GUID;
unsigned long nr_ugas;
u64 *handles = (u64 *)uga_handle;;
- efi_status_t status;
+ efi_status_t status = EFI_INVALID_PARAMETER;
int i;
first_uga = NULL;
diff --git a/arch/x86/boot/compressed/head_32.S b/arch/x86/boot/compressed/head_32.S
index 1038524..fd0b6a2 100644
--- a/arch/x86/boot/compressed/head_32.S
+++ b/arch/x86/boot/compressed/head_32.S
@@ -82,7 +82,7 @@
/* Relocate efi_config->call() */
leal efi32_config(%esi), %eax
- add %esi, 88(%eax)
+ add %esi, 32(%eax)
pushl %eax
call make_boot_params
@@ -108,7 +108,7 @@
/* Relocate efi_config->call() */
leal efi32_config(%esi), %eax
- add %esi, 88(%eax)
+ add %esi, 32(%eax)
pushl %eax
2:
call efi_main
@@ -264,7 +264,7 @@
#ifdef CONFIG_EFI_STUB
.data
efi32_config:
- .fill 11,8,0
+ .fill 4,8,0
.long efi_call_phys
.long 0
.byte 0
diff --git a/arch/x86/boot/compressed/head_64.S b/arch/x86/boot/compressed/head_64.S
index 0d80a7a..efdfba2 100644
--- a/arch/x86/boot/compressed/head_64.S
+++ b/arch/x86/boot/compressed/head_64.S
@@ -265,7 +265,7 @@
/*
* Relocate efi_config->call().
*/
- addq %rbp, efi64_config+88(%rip)
+ addq %rbp, efi64_config+32(%rip)
movq %rax, %rdi
call make_boot_params
@@ -285,7 +285,7 @@
* Relocate efi_config->call().
*/
movq efi_config(%rip), %rax
- addq %rbp, 88(%rax)
+ addq %rbp, 32(%rax)
2:
movq efi_config(%rip), %rdi
call efi_main
@@ -457,14 +457,14 @@
#ifdef CONFIG_EFI_MIXED
.global efi32_config
efi32_config:
- .fill 11,8,0
+ .fill 4,8,0
.quad efi64_thunk
.byte 0
#endif
.global efi64_config
efi64_config:
- .fill 11,8,0
+ .fill 4,8,0
.quad efi_call
.byte 1
#endif /* CONFIG_EFI_STUB */
diff --git a/arch/x86/entry/entry_64.S b/arch/x86/entry/entry_64.S
index d172c61..02fff3e 100644
--- a/arch/x86/entry/entry_64.S
+++ b/arch/x86/entry/entry_64.S
@@ -1002,7 +1002,6 @@
testb $3, CS+8(%rsp)
jz .Lerror_kernelspace
-.Lerror_entry_from_usermode_swapgs:
/*
* We entered from user mode or we're pretending to have entered
* from user mode due to an IRET fault.
@@ -1045,7 +1044,8 @@
* gsbase and proceed. We'll fix up the exception and land in
* .Lgs_change's error handler with kernel gsbase.
*/
- jmp .Lerror_entry_from_usermode_swapgs
+ SWAPGS
+ jmp .Lerror_entry_done
.Lbstep_iret:
/* Fix truncated RIP */
diff --git a/arch/x86/entry/vdso/vdso2c.h b/arch/x86/entry/vdso/vdso2c.h
index 4f74119..3dab75f 100644
--- a/arch/x86/entry/vdso/vdso2c.h
+++ b/arch/x86/entry/vdso/vdso2c.h
@@ -22,7 +22,7 @@
ELF(Phdr) *pt = (ELF(Phdr) *)(raw_addr + GET_LE(&hdr->e_phoff));
- if (hdr->e_type != ET_DYN)
+ if (GET_LE(&hdr->e_type) != ET_DYN)
fail("input is not a shared object\n");
/* Walk the segment table. */
diff --git a/arch/x86/include/asm/cmpxchg.h b/arch/x86/include/asm/cmpxchg.h
index 9733361..97848cd 100644
--- a/arch/x86/include/asm/cmpxchg.h
+++ b/arch/x86/include/asm/cmpxchg.h
@@ -158,53 +158,9 @@
* value of "*ptr".
*
* xadd() is locked when multiple CPUs are online
- * xadd_sync() is always locked
- * xadd_local() is never locked
*/
#define __xadd(ptr, inc, lock) __xchg_op((ptr), (inc), xadd, lock)
#define xadd(ptr, inc) __xadd((ptr), (inc), LOCK_PREFIX)
-#define xadd_sync(ptr, inc) __xadd((ptr), (inc), "lock; ")
-#define xadd_local(ptr, inc) __xadd((ptr), (inc), "")
-
-#define __add(ptr, inc, lock) \
- ({ \
- __typeof__ (*(ptr)) __ret = (inc); \
- switch (sizeof(*(ptr))) { \
- case __X86_CASE_B: \
- asm volatile (lock "addb %b1, %0\n" \
- : "+m" (*(ptr)) : "qi" (inc) \
- : "memory", "cc"); \
- break; \
- case __X86_CASE_W: \
- asm volatile (lock "addw %w1, %0\n" \
- : "+m" (*(ptr)) : "ri" (inc) \
- : "memory", "cc"); \
- break; \
- case __X86_CASE_L: \
- asm volatile (lock "addl %1, %0\n" \
- : "+m" (*(ptr)) : "ri" (inc) \
- : "memory", "cc"); \
- break; \
- case __X86_CASE_Q: \
- asm volatile (lock "addq %1, %0\n" \
- : "+m" (*(ptr)) : "ri" (inc) \
- : "memory", "cc"); \
- break; \
- default: \
- __add_wrong_size(); \
- } \
- __ret; \
- })
-
-/*
- * add_*() adds "inc" to "*ptr"
- *
- * __add() takes a lock prefix
- * add_smp() is locked when multiple CPUs are online
- * add_sync() is always locked
- */
-#define add_smp(ptr, inc) __add((ptr), (inc), LOCK_PREFIX)
-#define add_sync(ptr, inc) __add((ptr), (inc), "lock; ")
#define __cmpxchg_double(pfx, p1, p2, o1, o2, n1, n2) \
({ \
diff --git a/arch/x86/include/asm/efi.h b/arch/x86/include/asm/efi.h
index d0bb76d..389d700 100644
--- a/arch/x86/include/asm/efi.h
+++ b/arch/x86/include/asm/efi.h
@@ -117,7 +117,6 @@
extern pgd_t * __init efi_call_phys_prolog(void);
extern void __init efi_call_phys_epilog(pgd_t *save_pgd);
extern void __init efi_print_memmap(void);
-extern void __init efi_unmap_memmap(void);
extern void __init efi_memory_uc(u64 addr, unsigned long size);
extern void __init efi_map_region(efi_memory_desc_t *md);
extern void __init efi_map_region_fixed(efi_memory_desc_t *md);
@@ -192,14 +191,7 @@
struct efi_config {
u64 image_handle;
u64 table;
- u64 allocate_pool;
- u64 allocate_pages;
- u64 get_memory_map;
- u64 free_pool;
- u64 free_pages;
- u64 locate_handle;
- u64 handle_protocol;
- u64 exit_boot_services;
+ u64 boot_services;
u64 text_output;
efi_status_t (*call)(unsigned long, ...);
bool is64;
@@ -207,14 +199,27 @@
__pure const struct efi_config *__efi_early(void);
+static inline bool efi_is_64bit(void)
+{
+ if (!IS_ENABLED(CONFIG_X86_64))
+ return false;
+
+ if (!IS_ENABLED(CONFIG_EFI_MIXED))
+ return true;
+
+ return __efi_early()->is64;
+}
+
#define efi_call_early(f, ...) \
- __efi_early()->call(__efi_early()->f, __VA_ARGS__);
+ __efi_early()->call(efi_is_64bit() ? \
+ ((efi_boot_services_64_t *)(unsigned long) \
+ __efi_early()->boot_services)->f : \
+ ((efi_boot_services_32_t *)(unsigned long) \
+ __efi_early()->boot_services)->f, __VA_ARGS__)
#define __efi_call_early(f, ...) \
__efi_early()->call((unsigned long)f, __VA_ARGS__);
-#define efi_is_64bit() __efi_early()->is64
-
extern bool efi_reboot_required(void);
#else
diff --git a/arch/x86/include/asm/hypervisor.h b/arch/x86/include/asm/hypervisor.h
index 055ea99..67942b6 100644
--- a/arch/x86/include/asm/hypervisor.h
+++ b/arch/x86/include/asm/hypervisor.h
@@ -43,6 +43,9 @@
/* X2APIC detection (run once per boot) */
bool (*x2apic_available)(void);
+
+ /* pin current vcpu to specified physical cpu (run rarely) */
+ void (*pin_vcpu)(int);
};
extern const struct hypervisor_x86 *x86_hyper;
@@ -56,6 +59,7 @@
extern void init_hypervisor(struct cpuinfo_x86 *c);
extern void init_hypervisor_platform(void);
extern bool hypervisor_x2apic_available(void);
+extern void hypervisor_pin_vcpu(int cpu);
#else
static inline void init_hypervisor(struct cpuinfo_x86 *c) { }
static inline void init_hypervisor_platform(void) { }
diff --git a/arch/x86/include/asm/paravirt.h b/arch/x86/include/asm/paravirt.h
index 2970d22..4cd8db0 100644
--- a/arch/x86/include/asm/paravirt.h
+++ b/arch/x86/include/asm/paravirt.h
@@ -661,8 +661,6 @@
#if defined(CONFIG_SMP) && defined(CONFIG_PARAVIRT_SPINLOCKS)
-#ifdef CONFIG_QUEUED_SPINLOCKS
-
static __always_inline void pv_queued_spin_lock_slowpath(struct qspinlock *lock,
u32 val)
{
@@ -684,22 +682,6 @@
PVOP_VCALL1(pv_lock_ops.kick, cpu);
}
-#else /* !CONFIG_QUEUED_SPINLOCKS */
-
-static __always_inline void __ticket_lock_spinning(struct arch_spinlock *lock,
- __ticket_t ticket)
-{
- PVOP_VCALLEE2(pv_lock_ops.lock_spinning, lock, ticket);
-}
-
-static __always_inline void __ticket_unlock_kick(struct arch_spinlock *lock,
- __ticket_t ticket)
-{
- PVOP_VCALL2(pv_lock_ops.unlock_kick, lock, ticket);
-}
-
-#endif /* CONFIG_QUEUED_SPINLOCKS */
-
#endif /* SMP && PARAVIRT_SPINLOCKS */
#ifdef CONFIG_X86_32
diff --git a/arch/x86/include/asm/paravirt_types.h b/arch/x86/include/asm/paravirt_types.h
index 7fa9e77..60aac60 100644
--- a/arch/x86/include/asm/paravirt_types.h
+++ b/arch/x86/include/asm/paravirt_types.h
@@ -301,23 +301,16 @@
struct arch_spinlock;
#ifdef CONFIG_SMP
#include <asm/spinlock_types.h>
-#else
-typedef u16 __ticket_t;
#endif
struct qspinlock;
struct pv_lock_ops {
-#ifdef CONFIG_QUEUED_SPINLOCKS
void (*queued_spin_lock_slowpath)(struct qspinlock *lock, u32 val);
struct paravirt_callee_save queued_spin_unlock;
void (*wait)(u8 *ptr, u8 val);
void (*kick)(int cpu);
-#else /* !CONFIG_QUEUED_SPINLOCKS */
- struct paravirt_callee_save lock_spinning;
- void (*unlock_kick)(struct arch_spinlock *lock, __ticket_t ticket);
-#endif /* !CONFIG_QUEUED_SPINLOCKS */
};
/* This contains all the paravirt structures: we get a convenient
diff --git a/arch/x86/include/asm/rwsem.h b/arch/x86/include/asm/rwsem.h
index 8dbc762..3d33a71 100644
--- a/arch/x86/include/asm/rwsem.h
+++ b/arch/x86/include/asm/rwsem.h
@@ -154,7 +154,7 @@
: "+m" (sem->count), "=&a" (tmp0), "=&r" (tmp1),
CC_OUT(e) (result)
: "er" (RWSEM_ACTIVE_WRITE_BIAS)
- : "memory", "cc");
+ : "memory");
return result;
}
diff --git a/arch/x86/include/asm/spinlock.h b/arch/x86/include/asm/spinlock.h
index be0a059..921bea7 100644
--- a/arch/x86/include/asm/spinlock.h
+++ b/arch/x86/include/asm/spinlock.h
@@ -20,187 +20,13 @@
* (the type definitions are in asm/spinlock_types.h)
*/
-#ifdef CONFIG_X86_32
-# define LOCK_PTR_REG "a"
-#else
-# define LOCK_PTR_REG "D"
-#endif
-
-#if defined(CONFIG_X86_32) && (defined(CONFIG_X86_PPRO_FENCE))
-/*
- * On PPro SMP, we use a locked operation to unlock
- * (PPro errata 66, 92)
- */
-# define UNLOCK_LOCK_PREFIX LOCK_PREFIX
-#else
-# define UNLOCK_LOCK_PREFIX
-#endif
-
/* How long a lock should spin before we consider blocking */
#define SPIN_THRESHOLD (1 << 15)
extern struct static_key paravirt_ticketlocks_enabled;
static __always_inline bool static_key_false(struct static_key *key);
-#ifdef CONFIG_QUEUED_SPINLOCKS
#include <asm/qspinlock.h>
-#else
-
-#ifdef CONFIG_PARAVIRT_SPINLOCKS
-
-static inline void __ticket_enter_slowpath(arch_spinlock_t *lock)
-{
- set_bit(0, (volatile unsigned long *)&lock->tickets.head);
-}
-
-#else /* !CONFIG_PARAVIRT_SPINLOCKS */
-static __always_inline void __ticket_lock_spinning(arch_spinlock_t *lock,
- __ticket_t ticket)
-{
-}
-static inline void __ticket_unlock_kick(arch_spinlock_t *lock,
- __ticket_t ticket)
-{
-}
-
-#endif /* CONFIG_PARAVIRT_SPINLOCKS */
-static inline int __tickets_equal(__ticket_t one, __ticket_t two)
-{
- return !((one ^ two) & ~TICKET_SLOWPATH_FLAG);
-}
-
-static inline void __ticket_check_and_clear_slowpath(arch_spinlock_t *lock,
- __ticket_t head)
-{
- if (head & TICKET_SLOWPATH_FLAG) {
- arch_spinlock_t old, new;
-
- old.tickets.head = head;
- new.tickets.head = head & ~TICKET_SLOWPATH_FLAG;
- old.tickets.tail = new.tickets.head + TICKET_LOCK_INC;
- new.tickets.tail = old.tickets.tail;
-
- /* try to clear slowpath flag when there are no contenders */
- cmpxchg(&lock->head_tail, old.head_tail, new.head_tail);
- }
-}
-
-static __always_inline int arch_spin_value_unlocked(arch_spinlock_t lock)
-{
- return __tickets_equal(lock.tickets.head, lock.tickets.tail);
-}
-
-/*
- * Ticket locks are conceptually two parts, one indicating the current head of
- * the queue, and the other indicating the current tail. The lock is acquired
- * by atomically noting the tail and incrementing it by one (thus adding
- * ourself to the queue and noting our position), then waiting until the head
- * becomes equal to the the initial value of the tail.
- *
- * We use an xadd covering *both* parts of the lock, to increment the tail and
- * also load the position of the head, which takes care of memory ordering
- * issues and should be optimal for the uncontended case. Note the tail must be
- * in the high part, because a wide xadd increment of the low part would carry
- * up and contaminate the high part.
- */
-static __always_inline void arch_spin_lock(arch_spinlock_t *lock)
-{
- register struct __raw_tickets inc = { .tail = TICKET_LOCK_INC };
-
- inc = xadd(&lock->tickets, inc);
- if (likely(inc.head == inc.tail))
- goto out;
-
- for (;;) {
- unsigned count = SPIN_THRESHOLD;
-
- do {
- inc.head = READ_ONCE(lock->tickets.head);
- if (__tickets_equal(inc.head, inc.tail))
- goto clear_slowpath;
- cpu_relax();
- } while (--count);
- __ticket_lock_spinning(lock, inc.tail);
- }
-clear_slowpath:
- __ticket_check_and_clear_slowpath(lock, inc.head);
-out:
- barrier(); /* make sure nothing creeps before the lock is taken */
-}
-
-static __always_inline int arch_spin_trylock(arch_spinlock_t *lock)
-{
- arch_spinlock_t old, new;
-
- old.tickets = READ_ONCE(lock->tickets);
- if (!__tickets_equal(old.tickets.head, old.tickets.tail))
- return 0;
-
- new.head_tail = old.head_tail + (TICKET_LOCK_INC << TICKET_SHIFT);
- new.head_tail &= ~TICKET_SLOWPATH_FLAG;
-
- /* cmpxchg is a full barrier, so nothing can move before it */
- return cmpxchg(&lock->head_tail, old.head_tail, new.head_tail) == old.head_tail;
-}
-
-static __always_inline void arch_spin_unlock(arch_spinlock_t *lock)
-{
- if (TICKET_SLOWPATH_FLAG &&
- static_key_false(¶virt_ticketlocks_enabled)) {
- __ticket_t head;
-
- BUILD_BUG_ON(((__ticket_t)NR_CPUS) != NR_CPUS);
-
- head = xadd(&lock->tickets.head, TICKET_LOCK_INC);
-
- if (unlikely(head & TICKET_SLOWPATH_FLAG)) {
- head &= ~TICKET_SLOWPATH_FLAG;
- __ticket_unlock_kick(lock, (head + TICKET_LOCK_INC));
- }
- } else
- __add(&lock->tickets.head, TICKET_LOCK_INC, UNLOCK_LOCK_PREFIX);
-}
-
-static inline int arch_spin_is_locked(arch_spinlock_t *lock)
-{
- struct __raw_tickets tmp = READ_ONCE(lock->tickets);
-
- return !__tickets_equal(tmp.tail, tmp.head);
-}
-
-static inline int arch_spin_is_contended(arch_spinlock_t *lock)
-{
- struct __raw_tickets tmp = READ_ONCE(lock->tickets);
-
- tmp.head &= ~TICKET_SLOWPATH_FLAG;
- return (__ticket_t)(tmp.tail - tmp.head) > TICKET_LOCK_INC;
-}
-#define arch_spin_is_contended arch_spin_is_contended
-
-static __always_inline void arch_spin_lock_flags(arch_spinlock_t *lock,
- unsigned long flags)
-{
- arch_spin_lock(lock);
-}
-
-static inline void arch_spin_unlock_wait(arch_spinlock_t *lock)
-{
- __ticket_t head = READ_ONCE(lock->tickets.head);
-
- for (;;) {
- struct __raw_tickets tmp = READ_ONCE(lock->tickets);
- /*
- * We need to check "unlocked" in a loop, tmp.head == head
- * can be false positive because of overflow.
- */
- if (__tickets_equal(tmp.head, tmp.tail) ||
- !__tickets_equal(tmp.head, head))
- break;
-
- cpu_relax();
- }
-}
-#endif /* CONFIG_QUEUED_SPINLOCKS */
/*
* Read-write spinlocks, allowing multiple readers
diff --git a/arch/x86/include/asm/spinlock_types.h b/arch/x86/include/asm/spinlock_types.h
index 65c3e37..25311eb 100644
--- a/arch/x86/include/asm/spinlock_types.h
+++ b/arch/x86/include/asm/spinlock_types.h
@@ -23,20 +23,7 @@
#define TICKET_SHIFT (sizeof(__ticket_t) * 8)
-#ifdef CONFIG_QUEUED_SPINLOCKS
#include <asm-generic/qspinlock_types.h>
-#else
-typedef struct arch_spinlock {
- union {
- __ticketpair_t head_tail;
- struct __raw_tickets {
- __ticket_t head, tail;
- } tickets;
- };
-} arch_spinlock_t;
-
-#define __ARCH_SPIN_LOCK_UNLOCKED { { 0 } }
-#endif /* CONFIG_QUEUED_SPINLOCKS */
#include <asm-generic/qrwlock_types.h>
diff --git a/arch/x86/include/asm/tlbflush.h b/arch/x86/include/asm/tlbflush.h
index 6fa8594..dee8a70 100644
--- a/arch/x86/include/asm/tlbflush.h
+++ b/arch/x86/include/asm/tlbflush.h
@@ -81,7 +81,7 @@
/* Initialize cr4 shadow for this CPU. */
static inline void cr4_init_shadow(void)
{
- this_cpu_write(cpu_tlbstate.cr4, __read_cr4());
+ this_cpu_write(cpu_tlbstate.cr4, __read_cr4_safe());
}
/* Set in this cpu's CR4. */
diff --git a/arch/x86/kernel/acpi/Makefile b/arch/x86/kernel/acpi/Makefile
index 3242e59..26b78d8 100644
--- a/arch/x86/kernel/acpi/Makefile
+++ b/arch/x86/kernel/acpi/Makefile
@@ -1,6 +1,7 @@
obj-$(CONFIG_ACPI) += boot.o
obj-$(CONFIG_ACPI_SLEEP) += sleep.o wakeup_$(BITS).o
obj-$(CONFIG_ACPI_APEI) += apei.o
+obj-$(CONFIG_ACPI_CPPC_LIB) += cppc_msr.o
ifneq ($(CONFIG_ACPI_PROCESSOR),)
obj-y += cstate.o
diff --git a/arch/x86/kernel/acpi/boot.c b/arch/x86/kernel/acpi/boot.c
index 90d84c3..ccd27fe 100644
--- a/arch/x86/kernel/acpi/boot.c
+++ b/arch/x86/kernel/acpi/boot.c
@@ -1031,8 +1031,8 @@
return ret;
}
- x2count = madt_proc[0].count;
- count = madt_proc[1].count;
+ count = madt_proc[0].count;
+ x2count = madt_proc[1].count;
}
if (!count && !x2count) {
printk(KERN_ERR PREFIX "No LAPIC entries present\n");
@@ -1513,7 +1513,7 @@
* If acpi_disabled, bail out
*/
if (acpi_disabled)
- return;
+ return;
/*
* Initialize the ACPI boot-time table parser.
diff --git a/arch/x86/kernel/acpi/cppc_msr.c b/arch/x86/kernel/acpi/cppc_msr.c
new file mode 100644
index 0000000..6fb478b
--- /dev/null
+++ b/arch/x86/kernel/acpi/cppc_msr.c
@@ -0,0 +1,58 @@
+/*
+ * cppc_msr.c: MSR Interface for CPPC
+ * Copyright (c) 2016, Intel Corporation.
+ *
+ * This program is free software; you can redistribute it and/or modify it
+ * under the terms and conditions of the GNU General Public License,
+ * version 2, as published by the Free Software Foundation.
+ *
+ * This program is distributed in the hope it will be useful, but WITHOUT
+ * ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
+ * FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for
+ * more details.
+ *
+ */
+
+#include <acpi/cppc_acpi.h>
+#include <asm/msr.h>
+
+/* Refer to drivers/acpi/cppc_acpi.c for the description of functions */
+
+bool cpc_ffh_supported(void)
+{
+ return true;
+}
+
+int cpc_read_ffh(int cpunum, struct cpc_reg *reg, u64 *val)
+{
+ int err;
+
+ err = rdmsrl_safe_on_cpu(cpunum, reg->address, val);
+ if (!err) {
+ u64 mask = GENMASK_ULL(reg->bit_offset + reg->bit_width - 1,
+ reg->bit_offset);
+
+ *val &= mask;
+ *val >>= reg->bit_offset;
+ }
+ return err;
+}
+
+int cpc_write_ffh(int cpunum, struct cpc_reg *reg, u64 val)
+{
+ u64 rd_val;
+ int err;
+
+ err = rdmsrl_safe_on_cpu(cpunum, reg->address, &rd_val);
+ if (!err) {
+ u64 mask = GENMASK_ULL(reg->bit_offset + reg->bit_width - 1,
+ reg->bit_offset);
+
+ val <<= reg->bit_offset;
+ val &= mask;
+ rd_val &= ~mask;
+ rd_val |= val;
+ err = wrmsrl_safe_on_cpu(cpunum, reg->address, rd_val);
+ }
+ return err;
+}
diff --git a/arch/x86/kernel/cpu/common.c b/arch/x86/kernel/cpu/common.c
index 809eda0..bcc9ccc 100644
--- a/arch/x86/kernel/cpu/common.c
+++ b/arch/x86/kernel/cpu/common.c
@@ -804,21 +804,20 @@
identify_cpu_without_cpuid(c);
/* cyrix could have cpuid enabled via c_identify()*/
- if (!have_cpuid_p())
- return;
+ if (have_cpuid_p()) {
+ cpu_detect(c);
+ get_cpu_vendor(c);
+ get_cpu_cap(c);
- cpu_detect(c);
- get_cpu_vendor(c);
- get_cpu_cap(c);
+ if (this_cpu->c_early_init)
+ this_cpu->c_early_init(c);
- if (this_cpu->c_early_init)
- this_cpu->c_early_init(c);
+ c->cpu_index = 0;
+ filter_cpuid_features(c, false);
- c->cpu_index = 0;
- filter_cpuid_features(c, false);
-
- if (this_cpu->c_bsp_init)
- this_cpu->c_bsp_init(c);
+ if (this_cpu->c_bsp_init)
+ this_cpu->c_bsp_init(c);
+ }
setup_force_cpu_cap(X86_FEATURE_ALWAYS);
fpu__init_system(c);
diff --git a/arch/x86/kernel/cpu/hypervisor.c b/arch/x86/kernel/cpu/hypervisor.c
index 27e4665..35691a6 100644
--- a/arch/x86/kernel/cpu/hypervisor.c
+++ b/arch/x86/kernel/cpu/hypervisor.c
@@ -86,3 +86,14 @@
x86_hyper->x2apic_available &&
x86_hyper->x2apic_available();
}
+
+void hypervisor_pin_vcpu(int cpu)
+{
+ if (!x86_hyper)
+ return;
+
+ if (x86_hyper->pin_vcpu)
+ x86_hyper->pin_vcpu(cpu);
+ else
+ WARN_ONCE(1, "vcpu pinning requested but not supported!\n");
+}
diff --git a/arch/x86/kernel/kvm.c b/arch/x86/kernel/kvm.c
index 1726c4c..865058d 100644
--- a/arch/x86/kernel/kvm.c
+++ b/arch/x86/kernel/kvm.c
@@ -575,9 +575,6 @@
kvm_hypercall2(KVM_HC_KICK_CPU, flags, apicid);
}
-
-#ifdef CONFIG_QUEUED_SPINLOCKS
-
#include <asm/qspinlock.h>
static void kvm_wait(u8 *ptr, u8 val)
@@ -606,243 +603,6 @@
local_irq_restore(flags);
}
-#else /* !CONFIG_QUEUED_SPINLOCKS */
-
-enum kvm_contention_stat {
- TAKEN_SLOW,
- TAKEN_SLOW_PICKUP,
- RELEASED_SLOW,
- RELEASED_SLOW_KICKED,
- NR_CONTENTION_STATS
-};
-
-#ifdef CONFIG_KVM_DEBUG_FS
-#define HISTO_BUCKETS 30
-
-static struct kvm_spinlock_stats
-{
- u32 contention_stats[NR_CONTENTION_STATS];
- u32 histo_spin_blocked[HISTO_BUCKETS+1];
- u64 time_blocked;
-} spinlock_stats;
-
-static u8 zero_stats;
-
-static inline void check_zero(void)
-{
- u8 ret;
- u8 old;
-
- old = READ_ONCE(zero_stats);
- if (unlikely(old)) {
- ret = cmpxchg(&zero_stats, old, 0);
- /* This ensures only one fellow resets the stat */
- if (ret == old)
- memset(&spinlock_stats, 0, sizeof(spinlock_stats));
- }
-}
-
-static inline void add_stats(enum kvm_contention_stat var, u32 val)
-{
- check_zero();
- spinlock_stats.contention_stats[var] += val;
-}
-
-
-static inline u64 spin_time_start(void)
-{
- return sched_clock();
-}
-
-static void __spin_time_accum(u64 delta, u32 *array)
-{
- unsigned index;
-
- index = ilog2(delta);
- check_zero();
-
- if (index < HISTO_BUCKETS)
- array[index]++;
- else
- array[HISTO_BUCKETS]++;
-}
-
-static inline void spin_time_accum_blocked(u64 start)
-{
- u32 delta;
-
- delta = sched_clock() - start;
- __spin_time_accum(delta, spinlock_stats.histo_spin_blocked);
- spinlock_stats.time_blocked += delta;
-}
-
-static struct dentry *d_spin_debug;
-static struct dentry *d_kvm_debug;
-
-static struct dentry *kvm_init_debugfs(void)
-{
- d_kvm_debug = debugfs_create_dir("kvm-guest", NULL);
- if (!d_kvm_debug)
- printk(KERN_WARNING "Could not create 'kvm' debugfs directory\n");
-
- return d_kvm_debug;
-}
-
-static int __init kvm_spinlock_debugfs(void)
-{
- struct dentry *d_kvm;
-
- d_kvm = kvm_init_debugfs();
- if (d_kvm == NULL)
- return -ENOMEM;
-
- d_spin_debug = debugfs_create_dir("spinlocks", d_kvm);
-
- debugfs_create_u8("zero_stats", 0644, d_spin_debug, &zero_stats);
-
- debugfs_create_u32("taken_slow", 0444, d_spin_debug,
- &spinlock_stats.contention_stats[TAKEN_SLOW]);
- debugfs_create_u32("taken_slow_pickup", 0444, d_spin_debug,
- &spinlock_stats.contention_stats[TAKEN_SLOW_PICKUP]);
-
- debugfs_create_u32("released_slow", 0444, d_spin_debug,
- &spinlock_stats.contention_stats[RELEASED_SLOW]);
- debugfs_create_u32("released_slow_kicked", 0444, d_spin_debug,
- &spinlock_stats.contention_stats[RELEASED_SLOW_KICKED]);
-
- debugfs_create_u64("time_blocked", 0444, d_spin_debug,
- &spinlock_stats.time_blocked);
-
- debugfs_create_u32_array("histo_blocked", 0444, d_spin_debug,
- spinlock_stats.histo_spin_blocked, HISTO_BUCKETS + 1);
-
- return 0;
-}
-fs_initcall(kvm_spinlock_debugfs);
-#else /* !CONFIG_KVM_DEBUG_FS */
-static inline void add_stats(enum kvm_contention_stat var, u32 val)
-{
-}
-
-static inline u64 spin_time_start(void)
-{
- return 0;
-}
-
-static inline void spin_time_accum_blocked(u64 start)
-{
-}
-#endif /* CONFIG_KVM_DEBUG_FS */
-
-struct kvm_lock_waiting {
- struct arch_spinlock *lock;
- __ticket_t want;
-};
-
-/* cpus 'waiting' on a spinlock to become available */
-static cpumask_t waiting_cpus;
-
-/* Track spinlock on which a cpu is waiting */
-static DEFINE_PER_CPU(struct kvm_lock_waiting, klock_waiting);
-
-__visible void kvm_lock_spinning(struct arch_spinlock *lock, __ticket_t want)
-{
- struct kvm_lock_waiting *w;
- int cpu;
- u64 start;
- unsigned long flags;
- __ticket_t head;
-
- if (in_nmi())
- return;
-
- w = this_cpu_ptr(&klock_waiting);
- cpu = smp_processor_id();
- start = spin_time_start();
-
- /*
- * Make sure an interrupt handler can't upset things in a
- * partially setup state.
- */
- local_irq_save(flags);
-
- /*
- * The ordering protocol on this is that the "lock" pointer
- * may only be set non-NULL if the "want" ticket is correct.
- * If we're updating "want", we must first clear "lock".
- */
- w->lock = NULL;
- smp_wmb();
- w->want = want;
- smp_wmb();
- w->lock = lock;
-
- add_stats(TAKEN_SLOW, 1);
-
- /*
- * This uses set_bit, which is atomic but we should not rely on its
- * reordering gurantees. So barrier is needed after this call.
- */
- cpumask_set_cpu(cpu, &waiting_cpus);
-
- barrier();
-
- /*
- * Mark entry to slowpath before doing the pickup test to make
- * sure we don't deadlock with an unlocker.
- */
- __ticket_enter_slowpath(lock);
-
- /* make sure enter_slowpath, which is atomic does not cross the read */
- smp_mb__after_atomic();
-
- /*
- * check again make sure it didn't become free while
- * we weren't looking.
- */
- head = READ_ONCE(lock->tickets.head);
- if (__tickets_equal(head, want)) {
- add_stats(TAKEN_SLOW_PICKUP, 1);
- goto out;
- }
-
- /*
- * halt until it's our turn and kicked. Note that we do safe halt
- * for irq enabled case to avoid hang when lock info is overwritten
- * in irq spinlock slowpath and no spurious interrupt occur to save us.
- */
- if (arch_irqs_disabled_flags(flags))
- halt();
- else
- safe_halt();
-
-out:
- cpumask_clear_cpu(cpu, &waiting_cpus);
- w->lock = NULL;
- local_irq_restore(flags);
- spin_time_accum_blocked(start);
-}
-PV_CALLEE_SAVE_REGS_THUNK(kvm_lock_spinning);
-
-/* Kick vcpu waiting on @lock->head to reach value @ticket */
-static void kvm_unlock_kick(struct arch_spinlock *lock, __ticket_t ticket)
-{
- int cpu;
-
- add_stats(RELEASED_SLOW, 1);
- for_each_cpu(cpu, &waiting_cpus) {
- const struct kvm_lock_waiting *w = &per_cpu(klock_waiting, cpu);
- if (READ_ONCE(w->lock) == lock &&
- READ_ONCE(w->want) == ticket) {
- add_stats(RELEASED_SLOW_KICKED, 1);
- kvm_kick_cpu(cpu);
- break;
- }
- }
-}
-
-#endif /* !CONFIG_QUEUED_SPINLOCKS */
-
/*
* Setup pv_lock_ops to exploit KVM_FEATURE_PV_UNHALT if present.
*/
@@ -854,16 +614,11 @@
if (!kvm_para_has_feature(KVM_FEATURE_PV_UNHALT))
return;
-#ifdef CONFIG_QUEUED_SPINLOCKS
__pv_init_lock_hash();
pv_lock_ops.queued_spin_lock_slowpath = __pv_queued_spin_lock_slowpath;
pv_lock_ops.queued_spin_unlock = PV_CALLEE_SAVE(__pv_queued_spin_unlock);
pv_lock_ops.wait = kvm_wait;
pv_lock_ops.kick = kvm_kick_cpu;
-#else /* !CONFIG_QUEUED_SPINLOCKS */
- pv_lock_ops.lock_spinning = PV_CALLEE_SAVE(kvm_lock_spinning);
- pv_lock_ops.unlock_kick = kvm_unlock_kick;
-#endif
}
static __init int kvm_spinlock_init_jump(void)
diff --git a/arch/x86/kernel/paravirt-spinlocks.c b/arch/x86/kernel/paravirt-spinlocks.c
index 1939a02..2c55a00 100644
--- a/arch/x86/kernel/paravirt-spinlocks.c
+++ b/arch/x86/kernel/paravirt-spinlocks.c
@@ -8,7 +8,6 @@
#include <asm/paravirt.h>
-#ifdef CONFIG_QUEUED_SPINLOCKS
__visible void __native_queued_spin_unlock(struct qspinlock *lock)
{
native_queued_spin_unlock(lock);
@@ -21,19 +20,13 @@
return pv_lock_ops.queued_spin_unlock.func ==
__raw_callee_save___native_queued_spin_unlock;
}
-#endif
struct pv_lock_ops pv_lock_ops = {
#ifdef CONFIG_SMP
-#ifdef CONFIG_QUEUED_SPINLOCKS
.queued_spin_lock_slowpath = native_queued_spin_lock_slowpath,
.queued_spin_unlock = PV_CALLEE_SAVE(__native_queued_spin_unlock),
.wait = paravirt_nop,
.kick = paravirt_nop,
-#else /* !CONFIG_QUEUED_SPINLOCKS */
- .lock_spinning = __PV_IS_CALLEE_SAVE(paravirt_nop),
- .unlock_kick = paravirt_nop,
-#endif /* !CONFIG_QUEUED_SPINLOCKS */
#endif /* SMP */
};
EXPORT_SYMBOL(pv_lock_ops);
diff --git a/arch/x86/kernel/paravirt_patch_32.c b/arch/x86/kernel/paravirt_patch_32.c
index 158dc06..920c6ae 100644
--- a/arch/x86/kernel/paravirt_patch_32.c
+++ b/arch/x86/kernel/paravirt_patch_32.c
@@ -10,7 +10,7 @@
DEF_NATIVE(pv_mmu_ops, read_cr3, "mov %cr3, %eax");
DEF_NATIVE(pv_cpu_ops, clts, "clts");
-#if defined(CONFIG_PARAVIRT_SPINLOCKS) && defined(CONFIG_QUEUED_SPINLOCKS)
+#if defined(CONFIG_PARAVIRT_SPINLOCKS)
DEF_NATIVE(pv_lock_ops, queued_spin_unlock, "movb $0, (%eax)");
#endif
@@ -49,7 +49,7 @@
PATCH_SITE(pv_mmu_ops, read_cr3);
PATCH_SITE(pv_mmu_ops, write_cr3);
PATCH_SITE(pv_cpu_ops, clts);
-#if defined(CONFIG_PARAVIRT_SPINLOCKS) && defined(CONFIG_QUEUED_SPINLOCKS)
+#if defined(CONFIG_PARAVIRT_SPINLOCKS)
case PARAVIRT_PATCH(pv_lock_ops.queued_spin_unlock):
if (pv_is_native_spin_unlock()) {
start = start_pv_lock_ops_queued_spin_unlock;
diff --git a/arch/x86/kernel/paravirt_patch_64.c b/arch/x86/kernel/paravirt_patch_64.c
index e70087a..bb3840c 100644
--- a/arch/x86/kernel/paravirt_patch_64.c
+++ b/arch/x86/kernel/paravirt_patch_64.c
@@ -19,7 +19,7 @@
DEF_NATIVE(, mov32, "mov %edi, %eax");
DEF_NATIVE(, mov64, "mov %rdi, %rax");
-#if defined(CONFIG_PARAVIRT_SPINLOCKS) && defined(CONFIG_QUEUED_SPINLOCKS)
+#if defined(CONFIG_PARAVIRT_SPINLOCKS)
DEF_NATIVE(pv_lock_ops, queued_spin_unlock, "movb $0, (%rdi)");
#endif
@@ -61,7 +61,7 @@
PATCH_SITE(pv_cpu_ops, clts);
PATCH_SITE(pv_mmu_ops, flush_tlb_single);
PATCH_SITE(pv_cpu_ops, wbinvd);
-#if defined(CONFIG_PARAVIRT_SPINLOCKS) && defined(CONFIG_QUEUED_SPINLOCKS)
+#if defined(CONFIG_PARAVIRT_SPINLOCKS)
case PARAVIRT_PATCH(pv_lock_ops.queued_spin_unlock):
if (pv_is_native_spin_unlock()) {
start = start_pv_lock_ops_queued_spin_unlock;
diff --git a/arch/x86/kernel/setup.c b/arch/x86/kernel/setup.c
index 0fa60f5..7e54491 100644
--- a/arch/x86/kernel/setup.c
+++ b/arch/x86/kernel/setup.c
@@ -1096,19 +1096,19 @@
memblock_set_current_limit(ISA_END_ADDRESS);
memblock_x86_fill();
- if (efi_enabled(EFI_BOOT)) {
- efi_fake_memmap();
- efi_find_mirror();
- }
-
reserve_bios_regions();
- /*
- * The EFI specification says that boot service code won't be called
- * after ExitBootServices(). This is, in fact, a lie.
- */
- if (efi_enabled(EFI_MEMMAP))
+ if (efi_enabled(EFI_MEMMAP)) {
+ efi_fake_memmap();
+ efi_find_mirror();
+ efi_esrt_init();
+
+ /*
+ * The EFI specification says that boot service code won't be
+ * called after ExitBootServices(). This is, in fact, a lie.
+ */
efi_reserve_boot_services();
+ }
/* preallocate 4k for mptable mpc */
early_reserve_e820_mpc_new();
@@ -1137,9 +1137,7 @@
* auditing all the early-boot CR4 manipulation would be needed to
* rule it out.
*/
- if (boot_cpu_data.cpuid_level >= 0)
- /* A CPU has %cr4 if and only if it has CPUID. */
- mmu_cr4_features = __read_cr4();
+ mmu_cr4_features = __read_cr4_safe();
memblock_set_current_limit(get_max_mapped());
diff --git a/arch/x86/mm/pageattr.c b/arch/x86/mm/pageattr.c
index 849dc09..e3353c9 100644
--- a/arch/x86/mm/pageattr.c
+++ b/arch/x86/mm/pageattr.c
@@ -917,11 +917,11 @@
}
}
-static int populate_pmd(struct cpa_data *cpa,
- unsigned long start, unsigned long end,
- unsigned num_pages, pud_t *pud, pgprot_t pgprot)
+static long populate_pmd(struct cpa_data *cpa,
+ unsigned long start, unsigned long end,
+ unsigned num_pages, pud_t *pud, pgprot_t pgprot)
{
- unsigned int cur_pages = 0;
+ long cur_pages = 0;
pmd_t *pmd;
pgprot_t pmd_pgprot;
@@ -991,12 +991,12 @@
return num_pages;
}
-static int populate_pud(struct cpa_data *cpa, unsigned long start, pgd_t *pgd,
- pgprot_t pgprot)
+static long populate_pud(struct cpa_data *cpa, unsigned long start, pgd_t *pgd,
+ pgprot_t pgprot)
{
pud_t *pud;
unsigned long end;
- int cur_pages = 0;
+ long cur_pages = 0;
pgprot_t pud_pgprot;
end = start + (cpa->numpages << PAGE_SHIFT);
@@ -1052,7 +1052,7 @@
/* Map trailing leftover */
if (start < end) {
- int tmp;
+ long tmp;
pud = pud_offset(pgd, start);
if (pud_none(*pud))
@@ -1078,7 +1078,7 @@
pgprot_t pgprot = __pgprot(_KERNPG_TABLE);
pud_t *pud = NULL; /* shut up gcc */
pgd_t *pgd_entry;
- int ret;
+ long ret;
pgd_entry = cpa->pgd + pgd_index(addr);
@@ -1327,7 +1327,8 @@
static int __change_page_attr_set_clr(struct cpa_data *cpa, int checkalias)
{
- int ret, numpages = cpa->numpages;
+ unsigned long numpages = cpa->numpages;
+ int ret;
while (numpages) {
/*
diff --git a/arch/x86/platform/efi/efi-bgrt.c b/arch/x86/platform/efi/efi-bgrt.c
index 6a2f569..6aad870 100644
--- a/arch/x86/platform/efi/efi-bgrt.c
+++ b/arch/x86/platform/efi/efi-bgrt.c
@@ -82,21 +82,12 @@
}
bgrt_image_size = bmp_header.size;
- bgrt_image = kmalloc(bgrt_image_size, GFP_KERNEL | __GFP_NOWARN);
+ bgrt_image = memremap(bgrt_tab->image_address, bmp_header.size, MEMREMAP_WB);
if (!bgrt_image) {
- pr_notice("Ignoring BGRT: failed to allocate memory for image (wanted %zu bytes)\n",
- bgrt_image_size);
- return;
- }
-
- image = memremap(bgrt_tab->image_address, bmp_header.size, MEMREMAP_WB);
- if (!image) {
pr_notice("Ignoring BGRT: failed to map image memory\n");
- kfree(bgrt_image);
bgrt_image = NULL;
return;
}
- memcpy(bgrt_image, image, bgrt_image_size);
- memunmap(image);
+ efi_mem_reserve(bgrt_tab->image_address, bgrt_image_size);
}
diff --git a/arch/x86/platform/efi/efi.c b/arch/x86/platform/efi/efi.c
index 1fbb408..0955c70 100644
--- a/arch/x86/platform/efi/efi.c
+++ b/arch/x86/platform/efi/efi.c
@@ -172,7 +172,9 @@
int __init efi_memblock_x86_reserve_range(void)
{
struct efi_info *e = &boot_params.efi_info;
+ struct efi_memory_map_data data;
phys_addr_t pmap;
+ int rv;
if (efi_enabled(EFI_PARAVIRT))
return 0;
@@ -187,11 +189,17 @@
#else
pmap = (e->efi_memmap | ((__u64)e->efi_memmap_hi << 32));
#endif
- efi.memmap.phys_map = pmap;
- efi.memmap.nr_map = e->efi_memmap_size /
- e->efi_memdesc_size;
- efi.memmap.desc_size = e->efi_memdesc_size;
- efi.memmap.desc_version = e->efi_memdesc_version;
+ data.phys_map = pmap;
+ data.size = e->efi_memmap_size;
+ data.desc_size = e->efi_memdesc_size;
+ data.desc_version = e->efi_memdesc_version;
+
+ rv = efi_memmap_init_early(&data);
+ if (rv)
+ return rv;
+
+ if (add_efi_memmap)
+ do_add_efi_memmap();
WARN(efi.memmap.desc_version != 1,
"Unexpected EFI_MEMORY_DESCRIPTOR version %ld",
@@ -218,19 +226,6 @@
}
}
-void __init efi_unmap_memmap(void)
-{
- unsigned long size;
-
- clear_bit(EFI_MEMMAP, &efi.flags);
-
- size = efi.memmap.nr_map * efi.memmap.desc_size;
- if (efi.memmap.map) {
- early_memunmap(efi.memmap.map, size);
- efi.memmap.map = NULL;
- }
-}
-
static int __init efi_systab_init(void *phys)
{
if (efi_enabled(EFI_64BIT)) {
@@ -414,33 +409,6 @@
return 0;
}
-static int __init efi_memmap_init(void)
-{
- unsigned long addr, size;
-
- if (efi_enabled(EFI_PARAVIRT))
- return 0;
-
- /* Map the EFI memory map */
- size = efi.memmap.nr_map * efi.memmap.desc_size;
- addr = (unsigned long)efi.memmap.phys_map;
-
- efi.memmap.map = early_memremap(addr, size);
- if (efi.memmap.map == NULL) {
- pr_err("Could not map the memory map!\n");
- return -ENOMEM;
- }
-
- efi.memmap.map_end = efi.memmap.map + size;
-
- if (add_efi_memmap)
- do_add_efi_memmap();
-
- set_bit(EFI_MEMMAP, &efi.flags);
-
- return 0;
-}
-
void __init efi_init(void)
{
efi_char16_t *c16;
@@ -498,16 +466,14 @@
if (!efi_runtime_supported())
pr_info("No EFI runtime due to 32/64-bit mismatch with kernel\n");
else {
- if (efi_runtime_disabled() || efi_runtime_init())
+ if (efi_runtime_disabled() || efi_runtime_init()) {
+ efi_memmap_unmap();
return;
+ }
}
- if (efi_memmap_init())
- return;
if (efi_enabled(EFI_DBG))
efi_print_memmap();
-
- efi_esrt_init();
}
void __init efi_late_init(void)
@@ -624,42 +590,6 @@
}
}
-static void __init save_runtime_map(void)
-{
-#ifdef CONFIG_KEXEC_CORE
- unsigned long desc_size;
- efi_memory_desc_t *md;
- void *tmp, *q = NULL;
- int count = 0;
-
- if (efi_enabled(EFI_OLD_MEMMAP))
- return;
-
- desc_size = efi.memmap.desc_size;
-
- for_each_efi_memory_desc(md) {
- if (!(md->attribute & EFI_MEMORY_RUNTIME) ||
- (md->type == EFI_BOOT_SERVICES_CODE) ||
- (md->type == EFI_BOOT_SERVICES_DATA))
- continue;
- tmp = krealloc(q, (count + 1) * desc_size, GFP_KERNEL);
- if (!tmp)
- goto out;
- q = tmp;
-
- memcpy(q + count * desc_size, md, desc_size);
- count++;
- }
-
- efi_runtime_map_setup(q, count, desc_size);
- return;
-
-out:
- kfree(q);
- pr_err("Error saving runtime map, efi runtime on kexec non-functional!!\n");
-#endif
-}
-
static void *realloc_pages(void *old_memmap, int old_shift)
{
void *ret;
@@ -745,6 +675,46 @@
return entry;
}
+static bool should_map_region(efi_memory_desc_t *md)
+{
+ /*
+ * Runtime regions always require runtime mappings (obviously).
+ */
+ if (md->attribute & EFI_MEMORY_RUNTIME)
+ return true;
+
+ /*
+ * 32-bit EFI doesn't suffer from the bug that requires us to
+ * reserve boot services regions, and mixed mode support
+ * doesn't exist for 32-bit kernels.
+ */
+ if (IS_ENABLED(CONFIG_X86_32))
+ return false;
+
+ /*
+ * Map all of RAM so that we can access arguments in the 1:1
+ * mapping when making EFI runtime calls.
+ */
+ if (IS_ENABLED(CONFIG_EFI_MIXED) && !efi_is_native()) {
+ if (md->type == EFI_CONVENTIONAL_MEMORY ||
+ md->type == EFI_LOADER_DATA ||
+ md->type == EFI_LOADER_CODE)
+ return true;
+ }
+
+ /*
+ * Map boot services regions as a workaround for buggy
+ * firmware that accesses them even when they shouldn't.
+ *
+ * See efi_{reserve,free}_boot_services().
+ */
+ if (md->type == EFI_BOOT_SERVICES_CODE ||
+ md->type == EFI_BOOT_SERVICES_DATA)
+ return true;
+
+ return false;
+}
+
/*
* Map the efi memory ranges of the runtime services and update new_mmap with
* virtual addresses.
@@ -761,13 +731,9 @@
p = NULL;
while ((p = efi_map_next_entry(p))) {
md = p;
- if (!(md->attribute & EFI_MEMORY_RUNTIME)) {
-#ifdef CONFIG_X86_64
- if (md->type != EFI_BOOT_SERVICES_CODE &&
- md->type != EFI_BOOT_SERVICES_DATA)
-#endif
- continue;
- }
+
+ if (!should_map_region(md))
+ continue;
efi_map_region(md);
get_systab_virt_addr(md);
@@ -803,7 +769,7 @@
* non-native EFI
*/
if (!efi_is_native()) {
- efi_unmap_memmap();
+ efi_memmap_unmap();
clear_bit(EFI_RUNTIME_SERVICES, &efi.flags);
return;
}
@@ -823,7 +789,18 @@
get_systab_virt_addr(md);
}
- save_runtime_map();
+ /*
+ * Unregister the early EFI memmap from efi_init() and install
+ * the new EFI memory map.
+ */
+ efi_memmap_unmap();
+
+ if (efi_memmap_init_late(efi.memmap.phys_map,
+ efi.memmap.desc_size * efi.memmap.nr_map)) {
+ pr_err("Failed to remap late EFI memory map\n");
+ clear_bit(EFI_RUNTIME_SERVICES, &efi.flags);
+ return;
+ }
BUG_ON(!efi.systab);
@@ -884,6 +861,7 @@
int count = 0, pg_shift = 0;
void *new_memmap = NULL;
efi_status_t status;
+ phys_addr_t pa;
efi.systab = NULL;
@@ -901,11 +879,24 @@
return;
}
- save_runtime_map();
+ pa = __pa(new_memmap);
+
+ /*
+ * Unregister the early EFI memmap from efi_init() and install
+ * the new EFI memory map that we are about to pass to the
+ * firmware via SetVirtualAddressMap().
+ */
+ efi_memmap_unmap();
+
+ if (efi_memmap_init_late(pa, efi.memmap.desc_size * count)) {
+ pr_err("Failed to remap late EFI memory map\n");
+ clear_bit(EFI_RUNTIME_SERVICES, &efi.flags);
+ return;
+ }
BUG_ON(!efi.systab);
- if (efi_setup_page_tables(__pa(new_memmap), 1 << pg_shift)) {
+ if (efi_setup_page_tables(pa, 1 << pg_shift)) {
clear_bit(EFI_RUNTIME_SERVICES, &efi.flags);
return;
}
@@ -917,14 +908,14 @@
efi.memmap.desc_size * count,
efi.memmap.desc_size,
efi.memmap.desc_version,
- (efi_memory_desc_t *)__pa(new_memmap));
+ (efi_memory_desc_t *)pa);
} else {
status = efi_thunk_set_virtual_address_map(
efi_phys.set_virtual_address_map,
efi.memmap.desc_size * count,
efi.memmap.desc_size,
efi.memmap.desc_version,
- (efi_memory_desc_t *)__pa(new_memmap));
+ (efi_memory_desc_t *)pa);
}
if (status != EFI_SUCCESS) {
@@ -956,15 +947,6 @@
efi_runtime_update_mappings();
efi_dump_pagetable();
- /*
- * We mapped the descriptor array into the EFI pagetable above
- * but we're not unmapping it here because if we're running in
- * EFI mixed mode we need all of memory to be accessible when
- * we pass parameters to the EFI runtime services in the
- * thunking code.
- */
- free_pages((unsigned long)new_memmap, pg_shift);
-
/* clean DUMMY object */
efi_delete_dummy_variable();
}
diff --git a/arch/x86/platform/efi/efi_64.c b/arch/x86/platform/efi/efi_64.c
index 677e29e..58b0f80 100644
--- a/arch/x86/platform/efi/efi_64.c
+++ b/arch/x86/platform/efi/efi_64.c
@@ -85,7 +85,7 @@
early_code_mapping_set_exec(1);
n_pgds = DIV_ROUND_UP((max_pfn << PAGE_SHIFT), PGDIR_SIZE);
- save_pgd = kmalloc(n_pgds * sizeof(pgd_t), GFP_KERNEL);
+ save_pgd = kmalloc_array(n_pgds, sizeof(*save_pgd), GFP_KERNEL);
for (pgd = 0; pgd < n_pgds; pgd++) {
save_pgd[pgd] = *pgd_offset_k(pgd * PGDIR_SIZE);
@@ -214,7 +214,6 @@
int __init efi_setup_page_tables(unsigned long pa_memmap, unsigned num_pages)
{
unsigned long pfn, text;
- efi_memory_desc_t *md;
struct page *page;
unsigned npages;
pgd_t *pgd;
@@ -245,28 +244,9 @@
* text and allocate a new stack because we can't rely on the
* stack pointer being < 4GB.
*/
- if (!IS_ENABLED(CONFIG_EFI_MIXED))
+ if (!IS_ENABLED(CONFIG_EFI_MIXED) || efi_is_native())
return 0;
- /*
- * Map all of RAM so that we can access arguments in the 1:1
- * mapping when making EFI runtime calls.
- */
- for_each_efi_memory_desc(md) {
- if (md->type != EFI_CONVENTIONAL_MEMORY &&
- md->type != EFI_LOADER_DATA &&
- md->type != EFI_LOADER_CODE)
- continue;
-
- pfn = md->phys_addr >> PAGE_SHIFT;
- npages = md->num_pages;
-
- if (kernel_map_pages_in_pgd(pgd, pfn, md->phys_addr, npages, _PAGE_RW)) {
- pr_err("Failed to map 1:1 memory\n");
- return 1;
- }
- }
-
page = alloc_page(GFP_KERNEL|__GFP_DMA32);
if (!page)
panic("Unable to allocate EFI runtime stack < 4GB\n");
@@ -359,6 +339,7 @@
*/
void __init efi_map_region_fixed(efi_memory_desc_t *md)
{
+ __map_region(md, md->phys_addr);
__map_region(md, md->virt_addr);
}
diff --git a/arch/x86/platform/efi/quirks.c b/arch/x86/platform/efi/quirks.c
index 89d1146..10aca63 100644
--- a/arch/x86/platform/efi/quirks.c
+++ b/arch/x86/platform/efi/quirks.c
@@ -164,6 +164,75 @@
EXPORT_SYMBOL_GPL(efi_query_variable_store);
/*
+ * The UEFI specification makes it clear that the operating system is
+ * free to do whatever it wants with boot services code after
+ * ExitBootServices() has been called. Ignoring this recommendation a
+ * significant bunch of EFI implementations continue calling into boot
+ * services code (SetVirtualAddressMap). In order to work around such
+ * buggy implementations we reserve boot services region during EFI
+ * init and make sure it stays executable. Then, after
+ * SetVirtualAddressMap(), it is discarded.
+ *
+ * However, some boot services regions contain data that is required
+ * by drivers, so we need to track which memory ranges can never be
+ * freed. This is done by tagging those regions with the
+ * EFI_MEMORY_RUNTIME attribute.
+ *
+ * Any driver that wants to mark a region as reserved must use
+ * efi_mem_reserve() which will insert a new EFI memory descriptor
+ * into efi.memmap (splitting existing regions if necessary) and tag
+ * it with EFI_MEMORY_RUNTIME.
+ */
+void __init efi_arch_mem_reserve(phys_addr_t addr, u64 size)
+{
+ phys_addr_t new_phys, new_size;
+ struct efi_mem_range mr;
+ efi_memory_desc_t md;
+ int num_entries;
+ void *new;
+
+ if (efi_mem_desc_lookup(addr, &md)) {
+ pr_err("Failed to lookup EFI memory descriptor for %pa\n", &addr);
+ return;
+ }
+
+ if (addr + size > md.phys_addr + (md.num_pages << EFI_PAGE_SHIFT)) {
+ pr_err("Region spans EFI memory descriptors, %pa\n", &addr);
+ return;
+ }
+
+ size += addr % EFI_PAGE_SIZE;
+ size = round_up(size, EFI_PAGE_SIZE);
+ addr = round_down(addr, EFI_PAGE_SIZE);
+
+ mr.range.start = addr;
+ mr.range.end = addr + size - 1;
+ mr.attribute = md.attribute | EFI_MEMORY_RUNTIME;
+
+ num_entries = efi_memmap_split_count(&md, &mr.range);
+ num_entries += efi.memmap.nr_map;
+
+ new_size = efi.memmap.desc_size * num_entries;
+
+ new_phys = memblock_alloc(new_size, 0);
+ if (!new_phys) {
+ pr_err("Could not allocate boot services memmap\n");
+ return;
+ }
+
+ new = early_memremap(new_phys, new_size);
+ if (!new) {
+ pr_err("Failed to map new boot services memmap\n");
+ return;
+ }
+
+ efi_memmap_insert(&efi.memmap, new, &mr);
+ early_memunmap(new, new_size);
+
+ efi_memmap_install(new_phys, num_entries);
+}
+
+/*
* Helper function for efi_reserve_boot_services() to figure out if we
* can free regions in efi_free_boot_services().
*
@@ -184,15 +253,6 @@
return true;
}
-/*
- * The UEFI specification makes it clear that the operating system is free to do
- * whatever it wants with boot services code after ExitBootServices() has been
- * called. Ignoring this recommendation a significant bunch of EFI implementations
- * continue calling into boot services code (SetVirtualAddressMap). In order to
- * work around such buggy implementations we reserve boot services region during
- * EFI init and make sure it stays executable. Then, after SetVirtualAddressMap(), it
-* is discarded.
-*/
void __init efi_reserve_boot_services(void)
{
efi_memory_desc_t *md;
@@ -249,7 +309,10 @@
void __init efi_free_boot_services(void)
{
+ phys_addr_t new_phys, new_size;
efi_memory_desc_t *md;
+ int num_entries = 0;
+ void *new, *new_md;
for_each_efi_memory_desc(md) {
unsigned long long start = md->phys_addr;
@@ -257,12 +320,16 @@
size_t rm_size;
if (md->type != EFI_BOOT_SERVICES_CODE &&
- md->type != EFI_BOOT_SERVICES_DATA)
+ md->type != EFI_BOOT_SERVICES_DATA) {
+ num_entries++;
continue;
+ }
/* Do not free, someone else owns it: */
- if (md->attribute & EFI_MEMORY_RUNTIME)
+ if (md->attribute & EFI_MEMORY_RUNTIME) {
+ num_entries++;
continue;
+ }
/*
* Nasty quirk: if all sub-1MB memory is used for boot
@@ -287,7 +354,41 @@
free_bootmem_late(start, size);
}
- efi_unmap_memmap();
+ new_size = efi.memmap.desc_size * num_entries;
+ new_phys = memblock_alloc(new_size, 0);
+ if (!new_phys) {
+ pr_err("Failed to allocate new EFI memmap\n");
+ return;
+ }
+
+ new = memremap(new_phys, new_size, MEMREMAP_WB);
+ if (!new) {
+ pr_err("Failed to map new EFI memmap\n");
+ return;
+ }
+
+ /*
+ * Build a new EFI memmap that excludes any boot services
+ * regions that are not tagged EFI_MEMORY_RUNTIME, since those
+ * regions have now been freed.
+ */
+ new_md = new;
+ for_each_efi_memory_desc(md) {
+ if (!(md->attribute & EFI_MEMORY_RUNTIME) &&
+ (md->type == EFI_BOOT_SERVICES_CODE ||
+ md->type == EFI_BOOT_SERVICES_DATA))
+ continue;
+
+ memcpy(new_md, md, efi.memmap.desc_size);
+ new_md += efi.memmap.desc_size;
+ }
+
+ memunmap(new);
+
+ if (efi_memmap_install(new_phys, num_entries)) {
+ pr_err("Could not install new EFI memmap\n");
+ return;
+ }
}
/*
@@ -365,7 +466,7 @@
*/
if (!efi_runtime_supported()) {
pr_info("Setup done, disabling due to 32/64-bit mismatch\n");
- efi_unmap_memmap();
+ efi_memmap_unmap();
}
/* UV2+ BIOS has a fix for this issue. UV1 still needs the quirk. */
diff --git a/arch/x86/xen/enlighten.c b/arch/x86/xen/enlighten.c
index b86ebb1..bc9aaba 100644
--- a/arch/x86/xen/enlighten.c
+++ b/arch/x86/xen/enlighten.c
@@ -1925,6 +1925,45 @@
}
}
+static void xen_pin_vcpu(int cpu)
+{
+ static bool disable_pinning;
+ struct sched_pin_override pin_override;
+ int ret;
+
+ if (disable_pinning)
+ return;
+
+ pin_override.pcpu = cpu;
+ ret = HYPERVISOR_sched_op(SCHEDOP_pin_override, &pin_override);
+
+ /* Ignore errors when removing override. */
+ if (cpu < 0)
+ return;
+
+ switch (ret) {
+ case -ENOSYS:
+ pr_warn("Unable to pin on physical cpu %d. In case of problems consider vcpu pinning.\n",
+ cpu);
+ disable_pinning = true;
+ break;
+ case -EPERM:
+ WARN(1, "Trying to pin vcpu without having privilege to do so\n");
+ disable_pinning = true;
+ break;
+ case -EINVAL:
+ case -EBUSY:
+ pr_warn("Physical cpu %d not available for pinning. Check Xen cpu configuration.\n",
+ cpu);
+ break;
+ case 0:
+ break;
+ default:
+ WARN(1, "rc %d while trying to pin vcpu\n", ret);
+ disable_pinning = true;
+ }
+}
+
const struct hypervisor_x86 x86_hyper_xen = {
.name = "Xen",
.detect = xen_platform,
@@ -1933,6 +1972,7 @@
#endif
.x2apic_available = xen_x2apic_para_available,
.set_cpu_features = xen_set_cpu_features,
+ .pin_vcpu = xen_pin_vcpu,
};
EXPORT_SYMBOL(x86_hyper_xen);
diff --git a/arch/x86/xen/spinlock.c b/arch/x86/xen/spinlock.c
index f42e78d..3d6e006 100644
--- a/arch/x86/xen/spinlock.c
+++ b/arch/x86/xen/spinlock.c
@@ -21,8 +21,6 @@
static DEFINE_PER_CPU(char *, irq_name);
static bool xen_pvspin = true;
-#ifdef CONFIG_QUEUED_SPINLOCKS
-
#include <asm/qspinlock.h>
static void xen_qlock_kick(int cpu)
@@ -71,207 +69,6 @@
xen_poll_irq(irq);
}
-#else /* CONFIG_QUEUED_SPINLOCKS */
-
-enum xen_contention_stat {
- TAKEN_SLOW,
- TAKEN_SLOW_PICKUP,
- TAKEN_SLOW_SPURIOUS,
- RELEASED_SLOW,
- RELEASED_SLOW_KICKED,
- NR_CONTENTION_STATS
-};
-
-
-#ifdef CONFIG_XEN_DEBUG_FS
-#define HISTO_BUCKETS 30
-static struct xen_spinlock_stats
-{
- u32 contention_stats[NR_CONTENTION_STATS];
- u32 histo_spin_blocked[HISTO_BUCKETS+1];
- u64 time_blocked;
-} spinlock_stats;
-
-static u8 zero_stats;
-
-static inline void check_zero(void)
-{
- u8 ret;
- u8 old = READ_ONCE(zero_stats);
- if (unlikely(old)) {
- ret = cmpxchg(&zero_stats, old, 0);
- /* This ensures only one fellow resets the stat */
- if (ret == old)
- memset(&spinlock_stats, 0, sizeof(spinlock_stats));
- }
-}
-
-static inline void add_stats(enum xen_contention_stat var, u32 val)
-{
- check_zero();
- spinlock_stats.contention_stats[var] += val;
-}
-
-static inline u64 spin_time_start(void)
-{
- return xen_clocksource_read();
-}
-
-static void __spin_time_accum(u64 delta, u32 *array)
-{
- unsigned index = ilog2(delta);
-
- check_zero();
-
- if (index < HISTO_BUCKETS)
- array[index]++;
- else
- array[HISTO_BUCKETS]++;
-}
-
-static inline void spin_time_accum_blocked(u64 start)
-{
- u32 delta = xen_clocksource_read() - start;
-
- __spin_time_accum(delta, spinlock_stats.histo_spin_blocked);
- spinlock_stats.time_blocked += delta;
-}
-#else /* !CONFIG_XEN_DEBUG_FS */
-static inline void add_stats(enum xen_contention_stat var, u32 val)
-{
-}
-
-static inline u64 spin_time_start(void)
-{
- return 0;
-}
-
-static inline void spin_time_accum_blocked(u64 start)
-{
-}
-#endif /* CONFIG_XEN_DEBUG_FS */
-
-struct xen_lock_waiting {
- struct arch_spinlock *lock;
- __ticket_t want;
-};
-
-static DEFINE_PER_CPU(struct xen_lock_waiting, lock_waiting);
-static cpumask_t waiting_cpus;
-
-__visible void xen_lock_spinning(struct arch_spinlock *lock, __ticket_t want)
-{
- int irq = __this_cpu_read(lock_kicker_irq);
- struct xen_lock_waiting *w = this_cpu_ptr(&lock_waiting);
- int cpu = smp_processor_id();
- u64 start;
- __ticket_t head;
- unsigned long flags;
-
- /* If kicker interrupts not initialized yet, just spin */
- if (irq == -1)
- return;
-
- start = spin_time_start();
-
- /*
- * Make sure an interrupt handler can't upset things in a
- * partially setup state.
- */
- local_irq_save(flags);
- /*
- * We don't really care if we're overwriting some other
- * (lock,want) pair, as that would mean that we're currently
- * in an interrupt context, and the outer context had
- * interrupts enabled. That has already kicked the VCPU out
- * of xen_poll_irq(), so it will just return spuriously and
- * retry with newly setup (lock,want).
- *
- * The ordering protocol on this is that the "lock" pointer
- * may only be set non-NULL if the "want" ticket is correct.
- * If we're updating "want", we must first clear "lock".
- */
- w->lock = NULL;
- smp_wmb();
- w->want = want;
- smp_wmb();
- w->lock = lock;
-
- /* This uses set_bit, which atomic and therefore a barrier */
- cpumask_set_cpu(cpu, &waiting_cpus);
- add_stats(TAKEN_SLOW, 1);
-
- /* clear pending */
- xen_clear_irq_pending(irq);
-
- /* Only check lock once pending cleared */
- barrier();
-
- /*
- * Mark entry to slowpath before doing the pickup test to make
- * sure we don't deadlock with an unlocker.
- */
- __ticket_enter_slowpath(lock);
-
- /* make sure enter_slowpath, which is atomic does not cross the read */
- smp_mb__after_atomic();
-
- /*
- * check again make sure it didn't become free while
- * we weren't looking
- */
- head = READ_ONCE(lock->tickets.head);
- if (__tickets_equal(head, want)) {
- add_stats(TAKEN_SLOW_PICKUP, 1);
- goto out;
- }
-
- /* Allow interrupts while blocked */
- local_irq_restore(flags);
-
- /*
- * If an interrupt happens here, it will leave the wakeup irq
- * pending, which will cause xen_poll_irq() to return
- * immediately.
- */
-
- /* Block until irq becomes pending (or perhaps a spurious wakeup) */
- xen_poll_irq(irq);
- add_stats(TAKEN_SLOW_SPURIOUS, !xen_test_irq_pending(irq));
-
- local_irq_save(flags);
-
- kstat_incr_irq_this_cpu(irq);
-out:
- cpumask_clear_cpu(cpu, &waiting_cpus);
- w->lock = NULL;
-
- local_irq_restore(flags);
-
- spin_time_accum_blocked(start);
-}
-PV_CALLEE_SAVE_REGS_THUNK(xen_lock_spinning);
-
-static void xen_unlock_kick(struct arch_spinlock *lock, __ticket_t next)
-{
- int cpu;
-
- add_stats(RELEASED_SLOW, 1);
-
- for_each_cpu(cpu, &waiting_cpus) {
- const struct xen_lock_waiting *w = &per_cpu(lock_waiting, cpu);
-
- /* Make sure we read lock before want */
- if (READ_ONCE(w->lock) == lock &&
- READ_ONCE(w->want) == next) {
- add_stats(RELEASED_SLOW_KICKED, 1);
- xen_send_IPI_one(cpu, XEN_SPIN_UNLOCK_VECTOR);
- break;
- }
- }
-}
-#endif /* CONFIG_QUEUED_SPINLOCKS */
-
static irqreturn_t dummy_handler(int irq, void *dev_id)
{
BUG();
@@ -334,16 +131,12 @@
return;
}
printk(KERN_DEBUG "xen: PV spinlocks enabled\n");
-#ifdef CONFIG_QUEUED_SPINLOCKS
+
__pv_init_lock_hash();
pv_lock_ops.queued_spin_lock_slowpath = __pv_queued_spin_lock_slowpath;
pv_lock_ops.queued_spin_unlock = PV_CALLEE_SAVE(__pv_queued_spin_unlock);
pv_lock_ops.wait = xen_qlock_wait;
pv_lock_ops.kick = xen_qlock_kick;
-#else
- pv_lock_ops.lock_spinning = PV_CALLEE_SAVE(xen_lock_spinning);
- pv_lock_ops.unlock_kick = xen_unlock_kick;
-#endif
}
/*
@@ -372,44 +165,3 @@
}
early_param("xen_nopvspin", xen_parse_nopvspin);
-#if defined(CONFIG_XEN_DEBUG_FS) && !defined(CONFIG_QUEUED_SPINLOCKS)
-
-static struct dentry *d_spin_debug;
-
-static int __init xen_spinlock_debugfs(void)
-{
- struct dentry *d_xen = xen_init_debugfs();
-
- if (d_xen == NULL)
- return -ENOMEM;
-
- if (!xen_pvspin)
- return 0;
-
- d_spin_debug = debugfs_create_dir("spinlocks", d_xen);
-
- debugfs_create_u8("zero_stats", 0644, d_spin_debug, &zero_stats);
-
- debugfs_create_u32("taken_slow", 0444, d_spin_debug,
- &spinlock_stats.contention_stats[TAKEN_SLOW]);
- debugfs_create_u32("taken_slow_pickup", 0444, d_spin_debug,
- &spinlock_stats.contention_stats[TAKEN_SLOW_PICKUP]);
- debugfs_create_u32("taken_slow_spurious", 0444, d_spin_debug,
- &spinlock_stats.contention_stats[TAKEN_SLOW_SPURIOUS]);
-
- debugfs_create_u32("released_slow", 0444, d_spin_debug,
- &spinlock_stats.contention_stats[RELEASED_SLOW]);
- debugfs_create_u32("released_slow_kicked", 0444, d_spin_debug,
- &spinlock_stats.contention_stats[RELEASED_SLOW_KICKED]);
-
- debugfs_create_u64("time_blocked", 0444, d_spin_debug,
- &spinlock_stats.time_blocked);
-
- debugfs_create_u32_array("histo_blocked", 0444, d_spin_debug,
- spinlock_stats.histo_spin_blocked, HISTO_BUCKETS + 1);
-
- return 0;
-}
-fs_initcall(xen_spinlock_debugfs);
-
-#endif /* CONFIG_XEN_DEBUG_FS */
diff --git a/block/blk-mq.c b/block/blk-mq.c
index 13f5a6c..c207fa9 100644
--- a/block/blk-mq.c
+++ b/block/blk-mq.c
@@ -296,17 +296,29 @@
if (ret)
return ERR_PTR(ret);
+ /*
+ * Check if the hardware context is actually mapped to anything.
+ * If not tell the caller that it should skip this queue.
+ */
hctx = q->queue_hw_ctx[hctx_idx];
+ if (!blk_mq_hw_queue_mapped(hctx)) {
+ ret = -EXDEV;
+ goto out_queue_exit;
+ }
ctx = __blk_mq_get_ctx(q, cpumask_first(hctx->cpumask));
blk_mq_set_alloc_data(&alloc_data, q, flags, ctx, hctx);
rq = __blk_mq_alloc_request(&alloc_data, rw, 0);
if (!rq) {
- blk_queue_exit(q);
- return ERR_PTR(-EWOULDBLOCK);
+ ret = -EWOULDBLOCK;
+ goto out_queue_exit;
}
return rq;
+
+out_queue_exit:
+ blk_queue_exit(q);
+ return ERR_PTR(ret);
}
EXPORT_SYMBOL_GPL(blk_mq_alloc_request_hctx);
diff --git a/block/blk-throttle.c b/block/blk-throttle.c
index f1aba26..a3ea826 100644
--- a/block/blk-throttle.c
+++ b/block/blk-throttle.c
@@ -780,9 +780,11 @@
/*
* If previous slice expired, start a new one otherwise renew/extend
* existing slice to make sure it is at least throtl_slice interval
- * long since now.
+ * long since now. New slice is started only for empty throttle group.
+ * If there is queued bio, that means there should be an active
+ * slice and it should be extended instead.
*/
- if (throtl_slice_used(tg, rw))
+ if (throtl_slice_used(tg, rw) && !(tg->service_queue.nr_queued[rw]))
throtl_start_new_slice(tg, rw);
else {
if (time_before(tg->slice_end[rw], jiffies + throtl_slice))
diff --git a/crypto/blkcipher.c b/crypto/blkcipher.c
index 3699995..a832426 100644
--- a/crypto/blkcipher.c
+++ b/crypto/blkcipher.c
@@ -233,6 +233,8 @@
return blkcipher_walk_done(desc, walk, -EINVAL);
}
+ bsize = min(walk->walk_blocksize, n);
+
walk->flags &= ~(BLKCIPHER_WALK_SLOW | BLKCIPHER_WALK_COPY |
BLKCIPHER_WALK_DIFF);
if (!scatterwalk_aligned(&walk->in, walk->alignmask) ||
@@ -245,7 +247,6 @@
}
}
- bsize = min(walk->walk_blocksize, n);
n = scatterwalk_clamp(&walk->in, n);
n = scatterwalk_clamp(&walk->out, n);
diff --git a/crypto/echainiv.c b/crypto/echainiv.c
index 1b01fe9..e3d889b 100644
--- a/crypto/echainiv.c
+++ b/crypto/echainiv.c
@@ -1,8 +1,8 @@
/*
* echainiv: Encrypted Chain IV Generator
*
- * This generator generates an IV based on a sequence number by xoring it
- * with a salt and then encrypting it with the same key as used to encrypt
+ * This generator generates an IV based on a sequence number by multiplying
+ * it with a salt and then encrypting it with the same key as used to encrypt
* the plain text. This algorithm requires that the block size be equal
* to the IV size. It is mainly useful for CBC.
*
@@ -24,81 +24,17 @@
#include <linux/err.h>
#include <linux/init.h>
#include <linux/kernel.h>
-#include <linux/mm.h>
#include <linux/module.h>
-#include <linux/percpu.h>
-#include <linux/spinlock.h>
+#include <linux/slab.h>
#include <linux/string.h>
-#define MAX_IV_SIZE 16
-
-static DEFINE_PER_CPU(u32 [MAX_IV_SIZE / sizeof(u32)], echainiv_iv);
-
-/* We don't care if we get preempted and read/write IVs from the next CPU. */
-static void echainiv_read_iv(u8 *dst, unsigned size)
-{
- u32 *a = (u32 *)dst;
- u32 __percpu *b = echainiv_iv;
-
- for (; size >= 4; size -= 4) {
- *a++ = this_cpu_read(*b);
- b++;
- }
-}
-
-static void echainiv_write_iv(const u8 *src, unsigned size)
-{
- const u32 *a = (const u32 *)src;
- u32 __percpu *b = echainiv_iv;
-
- for (; size >= 4; size -= 4) {
- this_cpu_write(*b, *a);
- a++;
- b++;
- }
-}
-
-static void echainiv_encrypt_complete2(struct aead_request *req, int err)
-{
- struct aead_request *subreq = aead_request_ctx(req);
- struct crypto_aead *geniv;
- unsigned int ivsize;
-
- if (err == -EINPROGRESS)
- return;
-
- if (err)
- goto out;
-
- geniv = crypto_aead_reqtfm(req);
- ivsize = crypto_aead_ivsize(geniv);
-
- echainiv_write_iv(subreq->iv, ivsize);
-
- if (req->iv != subreq->iv)
- memcpy(req->iv, subreq->iv, ivsize);
-
-out:
- if (req->iv != subreq->iv)
- kzfree(subreq->iv);
-}
-
-static void echainiv_encrypt_complete(struct crypto_async_request *base,
- int err)
-{
- struct aead_request *req = base->data;
-
- echainiv_encrypt_complete2(req, err);
- aead_request_complete(req, err);
-}
-
static int echainiv_encrypt(struct aead_request *req)
{
struct crypto_aead *geniv = crypto_aead_reqtfm(req);
struct aead_geniv_ctx *ctx = crypto_aead_ctx(geniv);
struct aead_request *subreq = aead_request_ctx(req);
- crypto_completion_t compl;
- void *data;
+ __be64 nseqno;
+ u64 seqno;
u8 *info;
unsigned int ivsize = crypto_aead_ivsize(geniv);
int err;
@@ -108,8 +44,6 @@
aead_request_set_tfm(subreq, ctx->child);
- compl = echainiv_encrypt_complete;
- data = req;
info = req->iv;
if (req->src != req->dst) {
@@ -127,29 +61,30 @@
return err;
}
- if (unlikely(!IS_ALIGNED((unsigned long)info,
- crypto_aead_alignmask(geniv) + 1))) {
- info = kmalloc(ivsize, req->base.flags &
- CRYPTO_TFM_REQ_MAY_SLEEP ? GFP_KERNEL:
- GFP_ATOMIC);
- if (!info)
- return -ENOMEM;
-
- memcpy(info, req->iv, ivsize);
- }
-
- aead_request_set_callback(subreq, req->base.flags, compl, data);
+ aead_request_set_callback(subreq, req->base.flags,
+ req->base.complete, req->base.data);
aead_request_set_crypt(subreq, req->dst, req->dst,
req->cryptlen, info);
aead_request_set_ad(subreq, req->assoclen);
- crypto_xor(info, ctx->salt, ivsize);
- scatterwalk_map_and_copy(info, req->dst, req->assoclen, ivsize, 1);
- echainiv_read_iv(info, ivsize);
+ memcpy(&nseqno, info + ivsize - 8, 8);
+ seqno = be64_to_cpu(nseqno);
+ memset(info, 0, ivsize);
- err = crypto_aead_encrypt(subreq);
- echainiv_encrypt_complete2(req, err);
- return err;
+ scatterwalk_map_and_copy(info, req->dst, req->assoclen, ivsize, 1);
+
+ do {
+ u64 a;
+
+ memcpy(&a, ctx->salt + ivsize - 8, 8);
+
+ a |= 1;
+ a *= seqno;
+
+ memcpy(info + ivsize - 8, &a, 8);
+ } while ((ivsize -= 8));
+
+ return crypto_aead_encrypt(subreq);
}
static int echainiv_decrypt(struct aead_request *req)
@@ -196,8 +131,7 @@
alg = crypto_spawn_aead_alg(spawn);
err = -EINVAL;
- if (inst->alg.ivsize & (sizeof(u32) - 1) ||
- inst->alg.ivsize > MAX_IV_SIZE)
+ if (inst->alg.ivsize & (sizeof(u64) - 1) || !inst->alg.ivsize)
goto free_inst;
inst->alg.encrypt = echainiv_encrypt;
@@ -206,7 +140,6 @@
inst->alg.init = aead_init_geniv;
inst->alg.exit = aead_exit_geniv;
- inst->alg.base.cra_alignmask |= __alignof__(u32) - 1;
inst->alg.base.cra_ctxsize = sizeof(struct aead_geniv_ctx);
inst->alg.base.cra_ctxsize += inst->alg.ivsize;
diff --git a/crypto/rsa-pkcs1pad.c b/crypto/rsa-pkcs1pad.c
index 877019a..8baab43 100644
--- a/crypto/rsa-pkcs1pad.c
+++ b/crypto/rsa-pkcs1pad.c
@@ -298,41 +298,48 @@
struct crypto_akcipher *tfm = crypto_akcipher_reqtfm(req);
struct pkcs1pad_ctx *ctx = akcipher_tfm_ctx(tfm);
struct pkcs1pad_request *req_ctx = akcipher_request_ctx(req);
+ unsigned int dst_len;
unsigned int pos;
-
- if (err == -EOVERFLOW)
- /* Decrypted value had no leading 0 byte */
- err = -EINVAL;
+ u8 *out_buf;
if (err)
goto done;
- if (req_ctx->child_req.dst_len != ctx->key_size - 1) {
- err = -EINVAL;
+ err = -EINVAL;
+ dst_len = req_ctx->child_req.dst_len;
+ if (dst_len < ctx->key_size - 1)
goto done;
+
+ out_buf = req_ctx->out_buf;
+ if (dst_len == ctx->key_size) {
+ if (out_buf[0] != 0x00)
+ /* Decrypted value had no leading 0 byte */
+ goto done;
+
+ dst_len--;
+ out_buf++;
}
- if (req_ctx->out_buf[0] != 0x02) {
- err = -EINVAL;
+ if (out_buf[0] != 0x02)
goto done;
- }
- for (pos = 1; pos < req_ctx->child_req.dst_len; pos++)
- if (req_ctx->out_buf[pos] == 0x00)
+
+ for (pos = 1; pos < dst_len; pos++)
+ if (out_buf[pos] == 0x00)
break;
- if (pos < 9 || pos == req_ctx->child_req.dst_len) {
- err = -EINVAL;
+ if (pos < 9 || pos == dst_len)
goto done;
- }
pos++;
- if (req->dst_len < req_ctx->child_req.dst_len - pos)
+ err = 0;
+
+ if (req->dst_len < dst_len - pos)
err = -EOVERFLOW;
- req->dst_len = req_ctx->child_req.dst_len - pos;
+ req->dst_len = dst_len - pos;
if (!err)
sg_copy_from_buffer(req->dst,
sg_nents_for_len(req->dst, req->dst_len),
- req_ctx->out_buf + pos, req->dst_len);
+ out_buf + pos, req->dst_len);
done:
kzfree(req_ctx->out_buf);
diff --git a/drivers/acpi/Kconfig b/drivers/acpi/Kconfig
index 445ce28..696c6f7 100644
--- a/drivers/acpi/Kconfig
+++ b/drivers/acpi/Kconfig
@@ -227,7 +227,6 @@
config ACPI_CPPC_LIB
bool
depends on ACPI_PROCESSOR
- depends on !ACPI_CPU_FREQ_PSS
select MAILBOX
select PCC
help
@@ -462,6 +461,9 @@
source "drivers/acpi/apei/Kconfig"
source "drivers/acpi/dptf/Kconfig"
+config ACPI_WATCHDOG
+ bool
+
config ACPI_EXTLOG
tristate "Extended Error Log support"
depends on X86_MCE && X86_LOCAL_APIC
diff --git a/drivers/acpi/Makefile b/drivers/acpi/Makefile
index 5ae9d85..3a1fa8f 100644
--- a/drivers/acpi/Makefile
+++ b/drivers/acpi/Makefile
@@ -56,6 +56,7 @@
acpi-$(CONFIG_ACPI_PROCFS_POWER) += cm_sbs.o
acpi-y += acpi_lpat.o
acpi-$(CONFIG_ACPI_GENERIC_GSI) += gsi.o
+acpi-$(CONFIG_ACPI_WATCHDOG) += acpi_watchdog.o
# These are (potentially) separate modules
diff --git a/drivers/acpi/acpi_apd.c b/drivers/acpi/acpi_apd.c
index 1daf9c4..d58fbf7 100644
--- a/drivers/acpi/acpi_apd.c
+++ b/drivers/acpi/acpi_apd.c
@@ -42,6 +42,7 @@
struct apd_device_desc {
unsigned int flags;
unsigned int fixed_clk_rate;
+ struct property_entry *properties;
int (*setup)(struct apd_private_data *pdata);
};
@@ -71,22 +72,35 @@
}
#ifdef CONFIG_X86_AMD_PLATFORM_DEVICE
-static struct apd_device_desc cz_i2c_desc = {
+static const struct apd_device_desc cz_i2c_desc = {
.setup = acpi_apd_setup,
.fixed_clk_rate = 133000000,
};
-static struct apd_device_desc cz_uart_desc = {
+static struct property_entry uart_properties[] = {
+ PROPERTY_ENTRY_U32("reg-io-width", 4),
+ PROPERTY_ENTRY_U32("reg-shift", 2),
+ PROPERTY_ENTRY_BOOL("snps,uart-16550-compatible"),
+ { },
+};
+
+static const struct apd_device_desc cz_uart_desc = {
.setup = acpi_apd_setup,
.fixed_clk_rate = 48000000,
+ .properties = uart_properties,
};
#endif
#ifdef CONFIG_ARM64
-static struct apd_device_desc xgene_i2c_desc = {
+static const struct apd_device_desc xgene_i2c_desc = {
.setup = acpi_apd_setup,
.fixed_clk_rate = 100000000,
};
+
+static const struct apd_device_desc vulcan_spi_desc = {
+ .setup = acpi_apd_setup,
+ .fixed_clk_rate = 133000000,
+};
#endif
#else
@@ -125,6 +139,12 @@
goto err_out;
}
+ if (dev_desc->properties) {
+ ret = device_add_properties(&adev->dev, dev_desc->properties);
+ if (ret)
+ goto err_out;
+ }
+
adev->driver_data = pdata;
pdev = acpi_create_platform_device(adev);
if (!IS_ERR_OR_NULL(pdev))
@@ -149,6 +169,7 @@
#endif
#ifdef CONFIG_ARM64
{ "APMC0D0F", APD_ADDR(xgene_i2c_desc) },
+ { "BRCM900D", APD_ADDR(vulcan_spi_desc) },
#endif
{ }
};
diff --git a/drivers/acpi/acpi_lpss.c b/drivers/acpi/acpi_lpss.c
index 357a0b8..5520102 100644
--- a/drivers/acpi/acpi_lpss.c
+++ b/drivers/acpi/acpi_lpss.c
@@ -75,6 +75,7 @@
const char *clk_con_id;
unsigned int prv_offset;
size_t prv_size_override;
+ struct property_entry *properties;
void (*setup)(struct lpss_private_data *pdata);
};
@@ -163,11 +164,19 @@
.prv_offset = 0x800,
};
+static struct property_entry uart_properties[] = {
+ PROPERTY_ENTRY_U32("reg-io-width", 4),
+ PROPERTY_ENTRY_U32("reg-shift", 2),
+ PROPERTY_ENTRY_BOOL("snps,uart-16550-compatible"),
+ { },
+};
+
static const struct lpss_device_desc lpt_uart_dev_desc = {
.flags = LPSS_CLK | LPSS_CLK_GATE | LPSS_CLK_DIVIDER | LPSS_LTR,
.clk_con_id = "baudclk",
.prv_offset = 0x800,
.setup = lpss_uart_setup,
+ .properties = uart_properties,
};
static const struct lpss_device_desc lpt_sdio_dev_desc = {
@@ -189,6 +198,7 @@
.clk_con_id = "baudclk",
.prv_offset = 0x800,
.setup = lpss_uart_setup,
+ .properties = uart_properties,
};
static const struct lpss_device_desc bsw_uart_dev_desc = {
@@ -197,6 +207,7 @@
.clk_con_id = "baudclk",
.prv_offset = 0x800,
.setup = lpss_uart_setup,
+ .properties = uart_properties,
};
static const struct lpss_device_desc byt_spi_dev_desc = {
@@ -440,6 +451,12 @@
goto err_out;
}
+ if (dev_desc->properties) {
+ ret = device_add_properties(&adev->dev, dev_desc->properties);
+ if (ret)
+ goto err_out;
+ }
+
adev->driver_data = pdata;
pdev = acpi_create_platform_device(adev);
if (!IS_ERR_OR_NULL(pdev)) {
diff --git a/drivers/acpi/acpi_platform.c b/drivers/acpi/acpi_platform.c
index 159f7f1..b200ae1 100644
--- a/drivers/acpi/acpi_platform.c
+++ b/drivers/acpi/acpi_platform.c
@@ -17,6 +17,7 @@
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/dma-mapping.h>
+#include <linux/pci.h>
#include <linux/platform_device.h>
#include "internal.h"
@@ -30,6 +31,22 @@
{"", 0},
};
+static void acpi_platform_fill_resource(struct acpi_device *adev,
+ const struct resource *src, struct resource *dest)
+{
+ struct device *parent;
+
+ *dest = *src;
+
+ /*
+ * If the device has parent we need to take its resources into
+ * account as well because this device might consume part of those.
+ */
+ parent = acpi_get_first_physical_node(adev->parent);
+ if (parent && dev_is_pci(parent))
+ dest->parent = pci_find_resource(to_pci_dev(parent), dest);
+}
+
/**
* acpi_create_platform_device - Create platform device for ACPI device node
* @adev: ACPI device node to create a platform device for.
@@ -70,7 +87,8 @@
}
count = 0;
list_for_each_entry(rentry, &resource_list, node)
- resources[count++] = *rentry->res;
+ acpi_platform_fill_resource(adev, rentry->res,
+ &resources[count++]);
acpi_dev_free_resource_list(&resource_list);
}
diff --git a/drivers/acpi/acpi_watchdog.c b/drivers/acpi/acpi_watchdog.c
new file mode 100644
index 0000000..13caebd
--- /dev/null
+++ b/drivers/acpi/acpi_watchdog.c
@@ -0,0 +1,123 @@
+/*
+ * ACPI watchdog table parsing support.
+ *
+ * Copyright (C) 2016, Intel Corporation
+ * Author: Mika Westerberg <mika.westerberg@linux.intel.com>
+ *
+ * This program is free software; you can redistribute it and/or modify
+ * it under the terms of the GNU General Public License version 2 as
+ * published by the Free Software Foundation.
+ */
+
+#define pr_fmt(fmt) "ACPI: watchdog: " fmt
+
+#include <linux/acpi.h>
+#include <linux/ioport.h>
+#include <linux/platform_device.h>
+
+#include "internal.h"
+
+/**
+ * Returns true if this system should prefer ACPI based watchdog instead of
+ * the native one (which are typically the same hardware).
+ */
+bool acpi_has_watchdog(void)
+{
+ struct acpi_table_header hdr;
+
+ if (acpi_disabled)
+ return false;
+
+ return ACPI_SUCCESS(acpi_get_table_header(ACPI_SIG_WDAT, 0, &hdr));
+}
+EXPORT_SYMBOL_GPL(acpi_has_watchdog);
+
+void __init acpi_watchdog_init(void)
+{
+ const struct acpi_wdat_entry *entries;
+ const struct acpi_table_wdat *wdat;
+ struct list_head resource_list;
+ struct resource_entry *rentry;
+ struct platform_device *pdev;
+ struct resource *resources;
+ size_t nresources = 0;
+ acpi_status status;
+ int i;
+
+ status = acpi_get_table(ACPI_SIG_WDAT, 0,
+ (struct acpi_table_header **)&wdat);
+ if (ACPI_FAILURE(status)) {
+ /* It is fine if there is no WDAT */
+ return;
+ }
+
+ /* Watchdog disabled by BIOS */
+ if (!(wdat->flags & ACPI_WDAT_ENABLED))
+ return;
+
+ /* Skip legacy PCI WDT devices */
+ if (wdat->pci_segment != 0xff || wdat->pci_bus != 0xff ||
+ wdat->pci_device != 0xff || wdat->pci_function != 0xff)
+ return;
+
+ INIT_LIST_HEAD(&resource_list);
+
+ entries = (struct acpi_wdat_entry *)(wdat + 1);
+ for (i = 0; i < wdat->entries; i++) {
+ const struct acpi_generic_address *gas;
+ struct resource_entry *rentry;
+ struct resource res;
+ bool found;
+
+ gas = &entries[i].register_region;
+
+ res.start = gas->address;
+ if (gas->space_id == ACPI_ADR_SPACE_SYSTEM_MEMORY) {
+ res.flags = IORESOURCE_MEM;
+ res.end = res.start + ALIGN(gas->access_width, 4);
+ } else if (gas->space_id == ACPI_ADR_SPACE_SYSTEM_IO) {
+ res.flags = IORESOURCE_IO;
+ res.end = res.start + gas->access_width;
+ } else {
+ pr_warn("Unsupported address space: %u\n",
+ gas->space_id);
+ goto fail_free_resource_list;
+ }
+
+ found = false;
+ resource_list_for_each_entry(rentry, &resource_list) {
+ if (resource_contains(rentry->res, &res)) {
+ found = true;
+ break;
+ }
+ }
+
+ if (!found) {
+ rentry = resource_list_create_entry(NULL, 0);
+ if (!rentry)
+ goto fail_free_resource_list;
+
+ *rentry->res = res;
+ resource_list_add_tail(rentry, &resource_list);
+ nresources++;
+ }
+ }
+
+ resources = kcalloc(nresources, sizeof(*resources), GFP_KERNEL);
+ if (!resources)
+ goto fail_free_resource_list;
+
+ i = 0;
+ resource_list_for_each_entry(rentry, &resource_list)
+ resources[i++] = *rentry->res;
+
+ pdev = platform_device_register_simple("wdat_wdt", PLATFORM_DEVID_NONE,
+ resources, nresources);
+ if (IS_ERR(pdev))
+ pr_err("Failed to create platform device\n");
+
+ kfree(resources);
+
+fail_free_resource_list:
+ resource_list_free(&resource_list);
+}
diff --git a/drivers/acpi/acpica/Makefile b/drivers/acpi/acpica/Makefile
index 227bb7b..32d93ed 100644
--- a/drivers/acpi/acpica/Makefile
+++ b/drivers/acpi/acpica/Makefile
@@ -175,6 +175,7 @@
utresrc.o \
utstate.o \
utstring.o \
+ utstrtoul64.o \
utxface.o \
utxfinit.o \
utxferror.o \
diff --git a/drivers/acpi/acpica/acapps.h b/drivers/acpi/acpica/acapps.h
index ca2c060..0bd6307 100644
--- a/drivers/acpi/acpica/acapps.h
+++ b/drivers/acpi/acpica/acapps.h
@@ -44,7 +44,9 @@
#ifndef _ACAPPS
#define _ACAPPS
-#include <stdio.h>
+#ifdef ACPI_USE_STANDARD_HEADERS
+#include <sys/stat.h>
+#endif /* ACPI_USE_STANDARD_HEADERS */
/* Common info for tool signons */
@@ -81,13 +83,13 @@
/* Macros for usage messages */
#define ACPI_USAGE_HEADER(usage) \
- acpi_os_printf ("Usage: %s\nOptions:\n", usage);
+ printf ("Usage: %s\nOptions:\n", usage);
#define ACPI_USAGE_TEXT(description) \
- acpi_os_printf (description);
+ printf (description);
#define ACPI_OPTION(name, description) \
- acpi_os_printf (" %-20s%s\n", name, description);
+ printf (" %-20s%s\n", name, description);
/* Check for unexpected exceptions */
diff --git a/drivers/acpi/acpica/acdebug.h b/drivers/acpi/acpica/acdebug.h
index f6404ea..94737f8 100644
--- a/drivers/acpi/acpica/acdebug.h
+++ b/drivers/acpi/acpica/acdebug.h
@@ -155,7 +155,7 @@
void acpi_db_disassemble_aml(char *statements, union acpi_parse_object *op);
-void acpi_db_batch_execute(char *count_arg);
+void acpi_db_evaluate_predefined_names(void);
/*
* dbnames - namespace commands
diff --git a/drivers/acpi/acpica/acevents.h b/drivers/acpi/acpica/acevents.h
index 77af91c..92fa47c 100644
--- a/drivers/acpi/acpica/acevents.h
+++ b/drivers/acpi/acpica/acevents.h
@@ -86,6 +86,9 @@
acpi_status acpi_ev_enable_gpe(struct acpi_gpe_event_info *gpe_event_info);
acpi_status
+acpi_ev_mask_gpe(struct acpi_gpe_event_info *gpe_event_info, u8 is_masked);
+
+acpi_status
acpi_ev_add_gpe_reference(struct acpi_gpe_event_info *gpe_event_info);
acpi_status
diff --git a/drivers/acpi/acpica/acglobal.h b/drivers/acpi/acpica/acglobal.h
index fded776..750fa82 100644
--- a/drivers/acpi/acpica/acglobal.h
+++ b/drivers/acpi/acpica/acglobal.h
@@ -317,6 +317,7 @@
ACPI_INIT_GLOBAL(u8, acpi_gbl_cstyle_disassembly, TRUE);
ACPI_INIT_GLOBAL(u8, acpi_gbl_force_aml_disassembly, FALSE);
ACPI_INIT_GLOBAL(u8, acpi_gbl_dm_opt_verbose, TRUE);
+ACPI_INIT_GLOBAL(u8, acpi_gbl_dm_emit_external_opcodes, FALSE);
ACPI_GLOBAL(u8, acpi_gbl_dm_opt_disasm);
ACPI_GLOBAL(u8, acpi_gbl_dm_opt_listing);
@@ -382,6 +383,7 @@
ACPI_INIT_GLOBAL(ACPI_FILE, acpi_gbl_debug_file, NULL);
ACPI_INIT_GLOBAL(ACPI_FILE, acpi_gbl_output_file, NULL);
+ACPI_INIT_GLOBAL(u8, acpi_gbl_debug_timeout, FALSE);
/* Print buffer */
diff --git a/drivers/acpi/acpica/aclocal.h b/drivers/acpi/acpica/aclocal.h
index 13331d7..dff1207 100644
--- a/drivers/acpi/acpica/aclocal.h
+++ b/drivers/acpi/acpica/aclocal.h
@@ -484,6 +484,7 @@
u8 flags; /* Misc info about this GPE */
u8 gpe_number; /* This GPE */
u8 runtime_count; /* References to a run GPE */
+ u8 disable_for_dispatch; /* Masked during dispatching */
};
/* Information about a GPE register pair, one per each status/enable pair in an array */
@@ -494,6 +495,7 @@
u16 base_gpe_number; /* Base GPE number for this register */
u8 enable_for_wake; /* GPEs to keep enabled when sleeping */
u8 enable_for_run; /* GPEs to keep enabled when running */
+ u8 mask_for_run; /* GPEs to keep masked when running */
u8 enable_mask; /* Current mask of enabled GPEs */
};
diff --git a/drivers/acpi/acpica/acnamesp.h b/drivers/acpi/acpica/acnamesp.h
index f33a4ba..bb7fca1 100644
--- a/drivers/acpi/acpica/acnamesp.h
+++ b/drivers/acpi/acpica/acnamesp.h
@@ -130,6 +130,9 @@
acpi_ns_parse_table(u32 table_index, struct acpi_namespace_node *start_node);
acpi_status
+acpi_ns_execute_table(u32 table_index, struct acpi_namespace_node *start_node);
+
+acpi_status
acpi_ns_one_complete_parse(u32 pass_number,
u32 table_index,
struct acpi_namespace_node *start_node);
@@ -296,6 +299,11 @@
acpi_ns_pattern_match(struct acpi_namespace_node *obj_node, char *search_for);
acpi_status
+acpi_ns_get_node_unlocked(struct acpi_namespace_node *prefix_node,
+ const char *external_pathname,
+ u32 flags, struct acpi_namespace_node **out_node);
+
+acpi_status
acpi_ns_get_node(struct acpi_namespace_node *prefix_node,
const char *external_pathname,
u32 flags, struct acpi_namespace_node **out_node);
diff --git a/drivers/acpi/acpica/acparser.h b/drivers/acpi/acpica/acparser.h
index fc30577..939d411 100644
--- a/drivers/acpi/acpica/acparser.h
+++ b/drivers/acpi/acpica/acparser.h
@@ -78,6 +78,8 @@
*/
acpi_status acpi_ps_execute_method(struct acpi_evaluate_info *info);
+acpi_status acpi_ps_execute_table(struct acpi_evaluate_info *info);
+
/*
* psargs - Parse AML opcode arguments
*/
diff --git a/drivers/acpi/acpica/actables.h b/drivers/acpi/acpica/actables.h
index cd5a135..e85953b 100644
--- a/drivers/acpi/acpica/actables.h
+++ b/drivers/acpi/acpica/actables.h
@@ -123,6 +123,14 @@
void acpi_tb_uninstall_table(struct acpi_table_desc *table_desc);
+acpi_status
+acpi_tb_load_table(u32 table_index, struct acpi_namespace_node *parent_node);
+
+acpi_status
+acpi_tb_install_and_load_table(struct acpi_table_header *table,
+ acpi_physical_address address,
+ u8 flags, u8 override, u32 *table_index);
+
void acpi_tb_terminate(void);
acpi_status acpi_tb_delete_namespace_by_owner(u32 table_index);
@@ -155,10 +163,6 @@
acpi_tb_install_table_with_override(struct acpi_table_desc *new_table_desc,
u8 override, u32 *table_index);
-acpi_status
-acpi_tb_install_fixed_table(acpi_physical_address address,
- char *signature, u32 *table_index);
-
acpi_status acpi_tb_parse_root_table(acpi_physical_address rsdp_address);
/*
diff --git a/drivers/acpi/acpica/acutils.h b/drivers/acpi/acpica/acutils.h
index a7dbb2b..0a1b53c 100644
--- a/drivers/acpi/acpica/acutils.h
+++ b/drivers/acpi/acpica/acutils.h
@@ -114,13 +114,25 @@
/*
* Common error message prefixes
*/
+#ifndef ACPI_MSG_ERROR
#define ACPI_MSG_ERROR "ACPI Error: "
+#endif
+#ifndef ACPI_MSG_EXCEPTION
#define ACPI_MSG_EXCEPTION "ACPI Exception: "
+#endif
+#ifndef ACPI_MSG_WARNING
#define ACPI_MSG_WARNING "ACPI Warning: "
+#endif
+#ifndef ACPI_MSG_INFO
#define ACPI_MSG_INFO "ACPI: "
+#endif
+#ifndef ACPI_MSG_BIOS_ERROR
#define ACPI_MSG_BIOS_ERROR "ACPI BIOS Error (bug): "
+#endif
+#ifndef ACPI_MSG_BIOS_WARNING
#define ACPI_MSG_BIOS_WARNING "ACPI BIOS Warning (bug): "
+#endif
/*
* Common message suffix
@@ -184,14 +196,15 @@
int acpi_ut_stricmp(char *string1, char *string2);
-acpi_status
-acpi_ut_strtoul64(char *string,
- u32 base, u32 max_integer_byte_width, u64 *ret_integer);
+acpi_status acpi_ut_strtoul64(char *string, u32 flags, u64 *ret_integer);
-/* Values for max_integer_byte_width above */
-
-#define ACPI_MAX32_BYTE_WIDTH 4
-#define ACPI_MAX64_BYTE_WIDTH 8
+/*
+ * Values for Flags above
+ * Note: LIMIT values correspond to acpi_gbl_integer_byte_width values (4/8)
+ */
+#define ACPI_STRTOUL_32BIT 0x04 /* 4 bytes */
+#define ACPI_STRTOUL_64BIT 0x08 /* 8 bytes */
+#define ACPI_STRTOUL_BASE16 0x10 /* Default: Base10/16 */
/*
* utglobal - Global data structures and procedures
@@ -221,6 +234,8 @@
char acpi_ut_hex_to_ascii_char(u64 integer, u32 position);
+acpi_status acpi_ut_ascii_to_hex_byte(char *two_ascii_chars, u8 *return_byte);
+
u8 acpi_ut_ascii_char_to_hex(int hex_char);
u8 acpi_ut_valid_object_type(acpi_object_type type);
@@ -318,6 +333,11 @@
const char *module_name, u32 component_id, u8 *ptr);
void
+acpi_ut_str_exit(u32 line_number,
+ const char *function_name,
+ const char *module_name, u32 component_id, const char *string);
+
+void
acpi_ut_debug_dump_buffer(u8 *buffer, u32 count, u32 display, u32 component_id);
void acpi_ut_dump_buffer(u8 *buffer, u32 count, u32 display, u32 offset);
@@ -707,25 +727,6 @@
const char *acpi_ah_match_uuid(u8 *data);
/*
- * utprint - printf/vprintf output functions
- */
-const char *acpi_ut_scan_number(const char *string, u64 *number_ptr);
-
-const char *acpi_ut_print_number(char *string, u64 number);
-
-int
-acpi_ut_vsnprintf(char *string,
- acpi_size size, const char *format, va_list args);
-
-int acpi_ut_snprintf(char *string, acpi_size size, const char *format, ...);
-
-#ifdef ACPI_APPLICATION
-int acpi_ut_file_vprintf(ACPI_FILE file, const char *format, va_list args);
-
-int acpi_ut_file_printf(ACPI_FILE file, const char *format, ...);
-#endif
-
-/*
* utuuid -- UUID support functions
*/
#if (defined ACPI_ASL_COMPILER || defined ACPI_EXEC_APP || defined ACPI_HELP_APP)
diff --git a/drivers/acpi/acpica/dbconvert.c b/drivers/acpi/acpica/dbconvert.c
index 7cd07b2..147ce88 100644
--- a/drivers/acpi/acpica/dbconvert.c
+++ b/drivers/acpi/acpica/dbconvert.c
@@ -277,9 +277,10 @@
default:
object->type = ACPI_TYPE_INTEGER;
- status =
- acpi_ut_strtoul64(string, 16, acpi_gbl_integer_byte_width,
- &object->integer.value);
+ status = acpi_ut_strtoul64(string,
+ (acpi_gbl_integer_byte_width |
+ ACPI_STRTOUL_BASE16),
+ &object->integer.value);
break;
}
diff --git a/drivers/acpi/acpica/dbexec.c b/drivers/acpi/acpica/dbexec.c
index 12df291..fe3da7c 100644
--- a/drivers/acpi/acpica/dbexec.c
+++ b/drivers/acpi/acpica/dbexec.c
@@ -392,43 +392,49 @@
acpi_db_execution_walk, NULL, NULL,
NULL);
return;
- } else {
- name_string = ACPI_ALLOCATE(strlen(name) + 1);
- if (!name_string) {
- return;
- }
-
- memset(&acpi_gbl_db_method_info, 0,
- sizeof(struct acpi_db_method_info));
-
- strcpy(name_string, name);
- acpi_ut_strupr(name_string);
- acpi_gbl_db_method_info.name = name_string;
- acpi_gbl_db_method_info.args = args;
- acpi_gbl_db_method_info.types = types;
- acpi_gbl_db_method_info.flags = flags;
-
- return_obj.pointer = NULL;
- return_obj.length = ACPI_ALLOCATE_BUFFER;
-
- status = acpi_db_execute_setup(&acpi_gbl_db_method_info);
- if (ACPI_FAILURE(status)) {
- ACPI_FREE(name_string);
- return;
- }
-
- /* Get the NS node, determines existence also */
-
- status = acpi_get_handle(NULL, acpi_gbl_db_method_info.pathname,
- &acpi_gbl_db_method_info.method);
- if (ACPI_SUCCESS(status)) {
- status =
- acpi_db_execute_method(&acpi_gbl_db_method_info,
- &return_obj);
- }
- ACPI_FREE(name_string);
}
+ name_string = ACPI_ALLOCATE(strlen(name) + 1);
+ if (!name_string) {
+ return;
+ }
+
+ memset(&acpi_gbl_db_method_info, 0, sizeof(struct acpi_db_method_info));
+ strcpy(name_string, name);
+ acpi_ut_strupr(name_string);
+
+ /* Subcommand to Execute all predefined names in the namespace */
+
+ if (!strncmp(name_string, "PREDEF", 6)) {
+ acpi_db_evaluate_predefined_names();
+ ACPI_FREE(name_string);
+ return;
+ }
+
+ acpi_gbl_db_method_info.name = name_string;
+ acpi_gbl_db_method_info.args = args;
+ acpi_gbl_db_method_info.types = types;
+ acpi_gbl_db_method_info.flags = flags;
+
+ return_obj.pointer = NULL;
+ return_obj.length = ACPI_ALLOCATE_BUFFER;
+
+ status = acpi_db_execute_setup(&acpi_gbl_db_method_info);
+ if (ACPI_FAILURE(status)) {
+ ACPI_FREE(name_string);
+ return;
+ }
+
+ /* Get the NS node, determines existence also */
+
+ status = acpi_get_handle(NULL, acpi_gbl_db_method_info.pathname,
+ &acpi_gbl_db_method_info.method);
+ if (ACPI_SUCCESS(status)) {
+ status = acpi_db_execute_method(&acpi_gbl_db_method_info,
+ &return_obj);
+ }
+ ACPI_FREE(name_string);
+
/*
* Allow any handlers in separate threads to complete.
* (Such as Notify handlers invoked from AML executed above).
diff --git a/drivers/acpi/acpica/dbfileio.c b/drivers/acpi/acpica/dbfileio.c
index 4832879..6f05b8c 100644
--- a/drivers/acpi/acpica/dbfileio.c
+++ b/drivers/acpi/acpica/dbfileio.c
@@ -46,14 +46,12 @@
#include "accommon.h"
#include "acdebug.h"
#include "actables.h"
-#include <stdio.h>
-#ifdef ACPI_APPLICATION
-#include "acapps.h"
-#endif
#define _COMPONENT ACPI_CA_DEBUGGER
ACPI_MODULE_NAME("dbfileio")
+#ifdef ACPI_APPLICATION
+#include "acapps.h"
#ifdef ACPI_DEBUGGER
/*******************************************************************************
*
@@ -69,8 +67,6 @@
void acpi_db_close_debug_file(void)
{
-#ifdef ACPI_APPLICATION
-
if (acpi_gbl_debug_file) {
fclose(acpi_gbl_debug_file);
acpi_gbl_debug_file = NULL;
@@ -78,7 +74,6 @@
acpi_os_printf("Debug output file %s closed\n",
acpi_gbl_db_debug_filename);
}
-#endif
}
/*******************************************************************************
@@ -96,8 +91,6 @@
void acpi_db_open_debug_file(char *name)
{
-#ifdef ACPI_APPLICATION
-
acpi_db_close_debug_file();
acpi_gbl_debug_file = fopen(name, "w+");
if (!acpi_gbl_debug_file) {
@@ -109,8 +102,6 @@
strncpy(acpi_gbl_db_debug_filename, name,
sizeof(acpi_gbl_db_debug_filename));
acpi_gbl_db_output_to_file = TRUE;
-
-#endif
}
#endif
@@ -152,12 +143,13 @@
return (status);
}
- fprintf(stderr,
- "Acpi table [%4.4s] successfully installed and loaded\n",
- table->signature);
+ acpi_os_printf
+ ("Acpi table [%4.4s] successfully installed and loaded\n",
+ table->signature);
table_list_head = table_list_head->next;
}
return (AE_OK);
}
+#endif
diff --git a/drivers/acpi/acpica/dbinput.c b/drivers/acpi/acpica/dbinput.c
index 7cd5d2e..068214f 100644
--- a/drivers/acpi/acpica/dbinput.c
+++ b/drivers/acpi/acpica/dbinput.c
@@ -286,6 +286,8 @@
{1, " \"Ascii String\"", "String method argument\n"},
{1, " (Hex Byte List)", "Buffer method argument\n"},
{1, " [Package Element List]", "Package method argument\n"},
+ {5, " Execute predefined",
+ "Execute all predefined (public) methods\n"},
{1, " Go", "Allow method to run to completion\n"},
{1, " Information", "Display info about the current method\n"},
{1, " Into", "Step into (not over) a method call\n"},
diff --git a/drivers/acpi/acpica/dbmethod.c b/drivers/acpi/acpica/dbmethod.c
index f17a86f..314b94c 100644
--- a/drivers/acpi/acpica/dbmethod.c
+++ b/drivers/acpi/acpica/dbmethod.c
@@ -52,6 +52,11 @@
#define _COMPONENT ACPI_CA_DEBUGGER
ACPI_MODULE_NAME("dbmethod")
+/* Local prototypes */
+static acpi_status
+acpi_db_walk_for_execute(acpi_handle obj_handle,
+ u32 nesting_level, void *context, void **return_value);
+
/*******************************************************************************
*
* FUNCTION: acpi_db_set_method_breakpoint
@@ -66,6 +71,7 @@
* AML offset
*
******************************************************************************/
+
void
acpi_db_set_method_breakpoint(char *location,
struct acpi_walk_state *walk_state,
@@ -367,3 +373,129 @@
acpi_ut_release_owner_id(&obj_desc->method.owner_id);
return (AE_OK);
}
+
+/*******************************************************************************
+ *
+ * FUNCTION: acpi_db_walk_for_execute
+ *
+ * PARAMETERS: Callback from walk_namespace
+ *
+ * RETURN: Status
+ *
+ * DESCRIPTION: Batch execution module. Currently only executes predefined
+ * ACPI names.
+ *
+ ******************************************************************************/
+
+static acpi_status
+acpi_db_walk_for_execute(acpi_handle obj_handle,
+ u32 nesting_level, void *context, void **return_value)
+{
+ struct acpi_namespace_node *node =
+ (struct acpi_namespace_node *)obj_handle;
+ struct acpi_db_execute_walk *info =
+ (struct acpi_db_execute_walk *)context;
+ struct acpi_buffer return_obj;
+ acpi_status status;
+ char *pathname;
+ u32 i;
+ struct acpi_device_info *obj_info;
+ struct acpi_object_list param_objects;
+ union acpi_object params[ACPI_METHOD_NUM_ARGS];
+ const union acpi_predefined_info *predefined;
+
+ predefined = acpi_ut_match_predefined_method(node->name.ascii);
+ if (!predefined) {
+ return (AE_OK);
+ }
+
+ if (node->type == ACPI_TYPE_LOCAL_SCOPE) {
+ return (AE_OK);
+ }
+
+ pathname = acpi_ns_get_external_pathname(node);
+ if (!pathname) {
+ return (AE_OK);
+ }
+
+ /* Get the object info for number of method parameters */
+
+ status = acpi_get_object_info(obj_handle, &obj_info);
+ if (ACPI_FAILURE(status)) {
+ return (status);
+ }
+
+ param_objects.pointer = NULL;
+ param_objects.count = 0;
+
+ if (obj_info->type == ACPI_TYPE_METHOD) {
+
+ /* Setup default parameters */
+
+ for (i = 0; i < obj_info->param_count; i++) {
+ params[i].type = ACPI_TYPE_INTEGER;
+ params[i].integer.value = 1;
+ }
+
+ param_objects.pointer = params;
+ param_objects.count = obj_info->param_count;
+ }
+
+ ACPI_FREE(obj_info);
+ return_obj.pointer = NULL;
+ return_obj.length = ACPI_ALLOCATE_BUFFER;
+
+ /* Do the actual method execution */
+
+ acpi_gbl_method_executing = TRUE;
+
+ status = acpi_evaluate_object(node, NULL, ¶m_objects, &return_obj);
+
+ acpi_os_printf("%-32s returned %s\n", pathname,
+ acpi_format_exception(status));
+ acpi_gbl_method_executing = FALSE;
+ ACPI_FREE(pathname);
+
+ /* Ignore status from method execution */
+
+ status = AE_OK;
+
+ /* Update count, check if we have executed enough methods */
+
+ info->count++;
+ if (info->count >= info->max_count) {
+ status = AE_CTRL_TERMINATE;
+ }
+
+ return (status);
+}
+
+/*******************************************************************************
+ *
+ * FUNCTION: acpi_db_evaluate_predefined_names
+ *
+ * PARAMETERS: None
+ *
+ * RETURN: None
+ *
+ * DESCRIPTION: Namespace batch execution. Execute predefined names in the
+ * namespace, up to the max count, if specified.
+ *
+ ******************************************************************************/
+
+void acpi_db_evaluate_predefined_names(void)
+{
+ struct acpi_db_execute_walk info;
+
+ info.count = 0;
+ info.max_count = ACPI_UINT32_MAX;
+
+ /* Search all nodes in namespace */
+
+ (void)acpi_walk_namespace(ACPI_TYPE_ANY, ACPI_ROOT_OBJECT,
+ ACPI_UINT32_MAX, acpi_db_walk_for_execute,
+ NULL, (void *)&info, NULL);
+
+ acpi_os_printf("Evaluated %u predefined names in the namespace\n",
+ info.count);
+}
diff --git a/drivers/acpi/acpica/dbobject.c b/drivers/acpi/acpica/dbobject.c
index 1d59e8b..08eaaf3 100644
--- a/drivers/acpi/acpica/dbobject.c
+++ b/drivers/acpi/acpica/dbobject.c
@@ -142,11 +142,11 @@
case ACPI_TYPE_STRING:
- acpi_os_printf("(%u) \"%.24s",
+ acpi_os_printf("(%u) \"%.60s",
obj_desc->string.length,
obj_desc->string.pointer);
- if (obj_desc->string.length > 24) {
+ if (obj_desc->string.length > 60) {
acpi_os_printf("...");
} else {
acpi_os_printf("\"");
diff --git a/drivers/acpi/acpica/dsmethod.c b/drivers/acpi/acpica/dsmethod.c
index 47c7b52..32e9ddc 100644
--- a/drivers/acpi/acpica/dsmethod.c
+++ b/drivers/acpi/acpica/dsmethod.c
@@ -99,11 +99,14 @@
"Method auto-serialization parse [%4.4s] %p\n",
acpi_ut_get_node_name(node), node));
+ acpi_ex_enter_interpreter();
+
/* Create/Init a root op for the method parse tree */
op = acpi_ps_alloc_op(AML_METHOD_OP, obj_desc->method.aml_start);
if (!op) {
- return_ACPI_STATUS(AE_NO_MEMORY);
+ status = AE_NO_MEMORY;
+ goto unlock;
}
acpi_ps_set_name(op, node->name.integer);
@@ -115,7 +118,8 @@
acpi_ds_create_walk_state(node->owner_id, NULL, NULL, NULL);
if (!walk_state) {
acpi_ps_free_op(op);
- return_ACPI_STATUS(AE_NO_MEMORY);
+ status = AE_NO_MEMORY;
+ goto unlock;
}
status = acpi_ds_init_aml_walk(walk_state, op, node,
@@ -134,6 +138,8 @@
status = acpi_ps_parse_aml(walk_state);
acpi_ps_delete_parse_tree(op);
+unlock:
+ acpi_ex_exit_interpreter();
return_ACPI_STATUS(status);
}
@@ -757,8 +763,10 @@
/* Delete any direct children of (created by) this method */
+ (void)acpi_ex_exit_interpreter();
acpi_ns_delete_namespace_subtree(walk_state->
method_node);
+ (void)acpi_ex_enter_interpreter();
/*
* Delete any objects that were created by this method
@@ -769,9 +777,11 @@
*/
if (method_desc->method.
info_flags & ACPI_METHOD_MODIFIED_NAMESPACE) {
+ (void)acpi_ex_exit_interpreter();
acpi_ns_delete_namespace_by_owner(method_desc->
method.
owner_id);
+ (void)acpi_ex_enter_interpreter();
method_desc->method.info_flags &=
~ACPI_METHOD_MODIFIED_NAMESPACE;
}
diff --git a/drivers/acpi/acpica/dsutils.c b/drivers/acpi/acpica/dsutils.c
index f393de9..7d8ef52 100644
--- a/drivers/acpi/acpica/dsutils.c
+++ b/drivers/acpi/acpica/dsutils.c
@@ -565,15 +565,14 @@
status = AE_OK;
} else if (parent_op->common.aml_opcode ==
AML_EXTERNAL_OP) {
-
- /* TBD: May only be temporary */
-
- obj_desc =
- acpi_ut_create_string_object((acpi_size)name_length);
-
- strncpy(obj_desc->string.pointer,
- name_string, name_length);
- status = AE_OK;
+ /*
+ * This opcode should never appear here. It is used only
+ * by AML disassemblers and is surrounded by an If(0)
+ * by the ASL compiler.
+ *
+ * Therefore, if we see it here, it is a serious error.
+ */
+ status = AE_AML_BAD_OPCODE;
} else {
/*
* We just plain didn't find it -- which is a
diff --git a/drivers/acpi/acpica/dswexec.c b/drivers/acpi/acpica/dswexec.c
index 402ecc5..438597c 100644
--- a/drivers/acpi/acpica/dswexec.c
+++ b/drivers/acpi/acpica/dswexec.c
@@ -133,7 +133,8 @@
* Result of predicate evaluation must be an Integer
* object. Implicitly convert the argument if necessary.
*/
- status = acpi_ex_convert_to_integer(obj_desc, &local_obj_desc, 16);
+ status = acpi_ex_convert_to_integer(obj_desc, &local_obj_desc,
+ ACPI_STRTOUL_BASE16);
if (ACPI_FAILURE(status)) {
goto cleanup;
}
diff --git a/drivers/acpi/acpica/dswload2.c b/drivers/acpi/acpica/dswload2.c
index 762db3f..028b22a 100644
--- a/drivers/acpi/acpica/dswload2.c
+++ b/drivers/acpi/acpica/dswload2.c
@@ -605,16 +605,13 @@
if (ACPI_FAILURE(status)) {
return_ACPI_STATUS(status);
}
-
- acpi_ex_exit_interpreter();
}
+ acpi_ex_exit_interpreter();
status =
acpi_ev_initialize_region
(acpi_ns_get_attached_object(node), FALSE);
- if (walk_state->method_node) {
- acpi_ex_enter_interpreter();
- }
+ acpi_ex_enter_interpreter();
if (ACPI_FAILURE(status)) {
/*
diff --git a/drivers/acpi/acpica/evgpe.c b/drivers/acpi/acpica/evgpe.c
index 4b4949c..bdb10be 100644
--- a/drivers/acpi/acpica/evgpe.c
+++ b/drivers/acpi/acpica/evgpe.c
@@ -130,6 +130,60 @@
/*******************************************************************************
*
+ * FUNCTION: acpi_ev_mask_gpe
+ *
+ * PARAMETERS: gpe_event_info - GPE to be blocked/unblocked
+ * is_masked - Whether the GPE is masked or not
+ *
+ * RETURN: Status
+ *
+ * DESCRIPTION: Unconditionally mask/unmask a GPE during runtime.
+ *
+ ******************************************************************************/
+
+acpi_status
+acpi_ev_mask_gpe(struct acpi_gpe_event_info *gpe_event_info, u8 is_masked)
+{
+ struct acpi_gpe_register_info *gpe_register_info;
+ u32 register_bit;
+
+ ACPI_FUNCTION_TRACE(ev_mask_gpe);
+
+ gpe_register_info = gpe_event_info->register_info;
+ if (!gpe_register_info) {
+ return_ACPI_STATUS(AE_NOT_EXIST);
+ }
+
+ register_bit = acpi_hw_get_gpe_register_bit(gpe_event_info);
+
+ /* Perform the action */
+
+ if (is_masked) {
+ if (register_bit & gpe_register_info->mask_for_run) {
+ return_ACPI_STATUS(AE_BAD_PARAMETER);
+ }
+
+ (void)acpi_hw_low_set_gpe(gpe_event_info, ACPI_GPE_DISABLE);
+ ACPI_SET_BIT(gpe_register_info->mask_for_run, (u8)register_bit);
+ } else {
+ if (!(register_bit & gpe_register_info->mask_for_run)) {
+ return_ACPI_STATUS(AE_BAD_PARAMETER);
+ }
+
+ ACPI_CLEAR_BIT(gpe_register_info->mask_for_run,
+ (u8)register_bit);
+ if (gpe_event_info->runtime_count
+ && !gpe_event_info->disable_for_dispatch) {
+ (void)acpi_hw_low_set_gpe(gpe_event_info,
+ ACPI_GPE_ENABLE);
+ }
+ }
+
+ return_ACPI_STATUS(AE_OK);
+}
+
+/*******************************************************************************
+ *
* FUNCTION: acpi_ev_add_gpe_reference
*
* PARAMETERS: gpe_event_info - Add a reference to this GPE
@@ -674,6 +728,7 @@
* in the event_info.
*/
(void)acpi_hw_low_set_gpe(gpe_event_info, ACPI_GPE_CONDITIONAL_ENABLE);
+ gpe_event_info->disable_for_dispatch = FALSE;
return (AE_OK);
}
@@ -737,6 +792,8 @@
}
}
+ gpe_event_info->disable_for_dispatch = TRUE;
+
/*
* Dispatch the GPE to either an installed handler or the control
* method associated with this GPE (_Lxx or _Exx). If a handler
diff --git a/drivers/acpi/acpica/evgpeinit.c b/drivers/acpi/acpica/evgpeinit.c
index 7dc7547..16ce483 100644
--- a/drivers/acpi/acpica/evgpeinit.c
+++ b/drivers/acpi/acpica/evgpeinit.c
@@ -323,7 +323,9 @@
struct acpi_gpe_walk_info *walk_info =
ACPI_CAST_PTR(struct acpi_gpe_walk_info, context);
struct acpi_gpe_event_info *gpe_event_info;
+ acpi_status status;
u32 gpe_number;
+ u8 temp_gpe_number;
char name[ACPI_NAME_SIZE + 1];
u8 type;
@@ -377,8 +379,8 @@
/* 4) The last two characters of the name are the hex GPE Number */
- gpe_number = strtoul(&name[2], NULL, 16);
- if (gpe_number == ACPI_UINT32_MAX) {
+ status = acpi_ut_ascii_to_hex_byte(&name[2], &temp_gpe_number);
+ if (ACPI_FAILURE(status)) {
/* Conversion failed; invalid method, just ignore it */
@@ -390,6 +392,7 @@
/* Ensure that we have a valid GPE number for this GPE block */
+ gpe_number = (u32)temp_gpe_number;
gpe_event_info =
acpi_ev_low_get_gpe_info(gpe_number, walk_info->gpe_block);
if (!gpe_event_info) {
diff --git a/drivers/acpi/acpica/evrgnini.c b/drivers/acpi/acpica/evrgnini.c
index b6ea9c0..3843f1f 100644
--- a/drivers/acpi/acpica/evrgnini.c
+++ b/drivers/acpi/acpica/evrgnini.c
@@ -553,7 +553,8 @@
*
* See acpi_ns_exec_module_code
*/
- if (obj_desc->method.
+ if (!acpi_gbl_parse_table_as_term_list &&
+ obj_desc->method.
info_flags & ACPI_METHOD_MODULE_LEVEL) {
handler_obj =
obj_desc->method.dispatch.handler;
diff --git a/drivers/acpi/acpica/evxfgpe.c b/drivers/acpi/acpica/evxfgpe.c
index 17cfef7..d7a3b27 100644
--- a/drivers/acpi/acpica/evxfgpe.c
+++ b/drivers/acpi/acpica/evxfgpe.c
@@ -235,11 +235,13 @@
case ACPI_GPE_ENABLE:
status = acpi_hw_low_set_gpe(gpe_event_info, ACPI_GPE_ENABLE);
+ gpe_event_info->disable_for_dispatch = FALSE;
break;
case ACPI_GPE_DISABLE:
status = acpi_hw_low_set_gpe(gpe_event_info, ACPI_GPE_DISABLE);
+ gpe_event_info->disable_for_dispatch = TRUE;
break;
default:
@@ -257,6 +259,47 @@
/*******************************************************************************
*
+ * FUNCTION: acpi_mask_gpe
+ *
+ * PARAMETERS: gpe_device - Parent GPE Device. NULL for GPE0/GPE1
+ * gpe_number - GPE level within the GPE block
+ * is_masked - Whether the GPE is masked or not
+ *
+ * RETURN: Status
+ *
+ * DESCRIPTION: Unconditionally mask/unmask the an individual GPE, ex., to
+ * prevent a GPE flooding.
+ *
+ ******************************************************************************/
+acpi_status acpi_mask_gpe(acpi_handle gpe_device, u32 gpe_number, u8 is_masked)
+{
+ struct acpi_gpe_event_info *gpe_event_info;
+ acpi_status status;
+ acpi_cpu_flags flags;
+
+ ACPI_FUNCTION_TRACE(acpi_mask_gpe);
+
+ flags = acpi_os_acquire_lock(acpi_gbl_gpe_lock);
+
+ /* Ensure that we have a valid GPE number */
+
+ gpe_event_info = acpi_ev_get_gpe_event_info(gpe_device, gpe_number);
+ if (!gpe_event_info) {
+ status = AE_BAD_PARAMETER;
+ goto unlock_and_exit;
+ }
+
+ status = acpi_ev_mask_gpe(gpe_event_info, is_masked);
+
+unlock_and_exit:
+ acpi_os_release_lock(acpi_gbl_gpe_lock, flags);
+ return_ACPI_STATUS(status);
+}
+
+ACPI_EXPORT_SYMBOL(acpi_mask_gpe)
+
+/*******************************************************************************
+ *
* FUNCTION: acpi_mark_gpe_for_wake
*
* PARAMETERS: gpe_device - Parent GPE Device. NULL for GPE0/GPE1
diff --git a/drivers/acpi/acpica/exconcat.c b/drivers/acpi/acpica/exconcat.c
index 2423fe0..5429c2a 100644
--- a/drivers/acpi/acpica/exconcat.c
+++ b/drivers/acpi/acpica/exconcat.c
@@ -156,7 +156,7 @@
status =
acpi_ex_convert_to_integer(local_operand1, &temp_operand1,
- 16);
+ ACPI_STRTOUL_BASE16);
break;
case ACPI_TYPE_BUFFER:
diff --git a/drivers/acpi/acpica/exconfig.c b/drivers/acpi/acpica/exconfig.c
index a1d177d..718428b 100644
--- a/drivers/acpi/acpica/exconfig.c
+++ b/drivers/acpi/acpica/exconfig.c
@@ -55,9 +55,7 @@
/* Local prototypes */
static acpi_status
-acpi_ex_add_table(u32 table_index,
- struct acpi_namespace_node *parent_node,
- union acpi_operand_object **ddb_handle);
+acpi_ex_add_table(u32 table_index, union acpi_operand_object **ddb_handle);
static acpi_status
acpi_ex_region_read(union acpi_operand_object *obj_desc,
@@ -79,13 +77,9 @@
******************************************************************************/
static acpi_status
-acpi_ex_add_table(u32 table_index,
- struct acpi_namespace_node *parent_node,
- union acpi_operand_object **ddb_handle)
+acpi_ex_add_table(u32 table_index, union acpi_operand_object **ddb_handle)
{
union acpi_operand_object *obj_desc;
- acpi_status status;
- acpi_owner_id owner_id;
ACPI_FUNCTION_TRACE(ex_add_table);
@@ -100,39 +94,8 @@
obj_desc->common.flags |= AOPOBJ_DATA_VALID;
obj_desc->reference.class = ACPI_REFCLASS_TABLE;
- *ddb_handle = obj_desc;
-
- /* Install the new table into the local data structures */
-
obj_desc->reference.value = table_index;
-
- /* Add the table to the namespace */
-
- status = acpi_ns_load_table(table_index, parent_node);
- if (ACPI_FAILURE(status)) {
- acpi_ut_remove_reference(obj_desc);
- *ddb_handle = NULL;
- return_ACPI_STATUS(status);
- }
-
- /* Execute any module-level code that was found in the table */
-
- acpi_ex_exit_interpreter();
- if (acpi_gbl_group_module_level_code) {
- acpi_ns_exec_module_code_list();
- }
- acpi_ex_enter_interpreter();
-
- /*
- * Update GPEs for any new _Lxx/_Exx methods. Ignore errors. The host is
- * responsible for discovering any new wake GPEs by running _PRW methods
- * that may have been loaded by this table.
- */
- status = acpi_tb_get_owner_id(table_index, &owner_id);
- if (ACPI_SUCCESS(status)) {
- acpi_ev_update_gpes(owner_id);
- }
-
+ *ddb_handle = obj_desc;
return_ACPI_STATUS(AE_OK);
}
@@ -159,16 +122,17 @@
struct acpi_namespace_node *start_node;
struct acpi_namespace_node *parameter_node = NULL;
union acpi_operand_object *ddb_handle;
- struct acpi_table_header *table;
u32 table_index;
ACPI_FUNCTION_TRACE(ex_load_table_op);
/* Find the ACPI table in the RSDT/XSDT */
+ acpi_ex_exit_interpreter();
status = acpi_tb_find_table(operand[0]->string.pointer,
operand[1]->string.pointer,
operand[2]->string.pointer, &table_index);
+ acpi_ex_enter_interpreter();
if (ACPI_FAILURE(status)) {
if (status != AE_NOT_FOUND) {
return_ACPI_STATUS(status);
@@ -197,9 +161,10 @@
* Find the node referenced by the root_path_string. This is the
* location within the namespace where the table will be loaded.
*/
- status =
- acpi_ns_get_node(start_node, operand[3]->string.pointer,
- ACPI_NS_SEARCH_PARENT, &parent_node);
+ status = acpi_ns_get_node_unlocked(start_node,
+ operand[3]->string.pointer,
+ ACPI_NS_SEARCH_PARENT,
+ &parent_node);
if (ACPI_FAILURE(status)) {
return_ACPI_STATUS(status);
}
@@ -219,9 +184,10 @@
/* Find the node referenced by the parameter_path_string */
- status =
- acpi_ns_get_node(start_node, operand[4]->string.pointer,
- ACPI_NS_SEARCH_PARENT, ¶meter_node);
+ status = acpi_ns_get_node_unlocked(start_node,
+ operand[4]->string.pointer,
+ ACPI_NS_SEARCH_PARENT,
+ ¶meter_node);
if (ACPI_FAILURE(status)) {
return_ACPI_STATUS(status);
}
@@ -229,7 +195,15 @@
/* Load the table into the namespace */
- status = acpi_ex_add_table(table_index, parent_node, &ddb_handle);
+ ACPI_INFO(("Dynamic OEM Table Load:"));
+ acpi_ex_exit_interpreter();
+ status = acpi_tb_load_table(table_index, parent_node);
+ acpi_ex_enter_interpreter();
+ if (ACPI_FAILURE(status)) {
+ return_ACPI_STATUS(status);
+ }
+
+ status = acpi_ex_add_table(table_index, &ddb_handle);
if (ACPI_FAILURE(status)) {
return_ACPI_STATUS(status);
}
@@ -252,19 +226,6 @@
}
}
- status = acpi_get_table_by_index(table_index, &table);
- if (ACPI_SUCCESS(status)) {
- ACPI_INFO(("Dynamic OEM Table Load:"));
- acpi_tb_print_table_header(0, table);
- }
-
- /* Invoke table handler if present */
-
- if (acpi_gbl_table_handler) {
- (void)acpi_gbl_table_handler(ACPI_TABLE_EVENT_LOAD, table,
- acpi_gbl_table_handler_context);
- }
-
*return_desc = ddb_handle;
return_ACPI_STATUS(status);
}
@@ -475,13 +436,12 @@
/* Install the new table into the local data structures */
ACPI_INFO(("Dynamic OEM Table Load:"));
- (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
-
- status = acpi_tb_install_standard_table(ACPI_PTR_TO_PHYSADDR(table),
- ACPI_TABLE_ORIGIN_INTERNAL_VIRTUAL,
- TRUE, TRUE, &table_index);
-
- (void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
+ acpi_ex_exit_interpreter();
+ status =
+ acpi_tb_install_and_load_table(table, ACPI_PTR_TO_PHYSADDR(table),
+ ACPI_TABLE_ORIGIN_INTERNAL_VIRTUAL,
+ TRUE, &table_index);
+ acpi_ex_enter_interpreter();
if (ACPI_FAILURE(status)) {
/* Delete allocated table buffer */
@@ -491,25 +451,13 @@
}
/*
- * Note: Now table is "INSTALLED", it must be validated before
- * loading.
- */
- status =
- acpi_tb_validate_table(&acpi_gbl_root_table_list.
- tables[table_index]);
- if (ACPI_FAILURE(status)) {
- return_ACPI_STATUS(status);
- }
-
- /*
* Add the table to the namespace.
*
* Note: Load the table objects relative to the root of the namespace.
* This appears to go against the ACPI specification, but we do it for
* compatibility with other ACPI implementations.
*/
- status =
- acpi_ex_add_table(table_index, acpi_gbl_root_node, &ddb_handle);
+ status = acpi_ex_add_table(table_index, &ddb_handle);
if (ACPI_FAILURE(status)) {
/* On error, table_ptr was deallocated above */
@@ -532,14 +480,6 @@
/* Remove the reference by added by acpi_ex_store above */
acpi_ut_remove_reference(ddb_handle);
-
- /* Invoke table handler if present */
-
- if (acpi_gbl_table_handler) {
- (void)acpi_gbl_table_handler(ACPI_TABLE_EVENT_LOAD, table,
- acpi_gbl_table_handler_context);
- }
-
return_ACPI_STATUS(status);
}
@@ -592,10 +532,17 @@
table_index = table_desc->reference.value;
+ /*
+ * Release the interpreter lock so that the table lock won't have
+ * strict order requirement against it.
+ */
+ acpi_ex_exit_interpreter();
+
/* Ensure the table is still loaded */
if (!acpi_tb_is_table_loaded(table_index)) {
- return_ACPI_STATUS(AE_NOT_EXIST);
+ status = AE_NOT_EXIST;
+ goto lock_and_exit;
}
/* Invoke table handler if present */
@@ -613,16 +560,24 @@
status = acpi_tb_delete_namespace_by_owner(table_index);
if (ACPI_FAILURE(status)) {
- return_ACPI_STATUS(status);
+ goto lock_and_exit;
}
(void)acpi_tb_release_owner_id(table_index);
acpi_tb_set_table_loaded_flag(table_index, FALSE);
+lock_and_exit:
+
+ /* Re-acquire the interpreter lock */
+
+ acpi_ex_enter_interpreter();
+
/*
* Invalidate the handle. We do this because the handle may be stored
* in a named object and may not be actually deleted until much later.
*/
- ddb_handle->common.flags &= ~AOPOBJ_DATA_VALID;
- return_ACPI_STATUS(AE_OK);
+ if (ACPI_SUCCESS(status)) {
+ ddb_handle->common.flags &= ~AOPOBJ_DATA_VALID;
+ }
+ return_ACPI_STATUS(status);
}
diff --git a/drivers/acpi/acpica/exconvrt.c b/drivers/acpi/acpica/exconvrt.c
index b7e9b3d..588ad14 100644
--- a/drivers/acpi/acpica/exconvrt.c
+++ b/drivers/acpi/acpica/exconvrt.c
@@ -124,9 +124,9 @@
* of ACPI 3.0) is that the to_integer() operator allows both decimal
* and hexadecimal strings (hex prefixed with "0x").
*/
- status = acpi_ut_strtoul64((char *)pointer, flags,
- acpi_gbl_integer_byte_width,
- &result);
+ status = acpi_ut_strtoul64(ACPI_CAST_PTR(char, pointer),
+ (acpi_gbl_integer_byte_width |
+ flags), &result);
if (ACPI_FAILURE(status)) {
return_ACPI_STATUS(status);
}
@@ -632,7 +632,7 @@
*/
status =
acpi_ex_convert_to_integer(source_desc, result_desc,
- 16);
+ ACPI_STRTOUL_BASE16);
break;
case ACPI_TYPE_STRING:
diff --git a/drivers/acpi/acpica/exmisc.c b/drivers/acpi/acpica/exmisc.c
index 4f7e667..37c88b4 100644
--- a/drivers/acpi/acpica/exmisc.c
+++ b/drivers/acpi/acpica/exmisc.c
@@ -327,8 +327,8 @@
switch (operand0->common.type) {
case ACPI_TYPE_INTEGER:
- status =
- acpi_ex_convert_to_integer(operand1, &local_operand1, 16);
+ status = acpi_ex_convert_to_integer(operand1, &local_operand1,
+ ACPI_STRTOUL_BASE16);
break;
case ACPI_TYPE_STRING:
diff --git a/drivers/acpi/acpica/exoparg1.c b/drivers/acpi/acpica/exoparg1.c
index 4e17506..0073004 100644
--- a/drivers/acpi/acpica/exoparg1.c
+++ b/drivers/acpi/acpica/exoparg1.c
@@ -521,9 +521,10 @@
case AML_TO_INTEGER_OP: /* to_integer (Data, Result) */
+ /* Perform "explicit" conversion */
+
status =
- acpi_ex_convert_to_integer(operand[0], &return_desc,
- ACPI_ANY_BASE);
+ acpi_ex_convert_to_integer(operand[0], &return_desc, 0);
if (return_desc == operand[0]) {
/* No conversion performed, add ref to handle return value */
@@ -890,14 +891,16 @@
* Field, so we need to resolve the node to a value.
*/
status =
- acpi_ns_get_node(walk_state->scope_info->
- scope.node,
- operand[0]->string.pointer,
- ACPI_NS_SEARCH_PARENT,
- ACPI_CAST_INDIRECT_PTR
- (struct
- acpi_namespace_node,
- &return_desc));
+ acpi_ns_get_node_unlocked(walk_state->
+ scope_info->scope.
+ node,
+ operand[0]->
+ string.pointer,
+ ACPI_NS_SEARCH_PARENT,
+ ACPI_CAST_INDIRECT_PTR
+ (struct
+ acpi_namespace_node,
+ &return_desc));
if (ACPI_FAILURE(status)) {
goto cleanup;
}
diff --git a/drivers/acpi/acpica/exresop.c b/drivers/acpi/acpica/exresop.c
index 27b41fd..f29eba1 100644
--- a/drivers/acpi/acpica/exresop.c
+++ b/drivers/acpi/acpica/exresop.c
@@ -410,12 +410,13 @@
case ARGI_INTEGER:
/*
- * Need an operand of type ACPI_TYPE_INTEGER,
- * But we can implicitly convert from a STRING or BUFFER
- * aka - "Implicit Source Operand Conversion"
+ * Need an operand of type ACPI_TYPE_INTEGER, but we can
+ * implicitly convert from a STRING or BUFFER.
+ *
+ * Known as "Implicit Source Operand Conversion"
*/
- status =
- acpi_ex_convert_to_integer(obj_desc, stack_ptr, 16);
+ status = acpi_ex_convert_to_integer(obj_desc, stack_ptr,
+ ACPI_STRTOUL_BASE16);
if (ACPI_FAILURE(status)) {
if (status == AE_TYPE) {
ACPI_ERROR((AE_INFO,
diff --git a/drivers/acpi/acpica/extrace.c b/drivers/acpi/acpica/extrace.c
index b52e848..c9ca826 100644
--- a/drivers/acpi/acpica/extrace.c
+++ b/drivers/acpi/acpica/extrace.c
@@ -201,7 +201,6 @@
union acpi_operand_object *obj_desc,
struct acpi_walk_state *walk_state)
{
- acpi_status status;
char *pathname = NULL;
u8 enabled = FALSE;
@@ -211,11 +210,6 @@
pathname = acpi_ns_get_normalized_pathname(method_node, TRUE);
}
- status = acpi_ut_acquire_mutex(ACPI_MTX_NAMESPACE);
- if (ACPI_FAILURE(status)) {
- goto exit;
- }
-
enabled = acpi_ex_interpreter_trace_enabled(pathname);
if (enabled && !acpi_gbl_trace_method_object) {
acpi_gbl_trace_method_object = obj_desc;
@@ -233,9 +227,6 @@
}
}
- (void)acpi_ut_release_mutex(ACPI_MTX_NAMESPACE);
-
-exit:
if (enabled) {
ACPI_TRACE_POINT(ACPI_TRACE_AML_METHOD, TRUE,
obj_desc ? obj_desc->method.aml_start : NULL,
@@ -267,7 +258,6 @@
union acpi_operand_object *obj_desc,
struct acpi_walk_state *walk_state)
{
- acpi_status status;
char *pathname = NULL;
u8 enabled;
@@ -277,26 +267,14 @@
pathname = acpi_ns_get_normalized_pathname(method_node, TRUE);
}
- status = acpi_ut_acquire_mutex(ACPI_MTX_NAMESPACE);
- if (ACPI_FAILURE(status)) {
- goto exit_path;
- }
-
enabled = acpi_ex_interpreter_trace_enabled(NULL);
- (void)acpi_ut_release_mutex(ACPI_MTX_NAMESPACE);
-
if (enabled) {
ACPI_TRACE_POINT(ACPI_TRACE_AML_METHOD, FALSE,
obj_desc ? obj_desc->method.aml_start : NULL,
pathname);
}
- status = acpi_ut_acquire_mutex(ACPI_MTX_NAMESPACE);
- if (ACPI_FAILURE(status)) {
- goto exit_path;
- }
-
/* Check whether the tracer should be stopped */
if (acpi_gbl_trace_method_object == obj_desc) {
@@ -312,9 +290,6 @@
acpi_gbl_trace_method_object = NULL;
}
- (void)acpi_ut_release_mutex(ACPI_MTX_NAMESPACE);
-
-exit_path:
if (pathname) {
ACPI_FREE(pathname);
}
diff --git a/drivers/acpi/acpica/exutils.c b/drivers/acpi/acpica/exutils.c
index 425f133..a8b857a 100644
--- a/drivers/acpi/acpica/exutils.c
+++ b/drivers/acpi/acpica/exutils.c
@@ -94,6 +94,10 @@
ACPI_ERROR((AE_INFO,
"Could not acquire AML Interpreter mutex"));
}
+ status = acpi_ut_acquire_mutex(ACPI_MTX_NAMESPACE);
+ if (ACPI_FAILURE(status)) {
+ ACPI_ERROR((AE_INFO, "Could not acquire AML Namespace mutex"));
+ }
return_VOID;
}
@@ -127,6 +131,10 @@
ACPI_FUNCTION_TRACE(ex_exit_interpreter);
+ status = acpi_ut_release_mutex(ACPI_MTX_NAMESPACE);
+ if (ACPI_FAILURE(status)) {
+ ACPI_ERROR((AE_INFO, "Could not release AML Namespace mutex"));
+ }
status = acpi_ut_release_mutex(ACPI_MTX_INTERPRETER);
if (ACPI_FAILURE(status)) {
ACPI_ERROR((AE_INFO,
diff --git a/drivers/acpi/acpica/hwgpe.c b/drivers/acpi/acpica/hwgpe.c
index bdecd5e..76b0e35 100644
--- a/drivers/acpi/acpica/hwgpe.c
+++ b/drivers/acpi/acpica/hwgpe.c
@@ -98,7 +98,7 @@
acpi_hw_low_set_gpe(struct acpi_gpe_event_info *gpe_event_info, u32 action)
{
struct acpi_gpe_register_info *gpe_register_info;
- acpi_status status;
+ acpi_status status = AE_OK;
u32 enable_mask;
u32 register_bit;
@@ -148,9 +148,14 @@
return (AE_BAD_PARAMETER);
}
- /* Write the updated enable mask */
+ if (!(register_bit & gpe_register_info->mask_for_run)) {
- status = acpi_hw_write(enable_mask, &gpe_register_info->enable_address);
+ /* Write the updated enable mask */
+
+ status =
+ acpi_hw_write(enable_mask,
+ &gpe_register_info->enable_address);
+ }
return (status);
}
@@ -242,6 +247,12 @@
local_event_status |= ACPI_EVENT_FLAG_ENABLED;
}
+ /* GPE currently masked? (masked for runtime?) */
+
+ if (register_bit & gpe_register_info->mask_for_run) {
+ local_event_status |= ACPI_EVENT_FLAG_MASKED;
+ }
+
/* GPE enabled for wake? */
if (register_bit & gpe_register_info->enable_for_wake) {
@@ -397,6 +408,7 @@
u32 i;
acpi_status status;
struct acpi_gpe_register_info *gpe_register_info;
+ u8 enable_mask;
/* NOTE: assumes that all GPEs are currently disabled */
@@ -410,9 +422,10 @@
/* Enable all "runtime" GPEs in this register */
+ enable_mask = gpe_register_info->enable_for_run &
+ ~gpe_register_info->mask_for_run;
status =
- acpi_hw_gpe_enable_write(gpe_register_info->enable_for_run,
- gpe_register_info);
+ acpi_hw_gpe_enable_write(enable_mask, gpe_register_info);
if (ACPI_FAILURE(status)) {
return (status);
}
diff --git a/drivers/acpi/acpica/nsaccess.c b/drivers/acpi/acpica/nsaccess.c
index 426a630..73f98d3 100644
--- a/drivers/acpi/acpica/nsaccess.c
+++ b/drivers/acpi/acpica/nsaccess.c
@@ -108,9 +108,9 @@
}
status =
- acpi_ns_lookup(NULL, (char *)init_val->name, init_val->type,
- ACPI_IMODE_LOAD_PASS2, ACPI_NS_NO_UPSEARCH,
- NULL, &new_node);
+ acpi_ns_lookup(NULL, ACPI_CAST_PTR(char, init_val->name),
+ init_val->type, ACPI_IMODE_LOAD_PASS2,
+ ACPI_NS_NO_UPSEARCH, NULL, &new_node);
if (ACPI_FAILURE(status)) {
ACPI_EXCEPTION((AE_INFO, status,
"Could not create predefined name %s",
diff --git a/drivers/acpi/acpica/nsconvert.c b/drivers/acpi/acpica/nsconvert.c
index c803bda..2b85dee 100644
--- a/drivers/acpi/acpica/nsconvert.c
+++ b/drivers/acpi/acpica/nsconvert.c
@@ -79,7 +79,6 @@
/* String-to-Integer conversion */
status = acpi_ut_strtoul64(original_object->string.pointer,
- ACPI_ANY_BASE,
acpi_gbl_integer_byte_width, &value);
if (ACPI_FAILURE(status)) {
return (status);
diff --git a/drivers/acpi/acpica/nsdump.c b/drivers/acpi/acpica/nsdump.c
index ce1f860..84f35dd 100644
--- a/drivers/acpi/acpica/nsdump.c
+++ b/drivers/acpi/acpica/nsdump.c
@@ -338,7 +338,7 @@
case ACPI_TYPE_STRING:
acpi_os_printf("Len %.2X ", obj_desc->string.length);
- acpi_ut_print_string(obj_desc->string.pointer, 32);
+ acpi_ut_print_string(obj_desc->string.pointer, 80);
acpi_os_printf("\n");
break;
diff --git a/drivers/acpi/acpica/nsload.c b/drivers/acpi/acpica/nsload.c
index b5e2b0a..334d3c5 100644
--- a/drivers/acpi/acpica/nsload.c
+++ b/drivers/acpi/acpica/nsload.c
@@ -46,6 +46,7 @@
#include "acnamesp.h"
#include "acdispat.h"
#include "actables.h"
+#include "acinterp.h"
#define _COMPONENT ACPI_NAMESPACE
ACPI_MODULE_NAME("nsload")
@@ -78,20 +79,6 @@
ACPI_FUNCTION_TRACE(ns_load_table);
- /*
- * Parse the table and load the namespace with all named
- * objects found within. Control methods are NOT parsed
- * at this time. In fact, the control methods cannot be
- * parsed until the entire namespace is loaded, because
- * if a control method makes a forward reference (call)
- * to another control method, we can't continue parsing
- * because we don't know how many arguments to parse next!
- */
- status = acpi_ut_acquire_mutex(ACPI_MTX_NAMESPACE);
- if (ACPI_FAILURE(status)) {
- return_ACPI_STATUS(status);
- }
-
/* If table already loaded into namespace, just return */
if (acpi_tb_is_table_loaded(table_index)) {
@@ -107,6 +94,15 @@
goto unlock;
}
+ /*
+ * Parse the table and load the namespace with all named
+ * objects found within. Control methods are NOT parsed
+ * at this time. In fact, the control methods cannot be
+ * parsed until the entire namespace is loaded, because
+ * if a control method makes a forward reference (call)
+ * to another control method, we can't continue parsing
+ * because we don't know how many arguments to parse next!
+ */
status = acpi_ns_parse_table(table_index, node);
if (ACPI_SUCCESS(status)) {
acpi_tb_set_table_loaded_flag(table_index, TRUE);
@@ -120,7 +116,6 @@
* exist. This target of Scope must already exist in the
* namespace, as per the ACPI specification.
*/
- (void)acpi_ut_release_mutex(ACPI_MTX_NAMESPACE);
acpi_ns_delete_namespace_by_owner(acpi_gbl_root_table_list.
tables[table_index].owner_id);
@@ -129,8 +124,6 @@
}
unlock:
- (void)acpi_ut_release_mutex(ACPI_MTX_NAMESPACE);
-
if (ACPI_FAILURE(status)) {
return_ACPI_STATUS(status);
}
@@ -162,7 +155,8 @@
* other ACPI implementations. Optionally, the execution can be deferred
* until later, see acpi_initialize_objects.
*/
- if (!acpi_gbl_group_module_level_code) {
+ if (!acpi_gbl_parse_table_as_term_list
+ && !acpi_gbl_group_module_level_code) {
acpi_ns_exec_module_code_list();
}
diff --git a/drivers/acpi/acpica/nsparse.c b/drivers/acpi/acpica/nsparse.c
index f631a47..4f14e92 100644
--- a/drivers/acpi/acpica/nsparse.c
+++ b/drivers/acpi/acpica/nsparse.c
@@ -47,12 +47,103 @@
#include "acparser.h"
#include "acdispat.h"
#include "actables.h"
+#include "acinterp.h"
#define _COMPONENT ACPI_NAMESPACE
ACPI_MODULE_NAME("nsparse")
/*******************************************************************************
*
+ * FUNCTION: ns_execute_table
+ *
+ * PARAMETERS: table_desc - An ACPI table descriptor for table to parse
+ * start_node - Where to enter the table into the namespace
+ *
+ * RETURN: Status
+ *
+ * DESCRIPTION: Load ACPI/AML table by executing the entire table as a
+ * term_list.
+ *
+ ******************************************************************************/
+acpi_status
+acpi_ns_execute_table(u32 table_index, struct acpi_namespace_node *start_node)
+{
+ acpi_status status;
+ struct acpi_table_header *table;
+ acpi_owner_id owner_id;
+ struct acpi_evaluate_info *info = NULL;
+ u32 aml_length;
+ u8 *aml_start;
+ union acpi_operand_object *method_obj = NULL;
+
+ ACPI_FUNCTION_TRACE(ns_execute_table);
+
+ status = acpi_get_table_by_index(table_index, &table);
+ if (ACPI_FAILURE(status)) {
+ return_ACPI_STATUS(status);
+ }
+
+ /* Table must consist of at least a complete header */
+
+ if (table->length < sizeof(struct acpi_table_header)) {
+ return_ACPI_STATUS(AE_BAD_HEADER);
+ }
+
+ aml_start = (u8 *)table + sizeof(struct acpi_table_header);
+ aml_length = table->length - sizeof(struct acpi_table_header);
+
+ status = acpi_tb_get_owner_id(table_index, &owner_id);
+ if (ACPI_FAILURE(status)) {
+ return_ACPI_STATUS(status);
+ }
+
+ /* Create, initialize, and link a new temporary method object */
+
+ method_obj = acpi_ut_create_internal_object(ACPI_TYPE_METHOD);
+ if (!method_obj) {
+ return_ACPI_STATUS(AE_NO_MEMORY);
+ }
+
+ /* Allocate the evaluation information block */
+
+ info = ACPI_ALLOCATE_ZEROED(sizeof(struct acpi_evaluate_info));
+ if (!info) {
+ status = AE_NO_MEMORY;
+ goto cleanup;
+ }
+
+ ACPI_DEBUG_PRINT((ACPI_DB_PARSE,
+ "Create table code block: %p\n", method_obj));
+
+ method_obj->method.aml_start = aml_start;
+ method_obj->method.aml_length = aml_length;
+ method_obj->method.owner_id = owner_id;
+ method_obj->method.info_flags |= ACPI_METHOD_MODULE_LEVEL;
+
+ info->pass_number = ACPI_IMODE_EXECUTE;
+ info->node = start_node;
+ info->obj_desc = method_obj;
+ info->node_flags = info->node->flags;
+ info->full_pathname = acpi_ns_get_normalized_pathname(info->node, TRUE);
+ if (!info->full_pathname) {
+ status = AE_NO_MEMORY;
+ goto cleanup;
+ }
+
+ status = acpi_ps_execute_table(info);
+
+cleanup:
+ if (info) {
+ ACPI_FREE(info->full_pathname);
+ info->full_pathname = NULL;
+ }
+ ACPI_FREE(info);
+ acpi_ut_remove_reference(method_obj);
+ return_ACPI_STATUS(status);
+}
+
+/*******************************************************************************
+ *
* FUNCTION: ns_one_complete_parse
*
* PARAMETERS: pass_number - 1 or 2
@@ -63,6 +154,7 @@
* DESCRIPTION: Perform one complete parse of an ACPI/AML table.
*
******************************************************************************/
+
acpi_status
acpi_ns_one_complete_parse(u32 pass_number,
u32 table_index,
@@ -143,7 +235,9 @@
ACPI_DEBUG_PRINT((ACPI_DB_PARSE,
"*PARSE* pass %u parse\n", pass_number));
+ acpi_ex_enter_interpreter();
status = acpi_ps_parse_aml(walk_state);
+ acpi_ex_exit_interpreter();
cleanup:
acpi_ps_delete_parse_tree(parse_root);
@@ -170,38 +264,47 @@
ACPI_FUNCTION_TRACE(ns_parse_table);
- /*
- * AML Parse, pass 1
- *
- * In this pass, we load most of the namespace. Control methods
- * are not parsed until later. A parse tree is not created. Instead,
- * each Parser Op subtree is deleted when it is finished. This saves
- * a great deal of memory, and allows a small cache of parse objects
- * to service the entire parse. The second pass of the parse then
- * performs another complete parse of the AML.
- */
- ACPI_DEBUG_PRINT((ACPI_DB_PARSE, "**** Start pass 1\n"));
+ if (acpi_gbl_parse_table_as_term_list) {
+ ACPI_DEBUG_PRINT((ACPI_DB_PARSE, "**** Start load pass\n"));
- status = acpi_ns_one_complete_parse(ACPI_IMODE_LOAD_PASS1,
- table_index, start_node);
- if (ACPI_FAILURE(status)) {
- return_ACPI_STATUS(status);
- }
+ status = acpi_ns_execute_table(table_index, start_node);
+ if (ACPI_FAILURE(status)) {
+ return_ACPI_STATUS(status);
+ }
+ } else {
+ /*
+ * AML Parse, pass 1
+ *
+ * In this pass, we load most of the namespace. Control methods
+ * are not parsed until later. A parse tree is not created.
+ * Instead, each Parser Op subtree is deleted when it is finished.
+ * This saves a great deal of memory, and allows a small cache of
+ * parse objects to service the entire parse. The second pass of
+ * the parse then performs another complete parse of the AML.
+ */
+ ACPI_DEBUG_PRINT((ACPI_DB_PARSE, "**** Start pass 1\n"));
- /*
- * AML Parse, pass 2
- *
- * In this pass, we resolve forward references and other things
- * that could not be completed during the first pass.
- * Another complete parse of the AML is performed, but the
- * overhead of this is compensated for by the fact that the
- * parse objects are all cached.
- */
- ACPI_DEBUG_PRINT((ACPI_DB_PARSE, "**** Start pass 2\n"));
- status = acpi_ns_one_complete_parse(ACPI_IMODE_LOAD_PASS2,
- table_index, start_node);
- if (ACPI_FAILURE(status)) {
- return_ACPI_STATUS(status);
+ status = acpi_ns_one_complete_parse(ACPI_IMODE_LOAD_PASS1,
+ table_index, start_node);
+ if (ACPI_FAILURE(status)) {
+ return_ACPI_STATUS(status);
+ }
+
+ /*
+ * AML Parse, pass 2
+ *
+ * In this pass, we resolve forward references and other things
+ * that could not be completed during the first pass.
+ * Another complete parse of the AML is performed, but the
+ * overhead of this is compensated for by the fact that the
+ * parse objects are all cached.
+ */
+ ACPI_DEBUG_PRINT((ACPI_DB_PARSE, "**** Start pass 2\n"));
+ status = acpi_ns_one_complete_parse(ACPI_IMODE_LOAD_PASS2,
+ table_index, start_node);
+ if (ACPI_FAILURE(status)) {
+ return_ACPI_STATUS(status);
+ }
}
return_ACPI_STATUS(status);
diff --git a/drivers/acpi/acpica/nsutils.c b/drivers/acpi/acpica/nsutils.c
index 784a30b..691814d 100644
--- a/drivers/acpi/acpica/nsutils.c
+++ b/drivers/acpi/acpica/nsutils.c
@@ -662,7 +662,7 @@
/*******************************************************************************
*
- * FUNCTION: acpi_ns_get_node
+ * FUNCTION: acpi_ns_get_node_unlocked
*
* PARAMETERS: *pathname - Name to be found, in external (ASL) format. The
* \ (backslash) and ^ (carat) prefixes, and the
@@ -678,20 +678,21 @@
* DESCRIPTION: Look up a name relative to a given scope and return the
* corresponding Node. NOTE: Scope can be null.
*
- * MUTEX: Locks namespace
+ * MUTEX: Doesn't locks namespace
*
******************************************************************************/
acpi_status
-acpi_ns_get_node(struct acpi_namespace_node *prefix_node,
- const char *pathname,
- u32 flags, struct acpi_namespace_node **return_node)
+acpi_ns_get_node_unlocked(struct acpi_namespace_node *prefix_node,
+ const char *pathname,
+ u32 flags, struct acpi_namespace_node **return_node)
{
union acpi_generic_state scope_info;
acpi_status status;
char *internal_path;
- ACPI_FUNCTION_TRACE_PTR(ns_get_node, ACPI_CAST_PTR(char, pathname));
+ ACPI_FUNCTION_TRACE_PTR(ns_get_node_unlocked,
+ ACPI_CAST_PTR(char, pathname));
/* Simplest case is a null pathname */
@@ -718,13 +719,6 @@
return_ACPI_STATUS(status);
}
- /* Must lock namespace during lookup */
-
- status = acpi_ut_acquire_mutex(ACPI_MTX_NAMESPACE);
- if (ACPI_FAILURE(status)) {
- goto cleanup;
- }
-
/* Setup lookup scope (search starting point) */
scope_info.scope.node = prefix_node;
@@ -740,9 +734,49 @@
pathname, acpi_format_exception(status)));
}
- (void)acpi_ut_release_mutex(ACPI_MTX_NAMESPACE);
-
-cleanup:
ACPI_FREE(internal_path);
return_ACPI_STATUS(status);
}
+
+/*******************************************************************************
+ *
+ * FUNCTION: acpi_ns_get_node
+ *
+ * PARAMETERS: *pathname - Name to be found, in external (ASL) format. The
+ * \ (backslash) and ^ (carat) prefixes, and the
+ * . (period) to separate segments are supported.
+ * prefix_node - Root of subtree to be searched, or NS_ALL for the
+ * root of the name space. If Name is fully
+ * qualified (first s8 is '\'), the passed value
+ * of Scope will not be accessed.
+ * flags - Used to indicate whether to perform upsearch or
+ * not.
+ * return_node - Where the Node is returned
+ *
+ * DESCRIPTION: Look up a name relative to a given scope and return the
+ * corresponding Node. NOTE: Scope can be null.
+ *
+ * MUTEX: Locks namespace
+ *
+ ******************************************************************************/
+
+acpi_status
+acpi_ns_get_node(struct acpi_namespace_node *prefix_node,
+ const char *pathname,
+ u32 flags, struct acpi_namespace_node **return_node)
+{
+ acpi_status status;
+
+ ACPI_FUNCTION_TRACE_PTR(ns_get_node, ACPI_CAST_PTR(char, pathname));
+
+ status = acpi_ut_acquire_mutex(ACPI_MTX_NAMESPACE);
+ if (ACPI_FAILURE(status)) {
+ return_ACPI_STATUS(status);
+ }
+
+ status = acpi_ns_get_node_unlocked(prefix_node, pathname,
+ flags, return_node);
+
+ (void)acpi_ut_release_mutex(ACPI_MTX_NAMESPACE);
+ return_ACPI_STATUS(status);
+}
diff --git a/drivers/acpi/acpica/psparse.c b/drivers/acpi/acpica/psparse.c
index 0a23897..1ce26d9 100644
--- a/drivers/acpi/acpica/psparse.c
+++ b/drivers/acpi/acpica/psparse.c
@@ -537,9 +537,11 @@
/* Either the method parse or actual execution failed */
+ acpi_ex_exit_interpreter();
ACPI_ERROR_METHOD("Method parse/execution failed",
walk_state->method_node, NULL,
status);
+ acpi_ex_enter_interpreter();
/* Check for possible multi-thread reentrancy problem */
@@ -571,7 +573,9 @@
* cleanup to do
*/
if (((walk_state->parse_flags & ACPI_PARSE_MODE_MASK) ==
- ACPI_PARSE_EXECUTE) || (ACPI_FAILURE(status))) {
+ ACPI_PARSE_EXECUTE &&
+ !(walk_state->parse_flags & ACPI_PARSE_MODULE_LEVEL)) ||
+ (ACPI_FAILURE(status))) {
acpi_ds_terminate_control_method(walk_state->
method_desc,
walk_state);
diff --git a/drivers/acpi/acpica/psxface.c b/drivers/acpi/acpica/psxface.c
index cf30cd82..f3c8726 100644
--- a/drivers/acpi/acpica/psxface.c
+++ b/drivers/acpi/acpica/psxface.c
@@ -252,6 +252,90 @@
/*******************************************************************************
*
+ * FUNCTION: acpi_ps_execute_table
+ *
+ * PARAMETERS: info - Method info block, contains:
+ * node - Node to where the is entered into the
+ * namespace
+ * obj_desc - Pseudo method object describing the AML
+ * code of the entire table
+ * pass_number - Parse or execute pass
+ *
+ * RETURN: Status
+ *
+ * DESCRIPTION: Execute a table
+ *
+ ******************************************************************************/
+
+acpi_status acpi_ps_execute_table(struct acpi_evaluate_info *info)
+{
+ acpi_status status;
+ union acpi_parse_object *op = NULL;
+ struct acpi_walk_state *walk_state = NULL;
+
+ ACPI_FUNCTION_TRACE(ps_execute_table);
+
+ /* Create and init a Root Node */
+
+ op = acpi_ps_create_scope_op(info->obj_desc->method.aml_start);
+ if (!op) {
+ status = AE_NO_MEMORY;
+ goto cleanup;
+ }
+
+ /* Create and initialize a new walk state */
+
+ walk_state =
+ acpi_ds_create_walk_state(info->obj_desc->method.owner_id, NULL,
+ NULL, NULL);
+ if (!walk_state) {
+ status = AE_NO_MEMORY;
+ goto cleanup;
+ }
+
+ status = acpi_ds_init_aml_walk(walk_state, op, info->node,
+ info->obj_desc->method.aml_start,
+ info->obj_desc->method.aml_length, info,
+ info->pass_number);
+ if (ACPI_FAILURE(status)) {
+ goto cleanup;
+ }
+
+ if (info->obj_desc->method.info_flags & ACPI_METHOD_MODULE_LEVEL) {
+ walk_state->parse_flags |= ACPI_PARSE_MODULE_LEVEL;
+ }
+
+ /* Info->Node is the default location to load the table */
+
+ if (info->node && info->node != acpi_gbl_root_node) {
+ status =
+ acpi_ds_scope_stack_push(info->node, ACPI_TYPE_METHOD,
+ walk_state);
+ if (ACPI_FAILURE(status)) {
+ goto cleanup;
+ }
+ }
+
+ /*
+ * Parse the AML, walk_state will be deleted by parse_aml
+ */
+ acpi_ex_enter_interpreter();
+ status = acpi_ps_parse_aml(walk_state);
+ acpi_ex_exit_interpreter();
+ walk_state = NULL;
+
+cleanup:
+ if (walk_state) {
+ acpi_ds_delete_walk_state(walk_state);
+ }
+ if (op) {
+ acpi_ps_delete_parse_tree(op);
+ }
+ return_ACPI_STATUS(status);
+}
+
+/*******************************************************************************
+ *
* FUNCTION: acpi_ps_update_parameter_list
*
* PARAMETERS: info - See struct acpi_evaluate_info
diff --git a/drivers/acpi/acpica/tbdata.c b/drivers/acpi/acpica/tbdata.c
index 1388a19..d9ca8c2 100644
--- a/drivers/acpi/acpica/tbdata.c
+++ b/drivers/acpi/acpica/tbdata.c
@@ -45,6 +45,7 @@
#include "accommon.h"
#include "acnamesp.h"
#include "actables.h"
+#include "acevents.h"
#define _COMPONENT ACPI_TABLES
ACPI_MODULE_NAME("tbdata")
@@ -613,17 +614,12 @@
* lock may block, and also since the execution of a namespace walk
* must be allowed to use the interpreter.
*/
- (void)acpi_ut_release_mutex(ACPI_MTX_INTERPRETER);
status = acpi_ut_acquire_write_lock(&acpi_gbl_namespace_rw_lock);
-
- acpi_ns_delete_namespace_by_owner(owner_id);
if (ACPI_FAILURE(status)) {
return_ACPI_STATUS(status);
}
-
+ acpi_ns_delete_namespace_by_owner(owner_id);
acpi_ut_release_write_lock(&acpi_gbl_namespace_rw_lock);
-
- status = acpi_ut_acquire_mutex(ACPI_MTX_INTERPRETER);
return_ACPI_STATUS(status);
}
@@ -771,3 +767,142 @@
(void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
}
+
+/*******************************************************************************
+ *
+ * FUNCTION: acpi_tb_load_table
+ *
+ * PARAMETERS: table_index - Table index
+ * parent_node - Where table index is returned
+ *
+ * RETURN: Status
+ *
+ * DESCRIPTION: Load an ACPI table
+ *
+ ******************************************************************************/
+
+acpi_status
+acpi_tb_load_table(u32 table_index, struct acpi_namespace_node *parent_node)
+{
+ struct acpi_table_header *table;
+ acpi_status status;
+ acpi_owner_id owner_id;
+
+ ACPI_FUNCTION_TRACE(tb_load_table);
+
+ /*
+ * Note: Now table is "INSTALLED", it must be validated before
+ * using.
+ */
+ status = acpi_get_table_by_index(table_index, &table);
+ if (ACPI_FAILURE(status)) {
+ return_ACPI_STATUS(status);
+ }
+
+ status = acpi_ns_load_table(table_index, parent_node);
+
+ /* Execute any module-level code that was found in the table */
+
+ if (!acpi_gbl_parse_table_as_term_list
+ && acpi_gbl_group_module_level_code) {
+ acpi_ns_exec_module_code_list();
+ }
+
+ /*
+ * Update GPEs for any new _Lxx/_Exx methods. Ignore errors. The host is
+ * responsible for discovering any new wake GPEs by running _PRW methods
+ * that may have been loaded by this table.
+ */
+ status = acpi_tb_get_owner_id(table_index, &owner_id);
+ if (ACPI_SUCCESS(status)) {
+ acpi_ev_update_gpes(owner_id);
+ }
+
+ /* Invoke table handler if present */
+
+ if (acpi_gbl_table_handler) {
+ (void)acpi_gbl_table_handler(ACPI_TABLE_EVENT_LOAD, table,
+ acpi_gbl_table_handler_context);
+ }
+
+ return_ACPI_STATUS(status);
+}
+
+/*******************************************************************************
+ *
+ * FUNCTION: acpi_tb_install_and_load_table
+ *
+ * PARAMETERS: table - Pointer to the table
+ * address - Physical address of the table
+ * flags - Allocation flags of the table
+ * table_index - Where table index is returned
+ *
+ * RETURN: Status
+ *
+ * DESCRIPTION: Install and load an ACPI table
+ *
+ ******************************************************************************/
+
+acpi_status
+acpi_tb_install_and_load_table(struct acpi_table_header *table,
+ acpi_physical_address address,
+ u8 flags, u8 override, u32 *table_index)
+{
+ acpi_status status;
+ u32 i;
+ acpi_owner_id owner_id;
+
+ ACPI_FUNCTION_TRACE(acpi_load_table);
+
+ (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
+
+ /* Install the table and load it into the namespace */
+
+ status = acpi_tb_install_standard_table(address, flags, TRUE,
+ override, &i);
+ if (ACPI_FAILURE(status)) {
+ goto unlock_and_exit;
+ }
+
+ /*
+ * Note: Now table is "INSTALLED", it must be validated before
+ * using.
+ */
+ status = acpi_tb_validate_table(&acpi_gbl_root_table_list.tables[i]);
+ if (ACPI_FAILURE(status)) {
+ goto unlock_and_exit;
+ }
+
+ (void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
+ status = acpi_ns_load_table(i, acpi_gbl_root_node);
+
+ /* Execute any module-level code that was found in the table */
+
+ if (!acpi_gbl_parse_table_as_term_list
+ && acpi_gbl_group_module_level_code) {
+ acpi_ns_exec_module_code_list();
+ }
+
+ /*
+ * Update GPEs for any new _Lxx/_Exx methods. Ignore errors. The host is
+ * responsible for discovering any new wake GPEs by running _PRW methods
+ * that may have been loaded by this table.
+ */
+ status = acpi_tb_get_owner_id(i, &owner_id);
+ if (ACPI_SUCCESS(status)) {
+ acpi_ev_update_gpes(owner_id);
+ }
+
+ /* Invoke table handler if present */
+
+ if (acpi_gbl_table_handler) {
+ (void)acpi_gbl_table_handler(ACPI_TABLE_EVENT_LOAD, table,
+ acpi_gbl_table_handler_context);
+ }
+ (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
+
+unlock_and_exit:
+ *table_index = i;
+ (void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
+ return_ACPI_STATUS(status);
+}
diff --git a/drivers/acpi/acpica/tbfadt.c b/drivers/acpi/acpica/tbfadt.c
index 6208069..046c4d0 100644
--- a/drivers/acpi/acpica/tbfadt.c
+++ b/drivers/acpi/acpica/tbfadt.c
@@ -344,23 +344,27 @@
/* Obtain the DSDT and FACS tables via their addresses within the FADT */
- acpi_tb_install_fixed_table((acpi_physical_address)acpi_gbl_FADT.Xdsdt,
- ACPI_SIG_DSDT, &acpi_gbl_dsdt_index);
+ acpi_tb_install_standard_table((acpi_physical_address)acpi_gbl_FADT.
+ Xdsdt,
+ ACPI_TABLE_ORIGIN_INTERNAL_PHYSICAL,
+ FALSE, TRUE, &acpi_gbl_dsdt_index);
/* If Hardware Reduced flag is set, there is no FACS */
if (!acpi_gbl_reduced_hardware) {
if (acpi_gbl_FADT.facs) {
- acpi_tb_install_fixed_table((acpi_physical_address)
- acpi_gbl_FADT.facs,
- ACPI_SIG_FACS,
- &acpi_gbl_facs_index);
+ acpi_tb_install_standard_table((acpi_physical_address)
+ acpi_gbl_FADT.facs,
+ ACPI_TABLE_ORIGIN_INTERNAL_PHYSICAL,
+ FALSE, TRUE,
+ &acpi_gbl_facs_index);
}
if (acpi_gbl_FADT.Xfacs) {
- acpi_tb_install_fixed_table((acpi_physical_address)
- acpi_gbl_FADT.Xfacs,
- ACPI_SIG_FACS,
- &acpi_gbl_xfacs_index);
+ acpi_tb_install_standard_table((acpi_physical_address)
+ acpi_gbl_FADT.Xfacs,
+ ACPI_TABLE_ORIGIN_INTERNAL_PHYSICAL,
+ FALSE, TRUE,
+ &acpi_gbl_xfacs_index);
}
}
}
@@ -476,17 +480,19 @@
u32 i;
/*
- * For ACPI 1.0 FADTs (revision 1 or 2), ensure that reserved fields which
+ * For ACPI 1.0 FADTs (revision 1), ensure that reserved fields which
* should be zero are indeed zero. This will workaround BIOSs that
* inadvertently place values in these fields.
*
* The ACPI 1.0 reserved fields that will be zeroed are the bytes located
* at offset 45, 55, 95, and the word located at offset 109, 110.
*
- * Note: The FADT revision value is unreliable. Only the length can be
- * trusted.
+ * Note: The FADT revision value is unreliable because of BIOS errors.
+ * The table length is instead used as the final word on the version.
+ *
+ * Note: FADT revision 3 is the ACPI 2.0 version of the FADT.
*/
- if (acpi_gbl_FADT.header.length <= ACPI_FADT_V2_SIZE) {
+ if (acpi_gbl_FADT.header.length <= ACPI_FADT_V3_SIZE) {
acpi_gbl_FADT.preferred_profile = 0;
acpi_gbl_FADT.pstate_control = 0;
acpi_gbl_FADT.cst_control = 0;
@@ -552,76 +558,72 @@
*
* Address32 zero, Address64 [don't care] - Use Address64
*
+ * No override: if acpi_gbl_use32_bit_fadt_addresses is FALSE, and:
* Address32 non-zero, Address64 zero - Copy/use Address32
* Address32 non-zero == Address64 non-zero - Use Address64
* Address32 non-zero != Address64 non-zero - Warning, use Address64
*
* Override: if acpi_gbl_use32_bit_fadt_addresses is TRUE, and:
+ * Address32 non-zero, Address64 zero - Copy/use Address32
+ * Address32 non-zero == Address64 non-zero - Copy/use Address32
* Address32 non-zero != Address64 non-zero - Warning, copy/use Address32
*
* Note: space_id is always I/O for 32-bit legacy address fields
*/
if (address32) {
- if (!address64->address) {
+ if (address64->address) {
+ if (address64->address != (u64)address32) {
- /* 64-bit address is zero, use 32-bit address */
+ /* Address mismatch */
- acpi_tb_init_generic_address(address64,
- ACPI_ADR_SPACE_SYSTEM_IO,
- *ACPI_ADD_PTR(u8,
- &acpi_gbl_FADT,
- fadt_info_table
- [i].
- length),
- (u64)address32,
- name, flags);
- } else if (address64->address != (u64)address32) {
+ ACPI_BIOS_WARNING((AE_INFO,
+ "32/64X address mismatch in FADT/%s: "
+ "0x%8.8X/0x%8.8X%8.8X, using %u-bit address",
+ name, address32,
+ ACPI_FORMAT_UINT64
+ (address64->address),
+ acpi_gbl_use32_bit_fadt_addresses
+ ? 32 : 64));
+ }
- /* Address mismatch */
-
- ACPI_BIOS_WARNING((AE_INFO,
- "32/64X address mismatch in FADT/%s: "
- "0x%8.8X/0x%8.8X%8.8X, using %u-bit address",
- name, address32,
- ACPI_FORMAT_UINT64
- (address64->address),
- acpi_gbl_use32_bit_fadt_addresses
- ? 32 : 64));
-
- if (acpi_gbl_use32_bit_fadt_addresses) {
-
- /* 32-bit address override */
-
- acpi_tb_init_generic_address(address64,
- ACPI_ADR_SPACE_SYSTEM_IO,
- *ACPI_ADD_PTR
- (u8,
- &acpi_gbl_FADT,
- fadt_info_table
- [i].
- length),
- (u64)
- address32,
- name,
- flags);
+ /*
+ * For each extended field, check for length mismatch
+ * between the legacy length field and the corresponding
+ * 64-bit X length field.
+ * Note: If the legacy length field is > 0xFF bits, ignore
+ * this check. (GPE registers can be larger than the
+ * 64-bit GAS structure can accomodate, 0xFF bits).
+ */
+ if ((ACPI_MUL_8(length) <= ACPI_UINT8_MAX) &&
+ (address64->bit_width !=
+ ACPI_MUL_8(length))) {
+ ACPI_BIOS_WARNING((AE_INFO,
+ "32/64X length mismatch in FADT/%s: %u/%u",
+ name,
+ ACPI_MUL_8(length),
+ address64->
+ bit_width));
}
}
- }
- /*
- * For each extended field, check for length mismatch between the
- * legacy length field and the corresponding 64-bit X length field.
- * Note: If the legacy length field is > 0xFF bits, ignore this
- * check. (GPE registers can be larger than the 64-bit GAS structure
- * can accomodate, 0xFF bits).
- */
- if (address64->address &&
- (ACPI_MUL_8(length) <= ACPI_UINT8_MAX) &&
- (address64->bit_width != ACPI_MUL_8(length))) {
- ACPI_BIOS_WARNING((AE_INFO,
- "32/64X length mismatch in FADT/%s: %u/%u",
- name, ACPI_MUL_8(length),
- address64->bit_width));
+ /*
+ * Hardware register access code always uses the 64-bit fields.
+ * So if the 64-bit field is zero or is to be overridden,
+ * initialize it with the 32-bit fields.
+ * Note that when the 32-bit address favor is specified, the
+ * 64-bit fields are always re-initialized so that
+ * access_size/bit_width/bit_offset fields can be correctly
+ * configured to the values to trigger a 32-bit compatible
+ * access mode in the hardware register access code.
+ */
+ if (!address64->address
+ || acpi_gbl_use32_bit_fadt_addresses) {
+ acpi_tb_init_generic_address(address64,
+ ACPI_ADR_SPACE_SYSTEM_IO,
+ length,
+ (u64)address32,
+ name, flags);
+ }
}
if (fadt_info_table[i].flags & ACPI_FADT_REQUIRED) {
diff --git a/drivers/acpi/acpica/tbfind.c b/drivers/acpi/acpica/tbfind.c
index e348d61..f6b9b4e 100644
--- a/drivers/acpi/acpica/tbfind.c
+++ b/drivers/acpi/acpica/tbfind.c
@@ -68,7 +68,7 @@
acpi_tb_find_table(char *signature,
char *oem_id, char *oem_table_id, u32 *table_index)
{
- acpi_status status;
+ acpi_status status = AE_OK;
struct acpi_table_header header;
u32 i;
@@ -96,6 +96,7 @@
/* Search for the table */
+ (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
for (i = 0; i < acpi_gbl_root_table_list.current_table_count; ++i) {
if (memcmp(&(acpi_gbl_root_table_list.tables[i].signature),
header.signature, ACPI_NAME_SIZE)) {
@@ -115,7 +116,7 @@
acpi_tb_validate_table(&acpi_gbl_root_table_list.
tables[i]);
if (ACPI_FAILURE(status)) {
- return_ACPI_STATUS(status);
+ goto unlock_and_exit;
}
if (!acpi_gbl_root_table_list.tables[i].pointer) {
@@ -144,9 +145,12 @@
ACPI_DEBUG_PRINT((ACPI_DB_TABLES,
"Found table [%4.4s]\n",
header.signature));
- return_ACPI_STATUS(AE_OK);
+ goto unlock_and_exit;
}
}
+ status = AE_NOT_FOUND;
- return_ACPI_STATUS(AE_NOT_FOUND);
+unlock_and_exit:
+ (void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
+ return_ACPI_STATUS(status);
}
diff --git a/drivers/acpi/acpica/tbinstal.c b/drivers/acpi/acpica/tbinstal.c
index 8b13052..5fdf251 100644
--- a/drivers/acpi/acpica/tbinstal.c
+++ b/drivers/acpi/acpica/tbinstal.c
@@ -157,68 +157,6 @@
/*******************************************************************************
*
- * FUNCTION: acpi_tb_install_fixed_table
- *
- * PARAMETERS: address - Physical address of DSDT or FACS
- * signature - Table signature, NULL if no need to
- * match
- * table_index - Where the table index is returned
- *
- * RETURN: Status
- *
- * DESCRIPTION: Install a fixed ACPI table (DSDT/FACS) into the global data
- * structure.
- *
- ******************************************************************************/
-
-acpi_status
-acpi_tb_install_fixed_table(acpi_physical_address address,
- char *signature, u32 *table_index)
-{
- struct acpi_table_desc new_table_desc;
- acpi_status status;
-
- ACPI_FUNCTION_TRACE(tb_install_fixed_table);
-
- if (!address) {
- ACPI_ERROR((AE_INFO,
- "Null physical address for ACPI table [%s]",
- signature));
- return (AE_NO_MEMORY);
- }
-
- /* Fill a table descriptor for validation */
-
- status = acpi_tb_acquire_temp_table(&new_table_desc, address,
- ACPI_TABLE_ORIGIN_INTERNAL_PHYSICAL);
- if (ACPI_FAILURE(status)) {
- ACPI_ERROR((AE_INFO,
- "Could not acquire table length at %8.8X%8.8X",
- ACPI_FORMAT_UINT64(address)));
- return_ACPI_STATUS(status);
- }
-
- /* Validate and verify a table before installation */
-
- status = acpi_tb_verify_temp_table(&new_table_desc, signature);
- if (ACPI_FAILURE(status)) {
- goto release_and_exit;
- }
-
- /* Add the table to the global root table list */
-
- acpi_tb_install_table_with_override(&new_table_desc, TRUE, table_index);
-
-release_and_exit:
-
- /* Release the temporary table descriptor */
-
- acpi_tb_release_temp_table(&new_table_desc);
- return_ACPI_STATUS(status);
-}
-
-/*******************************************************************************
- *
* FUNCTION: acpi_tb_install_standard_table
*
* PARAMETERS: address - Address of the table (might be a virtual
@@ -230,8 +168,7 @@
*
* RETURN: Status
*
- * DESCRIPTION: This function is called to install an ACPI table that is
- * neither DSDT nor FACS (a "standard" table.)
+ * DESCRIPTION: This function is called to verify and install an ACPI table.
* When this function is called by "Load" or "LoadTable" opcodes,
* or by acpi_load_table() API, the "Reload" parameter is set.
* After sucessfully returning from this function, table is
@@ -364,6 +301,14 @@
acpi_tb_install_table_with_override(&new_table_desc, override,
table_index);
+ /* Invoke table handler if present */
+
+ if (acpi_gbl_table_handler) {
+ (void)acpi_gbl_table_handler(ACPI_TABLE_EVENT_INSTALL,
+ new_table_desc.pointer,
+ acpi_gbl_table_handler_context);
+ }
+
release_and_exit:
/* Release the temporary table descriptor */
diff --git a/drivers/acpi/acpica/tbutils.c b/drivers/acpi/acpica/tbutils.c
index e285539..51eb07c 100644
--- a/drivers/acpi/acpica/tbutils.c
+++ b/drivers/acpi/acpica/tbutils.c
@@ -252,7 +252,8 @@
*
******************************************************************************/
-acpi_status __init acpi_tb_parse_root_table(acpi_physical_address rsdp_address)
+acpi_status ACPI_INIT_FUNCTION
+acpi_tb_parse_root_table(acpi_physical_address rsdp_address)
{
struct acpi_table_rsdp *rsdp;
u32 table_entry_size;
diff --git a/drivers/acpi/acpica/tbxface.c b/drivers/acpi/acpica/tbxface.c
index 3ecec93..4ab6b9c 100644
--- a/drivers/acpi/acpica/tbxface.c
+++ b/drivers/acpi/acpica/tbxface.c
@@ -98,7 +98,7 @@
*
******************************************************************************/
-acpi_status __init
+acpi_status ACPI_INIT_FUNCTION
acpi_initialize_tables(struct acpi_table_desc *initial_table_array,
u32 initial_table_count, u8 allow_resize)
{
@@ -164,7 +164,7 @@
* kernel.
*
******************************************************************************/
-acpi_status __init acpi_reallocate_root_table(void)
+acpi_status ACPI_INIT_FUNCTION acpi_reallocate_root_table(void)
{
acpi_status status;
diff --git a/drivers/acpi/acpica/tbxfload.c b/drivers/acpi/acpica/tbxfload.c
index ac71abc..5569f63 100644
--- a/drivers/acpi/acpica/tbxfload.c
+++ b/drivers/acpi/acpica/tbxfload.c
@@ -63,7 +63,7 @@
* DESCRIPTION: Load the ACPI tables from the RSDT/XSDT
*
******************************************************************************/
-acpi_status __init acpi_load_tables(void)
+acpi_status ACPI_INIT_FUNCTION acpi_load_tables(void)
{
acpi_status status;
@@ -103,7 +103,8 @@
"While loading namespace from ACPI tables"));
}
- if (!acpi_gbl_group_module_level_code) {
+ if (acpi_gbl_parse_table_as_term_list
+ || !acpi_gbl_group_module_level_code) {
/*
* Initialize the objects that remain uninitialized. This
* runs the executable AML that may be part of the
@@ -188,11 +189,11 @@
memcpy(&acpi_gbl_original_dsdt_header, acpi_gbl_DSDT,
sizeof(struct acpi_table_header));
- (void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
-
/* Load and parse tables */
+ (void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
status = acpi_ns_load_table(acpi_gbl_dsdt_index, acpi_gbl_root_node);
+ (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
if (ACPI_FAILURE(status)) {
ACPI_EXCEPTION((AE_INFO, status, "[DSDT] table load failed"));
tables_failed++;
@@ -202,7 +203,6 @@
/* Load any SSDT or PSDT tables. Note: Loop leaves tables locked */
- (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
for (i = 0; i < acpi_gbl_root_table_list.current_table_count; ++i) {
table = &acpi_gbl_root_table_list.tables[i];
@@ -220,6 +220,7 @@
(void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
status = acpi_ns_load_table(i, acpi_gbl_root_node);
+ (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
if (ACPI_FAILURE(status)) {
ACPI_EXCEPTION((AE_INFO, status,
"(%4.4s:%8.8s) while loading table",
@@ -235,8 +236,6 @@
} else {
tables_loaded++;
}
-
- (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
}
if (!tables_failed) {
@@ -272,7 +271,7 @@
*
******************************************************************************/
-acpi_status __init
+acpi_status ACPI_INIT_FUNCTION
acpi_install_table(acpi_physical_address address, u8 physical)
{
acpi_status status;
@@ -324,49 +323,13 @@
return_ACPI_STATUS(AE_BAD_PARAMETER);
}
- /* Must acquire the interpreter lock during this operation */
-
- status = acpi_ut_acquire_mutex(ACPI_MTX_INTERPRETER);
- if (ACPI_FAILURE(status)) {
- return_ACPI_STATUS(status);
- }
-
/* Install the table and load it into the namespace */
ACPI_INFO(("Host-directed Dynamic ACPI Table Load:"));
- (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
-
- status = acpi_tb_install_standard_table(ACPI_PTR_TO_PHYSADDR(table),
- ACPI_TABLE_ORIGIN_EXTERNAL_VIRTUAL,
- TRUE, FALSE, &table_index);
-
- (void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
- if (ACPI_FAILURE(status)) {
- goto unlock_and_exit;
- }
-
- /*
- * Note: Now table is "INSTALLED", it must be validated before
- * using.
- */
status =
- acpi_tb_validate_table(&acpi_gbl_root_table_list.
- tables[table_index]);
- if (ACPI_FAILURE(status)) {
- goto unlock_and_exit;
- }
-
- status = acpi_ns_load_table(table_index, acpi_gbl_root_node);
-
- /* Invoke table handler if present */
-
- if (acpi_gbl_table_handler) {
- (void)acpi_gbl_table_handler(ACPI_TABLE_EVENT_LOAD, table,
- acpi_gbl_table_handler_context);
- }
-
-unlock_and_exit:
- (void)acpi_ut_release_mutex(ACPI_MTX_INTERPRETER);
+ acpi_tb_install_and_load_table(table, ACPI_PTR_TO_PHYSADDR(table),
+ ACPI_TABLE_ORIGIN_EXTERNAL_VIRTUAL,
+ FALSE, &table_index);
return_ACPI_STATUS(status);
}
@@ -415,9 +378,9 @@
return_ACPI_STATUS(AE_TYPE);
}
- /* Must acquire the interpreter lock during this operation */
+ /* Must acquire the table lock during this operation */
- status = acpi_ut_acquire_mutex(ACPI_MTX_INTERPRETER);
+ status = acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
if (ACPI_FAILURE(status)) {
return_ACPI_STATUS(status);
}
@@ -444,8 +407,10 @@
/* Ensure the table is actually loaded */
+ (void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
if (!acpi_tb_is_table_loaded(i)) {
status = AE_NOT_EXIST;
+ (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
break;
}
@@ -471,10 +436,11 @@
status = acpi_tb_release_owner_id(i);
acpi_tb_set_table_loaded_flag(i, FALSE);
+ (void)acpi_ut_acquire_mutex(ACPI_MTX_TABLES);
break;
}
- (void)acpi_ut_release_mutex(ACPI_MTX_INTERPRETER);
+ (void)acpi_ut_release_mutex(ACPI_MTX_TABLES);
return_ACPI_STATUS(status);
}
diff --git a/drivers/acpi/acpica/tbxfroot.c b/drivers/acpi/acpica/tbxfroot.c
index adb6cfc..0adb1c7 100644
--- a/drivers/acpi/acpica/tbxfroot.c
+++ b/drivers/acpi/acpica/tbxfroot.c
@@ -142,7 +142,8 @@
*
******************************************************************************/
-acpi_status __init acpi_find_root_pointer(acpi_physical_address *table_address)
+acpi_status ACPI_INIT_FUNCTION
+acpi_find_root_pointer(acpi_physical_address *table_address)
{
u8 *table_ptr;
u8 *mem_rover;
@@ -244,6 +245,8 @@
return_ACPI_STATUS(AE_NOT_FOUND);
}
+ACPI_EXPORT_SYMBOL_INIT(acpi_find_root_pointer)
+
/*******************************************************************************
*
* FUNCTION: acpi_tb_scan_memory_for_rsdp
diff --git a/drivers/acpi/acpica/utaddress.c b/drivers/acpi/acpica/utaddress.c
index c986ec6..433d822 100644
--- a/drivers/acpi/acpica/utaddress.c
+++ b/drivers/acpi/acpica/utaddress.c
@@ -77,7 +77,6 @@
u32 length, struct acpi_namespace_node *region_node)
{
struct acpi_address_range *range_info;
- acpi_status status;
ACPI_FUNCTION_TRACE(ut_add_address_range);
@@ -97,12 +96,6 @@
range_info->end_address = (address + length - 1);
range_info->region_node = region_node;
- status = acpi_ut_acquire_mutex(ACPI_MTX_NAMESPACE);
- if (ACPI_FAILURE(status)) {
- ACPI_FREE(range_info);
- return_ACPI_STATUS(status);
- }
-
range_info->next = acpi_gbl_address_range_list[space_id];
acpi_gbl_address_range_list[space_id] = range_info;
@@ -112,7 +105,6 @@
ACPI_FORMAT_UINT64(address),
ACPI_FORMAT_UINT64(range_info->end_address)));
- (void)acpi_ut_release_mutex(ACPI_MTX_NAMESPACE);
return_ACPI_STATUS(AE_OK);
}
diff --git a/drivers/acpi/acpica/utbuffer.c b/drivers/acpi/acpica/utbuffer.c
index bd31faf..ff29812 100644
--- a/drivers/acpi/acpica/utbuffer.c
+++ b/drivers/acpi/acpica/utbuffer.c
@@ -239,8 +239,7 @@
u8 buf_char;
if (!buffer) {
- acpi_ut_file_printf(file,
- "Null Buffer Pointer in DumpBuffer!\n");
+ fprintf(file, "Null Buffer Pointer in DumpBuffer!\n");
return;
}
@@ -254,7 +253,7 @@
/* Print current offset */
- acpi_ut_file_printf(file, "%6.4X: ", (base_offset + i));
+ fprintf(file, "%6.4X: ", (base_offset + i));
/* Print 16 hex chars */
@@ -263,8 +262,7 @@
/* Dump fill spaces */
- acpi_ut_file_printf(file, "%*s",
- ((display * 2) + 1), " ");
+ fprintf(file, "%*s", ((display * 2) + 1), " ");
j += display;
continue;
}
@@ -273,34 +271,34 @@
case DB_BYTE_DISPLAY:
default: /* Default is BYTE display */
- acpi_ut_file_printf(file, "%02X ",
- buffer[(acpi_size)i + j]);
+ fprintf(file, "%02X ",
+ buffer[(acpi_size)i + j]);
break;
case DB_WORD_DISPLAY:
ACPI_MOVE_16_TO_32(&temp32,
&buffer[(acpi_size)i + j]);
- acpi_ut_file_printf(file, "%04X ", temp32);
+ fprintf(file, "%04X ", temp32);
break;
case DB_DWORD_DISPLAY:
ACPI_MOVE_32_TO_32(&temp32,
&buffer[(acpi_size)i + j]);
- acpi_ut_file_printf(file, "%08X ", temp32);
+ fprintf(file, "%08X ", temp32);
break;
case DB_QWORD_DISPLAY:
ACPI_MOVE_32_TO_32(&temp32,
&buffer[(acpi_size)i + j]);
- acpi_ut_file_printf(file, "%08X", temp32);
+ fprintf(file, "%08X", temp32);
ACPI_MOVE_32_TO_32(&temp32,
&buffer[(acpi_size)i + j +
4]);
- acpi_ut_file_printf(file, "%08X ", temp32);
+ fprintf(file, "%08X ", temp32);
break;
}
@@ -311,24 +309,24 @@
* Print the ASCII equivalent characters but watch out for the bad
* unprintable ones (printable chars are 0x20 through 0x7E)
*/
- acpi_ut_file_printf(file, " ");
+ fprintf(file, " ");
for (j = 0; j < 16; j++) {
if (i + j >= count) {
- acpi_ut_file_printf(file, "\n");
+ fprintf(file, "\n");
return;
}
buf_char = buffer[(acpi_size)i + j];
if (isprint(buf_char)) {
- acpi_ut_file_printf(file, "%c", buf_char);
+ fprintf(file, "%c", buf_char);
} else {
- acpi_ut_file_printf(file, ".");
+ fprintf(file, ".");
}
}
/* Done with that line. */
- acpi_ut_file_printf(file, "\n");
+ fprintf(file, "\n");
i += 16;
}
diff --git a/drivers/acpi/acpica/utdebug.c b/drivers/acpi/acpica/utdebug.c
index 5744222..044df9b 100644
--- a/drivers/acpi/acpica/utdebug.c
+++ b/drivers/acpi/acpica/utdebug.c
@@ -562,6 +562,43 @@
/*******************************************************************************
*
+ * FUNCTION: acpi_ut_str_exit
+ *
+ * PARAMETERS: line_number - Caller's line number
+ * function_name - Caller's procedure name
+ * module_name - Caller's module name
+ * component_id - Caller's component ID
+ * string - String to display
+ *
+ * RETURN: None
+ *
+ * DESCRIPTION: Function exit trace. Prints only if TRACE_FUNCTIONS bit is
+ * set in debug_level. Prints exit value also.
+ *
+ ******************************************************************************/
+
+void
+acpi_ut_str_exit(u32 line_number,
+ const char *function_name,
+ const char *module_name, u32 component_id, const char *string)
+{
+
+ /* Check if enabled up-front for performance */
+
+ if (ACPI_IS_DEBUG_ENABLED(ACPI_LV_FUNCTIONS, component_id)) {
+ acpi_debug_print(ACPI_LV_FUNCTIONS,
+ line_number, function_name, module_name,
+ component_id, "%s %s\n",
+ acpi_gbl_function_exit_prefix, string);
+ }
+
+ if (acpi_gbl_nesting_level) {
+ acpi_gbl_nesting_level--;
+ }
+}
+
+/*******************************************************************************
+ *
* FUNCTION: acpi_trace_point
*
* PARAMETERS: type - Trace event type
@@ -591,27 +628,3 @@
ACPI_EXPORT_SYMBOL(acpi_trace_point)
#endif
-#ifdef ACPI_APPLICATION
-/*******************************************************************************
- *
- * FUNCTION: acpi_log_error
- *
- * PARAMETERS: format - Printf format field
- * ... - Optional printf arguments
- *
- * RETURN: None
- *
- * DESCRIPTION: Print error message to the console, used by applications.
- *
- ******************************************************************************/
-void ACPI_INTERNAL_VAR_XFACE acpi_log_error(const char *format, ...)
-{
- va_list args;
-
- va_start(args, format);
- (void)acpi_ut_file_vprintf(ACPI_FILE_ERR, format, args);
- va_end(args);
-}
-
-ACPI_EXPORT_SYMBOL(acpi_log_error)
-#endif
diff --git a/drivers/acpi/acpica/utdecode.c b/drivers/acpi/acpica/utdecode.c
index efd7988..15728ad 100644
--- a/drivers/acpi/acpica/utdecode.c
+++ b/drivers/acpi/acpica/utdecode.c
@@ -253,7 +253,7 @@
return_PTR("Invalid object");
}
- return_PTR(acpi_ut_get_type_name(obj_desc->common.type));
+ return_STR(acpi_ut_get_type_name(obj_desc->common.type));
}
/*******************************************************************************
diff --git a/drivers/acpi/acpica/uthex.c b/drivers/acpi/acpica/uthex.c
index 4354fb8..36d2fc7 100644
--- a/drivers/acpi/acpica/uthex.c
+++ b/drivers/acpi/acpica/uthex.c
@@ -75,9 +75,41 @@
/*******************************************************************************
*
+ * FUNCTION: acpi_ut_ascii_to_hex_byte
+ *
+ * PARAMETERS: two_ascii_chars - Pointer to two ASCII characters
+ * return_byte - Where converted byte is returned
+ *
+ * RETURN: Status and converted hex byte
+ *
+ * DESCRIPTION: Perform ascii-to-hex translation, exactly two ASCII characters
+ * to a single converted byte value.
+ *
+ ******************************************************************************/
+
+acpi_status acpi_ut_ascii_to_hex_byte(char *two_ascii_chars, u8 *return_byte)
+{
+
+ /* Both ASCII characters must be valid hex digits */
+
+ if (!isxdigit((int)two_ascii_chars[0]) ||
+ !isxdigit((int)two_ascii_chars[1])) {
+ return (AE_BAD_HEX_CONSTANT);
+ }
+
+ *return_byte =
+ acpi_ut_ascii_char_to_hex(two_ascii_chars[1]) |
+ (acpi_ut_ascii_char_to_hex(two_ascii_chars[0]) << 4);
+
+ return (AE_OK);
+}
+
+/*******************************************************************************
+ *
* FUNCTION: acpi_ut_ascii_char_to_hex
*
- * PARAMETERS: hex_char - Hex character in Ascii
+ * PARAMETERS: hex_char - Hex character in Ascii. Must be:
+ * 0-9 or A-F or a-f
*
* RETURN: The binary value of the ascii/hex character
*
@@ -88,13 +120,19 @@
u8 acpi_ut_ascii_char_to_hex(int hex_char)
{
- if (hex_char <= 0x39) {
- return ((u8)(hex_char - 0x30));
+ /* Values 0-9 */
+
+ if (hex_char <= '9') {
+ return ((u8)(hex_char - '0'));
}
- if (hex_char <= 0x46) {
+ /* Upper case A-F */
+
+ if (hex_char <= 'F') {
return ((u8)(hex_char - 0x37));
}
+ /* Lower case a-f */
+
return ((u8)(hex_char - 0x57));
}
diff --git a/drivers/acpi/acpica/utinit.c b/drivers/acpi/acpica/utinit.c
index f91f724..1711fdf 100644
--- a/drivers/acpi/acpica/utinit.c
+++ b/drivers/acpi/acpica/utinit.c
@@ -206,7 +206,7 @@
acpi_gbl_next_owner_id_offset = 0;
acpi_gbl_debugger_configuration = DEBUGGER_THREADING;
acpi_gbl_osi_mutex = NULL;
- acpi_gbl_max_loop_iterations = 0xFFFF;
+ acpi_gbl_max_loop_iterations = ACPI_MAX_LOOP_COUNT;
/* Hardware oriented */
diff --git a/drivers/acpi/acpica/utnonansi.c b/drivers/acpi/acpica/utnonansi.c
index 3465fe2..2514239 100644
--- a/drivers/acpi/acpica/utnonansi.c
+++ b/drivers/acpi/acpica/utnonansi.c
@@ -48,8 +48,8 @@
ACPI_MODULE_NAME("utnonansi")
/*
- * Non-ANSI C library functions - strlwr, strupr, stricmp, and a 64-bit
- * version of strtoul.
+ * Non-ANSI C library functions - strlwr, strupr, stricmp, and "safe"
+ * string functions.
*/
/*******************************************************************************
*
@@ -200,356 +200,3 @@
return (FALSE);
}
#endif
-
-/*******************************************************************************
- *
- * FUNCTION: acpi_ut_strtoul64
- *
- * PARAMETERS: string - Null terminated string
- * base - Radix of the string: 16 or 10 or
- * ACPI_ANY_BASE
- * max_integer_byte_width - Maximum allowable integer,in bytes:
- * 4 or 8 (32 or 64 bits)
- * ret_integer - Where the converted integer is
- * returned
- *
- * RETURN: Status and Converted value
- *
- * DESCRIPTION: Convert a string into an unsigned value. Performs either a
- * 32-bit or 64-bit conversion, depending on the input integer
- * size (often the current mode of the interpreter).
- *
- * NOTES: Negative numbers are not supported, as they are not supported
- * by ACPI.
- *
- * acpi_gbl_integer_byte_width should be set to the proper width.
- * For the core ACPICA code, this width depends on the DSDT
- * version. For iASL, the default byte width is always 8 for the
- * parser, but error checking is performed later to flag cases
- * where a 64-bit constant is defined in a 32-bit DSDT/SSDT.
- *
- * Does not support Octal strings, not needed at this time.
- *
- ******************************************************************************/
-
-acpi_status
-acpi_ut_strtoul64(char *string,
- u32 base, u32 max_integer_byte_width, u64 *ret_integer)
-{
- u32 this_digit = 0;
- u64 return_value = 0;
- u64 quotient;
- u64 dividend;
- u8 valid_digits = 0;
- u8 sign_of0x = 0;
- u8 term = 0;
-
- ACPI_FUNCTION_TRACE_STR(ut_strtoul64, string);
-
- switch (base) {
- case ACPI_ANY_BASE:
- case 10:
- case 16:
-
- break;
-
- default:
-
- /* Invalid Base */
-
- return_ACPI_STATUS(AE_BAD_PARAMETER);
- }
-
- if (!string) {
- goto error_exit;
- }
-
- /* Skip over any white space in the buffer */
-
- while ((*string) && (isspace((int)*string) || *string == '\t')) {
- string++;
- }
-
- if (base == ACPI_ANY_BASE) {
- /*
- * Base equal to ACPI_ANY_BASE means 'Either decimal or hex'.
- * We need to determine if it is decimal or hexadecimal.
- */
- if ((*string == '0') && (tolower((int)*(string + 1)) == 'x')) {
- sign_of0x = 1;
- base = 16;
-
- /* Skip over the leading '0x' */
- string += 2;
- } else {
- base = 10;
- }
- }
-
- /* Any string left? Check that '0x' is not followed by white space. */
-
- if (!(*string) || isspace((int)*string) || *string == '\t') {
- if (base == ACPI_ANY_BASE) {
- goto error_exit;
- } else {
- goto all_done;
- }
- }
-
- /*
- * Perform a 32-bit or 64-bit conversion, depending upon the input
- * byte width
- */
- dividend = (max_integer_byte_width <= ACPI_MAX32_BYTE_WIDTH) ?
- ACPI_UINT32_MAX : ACPI_UINT64_MAX;
-
- /* Main loop: convert the string to a 32- or 64-bit integer */
-
- while (*string) {
- if (isdigit((int)*string)) {
-
- /* Convert ASCII 0-9 to Decimal value */
-
- this_digit = ((u8)*string) - '0';
- } else if (base == 10) {
-
- /* Digit is out of range; possible in to_integer case only */
-
- term = 1;
- } else {
- this_digit = (u8)toupper((int)*string);
- if (isxdigit((int)this_digit)) {
-
- /* Convert ASCII Hex char to value */
-
- this_digit = this_digit - 'A' + 10;
- } else {
- term = 1;
- }
- }
-
- if (term) {
- if (base == ACPI_ANY_BASE) {
- goto error_exit;
- } else {
- break;
- }
- } else if ((valid_digits == 0) && (this_digit == 0)
- && !sign_of0x) {
-
- /* Skip zeros */
- string++;
- continue;
- }
-
- valid_digits++;
-
- if (sign_of0x && ((valid_digits > 16) ||
- ((valid_digits > 8)
- && (max_integer_byte_width <=
- ACPI_MAX32_BYTE_WIDTH)))) {
- /*
- * This is to_integer operation case.
- * No restrictions for string-to-integer conversion,
- * see ACPI spec.
- */
- goto error_exit;
- }
-
- /* Divide the digit into the correct position */
-
- (void)acpi_ut_short_divide((dividend - (u64)this_digit), base,
- "ient, NULL);
-
- if (return_value > quotient) {
- if (base == ACPI_ANY_BASE) {
- goto error_exit;
- } else {
- break;
- }
- }
-
- return_value *= base;
- return_value += this_digit;
- string++;
- }
-
- /* All done, normal exit */
-
-all_done:
-
- ACPI_DEBUG_PRINT((ACPI_DB_EXEC, "Converted value: %8.8X%8.8X\n",
- ACPI_FORMAT_UINT64(return_value)));
-
- *ret_integer = return_value;
- return_ACPI_STATUS(AE_OK);
-
-error_exit:
-
- /* Base was set/validated above (10 or 16) */
-
- if (base == 10) {
- return_ACPI_STATUS(AE_BAD_DECIMAL_CONSTANT);
- } else {
- return_ACPI_STATUS(AE_BAD_HEX_CONSTANT);
- }
-}
-
-#ifdef _OBSOLETE_FUNCTIONS
-/* Removed: 01/2016 */
-
-/*******************************************************************************
- *
- * FUNCTION: strtoul64
- *
- * PARAMETERS: string - Null terminated string
- * terminater - Where a pointer to the terminating byte
- * is returned
- * base - Radix of the string
- *
- * RETURN: Converted value
- *
- * DESCRIPTION: Convert a string into an unsigned value.
- *
- ******************************************************************************/
-
-acpi_status strtoul64(char *string, u32 base, u64 *ret_integer)
-{
- u32 index;
- u32 sign;
- u64 return_value = 0;
- acpi_status status = AE_OK;
-
- *ret_integer = 0;
-
- switch (base) {
- case 0:
- case 8:
- case 10:
- case 16:
-
- break;
-
- default:
- /*
- * The specified Base parameter is not in the domain of
- * this function:
- */
- return (AE_BAD_PARAMETER);
- }
-
- /* Skip over any white space in the buffer: */
-
- while (isspace((int)*string) || *string == '\t') {
- ++string;
- }
-
- /*
- * The buffer may contain an optional plus or minus sign.
- * If it does, then skip over it but remember what is was:
- */
- if (*string == '-') {
- sign = ACPI_SIGN_NEGATIVE;
- ++string;
- } else if (*string == '+') {
- ++string;
- sign = ACPI_SIGN_POSITIVE;
- } else {
- sign = ACPI_SIGN_POSITIVE;
- }
-
- /*
- * If the input parameter Base is zero, then we need to
- * determine if it is octal, decimal, or hexadecimal:
- */
- if (base == 0) {
- if (*string == '0') {
- if (tolower((int)*(++string)) == 'x') {
- base = 16;
- ++string;
- } else {
- base = 8;
- }
- } else {
- base = 10;
- }
- }
-
- /*
- * For octal and hexadecimal bases, skip over the leading
- * 0 or 0x, if they are present.
- */
- if (base == 8 && *string == '0') {
- string++;
- }
-
- if (base == 16 && *string == '0' && tolower((int)*(++string)) == 'x') {
- string++;
- }
-
- /* Main loop: convert the string to an unsigned long */
-
- while (*string) {
- if (isdigit((int)*string)) {
- index = ((u8)*string) - '0';
- } else {
- index = (u8)toupper((int)*string);
- if (isupper((int)index)) {
- index = index - 'A' + 10;
- } else {
- goto error_exit;
- }
- }
-
- if (index >= base) {
- goto error_exit;
- }
-
- /* Check to see if value is out of range: */
-
- if (return_value > ((ACPI_UINT64_MAX - (u64)index) / (u64)base)) {
- goto error_exit;
- } else {
- return_value *= base;
- return_value += index;
- }
-
- ++string;
- }
-
- /* If a minus sign was present, then "the conversion is negated": */
-
- if (sign == ACPI_SIGN_NEGATIVE) {
- return_value = (ACPI_UINT32_MAX - return_value) + 1;
- }
-
- *ret_integer = return_value;
- return (status);
-
-error_exit:
- switch (base) {
- case 8:
-
- status = AE_BAD_OCTAL_CONSTANT;
- break;
-
- case 10:
-
- status = AE_BAD_DECIMAL_CONSTANT;
- break;
-
- case 16:
-
- status = AE_BAD_HEX_CONSTANT;
- break;
-
- default:
-
- /* Base validated above */
-
- break;
- }
-
- return (status);
-}
-#endif
diff --git a/drivers/acpi/acpica/utosi.c b/drivers/acpi/acpica/utosi.c
index 3f5fed6..f0484b0 100644
--- a/drivers/acpi/acpica/utosi.c
+++ b/drivers/acpi/acpica/utosi.c
@@ -390,11 +390,22 @@
* PARAMETERS: walk_state - Current walk state
*
* RETURN: Status
+ * Integer: TRUE (0) if input string is matched
+ * FALSE (-1) if string is not matched
*
* DESCRIPTION: Implementation of the _OSI predefined control method. When
* an invocation of _OSI is encountered in the system AML,
* control is transferred to this function.
*
+ * (August 2016)
+ * Note: _OSI is now defined to return "Ones" to indicate a match, for
+ * compatibility with other ACPI implementations. On a 32-bit DSDT, Ones
+ * is 0xFFFFFFFF. On a 64-bit DSDT, Ones is 0xFFFFFFFFFFFFFFFF
+ * (ACPI_UINT64_MAX).
+ *
+ * This function always returns ACPI_UINT64_MAX for TRUE, and later code
+ * will truncate this to 32 bits if necessary.
+ *
******************************************************************************/
acpi_status acpi_ut_osi_implementation(struct acpi_walk_state *walk_state)
@@ -404,7 +415,7 @@
struct acpi_interface_info *interface_info;
acpi_interface_handler interface_handler;
acpi_status status;
- u32 return_value;
+ u64 return_value;
ACPI_FUNCTION_TRACE(ut_osi_implementation);
@@ -444,7 +455,7 @@
acpi_gbl_osi_data = interface_info->value;
}
- return_value = ACPI_UINT32_MAX;
+ return_value = ACPI_UINT64_MAX;
}
acpi_os_release_mutex(acpi_gbl_osi_mutex);
@@ -456,9 +467,10 @@
*/
interface_handler = acpi_gbl_interface_handler;
if (interface_handler) {
- return_value =
- interface_handler(string_desc->string.pointer,
- return_value);
+ if (interface_handler
+ (string_desc->string.pointer, (u32)return_value)) {
+ return_value = ACPI_UINT64_MAX;
+ }
}
ACPI_DEBUG_PRINT_RAW((ACPI_DB_INFO,
diff --git a/drivers/acpi/acpica/utpredef.c b/drivers/acpi/acpica/utpredef.c
index 770a177..ce18346 100644
--- a/drivers/acpi/acpica/utpredef.c
+++ b/drivers/acpi/acpica/utpredef.c
@@ -176,8 +176,6 @@
******************************************************************************/
#if (defined ACPI_ASL_COMPILER || defined ACPI_HELP_APP)
-#include <stdio.h>
-#include <string.h>
/* Local prototypes */
diff --git a/drivers/acpi/acpica/utprint.c b/drivers/acpi/acpica/utprint.c
index dd084cf..40eba80 100644
--- a/drivers/acpi/acpica/utprint.c
+++ b/drivers/acpi/acpica/utprint.c
@@ -336,7 +336,7 @@
/*******************************************************************************
*
- * FUNCTION: acpi_ut_vsnprintf
+ * FUNCTION: vsnprintf
*
* PARAMETERS: string - String with boundary
* size - Boundary of the string
@@ -349,9 +349,7 @@
*
******************************************************************************/
-int
-acpi_ut_vsnprintf(char *string,
- acpi_size size, const char *format, va_list args)
+int vsnprintf(char *string, acpi_size size, const char *format, va_list args)
{
u8 base;
u8 type;
@@ -586,7 +584,7 @@
/*******************************************************************************
*
- * FUNCTION: acpi_ut_snprintf
+ * FUNCTION: snprintf
*
* PARAMETERS: string - String with boundary
* size - Boundary of the string
@@ -598,13 +596,38 @@
*
******************************************************************************/
-int acpi_ut_snprintf(char *string, acpi_size size, const char *format, ...)
+int snprintf(char *string, acpi_size size, const char *format, ...)
{
va_list args;
int length;
va_start(args, format);
- length = acpi_ut_vsnprintf(string, size, format, args);
+ length = vsnprintf(string, size, format, args);
+ va_end(args);
+
+ return (length);
+}
+
+/*******************************************************************************
+ *
+ * FUNCTION: sprintf
+ *
+ * PARAMETERS: string - String with boundary
+ * Format, ... - Standard printf format
+ *
+ * RETURN: Number of bytes actually written.
+ *
+ * DESCRIPTION: Formatted output to a string.
+ *
+ ******************************************************************************/
+
+int sprintf(char *string, const char *format, ...)
+{
+ va_list args;
+ int length;
+
+ va_start(args, format);
+ length = vsnprintf(string, ACPI_UINT32_MAX, format, args);
va_end(args);
return (length);
@@ -613,7 +636,59 @@
#ifdef ACPI_APPLICATION
/*******************************************************************************
*
- * FUNCTION: acpi_ut_file_vprintf
+ * FUNCTION: vprintf
+ *
+ * PARAMETERS: format - Standard printf format
+ * args - Argument list
+ *
+ * RETURN: Number of bytes actually written.
+ *
+ * DESCRIPTION: Formatted output to stdout using argument list pointer.
+ *
+ ******************************************************************************/
+
+int vprintf(const char *format, va_list args)
+{
+ acpi_cpu_flags flags;
+ int length;
+
+ flags = acpi_os_acquire_lock(acpi_gbl_print_lock);
+ length = vsnprintf(acpi_gbl_print_buffer,
+ sizeof(acpi_gbl_print_buffer), format, args);
+
+ (void)fwrite(acpi_gbl_print_buffer, length, 1, ACPI_FILE_OUT);
+ acpi_os_release_lock(acpi_gbl_print_lock, flags);
+
+ return (length);
+}
+
+/*******************************************************************************
+ *
+ * FUNCTION: printf
+ *
+ * PARAMETERS: Format, ... - Standard printf format
+ *
+ * RETURN: Number of bytes actually written.
+ *
+ * DESCRIPTION: Formatted output to stdout.
+ *
+ ******************************************************************************/
+
+int printf(const char *format, ...)
+{
+ va_list args;
+ int length;
+
+ va_start(args, format);
+ length = vprintf(format, args);
+ va_end(args);
+
+ return (length);
+}
+
+/*******************************************************************************
+ *
+ * FUNCTION: vfprintf
*
* PARAMETERS: file - File descriptor
* format - Standard printf format
@@ -625,16 +700,16 @@
*
******************************************************************************/
-int acpi_ut_file_vprintf(ACPI_FILE file, const char *format, va_list args)
+int vfprintf(FILE * file, const char *format, va_list args)
{
acpi_cpu_flags flags;
int length;
flags = acpi_os_acquire_lock(acpi_gbl_print_lock);
- length = acpi_ut_vsnprintf(acpi_gbl_print_buffer,
- sizeof(acpi_gbl_print_buffer), format, args);
+ length = vsnprintf(acpi_gbl_print_buffer,
+ sizeof(acpi_gbl_print_buffer), format, args);
- (void)acpi_os_write_file(file, acpi_gbl_print_buffer, length, 1);
+ (void)fwrite(acpi_gbl_print_buffer, length, 1, file);
acpi_os_release_lock(acpi_gbl_print_lock, flags);
return (length);
@@ -642,7 +717,7 @@
/*******************************************************************************
*
- * FUNCTION: acpi_ut_file_printf
+ * FUNCTION: fprintf
*
* PARAMETERS: file - File descriptor
* Format, ... - Standard printf format
@@ -653,13 +728,13 @@
*
******************************************************************************/
-int acpi_ut_file_printf(ACPI_FILE file, const char *format, ...)
+int fprintf(FILE * file, const char *format, ...)
{
va_list args;
int length;
va_start(args, format);
- length = acpi_ut_file_vprintf(file, format, args);
+ length = vfprintf(file, format, args);
va_end(args);
return (length);
diff --git a/drivers/acpi/acpica/utstrtoul64.c b/drivers/acpi/acpica/utstrtoul64.c
new file mode 100644
index 0000000..b4f341c
--- /dev/null
+++ b/drivers/acpi/acpica/utstrtoul64.c
@@ -0,0 +1,348 @@
+/*******************************************************************************
+ *
+ * Module Name: utstrtoul64 - string to 64-bit integer support
+ *
+ ******************************************************************************/
+
+/*
+ * Copyright (C) 2000 - 2016, Intel Corp.
+ * All rights reserved.
+ *
+ * Redistribution and use in source and binary forms, with or without
+ * modification, are permitted provided that the following conditions
+ * are met:
+ * 1. Redistributions of source code must retain the above copyright
+ * notice, this list of conditions, and the following disclaimer,
+ * without modification.
+ * 2. Redistributions in binary form must reproduce at minimum a disclaimer
+ * substantially similar to the "NO WARRANTY" disclaimer below
+ * ("Disclaimer") and any redistribution must be conditioned upon
+ * including a substantially similar Disclaimer requirement for further
+ * binary redistribution.
+ * 3. Neither the names of the above-listed copyright holders nor the names
+ * of any contributors may be used to endorse or promote products derived
+ * from this software without specific prior written permission.
+ *
+ * Alternatively, this software may be distributed under the terms of the
+ * GNU General Public License ("GPL") version 2 as published by the Free
+ * Software Foundation.
+ *
+ * NO WARRANTY
+ * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
+ * "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
+ * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTIBILITY AND FITNESS FOR
+ * A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
+ * HOLDERS OR CONTRIBUTORS BE LIABLE FOR SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+ * DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
+ * OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
+ * HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT,
+ * STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING
+ * IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
+ * POSSIBILITY OF SUCH DAMAGES.
+ */
+
+#include <acpi/acpi.h>
+#include "accommon.h"
+
+/*******************************************************************************
+ *
+ * The functions in this module satisfy the need for 64-bit string-to-integer
+ * conversions on both 32-bit and 64-bit platforms.
+ *
+ ******************************************************************************/
+
+#define _COMPONENT ACPI_UTILITIES
+ACPI_MODULE_NAME("utstrtoul64")
+
+/* Local prototypes */
+static u64 acpi_ut_strtoul_base10(char *string, u32 flags);
+
+static u64 acpi_ut_strtoul_base16(char *string, u32 flags);
+
+/*******************************************************************************
+ *
+ * String conversion rules as written in the ACPI specification. The error
+ * conditions and behavior are different depending on the type of conversion.
+ *
+ *
+ * Implicit data type conversion: string-to-integer
+ * --------------------------------------------------
+ *
+ * Base is always 16. This is the ACPI_STRTOUL_BASE16 case.
+ *
+ * Example:
+ * Add ("BA98", Arg0, Local0)
+ *
+ * The integer is initialized to the value zero.
+ * The ASCII string is interpreted as a hexadecimal constant.
+ *
+ * 1) A "0x" prefix is not allowed. However, ACPICA allows this for
+ * compatibility with previous ACPICA. (NO ERROR)
+ *
+ * 2) Terminates when the size of an integer is reached (32 or 64 bits).
+ * (NO ERROR)
+ *
+ * 3) The first non-hex character terminates the conversion without error.
+ * (NO ERROR)
+ *
+ * 4) Conversion of a null (zero-length) string to an integer is not
+ * allowed. However, ACPICA allows this for compatibility with previous
+ * ACPICA. This conversion returns the value 0. (NO ERROR)
+ *
+ *
+ * Explicit data type conversion: to_integer() with string operand
+ * ---------------------------------------------------------------
+ *
+ * Base is either 10 (default) or 16 (with 0x prefix)
+ *
+ * Examples:
+ * to_integer ("1000")
+ * to_integer ("0xABCD")
+ *
+ * 1) Can be (must be) either a decimal or hexadecimal numeric string.
+ * A hex value must be prefixed by "0x" or it is interpreted as a decimal.
+ *
+ * 2) The value must not exceed the maximum of an integer value. ACPI spec
+ * states the behavior is "unpredictable", so ACPICA matches the behavior
+ * of the implicit conversion case.(NO ERROR)
+ *
+ * 3) Behavior on the first non-hex character is not specified by the ACPI
+ * spec, so ACPICA matches the behavior of the implicit conversion case
+ * and terminates. (NO ERROR)
+ *
+ * 4) A null (zero-length) string is illegal.
+ * However, ACPICA allows this for compatibility with previous ACPICA.
+ * This conversion returns the value 0. (NO ERROR)
+ *
+ ******************************************************************************/
+
+/*******************************************************************************
+ *
+ * FUNCTION: acpi_ut_strtoul64
+ *
+ * PARAMETERS: string - Null terminated input string
+ * flags - Conversion info, see below
+ * return_value - Where the converted integer is
+ * returned
+ *
+ * RETURN: Status and Converted value
+ *
+ * DESCRIPTION: Convert a string into an unsigned value. Performs either a
+ * 32-bit or 64-bit conversion, depending on the input integer
+ * size in Flags (often the current mode of the interpreter).
+ *
+ * Values for Flags:
+ * ACPI_STRTOUL_32BIT - Max integer value is 32 bits
+ * ACPI_STRTOUL_64BIT - Max integer value is 64 bits
+ * ACPI_STRTOUL_BASE16 - Input string is hexadecimal. Default
+ * is 10/16 based on string prefix (0x).
+ *
+ * NOTES:
+ * Negative numbers are not supported, as they are not supported by ACPI.
+ *
+ * Supports only base 16 or base 10 strings/values. Does not
+ * support Octal strings, as these are not supported by ACPI.
+ *
+ * Current users of this support:
+ *
+ * interpreter - Implicit and explicit conversions, GPE method names
+ * debugger - Command line input string conversion
+ * iASL - Main parser, conversion of constants to integers
+ * iASL - Data Table Compiler parser (constant math expressions)
+ * iASL - Preprocessor (constant math expressions)
+ * acpi_dump - Input table addresses
+ * acpi_exec - Testing of the acpi_ut_strtoul64 function
+ *
+ * Note concerning callers:
+ * acpi_gbl_integer_byte_width can be used to set the 32/64 limit. If used,
+ * this global should be set to the proper width. For the core ACPICA code,
+ * this width depends on the DSDT version. For iASL, the default byte
+ * width is always 8 for the parser, but error checking is performed later
+ * to flag cases where a 64-bit constant is defined in a 32-bit DSDT/SSDT.
+ *
+ ******************************************************************************/
+
+acpi_status acpi_ut_strtoul64(char *string, u32 flags, u64 *return_value)
+{
+ acpi_status status = AE_OK;
+ u32 base;
+
+ ACPI_FUNCTION_TRACE_STR(ut_strtoul64, string);
+
+ /* Parameter validation */
+
+ if (!string || !return_value) {
+ return_ACPI_STATUS(AE_BAD_PARAMETER);
+ }
+
+ *return_value = 0;
+
+ /* Check for zero-length string, returns 0 */
+
+ if (*string == 0) {
+ return_ACPI_STATUS(AE_OK);
+ }
+
+ /* Skip over any white space at start of string */
+
+ while (isspace((int)*string)) {
+ string++;
+ }
+
+ /* End of string? return 0 */
+
+ if (*string == 0) {
+ return_ACPI_STATUS(AE_OK);
+ }
+
+ /*
+ * 1) The "0x" prefix indicates base 16. Per the ACPI specification,
+ * the "0x" prefix is only allowed for implicit (non-strict) conversions.
+ * However, we always allow it for compatibility with older ACPICA.
+ */
+ if ((*string == ACPI_ASCII_ZERO) &&
+ (tolower((int)*(string + 1)) == 'x')) {
+ string += 2; /* Go past the 0x */
+ if (*string == 0) {
+ return_ACPI_STATUS(AE_OK); /* Return value 0 */
+ }
+
+ base = 16;
+ }
+
+ /* 2) Force to base 16 (implicit conversion case) */
+
+ else if (flags & ACPI_STRTOUL_BASE16) {
+ base = 16;
+ }
+
+ /* 3) Default fallback is to Base 10 */
+
+ else {
+ base = 10;
+ }
+
+ /* Skip all leading zeros */
+
+ while (*string == ACPI_ASCII_ZERO) {
+ string++;
+ if (*string == 0) {
+ return_ACPI_STATUS(AE_OK); /* Return value 0 */
+ }
+ }
+
+ /* Perform the base 16 or 10 conversion */
+
+ if (base == 16) {
+ *return_value = acpi_ut_strtoul_base16(string, flags);
+ } else {
+ *return_value = acpi_ut_strtoul_base10(string, flags);
+ }
+
+ return_ACPI_STATUS(status);
+}
+
+/*******************************************************************************
+ *
+ * FUNCTION: acpi_ut_strtoul_base10
+ *
+ * PARAMETERS: string - Null terminated input string
+ * flags - Conversion info
+ *
+ * RETURN: 64-bit converted integer
+ *
+ * DESCRIPTION: Performs a base 10 conversion of the input string to an
+ * integer value, either 32 or 64 bits.
+ * Note: String must be valid and non-null.
+ *
+ ******************************************************************************/
+
+static u64 acpi_ut_strtoul_base10(char *string, u32 flags)
+{
+ int ascii_digit;
+ u64 next_value;
+ u64 return_value = 0;
+
+ /* Main loop: convert each ASCII byte in the input string */
+
+ while (*string) {
+ ascii_digit = *string;
+ if (!isdigit(ascii_digit)) {
+
+ /* Not ASCII 0-9, terminate */
+
+ goto exit;
+ }
+
+ /* Convert and insert (add) the decimal digit */
+
+ next_value =
+ (return_value * 10) + (ascii_digit - ACPI_ASCII_ZERO);
+
+ /* Check for overflow (32 or 64 bit) - return current converted value */
+
+ if (((flags & ACPI_STRTOUL_32BIT) && (next_value > ACPI_UINT32_MAX)) || (next_value < return_value)) { /* 64-bit overflow case */
+ goto exit;
+ }
+
+ return_value = next_value;
+ string++;
+ }
+
+exit:
+ return (return_value);
+}
+
+/*******************************************************************************
+ *
+ * FUNCTION: acpi_ut_strtoul_base16
+ *
+ * PARAMETERS: string - Null terminated input string
+ * flags - conversion info
+ *
+ * RETURN: 64-bit converted integer
+ *
+ * DESCRIPTION: Performs a base 16 conversion of the input string to an
+ * integer value, either 32 or 64 bits.
+ * Note: String must be valid and non-null.
+ *
+ ******************************************************************************/
+
+static u64 acpi_ut_strtoul_base16(char *string, u32 flags)
+{
+ int ascii_digit;
+ u32 valid_digits = 1;
+ u64 return_value = 0;
+
+ /* Main loop: convert each ASCII byte in the input string */
+
+ while (*string) {
+
+ /* Check for overflow (32 or 64 bit) - return current converted value */
+
+ if ((valid_digits > 16) ||
+ ((valid_digits > 8) && (flags & ACPI_STRTOUL_32BIT))) {
+ goto exit;
+ }
+
+ ascii_digit = *string;
+ if (!isxdigit(ascii_digit)) {
+
+ /* Not Hex ASCII A-F, a-f, or 0-9, terminate */
+
+ goto exit;
+ }
+
+ /* Convert and insert the hex digit */
+
+ return_value =
+ (return_value << 4) |
+ acpi_ut_ascii_char_to_hex(ascii_digit);
+
+ string++;
+ valid_digits++;
+ }
+
+exit:
+ return (return_value);
+}
diff --git a/drivers/acpi/acpica/uttrack.c b/drivers/acpi/acpica/uttrack.c
index 0df07df..df31d71 100644
--- a/drivers/acpi/acpica/uttrack.c
+++ b/drivers/acpi/acpica/uttrack.c
@@ -95,13 +95,11 @@
{
struct acpi_memory_list *cache;
- cache = acpi_os_allocate(sizeof(struct acpi_memory_list));
+ cache = acpi_os_allocate_zeroed(sizeof(struct acpi_memory_list));
if (!cache) {
return (AE_NO_MEMORY);
}
- memset(cache, 0, sizeof(struct acpi_memory_list));
-
cache->list_name = list_name;
cache->object_size = object_size;
diff --git a/drivers/acpi/acpica/utxface.c b/drivers/acpi/acpica/utxface.c
index d9e6aac..ec503c8 100644
--- a/drivers/acpi/acpica/utxface.c
+++ b/drivers/acpi/acpica/utxface.c
@@ -61,7 +61,7 @@
* DESCRIPTION: Shutdown the ACPICA subsystem and release all resources.
*
******************************************************************************/
-acpi_status __init acpi_terminate(void)
+acpi_status ACPI_INIT_FUNCTION acpi_terminate(void)
{
acpi_status status;
diff --git a/drivers/acpi/acpica/utxfinit.c b/drivers/acpi/acpica/utxfinit.c
index 75b5f27..a5ca0f5 100644
--- a/drivers/acpi/acpica/utxfinit.c
+++ b/drivers/acpi/acpica/utxfinit.c
@@ -69,7 +69,7 @@
*
******************************************************************************/
-acpi_status __init acpi_initialize_subsystem(void)
+acpi_status ACPI_INIT_FUNCTION acpi_initialize_subsystem(void)
{
acpi_status status;
@@ -141,7 +141,7 @@
* Puts system into ACPI mode if it isn't already.
*
******************************************************************************/
-acpi_status __init acpi_enable_subsystem(u32 flags)
+acpi_status ACPI_INIT_FUNCTION acpi_enable_subsystem(u32 flags)
{
acpi_status status = AE_OK;
@@ -239,7 +239,7 @@
* objects and executing AML code for Regions, buffers, etc.
*
******************************************************************************/
-acpi_status __init acpi_initialize_objects(u32 flags)
+acpi_status ACPI_INIT_FUNCTION acpi_initialize_objects(u32 flags)
{
acpi_status status = AE_OK;
@@ -265,7 +265,8 @@
* all of the tables have been loaded. It is a legacy option and is
* not compatible with other ACPI implementations. See acpi_ns_load_table.
*/
- if (acpi_gbl_group_module_level_code) {
+ if (!acpi_gbl_parse_table_as_term_list
+ && acpi_gbl_group_module_level_code) {
acpi_ns_exec_module_code_list();
/*
diff --git a/drivers/acpi/battery.c b/drivers/acpi/battery.c
index ab23479..93ecae5 100644
--- a/drivers/acpi/battery.c
+++ b/drivers/acpi/battery.c
@@ -733,15 +733,17 @@
return result;
acpi_battery_init_alarm(battery);
}
+
+ result = acpi_battery_get_state(battery);
+ if (result)
+ return result;
+ acpi_battery_quirks(battery);
+
if (!battery->bat) {
result = sysfs_add_battery(battery);
if (result)
return result;
}
- result = acpi_battery_get_state(battery);
- if (result)
- return result;
- acpi_battery_quirks(battery);
/*
* Wakeup the system if battery is critical low
diff --git a/drivers/acpi/bus.c b/drivers/acpi/bus.c
index 85b7d07..658b4c4 100644
--- a/drivers/acpi/bus.c
+++ b/drivers/acpi/bus.c
@@ -985,7 +985,8 @@
goto error0;
}
- if (acpi_gbl_group_module_level_code) {
+ if (!acpi_gbl_parse_table_as_term_list &&
+ acpi_gbl_group_module_level_code) {
status = acpi_load_tables();
if (ACPI_FAILURE(status)) {
printk(KERN_ERR PREFIX
@@ -1074,7 +1075,8 @@
status = acpi_ec_ecdt_probe();
/* Ignore result. Not having an ECDT is not fatal. */
- if (!acpi_gbl_group_module_level_code) {
+ if (acpi_gbl_parse_table_as_term_list ||
+ !acpi_gbl_group_module_level_code) {
status = acpi_load_tables();
if (ACPI_FAILURE(status)) {
printk(KERN_ERR PREFIX
diff --git a/drivers/acpi/button.c b/drivers/acpi/button.c
index 31abb0b..e19f530 100644
--- a/drivers/acpi/button.c
+++ b/drivers/acpi/button.c
@@ -19,6 +19,8 @@
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
*/
+#define pr_fmt(fmt) "ACPI : button: " fmt
+
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
@@ -104,6 +106,8 @@
struct input_dev *input;
char phys[32]; /* for input device */
unsigned long pushed;
+ int last_state;
+ ktime_t last_time;
bool suspended;
};
@@ -111,6 +115,10 @@
static struct acpi_device *lid_device;
static u8 lid_init_state = ACPI_BUTTON_LID_INIT_METHOD;
+static unsigned long lid_report_interval __read_mostly = 500;
+module_param(lid_report_interval, ulong, 0644);
+MODULE_PARM_DESC(lid_report_interval, "Interval (ms) between lid key events");
+
/* --------------------------------------------------------------------------
FS Interface (/proc)
-------------------------------------------------------------------------- */
@@ -134,10 +142,79 @@
{
struct acpi_button *button = acpi_driver_data(device);
int ret;
+ ktime_t next_report;
+ bool do_update;
- /* input layer checks if event is redundant */
- input_report_switch(button->input, SW_LID, !state);
- input_sync(button->input);
+ /*
+ * In lid_init_state=ignore mode, if user opens/closes lid
+ * frequently with "open" missing, and "last_time" is also updated
+ * frequently, "close" cannot be delivered to the userspace.
+ * So "last_time" is only updated after a timeout or an actual
+ * switch.
+ */
+ if (lid_init_state != ACPI_BUTTON_LID_INIT_IGNORE ||
+ button->last_state != !!state)
+ do_update = true;
+ else
+ do_update = false;
+
+ next_report = ktime_add(button->last_time,
+ ms_to_ktime(lid_report_interval));
+ if (button->last_state == !!state &&
+ ktime_after(ktime_get(), next_report)) {
+ /* Complain the buggy firmware */
+ pr_warn_once("The lid device is not compliant to SW_LID.\n");
+
+ /*
+ * Send the unreliable complement switch event:
+ *
+ * On most platforms, the lid device is reliable. However
+ * there are exceptions:
+ * 1. Platforms returning initial lid state as "close" by
+ * default after booting/resuming:
+ * https://bugzilla.kernel.org/show_bug.cgi?id=89211
+ * https://bugzilla.kernel.org/show_bug.cgi?id=106151
+ * 2. Platforms never reporting "open" events:
+ * https://bugzilla.kernel.org/show_bug.cgi?id=106941
+ * On these buggy platforms, the usage model of the ACPI
+ * lid device actually is:
+ * 1. The initial returning value of _LID may not be
+ * reliable.
+ * 2. The open event may not be reliable.
+ * 3. The close event is reliable.
+ *
+ * But SW_LID is typed as input switch event, the input
+ * layer checks if the event is redundant. Hence if the
+ * state is not switched, the userspace cannot see this
+ * platform triggered reliable event. By inserting a
+ * complement switch event, it then is guaranteed that the
+ * platform triggered reliable one can always be seen by
+ * the userspace.
+ */
+ if (lid_init_state == ACPI_BUTTON_LID_INIT_IGNORE) {
+ do_update = true;
+ /*
+ * Do generate complement switch event for "close"
+ * as "close" is reliable and wrong "open" won't
+ * trigger unexpected behaviors.
+ * Do not generate complement switch event for
+ * "open" as "open" is not reliable and wrong
+ * "close" will trigger unexpected behaviors.
+ */
+ if (!state) {
+ input_report_switch(button->input,
+ SW_LID, state);
+ input_sync(button->input);
+ }
+ }
+ }
+ /* Send the platform triggered reliable event */
+ if (do_update) {
+ input_report_switch(button->input, SW_LID, !state);
+ input_sync(button->input);
+ button->last_state = !!state;
+ button->last_time = ktime_get();
+ }
if (state)
pm_wakeup_event(&device->dev, 0);
@@ -411,6 +488,8 @@
strcpy(name, ACPI_BUTTON_DEVICE_NAME_LID);
sprintf(class, "%s/%s",
ACPI_BUTTON_CLASS, ACPI_BUTTON_SUBCLASS_LID);
+ button->last_state = !!acpi_lid_evaluate_state(device);
+ button->last_time = ktime_get();
} else {
printk(KERN_ERR PREFIX "Unsupported hid [%s]\n", hid);
error = -ENODEV;
diff --git a/drivers/acpi/cppc_acpi.c b/drivers/acpi/cppc_acpi.c
index 2e98173..d0d0504 100644
--- a/drivers/acpi/cppc_acpi.c
+++ b/drivers/acpi/cppc_acpi.c
@@ -40,15 +40,48 @@
#include <linux/cpufreq.h>
#include <linux/delay.h>
#include <linux/ktime.h>
+#include <linux/rwsem.h>
+#include <linux/wait.h>
#include <acpi/cppc_acpi.h>
-/*
- * Lock to provide mutually exclusive access to the PCC
- * channel. e.g. When the remote updates the shared region
- * with new data, the reader needs to be protected from
- * other CPUs activity on the same channel.
- */
-static DEFINE_SPINLOCK(pcc_lock);
+
+struct cppc_pcc_data {
+ struct mbox_chan *pcc_channel;
+ void __iomem *pcc_comm_addr;
+ int pcc_subspace_idx;
+ bool pcc_channel_acquired;
+ ktime_t deadline;
+ unsigned int pcc_mpar, pcc_mrtt, pcc_nominal;
+
+ bool pending_pcc_write_cmd; /* Any pending/batched PCC write cmds? */
+ bool platform_owns_pcc; /* Ownership of PCC subspace */
+ unsigned int pcc_write_cnt; /* Running count of PCC write commands */
+
+ /*
+ * Lock to provide controlled access to the PCC channel.
+ *
+ * For performance critical usecases(currently cppc_set_perf)
+ * We need to take read_lock and check if channel belongs to OSPM
+ * before reading or writing to PCC subspace
+ * We need to take write_lock before transferring the channel
+ * ownership to the platform via a Doorbell
+ * This allows us to batch a number of CPPC requests if they happen
+ * to originate in about the same time
+ *
+ * For non-performance critical usecases(init)
+ * Take write_lock for all purposes which gives exclusive access
+ */
+ struct rw_semaphore pcc_lock;
+
+ /* Wait queue for CPUs whose requests were batched */
+ wait_queue_head_t pcc_write_wait_q;
+};
+
+/* Structure to represent the single PCC channel */
+static struct cppc_pcc_data pcc_data = {
+ .pcc_subspace_idx = -1,
+ .platform_owns_pcc = true,
+};
/*
* The cpc_desc structure contains the ACPI register details
@@ -59,18 +92,25 @@
*/
static DEFINE_PER_CPU(struct cpc_desc *, cpc_desc_ptr);
-/* This layer handles all the PCC specifics for CPPC. */
-static struct mbox_chan *pcc_channel;
-static void __iomem *pcc_comm_addr;
-static u64 comm_base_addr;
-static int pcc_subspace_idx = -1;
-static bool pcc_channel_acquired;
-static ktime_t deadline;
-static unsigned int pcc_mpar, pcc_mrtt;
-
/* pcc mapped address + header size + offset within PCC subspace */
-#define GET_PCC_VADDR(offs) (pcc_comm_addr + 0x8 + (offs))
+#define GET_PCC_VADDR(offs) (pcc_data.pcc_comm_addr + 0x8 + (offs))
+/* Check if a CPC regsiter is in PCC */
+#define CPC_IN_PCC(cpc) ((cpc)->type == ACPI_TYPE_BUFFER && \
+ (cpc)->cpc_entry.reg.space_id == \
+ ACPI_ADR_SPACE_PLATFORM_COMM)
+
+/* Evalutes to True if reg is a NULL register descriptor */
+#define IS_NULL_REG(reg) ((reg)->space_id == ACPI_ADR_SPACE_SYSTEM_MEMORY && \
+ (reg)->address == 0 && \
+ (reg)->bit_width == 0 && \
+ (reg)->bit_offset == 0 && \
+ (reg)->access_width == 0)
+
+/* Evalutes to True if an optional cpc field is supported */
+#define CPC_SUPPORTED(cpc) ((cpc)->type == ACPI_TYPE_INTEGER ? \
+ !!(cpc)->cpc_entry.int_value : \
+ !IS_NULL_REG(&(cpc)->cpc_entry.reg))
/*
* Arbitrary Retries in case the remote processor is slow to respond
* to PCC commands. Keeping it high enough to cover emulators where
@@ -78,11 +118,79 @@
*/
#define NUM_RETRIES 500
-static int check_pcc_chan(void)
+struct cppc_attr {
+ struct attribute attr;
+ ssize_t (*show)(struct kobject *kobj,
+ struct attribute *attr, char *buf);
+ ssize_t (*store)(struct kobject *kobj,
+ struct attribute *attr, const char *c, ssize_t count);
+};
+
+#define define_one_cppc_ro(_name) \
+static struct cppc_attr _name = \
+__ATTR(_name, 0444, show_##_name, NULL)
+
+#define to_cpc_desc(a) container_of(a, struct cpc_desc, kobj)
+
+static ssize_t show_feedback_ctrs(struct kobject *kobj,
+ struct attribute *attr, char *buf)
{
- int ret = -EIO;
- struct acpi_pcct_shared_memory __iomem *generic_comm_base = pcc_comm_addr;
- ktime_t next_deadline = ktime_add(ktime_get(), deadline);
+ struct cpc_desc *cpc_ptr = to_cpc_desc(kobj);
+ struct cppc_perf_fb_ctrs fb_ctrs = {0};
+
+ cppc_get_perf_ctrs(cpc_ptr->cpu_id, &fb_ctrs);
+
+ return scnprintf(buf, PAGE_SIZE, "ref:%llu del:%llu\n",
+ fb_ctrs.reference, fb_ctrs.delivered);
+}
+define_one_cppc_ro(feedback_ctrs);
+
+static ssize_t show_reference_perf(struct kobject *kobj,
+ struct attribute *attr, char *buf)
+{
+ struct cpc_desc *cpc_ptr = to_cpc_desc(kobj);
+ struct cppc_perf_fb_ctrs fb_ctrs = {0};
+
+ cppc_get_perf_ctrs(cpc_ptr->cpu_id, &fb_ctrs);
+
+ return scnprintf(buf, PAGE_SIZE, "%llu\n",
+ fb_ctrs.reference_perf);
+}
+define_one_cppc_ro(reference_perf);
+
+static ssize_t show_wraparound_time(struct kobject *kobj,
+ struct attribute *attr, char *buf)
+{
+ struct cpc_desc *cpc_ptr = to_cpc_desc(kobj);
+ struct cppc_perf_fb_ctrs fb_ctrs = {0};
+
+ cppc_get_perf_ctrs(cpc_ptr->cpu_id, &fb_ctrs);
+
+ return scnprintf(buf, PAGE_SIZE, "%llu\n", fb_ctrs.ctr_wrap_time);
+
+}
+define_one_cppc_ro(wraparound_time);
+
+static struct attribute *cppc_attrs[] = {
+ &feedback_ctrs.attr,
+ &reference_perf.attr,
+ &wraparound_time.attr,
+ NULL
+};
+
+static struct kobj_type cppc_ktype = {
+ .sysfs_ops = &kobj_sysfs_ops,
+ .default_attrs = cppc_attrs,
+};
+
+static int check_pcc_chan(bool chk_err_bit)
+{
+ int ret = -EIO, status = 0;
+ struct acpi_pcct_shared_memory __iomem *generic_comm_base = pcc_data.pcc_comm_addr;
+ ktime_t next_deadline = ktime_add(ktime_get(), pcc_data.deadline);
+
+ if (!pcc_data.platform_owns_pcc)
+ return 0;
/* Retry in case the remote processor was too slow to catch up. */
while (!ktime_after(ktime_get(), next_deadline)) {
@@ -91,8 +199,11 @@
* platform and should have set the command completion bit when
* PCC can be used by OSPM
*/
- if (readw_relaxed(&generic_comm_base->status) & PCC_CMD_COMPLETE) {
+ status = readw_relaxed(&generic_comm_base->status);
+ if (status & PCC_CMD_COMPLETE_MASK) {
ret = 0;
+ if (chk_err_bit && (status & PCC_ERROR_MASK))
+ ret = -EIO;
break;
}
/*
@@ -102,14 +213,23 @@
udelay(3);
}
+ if (likely(!ret))
+ pcc_data.platform_owns_pcc = false;
+ else
+ pr_err("PCC check channel failed. Status=%x\n", status);
+
return ret;
}
+/*
+ * This function transfers the ownership of the PCC to the platform
+ * So it must be called while holding write_lock(pcc_lock)
+ */
static int send_pcc_cmd(u16 cmd)
{
- int ret = -EIO;
+ int ret = -EIO, i;
struct acpi_pcct_shared_memory *generic_comm_base =
- (struct acpi_pcct_shared_memory *) pcc_comm_addr;
+ (struct acpi_pcct_shared_memory *) pcc_data.pcc_comm_addr;
static ktime_t last_cmd_cmpl_time, last_mpar_reset;
static int mpar_count;
unsigned int time_delta;
@@ -119,20 +239,29 @@
* the channel before writing to PCC space
*/
if (cmd == CMD_READ) {
- ret = check_pcc_chan();
+ /*
+ * If there are pending cpc_writes, then we stole the channel
+ * before write completion, so first send a WRITE command to
+ * platform
+ */
+ if (pcc_data.pending_pcc_write_cmd)
+ send_pcc_cmd(CMD_WRITE);
+
+ ret = check_pcc_chan(false);
if (ret)
- return ret;
- }
+ goto end;
+ } else /* CMD_WRITE */
+ pcc_data.pending_pcc_write_cmd = FALSE;
/*
* Handle the Minimum Request Turnaround Time(MRTT)
* "The minimum amount of time that OSPM must wait after the completion
* of a command before issuing the next command, in microseconds"
*/
- if (pcc_mrtt) {
+ if (pcc_data.pcc_mrtt) {
time_delta = ktime_us_delta(ktime_get(), last_cmd_cmpl_time);
- if (pcc_mrtt > time_delta)
- udelay(pcc_mrtt - time_delta);
+ if (pcc_data.pcc_mrtt > time_delta)
+ udelay(pcc_data.pcc_mrtt - time_delta);
}
/*
@@ -146,15 +275,16 @@
* not send the request to the platform after hitting the MPAR limit in
* any 60s window
*/
- if (pcc_mpar) {
+ if (pcc_data.pcc_mpar) {
if (mpar_count == 0) {
time_delta = ktime_ms_delta(ktime_get(), last_mpar_reset);
if (time_delta < 60 * MSEC_PER_SEC) {
pr_debug("PCC cmd not sent due to MPAR limit");
- return -EIO;
+ ret = -EIO;
+ goto end;
}
last_mpar_reset = ktime_get();
- mpar_count = pcc_mpar;
+ mpar_count = pcc_data.pcc_mpar;
}
mpar_count--;
}
@@ -165,33 +295,43 @@
/* Flip CMD COMPLETE bit */
writew_relaxed(0, &generic_comm_base->status);
+ pcc_data.platform_owns_pcc = true;
+
/* Ring doorbell */
- ret = mbox_send_message(pcc_channel, &cmd);
+ ret = mbox_send_message(pcc_data.pcc_channel, &cmd);
if (ret < 0) {
pr_err("Err sending PCC mbox message. cmd:%d, ret:%d\n",
cmd, ret);
- return ret;
+ goto end;
}
- /*
- * For READs we need to ensure the cmd completed to ensure
- * the ensuing read()s can proceed. For WRITEs we dont care
- * because the actual write()s are done before coming here
- * and the next READ or WRITE will check if the channel
- * is busy/free at the entry of this call.
- *
- * If Minimum Request Turnaround Time is non-zero, we need
- * to record the completion time of both READ and WRITE
- * command for proper handling of MRTT, so we need to check
- * for pcc_mrtt in addition to CMD_READ
- */
- if (cmd == CMD_READ || pcc_mrtt) {
- ret = check_pcc_chan();
- if (pcc_mrtt)
- last_cmd_cmpl_time = ktime_get();
+ /* wait for completion and check for PCC errro bit */
+ ret = check_pcc_chan(true);
+
+ if (pcc_data.pcc_mrtt)
+ last_cmd_cmpl_time = ktime_get();
+
+ if (pcc_data.pcc_channel->mbox->txdone_irq)
+ mbox_chan_txdone(pcc_data.pcc_channel, ret);
+ else
+ mbox_client_txdone(pcc_data.pcc_channel, ret);
+
+end:
+ if (cmd == CMD_WRITE) {
+ if (unlikely(ret)) {
+ for_each_possible_cpu(i) {
+ struct cpc_desc *desc = per_cpu(cpc_desc_ptr, i);
+ if (!desc)
+ continue;
+
+ if (desc->write_cmd_id == pcc_data.pcc_write_cnt)
+ desc->write_cmd_status = ret;
+ }
+ }
+ pcc_data.pcc_write_cnt++;
+ wake_up_all(&pcc_data.pcc_write_wait_q);
}
- mbox_client_txdone(pcc_channel, ret);
return ret;
}
@@ -272,13 +412,13 @@
*
* Return: 0 for success or negative value for err.
*/
-int acpi_get_psd_map(struct cpudata **all_cpu_data)
+int acpi_get_psd_map(struct cppc_cpudata **all_cpu_data)
{
int count_target;
int retval = 0;
unsigned int i, j;
cpumask_var_t covered_cpus;
- struct cpudata *pr, *match_pr;
+ struct cppc_cpudata *pr, *match_pr;
struct acpi_psd_package *pdomain;
struct acpi_psd_package *match_pdomain;
struct cpc_desc *cpc_ptr, *match_cpc_ptr;
@@ -394,14 +534,13 @@
static int register_pcc_channel(int pcc_subspace_idx)
{
struct acpi_pcct_hw_reduced *cppc_ss;
- unsigned int len;
u64 usecs_lat;
if (pcc_subspace_idx >= 0) {
- pcc_channel = pcc_mbox_request_channel(&cppc_mbox_cl,
+ pcc_data.pcc_channel = pcc_mbox_request_channel(&cppc_mbox_cl,
pcc_subspace_idx);
- if (IS_ERR(pcc_channel)) {
+ if (IS_ERR(pcc_data.pcc_channel)) {
pr_err("Failed to find PCC communication channel\n");
return -ENODEV;
}
@@ -412,7 +551,7 @@
* PCC channels) and stored pointers to the
* subspace communication region in con_priv.
*/
- cppc_ss = pcc_channel->con_priv;
+ cppc_ss = (pcc_data.pcc_channel)->con_priv;
if (!cppc_ss) {
pr_err("No PCC subspace found for CPPC\n");
@@ -420,35 +559,42 @@
}
/*
- * This is the shared communication region
- * for the OS and Platform to communicate over.
- */
- comm_base_addr = cppc_ss->base_address;
- len = cppc_ss->length;
-
- /*
* cppc_ss->latency is just a Nominal value. In reality
* the remote processor could be much slower to reply.
* So add an arbitrary amount of wait on top of Nominal.
*/
usecs_lat = NUM_RETRIES * cppc_ss->latency;
- deadline = ns_to_ktime(usecs_lat * NSEC_PER_USEC);
- pcc_mrtt = cppc_ss->min_turnaround_time;
- pcc_mpar = cppc_ss->max_access_rate;
+ pcc_data.deadline = ns_to_ktime(usecs_lat * NSEC_PER_USEC);
+ pcc_data.pcc_mrtt = cppc_ss->min_turnaround_time;
+ pcc_data.pcc_mpar = cppc_ss->max_access_rate;
+ pcc_data.pcc_nominal = cppc_ss->latency;
- pcc_comm_addr = acpi_os_ioremap(comm_base_addr, len);
- if (!pcc_comm_addr) {
+ pcc_data.pcc_comm_addr = acpi_os_ioremap(cppc_ss->base_address, cppc_ss->length);
+ if (!pcc_data.pcc_comm_addr) {
pr_err("Failed to ioremap PCC comm region mem\n");
return -ENOMEM;
}
/* Set flag so that we dont come here for each CPU. */
- pcc_channel_acquired = true;
+ pcc_data.pcc_channel_acquired = true;
}
return 0;
}
+/**
+ * cpc_ffh_supported() - check if FFH reading supported
+ *
+ * Check if the architecture has support for functional fixed hardware
+ * read/write capability.
+ *
+ * Return: true for supported, false for not supported
+ */
+bool __weak cpc_ffh_supported(void)
+{
+ return false;
+}
+
/*
* An example CPC table looks like the following.
*
@@ -507,6 +653,7 @@
union acpi_object *out_obj, *cpc_obj;
struct cpc_desc *cpc_ptr;
struct cpc_reg *gas_t;
+ struct device *cpu_dev;
acpi_handle handle = pr->handle;
unsigned int num_ent, i, cpc_rev;
acpi_status status;
@@ -545,6 +692,8 @@
goto out_free;
}
+ cpc_ptr->num_entries = num_ent;
+
/* Second entry should be revision. */
cpc_obj = &out_obj->package.elements[1];
if (cpc_obj->type == ACPI_TYPE_INTEGER) {
@@ -579,16 +728,27 @@
* so extract it only once.
*/
if (gas_t->space_id == ACPI_ADR_SPACE_PLATFORM_COMM) {
- if (pcc_subspace_idx < 0)
- pcc_subspace_idx = gas_t->access_width;
- else if (pcc_subspace_idx != gas_t->access_width) {
+ if (pcc_data.pcc_subspace_idx < 0)
+ pcc_data.pcc_subspace_idx = gas_t->access_width;
+ else if (pcc_data.pcc_subspace_idx != gas_t->access_width) {
pr_debug("Mismatched PCC ids.\n");
goto out_free;
}
- } else if (gas_t->space_id != ACPI_ADR_SPACE_SYSTEM_MEMORY) {
- /* Support only PCC and SYS MEM type regs */
- pr_debug("Unsupported register type: %d\n", gas_t->space_id);
- goto out_free;
+ } else if (gas_t->space_id == ACPI_ADR_SPACE_SYSTEM_MEMORY) {
+ if (gas_t->address) {
+ void __iomem *addr;
+
+ addr = ioremap(gas_t->address, gas_t->bit_width/8);
+ if (!addr)
+ goto out_free;
+ cpc_ptr->cpc_regs[i-2].sys_mem_vaddr = addr;
+ }
+ } else {
+ if (gas_t->space_id != ACPI_ADR_SPACE_FIXED_HARDWARE || !cpc_ffh_supported()) {
+ /* Support only PCC ,SYS MEM and FFH type regs */
+ pr_debug("Unsupported register type: %d\n", gas_t->space_id);
+ goto out_free;
+ }
}
cpc_ptr->cpc_regs[i-2].type = ACPI_TYPE_BUFFER;
@@ -607,10 +767,13 @@
goto out_free;
/* Register PCC channel once for all CPUs. */
- if (!pcc_channel_acquired) {
- ret = register_pcc_channel(pcc_subspace_idx);
+ if (!pcc_data.pcc_channel_acquired) {
+ ret = register_pcc_channel(pcc_data.pcc_subspace_idx);
if (ret)
goto out_free;
+
+ init_rwsem(&pcc_data.pcc_lock);
+ init_waitqueue_head(&pcc_data.pcc_write_wait_q);
}
/* Plug PSD data into this CPUs CPC descriptor. */
@@ -619,10 +782,27 @@
/* Everything looks okay */
pr_debug("Parsed CPC struct for CPU: %d\n", pr->id);
+ /* Add per logical CPU nodes for reading its feedback counters. */
+ cpu_dev = get_cpu_device(pr->id);
+ if (!cpu_dev)
+ goto out_free;
+
+ ret = kobject_init_and_add(&cpc_ptr->kobj, &cppc_ktype, &cpu_dev->kobj,
+ "acpi_cppc");
+ if (ret)
+ goto out_free;
+
kfree(output.pointer);
return 0;
out_free:
+ /* Free all the mapped sys mem areas for this CPU */
+ for (i = 2; i < cpc_ptr->num_entries; i++) {
+ void __iomem *addr = cpc_ptr->cpc_regs[i-2].sys_mem_vaddr;
+
+ if (addr)
+ iounmap(addr);
+ }
kfree(cpc_ptr);
out_buf_free:
@@ -640,26 +820,82 @@
void acpi_cppc_processor_exit(struct acpi_processor *pr)
{
struct cpc_desc *cpc_ptr;
+ unsigned int i;
+ void __iomem *addr;
+
cpc_ptr = per_cpu(cpc_desc_ptr, pr->id);
+
+ /* Free all the mapped sys mem areas for this CPU */
+ for (i = 2; i < cpc_ptr->num_entries; i++) {
+ addr = cpc_ptr->cpc_regs[i-2].sys_mem_vaddr;
+ if (addr)
+ iounmap(addr);
+ }
+
+ kobject_put(&cpc_ptr->kobj);
kfree(cpc_ptr);
}
EXPORT_SYMBOL_GPL(acpi_cppc_processor_exit);
+/**
+ * cpc_read_ffh() - Read FFH register
+ * @cpunum: cpu number to read
+ * @reg: cppc register information
+ * @val: place holder for return value
+ *
+ * Read bit_width bits from a specified address and bit_offset
+ *
+ * Return: 0 for success and error code
+ */
+int __weak cpc_read_ffh(int cpunum, struct cpc_reg *reg, u64 *val)
+{
+ return -ENOTSUPP;
+}
+
+/**
+ * cpc_write_ffh() - Write FFH register
+ * @cpunum: cpu number to write
+ * @reg: cppc register information
+ * @val: value to write
+ *
+ * Write value of bit_width bits to a specified address and bit_offset
+ *
+ * Return: 0 for success and error code
+ */
+int __weak cpc_write_ffh(int cpunum, struct cpc_reg *reg, u64 val)
+{
+ return -ENOTSUPP;
+}
+
/*
* Since cpc_read and cpc_write are called while holding pcc_lock, it should be
* as fast as possible. We have already mapped the PCC subspace during init, so
* we can directly write to it.
*/
-static int cpc_read(struct cpc_reg *reg, u64 *val)
+static int cpc_read(int cpu, struct cpc_register_resource *reg_res, u64 *val)
{
int ret_val = 0;
+ void __iomem *vaddr = 0;
+ struct cpc_reg *reg = ®_res->cpc_entry.reg;
+
+ if (reg_res->type == ACPI_TYPE_INTEGER) {
+ *val = reg_res->cpc_entry.int_value;
+ return ret_val;
+ }
*val = 0;
- if (reg->space_id == ACPI_ADR_SPACE_PLATFORM_COMM) {
- void __iomem *vaddr = GET_PCC_VADDR(reg->address);
+ if (reg->space_id == ACPI_ADR_SPACE_PLATFORM_COMM)
+ vaddr = GET_PCC_VADDR(reg->address);
+ else if (reg->space_id == ACPI_ADR_SPACE_SYSTEM_MEMORY)
+ vaddr = reg_res->sys_mem_vaddr;
+ else if (reg->space_id == ACPI_ADR_SPACE_FIXED_HARDWARE)
+ return cpc_read_ffh(cpu, reg, val);
+ else
+ return acpi_os_read_memory((acpi_physical_address)reg->address,
+ val, reg->bit_width);
- switch (reg->bit_width) {
+ switch (reg->bit_width) {
case 8:
*val = readb_relaxed(vaddr);
break;
@@ -674,23 +910,30 @@
break;
default:
pr_debug("Error: Cannot read %u bit width from PCC\n",
- reg->bit_width);
+ reg->bit_width);
ret_val = -EFAULT;
- }
- } else
- ret_val = acpi_os_read_memory((acpi_physical_address)reg->address,
- val, reg->bit_width);
+ }
+
return ret_val;
}
-static int cpc_write(struct cpc_reg *reg, u64 val)
+static int cpc_write(int cpu, struct cpc_register_resource *reg_res, u64 val)
{
int ret_val = 0;
+ void __iomem *vaddr = 0;
+ struct cpc_reg *reg = ®_res->cpc_entry.reg;
- if (reg->space_id == ACPI_ADR_SPACE_PLATFORM_COMM) {
- void __iomem *vaddr = GET_PCC_VADDR(reg->address);
+ if (reg->space_id == ACPI_ADR_SPACE_PLATFORM_COMM)
+ vaddr = GET_PCC_VADDR(reg->address);
+ else if (reg->space_id == ACPI_ADR_SPACE_SYSTEM_MEMORY)
+ vaddr = reg_res->sys_mem_vaddr;
+ else if (reg->space_id == ACPI_ADR_SPACE_FIXED_HARDWARE)
+ return cpc_write_ffh(cpu, reg, val);
+ else
+ return acpi_os_write_memory((acpi_physical_address)reg->address,
+ val, reg->bit_width);
- switch (reg->bit_width) {
+ switch (reg->bit_width) {
case 8:
writeb_relaxed(val, vaddr);
break;
@@ -705,13 +948,11 @@
break;
default:
pr_debug("Error: Cannot write %u bit width to PCC\n",
- reg->bit_width);
+ reg->bit_width);
ret_val = -EFAULT;
break;
- }
- } else
- ret_val = acpi_os_write_memory((acpi_physical_address)reg->address,
- val, reg->bit_width);
+ }
+
return ret_val;
}
@@ -727,8 +968,8 @@
struct cpc_desc *cpc_desc = per_cpu(cpc_desc_ptr, cpunum);
struct cpc_register_resource *highest_reg, *lowest_reg, *ref_perf,
*nom_perf;
- u64 high, low, ref, nom;
- int ret = 0;
+ u64 high, low, nom;
+ int ret = 0, regs_in_pcc = 0;
if (!cpc_desc) {
pr_debug("No CPC descriptor for CPU:%d\n", cpunum);
@@ -740,13 +981,11 @@
ref_perf = &cpc_desc->cpc_regs[REFERENCE_PERF];
nom_perf = &cpc_desc->cpc_regs[NOMINAL_PERF];
- spin_lock(&pcc_lock);
-
/* Are any of the regs PCC ?*/
- if ((highest_reg->cpc_entry.reg.space_id == ACPI_ADR_SPACE_PLATFORM_COMM) ||
- (lowest_reg->cpc_entry.reg.space_id == ACPI_ADR_SPACE_PLATFORM_COMM) ||
- (ref_perf->cpc_entry.reg.space_id == ACPI_ADR_SPACE_PLATFORM_COMM) ||
- (nom_perf->cpc_entry.reg.space_id == ACPI_ADR_SPACE_PLATFORM_COMM)) {
+ if (CPC_IN_PCC(highest_reg) || CPC_IN_PCC(lowest_reg) ||
+ CPC_IN_PCC(ref_perf) || CPC_IN_PCC(nom_perf)) {
+ regs_in_pcc = 1;
+ down_write(&pcc_data.pcc_lock);
/* Ring doorbell once to update PCC subspace */
if (send_pcc_cmd(CMD_READ) < 0) {
ret = -EIO;
@@ -754,26 +993,21 @@
}
}
- cpc_read(&highest_reg->cpc_entry.reg, &high);
+ cpc_read(cpunum, highest_reg, &high);
perf_caps->highest_perf = high;
- cpc_read(&lowest_reg->cpc_entry.reg, &low);
+ cpc_read(cpunum, lowest_reg, &low);
perf_caps->lowest_perf = low;
- cpc_read(&ref_perf->cpc_entry.reg, &ref);
- perf_caps->reference_perf = ref;
-
- cpc_read(&nom_perf->cpc_entry.reg, &nom);
+ cpc_read(cpunum, nom_perf, &nom);
perf_caps->nominal_perf = nom;
- if (!ref)
- perf_caps->reference_perf = perf_caps->nominal_perf;
-
if (!high || !low || !nom)
ret = -EFAULT;
out_err:
- spin_unlock(&pcc_lock);
+ if (regs_in_pcc)
+ up_write(&pcc_data.pcc_lock);
return ret;
}
EXPORT_SYMBOL_GPL(cppc_get_perf_caps);
@@ -788,9 +1022,10 @@
int cppc_get_perf_ctrs(int cpunum, struct cppc_perf_fb_ctrs *perf_fb_ctrs)
{
struct cpc_desc *cpc_desc = per_cpu(cpc_desc_ptr, cpunum);
- struct cpc_register_resource *delivered_reg, *reference_reg;
- u64 delivered, reference;
- int ret = 0;
+ struct cpc_register_resource *delivered_reg, *reference_reg,
+ *ref_perf_reg, *ctr_wrap_reg;
+ u64 delivered, reference, ref_perf, ctr_wrap_time;
+ int ret = 0, regs_in_pcc = 0;
if (!cpc_desc) {
pr_debug("No CPC descriptor for CPU:%d\n", cpunum);
@@ -799,12 +1034,21 @@
delivered_reg = &cpc_desc->cpc_regs[DELIVERED_CTR];
reference_reg = &cpc_desc->cpc_regs[REFERENCE_CTR];
+ ref_perf_reg = &cpc_desc->cpc_regs[REFERENCE_PERF];
+ ctr_wrap_reg = &cpc_desc->cpc_regs[CTR_WRAP_TIME];
- spin_lock(&pcc_lock);
+ /*
+ * If refernce perf register is not supported then we should
+ * use the nominal perf value
+ */
+ if (!CPC_SUPPORTED(ref_perf_reg))
+ ref_perf_reg = &cpc_desc->cpc_regs[NOMINAL_PERF];
/* Are any of the regs PCC ?*/
- if ((delivered_reg->cpc_entry.reg.space_id == ACPI_ADR_SPACE_PLATFORM_COMM) ||
- (reference_reg->cpc_entry.reg.space_id == ACPI_ADR_SPACE_PLATFORM_COMM)) {
+ if (CPC_IN_PCC(delivered_reg) || CPC_IN_PCC(reference_reg) ||
+ CPC_IN_PCC(ctr_wrap_reg) || CPC_IN_PCC(ref_perf_reg)) {
+ down_write(&pcc_data.pcc_lock);
+ regs_in_pcc = 1;
/* Ring doorbell once to update PCC subspace */
if (send_pcc_cmd(CMD_READ) < 0) {
ret = -EIO;
@@ -812,25 +1056,31 @@
}
}
- cpc_read(&delivered_reg->cpc_entry.reg, &delivered);
- cpc_read(&reference_reg->cpc_entry.reg, &reference);
+ cpc_read(cpunum, delivered_reg, &delivered);
+ cpc_read(cpunum, reference_reg, &reference);
+ cpc_read(cpunum, ref_perf_reg, &ref_perf);
- if (!delivered || !reference) {
+ /*
+ * Per spec, if ctr_wrap_time optional register is unsupported, then the
+ * performance counters are assumed to never wrap during the lifetime of
+ * platform
+ */
+ ctr_wrap_time = (u64)(~((u64)0));
+ if (CPC_SUPPORTED(ctr_wrap_reg))
+ cpc_read(cpunum, ctr_wrap_reg, &ctr_wrap_time);
+
+ if (!delivered || !reference || !ref_perf) {
ret = -EFAULT;
goto out_err;
}
perf_fb_ctrs->delivered = delivered;
perf_fb_ctrs->reference = reference;
-
- perf_fb_ctrs->delivered -= perf_fb_ctrs->prev_delivered;
- perf_fb_ctrs->reference -= perf_fb_ctrs->prev_reference;
-
- perf_fb_ctrs->prev_delivered = delivered;
- perf_fb_ctrs->prev_reference = reference;
-
+ perf_fb_ctrs->reference_perf = ref_perf;
+ perf_fb_ctrs->ctr_wrap_time = ctr_wrap_time;
out_err:
- spin_unlock(&pcc_lock);
+ if (regs_in_pcc)
+ up_write(&pcc_data.pcc_lock);
return ret;
}
EXPORT_SYMBOL_GPL(cppc_get_perf_ctrs);
@@ -855,30 +1105,142 @@
desired_reg = &cpc_desc->cpc_regs[DESIRED_PERF];
- spin_lock(&pcc_lock);
-
- /* If this is PCC reg, check if channel is free before writing */
- if (desired_reg->cpc_entry.reg.space_id == ACPI_ADR_SPACE_PLATFORM_COMM) {
- ret = check_pcc_chan();
- if (ret)
- goto busy_channel;
+ /*
+ * This is Phase-I where we want to write to CPC registers
+ * -> We want all CPUs to be able to execute this phase in parallel
+ *
+ * Since read_lock can be acquired by multiple CPUs simultaneously we
+ * achieve that goal here
+ */
+ if (CPC_IN_PCC(desired_reg)) {
+ down_read(&pcc_data.pcc_lock); /* BEGIN Phase-I */
+ if (pcc_data.platform_owns_pcc) {
+ ret = check_pcc_chan(false);
+ if (ret) {
+ up_read(&pcc_data.pcc_lock);
+ return ret;
+ }
+ }
+ /*
+ * Update the pending_write to make sure a PCC CMD_READ will not
+ * arrive and steal the channel during the switch to write lock
+ */
+ pcc_data.pending_pcc_write_cmd = true;
+ cpc_desc->write_cmd_id = pcc_data.pcc_write_cnt;
+ cpc_desc->write_cmd_status = 0;
}
/*
* Skip writing MIN/MAX until Linux knows how to come up with
* useful values.
*/
- cpc_write(&desired_reg->cpc_entry.reg, perf_ctrls->desired_perf);
+ cpc_write(cpu, desired_reg, perf_ctrls->desired_perf);
- /* Is this a PCC reg ?*/
- if (desired_reg->cpc_entry.reg.space_id == ACPI_ADR_SPACE_PLATFORM_COMM) {
- /* Ring doorbell so Remote can get our perf request. */
- if (send_pcc_cmd(CMD_WRITE) < 0)
- ret = -EIO;
+ if (CPC_IN_PCC(desired_reg))
+ up_read(&pcc_data.pcc_lock); /* END Phase-I */
+ /*
+ * This is Phase-II where we transfer the ownership of PCC to Platform
+ *
+ * Short Summary: Basically if we think of a group of cppc_set_perf
+ * requests that happened in short overlapping interval. The last CPU to
+ * come out of Phase-I will enter Phase-II and ring the doorbell.
+ *
+ * We have the following requirements for Phase-II:
+ * 1. We want to execute Phase-II only when there are no CPUs
+ * currently executing in Phase-I
+ * 2. Once we start Phase-II we want to avoid all other CPUs from
+ * entering Phase-I.
+ * 3. We want only one CPU among all those who went through Phase-I
+ * to run phase-II
+ *
+ * If write_trylock fails to get the lock and doesn't transfer the
+ * PCC ownership to the platform, then one of the following will be TRUE
+ * 1. There is at-least one CPU in Phase-I which will later execute
+ * write_trylock, so the CPUs in Phase-I will be responsible for
+ * executing the Phase-II.
+ * 2. Some other CPU has beaten this CPU to successfully execute the
+ * write_trylock and has already acquired the write_lock. We know for a
+ * fact it(other CPU acquiring the write_lock) couldn't have happened
+ * before this CPU's Phase-I as we held the read_lock.
+ * 3. Some other CPU executing pcc CMD_READ has stolen the
+ * down_write, in which case, send_pcc_cmd will check for pending
+ * CMD_WRITE commands by checking the pending_pcc_write_cmd.
+ * So this CPU can be certain that its request will be delivered
+ * So in all cases, this CPU knows that its request will be delivered
+ * by another CPU and can return
+ *
+ * After getting the down_write we still need to check for
+ * pending_pcc_write_cmd to take care of the following scenario
+ * The thread running this code could be scheduled out between
+ * Phase-I and Phase-II. Before it is scheduled back on, another CPU
+ * could have delivered the request to Platform by triggering the
+ * doorbell and transferred the ownership of PCC to platform. So this
+ * avoids triggering an unnecessary doorbell and more importantly before
+ * triggering the doorbell it makes sure that the PCC channel ownership
+ * is still with OSPM.
+ * pending_pcc_write_cmd can also be cleared by a different CPU, if
+ * there was a pcc CMD_READ waiting on down_write and it steals the lock
+ * before the pcc CMD_WRITE is completed. pcc_send_cmd checks for this
+ * case during a CMD_READ and if there are pending writes it delivers
+ * the write command before servicing the read command
+ */
+ if (CPC_IN_PCC(desired_reg)) {
+ if (down_write_trylock(&pcc_data.pcc_lock)) { /* BEGIN Phase-II */
+ /* Update only if there are pending write commands */
+ if (pcc_data.pending_pcc_write_cmd)
+ send_pcc_cmd(CMD_WRITE);
+ up_write(&pcc_data.pcc_lock); /* END Phase-II */
+ } else
+ /* Wait until pcc_write_cnt is updated by send_pcc_cmd */
+ wait_event(pcc_data.pcc_write_wait_q,
+ cpc_desc->write_cmd_id != pcc_data.pcc_write_cnt);
+
+ /* send_pcc_cmd updates the status in case of failure */
+ ret = cpc_desc->write_cmd_status;
}
-busy_channel:
- spin_unlock(&pcc_lock);
-
return ret;
}
EXPORT_SYMBOL_GPL(cppc_set_perf);
+
+/**
+ * cppc_get_transition_latency - returns frequency transition latency in ns
+ *
+ * ACPI CPPC does not explicitly specifiy how a platform can specify the
+ * transition latency for perfromance change requests. The closest we have
+ * is the timing information from the PCCT tables which provides the info
+ * on the number and frequency of PCC commands the platform can handle.
+ */
+unsigned int cppc_get_transition_latency(int cpu_num)
+{
+ /*
+ * Expected transition latency is based on the PCCT timing values
+ * Below are definition from ACPI spec:
+ * pcc_nominal- Expected latency to process a command, in microseconds
+ * pcc_mpar - The maximum number of periodic requests that the subspace
+ * channel can support, reported in commands per minute. 0
+ * indicates no limitation.
+ * pcc_mrtt - The minimum amount of time that OSPM must wait after the
+ * completion of a command before issuing the next command,
+ * in microseconds.
+ */
+ unsigned int latency_ns = 0;
+ struct cpc_desc *cpc_desc;
+ struct cpc_register_resource *desired_reg;
+
+ cpc_desc = per_cpu(cpc_desc_ptr, cpu_num);
+ if (!cpc_desc)
+ return CPUFREQ_ETERNAL;
+
+ desired_reg = &cpc_desc->cpc_regs[DESIRED_PERF];
+ if (!CPC_IN_PCC(desired_reg))
+ return CPUFREQ_ETERNAL;
+
+ if (pcc_data.pcc_mpar)
+ latency_ns = 60 * (1000 * 1000 * 1000 / pcc_data.pcc_mpar);
+
+ latency_ns = max(latency_ns, pcc_data.pcc_nominal * 1000);
+ latency_ns = max(latency_ns, pcc_data.pcc_mrtt * 1000);
+
+ return latency_ns;
+}
+EXPORT_SYMBOL_GPL(cppc_get_transition_latency);
diff --git a/drivers/acpi/ec.c b/drivers/acpi/ec.c
index e7bd57c..6805310 100644
--- a/drivers/acpi/ec.c
+++ b/drivers/acpi/ec.c
@@ -104,10 +104,12 @@
#define ACPI_EC_MAX_QUERIES 16 /* Maximum number of parallel queries */
enum {
+ EC_FLAGS_QUERY_ENABLED, /* Query is enabled */
EC_FLAGS_QUERY_PENDING, /* Query is pending */
EC_FLAGS_QUERY_GUARDING, /* Guard for SCI_EVT check */
EC_FLAGS_GPE_HANDLER_INSTALLED, /* GPE handler installed */
EC_FLAGS_EC_HANDLER_INSTALLED, /* OpReg handler installed */
+ EC_FLAGS_EVT_HANDLER_INSTALLED, /* _Qxx handlers installed */
EC_FLAGS_STARTED, /* Driver is started */
EC_FLAGS_STOPPED, /* Driver is stopped */
EC_FLAGS_COMMAND_STORM, /* GPE storms occurred to the
@@ -145,6 +147,10 @@
module_param(ec_storm_threshold, uint, 0644);
MODULE_PARM_DESC(ec_storm_threshold, "Maxim false GPE numbers not considered as GPE storm");
+static bool ec_freeze_events __read_mostly = true;
+module_param(ec_freeze_events, bool, 0644);
+MODULE_PARM_DESC(ec_freeze_events, "Disabling event handling during suspend/resume");
+
struct acpi_ec_query_handler {
struct list_head node;
acpi_ec_query_func func;
@@ -179,6 +185,7 @@
struct acpi_ec *boot_ec, *first_ec;
EXPORT_SYMBOL(first_ec);
+static bool boot_ec_is_ecdt = false;
static struct workqueue_struct *ec_query_wq;
static int EC_FLAGS_CLEAR_ON_RESUME; /* Needs acpi_ec_clear() on boot/resume */
@@ -239,6 +246,30 @@
!test_bit(EC_FLAGS_STOPPED, &ec->flags);
}
+static bool acpi_ec_event_enabled(struct acpi_ec *ec)
+{
+ /*
+ * There is an OSPM early stage logic. During the early stages
+ * (boot/resume), OSPMs shouldn't enable the event handling, only
+ * the EC transactions are allowed to be performed.
+ */
+ if (!test_bit(EC_FLAGS_QUERY_ENABLED, &ec->flags))
+ return false;
+ /*
+ * However, disabling the event handling is experimental for late
+ * stage (suspend), and is controlled by the boot parameter of
+ * "ec_freeze_events":
+ * 1. true: The EC event handling is disabled before entering
+ * the noirq stage.
+ * 2. false: The EC event handling is automatically disabled as
+ * soon as the EC driver is stopped.
+ */
+ if (ec_freeze_events)
+ return acpi_ec_started(ec);
+ else
+ return test_bit(EC_FLAGS_STARTED, &ec->flags);
+}
+
static bool acpi_ec_flushed(struct acpi_ec *ec)
{
return ec->reference_count == 1;
@@ -429,7 +460,8 @@
static void acpi_ec_submit_query(struct acpi_ec *ec)
{
- if (!test_and_set_bit(EC_FLAGS_QUERY_PENDING, &ec->flags)) {
+ if (acpi_ec_event_enabled(ec) &&
+ !test_and_set_bit(EC_FLAGS_QUERY_PENDING, &ec->flags)) {
ec_dbg_evt("Command(%s) submitted/blocked",
acpi_ec_cmd_string(ACPI_EC_COMMAND_QUERY));
ec->nr_pending_queries++;
@@ -446,6 +478,86 @@
}
}
+static inline void __acpi_ec_enable_event(struct acpi_ec *ec)
+{
+ if (!test_and_set_bit(EC_FLAGS_QUERY_ENABLED, &ec->flags))
+ ec_log_drv("event unblocked");
+ if (!test_bit(EC_FLAGS_QUERY_PENDING, &ec->flags))
+ advance_transaction(ec);
+}
+
+static inline void __acpi_ec_disable_event(struct acpi_ec *ec)
+{
+ if (test_and_clear_bit(EC_FLAGS_QUERY_ENABLED, &ec->flags))
+ ec_log_drv("event blocked");
+}
+
+/*
+ * Process _Q events that might have accumulated in the EC.
+ * Run with locked ec mutex.
+ */
+static void acpi_ec_clear(struct acpi_ec *ec)
+{
+ int i, status;
+ u8 value = 0;
+
+ for (i = 0; i < ACPI_EC_CLEAR_MAX; i++) {
+ status = acpi_ec_query(ec, &value);
+ if (status || !value)
+ break;
+ }
+ if (unlikely(i == ACPI_EC_CLEAR_MAX))
+ pr_warn("Warning: Maximum of %d stale EC events cleared\n", i);
+ else
+ pr_info("%d stale EC events cleared\n", i);
+}
+
+static void acpi_ec_enable_event(struct acpi_ec *ec)
+{
+ unsigned long flags;
+
+ spin_lock_irqsave(&ec->lock, flags);
+ if (acpi_ec_started(ec))
+ __acpi_ec_enable_event(ec);
+ spin_unlock_irqrestore(&ec->lock, flags);
+
+ /* Drain additional events if hardware requires that */
+ if (EC_FLAGS_CLEAR_ON_RESUME)
+ acpi_ec_clear(ec);
+}
+
+static bool acpi_ec_query_flushed(struct acpi_ec *ec)
+{
+ bool flushed;
+ unsigned long flags;
+
+ spin_lock_irqsave(&ec->lock, flags);
+ flushed = !ec->nr_pending_queries;
+ spin_unlock_irqrestore(&ec->lock, flags);
+ return flushed;
+}
+
+static void __acpi_ec_flush_event(struct acpi_ec *ec)
+{
+ /*
+ * When ec_freeze_events is true, we need to flush events in
+ * the proper position before entering the noirq stage.
+ */
+ wait_event(ec->wait, acpi_ec_query_flushed(ec));
+ if (ec_query_wq)
+ flush_workqueue(ec_query_wq);
+}
+
+static void acpi_ec_disable_event(struct acpi_ec *ec)
+{
+ unsigned long flags;
+
+ spin_lock_irqsave(&ec->lock, flags);
+ __acpi_ec_disable_event(ec);
+ spin_unlock_irqrestore(&ec->lock, flags);
+ __acpi_ec_flush_event(ec);
+}
+
static bool acpi_ec_guard_event(struct acpi_ec *ec)
{
bool guarded = true;
@@ -832,27 +944,6 @@
}
EXPORT_SYMBOL(ec_get_handle);
-/*
- * Process _Q events that might have accumulated in the EC.
- * Run with locked ec mutex.
- */
-static void acpi_ec_clear(struct acpi_ec *ec)
-{
- int i, status;
- u8 value = 0;
-
- for (i = 0; i < ACPI_EC_CLEAR_MAX; i++) {
- status = acpi_ec_query(ec, &value);
- if (status || !value)
- break;
- }
-
- if (unlikely(i == ACPI_EC_CLEAR_MAX))
- pr_warn("Warning: Maximum of %d stale EC events cleared\n", i);
- else
- pr_info("%d stale EC events cleared\n", i);
-}
-
static void acpi_ec_start(struct acpi_ec *ec, bool resuming)
{
unsigned long flags;
@@ -896,7 +987,8 @@
if (!suspending) {
acpi_ec_complete_request(ec);
ec_dbg_ref(ec, "Decrease driver");
- }
+ } else if (!ec_freeze_events)
+ __acpi_ec_disable_event(ec);
clear_bit(EC_FLAGS_STARTED, &ec->flags);
clear_bit(EC_FLAGS_STOPPED, &ec->flags);
ec_log_drv("EC stopped");
@@ -919,20 +1011,6 @@
void acpi_ec_unblock_transactions(void)
{
- struct acpi_ec *ec = first_ec;
-
- if (!ec)
- return;
-
- /* Allow transactions to be carried out again */
- acpi_ec_start(ec, true);
-
- if (EC_FLAGS_CLEAR_ON_RESUME)
- acpi_ec_clear(ec);
-}
-
-void acpi_ec_unblock_transactions_early(void)
-{
/*
* Allow transactions to happen again (this function is called from
* atomic context during wakeup, so we don't need to acquire the mutex).
@@ -1228,13 +1306,21 @@
static acpi_status
ec_parse_io_ports(struct acpi_resource *resource, void *context);
-static struct acpi_ec *make_acpi_ec(void)
+static void acpi_ec_free(struct acpi_ec *ec)
+{
+ if (first_ec == ec)
+ first_ec = NULL;
+ if (boot_ec == ec)
+ boot_ec = NULL;
+ kfree(ec);
+}
+
+static struct acpi_ec *acpi_ec_alloc(void)
{
struct acpi_ec *ec = kzalloc(sizeof(struct acpi_ec), GFP_KERNEL);
if (!ec)
return NULL;
- ec->flags = 1 << EC_FLAGS_QUERY_PENDING;
mutex_init(&ec->mutex);
init_waitqueue_head(&ec->wait);
INIT_LIST_HEAD(&ec->list);
@@ -1290,7 +1376,12 @@
return AE_CTRL_TERMINATE;
}
-static int ec_install_handlers(struct acpi_ec *ec)
+/*
+ * Note: This function returns an error code only when the address space
+ * handler is not installed, which means "not able to handle
+ * transactions".
+ */
+static int ec_install_handlers(struct acpi_ec *ec, bool handle_events)
{
acpi_status status;
@@ -1319,6 +1410,16 @@
set_bit(EC_FLAGS_EC_HANDLER_INSTALLED, &ec->flags);
}
+ if (!handle_events)
+ return 0;
+
+ if (!test_bit(EC_FLAGS_EVT_HANDLER_INSTALLED, &ec->flags)) {
+ /* Find and register all query methods */
+ acpi_walk_namespace(ACPI_TYPE_METHOD, ec->handle, 1,
+ acpi_ec_register_query_methods,
+ NULL, ec, NULL);
+ set_bit(EC_FLAGS_EVT_HANDLER_INSTALLED, &ec->flags);
+ }
if (!test_bit(EC_FLAGS_GPE_HANDLER_INSTALLED, &ec->flags)) {
status = acpi_install_gpe_raw_handler(NULL, ec->gpe,
ACPI_GPE_EDGE_TRIGGERED,
@@ -1329,6 +1430,9 @@
if (test_bit(EC_FLAGS_STARTED, &ec->flags) &&
ec->reference_count >= 1)
acpi_ec_enable_gpe(ec, true);
+
+ /* EC is fully operational, allow queries */
+ acpi_ec_enable_event(ec);
}
}
@@ -1363,23 +1467,104 @@
pr_err("failed to remove gpe handler\n");
clear_bit(EC_FLAGS_GPE_HANDLER_INSTALLED, &ec->flags);
}
+ if (test_bit(EC_FLAGS_EVT_HANDLER_INSTALLED, &ec->flags)) {
+ acpi_ec_remove_query_handlers(ec, true, 0);
+ clear_bit(EC_FLAGS_EVT_HANDLER_INSTALLED, &ec->flags);
+ }
}
-static struct acpi_ec *acpi_ec_alloc(void)
+static int acpi_ec_setup(struct acpi_ec *ec, bool handle_events)
{
- struct acpi_ec *ec;
+ int ret;
- /* Check for boot EC */
- if (boot_ec) {
- ec = boot_ec;
- boot_ec = NULL;
- ec_remove_handlers(ec);
- if (first_ec == ec)
- first_ec = NULL;
- } else {
- ec = make_acpi_ec();
+ ret = ec_install_handlers(ec, handle_events);
+ if (ret)
+ return ret;
+
+ /* First EC capable of handling transactions */
+ if (!first_ec) {
+ first_ec = ec;
+ acpi_handle_info(first_ec->handle, "Used as first EC\n");
}
- return ec;
+
+ acpi_handle_info(ec->handle,
+ "GPE=0x%lx, EC_CMD/EC_SC=0x%lx, EC_DATA=0x%lx\n",
+ ec->gpe, ec->command_addr, ec->data_addr);
+ return ret;
+}
+
+static int acpi_config_boot_ec(struct acpi_ec *ec, acpi_handle handle,
+ bool handle_events, bool is_ecdt)
+{
+ int ret;
+
+ /*
+ * Changing the ACPI handle results in a re-configuration of the
+ * boot EC. And if it happens after the namespace initialization,
+ * it causes _REG evaluations.
+ */
+ if (boot_ec && boot_ec->handle != handle)
+ ec_remove_handlers(boot_ec);
+
+ /* Unset old boot EC */
+ if (boot_ec != ec)
+ acpi_ec_free(boot_ec);
+
+ /*
+ * ECDT device creation is split into acpi_ec_ecdt_probe() and
+ * acpi_ec_ecdt_start(). This function takes care of completing the
+ * ECDT parsing logic as the handle update should be performed
+ * between the installation/uninstallation of the handlers.
+ */
+ if (ec->handle != handle)
+ ec->handle = handle;
+
+ ret = acpi_ec_setup(ec, handle_events);
+ if (ret)
+ return ret;
+
+ /* Set new boot EC */
+ if (!boot_ec) {
+ boot_ec = ec;
+ boot_ec_is_ecdt = is_ecdt;
+ }
+
+ acpi_handle_info(boot_ec->handle,
+ "Used as boot %s EC to handle transactions%s\n",
+ is_ecdt ? "ECDT" : "DSDT",
+ handle_events ? " and events" : "");
+ return ret;
+}
+
+static bool acpi_ec_ecdt_get_handle(acpi_handle *phandle)
+{
+ struct acpi_table_ecdt *ecdt_ptr;
+ acpi_status status;
+ acpi_handle handle;
+
+ status = acpi_get_table(ACPI_SIG_ECDT, 1,
+ (struct acpi_table_header **)&ecdt_ptr);
+ if (ACPI_FAILURE(status))
+ return false;
+
+ status = acpi_get_handle(NULL, ecdt_ptr->id, &handle);
+ if (ACPI_FAILURE(status))
+ return false;
+
+ *phandle = handle;
+ return true;
+}
+
+static bool acpi_is_boot_ec(struct acpi_ec *ec)
+{
+ if (!boot_ec)
+ return false;
+ if (ec->handle == boot_ec->handle &&
+ ec->gpe == boot_ec->gpe &&
+ ec->command_addr == boot_ec->command_addr &&
+ ec->data_addr == boot_ec->data_addr)
+ return true;
+ return false;
}
static int acpi_ec_add(struct acpi_device *device)
@@ -1395,16 +1580,21 @@
return -ENOMEM;
if (ec_parse_device(device->handle, 0, ec, NULL) !=
AE_CTRL_TERMINATE) {
- kfree(ec);
- return -EINVAL;
+ ret = -EINVAL;
+ goto err_alloc;
}
- /* Find and register all query methods */
- acpi_walk_namespace(ACPI_TYPE_METHOD, ec->handle, 1,
- acpi_ec_register_query_methods, NULL, ec, NULL);
+ if (acpi_is_boot_ec(ec)) {
+ boot_ec_is_ecdt = false;
+ acpi_handle_debug(ec->handle, "duplicated.\n");
+ acpi_ec_free(ec);
+ ec = boot_ec;
+ ret = acpi_config_boot_ec(ec, ec->handle, true, false);
+ } else
+ ret = acpi_ec_setup(ec, true);
+ if (ret)
+ goto err_query;
- if (!first_ec)
- first_ec = ec;
device->driver_data = ec;
ret = !!request_region(ec->data_addr, 1, "EC data");
@@ -1412,20 +1602,17 @@
ret = !!request_region(ec->command_addr, 1, "EC cmd");
WARN(!ret, "Could not request EC cmd io port 0x%lx", ec->command_addr);
- pr_info("GPE = 0x%lx, I/O: command/status = 0x%lx, data = 0x%lx\n",
- ec->gpe, ec->command_addr, ec->data_addr);
-
- ret = ec_install_handlers(ec);
-
/* Reprobe devices depending on the EC */
acpi_walk_dep_device_list(ec->handle);
+ acpi_handle_debug(ec->handle, "enumerated.\n");
+ return 0;
- /* EC is fully operational, allow queries */
- clear_bit(EC_FLAGS_QUERY_PENDING, &ec->flags);
-
- /* Clear stale _Q events if hardware might require that */
- if (EC_FLAGS_CLEAR_ON_RESUME)
- acpi_ec_clear(ec);
+err_query:
+ if (ec != boot_ec)
+ acpi_ec_remove_query_handlers(ec, true, 0);
+err_alloc:
+ if (ec != boot_ec)
+ acpi_ec_free(ec);
return ret;
}
@@ -1437,14 +1624,13 @@
return -EINVAL;
ec = acpi_driver_data(device);
- ec_remove_handlers(ec);
- acpi_ec_remove_query_handlers(ec, true, 0);
release_region(ec->data_addr, 1);
release_region(ec->command_addr, 1);
device->driver_data = NULL;
- if (ec == first_ec)
- first_ec = NULL;
- kfree(ec);
+ if (ec != boot_ec) {
+ ec_remove_handlers(ec);
+ acpi_ec_free(ec);
+ }
return 0;
}
@@ -1486,9 +1672,8 @@
if (!ec)
return -ENOMEM;
/*
- * Finding EC from DSDT if there is no ECDT EC available. When this
- * function is invoked, ACPI tables have been fully loaded, we can
- * walk namespace now.
+ * At this point, the namespace is initialized, so start to find
+ * the namespace objects.
*/
status = acpi_get_devices(ec_device_ids[0].id,
ec_parse_device, ec, NULL);
@@ -1496,16 +1681,47 @@
ret = -ENODEV;
goto error;
}
- ret = ec_install_handlers(ec);
-
+ /*
+ * When the DSDT EC is available, always re-configure boot EC to
+ * have _REG evaluated. _REG can only be evaluated after the
+ * namespace initialization.
+ * At this point, the GPE is not fully initialized, so do not to
+ * handle the events.
+ */
+ ret = acpi_config_boot_ec(ec, ec->handle, false, false);
error:
if (ret)
- kfree(ec);
- else
- first_ec = boot_ec = ec;
+ acpi_ec_free(ec);
return ret;
}
+/*
+ * If the DSDT EC is not functioning, we still need to prepare a fully
+ * functioning ECDT EC first in order to handle the events.
+ * https://bugzilla.kernel.org/show_bug.cgi?id=115021
+ */
+int __init acpi_ec_ecdt_start(void)
+{
+ acpi_handle handle;
+
+ if (!boot_ec)
+ return -ENODEV;
+ /*
+ * The DSDT EC should have already been started in
+ * acpi_ec_add().
+ */
+ if (!boot_ec_is_ecdt)
+ return -ENODEV;
+
+ /*
+ * At this point, the namespace and the GPE is initialized, so
+ * start to find the namespace objects and handle the events.
+ */
+ if (!acpi_ec_ecdt_get_handle(&handle))
+ return -ENODEV;
+ return acpi_config_boot_ec(boot_ec, handle, true, true);
+}
+
#if 0
/*
* Some EC firmware variations refuses to respond QR_EC when SCI_EVT is not
@@ -1600,7 +1816,6 @@
goto error;
}
- pr_info("EC description table is found, configuring boot EC\n");
if (EC_FLAGS_CORRECT_ECDT) {
ec->command_addr = ecdt_ptr->data.address;
ec->data_addr = ecdt_ptr->control.address;
@@ -1609,16 +1824,90 @@
ec->data_addr = ecdt_ptr->data.address;
}
ec->gpe = ecdt_ptr->gpe;
- ec->handle = ACPI_ROOT_OBJECT;
- ret = ec_install_handlers(ec);
+
+ /*
+ * At this point, the namespace is not initialized, so do not find
+ * the namespace objects, or handle the events.
+ */
+ ret = acpi_config_boot_ec(ec, ACPI_ROOT_OBJECT, false, true);
error:
if (ret)
- kfree(ec);
- else
- first_ec = boot_ec = ec;
+ acpi_ec_free(ec);
return ret;
}
+#ifdef CONFIG_PM_SLEEP
+static void acpi_ec_enter_noirq(struct acpi_ec *ec)
+{
+ unsigned long flags;
+
+ if (ec == first_ec) {
+ spin_lock_irqsave(&ec->lock, flags);
+ ec->saved_busy_polling = ec_busy_polling;
+ ec->saved_polling_guard = ec_polling_guard;
+ ec_busy_polling = true;
+ ec_polling_guard = 0;
+ ec_log_drv("interrupt blocked");
+ spin_unlock_irqrestore(&ec->lock, flags);
+ }
+}
+
+static void acpi_ec_leave_noirq(struct acpi_ec *ec)
+{
+ unsigned long flags;
+
+ if (ec == first_ec) {
+ spin_lock_irqsave(&ec->lock, flags);
+ ec_busy_polling = ec->saved_busy_polling;
+ ec_polling_guard = ec->saved_polling_guard;
+ ec_log_drv("interrupt unblocked");
+ spin_unlock_irqrestore(&ec->lock, flags);
+ }
+}
+
+static int acpi_ec_suspend_noirq(struct device *dev)
+{
+ struct acpi_ec *ec =
+ acpi_driver_data(to_acpi_device(dev));
+
+ acpi_ec_enter_noirq(ec);
+ return 0;
+}
+
+static int acpi_ec_resume_noirq(struct device *dev)
+{
+ struct acpi_ec *ec =
+ acpi_driver_data(to_acpi_device(dev));
+
+ acpi_ec_leave_noirq(ec);
+ return 0;
+}
+
+static int acpi_ec_suspend(struct device *dev)
+{
+ struct acpi_ec *ec =
+ acpi_driver_data(to_acpi_device(dev));
+
+ if (ec_freeze_events)
+ acpi_ec_disable_event(ec);
+ return 0;
+}
+
+static int acpi_ec_resume(struct device *dev)
+{
+ struct acpi_ec *ec =
+ acpi_driver_data(to_acpi_device(dev));
+
+ acpi_ec_enable_event(ec);
+ return 0;
+}
+#endif
+
+static const struct dev_pm_ops acpi_ec_pm = {
+ SET_NOIRQ_SYSTEM_SLEEP_PM_OPS(acpi_ec_suspend_noirq, acpi_ec_resume_noirq)
+ SET_SYSTEM_SLEEP_PM_OPS(acpi_ec_suspend, acpi_ec_resume)
+};
+
static int param_set_event_clearing(const char *val, struct kernel_param *kp)
{
int result = 0;
@@ -1664,6 +1953,7 @@
.add = acpi_ec_add,
.remove = acpi_ec_remove,
},
+ .drv.pm = &acpi_ec_pm,
};
static inline int acpi_ec_query_init(void)
diff --git a/drivers/acpi/internal.h b/drivers/acpi/internal.h
index 940218f..4bf8bf1 100644
--- a/drivers/acpi/internal.h
+++ b/drivers/acpi/internal.h
@@ -116,7 +116,6 @@
bool acpi_device_is_battery(struct acpi_device *adev);
bool acpi_device_is_first_physical_node(struct acpi_device *adev,
const struct device *dev);
-struct device *acpi_get_first_physical_node(struct acpi_device *adev);
/* --------------------------------------------------------------------------
Device Matching and Notification
@@ -174,6 +173,8 @@
struct work_struct work;
unsigned long timestamp;
unsigned long nr_pending_queries;
+ bool saved_busy_polling;
+ unsigned int saved_polling_guard;
};
extern struct acpi_ec *first_ec;
@@ -185,9 +186,9 @@
int acpi_ec_init(void);
int acpi_ec_ecdt_probe(void);
int acpi_ec_dsdt_probe(void);
+int acpi_ec_ecdt_start(void);
void acpi_ec_block_transactions(void);
void acpi_ec_unblock_transactions(void);
-void acpi_ec_unblock_transactions_early(void);
int acpi_ec_add_query_handler(struct acpi_ec *ec, u8 query_bit,
acpi_handle handle, acpi_ec_query_func func,
void *data);
@@ -225,4 +226,14 @@
void acpi_init_properties(struct acpi_device *adev);
void acpi_free_properties(struct acpi_device *adev);
+/*--------------------------------------------------------------------------
+ Watchdog
+ -------------------------------------------------------------------------- */
+
+#ifdef CONFIG_ACPI_WATCHDOG
+void acpi_watchdog_init(void);
+#else
+static inline void acpi_watchdog_init(void) {}
+#endif
+
#endif /* _ACPI_INTERNAL_H_ */
diff --git a/drivers/acpi/nfit/core.c b/drivers/acpi/nfit/core.c
index 80cc7c0..e1d5ea6 100644
--- a/drivers/acpi/nfit/core.c
+++ b/drivers/acpi/nfit/core.c
@@ -94,54 +94,50 @@
return to_acpi_device(acpi_desc->dev);
}
-static int xlat_status(void *buf, unsigned int cmd)
+static int xlat_status(void *buf, unsigned int cmd, u32 status)
{
struct nd_cmd_clear_error *clear_err;
struct nd_cmd_ars_status *ars_status;
- struct nd_cmd_ars_start *ars_start;
- struct nd_cmd_ars_cap *ars_cap;
u16 flags;
switch (cmd) {
case ND_CMD_ARS_CAP:
- ars_cap = buf;
- if ((ars_cap->status & 0xffff) == NFIT_ARS_CAP_NONE)
+ if ((status & 0xffff) == NFIT_ARS_CAP_NONE)
return -ENOTTY;
/* Command failed */
- if (ars_cap->status & 0xffff)
+ if (status & 0xffff)
return -EIO;
/* No supported scan types for this range */
flags = ND_ARS_PERSISTENT | ND_ARS_VOLATILE;
- if ((ars_cap->status >> 16 & flags) == 0)
+ if ((status >> 16 & flags) == 0)
return -ENOTTY;
break;
case ND_CMD_ARS_START:
- ars_start = buf;
/* ARS is in progress */
- if ((ars_start->status & 0xffff) == NFIT_ARS_START_BUSY)
+ if ((status & 0xffff) == NFIT_ARS_START_BUSY)
return -EBUSY;
/* Command failed */
- if (ars_start->status & 0xffff)
+ if (status & 0xffff)
return -EIO;
break;
case ND_CMD_ARS_STATUS:
ars_status = buf;
/* Command failed */
- if (ars_status->status & 0xffff)
+ if (status & 0xffff)
return -EIO;
/* Check extended status (Upper two bytes) */
- if (ars_status->status == NFIT_ARS_STATUS_DONE)
+ if (status == NFIT_ARS_STATUS_DONE)
return 0;
/* ARS is in progress */
- if (ars_status->status == NFIT_ARS_STATUS_BUSY)
+ if (status == NFIT_ARS_STATUS_BUSY)
return -EBUSY;
/* No ARS performed for the current boot */
- if (ars_status->status == NFIT_ARS_STATUS_NONE)
+ if (status == NFIT_ARS_STATUS_NONE)
return -EAGAIN;
/*
@@ -149,19 +145,19 @@
* agent wants the scan to stop. If we didn't overflow
* then just continue with the returned results.
*/
- if (ars_status->status == NFIT_ARS_STATUS_INTR) {
+ if (status == NFIT_ARS_STATUS_INTR) {
if (ars_status->flags & NFIT_ARS_F_OVERFLOW)
return -ENOSPC;
return 0;
}
/* Unknown status */
- if (ars_status->status >> 16)
+ if (status >> 16)
return -EIO;
break;
case ND_CMD_CLEAR_ERROR:
clear_err = buf;
- if (clear_err->status & 0xffff)
+ if (status & 0xffff)
return -EIO;
if (!clear_err->cleared)
return -EIO;
@@ -172,6 +168,9 @@
break;
}
+ /* all other non-zero status results in an error */
+ if (status)
+ return -EIO;
return 0;
}
@@ -186,10 +185,10 @@
struct nd_cmd_pkg *call_pkg = NULL;
const char *cmd_name, *dimm_name;
unsigned long cmd_mask, dsm_mask;
+ u32 offset, fw_status = 0;
acpi_handle handle;
unsigned int func;
const u8 *uuid;
- u32 offset;
int rc, i;
func = cmd;
@@ -317,6 +316,15 @@
out_obj->buffer.pointer + offset, out_size);
offset += out_size;
}
+
+ /*
+ * Set fw_status for all the commands with a known format to be
+ * later interpreted by xlat_status().
+ */
+ if (i >= 1 && ((cmd >= ND_CMD_ARS_CAP && cmd <= ND_CMD_CLEAR_ERROR)
+ || (cmd >= ND_CMD_SMART && cmd <= ND_CMD_VENDOR)))
+ fw_status = *(u32 *) out_obj->buffer.pointer;
+
if (offset + in_buf.buffer.length < buf_len) {
if (i >= 1) {
/*
@@ -325,7 +333,7 @@
*/
rc = buf_len - offset - in_buf.buffer.length;
if (cmd_rc)
- *cmd_rc = xlat_status(buf, cmd);
+ *cmd_rc = xlat_status(buf, cmd, fw_status);
} else {
dev_err(dev, "%s:%s underrun cmd: %s buf_len: %d out_len: %d\n",
__func__, dimm_name, cmd_name, buf_len,
@@ -335,7 +343,7 @@
} else {
rc = 0;
if (cmd_rc)
- *cmd_rc = xlat_status(buf, cmd);
+ *cmd_rc = xlat_status(buf, cmd, fw_status);
}
out:
diff --git a/drivers/acpi/pci_irq.c b/drivers/acpi/pci_irq.c
index 2c45dd3..c576a6f 100644
--- a/drivers/acpi/pci_irq.c
+++ b/drivers/acpi/pci_irq.c
@@ -411,7 +411,15 @@
int gsi;
u8 pin;
int triggering = ACPI_LEVEL_SENSITIVE;
- int polarity = ACPI_ACTIVE_LOW;
+ /*
+ * On ARM systems with the GIC interrupt model, level interrupts
+ * are always polarity high by specification; PCI legacy
+ * IRQs lines are inverted before reaching the interrupt
+ * controller and must therefore be considered active high
+ * as default.
+ */
+ int polarity = acpi_irq_model == ACPI_IRQ_MODEL_GIC ?
+ ACPI_ACTIVE_HIGH : ACPI_ACTIVE_LOW;
char *link = NULL;
char link_desc[16];
int rc;
diff --git a/drivers/acpi/processor_driver.c b/drivers/acpi/processor_driver.c
index 0553aee..8f8552a 100644
--- a/drivers/acpi/processor_driver.c
+++ b/drivers/acpi/processor_driver.c
@@ -245,8 +245,8 @@
return 0;
result = acpi_cppc_processor_probe(pr);
- if (result)
- return -ENODEV;
+ if (result && !IS_ENABLED(CONFIG_ACPI_CPU_FREQ_PSS))
+ dev_warn(&device->dev, "CPPC data invalid or not present\n");
if (!cpuidle_get_driver() || cpuidle_get_driver() == &acpi_idle_driver)
acpi_processor_power_init(pr);
diff --git a/drivers/acpi/scan.c b/drivers/acpi/scan.c
index e878fc7..035ac64 100644
--- a/drivers/acpi/scan.c
+++ b/drivers/acpi/scan.c
@@ -2002,6 +2002,7 @@
acpi_pnp_init();
acpi_int340x_thermal_init();
acpi_amba_init();
+ acpi_watchdog_init();
acpi_scan_add_handler(&generic_device_handler);
@@ -2044,6 +2045,7 @@
}
acpi_update_all_gpes();
+ acpi_ec_ecdt_start();
acpi_scan_initialized = true;
diff --git a/drivers/acpi/sleep.c b/drivers/acpi/sleep.c
index 2b38c1b..deb0ff7 100644
--- a/drivers/acpi/sleep.c
+++ b/drivers/acpi/sleep.c
@@ -572,7 +572,7 @@
acpi_get_event_status(ACPI_EVENT_POWER_BUTTON, &pwr_btn_status);
- if (pwr_btn_status & ACPI_EVENT_FLAG_SET) {
+ if (pwr_btn_status & ACPI_EVENT_FLAG_STATUS_SET) {
acpi_clear_event(ACPI_EVENT_POWER_BUTTON);
/* Flag for later */
pwr_btn_event_pending = true;
@@ -586,7 +586,7 @@
*/
acpi_disable_all_gpes();
/* Allow EC transactions to happen. */
- acpi_ec_unblock_transactions_early();
+ acpi_ec_unblock_transactions();
suspend_nvs_restore();
@@ -784,7 +784,7 @@
/* Restore the NVS memory area */
suspend_nvs_restore();
/* Allow EC transactions to happen. */
- acpi_ec_unblock_transactions_early();
+ acpi_ec_unblock_transactions();
}
static void acpi_pm_thaw(void)
diff --git a/drivers/acpi/sysfs.c b/drivers/acpi/sysfs.c
index 358165e..703c26e 100644
--- a/drivers/acpi/sysfs.c
+++ b/drivers/acpi/sysfs.c
@@ -314,10 +314,14 @@
static struct kobject *dynamic_tables_kobj;
static struct kobject *hotplug_kobj;
+#define ACPI_MAX_TABLE_INSTANCES 999
+#define ACPI_INST_SIZE 4 /* including trailing 0 */
+
struct acpi_table_attr {
struct bin_attribute attr;
- char name[8];
+ char name[ACPI_NAME_SIZE];
int instance;
+ char filename[ACPI_NAME_SIZE+ACPI_INST_SIZE];
struct list_head node;
};
@@ -329,14 +333,9 @@
container_of(bin_attr, struct acpi_table_attr, attr);
struct acpi_table_header *table_header = NULL;
acpi_status status;
- char name[ACPI_NAME_SIZE];
- if (strncmp(table_attr->name, "NULL", 4))
- memcpy(name, table_attr->name, ACPI_NAME_SIZE);
- else
- memcpy(name, "\0\0\0\0", 4);
-
- status = acpi_get_table(name, table_attr->instance, &table_header);
+ status = acpi_get_table(table_attr->name, table_attr->instance,
+ &table_header);
if (ACPI_FAILURE(status))
return -ENODEV;
@@ -344,38 +343,45 @@
table_header, table_header->length);
}
-static void acpi_table_attr_init(struct acpi_table_attr *table_attr,
- struct acpi_table_header *table_header)
+static int acpi_table_attr_init(struct kobject *tables_obj,
+ struct acpi_table_attr *table_attr,
+ struct acpi_table_header *table_header)
{
struct acpi_table_header *header = NULL;
struct acpi_table_attr *attr = NULL;
+ char instance_str[ACPI_INST_SIZE];
sysfs_attr_init(&table_attr->attr.attr);
- if (table_header->signature[0] != '\0')
- memcpy(table_attr->name, table_header->signature,
- ACPI_NAME_SIZE);
- else
- memcpy(table_attr->name, "NULL", 4);
+ ACPI_MOVE_NAME(table_attr->name, table_header->signature);
list_for_each_entry(attr, &acpi_table_attr_list, node) {
- if (!memcmp(table_attr->name, attr->name, ACPI_NAME_SIZE))
+ if (ACPI_COMPARE_NAME(table_attr->name, attr->name))
if (table_attr->instance < attr->instance)
table_attr->instance = attr->instance;
}
table_attr->instance++;
+ if (table_attr->instance > ACPI_MAX_TABLE_INSTANCES) {
+ pr_warn("%4.4s: too many table instances\n",
+ table_attr->name);
+ return -ERANGE;
+ }
+ ACPI_MOVE_NAME(table_attr->filename, table_header->signature);
+ table_attr->filename[ACPI_NAME_SIZE] = '\0';
if (table_attr->instance > 1 || (table_attr->instance == 1 &&
!acpi_get_table
- (table_header->signature, 2, &header)))
- sprintf(table_attr->name + ACPI_NAME_SIZE, "%d",
- table_attr->instance);
+ (table_header->signature, 2, &header))) {
+ snprintf(instance_str, sizeof(instance_str), "%u",
+ table_attr->instance);
+ strcat(table_attr->filename, instance_str);
+ }
table_attr->attr.size = table_header->length;
table_attr->attr.read = acpi_table_show;
- table_attr->attr.attr.name = table_attr->name;
+ table_attr->attr.attr.name = table_attr->filename;
table_attr->attr.attr.mode = 0400;
- return;
+ return sysfs_create_bin_file(tables_obj, &table_attr->attr);
}
acpi_status acpi_sysfs_table_handler(u32 event, void *table, void *context)
@@ -383,21 +389,22 @@
struct acpi_table_attr *table_attr;
switch (event) {
- case ACPI_TABLE_EVENT_LOAD:
+ case ACPI_TABLE_EVENT_INSTALL:
table_attr =
kzalloc(sizeof(struct acpi_table_attr), GFP_KERNEL);
if (!table_attr)
return AE_NO_MEMORY;
- acpi_table_attr_init(table_attr, table);
- if (sysfs_create_bin_file(dynamic_tables_kobj,
- &table_attr->attr)) {
+ if (acpi_table_attr_init(dynamic_tables_kobj,
+ table_attr, table)) {
kfree(table_attr);
return AE_ERROR;
- } else
- list_add_tail(&table_attr->node, &acpi_table_attr_list);
+ }
+ list_add_tail(&table_attr->node, &acpi_table_attr_list);
break;
+ case ACPI_TABLE_EVENT_LOAD:
case ACPI_TABLE_EVENT_UNLOAD:
+ case ACPI_TABLE_EVENT_UNINSTALL:
/*
* we do not need to do anything right now
* because the table is not deleted from the
@@ -435,13 +442,12 @@
if (ACPI_FAILURE(status))
continue;
- table_attr = NULL;
table_attr = kzalloc(sizeof(*table_attr), GFP_KERNEL);
if (!table_attr)
return -ENOMEM;
- acpi_table_attr_init(table_attr, table_header);
- ret = sysfs_create_bin_file(tables_kobj, &table_attr->attr);
+ ret = acpi_table_attr_init(tables_kobj,
+ table_attr, table_header);
if (ret) {
kfree(table_attr);
return ret;
@@ -597,14 +603,27 @@
if (result)
goto end;
- if (!(status & ACPI_EVENT_FLAG_HAS_HANDLER))
- size += sprintf(buf + size, " invalid");
- else if (status & ACPI_EVENT_FLAG_ENABLED)
- size += sprintf(buf + size, " enabled");
- else if (status & ACPI_EVENT_FLAG_WAKE_ENABLED)
- size += sprintf(buf + size, " wake_enabled");
+ if (status & ACPI_EVENT_FLAG_ENABLE_SET)
+ size += sprintf(buf + size, " EN");
else
- size += sprintf(buf + size, " disabled");
+ size += sprintf(buf + size, " ");
+ if (status & ACPI_EVENT_FLAG_STATUS_SET)
+ size += sprintf(buf + size, " STS");
+ else
+ size += sprintf(buf + size, " ");
+
+ if (!(status & ACPI_EVENT_FLAG_HAS_HANDLER))
+ size += sprintf(buf + size, " invalid ");
+ else if (status & ACPI_EVENT_FLAG_ENABLED)
+ size += sprintf(buf + size, " enabled ");
+ else if (status & ACPI_EVENT_FLAG_WAKE_ENABLED)
+ size += sprintf(buf + size, " wake_enabled");
+ else
+ size += sprintf(buf + size, " disabled ");
+ if (status & ACPI_EVENT_FLAG_MASKED)
+ size += sprintf(buf + size, " masked ");
+ else
+ size += sprintf(buf + size, " unmasked");
end:
size += sprintf(buf + size, "\n");
@@ -655,8 +674,12 @@
!(status & ACPI_EVENT_FLAG_ENABLED))
result = acpi_enable_gpe(handle, index);
else if (!strcmp(buf, "clear\n") &&
- (status & ACPI_EVENT_FLAG_SET))
+ (status & ACPI_EVENT_FLAG_STATUS_SET))
result = acpi_clear_gpe(handle, index);
+ else if (!strcmp(buf, "mask\n"))
+ result = acpi_mask_gpe(handle, index, TRUE);
+ else if (!strcmp(buf, "unmask\n"))
+ result = acpi_mask_gpe(handle, index, FALSE);
else if (!kstrtoul(buf, 0, &tmp))
all_counters[index].count = tmp;
else
@@ -664,13 +687,13 @@
} else if (index < num_gpes + ACPI_NUM_FIXED_EVENTS) {
int event = index - num_gpes;
if (!strcmp(buf, "disable\n") &&
- (status & ACPI_EVENT_FLAG_ENABLED))
+ (status & ACPI_EVENT_FLAG_ENABLE_SET))
result = acpi_disable_event(event, ACPI_NOT_ISR);
else if (!strcmp(buf, "enable\n") &&
- !(status & ACPI_EVENT_FLAG_ENABLED))
+ !(status & ACPI_EVENT_FLAG_ENABLE_SET))
result = acpi_enable_event(event, ACPI_NOT_ISR);
else if (!strcmp(buf, "clear\n") &&
- (status & ACPI_EVENT_FLAG_SET))
+ (status & ACPI_EVENT_FLAG_STATUS_SET))
result = acpi_clear_event(event);
else if (!kstrtoul(buf, 0, &tmp))
all_counters[index].count = tmp;
diff --git a/drivers/acpi/tables.c b/drivers/acpi/tables.c
index 9f0ad6e..cdd56c4 100644
--- a/drivers/acpi/tables.c
+++ b/drivers/acpi/tables.c
@@ -35,7 +35,6 @@
#include <linux/earlycpio.h>
#include <linux/memblock.h>
#include <linux/initrd.h>
-#include <linux/acpi.h>
#include "internal.h"
#ifdef CONFIG_ACPI_CUSTOM_DSDT
@@ -246,6 +245,7 @@
struct acpi_subtable_header *entry;
unsigned long table_end;
int count = 0;
+ int errs = 0;
int i;
if (acpi_disabled)
@@ -278,10 +278,12 @@
if (entry->type != proc[i].id)
continue;
if (!proc[i].handler ||
- proc[i].handler(entry, table_end))
- return -EINVAL;
+ (!errs && proc[i].handler(entry, table_end))) {
+ errs++;
+ continue;
+ }
- proc->count++;
+ proc[i].count++;
break;
}
if (i != proc_num)
@@ -301,11 +303,11 @@
}
if (max_entries && count > max_entries) {
- pr_warn("[%4.4s:0x%02x] ignored %i entries of %i found\n",
- id, proc->id, count - max_entries, count);
+ pr_warn("[%4.4s:0x%02x] found the maximum %i entries\n",
+ id, proc->id, count);
}
- return count;
+ return errs ? -EINVAL : count;
}
int __init
diff --git a/drivers/base/core.c b/drivers/base/core.c
index 0a8bdad..70c5be5 100644
--- a/drivers/base/core.c
+++ b/drivers/base/core.c
@@ -1266,6 +1266,7 @@
bus_remove_device(dev);
device_pm_remove(dev);
driver_deferred_probe_del(dev);
+ device_remove_properties(dev);
/* Notify the platform of the removal, in case they
* need to do anything...
diff --git a/drivers/base/power/domain.c b/drivers/base/power/domain.c
index a1f2aff..e023066 100644
--- a/drivers/base/power/domain.c
+++ b/drivers/base/power/domain.c
@@ -45,7 +45,7 @@
* and checks that the PM domain pointer is a real generic PM domain.
* Any failure results in NULL being returned.
*/
-struct generic_pm_domain *pm_genpd_lookup_dev(struct device *dev)
+static struct generic_pm_domain *genpd_lookup_dev(struct device *dev)
{
struct generic_pm_domain *genpd = NULL, *gpd;
@@ -586,7 +586,7 @@
}
late_initcall(genpd_poweroff_unused);
-#ifdef CONFIG_PM_SLEEP
+#if defined(CONFIG_PM_SLEEP) || defined(CONFIG_PM_GENERIC_DOMAINS_OF)
/**
* pm_genpd_present - Check if the given PM domain has been initialized.
@@ -606,6 +606,10 @@
return false;
}
+#endif
+
+#ifdef CONFIG_PM_SLEEP
+
static bool genpd_dev_active_wakeup(struct generic_pm_domain *genpd,
struct device *dev)
{
@@ -613,9 +617,8 @@
}
/**
- * pm_genpd_sync_poweroff - Synchronously power off a PM domain and its masters.
+ * genpd_sync_poweroff - Synchronously power off a PM domain and its masters.
* @genpd: PM domain to power off, if possible.
- * @timed: True if latency measurements are allowed.
*
* Check if the given PM domain can be powered off (during system suspend or
* hibernation) and do that if so. Also, in that case propagate to its masters.
@@ -625,8 +628,7 @@
* executed sequentially, so it is guaranteed that it will never run twice in
* parallel).
*/
-static void pm_genpd_sync_poweroff(struct generic_pm_domain *genpd,
- bool timed)
+static void genpd_sync_poweroff(struct generic_pm_domain *genpd)
{
struct gpd_link *link;
@@ -639,28 +641,26 @@
/* Choose the deepest state when suspending */
genpd->state_idx = genpd->state_count - 1;
- genpd_power_off(genpd, timed);
+ genpd_power_off(genpd, false);
genpd->status = GPD_STATE_POWER_OFF;
list_for_each_entry(link, &genpd->slave_links, slave_node) {
genpd_sd_counter_dec(link->master);
- pm_genpd_sync_poweroff(link->master, timed);
+ genpd_sync_poweroff(link->master);
}
}
/**
- * pm_genpd_sync_poweron - Synchronously power on a PM domain and its masters.
+ * genpd_sync_poweron - Synchronously power on a PM domain and its masters.
* @genpd: PM domain to power on.
- * @timed: True if latency measurements are allowed.
*
* This function is only called in "noirq" and "syscore" stages of system power
* transitions, so it need not acquire locks (all of the "noirq" callbacks are
* executed sequentially, so it is guaranteed that it will never run twice in
* parallel).
*/
-static void pm_genpd_sync_poweron(struct generic_pm_domain *genpd,
- bool timed)
+static void genpd_sync_poweron(struct generic_pm_domain *genpd)
{
struct gpd_link *link;
@@ -668,11 +668,11 @@
return;
list_for_each_entry(link, &genpd->slave_links, slave_node) {
- pm_genpd_sync_poweron(link->master, timed);
+ genpd_sync_poweron(link->master);
genpd_sd_counter_inc(link->master);
}
- genpd_power_on(genpd, timed);
+ genpd_power_on(genpd, false);
genpd->status = GPD_STATE_ACTIVE;
}
@@ -784,7 +784,7 @@
* the same PM domain, so it is not necessary to use locking here.
*/
genpd->suspended_count++;
- pm_genpd_sync_poweroff(genpd, true);
+ genpd_sync_poweroff(genpd);
return 0;
}
@@ -814,7 +814,7 @@
* guaranteed that this function will never run twice in parallel for
* the same PM domain, so it is not necessary to use locking here.
*/
- pm_genpd_sync_poweron(genpd, true);
+ genpd_sync_poweron(genpd);
genpd->suspended_count--;
if (genpd->dev_ops.stop && genpd->dev_ops.start)
@@ -902,12 +902,12 @@
if (genpd->suspended_count++ == 0)
/*
* The boot kernel might put the domain into arbitrary state,
- * so make it appear as powered off to pm_genpd_sync_poweron(),
+ * so make it appear as powered off to genpd_sync_poweron(),
* so that it tries to power it on in case it was really off.
*/
genpd->status = GPD_STATE_POWER_OFF;
- pm_genpd_sync_poweron(genpd, true);
+ genpd_sync_poweron(genpd);
if (genpd->dev_ops.stop && genpd->dev_ops.start)
ret = pm_runtime_force_resume(dev);
@@ -962,9 +962,9 @@
if (suspend) {
genpd->suspended_count++;
- pm_genpd_sync_poweroff(genpd, false);
+ genpd_sync_poweroff(genpd);
} else {
- pm_genpd_sync_poweron(genpd, false);
+ genpd_sync_poweron(genpd);
genpd->suspended_count--;
}
}
@@ -1056,14 +1056,8 @@
dev_pm_put_subsys_data(dev);
}
-/**
- * __pm_genpd_add_device - Add a device to an I/O PM domain.
- * @genpd: PM domain to add the device to.
- * @dev: Device to be added.
- * @td: Set of PM QoS timing parameters to attach to the device.
- */
-int __pm_genpd_add_device(struct generic_pm_domain *genpd, struct device *dev,
- struct gpd_timing_data *td)
+static int genpd_add_device(struct generic_pm_domain *genpd, struct device *dev,
+ struct gpd_timing_data *td)
{
struct generic_pm_domain_data *gpd_data;
int ret = 0;
@@ -1103,15 +1097,28 @@
return ret;
}
-EXPORT_SYMBOL_GPL(__pm_genpd_add_device);
/**
- * pm_genpd_remove_device - Remove a device from an I/O PM domain.
- * @genpd: PM domain to remove the device from.
- * @dev: Device to be removed.
+ * __pm_genpd_add_device - Add a device to an I/O PM domain.
+ * @genpd: PM domain to add the device to.
+ * @dev: Device to be added.
+ * @td: Set of PM QoS timing parameters to attach to the device.
*/
-int pm_genpd_remove_device(struct generic_pm_domain *genpd,
- struct device *dev)
+int __pm_genpd_add_device(struct generic_pm_domain *genpd, struct device *dev,
+ struct gpd_timing_data *td)
+{
+ int ret;
+
+ mutex_lock(&gpd_list_lock);
+ ret = genpd_add_device(genpd, dev, td);
+ mutex_unlock(&gpd_list_lock);
+
+ return ret;
+}
+EXPORT_SYMBOL_GPL(__pm_genpd_add_device);
+
+static int genpd_remove_device(struct generic_pm_domain *genpd,
+ struct device *dev)
{
struct generic_pm_domain_data *gpd_data;
struct pm_domain_data *pdd;
@@ -1119,10 +1126,6 @@
dev_dbg(dev, "%s()\n", __func__);
- if (!genpd || genpd != pm_genpd_lookup_dev(dev))
- return -EINVAL;
-
- /* The above validation also means we have existing domain_data. */
pdd = dev->power.subsys_data->domain_data;
gpd_data = to_gpd_data(pdd);
dev_pm_qos_remove_notifier(dev, &gpd_data->nb);
@@ -1154,15 +1157,24 @@
return ret;
}
-EXPORT_SYMBOL_GPL(pm_genpd_remove_device);
/**
- * pm_genpd_add_subdomain - Add a subdomain to an I/O PM domain.
- * @genpd: Master PM domain to add the subdomain to.
- * @subdomain: Subdomain to be added.
+ * pm_genpd_remove_device - Remove a device from an I/O PM domain.
+ * @genpd: PM domain to remove the device from.
+ * @dev: Device to be removed.
*/
-int pm_genpd_add_subdomain(struct generic_pm_domain *genpd,
- struct generic_pm_domain *subdomain)
+int pm_genpd_remove_device(struct generic_pm_domain *genpd,
+ struct device *dev)
+{
+ if (!genpd || genpd != genpd_lookup_dev(dev))
+ return -EINVAL;
+
+ return genpd_remove_device(genpd, dev);
+}
+EXPORT_SYMBOL_GPL(pm_genpd_remove_device);
+
+static int genpd_add_subdomain(struct generic_pm_domain *genpd,
+ struct generic_pm_domain *subdomain)
{
struct gpd_link *link, *itr;
int ret = 0;
@@ -1205,6 +1217,23 @@
kfree(link);
return ret;
}
+
+/**
+ * pm_genpd_add_subdomain - Add a subdomain to an I/O PM domain.
+ * @genpd: Master PM domain to add the subdomain to.
+ * @subdomain: Subdomain to be added.
+ */
+int pm_genpd_add_subdomain(struct generic_pm_domain *genpd,
+ struct generic_pm_domain *subdomain)
+{
+ int ret;
+
+ mutex_lock(&gpd_list_lock);
+ ret = genpd_add_subdomain(genpd, subdomain);
+ mutex_unlock(&gpd_list_lock);
+
+ return ret;
+}
EXPORT_SYMBOL_GPL(pm_genpd_add_subdomain);
/**
@@ -1278,27 +1307,17 @@
genpd->device_count = 0;
genpd->max_off_time_ns = -1;
genpd->max_off_time_changed = true;
+ genpd->provider = NULL;
+ genpd->has_provider = false;
genpd->domain.ops.runtime_suspend = genpd_runtime_suspend;
genpd->domain.ops.runtime_resume = genpd_runtime_resume;
genpd->domain.ops.prepare = pm_genpd_prepare;
- genpd->domain.ops.suspend = pm_generic_suspend;
- genpd->domain.ops.suspend_late = pm_generic_suspend_late;
genpd->domain.ops.suspend_noirq = pm_genpd_suspend_noirq;
genpd->domain.ops.resume_noirq = pm_genpd_resume_noirq;
- genpd->domain.ops.resume_early = pm_generic_resume_early;
- genpd->domain.ops.resume = pm_generic_resume;
- genpd->domain.ops.freeze = pm_generic_freeze;
- genpd->domain.ops.freeze_late = pm_generic_freeze_late;
genpd->domain.ops.freeze_noirq = pm_genpd_freeze_noirq;
genpd->domain.ops.thaw_noirq = pm_genpd_thaw_noirq;
- genpd->domain.ops.thaw_early = pm_generic_thaw_early;
- genpd->domain.ops.thaw = pm_generic_thaw;
- genpd->domain.ops.poweroff = pm_generic_poweroff;
- genpd->domain.ops.poweroff_late = pm_generic_poweroff_late;
genpd->domain.ops.poweroff_noirq = pm_genpd_suspend_noirq;
genpd->domain.ops.restore_noirq = pm_genpd_restore_noirq;
- genpd->domain.ops.restore_early = pm_generic_restore_early;
- genpd->domain.ops.restore = pm_generic_restore;
genpd->domain.ops.complete = pm_genpd_complete;
if (genpd->flags & GENPD_FLAG_PM_CLK) {
@@ -1328,7 +1347,71 @@
}
EXPORT_SYMBOL_GPL(pm_genpd_init);
+static int genpd_remove(struct generic_pm_domain *genpd)
+{
+ struct gpd_link *l, *link;
+
+ if (IS_ERR_OR_NULL(genpd))
+ return -EINVAL;
+
+ mutex_lock(&genpd->lock);
+
+ if (genpd->has_provider) {
+ mutex_unlock(&genpd->lock);
+ pr_err("Provider present, unable to remove %s\n", genpd->name);
+ return -EBUSY;
+ }
+
+ if (!list_empty(&genpd->master_links) || genpd->device_count) {
+ mutex_unlock(&genpd->lock);
+ pr_err("%s: unable to remove %s\n", __func__, genpd->name);
+ return -EBUSY;
+ }
+
+ list_for_each_entry_safe(link, l, &genpd->slave_links, slave_node) {
+ list_del(&link->master_node);
+ list_del(&link->slave_node);
+ kfree(link);
+ }
+
+ list_del(&genpd->gpd_list_node);
+ mutex_unlock(&genpd->lock);
+ cancel_work_sync(&genpd->power_off_work);
+ pr_debug("%s: removed %s\n", __func__, genpd->name);
+
+ return 0;
+}
+
+/**
+ * pm_genpd_remove - Remove a generic I/O PM domain
+ * @genpd: Pointer to PM domain that is to be removed.
+ *
+ * To remove the PM domain, this function:
+ * - Removes the PM domain as a subdomain to any parent domains,
+ * if it was added.
+ * - Removes the PM domain from the list of registered PM domains.
+ *
+ * The PM domain will only be removed, if the associated provider has
+ * been removed, it is not a parent to any other PM domain and has no
+ * devices associated with it.
+ */
+int pm_genpd_remove(struct generic_pm_domain *genpd)
+{
+ int ret;
+
+ mutex_lock(&gpd_list_lock);
+ ret = genpd_remove(genpd);
+ mutex_unlock(&gpd_list_lock);
+
+ return ret;
+}
+EXPORT_SYMBOL_GPL(pm_genpd_remove);
+
#ifdef CONFIG_PM_GENERIC_DOMAINS_OF
+
+typedef struct generic_pm_domain *(*genpd_xlate_t)(struct of_phandle_args *args,
+ void *data);
+
/*
* Device Tree based PM domain providers.
*
@@ -1340,8 +1423,8 @@
* maps a PM domain specifier retrieved from the device tree to a PM domain.
*
* Two simple mapping functions have been provided for convenience:
- * - __of_genpd_xlate_simple() for 1:1 device tree node to PM domain mapping.
- * - __of_genpd_xlate_onecell() for mapping of multiple PM domains per node by
+ * - genpd_xlate_simple() for 1:1 device tree node to PM domain mapping.
+ * - genpd_xlate_onecell() for mapping of multiple PM domains per node by
* index.
*/
@@ -1366,7 +1449,7 @@
static DEFINE_MUTEX(of_genpd_mutex);
/**
- * __of_genpd_xlate_simple() - Xlate function for direct node-domain mapping
+ * genpd_xlate_simple() - Xlate function for direct node-domain mapping
* @genpdspec: OF phandle args to map into a PM domain
* @data: xlate function private data - pointer to struct generic_pm_domain
*
@@ -1374,7 +1457,7 @@
* have their own device tree nodes. The private data of xlate function needs
* to be a valid pointer to struct generic_pm_domain.
*/
-struct generic_pm_domain *__of_genpd_xlate_simple(
+static struct generic_pm_domain *genpd_xlate_simple(
struct of_phandle_args *genpdspec,
void *data)
{
@@ -1382,10 +1465,9 @@
return ERR_PTR(-EINVAL);
return data;
}
-EXPORT_SYMBOL_GPL(__of_genpd_xlate_simple);
/**
- * __of_genpd_xlate_onecell() - Xlate function using a single index.
+ * genpd_xlate_onecell() - Xlate function using a single index.
* @genpdspec: OF phandle args to map into a PM domain
* @data: xlate function private data - pointer to struct genpd_onecell_data
*
@@ -1394,7 +1476,7 @@
* A single cell is used as an index into an array of PM domains specified in
* the genpd_onecell_data struct when registering the provider.
*/
-struct generic_pm_domain *__of_genpd_xlate_onecell(
+static struct generic_pm_domain *genpd_xlate_onecell(
struct of_phandle_args *genpdspec,
void *data)
{
@@ -1414,16 +1496,15 @@
return genpd_data->domains[idx];
}
-EXPORT_SYMBOL_GPL(__of_genpd_xlate_onecell);
/**
- * __of_genpd_add_provider() - Register a PM domain provider for a node
+ * genpd_add_provider() - Register a PM domain provider for a node
* @np: Device node pointer associated with the PM domain provider.
* @xlate: Callback for decoding PM domain from phandle arguments.
* @data: Context pointer for @xlate callback.
*/
-int __of_genpd_add_provider(struct device_node *np, genpd_xlate_t xlate,
- void *data)
+static int genpd_add_provider(struct device_node *np, genpd_xlate_t xlate,
+ void *data)
{
struct of_genpd_provider *cp;
@@ -1442,7 +1523,83 @@
return 0;
}
-EXPORT_SYMBOL_GPL(__of_genpd_add_provider);
+
+/**
+ * of_genpd_add_provider_simple() - Register a simple PM domain provider
+ * @np: Device node pointer associated with the PM domain provider.
+ * @genpd: Pointer to PM domain associated with the PM domain provider.
+ */
+int of_genpd_add_provider_simple(struct device_node *np,
+ struct generic_pm_domain *genpd)
+{
+ int ret = -EINVAL;
+
+ if (!np || !genpd)
+ return -EINVAL;
+
+ mutex_lock(&gpd_list_lock);
+
+ if (pm_genpd_present(genpd))
+ ret = genpd_add_provider(np, genpd_xlate_simple, genpd);
+
+ if (!ret) {
+ genpd->provider = &np->fwnode;
+ genpd->has_provider = true;
+ }
+
+ mutex_unlock(&gpd_list_lock);
+
+ return ret;
+}
+EXPORT_SYMBOL_GPL(of_genpd_add_provider_simple);
+
+/**
+ * of_genpd_add_provider_onecell() - Register a onecell PM domain provider
+ * @np: Device node pointer associated with the PM domain provider.
+ * @data: Pointer to the data associated with the PM domain provider.
+ */
+int of_genpd_add_provider_onecell(struct device_node *np,
+ struct genpd_onecell_data *data)
+{
+ unsigned int i;
+ int ret = -EINVAL;
+
+ if (!np || !data)
+ return -EINVAL;
+
+ mutex_lock(&gpd_list_lock);
+
+ for (i = 0; i < data->num_domains; i++) {
+ if (!data->domains[i])
+ continue;
+ if (!pm_genpd_present(data->domains[i]))
+ goto error;
+
+ data->domains[i]->provider = &np->fwnode;
+ data->domains[i]->has_provider = true;
+ }
+
+ ret = genpd_add_provider(np, genpd_xlate_onecell, data);
+ if (ret < 0)
+ goto error;
+
+ mutex_unlock(&gpd_list_lock);
+
+ return 0;
+
+error:
+ while (i--) {
+ if (!data->domains[i])
+ continue;
+ data->domains[i]->provider = NULL;
+ data->domains[i]->has_provider = false;
+ }
+
+ mutex_unlock(&gpd_list_lock);
+
+ return ret;
+}
+EXPORT_SYMBOL_GPL(of_genpd_add_provider_onecell);
/**
* of_genpd_del_provider() - Remove a previously registered PM domain provider
@@ -1451,10 +1608,21 @@
void of_genpd_del_provider(struct device_node *np)
{
struct of_genpd_provider *cp;
+ struct generic_pm_domain *gpd;
+ mutex_lock(&gpd_list_lock);
mutex_lock(&of_genpd_mutex);
list_for_each_entry(cp, &of_genpd_providers, link) {
if (cp->node == np) {
+ /*
+ * For each PM domain associated with the
+ * provider, set the 'has_provider' to false
+ * so that the PM domain can be safely removed.
+ */
+ list_for_each_entry(gpd, &gpd_list, gpd_list_node)
+ if (gpd->provider == &np->fwnode)
+ gpd->has_provider = false;
+
list_del(&cp->link);
of_node_put(cp->node);
kfree(cp);
@@ -1462,11 +1630,12 @@
}
}
mutex_unlock(&of_genpd_mutex);
+ mutex_unlock(&gpd_list_lock);
}
EXPORT_SYMBOL_GPL(of_genpd_del_provider);
/**
- * of_genpd_get_from_provider() - Look-up PM domain
+ * genpd_get_from_provider() - Look-up PM domain
* @genpdspec: OF phandle args to use for look-up
*
* Looks for a PM domain provider under the node specified by @genpdspec and if
@@ -1476,7 +1645,7 @@
* Returns a valid pointer to struct generic_pm_domain on success or ERR_PTR()
* on failure.
*/
-struct generic_pm_domain *of_genpd_get_from_provider(
+static struct generic_pm_domain *genpd_get_from_provider(
struct of_phandle_args *genpdspec)
{
struct generic_pm_domain *genpd = ERR_PTR(-ENOENT);
@@ -1499,7 +1668,109 @@
return genpd;
}
-EXPORT_SYMBOL_GPL(of_genpd_get_from_provider);
+
+/**
+ * of_genpd_add_device() - Add a device to an I/O PM domain
+ * @genpdspec: OF phandle args to use for look-up PM domain
+ * @dev: Device to be added.
+ *
+ * Looks-up an I/O PM domain based upon phandle args provided and adds
+ * the device to the PM domain. Returns a negative error code on failure.
+ */
+int of_genpd_add_device(struct of_phandle_args *genpdspec, struct device *dev)
+{
+ struct generic_pm_domain *genpd;
+ int ret;
+
+ mutex_lock(&gpd_list_lock);
+
+ genpd = genpd_get_from_provider(genpdspec);
+ if (IS_ERR(genpd)) {
+ ret = PTR_ERR(genpd);
+ goto out;
+ }
+
+ ret = genpd_add_device(genpd, dev, NULL);
+
+out:
+ mutex_unlock(&gpd_list_lock);
+
+ return ret;
+}
+EXPORT_SYMBOL_GPL(of_genpd_add_device);
+
+/**
+ * of_genpd_add_subdomain - Add a subdomain to an I/O PM domain.
+ * @parent_spec: OF phandle args to use for parent PM domain look-up
+ * @subdomain_spec: OF phandle args to use for subdomain look-up
+ *
+ * Looks-up a parent PM domain and subdomain based upon phandle args
+ * provided and adds the subdomain to the parent PM domain. Returns a
+ * negative error code on failure.
+ */
+int of_genpd_add_subdomain(struct of_phandle_args *parent_spec,
+ struct of_phandle_args *subdomain_spec)
+{
+ struct generic_pm_domain *parent, *subdomain;
+ int ret;
+
+ mutex_lock(&gpd_list_lock);
+
+ parent = genpd_get_from_provider(parent_spec);
+ if (IS_ERR(parent)) {
+ ret = PTR_ERR(parent);
+ goto out;
+ }
+
+ subdomain = genpd_get_from_provider(subdomain_spec);
+ if (IS_ERR(subdomain)) {
+ ret = PTR_ERR(subdomain);
+ goto out;
+ }
+
+ ret = genpd_add_subdomain(parent, subdomain);
+
+out:
+ mutex_unlock(&gpd_list_lock);
+
+ return ret;
+}
+EXPORT_SYMBOL_GPL(of_genpd_add_subdomain);
+
+/**
+ * of_genpd_remove_last - Remove the last PM domain registered for a provider
+ * @provider: Pointer to device structure associated with provider
+ *
+ * Find the last PM domain that was added by a particular provider and
+ * remove this PM domain from the list of PM domains. The provider is
+ * identified by the 'provider' device structure that is passed. The PM
+ * domain will only be removed, if the provider associated with domain
+ * has been removed.
+ *
+ * Returns a valid pointer to struct generic_pm_domain on success or
+ * ERR_PTR() on failure.
+ */
+struct generic_pm_domain *of_genpd_remove_last(struct device_node *np)
+{
+ struct generic_pm_domain *gpd, *genpd = ERR_PTR(-ENOENT);
+ int ret;
+
+ if (IS_ERR_OR_NULL(np))
+ return ERR_PTR(-EINVAL);
+
+ mutex_lock(&gpd_list_lock);
+ list_for_each_entry(gpd, &gpd_list, gpd_list_node) {
+ if (gpd->provider == &np->fwnode) {
+ ret = genpd_remove(gpd);
+ genpd = ret ? ERR_PTR(ret) : gpd;
+ break;
+ }
+ }
+ mutex_unlock(&gpd_list_lock);
+
+ return genpd;
+}
+EXPORT_SYMBOL_GPL(of_genpd_remove_last);
/**
* genpd_dev_pm_detach - Detach a device from its PM domain.
@@ -1515,14 +1786,14 @@
unsigned int i;
int ret = 0;
- pd = pm_genpd_lookup_dev(dev);
- if (!pd)
+ pd = dev_to_genpd(dev);
+ if (IS_ERR(pd))
return;
dev_dbg(dev, "removing from PM domain %s\n", pd->name);
for (i = 1; i < GENPD_RETRY_MAX_MS; i <<= 1) {
- ret = pm_genpd_remove_device(pd, dev);
+ ret = genpd_remove_device(pd, dev);
if (ret != -EAGAIN)
break;
@@ -1596,9 +1867,11 @@
return -ENOENT;
}
- pd = of_genpd_get_from_provider(&pd_args);
+ mutex_lock(&gpd_list_lock);
+ pd = genpd_get_from_provider(&pd_args);
of_node_put(pd_args.np);
if (IS_ERR(pd)) {
+ mutex_unlock(&gpd_list_lock);
dev_dbg(dev, "%s() failed to find PM domain: %ld\n",
__func__, PTR_ERR(pd));
return -EPROBE_DEFER;
@@ -1607,13 +1880,14 @@
dev_dbg(dev, "adding to PM domain %s\n", pd->name);
for (i = 1; i < GENPD_RETRY_MAX_MS; i <<= 1) {
- ret = pm_genpd_add_device(pd, dev);
+ ret = genpd_add_device(pd, dev, NULL);
if (ret != -EAGAIN)
break;
mdelay(i);
cond_resched();
}
+ mutex_unlock(&gpd_list_lock);
if (ret < 0) {
dev_err(dev, "failed to add to PM domain %s: %d",
@@ -1636,7 +1910,7 @@
/*** debugfs support ***/
-#ifdef CONFIG_PM_ADVANCED_DEBUG
+#ifdef CONFIG_DEBUG_FS
#include <linux/pm.h>
#include <linux/device.h>
#include <linux/debugfs.h>
@@ -1784,4 +2058,4 @@
debugfs_remove_recursive(pm_genpd_debugfs_dir);
}
__exitcall(pm_genpd_debug_exit);
-#endif /* CONFIG_PM_ADVANCED_DEBUG */
+#endif /* CONFIG_DEBUG_FS */
diff --git a/drivers/base/power/opp/core.c b/drivers/base/power/opp/core.c
index df0c709..4c7c6da 100644
--- a/drivers/base/power/opp/core.c
+++ b/drivers/base/power/opp/core.c
@@ -584,7 +584,6 @@
struct clk *clk;
unsigned long freq, old_freq;
unsigned long u_volt, u_volt_min, u_volt_max;
- unsigned long ou_volt, ou_volt_min, ou_volt_max;
int ret;
if (unlikely(!target_freq)) {
@@ -620,11 +619,7 @@
}
old_opp = _find_freq_ceil(opp_table, &old_freq);
- if (!IS_ERR(old_opp)) {
- ou_volt = old_opp->u_volt;
- ou_volt_min = old_opp->u_volt_min;
- ou_volt_max = old_opp->u_volt_max;
- } else {
+ if (IS_ERR(old_opp)) {
dev_err(dev, "%s: failed to find current OPP for freq %lu (%ld)\n",
__func__, old_freq, PTR_ERR(old_opp));
}
@@ -683,7 +678,8 @@
restore_voltage:
/* This shouldn't harm even if the voltages weren't updated earlier */
if (!IS_ERR(old_opp))
- _set_opp_voltage(dev, reg, ou_volt, ou_volt_min, ou_volt_max);
+ _set_opp_voltage(dev, reg, old_opp->u_volt,
+ old_opp->u_volt_min, old_opp->u_volt_max);
return ret;
}
diff --git a/drivers/base/power/opp/of.c b/drivers/base/power/opp/of.c
index 1dfd3dd..5552211 100644
--- a/drivers/base/power/opp/of.c
+++ b/drivers/base/power/opp/of.c
@@ -71,8 +71,18 @@
u32 version;
int ret;
- if (!opp_table->supported_hw)
- return true;
+ if (!opp_table->supported_hw) {
+ /*
+ * In the case that no supported_hw has been set by the
+ * platform but there is an opp-supported-hw value set for
+ * an OPP then the OPP should not be enabled as there is
+ * no way to see if the hardware supports it.
+ */
+ if (of_find_property(np, "opp-supported-hw", NULL))
+ return false;
+ else
+ return true;
+ }
while (count--) {
ret = of_property_read_u32_index(np, "opp-supported-hw", count,
diff --git a/drivers/base/regmap/regmap.c b/drivers/base/regmap/regmap.c
index 25d26bb..e964d06 100644
--- a/drivers/base/regmap/regmap.c
+++ b/drivers/base/regmap/regmap.c
@@ -1475,7 +1475,11 @@
kfree(buf);
} else if (ret != 0 && !map->cache_bypass && map->format.parse_val) {
- regcache_drop_region(map, reg, reg + 1);
+ /* regcache_drop_region() takes lock that we already have,
+ * thus call map->cache_ops->drop() directly
+ */
+ if (map->cache_ops && map->cache_ops->drop)
+ map->cache_ops->drop(map, reg, reg + 1);
}
trace_regmap_hw_write_done(map, reg, val_len / map->format.val_bytes);
diff --git a/drivers/clocksource/Kconfig b/drivers/clocksource/Kconfig
index 5677886..8a753fd 100644
--- a/drivers/clocksource/Kconfig
+++ b/drivers/clocksource/Kconfig
@@ -305,6 +305,16 @@
This must be disabled for hardware validation purposes to detect any
hardware anomalies of missing events.
+config FSL_ERRATUM_A008585
+ bool "Workaround for Freescale/NXP Erratum A-008585"
+ default y
+ depends on ARM_ARCH_TIMER && ARM64
+ help
+ This option enables a workaround for Freescale/NXP Erratum
+ A-008585 ("ARM generic timer may contain an erroneous
+ value"). The workaround will only be active if the
+ fsl,erratum-a008585 property is found in the timer node.
+
config ARM_GLOBAL_TIMER
bool "Support for the ARM global timer" if COMPILE_TEST
select CLKSRC_OF if OF
diff --git a/drivers/clocksource/arm_arch_timer.c b/drivers/clocksource/arm_arch_timer.c
index 5770054..73c487d 100644
--- a/drivers/clocksource/arm_arch_timer.c
+++ b/drivers/clocksource/arm_arch_timer.c
@@ -94,6 +94,43 @@
* Architected system timer support.
*/
+#ifdef CONFIG_FSL_ERRATUM_A008585
+DEFINE_STATIC_KEY_FALSE(arch_timer_read_ool_enabled);
+EXPORT_SYMBOL_GPL(arch_timer_read_ool_enabled);
+
+static int fsl_a008585_enable = -1;
+
+static int __init early_fsl_a008585_cfg(char *buf)
+{
+ int ret;
+ bool val;
+
+ ret = strtobool(buf, &val);
+ if (ret)
+ return ret;
+
+ fsl_a008585_enable = val;
+ return 0;
+}
+early_param("clocksource.arm_arch_timer.fsl-a008585", early_fsl_a008585_cfg);
+
+u32 __fsl_a008585_read_cntp_tval_el0(void)
+{
+ return __fsl_a008585_read_reg(cntp_tval_el0);
+}
+
+u32 __fsl_a008585_read_cntv_tval_el0(void)
+{
+ return __fsl_a008585_read_reg(cntv_tval_el0);
+}
+
+u64 __fsl_a008585_read_cntvct_el0(void)
+{
+ return __fsl_a008585_read_reg(cntvct_el0);
+}
+EXPORT_SYMBOL(__fsl_a008585_read_cntvct_el0);
+#endif /* CONFIG_FSL_ERRATUM_A008585 */
+
static __always_inline
void arch_timer_reg_write(int access, enum arch_timer_reg reg, u32 val,
struct clock_event_device *clk)
@@ -243,6 +280,40 @@
arch_timer_reg_write(access, ARCH_TIMER_REG_CTRL, ctrl, clk);
}
+#ifdef CONFIG_FSL_ERRATUM_A008585
+static __always_inline void fsl_a008585_set_next_event(const int access,
+ unsigned long evt, struct clock_event_device *clk)
+{
+ unsigned long ctrl;
+ u64 cval = evt + arch_counter_get_cntvct();
+
+ ctrl = arch_timer_reg_read(access, ARCH_TIMER_REG_CTRL, clk);
+ ctrl |= ARCH_TIMER_CTRL_ENABLE;
+ ctrl &= ~ARCH_TIMER_CTRL_IT_MASK;
+
+ if (access == ARCH_TIMER_PHYS_ACCESS)
+ write_sysreg(cval, cntp_cval_el0);
+ else if (access == ARCH_TIMER_VIRT_ACCESS)
+ write_sysreg(cval, cntv_cval_el0);
+
+ arch_timer_reg_write(access, ARCH_TIMER_REG_CTRL, ctrl, clk);
+}
+
+static int fsl_a008585_set_next_event_virt(unsigned long evt,
+ struct clock_event_device *clk)
+{
+ fsl_a008585_set_next_event(ARCH_TIMER_VIRT_ACCESS, evt, clk);
+ return 0;
+}
+
+static int fsl_a008585_set_next_event_phys(unsigned long evt,
+ struct clock_event_device *clk)
+{
+ fsl_a008585_set_next_event(ARCH_TIMER_PHYS_ACCESS, evt, clk);
+ return 0;
+}
+#endif /* CONFIG_FSL_ERRATUM_A008585 */
+
static int arch_timer_set_next_event_virt(unsigned long evt,
struct clock_event_device *clk)
{
@@ -271,6 +342,19 @@
return 0;
}
+static void fsl_a008585_set_sne(struct clock_event_device *clk)
+{
+#ifdef CONFIG_FSL_ERRATUM_A008585
+ if (!static_branch_unlikely(&arch_timer_read_ool_enabled))
+ return;
+
+ if (arch_timer_uses_ppi == VIRT_PPI)
+ clk->set_next_event = fsl_a008585_set_next_event_virt;
+ else
+ clk->set_next_event = fsl_a008585_set_next_event_phys;
+#endif
+}
+
static void __arch_timer_setup(unsigned type,
struct clock_event_device *clk)
{
@@ -299,6 +383,8 @@
default:
BUG();
}
+
+ fsl_a008585_set_sne(clk);
} else {
clk->features |= CLOCK_EVT_FEAT_DYNIRQ;
clk->name = "arch_mem_timer";
@@ -515,15 +601,19 @@
arch_timer_read_counter = arch_counter_get_cntvct;
else
arch_timer_read_counter = arch_counter_get_cntpct;
+
+ clocksource_counter.archdata.vdso_direct = true;
+
+#ifdef CONFIG_FSL_ERRATUM_A008585
+ /*
+ * Don't use the vdso fastpath if errata require using
+ * the out-of-line counter accessor.
+ */
+ if (static_branch_unlikely(&arch_timer_read_ool_enabled))
+ clocksource_counter.archdata.vdso_direct = false;
+#endif
} else {
arch_timer_read_counter = arch_counter_get_cntvct_mem;
-
- /* If the clocksource name is "arch_sys_counter" the
- * VDSO will attempt to read the CP15-based counter.
- * Ensure this does not happen when CP15-based
- * counter is not available.
- */
- clocksource_counter.name = "arch_mem_counter";
}
start_count = arch_timer_read_counter();
@@ -800,6 +890,15 @@
arch_timer_c3stop = !of_property_read_bool(np, "always-on");
+#ifdef CONFIG_FSL_ERRATUM_A008585
+ if (fsl_a008585_enable < 0)
+ fsl_a008585_enable = of_property_read_bool(np, "fsl,erratum-a008585");
+ if (fsl_a008585_enable) {
+ static_branch_enable(&arch_timer_read_ool_enabled);
+ pr_info("Enabling workaround for FSL erratum A-008585\n");
+ }
+#endif
+
/*
* If we cannot rely on firmware initializing the timer registers then
* we should use the physical timers instead.
diff --git a/drivers/cpufreq/Kconfig b/drivers/cpufreq/Kconfig
index 74919aa..d8b164a 100644
--- a/drivers/cpufreq/Kconfig
+++ b/drivers/cpufreq/Kconfig
@@ -194,7 +194,7 @@
If in doubt, say N.
config CPU_FREQ_GOV_SCHEDUTIL
- tristate "'schedutil' cpufreq policy governor"
+ bool "'schedutil' cpufreq policy governor"
depends on CPU_FREQ && SMP
select CPU_FREQ_GOV_ATTR_SET
select IRQ_WORK
@@ -208,9 +208,6 @@
frequency tipping point is at utilization/capacity equal to 80% in
both cases.
- To compile this driver as a module, choose M here: the module will
- be called cpufreq_schedutil.
-
If in doubt, say N.
comment "CPU frequency scaling drivers"
@@ -225,7 +222,7 @@
help
This adds a generic DT based cpufreq driver for frequency management.
It supports both uniprocessor (UP) and symmetric multiprocessor (SMP)
- systems which share clock and voltage across all CPUs.
+ systems.
If in doubt, say N.
diff --git a/drivers/cpufreq/cppc_cpufreq.c b/drivers/cpufreq/cppc_cpufreq.c
index 8882b8e..1b2f28f 100644
--- a/drivers/cpufreq/cppc_cpufreq.c
+++ b/drivers/cpufreq/cppc_cpufreq.c
@@ -19,10 +19,19 @@
#include <linux/delay.h>
#include <linux/cpu.h>
#include <linux/cpufreq.h>
+#include <linux/dmi.h>
#include <linux/vmalloc.h>
+#include <asm/unaligned.h>
+
#include <acpi/cppc_acpi.h>
+/* Minimum struct length needed for the DMI processor entry we want */
+#define DMI_ENTRY_PROCESSOR_MIN_LENGTH 48
+
+/* Offest in the DMI processor structure for the max frequency */
+#define DMI_PROCESSOR_MAX_SPEED 0x14
+
/*
* These structs contain information parsed from per CPU
* ACPI _CPC structures.
@@ -30,19 +39,52 @@
* performance capabilities, desired performance level
* requested etc.
*/
-static struct cpudata **all_cpu_data;
+static struct cppc_cpudata **all_cpu_data;
+
+/* Capture the max KHz from DMI */
+static u64 cppc_dmi_max_khz;
+
+/* Callback function used to retrieve the max frequency from DMI */
+static void cppc_find_dmi_mhz(const struct dmi_header *dm, void *private)
+{
+ const u8 *dmi_data = (const u8 *)dm;
+ u16 *mhz = (u16 *)private;
+
+ if (dm->type == DMI_ENTRY_PROCESSOR &&
+ dm->length >= DMI_ENTRY_PROCESSOR_MIN_LENGTH) {
+ u16 val = (u16)get_unaligned((const u16 *)
+ (dmi_data + DMI_PROCESSOR_MAX_SPEED));
+ *mhz = val > *mhz ? val : *mhz;
+ }
+}
+
+/* Look up the max frequency in DMI */
+static u64 cppc_get_dmi_max_khz(void)
+{
+ u16 mhz = 0;
+
+ dmi_walk(cppc_find_dmi_mhz, &mhz);
+
+ /*
+ * Real stupid fallback value, just in case there is no
+ * actual value set.
+ */
+ mhz = mhz ? mhz : 1;
+
+ return (1000 * mhz);
+}
static int cppc_cpufreq_set_target(struct cpufreq_policy *policy,
unsigned int target_freq,
unsigned int relation)
{
- struct cpudata *cpu;
+ struct cppc_cpudata *cpu;
struct cpufreq_freqs freqs;
int ret = 0;
cpu = all_cpu_data[policy->cpu];
- cpu->perf_ctrls.desired_perf = target_freq;
+ cpu->perf_ctrls.desired_perf = (u64)target_freq * policy->max / cppc_dmi_max_khz;
freqs.old = policy->cur;
freqs.new = target_freq;
@@ -66,7 +108,7 @@
static void cppc_cpufreq_stop_cpu(struct cpufreq_policy *policy)
{
int cpu_num = policy->cpu;
- struct cpudata *cpu = all_cpu_data[cpu_num];
+ struct cppc_cpudata *cpu = all_cpu_data[cpu_num];
int ret;
cpu->perf_ctrls.desired_perf = cpu->perf_caps.lowest_perf;
@@ -79,7 +121,7 @@
static int cppc_cpufreq_cpu_init(struct cpufreq_policy *policy)
{
- struct cpudata *cpu;
+ struct cppc_cpudata *cpu;
unsigned int cpu_num = policy->cpu;
int ret = 0;
@@ -94,10 +136,13 @@
return ret;
}
- policy->min = cpu->perf_caps.lowest_perf;
- policy->max = cpu->perf_caps.highest_perf;
+ cppc_dmi_max_khz = cppc_get_dmi_max_khz();
+
+ policy->min = cpu->perf_caps.lowest_perf * cppc_dmi_max_khz / cpu->perf_caps.highest_perf;
+ policy->max = cppc_dmi_max_khz;
policy->cpuinfo.min_freq = policy->min;
policy->cpuinfo.max_freq = policy->max;
+ policy->cpuinfo.transition_latency = cppc_get_transition_latency(cpu_num);
policy->shared_type = cpu->shared_type;
if (policy->shared_type == CPUFREQ_SHARED_TYPE_ANY)
@@ -112,7 +157,8 @@
cpu->cur_policy = policy;
/* Set policy->cur to max now. The governors will adjust later. */
- policy->cur = cpu->perf_ctrls.desired_perf = cpu->perf_caps.highest_perf;
+ policy->cur = cppc_dmi_max_khz;
+ cpu->perf_ctrls.desired_perf = cpu->perf_caps.highest_perf;
ret = cppc_set_perf(cpu_num, &cpu->perf_ctrls);
if (ret)
@@ -134,7 +180,7 @@
static int __init cppc_cpufreq_init(void)
{
int i, ret = 0;
- struct cpudata *cpu;
+ struct cppc_cpudata *cpu;
if (acpi_disabled)
return -ENODEV;
@@ -144,7 +190,7 @@
return -ENOMEM;
for_each_possible_cpu(i) {
- all_cpu_data[i] = kzalloc(sizeof(struct cpudata), GFP_KERNEL);
+ all_cpu_data[i] = kzalloc(sizeof(struct cppc_cpudata), GFP_KERNEL);
if (!all_cpu_data[i])
goto out;
@@ -175,7 +221,7 @@
static void __exit cppc_cpufreq_exit(void)
{
- struct cpudata *cpu;
+ struct cppc_cpudata *cpu;
int i;
cpufreq_unregister_driver(&cppc_cpufreq_driver);
diff --git a/drivers/cpufreq/cpufreq-dt-platdev.c b/drivers/cpufreq/cpufreq-dt-platdev.c
index 2ee40fd..7126762 100644
--- a/drivers/cpufreq/cpufreq-dt-platdev.c
+++ b/drivers/cpufreq/cpufreq-dt-platdev.c
@@ -11,6 +11,8 @@
#include <linux/of.h>
#include <linux/platform_device.h>
+#include "cpufreq-dt.h"
+
static const struct of_device_id machines[] __initconst = {
{ .compatible = "allwinner,sun4i-a10", },
{ .compatible = "allwinner,sun5i-a10s", },
@@ -40,6 +42,7 @@
{ .compatible = "samsung,exynos5250", },
#ifndef CONFIG_BL_SWITCHER
{ .compatible = "samsung,exynos5420", },
+ { .compatible = "samsung,exynos5433", },
{ .compatible = "samsung,exynos5800", },
#endif
@@ -51,6 +54,7 @@
{ .compatible = "renesas,r8a7779", },
{ .compatible = "renesas,r8a7790", },
{ .compatible = "renesas,r8a7791", },
+ { .compatible = "renesas,r8a7792", },
{ .compatible = "renesas,r8a7793", },
{ .compatible = "renesas,r8a7794", },
{ .compatible = "renesas,sh73a0", },
@@ -68,6 +72,8 @@
{ .compatible = "sigma,tango4" },
+ { .compatible = "ti,am33xx", },
+ { .compatible = "ti,dra7", },
{ .compatible = "ti,omap2", },
{ .compatible = "ti,omap3", },
{ .compatible = "ti,omap4", },
@@ -91,7 +97,8 @@
if (!match)
return -ENODEV;
- return PTR_ERR_OR_ZERO(platform_device_register_simple("cpufreq-dt", -1,
- NULL, 0));
+ return PTR_ERR_OR_ZERO(platform_device_register_data(NULL, "cpufreq-dt",
+ -1, match->data,
+ sizeof(struct cpufreq_dt_platform_data)));
}
device_initcall(cpufreq_dt_platdev_init);
diff --git a/drivers/cpufreq/cpufreq-dt.c b/drivers/cpufreq/cpufreq-dt.c
index 3957de8..5c07ae0 100644
--- a/drivers/cpufreq/cpufreq-dt.c
+++ b/drivers/cpufreq/cpufreq-dt.c
@@ -25,6 +25,8 @@
#include <linux/slab.h>
#include <linux/thermal.h>
+#include "cpufreq-dt.h"
+
struct private_data {
struct device *cpu_dev;
struct thermal_cooling_device *cdev;
@@ -353,6 +355,7 @@
static int dt_cpufreq_probe(struct platform_device *pdev)
{
+ struct cpufreq_dt_platform_data *data = dev_get_platdata(&pdev->dev);
int ret;
/*
@@ -366,7 +369,8 @@
if (ret)
return ret;
- dt_cpufreq_driver.driver_data = dev_get_platdata(&pdev->dev);
+ if (data && data->have_governor_per_policy)
+ dt_cpufreq_driver.flags |= CPUFREQ_HAVE_GOVERNOR_PER_POLICY;
ret = cpufreq_register_driver(&dt_cpufreq_driver);
if (ret)
diff --git a/drivers/cpufreq/cpufreq-dt.h b/drivers/cpufreq/cpufreq-dt.h
new file mode 100644
index 0000000..54d774e
--- /dev/null
+++ b/drivers/cpufreq/cpufreq-dt.h
@@ -0,0 +1,19 @@
+/*
+ * Copyright (C) 2016 Linaro
+ * Viresh Kumar <viresh.kumar@linaro.org>
+ *
+ * This program is free software; you can redistribute it and/or modify
+ * it under the terms of the GNU General Public License version 2 as
+ * published by the Free Software Foundation.
+ */
+
+#ifndef __CPUFREQ_DT_H__
+#define __CPUFREQ_DT_H__
+
+#include <linux/types.h>
+
+struct cpufreq_dt_platform_data {
+ bool have_governor_per_policy;
+};
+
+#endif /* __CPUFREQ_DT_H__ */
diff --git a/drivers/cpufreq/cpufreq.c b/drivers/cpufreq/cpufreq.c
index 3dd4884..3a64136 100644
--- a/drivers/cpufreq/cpufreq.c
+++ b/drivers/cpufreq/cpufreq.c
@@ -916,58 +916,18 @@
.release = cpufreq_sysfs_release,
};
-static int add_cpu_dev_symlink(struct cpufreq_policy *policy, int cpu)
+static int add_cpu_dev_symlink(struct cpufreq_policy *policy,
+ struct device *dev)
{
- struct device *cpu_dev;
-
- pr_debug("%s: Adding symlink for CPU: %u\n", __func__, cpu);
-
- if (!policy)
- return 0;
-
- cpu_dev = get_cpu_device(cpu);
- if (WARN_ON(!cpu_dev))
- return 0;
-
- return sysfs_create_link(&cpu_dev->kobj, &policy->kobj, "cpufreq");
+ dev_dbg(dev, "%s: Adding symlink\n", __func__);
+ return sysfs_create_link(&dev->kobj, &policy->kobj, "cpufreq");
}
-static void remove_cpu_dev_symlink(struct cpufreq_policy *policy, int cpu)
+static void remove_cpu_dev_symlink(struct cpufreq_policy *policy,
+ struct device *dev)
{
- struct device *cpu_dev;
-
- pr_debug("%s: Removing symlink for CPU: %u\n", __func__, cpu);
-
- cpu_dev = get_cpu_device(cpu);
- if (WARN_ON(!cpu_dev))
- return;
-
- sysfs_remove_link(&cpu_dev->kobj, "cpufreq");
-}
-
-/* Add/remove symlinks for all related CPUs */
-static int cpufreq_add_dev_symlink(struct cpufreq_policy *policy)
-{
- unsigned int j;
- int ret = 0;
-
- /* Some related CPUs might not be present (physically hotplugged) */
- for_each_cpu(j, policy->real_cpus) {
- ret = add_cpu_dev_symlink(policy, j);
- if (ret)
- break;
- }
-
- return ret;
-}
-
-static void cpufreq_remove_dev_symlink(struct cpufreq_policy *policy)
-{
- unsigned int j;
-
- /* Some related CPUs might not be present (physically hotplugged) */
- for_each_cpu(j, policy->real_cpus)
- remove_cpu_dev_symlink(policy, j);
+ dev_dbg(dev, "%s: Removing symlink\n", __func__);
+ sysfs_remove_link(&dev->kobj, "cpufreq");
}
static int cpufreq_add_dev_interface(struct cpufreq_policy *policy)
@@ -999,7 +959,7 @@
return ret;
}
- return cpufreq_add_dev_symlink(policy);
+ return 0;
}
__weak struct cpufreq_governor *cpufreq_default_governor(void)
@@ -1073,13 +1033,9 @@
static struct cpufreq_policy *cpufreq_policy_alloc(unsigned int cpu)
{
- struct device *dev = get_cpu_device(cpu);
struct cpufreq_policy *policy;
int ret;
- if (WARN_ON(!dev))
- return NULL;
-
policy = kzalloc(sizeof(*policy), GFP_KERNEL);
if (!policy)
return NULL;
@@ -1133,7 +1089,6 @@
down_write(&policy->rwsem);
cpufreq_stats_free_table(policy);
- cpufreq_remove_dev_symlink(policy);
kobj = &policy->kobj;
cmp = &policy->kobj_unregister;
up_write(&policy->rwsem);
@@ -1215,8 +1170,8 @@
if (new_policy) {
/* related_cpus should at least include policy->cpus. */
cpumask_copy(policy->related_cpus, policy->cpus);
- /* Remember CPUs present at the policy creation time. */
- cpumask_and(policy->real_cpus, policy->cpus, cpu_present_mask);
+ /* Clear mask of registered CPUs */
+ cpumask_clear(policy->real_cpus);
}
/*
@@ -1331,6 +1286,8 @@
return ret;
}
+static void cpufreq_offline(unsigned int cpu);
+
/**
* cpufreq_add_dev - the cpufreq interface for a CPU device.
* @dev: CPU device.
@@ -1340,22 +1297,28 @@
{
struct cpufreq_policy *policy;
unsigned cpu = dev->id;
+ int ret;
dev_dbg(dev, "%s: adding CPU%u\n", __func__, cpu);
- if (cpu_online(cpu))
- return cpufreq_online(cpu);
+ if (cpu_online(cpu)) {
+ ret = cpufreq_online(cpu);
+ if (ret)
+ return ret;
+ }
- /*
- * A hotplug notifier will follow and we will handle it as CPU online
- * then. For now, just create the sysfs link, unless there is no policy
- * or the link is already present.
- */
+ /* Create sysfs link on CPU registration */
policy = per_cpu(cpufreq_cpu_data, cpu);
if (!policy || cpumask_test_and_set_cpu(cpu, policy->real_cpus))
return 0;
- return add_cpu_dev_symlink(policy, cpu);
+ ret = add_cpu_dev_symlink(policy, dev);
+ if (ret) {
+ cpumask_clear_cpu(cpu, policy->real_cpus);
+ cpufreq_offline(cpu);
+ }
+
+ return ret;
}
static void cpufreq_offline(unsigned int cpu)
@@ -1436,7 +1399,7 @@
cpufreq_offline(cpu);
cpumask_clear_cpu(cpu, policy->real_cpus);
- remove_cpu_dev_symlink(policy, cpu);
+ remove_cpu_dev_symlink(policy, dev);
if (cpumask_empty(policy->real_cpus))
cpufreq_policy_free(policy, true);
diff --git a/drivers/cpufreq/cpufreq_governor.c b/drivers/cpufreq/cpufreq_governor.c
index e415349..642dd0f 100644
--- a/drivers/cpufreq/cpufreq_governor.c
+++ b/drivers/cpufreq/cpufreq_governor.c
@@ -260,7 +260,7 @@
}
static void dbs_update_util_handler(struct update_util_data *data, u64 time,
- unsigned long util, unsigned long max)
+ unsigned int flags)
{
struct cpu_dbs_info *cdbs = container_of(data, struct cpu_dbs_info, update_util);
struct policy_dbs_info *policy_dbs = cdbs->policy_dbs;
diff --git a/drivers/cpufreq/intel_pstate.c b/drivers/cpufreq/intel_pstate.c
index be9eade..806f203 100644
--- a/drivers/cpufreq/intel_pstate.c
+++ b/drivers/cpufreq/intel_pstate.c
@@ -181,6 +181,8 @@
* @cpu: CPU number for this instance data
* @update_util: CPUFreq utility callback information
* @update_util_set: CPUFreq utility callback is set
+ * @iowait_boost: iowait-related boost fraction
+ * @last_update: Time of the last update.
* @pstate: Stores P state limits for this CPU
* @vid: Stores VID limits for this CPU
* @pid: Stores PID parameters for this CPU
@@ -206,6 +208,7 @@
struct vid_data vid;
struct _pid pid;
+ u64 last_update;
u64 last_sample_time;
u64 prev_aperf;
u64 prev_mperf;
@@ -216,6 +219,7 @@
struct acpi_processor_performance acpi_perf_data;
bool valid_pss_table;
#endif
+ unsigned int iowait_boost;
};
static struct cpudata **all_cpu_data;
@@ -229,6 +233,7 @@
* @p_gain_pct: PID proportional gain
* @i_gain_pct: PID integral gain
* @d_gain_pct: PID derivative gain
+ * @boost_iowait: Whether or not to use iowait boosting.
*
* Stores per CPU model static PID configuration data.
*/
@@ -240,6 +245,7 @@
int p_gain_pct;
int d_gain_pct;
int i_gain_pct;
+ bool boost_iowait;
};
/**
@@ -1029,7 +1035,7 @@
},
};
-static struct cpu_defaults silvermont_params = {
+static const struct cpu_defaults silvermont_params = {
.pid_policy = {
.sample_rate_ms = 10,
.deadband = 0,
@@ -1037,6 +1043,7 @@
.p_gain_pct = 14,
.d_gain_pct = 0,
.i_gain_pct = 4,
+ .boost_iowait = true,
},
.funcs = {
.get_max = atom_get_max_pstate,
@@ -1050,7 +1057,7 @@
},
};
-static struct cpu_defaults airmont_params = {
+static const struct cpu_defaults airmont_params = {
.pid_policy = {
.sample_rate_ms = 10,
.deadband = 0,
@@ -1058,6 +1065,7 @@
.p_gain_pct = 14,
.d_gain_pct = 0,
.i_gain_pct = 4,
+ .boost_iowait = true,
},
.funcs = {
.get_max = atom_get_max_pstate,
@@ -1071,7 +1079,7 @@
},
};
-static struct cpu_defaults knl_params = {
+static const struct cpu_defaults knl_params = {
.pid_policy = {
.sample_rate_ms = 10,
.deadband = 0,
@@ -1091,7 +1099,7 @@
},
};
-static struct cpu_defaults bxt_params = {
+static const struct cpu_defaults bxt_params = {
.pid_policy = {
.sample_rate_ms = 10,
.deadband = 0,
@@ -1099,6 +1107,7 @@
.p_gain_pct = 14,
.d_gain_pct = 0,
.i_gain_pct = 4,
+ .boost_iowait = true,
},
.funcs = {
.get_max = core_get_max_pstate,
@@ -1222,36 +1231,18 @@
static inline int32_t get_target_pstate_use_cpu_load(struct cpudata *cpu)
{
struct sample *sample = &cpu->sample;
- u64 cummulative_iowait, delta_iowait_us;
- u64 delta_iowait_mperf;
- u64 mperf, now;
- int32_t cpu_load;
+ int32_t busy_frac, boost;
- cummulative_iowait = get_cpu_iowait_time_us(cpu->cpu, &now);
+ busy_frac = div_fp(sample->mperf, sample->tsc);
- /*
- * Convert iowait time into number of IO cycles spent at max_freq.
- * IO is considered as busy only for the cpu_load algorithm. For
- * performance this is not needed since we always try to reach the
- * maximum P-State, so we are already boosting the IOs.
- */
- delta_iowait_us = cummulative_iowait - cpu->prev_cummulative_iowait;
- delta_iowait_mperf = div64_u64(delta_iowait_us * cpu->pstate.scaling *
- cpu->pstate.max_pstate, MSEC_PER_SEC);
+ boost = cpu->iowait_boost;
+ cpu->iowait_boost >>= 1;
- mperf = cpu->sample.mperf + delta_iowait_mperf;
- cpu->prev_cummulative_iowait = cummulative_iowait;
+ if (busy_frac < boost)
+ busy_frac = boost;
- /*
- * The load can be estimated as the ratio of the mperf counter
- * running at a constant frequency during active periods
- * (C0) and the time stamp counter running at the same frequency
- * also during C-states.
- */
- cpu_load = div64_u64(int_tofp(100) * mperf, sample->tsc);
- cpu->sample.busy_scaled = cpu_load;
-
- return get_avg_pstate(cpu) - pid_calc(&cpu->pid, cpu_load);
+ sample->busy_scaled = busy_frac * 100;
+ return get_avg_pstate(cpu) - pid_calc(&cpu->pid, sample->busy_scaled);
}
static inline int32_t get_target_pstate_use_performance(struct cpudata *cpu)
@@ -1325,15 +1316,29 @@
sample->mperf,
sample->aperf,
sample->tsc,
- get_avg_frequency(cpu));
+ get_avg_frequency(cpu),
+ fp_toint(cpu->iowait_boost * 100));
}
static void intel_pstate_update_util(struct update_util_data *data, u64 time,
- unsigned long util, unsigned long max)
+ unsigned int flags)
{
struct cpudata *cpu = container_of(data, struct cpudata, update_util);
- u64 delta_ns = time - cpu->sample.time;
+ u64 delta_ns;
+ if (pid_params.boost_iowait) {
+ if (flags & SCHED_CPUFREQ_IOWAIT) {
+ cpu->iowait_boost = int_tofp(1);
+ } else if (cpu->iowait_boost) {
+ /* Clear iowait_boost if the CPU may have been idle. */
+ delta_ns = time - cpu->last_update;
+ if (delta_ns > TICK_NSEC)
+ cpu->iowait_boost = 0;
+ }
+ cpu->last_update = time;
+ }
+
+ delta_ns = time - cpu->sample.time;
if ((s64)delta_ns >= pid_params.sample_rate_ns) {
bool sample_taken = intel_pstate_sample(cpu, time);
diff --git a/drivers/cpufreq/kirkwood-cpufreq.c b/drivers/cpufreq/kirkwood-cpufreq.c
index be42f10..1b9bcd7 100644
--- a/drivers/cpufreq/kirkwood-cpufreq.c
+++ b/drivers/cpufreq/kirkwood-cpufreq.c
@@ -123,7 +123,7 @@
priv.cpu_clk = of_clk_get_by_name(np, "cpu_clk");
if (IS_ERR(priv.cpu_clk)) {
- dev_err(priv.dev, "Unable to get cpuclk");
+ dev_err(priv.dev, "Unable to get cpuclk\n");
return PTR_ERR(priv.cpu_clk);
}
@@ -132,7 +132,7 @@
priv.ddr_clk = of_clk_get_by_name(np, "ddrclk");
if (IS_ERR(priv.ddr_clk)) {
- dev_err(priv.dev, "Unable to get ddrclk");
+ dev_err(priv.dev, "Unable to get ddrclk\n");
err = PTR_ERR(priv.ddr_clk);
goto out_cpu;
}
@@ -142,7 +142,7 @@
priv.powersave_clk = of_clk_get_by_name(np, "powersave");
if (IS_ERR(priv.powersave_clk)) {
- dev_err(priv.dev, "Unable to get powersave");
+ dev_err(priv.dev, "Unable to get powersave\n");
err = PTR_ERR(priv.powersave_clk);
goto out_ddr;
}
@@ -155,7 +155,7 @@
if (!err)
return 0;
- dev_err(priv.dev, "Failed to register cpufreq driver");
+ dev_err(priv.dev, "Failed to register cpufreq driver\n");
clk_disable_unprepare(priv.powersave_clk);
out_ddr:
diff --git a/drivers/cpufreq/scpi-cpufreq.c b/drivers/cpufreq/scpi-cpufreq.c
index e8a7bf5..ea7a4e1 100644
--- a/drivers/cpufreq/scpi-cpufreq.c
+++ b/drivers/cpufreq/scpi-cpufreq.c
@@ -105,7 +105,6 @@
static struct platform_driver scpi_cpufreq_platdrv = {
.driver = {
.name = "scpi-cpufreq",
- .owner = THIS_MODULE,
},
.probe = scpi_cpufreq_probe,
.remove = scpi_cpufreq_remove,
diff --git a/drivers/cpufreq/sti-cpufreq.c b/drivers/cpufreq/sti-cpufreq.c
index 0404203..b366e6d 100644
--- a/drivers/cpufreq/sti-cpufreq.c
+++ b/drivers/cpufreq/sti-cpufreq.c
@@ -163,7 +163,7 @@
reg_fields = sti_cpufreq_match();
if (!reg_fields) {
- dev_err(dev, "This SoC doesn't support voltage scaling");
+ dev_err(dev, "This SoC doesn't support voltage scaling\n");
return -ENODEV;
}
diff --git a/drivers/cpuidle/cpuidle-arm.c b/drivers/cpuidle/cpuidle-arm.c
index 4ba3d3f..f440d38 100644
--- a/drivers/cpuidle/cpuidle-arm.c
+++ b/drivers/cpuidle/cpuidle-arm.c
@@ -121,6 +121,7 @@
dev = kzalloc(sizeof(*dev), GFP_KERNEL);
if (!dev) {
pr_err("Failed to allocate cpuidle device\n");
+ ret = -ENOMEM;
goto out_fail;
}
dev->cpu = cpu;
diff --git a/drivers/devfreq/Kconfig b/drivers/devfreq/Kconfig
index a5be56e..41254e7 100644
--- a/drivers/devfreq/Kconfig
+++ b/drivers/devfreq/Kconfig
@@ -76,7 +76,7 @@
config ARM_EXYNOS_BUS_DEVFREQ
tristate "ARM EXYNOS Generic Memory Bus DEVFREQ Driver"
- depends on ARCH_EXYNOS
+ depends on ARCH_EXYNOS || COMPILE_TEST
select DEVFREQ_GOV_SIMPLE_ONDEMAND
select DEVFREQ_GOV_PASSIVE
select DEVFREQ_EVENT_EXYNOS_PPMU
@@ -91,14 +91,26 @@
This does not yet operate with optimal voltages.
config ARM_TEGRA_DEVFREQ
- tristate "Tegra DEVFREQ Driver"
- depends on ARCH_TEGRA_124_SOC
- select DEVFREQ_GOV_SIMPLE_ONDEMAND
- select PM_OPP
- help
- This adds the DEVFREQ driver for the Tegra family of SoCs.
- It reads ACTMON counters of memory controllers and adjusts the
- operating frequencies and voltages with OPP support.
+ tristate "Tegra DEVFREQ Driver"
+ depends on ARCH_TEGRA_124_SOC
+ select DEVFREQ_GOV_SIMPLE_ONDEMAND
+ select PM_OPP
+ help
+ This adds the DEVFREQ driver for the Tegra family of SoCs.
+ It reads ACTMON counters of memory controllers and adjusts the
+ operating frequencies and voltages with OPP support.
+
+config ARM_RK3399_DMC_DEVFREQ
+ tristate "ARM RK3399 DMC DEVFREQ Driver"
+ depends on ARCH_ROCKCHIP
+ select DEVFREQ_EVENT_ROCKCHIP_DFI
+ select DEVFREQ_GOV_SIMPLE_ONDEMAND
+ select PM_DEVFREQ_EVENT
+ select PM_OPP
+ help
+ This adds the DEVFREQ driver for the RK3399 DMC(Dynamic Memory Controller).
+ It sets the frequency for the memory controller and reads the usage counts
+ from hardware.
source "drivers/devfreq/event/Kconfig"
diff --git a/drivers/devfreq/Makefile b/drivers/devfreq/Makefile
index 09f11d9..fbff40a 100644
--- a/drivers/devfreq/Makefile
+++ b/drivers/devfreq/Makefile
@@ -8,6 +8,7 @@
# DEVFREQ Drivers
obj-$(CONFIG_ARM_EXYNOS_BUS_DEVFREQ) += exynos-bus.o
+obj-$(CONFIG_ARM_RK3399_DMC_DEVFREQ) += rk3399_dmc.o
obj-$(CONFIG_ARM_TEGRA_DEVFREQ) += tegra-devfreq.o
# DEVFREQ Event Drivers
diff --git a/drivers/devfreq/event/Kconfig b/drivers/devfreq/event/Kconfig
index eb6f74a..0fdae86 100644
--- a/drivers/devfreq/event/Kconfig
+++ b/drivers/devfreq/event/Kconfig
@@ -15,7 +15,7 @@
config DEVFREQ_EVENT_EXYNOS_NOCP
tristate "EXYNOS NoC (Network On Chip) Probe DEVFREQ event Driver"
- depends on ARCH_EXYNOS
+ depends on ARCH_EXYNOS || COMPILE_TEST
select PM_OPP
help
This add the devfreq-event driver for Exynos SoC. It provides NoC
@@ -23,11 +23,18 @@
config DEVFREQ_EVENT_EXYNOS_PPMU
tristate "EXYNOS PPMU (Platform Performance Monitoring Unit) DEVFREQ event Driver"
- depends on ARCH_EXYNOS
+ depends on ARCH_EXYNOS || COMPILE_TEST
select PM_OPP
help
This add the devfreq-event driver for Exynos SoC. It provides PPMU
(Platform Performance Monitoring Unit) counters to estimate the
utilization of each module.
+config DEVFREQ_EVENT_ROCKCHIP_DFI
+ tristate "ROCKCHIP DFI DEVFREQ event Driver"
+ depends on ARCH_ROCKCHIP
+ help
+ This add the devfreq-event driver for Rockchip SoC. It provides DFI
+ (DDR Monitor Module) driver to count ddr load.
+
endif # PM_DEVFREQ_EVENT
diff --git a/drivers/devfreq/event/Makefile b/drivers/devfreq/event/Makefile
index 3d6afd3..dda7090 100644
--- a/drivers/devfreq/event/Makefile
+++ b/drivers/devfreq/event/Makefile
@@ -2,3 +2,4 @@
obj-$(CONFIG_DEVFREQ_EVENT_EXYNOS_NOCP) += exynos-nocp.o
obj-$(CONFIG_DEVFREQ_EVENT_EXYNOS_PPMU) += exynos-ppmu.o
+obj-$(CONFIG_DEVFREQ_EVENT_ROCKCHIP_DFI) += rockchip-dfi.o
diff --git a/drivers/devfreq/event/exynos-ppmu.c b/drivers/devfreq/event/exynos-ppmu.c
index 845bf25..f55cf0e 100644
--- a/drivers/devfreq/event/exynos-ppmu.c
+++ b/drivers/devfreq/event/exynos-ppmu.c
@@ -406,8 +406,6 @@
of_property_read_string(node, "event-name", &desc[j].name);
j++;
-
- of_node_put(node);
}
info->desc = desc;
diff --git a/drivers/devfreq/event/rockchip-dfi.c b/drivers/devfreq/event/rockchip-dfi.c
new file mode 100644
index 0000000..43fcc5a
--- /dev/null
+++ b/drivers/devfreq/event/rockchip-dfi.c
@@ -0,0 +1,256 @@
+/*
+ * Copyright (c) 2016, Fuzhou Rockchip Electronics Co., Ltd
+ * Author: Lin Huang <hl@rock-chips.com>
+ *
+ * This program is free software; you can redistribute it and/or modify it
+ * under the terms and conditions of the GNU General Public License,
+ * version 2, as published by the Free Software Foundation.
+ *
+ * This program is distributed in the hope it will be useful, but WITHOUT
+ * ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
+ * FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for
+ * more details.
+ */
+
+#include <linux/clk.h>
+#include <linux/devfreq-event.h>
+#include <linux/kernel.h>
+#include <linux/err.h>
+#include <linux/init.h>
+#include <linux/io.h>
+#include <linux/mfd/syscon.h>
+#include <linux/module.h>
+#include <linux/platform_device.h>
+#include <linux/regmap.h>
+#include <linux/slab.h>
+#include <linux/list.h>
+#include <linux/of.h>
+
+#define RK3399_DMC_NUM_CH 2
+
+/* DDRMON_CTRL */
+#define DDRMON_CTRL 0x04
+#define CLR_DDRMON_CTRL (0x1f0000 << 0)
+#define LPDDR4_EN (0x10001 << 4)
+#define HARDWARE_EN (0x10001 << 3)
+#define LPDDR3_EN (0x10001 << 2)
+#define SOFTWARE_EN (0x10001 << 1)
+#define SOFTWARE_DIS (0x10000 << 1)
+#define TIME_CNT_EN (0x10001 << 0)
+
+#define DDRMON_CH0_COUNT_NUM 0x28
+#define DDRMON_CH0_DFI_ACCESS_NUM 0x2c
+#define DDRMON_CH1_COUNT_NUM 0x3c
+#define DDRMON_CH1_DFI_ACCESS_NUM 0x40
+
+/* pmu grf */
+#define PMUGRF_OS_REG2 0x308
+#define DDRTYPE_SHIFT 13
+#define DDRTYPE_MASK 7
+
+enum {
+ DDR3 = 3,
+ LPDDR3 = 6,
+ LPDDR4 = 7,
+ UNUSED = 0xFF
+};
+
+struct dmc_usage {
+ u32 access;
+ u32 total;
+};
+
+/*
+ * The dfi controller can monitor DDR load. It has an upper and lower threshold
+ * for the operating points. Whenever the usage leaves these bounds an event is
+ * generated to indicate the DDR frequency should be changed.
+ */
+struct rockchip_dfi {
+ struct devfreq_event_dev *edev;
+ struct devfreq_event_desc *desc;
+ struct dmc_usage ch_usage[RK3399_DMC_NUM_CH];
+ struct device *dev;
+ void __iomem *regs;
+ struct regmap *regmap_pmu;
+ struct clk *clk;
+};
+
+static void rockchip_dfi_start_hardware_counter(struct devfreq_event_dev *edev)
+{
+ struct rockchip_dfi *info = devfreq_event_get_drvdata(edev);
+ void __iomem *dfi_regs = info->regs;
+ u32 val;
+ u32 ddr_type;
+
+ /* get ddr type */
+ regmap_read(info->regmap_pmu, PMUGRF_OS_REG2, &val);
+ ddr_type = (val >> DDRTYPE_SHIFT) & DDRTYPE_MASK;
+
+ /* clear DDRMON_CTRL setting */
+ writel_relaxed(CLR_DDRMON_CTRL, dfi_regs + DDRMON_CTRL);
+
+ /* set ddr type to dfi */
+ if (ddr_type == LPDDR3)
+ writel_relaxed(LPDDR3_EN, dfi_regs + DDRMON_CTRL);
+ else if (ddr_type == LPDDR4)
+ writel_relaxed(LPDDR4_EN, dfi_regs + DDRMON_CTRL);
+
+ /* enable count, use software mode */
+ writel_relaxed(SOFTWARE_EN, dfi_regs + DDRMON_CTRL);
+}
+
+static void rockchip_dfi_stop_hardware_counter(struct devfreq_event_dev *edev)
+{
+ struct rockchip_dfi *info = devfreq_event_get_drvdata(edev);
+ void __iomem *dfi_regs = info->regs;
+
+ writel_relaxed(SOFTWARE_DIS, dfi_regs + DDRMON_CTRL);
+}
+
+static int rockchip_dfi_get_busier_ch(struct devfreq_event_dev *edev)
+{
+ struct rockchip_dfi *info = devfreq_event_get_drvdata(edev);
+ u32 tmp, max = 0;
+ u32 i, busier_ch = 0;
+ void __iomem *dfi_regs = info->regs;
+
+ rockchip_dfi_stop_hardware_counter(edev);
+
+ /* Find out which channel is busier */
+ for (i = 0; i < RK3399_DMC_NUM_CH; i++) {
+ info->ch_usage[i].access = readl_relaxed(dfi_regs +
+ DDRMON_CH0_DFI_ACCESS_NUM + i * 20) * 4;
+ info->ch_usage[i].total = readl_relaxed(dfi_regs +
+ DDRMON_CH0_COUNT_NUM + i * 20);
+ tmp = info->ch_usage[i].access;
+ if (tmp > max) {
+ busier_ch = i;
+ max = tmp;
+ }
+ }
+ rockchip_dfi_start_hardware_counter(edev);
+
+ return busier_ch;
+}
+
+static int rockchip_dfi_disable(struct devfreq_event_dev *edev)
+{
+ struct rockchip_dfi *info = devfreq_event_get_drvdata(edev);
+
+ rockchip_dfi_stop_hardware_counter(edev);
+ clk_disable_unprepare(info->clk);
+
+ return 0;
+}
+
+static int rockchip_dfi_enable(struct devfreq_event_dev *edev)
+{
+ struct rockchip_dfi *info = devfreq_event_get_drvdata(edev);
+ int ret;
+
+ ret = clk_prepare_enable(info->clk);
+ if (ret) {
+ dev_err(&edev->dev, "failed to enable dfi clk: %d\n", ret);
+ return ret;
+ }
+
+ rockchip_dfi_start_hardware_counter(edev);
+ return 0;
+}
+
+static int rockchip_dfi_set_event(struct devfreq_event_dev *edev)
+{
+ return 0;
+}
+
+static int rockchip_dfi_get_event(struct devfreq_event_dev *edev,
+ struct devfreq_event_data *edata)
+{
+ struct rockchip_dfi *info = devfreq_event_get_drvdata(edev);
+ int busier_ch;
+
+ busier_ch = rockchip_dfi_get_busier_ch(edev);
+
+ edata->load_count = info->ch_usage[busier_ch].access;
+ edata->total_count = info->ch_usage[busier_ch].total;
+
+ return 0;
+}
+
+static const struct devfreq_event_ops rockchip_dfi_ops = {
+ .disable = rockchip_dfi_disable,
+ .enable = rockchip_dfi_enable,
+ .get_event = rockchip_dfi_get_event,
+ .set_event = rockchip_dfi_set_event,
+};
+
+static const struct of_device_id rockchip_dfi_id_match[] = {
+ { .compatible = "rockchip,rk3399-dfi" },
+ { },
+};
+
+static int rockchip_dfi_probe(struct platform_device *pdev)
+{
+ struct device *dev = &pdev->dev;
+ struct rockchip_dfi *data;
+ struct resource *res;
+ struct devfreq_event_desc *desc;
+ struct device_node *np = pdev->dev.of_node, *node;
+
+ data = devm_kzalloc(dev, sizeof(struct rockchip_dfi), GFP_KERNEL);
+ if (!data)
+ return -ENOMEM;
+
+ res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
+ data->regs = devm_ioremap_resource(&pdev->dev, res);
+ if (IS_ERR(data->regs))
+ return PTR_ERR(data->regs);
+
+ data->clk = devm_clk_get(dev, "pclk_ddr_mon");
+ if (IS_ERR(data->clk)) {
+ dev_err(dev, "Cannot get the clk dmc_clk\n");
+ return PTR_ERR(data->clk);
+ };
+
+ /* try to find the optional reference to the pmu syscon */
+ node = of_parse_phandle(np, "rockchip,pmu", 0);
+ if (node) {
+ data->regmap_pmu = syscon_node_to_regmap(node);
+ if (IS_ERR(data->regmap_pmu))
+ return PTR_ERR(data->regmap_pmu);
+ }
+ data->dev = dev;
+
+ desc = devm_kzalloc(dev, sizeof(*desc), GFP_KERNEL);
+ if (!desc)
+ return -ENOMEM;
+
+ desc->ops = &rockchip_dfi_ops;
+ desc->driver_data = data;
+ desc->name = np->name;
+ data->desc = desc;
+
+ data->edev = devm_devfreq_event_add_edev(&pdev->dev, desc);
+ if (IS_ERR(data->edev)) {
+ dev_err(&pdev->dev,
+ "failed to add devfreq-event device\n");
+ return PTR_ERR(data->edev);
+ }
+
+ platform_set_drvdata(pdev, data);
+
+ return 0;
+}
+
+static struct platform_driver rockchip_dfi_driver = {
+ .probe = rockchip_dfi_probe,
+ .driver = {
+ .name = "rockchip-dfi",
+ .of_match_table = rockchip_dfi_id_match,
+ },
+};
+module_platform_driver(rockchip_dfi_driver);
+
+MODULE_LICENSE("GPL v2");
+MODULE_AUTHOR("Lin Huang <hl@rock-chips.com>");
+MODULE_DESCRIPTION("Rockchip DFI driver");
diff --git a/drivers/devfreq/rk3399_dmc.c b/drivers/devfreq/rk3399_dmc.c
new file mode 100644
index 0000000..e24b73d
--- /dev/null
+++ b/drivers/devfreq/rk3399_dmc.c
@@ -0,0 +1,470 @@
+/*
+ * Copyright (c) 2016, Fuzhou Rockchip Electronics Co., Ltd.
+ * Author: Lin Huang <hl@rock-chips.com>
+ *
+ * This program is free software; you can redistribute it and/or modify it
+ * under the terms and conditions of the GNU General Public License,
+ * version 2, as published by the Free Software Foundation.
+ *
+ * This program is distributed in the hope it will be useful, but WITHOUT
+ * ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
+ * FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for
+ * more details.
+ */
+
+#include <linux/arm-smccc.h>
+#include <linux/clk.h>
+#include <linux/delay.h>
+#include <linux/devfreq.h>
+#include <linux/devfreq-event.h>
+#include <linux/interrupt.h>
+#include <linux/module.h>
+#include <linux/of.h>
+#include <linux/platform_device.h>
+#include <linux/pm_opp.h>
+#include <linux/regulator/consumer.h>
+#include <linux/rwsem.h>
+#include <linux/suspend.h>
+
+#include <soc/rockchip/rockchip_sip.h>
+
+struct dram_timing {
+ unsigned int ddr3_speed_bin;
+ unsigned int pd_idle;
+ unsigned int sr_idle;
+ unsigned int sr_mc_gate_idle;
+ unsigned int srpd_lite_idle;
+ unsigned int standby_idle;
+ unsigned int auto_pd_dis_freq;
+ unsigned int dram_dll_dis_freq;
+ unsigned int phy_dll_dis_freq;
+ unsigned int ddr3_odt_dis_freq;
+ unsigned int ddr3_drv;
+ unsigned int ddr3_odt;
+ unsigned int phy_ddr3_ca_drv;
+ unsigned int phy_ddr3_dq_drv;
+ unsigned int phy_ddr3_odt;
+ unsigned int lpddr3_odt_dis_freq;
+ unsigned int lpddr3_drv;
+ unsigned int lpddr3_odt;
+ unsigned int phy_lpddr3_ca_drv;
+ unsigned int phy_lpddr3_dq_drv;
+ unsigned int phy_lpddr3_odt;
+ unsigned int lpddr4_odt_dis_freq;
+ unsigned int lpddr4_drv;
+ unsigned int lpddr4_dq_odt;
+ unsigned int lpddr4_ca_odt;
+ unsigned int phy_lpddr4_ca_drv;
+ unsigned int phy_lpddr4_ck_cs_drv;
+ unsigned int phy_lpddr4_dq_drv;
+ unsigned int phy_lpddr4_odt;
+};
+
+struct rk3399_dmcfreq {
+ struct device *dev;
+ struct devfreq *devfreq;
+ struct devfreq_simple_ondemand_data ondemand_data;
+ struct clk *dmc_clk;
+ struct devfreq_event_dev *edev;
+ struct mutex lock;
+ struct dram_timing timing;
+
+ /*
+ * DDR Converser of Frequency (DCF) is used to implement DDR frequency
+ * conversion without the participation of CPU, we will implement and
+ * control it in arm trust firmware.
+ */
+ wait_queue_head_t wait_dcf_queue;
+ int irq;
+ int wait_dcf_flag;
+ struct regulator *vdd_center;
+ unsigned long rate, target_rate;
+ unsigned long volt, target_volt;
+ struct dev_pm_opp *curr_opp;
+};
+
+static int rk3399_dmcfreq_target(struct device *dev, unsigned long *freq,
+ u32 flags)
+{
+ struct rk3399_dmcfreq *dmcfreq = dev_get_drvdata(dev);
+ struct dev_pm_opp *opp;
+ unsigned long old_clk_rate = dmcfreq->rate;
+ unsigned long target_volt, target_rate;
+ int err;
+
+ rcu_read_lock();
+ opp = devfreq_recommended_opp(dev, freq, flags);
+ if (IS_ERR(opp)) {
+ rcu_read_unlock();
+ return PTR_ERR(opp);
+ }
+
+ target_rate = dev_pm_opp_get_freq(opp);
+ target_volt = dev_pm_opp_get_voltage(opp);
+
+ dmcfreq->rate = dev_pm_opp_get_freq(dmcfreq->curr_opp);
+ dmcfreq->volt = dev_pm_opp_get_voltage(dmcfreq->curr_opp);
+
+ rcu_read_unlock();
+
+ if (dmcfreq->rate == target_rate)
+ return 0;
+
+ mutex_lock(&dmcfreq->lock);
+
+ /*
+ * If frequency scaling from low to high, adjust voltage first.
+ * If frequency scaling from high to low, adjust frequency first.
+ */
+ if (old_clk_rate < target_rate) {
+ err = regulator_set_voltage(dmcfreq->vdd_center, target_volt,
+ target_volt);
+ if (err) {
+ dev_err(dev, "Cannot to set voltage %lu uV\n",
+ target_volt);
+ goto out;
+ }
+ }
+ dmcfreq->wait_dcf_flag = 1;
+
+ err = clk_set_rate(dmcfreq->dmc_clk, target_rate);
+ if (err) {
+ dev_err(dev, "Cannot to set frequency %lu (%d)\n",
+ target_rate, err);
+ regulator_set_voltage(dmcfreq->vdd_center, dmcfreq->volt,
+ dmcfreq->volt);
+ goto out;
+ }
+
+ /*
+ * Wait until bcf irq happen, it means freq scaling finish in
+ * arm trust firmware, use 100ms as timeout time.
+ */
+ if (!wait_event_timeout(dmcfreq->wait_dcf_queue,
+ !dmcfreq->wait_dcf_flag, HZ / 10))
+ dev_warn(dev, "Timeout waiting for dcf interrupt\n");
+
+ /*
+ * Check the dpll rate,
+ * There only two result we will get,
+ * 1. Ddr frequency scaling fail, we still get the old rate.
+ * 2. Ddr frequency scaling sucessful, we get the rate we set.
+ */
+ dmcfreq->rate = clk_get_rate(dmcfreq->dmc_clk);
+
+ /* If get the incorrect rate, set voltage to old value. */
+ if (dmcfreq->rate != target_rate) {
+ dev_err(dev, "Get wrong ddr frequency, Request frequency %lu,\
+ Current frequency %lu\n", target_rate, dmcfreq->rate);
+ regulator_set_voltage(dmcfreq->vdd_center, dmcfreq->volt,
+ dmcfreq->volt);
+ goto out;
+ } else if (old_clk_rate > target_rate)
+ err = regulator_set_voltage(dmcfreq->vdd_center, target_volt,
+ target_volt);
+ if (err)
+ dev_err(dev, "Cannot to set vol %lu uV\n", target_volt);
+
+ dmcfreq->curr_opp = opp;
+out:
+ mutex_unlock(&dmcfreq->lock);
+ return err;
+}
+
+static int rk3399_dmcfreq_get_dev_status(struct device *dev,
+ struct devfreq_dev_status *stat)
+{
+ struct rk3399_dmcfreq *dmcfreq = dev_get_drvdata(dev);
+ struct devfreq_event_data edata;
+ int ret = 0;
+
+ ret = devfreq_event_get_event(dmcfreq->edev, &edata);
+ if (ret < 0)
+ return ret;
+
+ stat->current_frequency = dmcfreq->rate;
+ stat->busy_time = edata.load_count;
+ stat->total_time = edata.total_count;
+
+ return ret;
+}
+
+static int rk3399_dmcfreq_get_cur_freq(struct device *dev, unsigned long *freq)
+{
+ struct rk3399_dmcfreq *dmcfreq = dev_get_drvdata(dev);
+
+ *freq = dmcfreq->rate;
+
+ return 0;
+}
+
+static struct devfreq_dev_profile rk3399_devfreq_dmc_profile = {
+ .polling_ms = 200,
+ .target = rk3399_dmcfreq_target,
+ .get_dev_status = rk3399_dmcfreq_get_dev_status,
+ .get_cur_freq = rk3399_dmcfreq_get_cur_freq,
+};
+
+static __maybe_unused int rk3399_dmcfreq_suspend(struct device *dev)
+{
+ struct rk3399_dmcfreq *dmcfreq = dev_get_drvdata(dev);
+ int ret = 0;
+
+ ret = devfreq_event_disable_edev(dmcfreq->edev);
+ if (ret < 0) {
+ dev_err(dev, "failed to disable the devfreq-event devices\n");
+ return ret;
+ }
+
+ ret = devfreq_suspend_device(dmcfreq->devfreq);
+ if (ret < 0) {
+ dev_err(dev, "failed to suspend the devfreq devices\n");
+ return ret;
+ }
+
+ return 0;
+}
+
+static __maybe_unused int rk3399_dmcfreq_resume(struct device *dev)
+{
+ struct rk3399_dmcfreq *dmcfreq = dev_get_drvdata(dev);
+ int ret = 0;
+
+ ret = devfreq_event_enable_edev(dmcfreq->edev);
+ if (ret < 0) {
+ dev_err(dev, "failed to enable the devfreq-event devices\n");
+ return ret;
+ }
+
+ ret = devfreq_resume_device(dmcfreq->devfreq);
+ if (ret < 0) {
+ dev_err(dev, "failed to resume the devfreq devices\n");
+ return ret;
+ }
+ return ret;
+}
+
+static SIMPLE_DEV_PM_OPS(rk3399_dmcfreq_pm, rk3399_dmcfreq_suspend,
+ rk3399_dmcfreq_resume);
+
+static irqreturn_t rk3399_dmc_irq(int irq, void *dev_id)
+{
+ struct rk3399_dmcfreq *dmcfreq = dev_id;
+ struct arm_smccc_res res;
+
+ dmcfreq->wait_dcf_flag = 0;
+ wake_up(&dmcfreq->wait_dcf_queue);
+
+ /* Clear the DCF interrupt */
+ arm_smccc_smc(ROCKCHIP_SIP_DRAM_FREQ, 0, 0,
+ ROCKCHIP_SIP_CONFIG_DRAM_CLR_IRQ,
+ 0, 0, 0, 0, &res);
+
+ return IRQ_HANDLED;
+}
+
+static int of_get_ddr_timings(struct dram_timing *timing,
+ struct device_node *np)
+{
+ int ret = 0;
+
+ ret = of_property_read_u32(np, "rockchip,ddr3_speed_bin",
+ &timing->ddr3_speed_bin);
+ ret |= of_property_read_u32(np, "rockchip,pd_idle",
+ &timing->pd_idle);
+ ret |= of_property_read_u32(np, "rockchip,sr_idle",
+ &timing->sr_idle);
+ ret |= of_property_read_u32(np, "rockchip,sr_mc_gate_idle",
+ &timing->sr_mc_gate_idle);
+ ret |= of_property_read_u32(np, "rockchip,srpd_lite_idle",
+ &timing->srpd_lite_idle);
+ ret |= of_property_read_u32(np, "rockchip,standby_idle",
+ &timing->standby_idle);
+ ret |= of_property_read_u32(np, "rockchip,auto_pd_dis_freq",
+ &timing->auto_pd_dis_freq);
+ ret |= of_property_read_u32(np, "rockchip,dram_dll_dis_freq",
+ &timing->dram_dll_dis_freq);
+ ret |= of_property_read_u32(np, "rockchip,phy_dll_dis_freq",
+ &timing->phy_dll_dis_freq);
+ ret |= of_property_read_u32(np, "rockchip,ddr3_odt_dis_freq",
+ &timing->ddr3_odt_dis_freq);
+ ret |= of_property_read_u32(np, "rockchip,ddr3_drv",
+ &timing->ddr3_drv);
+ ret |= of_property_read_u32(np, "rockchip,ddr3_odt",
+ &timing->ddr3_odt);
+ ret |= of_property_read_u32(np, "rockchip,phy_ddr3_ca_drv",
+ &timing->phy_ddr3_ca_drv);
+ ret |= of_property_read_u32(np, "rockchip,phy_ddr3_dq_drv",
+ &timing->phy_ddr3_dq_drv);
+ ret |= of_property_read_u32(np, "rockchip,phy_ddr3_odt",
+ &timing->phy_ddr3_odt);
+ ret |= of_property_read_u32(np, "rockchip,lpddr3_odt_dis_freq",
+ &timing->lpddr3_odt_dis_freq);
+ ret |= of_property_read_u32(np, "rockchip,lpddr3_drv",
+ &timing->lpddr3_drv);
+ ret |= of_property_read_u32(np, "rockchip,lpddr3_odt",
+ &timing->lpddr3_odt);
+ ret |= of_property_read_u32(np, "rockchip,phy_lpddr3_ca_drv",
+ &timing->phy_lpddr3_ca_drv);
+ ret |= of_property_read_u32(np, "rockchip,phy_lpddr3_dq_drv",
+ &timing->phy_lpddr3_dq_drv);
+ ret |= of_property_read_u32(np, "rockchip,phy_lpddr3_odt",
+ &timing->phy_lpddr3_odt);
+ ret |= of_property_read_u32(np, "rockchip,lpddr4_odt_dis_freq",
+ &timing->lpddr4_odt_dis_freq);
+ ret |= of_property_read_u32(np, "rockchip,lpddr4_drv",
+ &timing->lpddr4_drv);
+ ret |= of_property_read_u32(np, "rockchip,lpddr4_dq_odt",
+ &timing->lpddr4_dq_odt);
+ ret |= of_property_read_u32(np, "rockchip,lpddr4_ca_odt",
+ &timing->lpddr4_ca_odt);
+ ret |= of_property_read_u32(np, "rockchip,phy_lpddr4_ca_drv",
+ &timing->phy_lpddr4_ca_drv);
+ ret |= of_property_read_u32(np, "rockchip,phy_lpddr4_ck_cs_drv",
+ &timing->phy_lpddr4_ck_cs_drv);
+ ret |= of_property_read_u32(np, "rockchip,phy_lpddr4_dq_drv",
+ &timing->phy_lpddr4_dq_drv);
+ ret |= of_property_read_u32(np, "rockchip,phy_lpddr4_odt",
+ &timing->phy_lpddr4_odt);
+
+ return ret;
+}
+
+static int rk3399_dmcfreq_probe(struct platform_device *pdev)
+{
+ struct arm_smccc_res res;
+ struct device *dev = &pdev->dev;
+ struct device_node *np = pdev->dev.of_node;
+ struct rk3399_dmcfreq *data;
+ int ret, irq, index, size;
+ uint32_t *timing;
+ struct dev_pm_opp *opp;
+
+ irq = platform_get_irq(pdev, 0);
+ if (irq < 0) {
+ dev_err(&pdev->dev, "Cannot get the dmc interrupt resource\n");
+ return -EINVAL;
+ }
+ data = devm_kzalloc(dev, sizeof(struct rk3399_dmcfreq), GFP_KERNEL);
+ if (!data)
+ return -ENOMEM;
+
+ mutex_init(&data->lock);
+
+ data->vdd_center = devm_regulator_get(dev, "center");
+ if (IS_ERR(data->vdd_center)) {
+ dev_err(dev, "Cannot get the regulator \"center\"\n");
+ return PTR_ERR(data->vdd_center);
+ }
+
+ data->dmc_clk = devm_clk_get(dev, "dmc_clk");
+ if (IS_ERR(data->dmc_clk)) {
+ dev_err(dev, "Cannot get the clk dmc_clk\n");
+ return PTR_ERR(data->dmc_clk);
+ };
+
+ data->irq = irq;
+ ret = devm_request_irq(dev, irq, rk3399_dmc_irq, 0,
+ dev_name(dev), data);
+ if (ret) {
+ dev_err(dev, "Failed to request dmc irq: %d\n", ret);
+ return ret;
+ }
+
+ init_waitqueue_head(&data->wait_dcf_queue);
+ data->wait_dcf_flag = 0;
+
+ data->edev = devfreq_event_get_edev_by_phandle(dev, 0);
+ if (IS_ERR(data->edev))
+ return -EPROBE_DEFER;
+
+ ret = devfreq_event_enable_edev(data->edev);
+ if (ret < 0) {
+ dev_err(dev, "failed to enable devfreq-event devices\n");
+ return ret;
+ }
+
+ /*
+ * Get dram timing and pass it to arm trust firmware,
+ * the dram drvier in arm trust firmware will get these
+ * timing and to do dram initial.
+ */
+ if (!of_get_ddr_timings(&data->timing, np)) {
+ timing = &data->timing.ddr3_speed_bin;
+ size = sizeof(struct dram_timing) / 4;
+ for (index = 0; index < size; index++) {
+ arm_smccc_smc(ROCKCHIP_SIP_DRAM_FREQ, *timing++, index,
+ ROCKCHIP_SIP_CONFIG_DRAM_SET_PARAM,
+ 0, 0, 0, 0, &res);
+ if (res.a0) {
+ dev_err(dev, "Failed to set dram param: %ld\n",
+ res.a0);
+ return -EINVAL;
+ }
+ }
+ }
+
+ arm_smccc_smc(ROCKCHIP_SIP_DRAM_FREQ, 0, 0,
+ ROCKCHIP_SIP_CONFIG_DRAM_INIT,
+ 0, 0, 0, 0, &res);
+
+ /*
+ * We add a devfreq driver to our parent since it has a device tree node
+ * with operating points.
+ */
+ if (dev_pm_opp_of_add_table(dev)) {
+ dev_err(dev, "Invalid operating-points in device tree.\n");
+ rcu_read_unlock();
+ return -EINVAL;
+ }
+
+ of_property_read_u32(np, "upthreshold",
+ &data->ondemand_data.upthreshold);
+ of_property_read_u32(np, "downdifferential",
+ &data->ondemand_data.downdifferential);
+
+ data->rate = clk_get_rate(data->dmc_clk);
+
+ rcu_read_lock();
+ opp = devfreq_recommended_opp(dev, &data->rate, 0);
+ if (IS_ERR(opp)) {
+ rcu_read_unlock();
+ return PTR_ERR(opp);
+ }
+ rcu_read_unlock();
+ data->curr_opp = opp;
+
+ rk3399_devfreq_dmc_profile.initial_freq = data->rate;
+
+ data->devfreq = devfreq_add_device(dev,
+ &rk3399_devfreq_dmc_profile,
+ "simple_ondemand",
+ &data->ondemand_data);
+ if (IS_ERR(data->devfreq))
+ return PTR_ERR(data->devfreq);
+ devm_devfreq_register_opp_notifier(dev, data->devfreq);
+
+ data->dev = dev;
+ platform_set_drvdata(pdev, data);
+
+ return 0;
+}
+
+static const struct of_device_id rk3399dmc_devfreq_of_match[] = {
+ { .compatible = "rockchip,rk3399-dmc" },
+ { },
+};
+
+static struct platform_driver rk3399_dmcfreq_driver = {
+ .probe = rk3399_dmcfreq_probe,
+ .driver = {
+ .name = "rk3399-dmc-freq",
+ .pm = &rk3399_dmcfreq_pm,
+ .of_match_table = rk3399dmc_devfreq_of_match,
+ },
+};
+module_platform_driver(rk3399_dmcfreq_driver);
+
+MODULE_LICENSE("GPL v2");
+MODULE_AUTHOR("Lin Huang <hl@rock-chips.com>");
+MODULE_DESCRIPTION("RK3399 dmcfreq driver with devfreq framework");
diff --git a/drivers/firmware/dcdbas.c b/drivers/firmware/dcdbas.c
index 829eec8..2fe1a13 100644
--- a/drivers/firmware/dcdbas.c
+++ b/drivers/firmware/dcdbas.c
@@ -23,6 +23,7 @@
#include <linux/platform_device.h>
#include <linux/dma-mapping.h>
#include <linux/errno.h>
+#include <linux/cpu.h>
#include <linux/gfp.h>
#include <linux/init.h>
#include <linux/kernel.h>
@@ -238,33 +239,14 @@
return count;
}
-/**
- * dcdbas_smi_request: generate SMI request
- *
- * Called with smi_data_lock.
- */
-int dcdbas_smi_request(struct smi_cmd *smi_cmd)
+static int raise_smi(void *par)
{
- cpumask_var_t old_mask;
- int ret = 0;
+ struct smi_cmd *smi_cmd = par;
- if (smi_cmd->magic != SMI_CMD_MAGIC) {
- dev_info(&dcdbas_pdev->dev, "%s: invalid magic value\n",
- __func__);
- return -EBADR;
- }
-
- /* SMI requires CPU 0 */
- if (!alloc_cpumask_var(&old_mask, GFP_KERNEL))
- return -ENOMEM;
-
- cpumask_copy(old_mask, ¤t->cpus_allowed);
- set_cpus_allowed_ptr(current, cpumask_of(0));
if (smp_processor_id() != 0) {
dev_dbg(&dcdbas_pdev->dev, "%s: failed to get CPU 0\n",
__func__);
- ret = -EBUSY;
- goto out;
+ return -EBUSY;
}
/* generate SMI */
@@ -280,9 +262,28 @@
: "memory"
);
-out:
- set_cpus_allowed_ptr(current, old_mask);
- free_cpumask_var(old_mask);
+ return 0;
+}
+/**
+ * dcdbas_smi_request: generate SMI request
+ *
+ * Called with smi_data_lock.
+ */
+int dcdbas_smi_request(struct smi_cmd *smi_cmd)
+{
+ int ret;
+
+ if (smi_cmd->magic != SMI_CMD_MAGIC) {
+ dev_info(&dcdbas_pdev->dev, "%s: invalid magic value\n",
+ __func__);
+ return -EBADR;
+ }
+
+ /* SMI requires CPU 0 */
+ get_online_cpus();
+ ret = smp_call_on_cpu(0, raise_smi, smi_cmd, true);
+ put_online_cpus();
+
return ret;
}
diff --git a/drivers/firmware/efi/Kconfig b/drivers/firmware/efi/Kconfig
index 6394152..c981be1 100644
--- a/drivers/firmware/efi/Kconfig
+++ b/drivers/firmware/efi/Kconfig
@@ -112,6 +112,23 @@
Most users should say N.
+config EFI_TEST
+ tristate "EFI Runtime Service Tests Support"
+ depends on EFI
+ default n
+ help
+ This driver uses the efi.<service> function pointers directly instead
+ of going through the efivar API, because it is not trying to test the
+ kernel subsystem, just for testing the UEFI runtime service
+ interfaces which are provided by the firmware. This driver is used
+ by the Firmware Test Suite (FWTS) for testing the UEFI runtime
+ interfaces readiness of the firmware.
+ Details for FWTS are available from:
+ <https://wiki.ubuntu.com/FirmwareTestSuite>
+
+ Say Y here to enable the runtime services support via /dev/efi_test.
+ If unsure, say N.
+
endmenu
config UEFI_CPER
diff --git a/drivers/firmware/efi/Makefile b/drivers/firmware/efi/Makefile
index a219640..c8a439f 100644
--- a/drivers/firmware/efi/Makefile
+++ b/drivers/firmware/efi/Makefile
@@ -10,7 +10,7 @@
KASAN_SANITIZE_runtime-wrappers.o := n
obj-$(CONFIG_EFI) += efi.o vars.o reboot.o memattr.o
-obj-$(CONFIG_EFI) += capsule.o
+obj-$(CONFIG_EFI) += capsule.o memmap.o
obj-$(CONFIG_EFI_VARS) += efivars.o
obj-$(CONFIG_EFI_ESRT) += esrt.o
obj-$(CONFIG_EFI_VARS_PSTORE) += efi-pstore.o
@@ -20,6 +20,7 @@
obj-$(CONFIG_EFI_STUB) += libstub/
obj-$(CONFIG_EFI_FAKE_MEMMAP) += fake_mem.o
obj-$(CONFIG_EFI_BOOTLOADER_CONTROL) += efibc.o
+obj-$(CONFIG_EFI_TEST) += test/
arm-obj-$(CONFIG_EFI) := arm-init.o arm-runtime.o
obj-$(CONFIG_ARM) += $(arm-obj-y)
diff --git a/drivers/firmware/efi/arm-init.c b/drivers/firmware/efi/arm-init.c
index c49d50e..8efe130 100644
--- a/drivers/firmware/efi/arm-init.c
+++ b/drivers/firmware/efi/arm-init.c
@@ -26,9 +26,9 @@
u64 efi_system_table;
-static int __init is_normal_ram(efi_memory_desc_t *md)
+static int __init is_memory(efi_memory_desc_t *md)
{
- if (md->attribute & EFI_MEMORY_WB)
+ if (md->attribute & (EFI_MEMORY_WB|EFI_MEMORY_WT|EFI_MEMORY_WC))
return 1;
return 0;
}
@@ -152,9 +152,9 @@
}
/*
- * Return true for RAM regions we want to permanently reserve.
+ * Return true for regions that can be used as System RAM.
*/
-static __init int is_reserve_region(efi_memory_desc_t *md)
+static __init int is_usable_memory(efi_memory_desc_t *md)
{
switch (md->type) {
case EFI_LOADER_CODE:
@@ -163,18 +163,22 @@
case EFI_BOOT_SERVICES_DATA:
case EFI_CONVENTIONAL_MEMORY:
case EFI_PERSISTENT_MEMORY:
- return 0;
+ /*
+ * According to the spec, these regions are no longer reserved
+ * after calling ExitBootServices(). However, we can only use
+ * them as System RAM if they can be mapped writeback cacheable.
+ */
+ return (md->attribute & EFI_MEMORY_WB);
default:
break;
}
- return is_normal_ram(md);
+ return false;
}
static __init void reserve_regions(void)
{
efi_memory_desc_t *md;
u64 paddr, npages, size;
- int resv;
if (efi_enabled(EFI_DBG))
pr_info("Processing EFI memory map:\n");
@@ -191,32 +195,29 @@
paddr = md->phys_addr;
npages = md->num_pages;
- resv = is_reserve_region(md);
if (efi_enabled(EFI_DBG)) {
char buf[64];
- pr_info(" 0x%012llx-0x%012llx %s%s\n",
+ pr_info(" 0x%012llx-0x%012llx %s\n",
paddr, paddr + (npages << EFI_PAGE_SHIFT) - 1,
- efi_md_typeattr_format(buf, sizeof(buf), md),
- resv ? "*" : "");
+ efi_md_typeattr_format(buf, sizeof(buf), md));
}
memrange_efi_to_native(&paddr, &npages);
size = npages << PAGE_SHIFT;
- if (is_normal_ram(md))
+ if (is_memory(md)) {
early_init_dt_add_memory_arch(paddr, size);
- if (resv)
- memblock_mark_nomap(paddr, size);
-
+ if (!is_usable_memory(md))
+ memblock_mark_nomap(paddr, size);
+ }
}
-
- set_bit(EFI_MEMMAP, &efi.flags);
}
void __init efi_init(void)
{
+ struct efi_memory_map_data data;
struct efi_fdt_params params;
/* Grab UEFI information placed in FDT by stub */
@@ -225,9 +226,12 @@
efi_system_table = params.system_table;
- efi.memmap.phys_map = params.mmap;
- efi.memmap.map = early_memremap_ro(params.mmap, params.mmap_size);
- if (efi.memmap.map == NULL) {
+ data.desc_version = params.desc_ver;
+ data.desc_size = params.desc_size;
+ data.size = params.mmap_size;
+ data.phys_map = params.mmap;
+
+ if (efi_memmap_init_early(&data) < 0) {
/*
* If we are booting via UEFI, the UEFI memory map is the only
* description of memory we have, so there is little point in
@@ -235,9 +239,6 @@
*/
panic("Unable to map EFI memory map.\n");
}
- efi.memmap.map_end = efi.memmap.map + params.mmap_size;
- efi.memmap.desc_size = params.desc_size;
- efi.memmap.desc_version = params.desc_ver;
WARN(efi.memmap.desc_version != 1,
"Unexpected EFI_MEMORY_DESCRIPTOR version %ld",
@@ -248,7 +249,8 @@
reserve_regions();
efi_memattr_init();
- early_memunmap(efi.memmap.map, params.mmap_size);
+ efi_esrt_init();
+ efi_memmap_unmap();
memblock_reserve(params.mmap & PAGE_MASK,
PAGE_ALIGN(params.mmap_size +
diff --git a/drivers/firmware/efi/arm-runtime.c b/drivers/firmware/efi/arm-runtime.c
index c394b81..7c75a8d 100644
--- a/drivers/firmware/efi/arm-runtime.c
+++ b/drivers/firmware/efi/arm-runtime.c
@@ -39,6 +39,26 @@
.mmlist = LIST_HEAD_INIT(efi_mm.mmlist),
};
+#ifdef CONFIG_ARM64_PTDUMP
+#include <asm/ptdump.h>
+
+static struct ptdump_info efi_ptdump_info = {
+ .mm = &efi_mm,
+ .markers = (struct addr_marker[]){
+ { 0, "UEFI runtime start" },
+ { TASK_SIZE_64, "UEFI runtime end" }
+ },
+ .base_addr = 0,
+};
+
+static int __init ptdump_init(void)
+{
+ return ptdump_register(&efi_ptdump_info, "efi_page_tables");
+}
+device_initcall(ptdump_init);
+
+#endif
+
static bool __init efi_virtmap_init(void)
{
efi_memory_desc_t *md;
@@ -114,14 +134,12 @@
pr_info("Remapping and enabling EFI services.\n");
- mapsize = efi.memmap.map_end - efi.memmap.map;
+ mapsize = efi.memmap.desc_size * efi.memmap.nr_map;
- efi.memmap.map = memremap(efi.memmap.phys_map, mapsize, MEMREMAP_WB);
- if (!efi.memmap.map) {
+ if (efi_memmap_init_late(efi.memmap.phys_map, mapsize)) {
pr_err("Failed to remap EFI memory map\n");
return -ENOMEM;
}
- efi.memmap.map_end = efi.memmap.map + mapsize;
if (!efi_virtmap_init()) {
pr_err("UEFI virtual mapping missing or invalid -- runtime services will not be available\n");
diff --git a/drivers/firmware/efi/efi-pstore.c b/drivers/firmware/efi/efi-pstore.c
index 30a24d0..1c33d74 100644
--- a/drivers/firmware/efi/efi-pstore.c
+++ b/drivers/firmware/efi/efi-pstore.c
@@ -125,16 +125,19 @@
* @entry: deleting entry
* @turn_off_scanning: Check if a scanning flag should be turned off
*/
-static inline void __efi_pstore_scan_sysfs_exit(struct efivar_entry *entry,
+static inline int __efi_pstore_scan_sysfs_exit(struct efivar_entry *entry,
bool turn_off_scanning)
{
if (entry->deleting) {
list_del(&entry->list);
efivar_entry_iter_end();
efivar_unregister(entry);
- efivar_entry_iter_begin();
+ if (efivar_entry_iter_begin())
+ return -EINTR;
} else if (turn_off_scanning)
entry->scanning = false;
+
+ return 0;
}
/**
@@ -144,13 +147,18 @@
* @head: list head
* @stop: a flag checking if scanning will stop
*/
-static void efi_pstore_scan_sysfs_exit(struct efivar_entry *pos,
+static int efi_pstore_scan_sysfs_exit(struct efivar_entry *pos,
struct efivar_entry *next,
struct list_head *head, bool stop)
{
- __efi_pstore_scan_sysfs_exit(pos, true);
+ int ret = __efi_pstore_scan_sysfs_exit(pos, true);
+
+ if (ret)
+ return ret;
+
if (stop)
- __efi_pstore_scan_sysfs_exit(next, &next->list != head);
+ ret = __efi_pstore_scan_sysfs_exit(next, &next->list != head);
+ return ret;
}
/**
@@ -172,13 +180,17 @@
struct efivar_entry *entry, *n;
struct list_head *head = &efivar_sysfs_list;
int size = 0;
+ int ret;
if (!*pos) {
list_for_each_entry_safe(entry, n, head, list) {
efi_pstore_scan_sysfs_enter(entry, n, head);
size = efi_pstore_read_func(entry, data);
- efi_pstore_scan_sysfs_exit(entry, n, head, size < 0);
+ ret = efi_pstore_scan_sysfs_exit(entry, n, head,
+ size < 0);
+ if (ret)
+ return ret;
if (size)
break;
}
@@ -190,7 +202,9 @@
efi_pstore_scan_sysfs_enter((*pos), n, head);
size = efi_pstore_read_func((*pos), data);
- efi_pstore_scan_sysfs_exit((*pos), n, head, size < 0);
+ ret = efi_pstore_scan_sysfs_exit((*pos), n, head, size < 0);
+ if (ret)
+ return ret;
if (size)
break;
}
@@ -232,7 +246,10 @@
if (!*data.buf)
return -ENOMEM;
- efivar_entry_iter_begin();
+ if (efivar_entry_iter_begin()) {
+ kfree(*data.buf);
+ return -EINTR;
+ }
size = efi_pstore_sysfs_entry_iter(&data,
(struct efivar_entry **)&psi->data);
efivar_entry_iter_end();
@@ -347,7 +364,8 @@
edata.time = time;
edata.name = efi_name;
- efivar_entry_iter_begin();
+ if (efivar_entry_iter_begin())
+ return -EINTR;
found = __efivar_entry_iter(efi_pstore_erase_func, &efivar_sysfs_list, &edata, &entry);
if (found && !entry->scanning) {
diff --git a/drivers/firmware/efi/efi.c b/drivers/firmware/efi/efi.c
index 7dd2e2d..1ac199c 100644
--- a/drivers/firmware/efi/efi.c
+++ b/drivers/firmware/efi/efi.c
@@ -27,6 +27,7 @@
#include <linux/slab.h>
#include <linux/acpi.h>
#include <linux/ucs2_string.h>
+#include <linux/memblock.h>
#include <asm/early_ioremap.h>
@@ -347,56 +348,31 @@
/*
* Find the efi memory descriptor for a given physical address. Given a
- * physicall address, determine if it exists within an EFI Memory Map entry,
+ * physical address, determine if it exists within an EFI Memory Map entry,
* and if so, populate the supplied memory descriptor with the appropriate
* data.
*/
int __init efi_mem_desc_lookup(u64 phys_addr, efi_memory_desc_t *out_md)
{
- struct efi_memory_map *map = &efi.memmap;
- phys_addr_t p, e;
+ efi_memory_desc_t *md;
if (!efi_enabled(EFI_MEMMAP)) {
pr_err_once("EFI_MEMMAP is not enabled.\n");
return -EINVAL;
}
- if (!map) {
- pr_err_once("efi.memmap is not set.\n");
- return -EINVAL;
- }
if (!out_md) {
pr_err_once("out_md is null.\n");
return -EINVAL;
}
- if (WARN_ON_ONCE(!map->phys_map))
- return -EINVAL;
- if (WARN_ON_ONCE(map->nr_map == 0) || WARN_ON_ONCE(map->desc_size == 0))
- return -EINVAL;
- e = map->phys_map + map->nr_map * map->desc_size;
- for (p = map->phys_map; p < e; p += map->desc_size) {
- efi_memory_desc_t *md;
+ for_each_efi_memory_desc(md) {
u64 size;
u64 end;
- /*
- * If a driver calls this after efi_free_boot_services,
- * ->map will be NULL, and the target may also not be mapped.
- * So just always get our own virtual map on the CPU.
- *
- */
- md = early_memremap(p, sizeof (*md));
- if (!md) {
- pr_err_once("early_memremap(%pa, %zu) failed.\n",
- &p, sizeof (*md));
- return -ENOMEM;
- }
-
if (!(md->attribute & EFI_MEMORY_RUNTIME) &&
md->type != EFI_BOOT_SERVICES_DATA &&
md->type != EFI_RUNTIME_SERVICES_DATA) {
- early_memunmap(md, sizeof (*md));
continue;
}
@@ -404,11 +380,8 @@
end = md->phys_addr + size;
if (phys_addr >= md->phys_addr && phys_addr < end) {
memcpy(out_md, md, sizeof(*out_md));
- early_memunmap(md, sizeof (*md));
return 0;
}
-
- early_memunmap(md, sizeof (*md));
}
pr_err_once("requested map not found.\n");
return -ENOENT;
@@ -424,6 +397,35 @@
return end;
}
+void __init __weak efi_arch_mem_reserve(phys_addr_t addr, u64 size) {}
+
+/**
+ * efi_mem_reserve - Reserve an EFI memory region
+ * @addr: Physical address to reserve
+ * @size: Size of reservation
+ *
+ * Mark a region as reserved from general kernel allocation and
+ * prevent it being released by efi_free_boot_services().
+ *
+ * This function should be called drivers once they've parsed EFI
+ * configuration tables to figure out where their data lives, e.g.
+ * efi_esrt_init().
+ */
+void __init efi_mem_reserve(phys_addr_t addr, u64 size)
+{
+ if (!memblock_is_region_reserved(addr, size))
+ memblock_reserve(addr, size);
+
+ /*
+ * Some architectures (x86) reserve all boot services ranges
+ * until efi_free_boot_services() because of buggy firmware
+ * implementations. This means the above memblock_reserve() is
+ * superfluous on x86 and instead what it needs to do is
+ * ensure the @start, @size is not freed.
+ */
+ efi_arch_mem_reserve(addr, size);
+}
+
static __initdata efi_config_table_type_t common_tables[] = {
{ACPI_20_TABLE_GUID, "ACPI 2.0", &efi.acpi20},
{ACPI_TABLE_GUID, "ACPI", &efi.acpi},
@@ -811,6 +813,9 @@
case EFI_NOT_FOUND:
err = -ENOENT;
break;
+ case EFI_ABORTED:
+ err = -EINTR;
+ break;
default:
err = -EINVAL;
}
diff --git a/drivers/firmware/efi/efivars.c b/drivers/firmware/efi/efivars.c
index 116b244..3e626fd 100644
--- a/drivers/firmware/efi/efivars.c
+++ b/drivers/firmware/efi/efivars.c
@@ -510,7 +510,8 @@
vendor = del_var->VendorGuid;
}
- efivar_entry_iter_begin();
+ if (efivar_entry_iter_begin())
+ return -EINTR;
entry = efivar_entry_find(name, vendor, &efivar_sysfs_list, true);
if (!entry)
err = -EINVAL;
@@ -575,7 +576,10 @@
return ret;
kobject_uevent(&new_var->kobj, KOBJ_ADD);
- efivar_entry_add(new_var, &efivar_sysfs_list);
+ if (efivar_entry_add(new_var, &efivar_sysfs_list)) {
+ efivar_unregister(new_var);
+ return -EINTR;
+ }
return 0;
}
@@ -690,7 +694,10 @@
static int efivar_sysfs_destroy(struct efivar_entry *entry, void *data)
{
- efivar_entry_remove(entry);
+ int err = efivar_entry_remove(entry);
+
+ if (err)
+ return err;
efivar_unregister(entry);
return 0;
}
@@ -698,7 +705,14 @@
static void efivars_sysfs_exit(void)
{
/* Remove all entries and destroy */
- __efivar_entry_iter(efivar_sysfs_destroy, &efivar_sysfs_list, NULL, NULL);
+ int err;
+
+ err = __efivar_entry_iter(efivar_sysfs_destroy, &efivar_sysfs_list,
+ NULL, NULL);
+ if (err) {
+ pr_err("efivars: Failed to destroy sysfs entries\n");
+ return;
+ }
if (efivars_new_var)
sysfs_remove_bin_file(&efivars_kset->kobj, efivars_new_var);
diff --git a/drivers/firmware/efi/esrt.c b/drivers/firmware/efi/esrt.c
index 75feb3f..1491407 100644
--- a/drivers/firmware/efi/esrt.c
+++ b/drivers/firmware/efi/esrt.c
@@ -16,6 +16,7 @@
#include <linux/device.h>
#include <linux/efi.h>
#include <linux/init.h>
+#include <linux/io.h>
#include <linux/kernel.h>
#include <linux/kobject.h>
#include <linux/list.h>
@@ -235,7 +236,7 @@
};
/*
- * remap the table, copy it to kmalloced pages, and unmap it.
+ * remap the table, validate it, mark it reserved and unmap it.
*/
void __init efi_esrt_init(void)
{
@@ -335,7 +336,7 @@
end = esrt_data + size;
pr_info("Reserving ESRT space from %pa to %pa.\n", &esrt_data, &end);
- memblock_reserve(esrt_data, esrt_data_size);
+ efi_mem_reserve(esrt_data, esrt_data_size);
pr_debug("esrt-init: loaded.\n");
err_memunmap:
@@ -382,28 +383,18 @@
static int __init esrt_sysfs_init(void)
{
int error;
- struct efi_system_resource_table __iomem *ioesrt;
pr_debug("esrt-sysfs: loading.\n");
if (!esrt_data || !esrt_data_size)
return -ENOSYS;
- ioesrt = ioremap(esrt_data, esrt_data_size);
- if (!ioesrt) {
- pr_err("ioremap(%pa, %zu) failed.\n", &esrt_data,
+ esrt = memremap(esrt_data, esrt_data_size, MEMREMAP_WB);
+ if (!esrt) {
+ pr_err("memremap(%pa, %zu) failed.\n", &esrt_data,
esrt_data_size);
return -ENOMEM;
}
- esrt = kmalloc(esrt_data_size, GFP_KERNEL);
- if (!esrt) {
- pr_err("kmalloc failed. (wanted %zu bytes)\n", esrt_data_size);
- iounmap(ioesrt);
- return -ENOMEM;
- }
-
- memcpy_fromio(esrt, ioesrt, esrt_data_size);
-
esrt_kobj = kobject_create_and_add("esrt", efi_kobj);
if (!esrt_kobj) {
pr_err("Firmware table registration failed.\n");
@@ -429,8 +420,6 @@
if (error)
goto err_cleanup_list;
- memblock_remove(esrt_data, esrt_data_size);
-
pr_debug("esrt-sysfs: loaded.\n");
return 0;
diff --git a/drivers/firmware/efi/fake_mem.c b/drivers/firmware/efi/fake_mem.c
index 48430ab..520a40e 100644
--- a/drivers/firmware/efi/fake_mem.c
+++ b/drivers/firmware/efi/fake_mem.c
@@ -35,17 +35,13 @@
#define EFI_MAX_FAKEMEM CONFIG_EFI_MAX_FAKE_MEM
-struct fake_mem {
- struct range range;
- u64 attribute;
-};
-static struct fake_mem fake_mems[EFI_MAX_FAKEMEM];
+static struct efi_mem_range fake_mems[EFI_MAX_FAKEMEM];
static int nr_fake_mem;
static int __init cmp_fake_mem(const void *x1, const void *x2)
{
- const struct fake_mem *m1 = x1;
- const struct fake_mem *m2 = x2;
+ const struct efi_mem_range *m1 = x1;
+ const struct efi_mem_range *m2 = x2;
if (m1->range.start < m2->range.start)
return -1;
@@ -56,40 +52,21 @@
void __init efi_fake_memmap(void)
{
- u64 start, end, m_start, m_end, m_attr;
int new_nr_map = efi.memmap.nr_map;
efi_memory_desc_t *md;
phys_addr_t new_memmap_phy;
void *new_memmap;
- void *old, *new;
int i;
- if (!nr_fake_mem || !efi_enabled(EFI_MEMMAP))
+ if (!nr_fake_mem)
return;
/* count up the number of EFI memory descriptor */
- for_each_efi_memory_desc(md) {
- start = md->phys_addr;
- end = start + (md->num_pages << EFI_PAGE_SHIFT) - 1;
+ for (i = 0; i < nr_fake_mem; i++) {
+ for_each_efi_memory_desc(md) {
+ struct range *r = &fake_mems[i].range;
- for (i = 0; i < nr_fake_mem; i++) {
- /* modifying range */
- m_start = fake_mems[i].range.start;
- m_end = fake_mems[i].range.end;
-
- if (m_start <= start) {
- /* split into 2 parts */
- if (start < m_end && m_end < end)
- new_nr_map++;
- }
- if (start < m_start && m_start < end) {
- /* split into 3 parts */
- if (m_end < end)
- new_nr_map += 2;
- /* split into 2 parts */
- if (end <= m_end)
- new_nr_map++;
- }
+ new_nr_map += efi_memmap_split_count(md, r);
}
}
@@ -107,85 +84,13 @@
return;
}
- for (old = efi.memmap.map, new = new_memmap;
- old < efi.memmap.map_end;
- old += efi.memmap.desc_size, new += efi.memmap.desc_size) {
-
- /* copy original EFI memory descriptor */
- memcpy(new, old, efi.memmap.desc_size);
- md = new;
- start = md->phys_addr;
- end = md->phys_addr + (md->num_pages << EFI_PAGE_SHIFT) - 1;
-
- for (i = 0; i < nr_fake_mem; i++) {
- /* modifying range */
- m_start = fake_mems[i].range.start;
- m_end = fake_mems[i].range.end;
- m_attr = fake_mems[i].attribute;
-
- if (m_start <= start && end <= m_end)
- md->attribute |= m_attr;
-
- if (m_start <= start &&
- (start < m_end && m_end < end)) {
- /* first part */
- md->attribute |= m_attr;
- md->num_pages = (m_end - md->phys_addr + 1) >>
- EFI_PAGE_SHIFT;
- /* latter part */
- new += efi.memmap.desc_size;
- memcpy(new, old, efi.memmap.desc_size);
- md = new;
- md->phys_addr = m_end + 1;
- md->num_pages = (end - md->phys_addr + 1) >>
- EFI_PAGE_SHIFT;
- }
-
- if ((start < m_start && m_start < end) && m_end < end) {
- /* first part */
- md->num_pages = (m_start - md->phys_addr) >>
- EFI_PAGE_SHIFT;
- /* middle part */
- new += efi.memmap.desc_size;
- memcpy(new, old, efi.memmap.desc_size);
- md = new;
- md->attribute |= m_attr;
- md->phys_addr = m_start;
- md->num_pages = (m_end - m_start + 1) >>
- EFI_PAGE_SHIFT;
- /* last part */
- new += efi.memmap.desc_size;
- memcpy(new, old, efi.memmap.desc_size);
- md = new;
- md->phys_addr = m_end + 1;
- md->num_pages = (end - m_end) >>
- EFI_PAGE_SHIFT;
- }
-
- if ((start < m_start && m_start < end) &&
- (end <= m_end)) {
- /* first part */
- md->num_pages = (m_start - md->phys_addr) >>
- EFI_PAGE_SHIFT;
- /* latter part */
- new += efi.memmap.desc_size;
- memcpy(new, old, efi.memmap.desc_size);
- md = new;
- md->phys_addr = m_start;
- md->num_pages = (end - md->phys_addr + 1) >>
- EFI_PAGE_SHIFT;
- md->attribute |= m_attr;
- }
- }
- }
+ for (i = 0; i < nr_fake_mem; i++)
+ efi_memmap_insert(&efi.memmap, new_memmap, &fake_mems[i]);
/* swap into new EFI memmap */
- efi_unmap_memmap();
- efi.memmap.map = new_memmap;
- efi.memmap.phys_map = new_memmap_phy;
- efi.memmap.nr_map = new_nr_map;
- efi.memmap.map_end = efi.memmap.map + efi.memmap.nr_map * efi.memmap.desc_size;
- set_bit(EFI_MEMMAP, &efi.flags);
+ early_memunmap(new_memmap, efi.memmap.desc_size * new_nr_map);
+
+ efi_memmap_install(new_memmap_phy, new_nr_map);
/* print new EFI memmap */
efi_print_memmap();
@@ -223,7 +128,7 @@
p++;
}
- sort(fake_mems, nr_fake_mem, sizeof(struct fake_mem),
+ sort(fake_mems, nr_fake_mem, sizeof(struct efi_mem_range),
cmp_fake_mem, NULL);
for (i = 0; i < nr_fake_mem; i++)
diff --git a/drivers/firmware/efi/memmap.c b/drivers/firmware/efi/memmap.c
new file mode 100644
index 0000000..f03ddec
--- /dev/null
+++ b/drivers/firmware/efi/memmap.c
@@ -0,0 +1,303 @@
+/*
+ * Common EFI memory map functions.
+ */
+
+#define pr_fmt(fmt) "efi: " fmt
+
+#include <linux/init.h>
+#include <linux/kernel.h>
+#include <linux/efi.h>
+#include <linux/io.h>
+#include <asm/early_ioremap.h>
+
+/**
+ * __efi_memmap_init - Common code for mapping the EFI memory map
+ * @data: EFI memory map data
+ * @late: Use early or late mapping function?
+ *
+ * This function takes care of figuring out which function to use to
+ * map the EFI memory map in efi.memmap based on how far into the boot
+ * we are.
+ *
+ * During bootup @late should be %false since we only have access to
+ * the early_memremap*() functions as the vmalloc space isn't setup.
+ * Once the kernel is fully booted we can fallback to the more robust
+ * memremap*() API.
+ *
+ * Returns zero on success, a negative error code on failure.
+ */
+static int __init
+__efi_memmap_init(struct efi_memory_map_data *data, bool late)
+{
+ struct efi_memory_map map;
+ phys_addr_t phys_map;
+
+ if (efi_enabled(EFI_PARAVIRT))
+ return 0;
+
+ phys_map = data->phys_map;
+
+ if (late)
+ map.map = memremap(phys_map, data->size, MEMREMAP_WB);
+ else
+ map.map = early_memremap(phys_map, data->size);
+
+ if (!map.map) {
+ pr_err("Could not map the memory map!\n");
+ return -ENOMEM;
+ }
+
+ map.phys_map = data->phys_map;
+ map.nr_map = data->size / data->desc_size;
+ map.map_end = map.map + data->size;
+
+ map.desc_version = data->desc_version;
+ map.desc_size = data->desc_size;
+ map.late = late;
+
+ set_bit(EFI_MEMMAP, &efi.flags);
+
+ efi.memmap = map;
+
+ return 0;
+}
+
+/**
+ * efi_memmap_init_early - Map the EFI memory map data structure
+ * @data: EFI memory map data
+ *
+ * Use early_memremap() to map the passed in EFI memory map and assign
+ * it to efi.memmap.
+ */
+int __init efi_memmap_init_early(struct efi_memory_map_data *data)
+{
+ /* Cannot go backwards */
+ WARN_ON(efi.memmap.late);
+
+ return __efi_memmap_init(data, false);
+}
+
+void __init efi_memmap_unmap(void)
+{
+ if (!efi.memmap.late) {
+ unsigned long size;
+
+ size = efi.memmap.desc_size * efi.memmap.nr_map;
+ early_memunmap(efi.memmap.map, size);
+ } else {
+ memunmap(efi.memmap.map);
+ }
+
+ efi.memmap.map = NULL;
+ clear_bit(EFI_MEMMAP, &efi.flags);
+}
+
+/**
+ * efi_memmap_init_late - Map efi.memmap with memremap()
+ * @phys_addr: Physical address of the new EFI memory map
+ * @size: Size in bytes of the new EFI memory map
+ *
+ * Setup a mapping of the EFI memory map using ioremap_cache(). This
+ * function should only be called once the vmalloc space has been
+ * setup and is therefore not suitable for calling during early EFI
+ * initialise, e.g. in efi_init(). Additionally, it expects
+ * efi_memmap_init_early() to have already been called.
+ *
+ * The reason there are two EFI memmap initialisation
+ * (efi_memmap_init_early() and this late version) is because the
+ * early EFI memmap should be explicitly unmapped once EFI
+ * initialisation is complete as the fixmap space used to map the EFI
+ * memmap (via early_memremap()) is a scarce resource.
+ *
+ * This late mapping is intended to persist for the duration of
+ * runtime so that things like efi_mem_desc_lookup() and
+ * efi_mem_attributes() always work.
+ *
+ * Returns zero on success, a negative error code on failure.
+ */
+int __init efi_memmap_init_late(phys_addr_t addr, unsigned long size)
+{
+ struct efi_memory_map_data data = {
+ .phys_map = addr,
+ .size = size,
+ };
+
+ /* Did we forget to unmap the early EFI memmap? */
+ WARN_ON(efi.memmap.map);
+
+ /* Were we already called? */
+ WARN_ON(efi.memmap.late);
+
+ /*
+ * It makes no sense to allow callers to register different
+ * values for the following fields. Copy them out of the
+ * existing early EFI memmap.
+ */
+ data.desc_version = efi.memmap.desc_version;
+ data.desc_size = efi.memmap.desc_size;
+
+ return __efi_memmap_init(&data, true);
+}
+
+/**
+ * efi_memmap_install - Install a new EFI memory map in efi.memmap
+ * @addr: Physical address of the memory map
+ * @nr_map: Number of entries in the memory map
+ *
+ * Unlike efi_memmap_init_*(), this function does not allow the caller
+ * to switch from early to late mappings. It simply uses the existing
+ * mapping function and installs the new memmap.
+ *
+ * Returns zero on success, a negative error code on failure.
+ */
+int __init efi_memmap_install(phys_addr_t addr, unsigned int nr_map)
+{
+ struct efi_memory_map_data data;
+
+ efi_memmap_unmap();
+
+ data.phys_map = addr;
+ data.size = efi.memmap.desc_size * nr_map;
+ data.desc_version = efi.memmap.desc_version;
+ data.desc_size = efi.memmap.desc_size;
+
+ return __efi_memmap_init(&data, efi.memmap.late);
+}
+
+/**
+ * efi_memmap_split_count - Count number of additional EFI memmap entries
+ * @md: EFI memory descriptor to split
+ * @range: Address range (start, end) to split around
+ *
+ * Returns the number of additional EFI memmap entries required to
+ * accomodate @range.
+ */
+int __init efi_memmap_split_count(efi_memory_desc_t *md, struct range *range)
+{
+ u64 m_start, m_end;
+ u64 start, end;
+ int count = 0;
+
+ start = md->phys_addr;
+ end = start + (md->num_pages << EFI_PAGE_SHIFT) - 1;
+
+ /* modifying range */
+ m_start = range->start;
+ m_end = range->end;
+
+ if (m_start <= start) {
+ /* split into 2 parts */
+ if (start < m_end && m_end < end)
+ count++;
+ }
+
+ if (start < m_start && m_start < end) {
+ /* split into 3 parts */
+ if (m_end < end)
+ count += 2;
+ /* split into 2 parts */
+ if (end <= m_end)
+ count++;
+ }
+
+ return count;
+}
+
+/**
+ * efi_memmap_insert - Insert a memory region in an EFI memmap
+ * @old_memmap: The existing EFI memory map structure
+ * @buf: Address of buffer to store new map
+ * @mem: Memory map entry to insert
+ *
+ * It is suggested that you call efi_memmap_split_count() first
+ * to see how large @buf needs to be.
+ */
+void __init efi_memmap_insert(struct efi_memory_map *old_memmap, void *buf,
+ struct efi_mem_range *mem)
+{
+ u64 m_start, m_end, m_attr;
+ efi_memory_desc_t *md;
+ u64 start, end;
+ void *old, *new;
+
+ /* modifying range */
+ m_start = mem->range.start;
+ m_end = mem->range.end;
+ m_attr = mem->attribute;
+
+ /*
+ * The EFI memory map deals with regions in EFI_PAGE_SIZE
+ * units. Ensure that the region described by 'mem' is aligned
+ * correctly.
+ */
+ if (!IS_ALIGNED(m_start, EFI_PAGE_SIZE) ||
+ !IS_ALIGNED(m_end + 1, EFI_PAGE_SIZE)) {
+ WARN_ON(1);
+ return;
+ }
+
+ for (old = old_memmap->map, new = buf;
+ old < old_memmap->map_end;
+ old += old_memmap->desc_size, new += old_memmap->desc_size) {
+
+ /* copy original EFI memory descriptor */
+ memcpy(new, old, old_memmap->desc_size);
+ md = new;
+ start = md->phys_addr;
+ end = md->phys_addr + (md->num_pages << EFI_PAGE_SHIFT) - 1;
+
+ if (m_start <= start && end <= m_end)
+ md->attribute |= m_attr;
+
+ if (m_start <= start &&
+ (start < m_end && m_end < end)) {
+ /* first part */
+ md->attribute |= m_attr;
+ md->num_pages = (m_end - md->phys_addr + 1) >>
+ EFI_PAGE_SHIFT;
+ /* latter part */
+ new += old_memmap->desc_size;
+ memcpy(new, old, old_memmap->desc_size);
+ md = new;
+ md->phys_addr = m_end + 1;
+ md->num_pages = (end - md->phys_addr + 1) >>
+ EFI_PAGE_SHIFT;
+ }
+
+ if ((start < m_start && m_start < end) && m_end < end) {
+ /* first part */
+ md->num_pages = (m_start - md->phys_addr) >>
+ EFI_PAGE_SHIFT;
+ /* middle part */
+ new += old_memmap->desc_size;
+ memcpy(new, old, old_memmap->desc_size);
+ md = new;
+ md->attribute |= m_attr;
+ md->phys_addr = m_start;
+ md->num_pages = (m_end - m_start + 1) >>
+ EFI_PAGE_SHIFT;
+ /* last part */
+ new += old_memmap->desc_size;
+ memcpy(new, old, old_memmap->desc_size);
+ md = new;
+ md->phys_addr = m_end + 1;
+ md->num_pages = (end - m_end) >>
+ EFI_PAGE_SHIFT;
+ }
+
+ if ((start < m_start && m_start < end) &&
+ (end <= m_end)) {
+ /* first part */
+ md->num_pages = (m_start - md->phys_addr) >>
+ EFI_PAGE_SHIFT;
+ /* latter part */
+ new += old_memmap->desc_size;
+ memcpy(new, old, old_memmap->desc_size);
+ md = new;
+ md->phys_addr = m_start;
+ md->num_pages = (end - md->phys_addr + 1) >>
+ EFI_PAGE_SHIFT;
+ md->attribute |= m_attr;
+ }
+ }
+}
diff --git a/drivers/firmware/efi/runtime-map.c b/drivers/firmware/efi/runtime-map.c
index 5c55227..8e64b77 100644
--- a/drivers/firmware/efi/runtime-map.c
+++ b/drivers/firmware/efi/runtime-map.c
@@ -14,10 +14,6 @@
#include <asm/setup.h>
-static void *efi_runtime_map;
-static int nr_efi_runtime_map;
-static u32 efi_memdesc_size;
-
struct efi_runtime_map_entry {
efi_memory_desc_t md;
struct kobject kobj; /* kobject for each entry */
@@ -106,7 +102,8 @@
static struct kset *map_kset;
static struct efi_runtime_map_entry *
-add_sysfs_runtime_map_entry(struct kobject *kobj, int nr)
+add_sysfs_runtime_map_entry(struct kobject *kobj, int nr,
+ efi_memory_desc_t *md)
{
int ret;
struct efi_runtime_map_entry *entry;
@@ -124,8 +121,7 @@
return ERR_PTR(-ENOMEM);
}
- memcpy(&entry->md, efi_runtime_map + nr * efi_memdesc_size,
- sizeof(efi_memory_desc_t));
+ memcpy(&entry->md, md, sizeof(efi_memory_desc_t));
kobject_init(&entry->kobj, &map_ktype);
entry->kobj.kset = map_kset;
@@ -142,12 +138,12 @@
int efi_get_runtime_map_size(void)
{
- return nr_efi_runtime_map * efi_memdesc_size;
+ return efi.memmap.nr_map * efi.memmap.desc_size;
}
int efi_get_runtime_map_desc_size(void)
{
- return efi_memdesc_size;
+ return efi.memmap.desc_size;
}
int efi_runtime_map_copy(void *buf, size_t bufsz)
@@ -157,38 +153,33 @@
if (sz > bufsz)
sz = bufsz;
- memcpy(buf, efi_runtime_map, sz);
+ memcpy(buf, efi.memmap.map, sz);
return 0;
}
-void efi_runtime_map_setup(void *map, int nr_entries, u32 desc_size)
-{
- efi_runtime_map = map;
- nr_efi_runtime_map = nr_entries;
- efi_memdesc_size = desc_size;
-}
-
int __init efi_runtime_map_init(struct kobject *efi_kobj)
{
int i, j, ret = 0;
struct efi_runtime_map_entry *entry;
+ efi_memory_desc_t *md;
- if (!efi_runtime_map)
+ if (!efi_enabled(EFI_MEMMAP))
return 0;
- map_entries = kzalloc(nr_efi_runtime_map * sizeof(entry), GFP_KERNEL);
+ map_entries = kzalloc(efi.memmap.nr_map * sizeof(entry), GFP_KERNEL);
if (!map_entries) {
ret = -ENOMEM;
goto out;
}
- for (i = 0; i < nr_efi_runtime_map; i++) {
- entry = add_sysfs_runtime_map_entry(efi_kobj, i);
+ i = 0;
+ for_each_efi_memory_desc(md) {
+ entry = add_sysfs_runtime_map_entry(efi_kobj, i, md);
if (IS_ERR(entry)) {
ret = PTR_ERR(entry);
goto out_add_entry;
}
- *(map_entries + i) = entry;
+ *(map_entries + i++) = entry;
}
return 0;
diff --git a/drivers/firmware/efi/runtime-wrappers.c b/drivers/firmware/efi/runtime-wrappers.c
index 4195877..ae54870b 100644
--- a/drivers/firmware/efi/runtime-wrappers.c
+++ b/drivers/firmware/efi/runtime-wrappers.c
@@ -14,11 +14,13 @@
* This file is released under the GPLv2.
*/
+#define pr_fmt(fmt) "efi: " fmt
+
#include <linux/bug.h>
#include <linux/efi.h>
#include <linux/irqflags.h>
#include <linux/mutex.h>
-#include <linux/spinlock.h>
+#include <linux/semaphore.h>
#include <linux/stringify.h>
#include <asm/efi.h>
@@ -81,20 +83,21 @@
* +------------------------------------+-------------------------------+
*
* Due to the fact that the EFI pstore may write to the variable store in
- * interrupt context, we need to use a spinlock for at least the groups that
+ * interrupt context, we need to use a lock for at least the groups that
* contain SetVariable() and QueryVariableInfo(). That leaves little else, as
* none of the remaining functions are actually ever called at runtime.
- * So let's just use a single spinlock to serialize all Runtime Services calls.
+ * So let's just use a single lock to serialize all Runtime Services calls.
*/
-static DEFINE_SPINLOCK(efi_runtime_lock);
+static DEFINE_SEMAPHORE(efi_runtime_lock);
static efi_status_t virt_efi_get_time(efi_time_t *tm, efi_time_cap_t *tc)
{
efi_status_t status;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(get_time, tm, tc);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -102,9 +105,10 @@
{
efi_status_t status;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(set_time, tm);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -114,9 +118,10 @@
{
efi_status_t status;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(get_wakeup_time, enabled, pending, tm);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -124,9 +129,10 @@
{
efi_status_t status;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(set_wakeup_time, enabled, tm);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -138,10 +144,11 @@
{
efi_status_t status;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(get_variable, name, vendor, attr, data_size,
data);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -151,9 +158,10 @@
{
efi_status_t status;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(get_next_variable, name_size, name, vendor);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -165,10 +173,11 @@
{
efi_status_t status;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(set_variable, name, vendor, attr, data_size,
data);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -179,12 +188,12 @@
{
efi_status_t status;
- if (!spin_trylock(&efi_runtime_lock))
+ if (down_trylock(&efi_runtime_lock))
return EFI_NOT_READY;
status = efi_call_virt(set_variable, name, vendor, attr, data_size,
data);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -199,10 +208,11 @@
if (efi.runtime_version < EFI_2_00_SYSTEM_TABLE_REVISION)
return EFI_UNSUPPORTED;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(query_variable_info, attr, storage_space,
remaining_space, max_variable_size);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -217,12 +227,12 @@
if (efi.runtime_version < EFI_2_00_SYSTEM_TABLE_REVISION)
return EFI_UNSUPPORTED;
- if (!spin_trylock(&efi_runtime_lock))
+ if (down_trylock(&efi_runtime_lock))
return EFI_NOT_READY;
status = efi_call_virt(query_variable_info, attr, storage_space,
remaining_space, max_variable_size);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -230,9 +240,10 @@
{
efi_status_t status;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(get_next_high_mono_count, count);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -241,9 +252,13 @@
unsigned long data_size,
efi_char16_t *data)
{
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock)) {
+ pr_warn("failed to invoke the reset_system() runtime service:\n"
+ "could not get exclusive access to the firmware\n");
+ return;
+ }
__efi_call_virt(reset_system, reset_type, status, data_size, data);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
}
static efi_status_t virt_efi_update_capsule(efi_capsule_header_t **capsules,
@@ -255,9 +270,10 @@
if (efi.runtime_version < EFI_2_00_SYSTEM_TABLE_REVISION)
return EFI_UNSUPPORTED;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(update_capsule, capsules, count, sg_list);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
@@ -271,10 +287,11 @@
if (efi.runtime_version < EFI_2_00_SYSTEM_TABLE_REVISION)
return EFI_UNSUPPORTED;
- spin_lock(&efi_runtime_lock);
+ if (down_interruptible(&efi_runtime_lock))
+ return EFI_ABORTED;
status = efi_call_virt(query_capsule_caps, capsules, count, max_size,
reset_type);
- spin_unlock(&efi_runtime_lock);
+ up(&efi_runtime_lock);
return status;
}
diff --git a/drivers/firmware/efi/test/Makefile b/drivers/firmware/efi/test/Makefile
new file mode 100644
index 0000000..bcd4577
--- /dev/null
+++ b/drivers/firmware/efi/test/Makefile
@@ -0,0 +1 @@
+obj-$(CONFIG_EFI_TEST) += efi_test.o
diff --git a/drivers/firmware/efi/test/efi_test.c b/drivers/firmware/efi/test/efi_test.c
new file mode 100644
index 0000000..f61bb52
--- /dev/null
+++ b/drivers/firmware/efi/test/efi_test.c
@@ -0,0 +1,749 @@
+/*
+ * EFI Test Driver for Runtime Services
+ *
+ * Copyright(C) 2012-2016 Canonical Ltd.
+ *
+ * This driver exports EFI runtime services interfaces into userspace, which
+ * allow to use and test UEFI runtime services provided by firmware.
+ *
+ */
+
+#include <linux/version.h>
+#include <linux/miscdevice.h>
+#include <linux/module.h>
+#include <linux/init.h>
+#include <linux/proc_fs.h>
+#include <linux/efi.h>
+#include <linux/slab.h>
+#include <linux/uaccess.h>
+
+#include "efi_test.h"
+
+MODULE_AUTHOR("Ivan Hu <ivan.hu@canonical.com>");
+MODULE_DESCRIPTION("EFI Test Driver");
+MODULE_LICENSE("GPL");
+
+/*
+ * Count the bytes in 'str', including the terminating NULL.
+ *
+ * Note this function returns the number of *bytes*, not the number of
+ * ucs2 characters.
+ */
+static inline size_t user_ucs2_strsize(efi_char16_t __user *str)
+{
+ efi_char16_t *s = str, c;
+ size_t len;
+
+ if (!str)
+ return 0;
+
+ /* Include terminating NULL */
+ len = sizeof(efi_char16_t);
+
+ if (get_user(c, s++)) {
+ /* Can't read userspace memory for size */
+ return 0;
+ }
+
+ while (c != 0) {
+ if (get_user(c, s++)) {
+ /* Can't read userspace memory for size */
+ return 0;
+ }
+ len += sizeof(efi_char16_t);
+ }
+ return len;
+}
+
+/*
+ * Allocate a buffer and copy a ucs2 string from user space into it.
+ */
+static inline int
+copy_ucs2_from_user_len(efi_char16_t **dst, efi_char16_t __user *src,
+ size_t len)
+{
+ efi_char16_t *buf;
+
+ if (!src) {
+ *dst = NULL;
+ return 0;
+ }
+
+ if (!access_ok(VERIFY_READ, src, 1))
+ return -EFAULT;
+
+ buf = kmalloc(len, GFP_KERNEL);
+ if (!buf) {
+ *dst = NULL;
+ return -ENOMEM;
+ }
+ *dst = buf;
+
+ if (copy_from_user(*dst, src, len)) {
+ kfree(buf);
+ return -EFAULT;
+ }
+
+ return 0;
+}
+
+/*
+ * Count the bytes in 'str', including the terminating NULL.
+ *
+ * Just a wrap for user_ucs2_strsize
+ */
+static inline int
+get_ucs2_strsize_from_user(efi_char16_t __user *src, size_t *len)
+{
+ if (!access_ok(VERIFY_READ, src, 1))
+ return -EFAULT;
+
+ *len = user_ucs2_strsize(src);
+ if (*len == 0)
+ return -EFAULT;
+
+ return 0;
+}
+
+/*
+ * Calculate the required buffer allocation size and copy a ucs2 string
+ * from user space into it.
+ *
+ * This function differs from copy_ucs2_from_user_len() because it
+ * calculates the size of the buffer to allocate by taking the length of
+ * the string 'src'.
+ *
+ * If a non-zero value is returned, the caller MUST NOT access 'dst'.
+ *
+ * It is the caller's responsibility to free 'dst'.
+ */
+static inline int
+copy_ucs2_from_user(efi_char16_t **dst, efi_char16_t __user *src)
+{
+ size_t len;
+
+ if (!access_ok(VERIFY_READ, src, 1))
+ return -EFAULT;
+
+ len = user_ucs2_strsize(src);
+ if (len == 0)
+ return -EFAULT;
+ return copy_ucs2_from_user_len(dst, src, len);
+}
+
+/*
+ * Copy a ucs2 string to a user buffer.
+ *
+ * This function is a simple wrapper around copy_to_user() that does
+ * nothing if 'src' is NULL, which is useful for reducing the amount of
+ * NULL checking the caller has to do.
+ *
+ * 'len' specifies the number of bytes to copy.
+ */
+static inline int
+copy_ucs2_to_user_len(efi_char16_t __user *dst, efi_char16_t *src, size_t len)
+{
+ if (!src)
+ return 0;
+
+ if (!access_ok(VERIFY_WRITE, dst, 1))
+ return -EFAULT;
+
+ return copy_to_user(dst, src, len);
+}
+
+static long efi_runtime_get_variable(unsigned long arg)
+{
+ struct efi_getvariable __user *getvariable_user;
+ struct efi_getvariable getvariable;
+ unsigned long datasize, prev_datasize, *dz;
+ efi_guid_t vendor_guid, *vd = NULL;
+ efi_status_t status;
+ efi_char16_t *name = NULL;
+ u32 attr, *at;
+ void *data = NULL;
+ int rv = 0;
+
+ getvariable_user = (struct efi_getvariable __user *)arg;
+
+ if (copy_from_user(&getvariable, getvariable_user,
+ sizeof(getvariable)))
+ return -EFAULT;
+ if (getvariable.data_size &&
+ get_user(datasize, getvariable.data_size))
+ return -EFAULT;
+ if (getvariable.vendor_guid) {
+ if (copy_from_user(&vendor_guid, getvariable.vendor_guid,
+ sizeof(vendor_guid)))
+ return -EFAULT;
+ vd = &vendor_guid;
+ }
+
+ if (getvariable.variable_name) {
+ rv = copy_ucs2_from_user(&name, getvariable.variable_name);
+ if (rv)
+ return rv;
+ }
+
+ at = getvariable.attributes ? &attr : NULL;
+ dz = getvariable.data_size ? &datasize : NULL;
+
+ if (getvariable.data_size && getvariable.data) {
+ data = kmalloc(datasize, GFP_KERNEL);
+ if (!data) {
+ kfree(name);
+ return -ENOMEM;
+ }
+ }
+
+ prev_datasize = datasize;
+ status = efi.get_variable(name, vd, at, dz, data);
+ kfree(name);
+
+ if (put_user(status, getvariable.status)) {
+ rv = -EFAULT;
+ goto out;
+ }
+
+ if (status != EFI_SUCCESS) {
+ if (status == EFI_BUFFER_TOO_SMALL) {
+ if (dz && put_user(datasize, getvariable.data_size)) {
+ rv = -EFAULT;
+ goto out;
+ }
+ }
+ rv = -EINVAL;
+ goto out;
+ }
+
+ if (prev_datasize < datasize) {
+ rv = -EINVAL;
+ goto out;
+ }
+
+ if (data) {
+ if (copy_to_user(getvariable.data, data, datasize)) {
+ rv = -EFAULT;
+ goto out;
+ }
+ }
+
+ if (at && put_user(attr, getvariable.attributes)) {
+ rv = -EFAULT;
+ goto out;
+ }
+
+ if (dz && put_user(datasize, getvariable.data_size))
+ rv = -EFAULT;
+
+out:
+ kfree(data);
+ return rv;
+
+}
+
+static long efi_runtime_set_variable(unsigned long arg)
+{
+ struct efi_setvariable __user *setvariable_user;
+ struct efi_setvariable setvariable;
+ efi_guid_t vendor_guid;
+ efi_status_t status;
+ efi_char16_t *name = NULL;
+ void *data;
+ int rv = 0;
+
+ setvariable_user = (struct efi_setvariable __user *)arg;
+
+ if (copy_from_user(&setvariable, setvariable_user, sizeof(setvariable)))
+ return -EFAULT;
+ if (copy_from_user(&vendor_guid, setvariable.vendor_guid,
+ sizeof(vendor_guid)))
+ return -EFAULT;
+
+ if (setvariable.variable_name) {
+ rv = copy_ucs2_from_user(&name, setvariable.variable_name);
+ if (rv)
+ return rv;
+ }
+
+ data = kmalloc(setvariable.data_size, GFP_KERNEL);
+ if (!data) {
+ kfree(name);
+ return -ENOMEM;
+ }
+ if (copy_from_user(data, setvariable.data, setvariable.data_size)) {
+ rv = -EFAULT;
+ goto out;
+ }
+
+ status = efi.set_variable(name, &vendor_guid,
+ setvariable.attributes,
+ setvariable.data_size, data);
+
+ if (put_user(status, setvariable.status)) {
+ rv = -EFAULT;
+ goto out;
+ }
+
+ rv = status == EFI_SUCCESS ? 0 : -EINVAL;
+
+out:
+ kfree(data);
+ kfree(name);
+
+ return rv;
+}
+
+static long efi_runtime_get_time(unsigned long arg)
+{
+ struct efi_gettime __user *gettime_user;
+ struct efi_gettime gettime;
+ efi_status_t status;
+ efi_time_cap_t cap;
+ efi_time_t efi_time;
+
+ gettime_user = (struct efi_gettime __user *)arg;
+ if (copy_from_user(&gettime, gettime_user, sizeof(gettime)))
+ return -EFAULT;
+
+ status = efi.get_time(gettime.time ? &efi_time : NULL,
+ gettime.capabilities ? &cap : NULL);
+
+ if (put_user(status, gettime.status))
+ return -EFAULT;
+
+ if (status != EFI_SUCCESS)
+ return -EINVAL;
+
+ if (gettime.capabilities) {
+ efi_time_cap_t __user *cap_local;
+
+ cap_local = (efi_time_cap_t *)gettime.capabilities;
+ if (put_user(cap.resolution, &(cap_local->resolution)) ||
+ put_user(cap.accuracy, &(cap_local->accuracy)) ||
+ put_user(cap.sets_to_zero, &(cap_local->sets_to_zero)))
+ return -EFAULT;
+ }
+ if (gettime.time) {
+ if (copy_to_user(gettime.time, &efi_time, sizeof(efi_time_t)))
+ return -EFAULT;
+ }
+
+ return 0;
+}
+
+static long efi_runtime_set_time(unsigned long arg)
+{
+ struct efi_settime __user *settime_user;
+ struct efi_settime settime;
+ efi_status_t status;
+ efi_time_t efi_time;
+
+ settime_user = (struct efi_settime __user *)arg;
+ if (copy_from_user(&settime, settime_user, sizeof(settime)))
+ return -EFAULT;
+ if (copy_from_user(&efi_time, settime.time,
+ sizeof(efi_time_t)))
+ return -EFAULT;
+ status = efi.set_time(&efi_time);
+
+ if (put_user(status, settime.status))
+ return -EFAULT;
+
+ return status == EFI_SUCCESS ? 0 : -EINVAL;
+}
+
+static long efi_runtime_get_waketime(unsigned long arg)
+{
+ struct efi_getwakeuptime __user *getwakeuptime_user;
+ struct efi_getwakeuptime getwakeuptime;
+ efi_bool_t enabled, pending;
+ efi_status_t status;
+ efi_time_t efi_time;
+
+ getwakeuptime_user = (struct efi_getwakeuptime __user *)arg;
+ if (copy_from_user(&getwakeuptime, getwakeuptime_user,
+ sizeof(getwakeuptime)))
+ return -EFAULT;
+
+ status = efi.get_wakeup_time(
+ getwakeuptime.enabled ? (efi_bool_t *)&enabled : NULL,
+ getwakeuptime.pending ? (efi_bool_t *)&pending : NULL,
+ getwakeuptime.time ? &efi_time : NULL);
+
+ if (put_user(status, getwakeuptime.status))
+ return -EFAULT;
+
+ if (status != EFI_SUCCESS)
+ return -EINVAL;
+
+ if (getwakeuptime.enabled && put_user(enabled,
+ getwakeuptime.enabled))
+ return -EFAULT;
+
+ if (getwakeuptime.time) {
+ if (copy_to_user(getwakeuptime.time, &efi_time,
+ sizeof(efi_time_t)))
+ return -EFAULT;
+ }
+
+ return 0;
+}
+
+static long efi_runtime_set_waketime(unsigned long arg)
+{
+ struct efi_setwakeuptime __user *setwakeuptime_user;
+ struct efi_setwakeuptime setwakeuptime;
+ efi_bool_t enabled;
+ efi_status_t status;
+ efi_time_t efi_time;
+
+ setwakeuptime_user = (struct efi_setwakeuptime __user *)arg;
+
+ if (copy_from_user(&setwakeuptime, setwakeuptime_user,
+ sizeof(setwakeuptime)))
+ return -EFAULT;
+
+ enabled = setwakeuptime.enabled;
+ if (setwakeuptime.time) {
+ if (copy_from_user(&efi_time, setwakeuptime.time,
+ sizeof(efi_time_t)))
+ return -EFAULT;
+
+ status = efi.set_wakeup_time(enabled, &efi_time);
+ } else
+ status = efi.set_wakeup_time(enabled, NULL);
+
+ if (put_user(status, setwakeuptime.status))
+ return -EFAULT;
+
+ return status == EFI_SUCCESS ? 0 : -EINVAL;
+}
+
+static long efi_runtime_get_nextvariablename(unsigned long arg)
+{
+ struct efi_getnextvariablename __user *getnextvariablename_user;
+ struct efi_getnextvariablename getnextvariablename;
+ unsigned long name_size, prev_name_size = 0, *ns = NULL;
+ efi_status_t status;
+ efi_guid_t *vd = NULL;
+ efi_guid_t vendor_guid;
+ efi_char16_t *name = NULL;
+ int rv;
+
+ getnextvariablename_user = (struct efi_getnextvariablename __user *)arg;
+
+ if (copy_from_user(&getnextvariablename, getnextvariablename_user,
+ sizeof(getnextvariablename)))
+ return -EFAULT;
+
+ if (getnextvariablename.variable_name_size) {
+ if (get_user(name_size, getnextvariablename.variable_name_size))
+ return -EFAULT;
+ ns = &name_size;
+ prev_name_size = name_size;
+ }
+
+ if (getnextvariablename.vendor_guid) {
+ if (copy_from_user(&vendor_guid,
+ getnextvariablename.vendor_guid,
+ sizeof(vendor_guid)))
+ return -EFAULT;
+ vd = &vendor_guid;
+ }
+
+ if (getnextvariablename.variable_name) {
+ size_t name_string_size = 0;
+
+ rv = get_ucs2_strsize_from_user(
+ getnextvariablename.variable_name,
+ &name_string_size);
+ if (rv)
+ return rv;
+ /*
+ * The name_size may be smaller than the real buffer size where
+ * variable name located in some use cases. The most typical
+ * case is passing a 0 to get the required buffer size for the
+ * 1st time call. So we need to copy the content from user
+ * space for at least the string size of variable name, or else
+ * the name passed to UEFI may not be terminated as we expected.
+ */
+ rv = copy_ucs2_from_user_len(&name,
+ getnextvariablename.variable_name,
+ prev_name_size > name_string_size ?
+ prev_name_size : name_string_size);
+ if (rv)
+ return rv;
+ }
+
+ status = efi.get_next_variable(ns, name, vd);
+
+ if (put_user(status, getnextvariablename.status)) {
+ rv = -EFAULT;
+ goto out;
+ }
+
+ if (status != EFI_SUCCESS) {
+ if (status == EFI_BUFFER_TOO_SMALL) {
+ if (ns && put_user(*ns,
+ getnextvariablename.variable_name_size)) {
+ rv = -EFAULT;
+ goto out;
+ }
+ }
+ rv = -EINVAL;
+ goto out;
+ }
+
+ if (name) {
+ if (copy_ucs2_to_user_len(getnextvariablename.variable_name,
+ name, prev_name_size)) {
+ rv = -EFAULT;
+ goto out;
+ }
+ }
+
+ if (ns) {
+ if (put_user(*ns, getnextvariablename.variable_name_size)) {
+ rv = -EFAULT;
+ goto out;
+ }
+ }
+
+ if (vd) {
+ if (copy_to_user(getnextvariablename.vendor_guid, vd,
+ sizeof(efi_guid_t)))
+ rv = -EFAULT;
+ }
+
+out:
+ kfree(name);
+ return rv;
+}
+
+static long efi_runtime_get_nexthighmonocount(unsigned long arg)
+{
+ struct efi_getnexthighmonotoniccount __user *getnexthighmonocount_user;
+ struct efi_getnexthighmonotoniccount getnexthighmonocount;
+ efi_status_t status;
+ u32 count;
+
+ getnexthighmonocount_user = (struct
+ efi_getnexthighmonotoniccount __user *)arg;
+
+ if (copy_from_user(&getnexthighmonocount,
+ getnexthighmonocount_user,
+ sizeof(getnexthighmonocount)))
+ return -EFAULT;
+
+ status = efi.get_next_high_mono_count(
+ getnexthighmonocount.high_count ? &count : NULL);
+
+ if (put_user(status, getnexthighmonocount.status))
+ return -EFAULT;
+
+ if (status != EFI_SUCCESS)
+ return -EINVAL;
+
+ if (getnexthighmonocount.high_count &&
+ put_user(count, getnexthighmonocount.high_count))
+ return -EFAULT;
+
+ return 0;
+}
+
+static long efi_runtime_query_variableinfo(unsigned long arg)
+{
+ struct efi_queryvariableinfo __user *queryvariableinfo_user;
+ struct efi_queryvariableinfo queryvariableinfo;
+ efi_status_t status;
+ u64 max_storage, remaining, max_size;
+
+ queryvariableinfo_user = (struct efi_queryvariableinfo __user *)arg;
+
+ if (copy_from_user(&queryvariableinfo, queryvariableinfo_user,
+ sizeof(queryvariableinfo)))
+ return -EFAULT;
+
+ status = efi.query_variable_info(queryvariableinfo.attributes,
+ &max_storage, &remaining, &max_size);
+
+ if (put_user(status, queryvariableinfo.status))
+ return -EFAULT;
+
+ if (status != EFI_SUCCESS)
+ return -EINVAL;
+
+ if (put_user(max_storage,
+ queryvariableinfo.maximum_variable_storage_size))
+ return -EFAULT;
+
+ if (put_user(remaining,
+ queryvariableinfo.remaining_variable_storage_size))
+ return -EFAULT;
+
+ if (put_user(max_size, queryvariableinfo.maximum_variable_size))
+ return -EFAULT;
+
+ return 0;
+}
+
+static long efi_runtime_query_capsulecaps(unsigned long arg)
+{
+ struct efi_querycapsulecapabilities __user *qcaps_user;
+ struct efi_querycapsulecapabilities qcaps;
+ efi_capsule_header_t *capsules;
+ efi_status_t status;
+ u64 max_size;
+ int i, reset_type;
+ int rv = 0;
+
+ qcaps_user = (struct efi_querycapsulecapabilities __user *)arg;
+
+ if (copy_from_user(&qcaps, qcaps_user, sizeof(qcaps)))
+ return -EFAULT;
+
+ capsules = kcalloc(qcaps.capsule_count + 1,
+ sizeof(efi_capsule_header_t), GFP_KERNEL);
+ if (!capsules)
+ return -ENOMEM;
+
+ for (i = 0; i < qcaps.capsule_count; i++) {
+ efi_capsule_header_t *c;
+ /*
+ * We cannot dereference qcaps.capsule_header_array directly to
+ * obtain the address of the capsule as it resides in the
+ * user space
+ */
+ if (get_user(c, qcaps.capsule_header_array + i)) {
+ rv = -EFAULT;
+ goto out;
+ }
+ if (copy_from_user(&capsules[i], c,
+ sizeof(efi_capsule_header_t))) {
+ rv = -EFAULT;
+ goto out;
+ }
+ }
+
+ qcaps.capsule_header_array = &capsules;
+
+ status = efi.query_capsule_caps((efi_capsule_header_t **)
+ qcaps.capsule_header_array,
+ qcaps.capsule_count,
+ &max_size, &reset_type);
+
+ if (put_user(status, qcaps.status)) {
+ rv = -EFAULT;
+ goto out;
+ }
+
+ if (status != EFI_SUCCESS) {
+ rv = -EINVAL;
+ goto out;
+ }
+
+ if (put_user(max_size, qcaps.maximum_capsule_size)) {
+ rv = -EFAULT;
+ goto out;
+ }
+
+ if (put_user(reset_type, qcaps.reset_type))
+ rv = -EFAULT;
+
+out:
+ kfree(capsules);
+ return rv;
+}
+
+static long efi_test_ioctl(struct file *file, unsigned int cmd,
+ unsigned long arg)
+{
+ switch (cmd) {
+ case EFI_RUNTIME_GET_VARIABLE:
+ return efi_runtime_get_variable(arg);
+
+ case EFI_RUNTIME_SET_VARIABLE:
+ return efi_runtime_set_variable(arg);
+
+ case EFI_RUNTIME_GET_TIME:
+ return efi_runtime_get_time(arg);
+
+ case EFI_RUNTIME_SET_TIME:
+ return efi_runtime_set_time(arg);
+
+ case EFI_RUNTIME_GET_WAKETIME:
+ return efi_runtime_get_waketime(arg);
+
+ case EFI_RUNTIME_SET_WAKETIME:
+ return efi_runtime_set_waketime(arg);
+
+ case EFI_RUNTIME_GET_NEXTVARIABLENAME:
+ return efi_runtime_get_nextvariablename(arg);
+
+ case EFI_RUNTIME_GET_NEXTHIGHMONOTONICCOUNT:
+ return efi_runtime_get_nexthighmonocount(arg);
+
+ case EFI_RUNTIME_QUERY_VARIABLEINFO:
+ return efi_runtime_query_variableinfo(arg);
+
+ case EFI_RUNTIME_QUERY_CAPSULECAPABILITIES:
+ return efi_runtime_query_capsulecaps(arg);
+ }
+
+ return -ENOTTY;
+}
+
+static int efi_test_open(struct inode *inode, struct file *file)
+{
+ /*
+ * nothing special to do here
+ * We do accept multiple open files at the same time as we
+ * synchronize on the per call operation.
+ */
+ return 0;
+}
+
+static int efi_test_close(struct inode *inode, struct file *file)
+{
+ return 0;
+}
+
+/*
+ * The various file operations we support.
+ */
+static const struct file_operations efi_test_fops = {
+ .owner = THIS_MODULE,
+ .unlocked_ioctl = efi_test_ioctl,
+ .open = efi_test_open,
+ .release = efi_test_close,
+ .llseek = no_llseek,
+};
+
+static struct miscdevice efi_test_dev = {
+ MISC_DYNAMIC_MINOR,
+ "efi_test",
+ &efi_test_fops
+};
+
+static int __init efi_test_init(void)
+{
+ int ret;
+
+ ret = misc_register(&efi_test_dev);
+ if (ret) {
+ pr_err("efi_test: can't misc_register on minor=%d\n",
+ MISC_DYNAMIC_MINOR);
+ return ret;
+ }
+
+ return 0;
+}
+
+static void __exit efi_test_exit(void)
+{
+ misc_deregister(&efi_test_dev);
+}
+
+module_init(efi_test_init);
+module_exit(efi_test_exit);
diff --git a/drivers/firmware/efi/test/efi_test.h b/drivers/firmware/efi/test/efi_test.h
new file mode 100644
index 0000000..a33a6c6
--- /dev/null
+++ b/drivers/firmware/efi/test/efi_test.h
@@ -0,0 +1,110 @@
+/*
+ * EFI Test driver Header
+ *
+ * Copyright(C) 2012-2016 Canonical Ltd.
+ *
+ */
+
+#ifndef _DRIVERS_FIRMWARE_EFI_TEST_H_
+#define _DRIVERS_FIRMWARE_EFI_TEST_H_
+
+#include <linux/efi.h>
+
+struct efi_getvariable {
+ efi_char16_t *variable_name;
+ efi_guid_t *vendor_guid;
+ u32 *attributes;
+ unsigned long *data_size;
+ void *data;
+ efi_status_t *status;
+} __packed;
+
+struct efi_setvariable {
+ efi_char16_t *variable_name;
+ efi_guid_t *vendor_guid;
+ u32 attributes;
+ unsigned long data_size;
+ void *data;
+ efi_status_t *status;
+} __packed;
+
+struct efi_getnextvariablename {
+ unsigned long *variable_name_size;
+ efi_char16_t *variable_name;
+ efi_guid_t *vendor_guid;
+ efi_status_t *status;
+} __packed;
+
+struct efi_queryvariableinfo {
+ u32 attributes;
+ u64 *maximum_variable_storage_size;
+ u64 *remaining_variable_storage_size;
+ u64 *maximum_variable_size;
+ efi_status_t *status;
+} __packed;
+
+struct efi_gettime {
+ efi_time_t *time;
+ efi_time_cap_t *capabilities;
+ efi_status_t *status;
+} __packed;
+
+struct efi_settime {
+ efi_time_t *time;
+ efi_status_t *status;
+} __packed;
+
+struct efi_getwakeuptime {
+ efi_bool_t *enabled;
+ efi_bool_t *pending;
+ efi_time_t *time;
+ efi_status_t *status;
+} __packed;
+
+struct efi_setwakeuptime {
+ efi_bool_t enabled;
+ efi_time_t *time;
+ efi_status_t *status;
+} __packed;
+
+struct efi_getnexthighmonotoniccount {
+ u32 *high_count;
+ efi_status_t *status;
+} __packed;
+
+struct efi_querycapsulecapabilities {
+ efi_capsule_header_t **capsule_header_array;
+ unsigned long capsule_count;
+ u64 *maximum_capsule_size;
+ int *reset_type;
+ efi_status_t *status;
+} __packed;
+
+#define EFI_RUNTIME_GET_VARIABLE \
+ _IOWR('p', 0x01, struct efi_getvariable)
+#define EFI_RUNTIME_SET_VARIABLE \
+ _IOW('p', 0x02, struct efi_setvariable)
+
+#define EFI_RUNTIME_GET_TIME \
+ _IOR('p', 0x03, struct efi_gettime)
+#define EFI_RUNTIME_SET_TIME \
+ _IOW('p', 0x04, struct efi_settime)
+
+#define EFI_RUNTIME_GET_WAKETIME \
+ _IOR('p', 0x05, struct efi_getwakeuptime)
+#define EFI_RUNTIME_SET_WAKETIME \
+ _IOW('p', 0x06, struct efi_setwakeuptime)
+
+#define EFI_RUNTIME_GET_NEXTVARIABLENAME \
+ _IOWR('p', 0x07, struct efi_getnextvariablename)
+
+#define EFI_RUNTIME_QUERY_VARIABLEINFO \
+ _IOR('p', 0x08, struct efi_queryvariableinfo)
+
+#define EFI_RUNTIME_GET_NEXTHIGHMONOTONICCOUNT \
+ _IOR('p', 0x09, struct efi_getnexthighmonotoniccount)
+
+#define EFI_RUNTIME_QUERY_CAPSULECAPABILITIES \
+ _IOR('p', 0x0A, struct efi_querycapsulecapabilities)
+
+#endif /* _DRIVERS_FIRMWARE_EFI_TEST_H_ */
diff --git a/drivers/firmware/efi/vars.c b/drivers/firmware/efi/vars.c
index d3b7513..9336ffd 100644
--- a/drivers/firmware/efi/vars.c
+++ b/drivers/firmware/efi/vars.c
@@ -37,6 +37,14 @@
/* Private pointer to registered efivars */
static struct efivars *__efivars;
+/*
+ * efivars_lock protects three things:
+ * 1) efivarfs_list and efivars_sysfs_list
+ * 2) ->ops calls
+ * 3) (un)registration of __efivars
+ */
+static DEFINE_SEMAPHORE(efivars_lock);
+
static bool efivar_wq_enabled = true;
DECLARE_WORK(efivar_work, NULL);
EXPORT_SYMBOL_GPL(efivar_work);
@@ -434,7 +442,10 @@
return -ENOMEM;
}
- spin_lock_irq(&__efivars->lock);
+ if (down_interruptible(&efivars_lock)) {
+ err = -EINTR;
+ goto free;
+ }
/*
* Per EFI spec, the maximum storage allocated for both
@@ -450,7 +461,7 @@
switch (status) {
case EFI_SUCCESS:
if (duplicates)
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
variable_name_size = var_name_strnsize(variable_name,
variable_name_size);
@@ -476,8 +487,12 @@
status = EFI_NOT_FOUND;
}
- if (duplicates)
- spin_lock_irq(&__efivars->lock);
+ if (duplicates) {
+ if (down_interruptible(&efivars_lock)) {
+ err = -EINTR;
+ goto free;
+ }
+ }
break;
case EFI_NOT_FOUND:
@@ -491,8 +506,8 @@
} while (status != EFI_NOT_FOUND);
- spin_unlock_irq(&__efivars->lock);
-
+ up(&efivars_lock);
+free:
kfree(variable_name);
return err;
@@ -503,24 +518,34 @@
* efivar_entry_add - add entry to variable list
* @entry: entry to add to list
* @head: list head
+ *
+ * Returns 0 on success, or a kernel error code on failure.
*/
-void efivar_entry_add(struct efivar_entry *entry, struct list_head *head)
+int efivar_entry_add(struct efivar_entry *entry, struct list_head *head)
{
- spin_lock_irq(&__efivars->lock);
+ if (down_interruptible(&efivars_lock))
+ return -EINTR;
list_add(&entry->list, head);
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
+
+ return 0;
}
EXPORT_SYMBOL_GPL(efivar_entry_add);
/**
* efivar_entry_remove - remove entry from variable list
* @entry: entry to remove from list
+ *
+ * Returns 0 on success, or a kernel error code on failure.
*/
-void efivar_entry_remove(struct efivar_entry *entry)
+int efivar_entry_remove(struct efivar_entry *entry)
{
- spin_lock_irq(&__efivars->lock);
+ if (down_interruptible(&efivars_lock))
+ return -EINTR;
list_del(&entry->list);
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
+
+ return 0;
}
EXPORT_SYMBOL_GPL(efivar_entry_remove);
@@ -537,10 +562,8 @@
*/
static void efivar_entry_list_del_unlock(struct efivar_entry *entry)
{
- lockdep_assert_held(&__efivars->lock);
-
list_del(&entry->list);
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
}
/**
@@ -563,8 +586,6 @@
const struct efivar_operations *ops = __efivars->ops;
efi_status_t status;
- lockdep_assert_held(&__efivars->lock);
-
status = ops->set_variable(entry->var.VariableName,
&entry->var.VendorGuid,
0, 0, NULL);
@@ -581,20 +602,22 @@
* variable list. It is the caller's responsibility to free @entry
* once we return.
*
- * Returns 0 on success, or a converted EFI status code if
- * set_variable() fails.
+ * Returns 0 on success, -EINTR if we can't grab the semaphore,
+ * converted EFI status code if set_variable() fails.
*/
int efivar_entry_delete(struct efivar_entry *entry)
{
const struct efivar_operations *ops = __efivars->ops;
efi_status_t status;
- spin_lock_irq(&__efivars->lock);
+ if (down_interruptible(&efivars_lock))
+ return -EINTR;
+
status = ops->set_variable(entry->var.VariableName,
&entry->var.VendorGuid,
0, 0, NULL);
if (!(status == EFI_SUCCESS || status == EFI_NOT_FOUND)) {
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
return efi_status_to_err(status);
}
@@ -620,9 +643,9 @@
* If @head is not NULL a lookup is performed to determine whether
* the entry is already on the list.
*
- * Returns 0 on success, -EEXIST if a lookup is performed and the entry
- * already exists on the list, or a converted EFI status code if
- * set_variable() fails.
+ * Returns 0 on success, -EINTR if we can't grab the semaphore,
+ * -EEXIST if a lookup is performed and the entry already exists on
+ * the list, or a converted EFI status code if set_variable() fails.
*/
int efivar_entry_set(struct efivar_entry *entry, u32 attributes,
unsigned long size, void *data, struct list_head *head)
@@ -632,10 +655,10 @@
efi_char16_t *name = entry->var.VariableName;
efi_guid_t vendor = entry->var.VendorGuid;
- spin_lock_irq(&__efivars->lock);
-
+ if (down_interruptible(&efivars_lock))
+ return -EINTR;
if (head && efivar_entry_find(name, vendor, head, false)) {
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
return -EEXIST;
}
@@ -644,7 +667,7 @@
status = ops->set_variable(name, &vendor,
attributes, size, data);
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
return efi_status_to_err(status);
@@ -658,30 +681,29 @@
* from crash/panic handlers.
*
* Crucially, this function will not block if it cannot acquire
- * __efivars->lock. Instead, it returns -EBUSY.
+ * efivars_lock. Instead, it returns -EBUSY.
*/
static int
efivar_entry_set_nonblocking(efi_char16_t *name, efi_guid_t vendor,
u32 attributes, unsigned long size, void *data)
{
const struct efivar_operations *ops = __efivars->ops;
- unsigned long flags;
efi_status_t status;
- if (!spin_trylock_irqsave(&__efivars->lock, flags))
+ if (down_trylock(&efivars_lock))
return -EBUSY;
status = check_var_size_nonblocking(attributes,
size + ucs2_strsize(name, 1024));
if (status != EFI_SUCCESS) {
- spin_unlock_irqrestore(&__efivars->lock, flags);
+ up(&efivars_lock);
return -ENOSPC;
}
status = ops->set_variable_nonblocking(name, &vendor, attributes,
size, data);
- spin_unlock_irqrestore(&__efivars->lock, flags);
+ up(&efivars_lock);
return efi_status_to_err(status);
}
@@ -706,7 +728,6 @@
bool block, unsigned long size, void *data)
{
const struct efivar_operations *ops = __efivars->ops;
- unsigned long flags;
efi_status_t status;
if (!ops->query_variable_store)
@@ -727,21 +748,22 @@
size, data);
if (!block) {
- if (!spin_trylock_irqsave(&__efivars->lock, flags))
+ if (down_trylock(&efivars_lock))
return -EBUSY;
} else {
- spin_lock_irqsave(&__efivars->lock, flags);
+ if (down_interruptible(&efivars_lock))
+ return -EINTR;
}
status = check_var_size(attributes, size + ucs2_strsize(name, 1024));
if (status != EFI_SUCCESS) {
- spin_unlock_irqrestore(&__efivars->lock, flags);
+ up(&efivars_lock);
return -ENOSPC;
}
status = ops->set_variable(name, &vendor, attributes, size, data);
- spin_unlock_irqrestore(&__efivars->lock, flags);
+ up(&efivars_lock);
return efi_status_to_err(status);
}
@@ -771,8 +793,6 @@
int strsize1, strsize2;
bool found = false;
- lockdep_assert_held(&__efivars->lock);
-
list_for_each_entry_safe(entry, n, head, list) {
strsize1 = ucs2_strsize(name, 1024);
strsize2 = ucs2_strsize(entry->var.VariableName, 1024);
@@ -814,10 +834,11 @@
*size = 0;
- spin_lock_irq(&__efivars->lock);
+ if (down_interruptible(&efivars_lock))
+ return -EINTR;
status = ops->get_variable(entry->var.VariableName,
&entry->var.VendorGuid, NULL, size, NULL);
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
if (status != EFI_BUFFER_TOO_SMALL)
return efi_status_to_err(status);
@@ -843,8 +864,6 @@
const struct efivar_operations *ops = __efivars->ops;
efi_status_t status;
- lockdep_assert_held(&__efivars->lock);
-
status = ops->get_variable(entry->var.VariableName,
&entry->var.VendorGuid,
attributes, size, data);
@@ -866,11 +885,12 @@
const struct efivar_operations *ops = __efivars->ops;
efi_status_t status;
- spin_lock_irq(&__efivars->lock);
+ if (down_interruptible(&efivars_lock))
+ return -EINTR;
status = ops->get_variable(entry->var.VariableName,
&entry->var.VendorGuid,
attributes, size, data);
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
return efi_status_to_err(status);
}
@@ -917,7 +937,8 @@
* set_variable call, and removal of the variable from the efivars
* list (in the case of an authenticated delete).
*/
- spin_lock_irq(&__efivars->lock);
+ if (down_interruptible(&efivars_lock))
+ return -EINTR;
/*
* Ensure that the available space hasn't shrunk below the safe level
@@ -957,7 +978,7 @@
if (status == EFI_NOT_FOUND)
efivar_entry_list_del_unlock(entry);
else
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
if (status && status != EFI_BUFFER_TOO_SMALL)
return efi_status_to_err(status);
@@ -965,7 +986,7 @@
return 0;
out:
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
return err;
}
@@ -978,9 +999,9 @@
* efivar_entry_iter_end() is called. This function is usually used in
* conjunction with __efivar_entry_iter() or efivar_entry_iter().
*/
-void efivar_entry_iter_begin(void)
+int efivar_entry_iter_begin(void)
{
- spin_lock_irq(&__efivars->lock);
+ return down_interruptible(&efivars_lock);
}
EXPORT_SYMBOL_GPL(efivar_entry_iter_begin);
@@ -991,7 +1012,7 @@
*/
void efivar_entry_iter_end(void)
{
- spin_unlock_irq(&__efivars->lock);
+ up(&efivars_lock);
}
EXPORT_SYMBOL_GPL(efivar_entry_iter_end);
@@ -1067,7 +1088,9 @@
{
int err = 0;
- efivar_entry_iter_begin();
+ err = efivar_entry_iter_begin();
+ if (err)
+ return err;
err = __efivar_entry_iter(func, head, data, NULL);
efivar_entry_iter_end();
@@ -1112,12 +1135,18 @@
const struct efivar_operations *ops,
struct kobject *kobject)
{
- spin_lock_init(&efivars->lock);
+ if (down_interruptible(&efivars_lock))
+ return -EINTR;
+
efivars->ops = ops;
efivars->kobject = kobject;
__efivars = efivars;
+ pr_info("Registered efivars operations\n");
+
+ up(&efivars_lock);
+
return 0;
}
EXPORT_SYMBOL_GPL(efivars_register);
@@ -1133,6 +1162,9 @@
{
int rv;
+ if (down_interruptible(&efivars_lock))
+ return -EINTR;
+
if (!__efivars) {
printk(KERN_ERR "efivars not registered\n");
rv = -EINVAL;
@@ -1144,10 +1176,12 @@
goto out;
}
+ pr_info("Unregistered efivars operations\n");
__efivars = NULL;
rv = 0;
out:
+ up(&efivars_lock);
return rv;
}
EXPORT_SYMBOL_GPL(efivars_unregister);
diff --git a/drivers/firmware/google/gsmi.c b/drivers/firmware/google/gsmi.c
index f1ab05e..c463871 100644
--- a/drivers/firmware/google/gsmi.c
+++ b/drivers/firmware/google/gsmi.c
@@ -910,8 +910,7 @@
gsmi_buf_free(gsmi_dev.param_buf);
gsmi_buf_free(gsmi_dev.data_buf);
gsmi_buf_free(gsmi_dev.name_buf);
- if (gsmi_dev.dma_pool)
- dma_pool_destroy(gsmi_dev.dma_pool);
+ dma_pool_destroy(gsmi_dev.dma_pool);
platform_device_unregister(gsmi_dev.pdev);
pr_info("gsmi: failed to load: %d\n", ret);
return ret;
diff --git a/drivers/gpu/drm/amd/amdgpu/amdgpu_device.c b/drivers/gpu/drm/amd/amdgpu/amdgpu_device.c
index df7ab245..39c01b9 100644
--- a/drivers/gpu/drm/amd/amdgpu/amdgpu_device.c
+++ b/drivers/gpu/drm/amd/amdgpu/amdgpu_device.c
@@ -1708,11 +1708,11 @@
DRM_INFO("amdgpu: finishing device.\n");
adev->shutdown = true;
+ drm_crtc_force_disable_all(adev->ddev);
/* evict vram memory */
amdgpu_bo_evict_vram(adev);
amdgpu_ib_pool_fini(adev);
amdgpu_fence_driver_fini(adev);
- drm_crtc_force_disable_all(adev->ddev);
amdgpu_fbdev_fini(adev);
r = amdgpu_fini(adev);
kfree(adev->ip_block_status);
diff --git a/drivers/gpu/drm/drm_ioc32.c b/drivers/gpu/drm/drm_ioc32.c
index 57676f8..a628975 100644
--- a/drivers/gpu/drm/drm_ioc32.c
+++ b/drivers/gpu/drm/drm_ioc32.c
@@ -1015,6 +1015,7 @@
return 0;
}
+#if defined(CONFIG_X86) || defined(CONFIG_IA64)
typedef struct drm_mode_fb_cmd232 {
u32 fb_id;
u32 width;
@@ -1071,6 +1072,7 @@
return 0;
}
+#endif
static drm_ioctl_compat_t *drm_compat_ioctls[] = {
[DRM_IOCTL_NR(DRM_IOCTL_VERSION32)] = compat_drm_version,
@@ -1104,7 +1106,9 @@
[DRM_IOCTL_NR(DRM_IOCTL_UPDATE_DRAW32)] = compat_drm_update_draw,
#endif
[DRM_IOCTL_NR(DRM_IOCTL_WAIT_VBLANK32)] = compat_drm_wait_vblank,
+#if defined(CONFIG_X86) || defined(CONFIG_IA64)
[DRM_IOCTL_NR(DRM_IOCTL_MODE_ADDFB232)] = compat_drm_mode_addfb2,
+#endif
};
/**
diff --git a/drivers/gpu/drm/exynos/exynos_drm_fb.c b/drivers/gpu/drm/exynos/exynos_drm_fb.c
index e016640..40ce841 100644
--- a/drivers/gpu/drm/exynos/exynos_drm_fb.c
+++ b/drivers/gpu/drm/exynos/exynos_drm_fb.c
@@ -55,11 +55,11 @@
flags = exynos_gem->flags;
/*
- * without iommu support, not support physically non-continuous memory
- * for framebuffer.
+ * Physically non-contiguous memory type for framebuffer is not
+ * supported without IOMMU.
*/
if (IS_NONCONTIG_BUFFER(flags)) {
- DRM_ERROR("cannot use this gem memory type for fb.\n");
+ DRM_ERROR("Non-contiguous GEM memory is not supported.\n");
return -EINVAL;
}
diff --git a/drivers/gpu/drm/exynos/exynos_drm_fimc.c b/drivers/gpu/drm/exynos/exynos_drm_fimc.c
index 0525c56..147ef0d 100644
--- a/drivers/gpu/drm/exynos/exynos_drm_fimc.c
+++ b/drivers/gpu/drm/exynos/exynos_drm_fimc.c
@@ -1753,32 +1753,6 @@
return 0;
}
-#ifdef CONFIG_PM_SLEEP
-static int fimc_suspend(struct device *dev)
-{
- struct fimc_context *ctx = get_fimc_context(dev);
-
- DRM_DEBUG_KMS("id[%d]\n", ctx->id);
-
- if (pm_runtime_suspended(dev))
- return 0;
-
- return fimc_clk_ctrl(ctx, false);
-}
-
-static int fimc_resume(struct device *dev)
-{
- struct fimc_context *ctx = get_fimc_context(dev);
-
- DRM_DEBUG_KMS("id[%d]\n", ctx->id);
-
- if (!pm_runtime_suspended(dev))
- return fimc_clk_ctrl(ctx, true);
-
- return 0;
-}
-#endif
-
static int fimc_runtime_suspend(struct device *dev)
{
struct fimc_context *ctx = get_fimc_context(dev);
@@ -1799,7 +1773,8 @@
#endif
static const struct dev_pm_ops fimc_pm_ops = {
- SET_SYSTEM_SLEEP_PM_OPS(fimc_suspend, fimc_resume)
+ SET_SYSTEM_SLEEP_PM_OPS(pm_runtime_force_suspend,
+ pm_runtime_force_resume)
SET_RUNTIME_PM_OPS(fimc_runtime_suspend, fimc_runtime_resume, NULL)
};
diff --git a/drivers/gpu/drm/exynos/exynos_drm_g2d.c b/drivers/gpu/drm/exynos/exynos_drm_g2d.c
index 4bf00f5..6eca8bb 100644
--- a/drivers/gpu/drm/exynos/exynos_drm_g2d.c
+++ b/drivers/gpu/drm/exynos/exynos_drm_g2d.c
@@ -1475,8 +1475,8 @@
return 0;
}
-#ifdef CONFIG_PM_SLEEP
-static int g2d_suspend(struct device *dev)
+#ifdef CONFIG_PM
+static int g2d_runtime_suspend(struct device *dev)
{
struct g2d_data *g2d = dev_get_drvdata(dev);
@@ -1490,25 +1490,6 @@
flush_work(&g2d->runqueue_work);
- return 0;
-}
-
-static int g2d_resume(struct device *dev)
-{
- struct g2d_data *g2d = dev_get_drvdata(dev);
-
- g2d->suspended = false;
- g2d_exec_runqueue(g2d);
-
- return 0;
-}
-#endif
-
-#ifdef CONFIG_PM
-static int g2d_runtime_suspend(struct device *dev)
-{
- struct g2d_data *g2d = dev_get_drvdata(dev);
-
clk_disable_unprepare(g2d->gate_clk);
return 0;
@@ -1523,12 +1504,16 @@
if (ret < 0)
dev_warn(dev, "failed to enable clock.\n");
+ g2d->suspended = false;
+ g2d_exec_runqueue(g2d);
+
return ret;
}
#endif
static const struct dev_pm_ops g2d_pm_ops = {
- SET_SYSTEM_SLEEP_PM_OPS(g2d_suspend, g2d_resume)
+ SET_SYSTEM_SLEEP_PM_OPS(pm_runtime_force_suspend,
+ pm_runtime_force_resume)
SET_RUNTIME_PM_OPS(g2d_runtime_suspend, g2d_runtime_resume, NULL)
};
diff --git a/drivers/gpu/drm/exynos/exynos_drm_gsc.c b/drivers/gpu/drm/exynos/exynos_drm_gsc.c
index 5d20da8..52a9d26 100644
--- a/drivers/gpu/drm/exynos/exynos_drm_gsc.c
+++ b/drivers/gpu/drm/exynos/exynos_drm_gsc.c
@@ -1760,34 +1760,7 @@
return 0;
}
-#ifdef CONFIG_PM_SLEEP
-static int gsc_suspend(struct device *dev)
-{
- struct gsc_context *ctx = get_gsc_context(dev);
-
- DRM_DEBUG_KMS("id[%d]\n", ctx->id);
-
- if (pm_runtime_suspended(dev))
- return 0;
-
- return gsc_clk_ctrl(ctx, false);
-}
-
-static int gsc_resume(struct device *dev)
-{
- struct gsc_context *ctx = get_gsc_context(dev);
-
- DRM_DEBUG_KMS("id[%d]\n", ctx->id);
-
- if (!pm_runtime_suspended(dev))
- return gsc_clk_ctrl(ctx, true);
-
- return 0;
-}
-#endif
-
-#ifdef CONFIG_PM
-static int gsc_runtime_suspend(struct device *dev)
+static int __maybe_unused gsc_runtime_suspend(struct device *dev)
{
struct gsc_context *ctx = get_gsc_context(dev);
@@ -1796,7 +1769,7 @@
return gsc_clk_ctrl(ctx, false);
}
-static int gsc_runtime_resume(struct device *dev)
+static int __maybe_unused gsc_runtime_resume(struct device *dev)
{
struct gsc_context *ctx = get_gsc_context(dev);
@@ -1804,10 +1777,10 @@
return gsc_clk_ctrl(ctx, true);
}
-#endif
static const struct dev_pm_ops gsc_pm_ops = {
- SET_SYSTEM_SLEEP_PM_OPS(gsc_suspend, gsc_resume)
+ SET_SYSTEM_SLEEP_PM_OPS(pm_runtime_force_suspend,
+ pm_runtime_force_resume)
SET_RUNTIME_PM_OPS(gsc_runtime_suspend, gsc_runtime_resume, NULL)
};
diff --git a/drivers/gpu/drm/exynos/exynos_drm_rotator.c b/drivers/gpu/drm/exynos/exynos_drm_rotator.c
index 404367a..6591e40 100644
--- a/drivers/gpu/drm/exynos/exynos_drm_rotator.c
+++ b/drivers/gpu/drm/exynos/exynos_drm_rotator.c
@@ -794,29 +794,6 @@
return 0;
}
-
-#ifdef CONFIG_PM_SLEEP
-static int rotator_suspend(struct device *dev)
-{
- struct rot_context *rot = dev_get_drvdata(dev);
-
- if (pm_runtime_suspended(dev))
- return 0;
-
- return rotator_clk_crtl(rot, false);
-}
-
-static int rotator_resume(struct device *dev)
-{
- struct rot_context *rot = dev_get_drvdata(dev);
-
- if (!pm_runtime_suspended(dev))
- return rotator_clk_crtl(rot, true);
-
- return 0;
-}
-#endif
-
static int rotator_runtime_suspend(struct device *dev)
{
struct rot_context *rot = dev_get_drvdata(dev);
@@ -833,7 +810,8 @@
#endif
static const struct dev_pm_ops rotator_pm_ops = {
- SET_SYSTEM_SLEEP_PM_OPS(rotator_suspend, rotator_resume)
+ SET_SYSTEM_SLEEP_PM_OPS(pm_runtime_force_suspend,
+ pm_runtime_force_resume)
SET_RUNTIME_PM_OPS(rotator_runtime_suspend, rotator_runtime_resume,
NULL)
};
diff --git a/drivers/gpu/drm/nouveau/include/nvkm/core/device.h b/drivers/gpu/drm/nouveau/include/nvkm/core/device.h
index 7ea8aa7..6bc712f 100644
--- a/drivers/gpu/drm/nouveau/include/nvkm/core/device.h
+++ b/drivers/gpu/drm/nouveau/include/nvkm/core/device.h
@@ -175,6 +175,7 @@
void (*fini)(struct nvkm_device *, bool suspend);
resource_size_t (*resource_addr)(struct nvkm_device *, unsigned bar);
resource_size_t (*resource_size)(struct nvkm_device *, unsigned bar);
+ bool cpu_coherent;
};
struct nvkm_device_quirk {
diff --git a/drivers/gpu/drm/nouveau/nouveau_bo.c b/drivers/gpu/drm/nouveau/nouveau_bo.c
index 6190035..864323b 100644
--- a/drivers/gpu/drm/nouveau/nouveau_bo.c
+++ b/drivers/gpu/drm/nouveau/nouveau_bo.c
@@ -209,7 +209,8 @@
nvbo->tile_flags = tile_flags;
nvbo->bo.bdev = &drm->ttm.bdev;
- nvbo->force_coherent = flags & TTM_PL_FLAG_UNCACHED;
+ if (!nvxx_device(&drm->device)->func->cpu_coherent)
+ nvbo->force_coherent = flags & TTM_PL_FLAG_UNCACHED;
nvbo->page_shift = 12;
if (drm->client.vm) {
diff --git a/drivers/gpu/drm/nouveau/nvkm/engine/device/pci.c b/drivers/gpu/drm/nouveau/nvkm/engine/device/pci.c
index b1b6932..62ad030 100644
--- a/drivers/gpu/drm/nouveau/nvkm/engine/device/pci.c
+++ b/drivers/gpu/drm/nouveau/nvkm/engine/device/pci.c
@@ -1614,6 +1614,7 @@
.fini = nvkm_device_pci_fini,
.resource_addr = nvkm_device_pci_resource_addr,
.resource_size = nvkm_device_pci_resource_size,
+ .cpu_coherent = !IS_ENABLED(CONFIG_ARM),
};
int
diff --git a/drivers/gpu/drm/nouveau/nvkm/engine/device/tegra.c b/drivers/gpu/drm/nouveau/nvkm/engine/device/tegra.c
index 939682f..9b638bd 100644
--- a/drivers/gpu/drm/nouveau/nvkm/engine/device/tegra.c
+++ b/drivers/gpu/drm/nouveau/nvkm/engine/device/tegra.c
@@ -245,6 +245,7 @@
.fini = nvkm_device_tegra_fini,
.resource_addr = nvkm_device_tegra_resource_addr,
.resource_size = nvkm_device_tegra_resource_size,
+ .cpu_coherent = false,
};
int
diff --git a/drivers/gpu/drm/nouveau/nvkm/engine/fifo/dmanv04.c b/drivers/gpu/drm/nouveau/nvkm/engine/fifo/dmanv04.c
index edec30f..0a7b6ed 100644
--- a/drivers/gpu/drm/nouveau/nvkm/engine/fifo/dmanv04.c
+++ b/drivers/gpu/drm/nouveau/nvkm/engine/fifo/dmanv04.c
@@ -37,7 +37,10 @@
{
struct nv04_fifo_chan *chan = nv04_fifo_chan(base);
struct nvkm_instmem *imem = chan->fifo->base.engine.subdev.device->imem;
+
+ mutex_lock(&chan->fifo->base.engine.subdev.mutex);
nvkm_ramht_remove(imem->ramht, cookie);
+ mutex_unlock(&chan->fifo->base.engine.subdev.mutex);
}
static int
diff --git a/drivers/gpu/drm/radeon/si_dpm.c b/drivers/gpu/drm/radeon/si_dpm.c
index e6abc09..1f78ec2 100644
--- a/drivers/gpu/drm/radeon/si_dpm.c
+++ b/drivers/gpu/drm/radeon/si_dpm.c
@@ -3015,6 +3015,12 @@
if (rdev->pdev->device == 0x6811 &&
rdev->pdev->revision == 0x81)
max_mclk = 120000;
+ /* limit sclk/mclk on Jet parts for stability */
+ if (rdev->pdev->device == 0x6665 &&
+ rdev->pdev->revision == 0xc3) {
+ max_sclk = 75000;
+ max_mclk = 80000;
+ }
if (rps->vce_active) {
rps->evclk = rdev->pm.dpm.vce_states[rdev->pm.dpm.vce_level].evclk;
diff --git a/drivers/gpu/drm/udl/udl_fb.c b/drivers/gpu/drm/udl/udl_fb.c
index 9688bfa..611b6b9 100644
--- a/drivers/gpu/drm/udl/udl_fb.c
+++ b/drivers/gpu/drm/udl/udl_fb.c
@@ -122,7 +122,7 @@
return 0;
cmd = urb->transfer_buffer;
- for (i = y; i < height ; i++) {
+ for (i = y; i < y + height ; i++) {
const int line_offset = fb->base.pitches[0] * i;
const int byte_offset = line_offset + (x * bpp);
const int dev_byte_offset = (fb->base.width * bpp * i) + (x * bpp);
diff --git a/drivers/hwmon/dell-smm-hwmon.c b/drivers/hwmon/dell-smm-hwmon.c
index acf9c03..34704b0 100644
--- a/drivers/hwmon/dell-smm-hwmon.c
+++ b/drivers/hwmon/dell-smm-hwmon.c
@@ -21,6 +21,7 @@
#define pr_fmt(fmt) KBUILD_MODNAME ": " fmt
+#include <linux/cpu.h>
#include <linux/delay.h>
#include <linux/module.h>
#include <linux/types.h>
@@ -36,6 +37,7 @@
#include <linux/io.h>
#include <linux/sched.h>
#include <linux/ctype.h>
+#include <linux/smp.h>
#include <linux/i8k.h>
@@ -134,11 +136,11 @@
/*
* Call the System Management Mode BIOS. Code provided by Jonathan Buzzard.
*/
-static int i8k_smm(struct smm_regs *regs)
+static int i8k_smm_func(void *par)
{
int rc;
+ struct smm_regs *regs = par;
int eax = regs->eax;
- cpumask_var_t old_mask;
#ifdef DEBUG
int ebx = regs->ebx;
@@ -149,16 +151,8 @@
#endif
/* SMM requires CPU 0 */
- if (!alloc_cpumask_var(&old_mask, GFP_KERNEL))
- return -ENOMEM;
- cpumask_copy(old_mask, ¤t->cpus_allowed);
- rc = set_cpus_allowed_ptr(current, cpumask_of(0));
- if (rc)
- goto out;
- if (smp_processor_id() != 0) {
- rc = -EBUSY;
- goto out;
- }
+ if (smp_processor_id() != 0)
+ return -EBUSY;
#if defined(CONFIG_X86_64)
asm volatile("pushq %%rax\n\t"
@@ -216,10 +210,6 @@
if (rc != 0 || (regs->eax & 0xffff) == 0xffff || regs->eax == eax)
rc = -EINVAL;
-out:
- set_cpus_allowed_ptr(current, old_mask);
- free_cpumask_var(old_mask);
-
#ifdef DEBUG
rettime = ktime_get();
delta = ktime_sub(rettime, calltime);
@@ -232,6 +222,20 @@
}
/*
+ * Call the System Management Mode BIOS.
+ */
+static int i8k_smm(struct smm_regs *regs)
+{
+ int ret;
+
+ get_online_cpus();
+ ret = smp_call_on_cpu(0, i8k_smm_func, regs, true);
+ put_online_cpus();
+
+ return ret;
+}
+
+/*
* Read the fan status.
*/
static int i8k_get_fan_status(int fan)
diff --git a/drivers/i2c/busses/i2c-eg20t.c b/drivers/i2c/busses/i2c-eg20t.c
index 137125b..5ce71ce 100644
--- a/drivers/i2c/busses/i2c-eg20t.c
+++ b/drivers/i2c/busses/i2c-eg20t.c
@@ -773,13 +773,6 @@
/* Set the number of I2C channel instance */
adap_info->ch_num = id->driver_data;
- ret = request_irq(pdev->irq, pch_i2c_handler, IRQF_SHARED,
- KBUILD_MODNAME, adap_info);
- if (ret) {
- pch_pci_err(pdev, "request_irq FAILED\n");
- goto err_request_irq;
- }
-
for (i = 0; i < adap_info->ch_num; i++) {
pch_adap = &adap_info->pch_data[i].pch_adapter;
adap_info->pch_i2c_suspended = false;
@@ -797,6 +790,17 @@
pch_adap->dev.of_node = pdev->dev.of_node;
pch_adap->dev.parent = &pdev->dev;
+ }
+
+ ret = request_irq(pdev->irq, pch_i2c_handler, IRQF_SHARED,
+ KBUILD_MODNAME, adap_info);
+ if (ret) {
+ pch_pci_err(pdev, "request_irq FAILED\n");
+ goto err_request_irq;
+ }
+
+ for (i = 0; i < adap_info->ch_num; i++) {
+ pch_adap = &adap_info->pch_data[i].pch_adapter;
pch_i2c_init(&adap_info->pch_data[i]);
diff --git a/drivers/i2c/busses/i2c-i801.c b/drivers/i2c/busses/i2c-i801.c
index 5ef9b73..26298af 100644
--- a/drivers/i2c/busses/i2c-i801.c
+++ b/drivers/i2c/busses/i2c-i801.c
@@ -1486,7 +1486,9 @@
priv->features |= FEATURE_IRQ;
priv->features |= FEATURE_SMBUS_PEC;
priv->features |= FEATURE_BLOCK_BUFFER;
- priv->features |= FEATURE_TCO;
+ /* If we have ACPI based watchdog use that instead */
+ if (!acpi_has_watchdog())
+ priv->features |= FEATURE_TCO;
priv->features |= FEATURE_HOST_NOTIFY;
break;
diff --git a/drivers/i2c/busses/i2c-qup.c b/drivers/i2c/busses/i2c-qup.c
index 501bd15..a8497cf 100644
--- a/drivers/i2c/busses/i2c-qup.c
+++ b/drivers/i2c/busses/i2c-qup.c
@@ -1599,7 +1599,8 @@
#ifdef CONFIG_PM_SLEEP
static int qup_i2c_suspend(struct device *device)
{
- qup_i2c_pm_suspend_runtime(device);
+ if (!pm_runtime_suspended(device))
+ return qup_i2c_pm_suspend_runtime(device);
return 0;
}
diff --git a/drivers/i2c/muxes/i2c-mux-pca954x.c b/drivers/i2c/muxes/i2c-mux-pca954x.c
index 528e755..3278ebf 100644
--- a/drivers/i2c/muxes/i2c-mux-pca954x.c
+++ b/drivers/i2c/muxes/i2c-mux-pca954x.c
@@ -164,7 +164,7 @@
/* Only select the channel if its different from the last channel */
if (data->last_chan != regval) {
ret = pca954x_reg_write(muxc->parent, client, regval);
- data->last_chan = regval;
+ data->last_chan = ret ? 0 : regval;
}
return ret;
diff --git a/drivers/input/joydev.c b/drivers/input/joydev.c
index 5d11fea..f3135ae 100644
--- a/drivers/input/joydev.c
+++ b/drivers/input/joydev.c
@@ -950,6 +950,12 @@
.flags = INPUT_DEVICE_ID_MATCH_EVBIT |
INPUT_DEVICE_ID_MATCH_ABSBIT,
.evbit = { BIT_MASK(EV_ABS) },
+ .absbit = { BIT_MASK(ABS_Z) },
+ },
+ {
+ .flags = INPUT_DEVICE_ID_MATCH_EVBIT |
+ INPUT_DEVICE_ID_MATCH_ABSBIT,
+ .evbit = { BIT_MASK(EV_ABS) },
.absbit = { BIT_MASK(ABS_WHEEL) },
},
{
diff --git a/drivers/input/touchscreen/silead.c b/drivers/input/touchscreen/silead.c
index b2744a6..f502c84 100644
--- a/drivers/input/touchscreen/silead.c
+++ b/drivers/input/touchscreen/silead.c
@@ -390,9 +390,10 @@
data->max_fingers = 5; /* Most devices handle up-to 5 fingers */
}
- error = device_property_read_string(dev, "touchscreen-fw-name", &str);
+ error = device_property_read_string(dev, "firmware-name", &str);
if (!error)
- snprintf(data->fw_name, sizeof(data->fw_name), "%s", str);
+ snprintf(data->fw_name, sizeof(data->fw_name),
+ "silead/%s", str);
else
dev_dbg(dev, "Firmware file name read error. Using default.");
}
@@ -410,14 +411,14 @@
if (!acpi_id)
return -ENODEV;
- snprintf(data->fw_name, sizeof(data->fw_name), "%s.fw",
- acpi_id->id);
+ snprintf(data->fw_name, sizeof(data->fw_name),
+ "silead/%s.fw", acpi_id->id);
for (i = 0; i < strlen(data->fw_name); i++)
data->fw_name[i] = tolower(data->fw_name[i]);
} else {
- snprintf(data->fw_name, sizeof(data->fw_name), "%s.fw",
- id->name);
+ snprintf(data->fw_name, sizeof(data->fw_name),
+ "silead/%s.fw", id->name);
}
return 0;
@@ -426,7 +427,8 @@
static int silead_ts_set_default_fw_name(struct silead_ts_data *data,
const struct i2c_device_id *id)
{
- snprintf(data->fw_name, sizeof(data->fw_name), "%s.fw", id->name);
+ snprintf(data->fw_name, sizeof(data->fw_name),
+ "silead/%s.fw", id->name);
return 0;
}
#endif
diff --git a/drivers/irqchip/irq-gic-v3.c b/drivers/irqchip/irq-gic-v3.c
index ede5672..da6c0ba 100644
--- a/drivers/irqchip/irq-gic-v3.c
+++ b/drivers/irqchip/irq-gic-v3.c
@@ -548,7 +548,7 @@
static u16 gic_compute_target_list(int *base_cpu, const struct cpumask *mask,
unsigned long cluster_id)
{
- int cpu = *base_cpu;
+ int next_cpu, cpu = *base_cpu;
unsigned long mpidr = cpu_logical_map(cpu);
u16 tlist = 0;
@@ -562,9 +562,10 @@
tlist |= 1 << (mpidr & 0xf);
- cpu = cpumask_next(cpu, mask);
- if (cpu >= nr_cpu_ids)
+ next_cpu = cpumask_next(cpu, mask);
+ if (next_cpu >= nr_cpu_ids)
goto out;
+ cpu = next_cpu;
mpidr = cpu_logical_map(cpu);
diff --git a/drivers/irqchip/irq-mips-gic.c b/drivers/irqchip/irq-mips-gic.c
index 83f4983..61856964 100644
--- a/drivers/irqchip/irq-mips-gic.c
+++ b/drivers/irqchip/irq-mips-gic.c
@@ -638,27 +638,6 @@
if (!gic_local_irq_is_routable(intr))
return -EPERM;
- /*
- * HACK: These are all really percpu interrupts, but the rest
- * of the MIPS kernel code does not use the percpu IRQ API for
- * the CP0 timer and performance counter interrupts.
- */
- switch (intr) {
- case GIC_LOCAL_INT_TIMER:
- case GIC_LOCAL_INT_PERFCTR:
- case GIC_LOCAL_INT_FDC:
- irq_set_chip_and_handler(virq,
- &gic_all_vpes_local_irq_controller,
- handle_percpu_irq);
- break;
- default:
- irq_set_chip_and_handler(virq,
- &gic_local_irq_controller,
- handle_percpu_devid_irq);
- irq_set_percpu_devid(virq);
- break;
- }
-
spin_lock_irqsave(&gic_lock, flags);
for (i = 0; i < gic_vpes; i++) {
u32 val = GIC_MAP_TO_PIN_MSK | gic_cpu_pin;
@@ -724,16 +703,42 @@
return 0;
}
-static int gic_irq_domain_map(struct irq_domain *d, unsigned int virq,
- irq_hw_number_t hw)
+static int gic_setup_dev_chip(struct irq_domain *d, unsigned int virq,
+ unsigned int hwirq)
{
- if (GIC_HWIRQ_TO_LOCAL(hw) < GIC_NUM_LOCAL_INTRS)
- return gic_local_irq_domain_map(d, virq, hw);
+ struct irq_chip *chip;
+ int err;
- irq_set_chip_and_handler(virq, &gic_level_irq_controller,
- handle_level_irq);
+ if (hwirq >= GIC_SHARED_HWIRQ_BASE) {
+ err = irq_domain_set_hwirq_and_chip(d, virq, hwirq,
+ &gic_level_irq_controller,
+ NULL);
+ } else {
+ switch (GIC_HWIRQ_TO_LOCAL(hwirq)) {
+ case GIC_LOCAL_INT_TIMER:
+ case GIC_LOCAL_INT_PERFCTR:
+ case GIC_LOCAL_INT_FDC:
+ /*
+ * HACK: These are all really percpu interrupts, but
+ * the rest of the MIPS kernel code does not use the
+ * percpu IRQ API for them.
+ */
+ chip = &gic_all_vpes_local_irq_controller;
+ irq_set_handler(virq, handle_percpu_irq);
+ break;
- return gic_shared_irq_domain_map(d, virq, hw, 0);
+ default:
+ chip = &gic_local_irq_controller;
+ irq_set_handler(virq, handle_percpu_devid_irq);
+ irq_set_percpu_devid(virq);
+ break;
+ }
+
+ err = irq_domain_set_hwirq_and_chip(d, virq, hwirq,
+ chip, NULL);
+ }
+
+ return err;
}
static int gic_irq_domain_alloc(struct irq_domain *d, unsigned int virq,
@@ -744,15 +749,12 @@
int cpu, ret, i;
if (spec->type == GIC_DEVICE) {
- /* verify that it doesn't conflict with an IPI irq */
- if (test_bit(spec->hwirq, ipi_resrv))
+ /* verify that shared irqs don't conflict with an IPI irq */
+ if ((spec->hwirq >= GIC_SHARED_HWIRQ_BASE) &&
+ test_bit(GIC_HWIRQ_TO_SHARED(spec->hwirq), ipi_resrv))
return -EBUSY;
- hwirq = GIC_SHARED_TO_HWIRQ(spec->hwirq);
-
- return irq_domain_set_hwirq_and_chip(d, virq, hwirq,
- &gic_level_irq_controller,
- NULL);
+ return gic_setup_dev_chip(d, virq, spec->hwirq);
} else {
base_hwirq = find_first_bit(ipi_resrv, gic_shared_intrs);
if (base_hwirq == gic_shared_intrs) {
@@ -821,7 +823,6 @@
}
static const struct irq_domain_ops gic_irq_domain_ops = {
- .map = gic_irq_domain_map,
.alloc = gic_irq_domain_alloc,
.free = gic_irq_domain_free,
.match = gic_irq_domain_match,
@@ -852,29 +853,20 @@
struct irq_fwspec *fwspec = arg;
struct gic_irq_spec spec = {
.type = GIC_DEVICE,
- .hwirq = fwspec->param[1],
};
int i, ret;
- bool is_shared = fwspec->param[0] == GIC_SHARED;
- if (is_shared) {
- ret = irq_domain_alloc_irqs_parent(d, virq, nr_irqs, &spec);
- if (ret)
- return ret;
- }
+ if (fwspec->param[0] == GIC_SHARED)
+ spec.hwirq = GIC_SHARED_TO_HWIRQ(fwspec->param[1]);
+ else
+ spec.hwirq = GIC_LOCAL_TO_HWIRQ(fwspec->param[1]);
+
+ ret = irq_domain_alloc_irqs_parent(d, virq, nr_irqs, &spec);
+ if (ret)
+ return ret;
for (i = 0; i < nr_irqs; i++) {
- irq_hw_number_t hwirq;
-
- if (is_shared)
- hwirq = GIC_SHARED_TO_HWIRQ(spec.hwirq + i);
- else
- hwirq = GIC_LOCAL_TO_HWIRQ(spec.hwirq + i);
-
- ret = irq_domain_set_hwirq_and_chip(d, virq + i,
- hwirq,
- &gic_level_irq_controller,
- NULL);
+ ret = gic_setup_dev_chip(d, virq + i, spec.hwirq + i);
if (ret)
goto error;
}
@@ -896,7 +888,10 @@
static void gic_dev_domain_activate(struct irq_domain *domain,
struct irq_data *d)
{
- gic_shared_irq_domain_map(domain, d->irq, d->hwirq, 0);
+ if (GIC_HWIRQ_TO_LOCAL(d->hwirq) < GIC_NUM_LOCAL_INTRS)
+ gic_local_irq_domain_map(domain, d->irq, d->hwirq);
+ else
+ gic_shared_irq_domain_map(domain, d->irq, d->hwirq, 0);
}
static struct irq_domain_ops gic_dev_domain_ops = {
diff --git a/drivers/mailbox/pcc.c b/drivers/mailbox/pcc.c
index 043828d..08c87fa 100644
--- a/drivers/mailbox/pcc.c
+++ b/drivers/mailbox/pcc.c
@@ -59,6 +59,7 @@
#include <linux/delay.h>
#include <linux/io.h>
#include <linux/init.h>
+#include <linux/interrupt.h>
#include <linux/list.h>
#include <linux/platform_device.h>
#include <linux/mailbox_controller.h>
@@ -68,11 +69,16 @@
#include "mailbox.h"
#define MAX_PCC_SUBSPACES 256
+#define MBOX_IRQ_NAME "pcc-mbox"
static struct mbox_chan *pcc_mbox_channels;
/* Array of cached virtual address for doorbell registers */
static void __iomem **pcc_doorbell_vaddr;
+/* Array of cached virtual address for doorbell ack registers */
+static void __iomem **pcc_doorbell_ack_vaddr;
+/* Array of doorbell interrupts */
+static int *pcc_doorbell_irq;
static struct mbox_controller pcc_mbox_ctrl = {};
/**
@@ -91,79 +97,6 @@
return &pcc_mbox_channels[id];
}
-/**
- * pcc_mbox_request_channel - PCC clients call this function to
- * request a pointer to their PCC subspace, from which they
- * can get the details of communicating with the remote.
- * @cl: Pointer to Mailbox client, so we know where to bind the
- * Channel.
- * @subspace_id: The PCC Subspace index as parsed in the PCC client
- * ACPI package. This is used to lookup the array of PCC
- * subspaces as parsed by the PCC Mailbox controller.
- *
- * Return: Pointer to the Mailbox Channel if successful or
- * ERR_PTR.
- */
-struct mbox_chan *pcc_mbox_request_channel(struct mbox_client *cl,
- int subspace_id)
-{
- struct device *dev = pcc_mbox_ctrl.dev;
- struct mbox_chan *chan;
- unsigned long flags;
-
- /*
- * Each PCC Subspace is a Mailbox Channel.
- * The PCC Clients get their PCC Subspace ID
- * from their own tables and pass it here.
- * This returns a pointer to the PCC subspace
- * for the Client to operate on.
- */
- chan = get_pcc_channel(subspace_id);
-
- if (IS_ERR(chan) || chan->cl) {
- dev_err(dev, "Channel not found for idx: %d\n", subspace_id);
- return ERR_PTR(-EBUSY);
- }
-
- spin_lock_irqsave(&chan->lock, flags);
- chan->msg_free = 0;
- chan->msg_count = 0;
- chan->active_req = NULL;
- chan->cl = cl;
- init_completion(&chan->tx_complete);
-
- if (chan->txdone_method == TXDONE_BY_POLL && cl->knows_txdone)
- chan->txdone_method |= TXDONE_BY_ACK;
-
- spin_unlock_irqrestore(&chan->lock, flags);
-
- return chan;
-}
-EXPORT_SYMBOL_GPL(pcc_mbox_request_channel);
-
-/**
- * pcc_mbox_free_channel - Clients call this to free their Channel.
- *
- * @chan: Pointer to the mailbox channel as returned by
- * pcc_mbox_request_channel()
- */
-void pcc_mbox_free_channel(struct mbox_chan *chan)
-{
- unsigned long flags;
-
- if (!chan || !chan->cl)
- return;
-
- spin_lock_irqsave(&chan->lock, flags);
- chan->cl = NULL;
- chan->active_req = NULL;
- if (chan->txdone_method == (TXDONE_BY_POLL | TXDONE_BY_ACK))
- chan->txdone_method = TXDONE_BY_POLL;
-
- spin_unlock_irqrestore(&chan->lock, flags);
-}
-EXPORT_SYMBOL_GPL(pcc_mbox_free_channel);
-
/*
* PCC can be used with perf critical drivers such as CPPC
* So it makes sense to locally cache the virtual address and
@@ -225,6 +158,167 @@
}
/**
+ * pcc_map_interrupt - Map a PCC subspace GSI to a linux IRQ number
+ * @interrupt: GSI number.
+ * @flags: interrupt flags
+ *
+ * Returns: a valid linux IRQ number on success
+ * 0 or -EINVAL on failure
+ */
+static int pcc_map_interrupt(u32 interrupt, u32 flags)
+{
+ int trigger, polarity;
+
+ if (!interrupt)
+ return 0;
+
+ trigger = (flags & ACPI_PCCT_INTERRUPT_MODE) ? ACPI_EDGE_SENSITIVE
+ : ACPI_LEVEL_SENSITIVE;
+
+ polarity = (flags & ACPI_PCCT_INTERRUPT_POLARITY) ? ACPI_ACTIVE_LOW
+ : ACPI_ACTIVE_HIGH;
+
+ return acpi_register_gsi(NULL, interrupt, trigger, polarity);
+}
+
+/**
+ * pcc_mbox_irq - PCC mailbox interrupt handler
+ */
+static irqreturn_t pcc_mbox_irq(int irq, void *p)
+{
+ struct acpi_generic_address *doorbell_ack;
+ struct acpi_pcct_hw_reduced *pcct_ss;
+ struct mbox_chan *chan = p;
+ u64 doorbell_ack_preserve;
+ u64 doorbell_ack_write;
+ u64 doorbell_ack_val;
+ int ret;
+
+ pcct_ss = chan->con_priv;
+
+ mbox_chan_received_data(chan, NULL);
+
+ if (pcct_ss->header.type == ACPI_PCCT_TYPE_HW_REDUCED_SUBSPACE_TYPE2) {
+ struct acpi_pcct_hw_reduced_type2 *pcct2_ss = chan->con_priv;
+ u32 id = chan - pcc_mbox_channels;
+
+ doorbell_ack = &pcct2_ss->doorbell_ack_register;
+ doorbell_ack_preserve = pcct2_ss->ack_preserve_mask;
+ doorbell_ack_write = pcct2_ss->ack_write_mask;
+
+ ret = read_register(pcc_doorbell_ack_vaddr[id],
+ &doorbell_ack_val,
+ doorbell_ack->bit_width);
+ if (ret)
+ return IRQ_NONE;
+
+ ret = write_register(pcc_doorbell_ack_vaddr[id],
+ (doorbell_ack_val & doorbell_ack_preserve)
+ | doorbell_ack_write,
+ doorbell_ack->bit_width);
+ if (ret)
+ return IRQ_NONE;
+ }
+
+ return IRQ_HANDLED;
+}
+
+/**
+ * pcc_mbox_request_channel - PCC clients call this function to
+ * request a pointer to their PCC subspace, from which they
+ * can get the details of communicating with the remote.
+ * @cl: Pointer to Mailbox client, so we know where to bind the
+ * Channel.
+ * @subspace_id: The PCC Subspace index as parsed in the PCC client
+ * ACPI package. This is used to lookup the array of PCC
+ * subspaces as parsed by the PCC Mailbox controller.
+ *
+ * Return: Pointer to the Mailbox Channel if successful or
+ * ERR_PTR.
+ */
+struct mbox_chan *pcc_mbox_request_channel(struct mbox_client *cl,
+ int subspace_id)
+{
+ struct device *dev = pcc_mbox_ctrl.dev;
+ struct mbox_chan *chan;
+ unsigned long flags;
+
+ /*
+ * Each PCC Subspace is a Mailbox Channel.
+ * The PCC Clients get their PCC Subspace ID
+ * from their own tables and pass it here.
+ * This returns a pointer to the PCC subspace
+ * for the Client to operate on.
+ */
+ chan = get_pcc_channel(subspace_id);
+
+ if (IS_ERR(chan) || chan->cl) {
+ dev_err(dev, "Channel not found for idx: %d\n", subspace_id);
+ return ERR_PTR(-EBUSY);
+ }
+
+ spin_lock_irqsave(&chan->lock, flags);
+ chan->msg_free = 0;
+ chan->msg_count = 0;
+ chan->active_req = NULL;
+ chan->cl = cl;
+ init_completion(&chan->tx_complete);
+
+ if (chan->txdone_method == TXDONE_BY_POLL && cl->knows_txdone)
+ chan->txdone_method |= TXDONE_BY_ACK;
+
+ if (pcc_doorbell_irq[subspace_id] > 0) {
+ int rc;
+
+ rc = devm_request_irq(dev, pcc_doorbell_irq[subspace_id],
+ pcc_mbox_irq, 0, MBOX_IRQ_NAME, chan);
+ if (unlikely(rc)) {
+ dev_err(dev, "failed to register PCC interrupt %d\n",
+ pcc_doorbell_irq[subspace_id]);
+ chan = ERR_PTR(rc);
+ }
+ }
+
+ spin_unlock_irqrestore(&chan->lock, flags);
+
+ return chan;
+}
+EXPORT_SYMBOL_GPL(pcc_mbox_request_channel);
+
+/**
+ * pcc_mbox_free_channel - Clients call this to free their Channel.
+ *
+ * @chan: Pointer to the mailbox channel as returned by
+ * pcc_mbox_request_channel()
+ */
+void pcc_mbox_free_channel(struct mbox_chan *chan)
+{
+ u32 id = chan - pcc_mbox_channels;
+ unsigned long flags;
+
+ if (!chan || !chan->cl)
+ return;
+
+ if (id >= pcc_mbox_ctrl.num_chans) {
+ pr_debug("pcc_mbox_free_channel: Invalid mbox_chan passed\n");
+ return;
+ }
+
+ spin_lock_irqsave(&chan->lock, flags);
+ chan->cl = NULL;
+ chan->active_req = NULL;
+ if (chan->txdone_method == (TXDONE_BY_POLL | TXDONE_BY_ACK))
+ chan->txdone_method = TXDONE_BY_POLL;
+
+ if (pcc_doorbell_irq[id] > 0)
+ devm_free_irq(chan->mbox->dev, pcc_doorbell_irq[id], chan);
+
+ spin_unlock_irqrestore(&chan->lock, flags);
+}
+EXPORT_SYMBOL_GPL(pcc_mbox_free_channel);
+
+
+/**
* pcc_send_data - Called from Mailbox Controller code. Used
* here only to ring the channel doorbell. The PCC client
* specific read/write is done in the client driver in
@@ -296,8 +390,10 @@
if (pcc_mbox_ctrl.num_chans <= MAX_PCC_SUBSPACES) {
pcct_ss = (struct acpi_pcct_hw_reduced *) header;
- if (pcct_ss->header.type !=
- ACPI_PCCT_TYPE_HW_REDUCED_SUBSPACE) {
+ if ((pcct_ss->header.type !=
+ ACPI_PCCT_TYPE_HW_REDUCED_SUBSPACE)
+ && (pcct_ss->header.type !=
+ ACPI_PCCT_TYPE_HW_REDUCED_SUBSPACE_TYPE2)) {
pr_err("Incorrect PCC Subspace type detected\n");
return -EINVAL;
}
@@ -307,6 +403,43 @@
}
/**
+ * pcc_parse_subspace_irq - Parse the PCC IRQ and PCC ACK register
+ * There should be one entry per PCC client.
+ * @id: PCC subspace index.
+ * @pcct_ss: Pointer to the ACPI subtable header under the PCCT.
+ *
+ * Return: 0 for Success, else errno.
+ *
+ * This gets called for each entry in the PCC table.
+ */
+static int pcc_parse_subspace_irq(int id,
+ struct acpi_pcct_hw_reduced *pcct_ss)
+{
+ pcc_doorbell_irq[id] = pcc_map_interrupt(pcct_ss->doorbell_interrupt,
+ (u32)pcct_ss->flags);
+ if (pcc_doorbell_irq[id] <= 0) {
+ pr_err("PCC GSI %d not registered\n",
+ pcct_ss->doorbell_interrupt);
+ return -EINVAL;
+ }
+
+ if (pcct_ss->header.type
+ == ACPI_PCCT_TYPE_HW_REDUCED_SUBSPACE_TYPE2) {
+ struct acpi_pcct_hw_reduced_type2 *pcct2_ss = (void *)pcct_ss;
+
+ pcc_doorbell_ack_vaddr[id] = acpi_os_ioremap(
+ pcct2_ss->doorbell_ack_register.address,
+ pcct2_ss->doorbell_ack_register.bit_width / 8);
+ if (!pcc_doorbell_ack_vaddr[id]) {
+ pr_err("Failed to ioremap PCC ACK register\n");
+ return -ENOMEM;
+ }
+ }
+
+ return 0;
+}
+
+/**
* acpi_pcc_probe - Parse the ACPI tree for the PCCT.
*
* Return: 0 for Success, else errno.
@@ -316,7 +449,9 @@
acpi_size pcct_tbl_header_size;
struct acpi_table_header *pcct_tbl;
struct acpi_subtable_header *pcct_entry;
- int count, i;
+ struct acpi_table_pcct *acpi_pcct_tbl;
+ int count, i, rc;
+ int sum = 0;
acpi_status status = AE_OK;
/* Search for PCCT */
@@ -333,37 +468,66 @@
sizeof(struct acpi_table_pcct),
ACPI_PCCT_TYPE_HW_REDUCED_SUBSPACE,
parse_pcc_subspace, MAX_PCC_SUBSPACES);
+ sum += (count > 0) ? count : 0;
- if (count <= 0) {
+ count = acpi_table_parse_entries(ACPI_SIG_PCCT,
+ sizeof(struct acpi_table_pcct),
+ ACPI_PCCT_TYPE_HW_REDUCED_SUBSPACE_TYPE2,
+ parse_pcc_subspace, MAX_PCC_SUBSPACES);
+ sum += (count > 0) ? count : 0;
+
+ if (sum == 0 || sum >= MAX_PCC_SUBSPACES) {
pr_err("Error parsing PCC subspaces from PCCT\n");
return -EINVAL;
}
pcc_mbox_channels = kzalloc(sizeof(struct mbox_chan) *
- count, GFP_KERNEL);
-
+ sum, GFP_KERNEL);
if (!pcc_mbox_channels) {
pr_err("Could not allocate space for PCC mbox channels\n");
return -ENOMEM;
}
- pcc_doorbell_vaddr = kcalloc(count, sizeof(void *), GFP_KERNEL);
+ pcc_doorbell_vaddr = kcalloc(sum, sizeof(void *), GFP_KERNEL);
if (!pcc_doorbell_vaddr) {
- kfree(pcc_mbox_channels);
- return -ENOMEM;
+ rc = -ENOMEM;
+ goto err_free_mbox;
+ }
+
+ pcc_doorbell_ack_vaddr = kcalloc(sum, sizeof(void *), GFP_KERNEL);
+ if (!pcc_doorbell_ack_vaddr) {
+ rc = -ENOMEM;
+ goto err_free_db_vaddr;
+ }
+
+ pcc_doorbell_irq = kcalloc(sum, sizeof(int), GFP_KERNEL);
+ if (!pcc_doorbell_irq) {
+ rc = -ENOMEM;
+ goto err_free_db_ack_vaddr;
}
/* Point to the first PCC subspace entry */
pcct_entry = (struct acpi_subtable_header *) (
(unsigned long) pcct_tbl + sizeof(struct acpi_table_pcct));
- for (i = 0; i < count; i++) {
+ acpi_pcct_tbl = (struct acpi_table_pcct *) pcct_tbl;
+ if (acpi_pcct_tbl->flags & ACPI_PCCT_DOORBELL)
+ pcc_mbox_ctrl.txdone_irq = true;
+
+ for (i = 0; i < sum; i++) {
struct acpi_generic_address *db_reg;
struct acpi_pcct_hw_reduced *pcct_ss;
pcc_mbox_channels[i].con_priv = pcct_entry;
+ pcct_ss = (struct acpi_pcct_hw_reduced *) pcct_entry;
+
+ if (pcc_mbox_ctrl.txdone_irq) {
+ rc = pcc_parse_subspace_irq(i, pcct_ss);
+ if (rc < 0)
+ goto err;
+ }
+
/* If doorbell is in system memory cache the virt address */
- pcct_ss = (struct acpi_pcct_hw_reduced *)pcct_entry;
db_reg = &pcct_ss->doorbell_register;
if (db_reg->space_id == ACPI_ADR_SPACE_SYSTEM_MEMORY)
pcc_doorbell_vaddr[i] = acpi_os_ioremap(db_reg->address,
@@ -372,11 +536,21 @@
((unsigned long) pcct_entry + pcct_entry->length);
}
- pcc_mbox_ctrl.num_chans = count;
+ pcc_mbox_ctrl.num_chans = sum;
pr_info("Detected %d PCC Subspaces\n", pcc_mbox_ctrl.num_chans);
return 0;
+
+err:
+ kfree(pcc_doorbell_irq);
+err_free_db_ack_vaddr:
+ kfree(pcc_doorbell_ack_vaddr);
+err_free_db_vaddr:
+ kfree(pcc_doorbell_vaddr);
+err_free_mbox:
+ kfree(pcc_mbox_channels);
+ return rc;
}
/**
diff --git a/drivers/media/cec-edid.c b/drivers/media/cec-edid.c
index 7001824..5719b99 100644
--- a/drivers/media/cec-edid.c
+++ b/drivers/media/cec-edid.c
@@ -70,7 +70,10 @@
u8 tag = edid[i] >> 5;
u8 len = edid[i] & 0x1f;
- if (tag == 3 && len >= 5 && i + len <= end)
+ if (tag == 3 && len >= 5 && i + len <= end &&
+ edid[i + 1] == 0x03 &&
+ edid[i + 2] == 0x0c &&
+ edid[i + 3] == 0x00)
return i + 4;
i += len + 1;
} while (i < end);
diff --git a/drivers/media/pci/cx23885/cx23885-417.c b/drivers/media/pci/cx23885/cx23885-417.c
index efec2d1..4d080da 100644
--- a/drivers/media/pci/cx23885/cx23885-417.c
+++ b/drivers/media/pci/cx23885/cx23885-417.c
@@ -1552,6 +1552,7 @@
q->mem_ops = &vb2_dma_sg_memops;
q->timestamp_flags = V4L2_BUF_FLAG_TIMESTAMP_MONOTONIC;
q->lock = &dev->lock;
+ q->dev = &dev->pci->dev;
err = vb2_queue_init(q);
if (err < 0)
diff --git a/drivers/media/pci/saa7134/saa7134-dvb.c b/drivers/media/pci/saa7134/saa7134-dvb.c
index db987e5..59a4b5f 100644
--- a/drivers/media/pci/saa7134/saa7134-dvb.c
+++ b/drivers/media/pci/saa7134/saa7134-dvb.c
@@ -1238,6 +1238,7 @@
q->buf_struct_size = sizeof(struct saa7134_buf);
q->timestamp_flags = V4L2_BUF_FLAG_TIMESTAMP_MONOTONIC;
q->lock = &dev->lock;
+ q->dev = &dev->pci->dev;
ret = vb2_queue_init(q);
if (ret) {
vb2_dvb_dealloc_frontends(&dev->frontends);
diff --git a/drivers/media/pci/saa7134/saa7134-empress.c b/drivers/media/pci/saa7134/saa7134-empress.c
index ca417a4..791a516 100644
--- a/drivers/media/pci/saa7134/saa7134-empress.c
+++ b/drivers/media/pci/saa7134/saa7134-empress.c
@@ -295,6 +295,7 @@
q->buf_struct_size = sizeof(struct saa7134_buf);
q->timestamp_flags = V4L2_BUF_FLAG_TIMESTAMP_MONOTONIC;
q->lock = &dev->lock;
+ q->dev = &dev->pci->dev;
err = vb2_queue_init(q);
if (err)
return err;
diff --git a/drivers/media/platform/Kconfig b/drivers/media/platform/Kconfig
index f25344b..552b635 100644
--- a/drivers/media/platform/Kconfig
+++ b/drivers/media/platform/Kconfig
@@ -169,7 +169,7 @@
config VIDEO_MEDIATEK_VCODEC
tristate "Mediatek Video Codec driver"
depends on MTK_IOMMU || COMPILE_TEST
- depends on VIDEO_DEV && VIDEO_V4L2
+ depends on VIDEO_DEV && VIDEO_V4L2 && HAS_DMA
depends on ARCH_MEDIATEK || COMPILE_TEST
select VIDEOBUF2_DMA_CONTIG
select V4L2_MEM2MEM_DEV
diff --git a/drivers/media/platform/mtk-vcodec/mtk_vcodec_drv.h b/drivers/media/platform/mtk-vcodec/mtk_vcodec_drv.h
index 94f0a42..3a8e695 100644
--- a/drivers/media/platform/mtk-vcodec/mtk_vcodec_drv.h
+++ b/drivers/media/platform/mtk-vcodec/mtk_vcodec_drv.h
@@ -23,7 +23,6 @@
#include <media/v4l2-ioctl.h>
#include <media/videobuf2-core.h>
-#include "mtk_vcodec_util.h"
#define MTK_VCODEC_DRV_NAME "mtk_vcodec_drv"
#define MTK_VCODEC_ENC_NAME "mtk-vcodec-enc"
diff --git a/drivers/media/platform/mtk-vcodec/mtk_vcodec_enc.c b/drivers/media/platform/mtk-vcodec/mtk_vcodec_enc.c
index 3ed3f2d..2c5719a 100644
--- a/drivers/media/platform/mtk-vcodec/mtk_vcodec_enc.c
+++ b/drivers/media/platform/mtk-vcodec/mtk_vcodec_enc.c
@@ -487,7 +487,6 @@
struct mtk_q_data *q_data;
int ret, i;
struct mtk_video_fmt *fmt;
- unsigned int pitch_w_div16;
struct v4l2_pix_format_mplane *pix_fmt_mp = &f->fmt.pix_mp;
vq = v4l2_m2m_get_vq(ctx->m2m_ctx, f->type);
@@ -530,15 +529,6 @@
q_data->coded_width = f->fmt.pix_mp.width;
q_data->coded_height = f->fmt.pix_mp.height;
- pitch_w_div16 = DIV_ROUND_UP(q_data->visible_width, 16);
- if (pitch_w_div16 % 8 != 0) {
- /* Adjust returned width/height, so application could correctly
- * allocate hw required memory
- */
- q_data->visible_height += 32;
- vidioc_try_fmt(f, q_data->fmt);
- }
-
q_data->field = f->fmt.pix_mp.field;
ctx->colorspace = f->fmt.pix_mp.colorspace;
ctx->ycbcr_enc = f->fmt.pix_mp.ycbcr_enc;
@@ -878,7 +868,8 @@
{
struct mtk_vcodec_ctx *ctx = priv;
int ret;
- struct vb2_buffer *dst_buf;
+ struct vb2_buffer *src_buf, *dst_buf;
+ struct vb2_v4l2_buffer *dst_vb2_v4l2, *src_vb2_v4l2;
struct mtk_vcodec_mem bs_buf;
struct venc_done_result enc_result;
@@ -911,6 +902,15 @@
mtk_v4l2_err("venc_if_encode failed=%d", ret);
return -EINVAL;
}
+ src_buf = v4l2_m2m_next_src_buf(ctx->m2m_ctx);
+ if (src_buf) {
+ src_vb2_v4l2 = to_vb2_v4l2_buffer(src_buf);
+ dst_vb2_v4l2 = to_vb2_v4l2_buffer(dst_buf);
+ dst_buf->timestamp = src_buf->timestamp;
+ dst_vb2_v4l2->timecode = src_vb2_v4l2->timecode;
+ } else {
+ mtk_v4l2_err("No timestamp for the header buffer.");
+ }
ctx->state = MTK_STATE_HEADER;
dst_buf->planes[0].bytesused = enc_result.bs_size;
@@ -1003,7 +1003,7 @@
struct mtk_vcodec_mem bs_buf;
struct venc_done_result enc_result;
int ret, i;
- struct vb2_v4l2_buffer *vb2_v4l2;
+ struct vb2_v4l2_buffer *dst_vb2_v4l2, *src_vb2_v4l2;
/* check dst_buf, dst_buf may be removed in device_run
* to stored encdoe header so we need check dst_buf and
@@ -1043,9 +1043,14 @@
ret = venc_if_encode(ctx, VENC_START_OPT_ENCODE_FRAME,
&frm_buf, &bs_buf, &enc_result);
- vb2_v4l2 = container_of(dst_buf, struct vb2_v4l2_buffer, vb2_buf);
+ src_vb2_v4l2 = to_vb2_v4l2_buffer(src_buf);
+ dst_vb2_v4l2 = to_vb2_v4l2_buffer(dst_buf);
+
+ dst_buf->timestamp = src_buf->timestamp;
+ dst_vb2_v4l2->timecode = src_vb2_v4l2->timecode;
+
if (enc_result.is_key_frm)
- vb2_v4l2->flags |= V4L2_BUF_FLAG_KEYFRAME;
+ dst_vb2_v4l2->flags |= V4L2_BUF_FLAG_KEYFRAME;
if (ret) {
v4l2_m2m_buf_done(to_vb2_v4l2_buffer(src_buf),
@@ -1217,7 +1222,7 @@
0, V4L2_MPEG_VIDEO_HEADER_MODE_SEPARATE);
v4l2_ctrl_new_std_menu(handler, ops, V4L2_CID_MPEG_VIDEO_H264_PROFILE,
V4L2_MPEG_VIDEO_H264_PROFILE_HIGH,
- 0, V4L2_MPEG_VIDEO_H264_PROFILE_MAIN);
+ 0, V4L2_MPEG_VIDEO_H264_PROFILE_HIGH);
v4l2_ctrl_new_std_menu(handler, ops, V4L2_CID_MPEG_VIDEO_H264_LEVEL,
V4L2_MPEG_VIDEO_H264_LEVEL_4_2,
0, V4L2_MPEG_VIDEO_H264_LEVEL_4_0);
@@ -1288,5 +1293,10 @@
void mtk_vcodec_enc_release(struct mtk_vcodec_ctx *ctx)
{
- venc_if_deinit(ctx);
+ int ret = venc_if_deinit(ctx);
+
+ if (ret)
+ mtk_v4l2_err("venc_if_deinit failed=%d", ret);
+
+ ctx->state = MTK_STATE_FREE;
}
diff --git a/drivers/media/platform/mtk-vcodec/mtk_vcodec_enc_drv.c b/drivers/media/platform/mtk-vcodec/mtk_vcodec_enc_drv.c
index c7806ec..5cd2151 100644
--- a/drivers/media/platform/mtk-vcodec/mtk_vcodec_enc_drv.c
+++ b/drivers/media/platform/mtk-vcodec/mtk_vcodec_enc_drv.c
@@ -218,11 +218,15 @@
mtk_v4l2_debug(1, "[%d] encoder", ctx->id);
mutex_lock(&dev->dev_mutex);
+ /*
+ * Call v4l2_m2m_ctx_release to make sure the worker thread is not
+ * running after venc_if_deinit.
+ */
+ v4l2_m2m_ctx_release(ctx->m2m_ctx);
mtk_vcodec_enc_release(ctx);
v4l2_fh_del(&ctx->fh);
v4l2_fh_exit(&ctx->fh);
v4l2_ctrl_handler_free(&ctx->ctrl_hdl);
- v4l2_m2m_ctx_release(ctx->m2m_ctx);
list_del_init(&ctx->list);
dev->num_instances--;
diff --git a/drivers/media/platform/mtk-vcodec/mtk_vcodec_intr.h b/drivers/media/platform/mtk-vcodec/mtk_vcodec_intr.h
index 33e890f..1213185 100644
--- a/drivers/media/platform/mtk-vcodec/mtk_vcodec_intr.h
+++ b/drivers/media/platform/mtk-vcodec/mtk_vcodec_intr.h
@@ -16,7 +16,6 @@
#define _MTK_VCODEC_INTR_H_
#define MTK_INST_IRQ_RECEIVED 0x1
-#define MTK_INST_WORK_THREAD_ABORT_DONE 0x2
struct mtk_vcodec_ctx;
diff --git a/drivers/media/platform/mtk-vcodec/venc/venc_h264_if.c b/drivers/media/platform/mtk-vcodec/venc/venc_h264_if.c
index 9a60052..63d4be4 100644
--- a/drivers/media/platform/mtk-vcodec/venc/venc_h264_if.c
+++ b/drivers/media/platform/mtk-vcodec/venc/venc_h264_if.c
@@ -61,6 +61,8 @@
/*
* struct venc_h264_vpu_config - Structure for h264 encoder configuration
+ * AP-W/R : AP is writer/reader on this item
+ * VPU-W/R: VPU is write/reader on this item
* @input_fourcc: input fourcc
* @bitrate: target bitrate (in bps)
* @pic_w: picture width. Picture size is visible stream resolution, in pixels,
@@ -94,13 +96,13 @@
/*
* struct venc_h264_vpu_buf - Structure for buffer information
- * @align: buffer alignment (in bytes)
+ * AP-W/R : AP is writer/reader on this item
+ * VPU-W/R: VPU is write/reader on this item
* @iova: IO virtual address
* @vpua: VPU side memory addr which is used by RC_CODE
* @size: buffer size (in bytes)
*/
struct venc_h264_vpu_buf {
- u32 align;
u32 iova;
u32 vpua;
u32 size;
@@ -108,6 +110,8 @@
/*
* struct venc_h264_vsi - Structure for VPU driver control and info share
+ * AP-W/R : AP is writer/reader on this item
+ * VPU-W/R: VPU is write/reader on this item
* This structure is allocated in VPU side and shared to AP side.
* @config: h264 encoder configuration
* @work_bufs: working buffer information in VPU side
@@ -150,12 +154,6 @@
struct mtk_vcodec_ctx *ctx;
};
-static inline void h264_write_reg(struct venc_h264_inst *inst, u32 addr,
- u32 val)
-{
- writel(val, inst->hw_base + addr);
-}
-
static inline u32 h264_read_reg(struct venc_h264_inst *inst, u32 addr)
{
return readl(inst->hw_base + addr);
@@ -214,6 +212,8 @@
return 40;
case V4L2_MPEG_VIDEO_H264_LEVEL_4_1:
return 41;
+ case V4L2_MPEG_VIDEO_H264_LEVEL_4_2:
+ return 42;
default:
mtk_vcodec_debug(inst, "unsupported level %d", level);
return 31;
diff --git a/drivers/media/platform/mtk-vcodec/venc/venc_vp8_if.c b/drivers/media/platform/mtk-vcodec/venc/venc_vp8_if.c
index 60bbcd2..6d97584 100644
--- a/drivers/media/platform/mtk-vcodec/venc/venc_vp8_if.c
+++ b/drivers/media/platform/mtk-vcodec/venc/venc_vp8_if.c
@@ -56,6 +56,8 @@
/*
* struct venc_vp8_vpu_config - Structure for vp8 encoder configuration
+ * AP-W/R : AP is writer/reader on this item
+ * VPU-W/R: VPU is write/reader on this item
* @input_fourcc: input fourcc
* @bitrate: target bitrate (in bps)
* @pic_w: picture width. Picture size is visible stream resolution, in pixels,
@@ -83,14 +85,14 @@
};
/*
- * struct venc_vp8_vpu_buf -Structure for buffer information
- * @align: buffer alignment (in bytes)
+ * struct venc_vp8_vpu_buf - Structure for buffer information
+ * AP-W/R : AP is writer/reader on this item
+ * VPU-W/R: VPU is write/reader on this item
* @iova: IO virtual address
* @vpua: VPU side memory addr which is used by RC_CODE
* @size: buffer size (in bytes)
*/
struct venc_vp8_vpu_buf {
- u32 align;
u32 iova;
u32 vpua;
u32 size;
@@ -98,6 +100,8 @@
/*
* struct venc_vp8_vsi - Structure for VPU driver control and info share
+ * AP-W/R : AP is writer/reader on this item
+ * VPU-W/R: VPU is write/reader on this item
* This structure is allocated in VPU side and shared to AP side.
* @config: vp8 encoder configuration
* @work_bufs: working buffer information in VPU side
@@ -138,12 +142,6 @@
struct mtk_vcodec_ctx *ctx;
};
-static inline void vp8_enc_write_reg(struct venc_vp8_inst *inst, u32 addr,
- u32 val)
-{
- writel(val, inst->hw_base + addr);
-}
-
static inline u32 vp8_enc_read_reg(struct venc_vp8_inst *inst, u32 addr)
{
return readl(inst->hw_base + addr);
diff --git a/drivers/media/platform/rcar-fcp.c b/drivers/media/platform/rcar-fcp.c
index 6a7bcc3..bc50c69 100644
--- a/drivers/media/platform/rcar-fcp.c
+++ b/drivers/media/platform/rcar-fcp.c
@@ -99,10 +99,16 @@
*/
int rcar_fcp_enable(struct rcar_fcp_device *fcp)
{
+ int error;
+
if (!fcp)
return 0;
- return pm_runtime_get_sync(fcp->dev);
+ error = pm_runtime_get_sync(fcp->dev);
+ if (error < 0)
+ return error;
+
+ return 0;
}
EXPORT_SYMBOL_GPL(rcar_fcp_enable);
diff --git a/drivers/mfd/lpc_ich.c b/drivers/mfd/lpc_ich.c
index bd3aa45..c8dee47 100644
--- a/drivers/mfd/lpc_ich.c
+++ b/drivers/mfd/lpc_ich.c
@@ -984,6 +984,10 @@
int ret;
struct resource *res;
+ /* If we have ACPI based watchdog use that instead */
+ if (acpi_has_watchdog())
+ return -ENODEV;
+
/* Setup power management base register */
pci_read_config_dword(dev, priv->abase, &base_addr_cfg);
base_addr = base_addr_cfg & 0x0000ff80;
diff --git a/drivers/mmc/host/dw_mmc.c b/drivers/mmc/host/dw_mmc.c
index 32380d5..767af20 100644
--- a/drivers/mmc/host/dw_mmc.c
+++ b/drivers/mmc/host/dw_mmc.c
@@ -1112,11 +1112,12 @@
div = (host->bus_hz != clock) ? DIV_ROUND_UP(div, 2) : 0;
- dev_info(&slot->mmc->class_dev,
- "Bus speed (slot %d) = %dHz (slot req %dHz, actual %dHZ div = %d)\n",
- slot->id, host->bus_hz, clock,
- div ? ((host->bus_hz / div) >> 1) :
- host->bus_hz, div);
+ if (clock != slot->__clk_old || force_clkinit)
+ dev_info(&slot->mmc->class_dev,
+ "Bus speed (slot %d) = %dHz (slot req %dHz, actual %dHZ div = %d)\n",
+ slot->id, host->bus_hz, clock,
+ div ? ((host->bus_hz / div) >> 1) :
+ host->bus_hz, div);
/* disable clock */
mci_writel(host, CLKENA, 0);
@@ -1139,6 +1140,9 @@
/* inform CIU */
mci_send_cmd(slot, sdmmc_cmd_bits, 0);
+
+ /* keep the last clock value that was requested from core */
+ slot->__clk_old = clock;
}
host->current_speed = clock;
diff --git a/drivers/mmc/host/dw_mmc.h b/drivers/mmc/host/dw_mmc.h
index 9e740bc..e8cd2de 100644
--- a/drivers/mmc/host/dw_mmc.h
+++ b/drivers/mmc/host/dw_mmc.h
@@ -249,6 +249,8 @@
* @queue_node: List node for placing this node in the @queue list of
* &struct dw_mci.
* @clock: Clock rate configured by set_ios(). Protected by host->lock.
+ * @__clk_old: The last clock value that was requested from core.
+ * Keeping track of this helps us to avoid spamming the console.
* @flags: Random state bits associated with the slot.
* @id: Number of this slot.
* @sdio_id: Number of this slot in the SDIO interrupt registers.
@@ -263,6 +265,7 @@
struct list_head queue_node;
unsigned int clock;
+ unsigned int __clk_old;
unsigned long flags;
#define DW_MMC_CARD_PRESENT 0
diff --git a/drivers/mtd/nand/davinci_nand.c b/drivers/mtd/nand/davinci_nand.c
index cc07ba0..27fa8b8 100644
--- a/drivers/mtd/nand/davinci_nand.c
+++ b/drivers/mtd/nand/davinci_nand.c
@@ -240,6 +240,9 @@
unsigned long flags;
u32 val;
+ /* Reset ECC hardware */
+ davinci_nand_readl(info, NAND_4BIT_ECC1_OFFSET);
+
spin_lock_irqsave(&davinci_nand_lock, flags);
/* Start 4-bit ECC calculation for read/write */
diff --git a/drivers/mtd/nand/mtk_ecc.c b/drivers/mtd/nand/mtk_ecc.c
index 25a4fbd..d54f666 100644
--- a/drivers/mtd/nand/mtk_ecc.c
+++ b/drivers/mtd/nand/mtk_ecc.c
@@ -366,7 +366,8 @@
u8 *data, u32 bytes)
{
dma_addr_t addr;
- u32 *p, len, i;
+ u8 *p;
+ u32 len, i, val;
int ret = 0;
addr = dma_map_single(ecc->dev, data, bytes, DMA_TO_DEVICE);
@@ -392,11 +393,14 @@
/* Program ECC bytes to OOB: per sector oob = FDM + ECC + SPARE */
len = (config->strength * ECC_PARITY_BITS + 7) >> 3;
- p = (u32 *)(data + bytes);
+ p = data + bytes;
/* write the parity bytes generated by the ECC back to the OOB region */
- for (i = 0; i < len; i++)
- p[i] = readl(ecc->regs + ECC_ENCPAR(i));
+ for (i = 0; i < len; i++) {
+ if ((i % 4) == 0)
+ val = readl(ecc->regs + ECC_ENCPAR(i / 4));
+ p[i] = (val >> ((i % 4) * 8)) & 0xff;
+ }
timeout:
dma_unmap_single(ecc->dev, addr, bytes, DMA_TO_DEVICE);
diff --git a/drivers/mtd/nand/mtk_nand.c b/drivers/mtd/nand/mtk_nand.c
index ddaa2ac..5223a21 100644
--- a/drivers/mtd/nand/mtk_nand.c
+++ b/drivers/mtd/nand/mtk_nand.c
@@ -93,6 +93,9 @@
#define NFI_FSM_MASK (0xf << 16)
#define NFI_ADDRCNTR (0x70)
#define CNTR_MASK GENMASK(16, 12)
+#define ADDRCNTR_SEC_SHIFT (12)
+#define ADDRCNTR_SEC(val) \
+ (((val) & CNTR_MASK) >> ADDRCNTR_SEC_SHIFT)
#define NFI_STRADDR (0x80)
#define NFI_BYTELEN (0x84)
#define NFI_CSEL (0x90)
@@ -699,7 +702,7 @@
}
ret = readl_poll_timeout_atomic(nfc->regs + NFI_ADDRCNTR, reg,
- (reg & CNTR_MASK) >= chip->ecc.steps,
+ ADDRCNTR_SEC(reg) >= chip->ecc.steps,
10, MTK_TIMEOUT);
if (ret)
dev_err(dev, "hwecc write timeout\n");
@@ -902,7 +905,7 @@
dev_warn(nfc->dev, "read ahb/dma done timeout\n");
rc = readl_poll_timeout_atomic(nfc->regs + NFI_BYTELEN, reg,
- (reg & CNTR_MASK) >= sectors, 10,
+ ADDRCNTR_SEC(reg) >= sectors, 10,
MTK_TIMEOUT);
if (rc < 0) {
dev_err(nfc->dev, "subpage done timeout\n");
diff --git a/drivers/mtd/nand/mxc_nand.c b/drivers/mtd/nand/mxc_nand.c
index 5173fad..57cbe2b 100644
--- a/drivers/mtd/nand/mxc_nand.c
+++ b/drivers/mtd/nand/mxc_nand.c
@@ -943,7 +943,7 @@
struct nand_chip *nand_chip = mtd_to_nand(mtd);
int stepsize = nand_chip->ecc.bytes == 9 ? 16 : 26;
- if (section > nand_chip->ecc.steps)
+ if (section >= nand_chip->ecc.steps)
return -ERANGE;
if (!section) {
diff --git a/drivers/mtd/nand/omap2.c b/drivers/mtd/nand/omap2.c
index a59361c..5513bfd9 100644
--- a/drivers/mtd/nand/omap2.c
+++ b/drivers/mtd/nand/omap2.c
@@ -2169,7 +2169,7 @@
return 0;
return_error:
- if (info->dma)
+ if (!IS_ERR_OR_NULL(info->dma))
dma_release_channel(info->dma);
if (nand_chip->ecc.priv) {
nand_bch_free(nand_chip->ecc.priv);
diff --git a/drivers/net/can/dev.c b/drivers/net/can/dev.c
index e21f7cc..8d6208c 100644
--- a/drivers/net/can/dev.c
+++ b/drivers/net/can/dev.c
@@ -21,6 +21,7 @@
#include <linux/slab.h>
#include <linux/netdevice.h>
#include <linux/if_arp.h>
+#include <linux/workqueue.h>
#include <linux/can.h>
#include <linux/can/dev.h>
#include <linux/can/skb.h>
@@ -501,9 +502,8 @@
/*
* CAN device restart for bus-off recovery
*/
-static void can_restart(unsigned long data)
+static void can_restart(struct net_device *dev)
{
- struct net_device *dev = (struct net_device *)data;
struct can_priv *priv = netdev_priv(dev);
struct net_device_stats *stats = &dev->stats;
struct sk_buff *skb;
@@ -543,6 +543,14 @@
netdev_err(dev, "Error %d during restart", err);
}
+static void can_restart_work(struct work_struct *work)
+{
+ struct delayed_work *dwork = to_delayed_work(work);
+ struct can_priv *priv = container_of(dwork, struct can_priv, restart_work);
+
+ can_restart(priv->dev);
+}
+
int can_restart_now(struct net_device *dev)
{
struct can_priv *priv = netdev_priv(dev);
@@ -556,8 +564,8 @@
if (priv->state != CAN_STATE_BUS_OFF)
return -EBUSY;
- /* Runs as soon as possible in the timer context */
- mod_timer(&priv->restart_timer, jiffies);
+ cancel_delayed_work_sync(&priv->restart_work);
+ can_restart(dev);
return 0;
}
@@ -578,8 +586,8 @@
netif_carrier_off(dev);
if (priv->restart_ms)
- mod_timer(&priv->restart_timer,
- jiffies + (priv->restart_ms * HZ) / 1000);
+ schedule_delayed_work(&priv->restart_work,
+ msecs_to_jiffies(priv->restart_ms));
}
EXPORT_SYMBOL_GPL(can_bus_off);
@@ -688,6 +696,7 @@
return NULL;
priv = netdev_priv(dev);
+ priv->dev = dev;
if (echo_skb_max) {
priv->echo_skb_max = echo_skb_max;
@@ -697,7 +706,7 @@
priv->state = CAN_STATE_STOPPED;
- init_timer(&priv->restart_timer);
+ INIT_DELAYED_WORK(&priv->restart_work, can_restart_work);
return dev;
}
@@ -778,8 +787,6 @@
if (!netif_carrier_ok(dev))
netif_carrier_on(dev);
- setup_timer(&priv->restart_timer, can_restart, (unsigned long)dev);
-
return 0;
}
EXPORT_SYMBOL_GPL(open_candev);
@@ -794,7 +801,7 @@
{
struct can_priv *priv = netdev_priv(dev);
- del_timer_sync(&priv->restart_timer);
+ cancel_delayed_work_sync(&priv->restart_work);
can_flush_echo_skb(dev);
}
EXPORT_SYMBOL_GPL(close_candev);
diff --git a/drivers/net/can/flexcan.c b/drivers/net/can/flexcan.c
index 41c0fc9..16f7cad 100644
--- a/drivers/net/can/flexcan.c
+++ b/drivers/net/can/flexcan.c
@@ -1268,11 +1268,10 @@
struct flexcan_priv *priv = netdev_priv(dev);
int err;
- err = flexcan_chip_disable(priv);
- if (err)
- return err;
-
if (netif_running(dev)) {
+ err = flexcan_chip_disable(priv);
+ if (err)
+ return err;
netif_stop_queue(dev);
netif_device_detach(dev);
}
@@ -1285,13 +1284,17 @@
{
struct net_device *dev = dev_get_drvdata(device);
struct flexcan_priv *priv = netdev_priv(dev);
+ int err;
priv->can.state = CAN_STATE_ERROR_ACTIVE;
if (netif_running(dev)) {
netif_device_attach(dev);
netif_start_queue(dev);
+ err = flexcan_chip_enable(priv);
+ if (err)
+ return err;
}
- return flexcan_chip_enable(priv);
+ return 0;
}
static SIMPLE_DEV_PM_OPS(flexcan_pm_ops, flexcan_suspend, flexcan_resume);
diff --git a/drivers/net/can/ifi_canfd/ifi_canfd.c b/drivers/net/can/ifi_canfd/ifi_canfd.c
index 2d1d22e..368bb07 100644
--- a/drivers/net/can/ifi_canfd/ifi_canfd.c
+++ b/drivers/net/can/ifi_canfd/ifi_canfd.c
@@ -81,6 +81,10 @@
#define IFI_CANFD_TIME_SET_TIMEA_4_12_6_6 BIT(15)
#define IFI_CANFD_TDELAY 0x1c
+#define IFI_CANFD_TDELAY_DEFAULT 0xb
+#define IFI_CANFD_TDELAY_MASK 0x3fff
+#define IFI_CANFD_TDELAY_ABS BIT(14)
+#define IFI_CANFD_TDELAY_EN BIT(15)
#define IFI_CANFD_ERROR 0x20
#define IFI_CANFD_ERROR_TX_OFFSET 0
@@ -641,7 +645,7 @@
struct ifi_canfd_priv *priv = netdev_priv(ndev);
const struct can_bittiming *bt = &priv->can.bittiming;
const struct can_bittiming *dbt = &priv->can.data_bittiming;
- u16 brp, sjw, tseg1, tseg2;
+ u16 brp, sjw, tseg1, tseg2, tdc;
/* Configure bit timing */
brp = bt->brp - 2;
@@ -664,6 +668,11 @@
(brp << IFI_CANFD_TIME_PRESCALE_OFF) |
(sjw << IFI_CANFD_TIME_SJW_OFF_7_9_8_8),
priv->base + IFI_CANFD_FTIME);
+
+ /* Configure transmitter delay */
+ tdc = (dbt->brp * (dbt->phase_seg1 + 1)) & IFI_CANFD_TDELAY_MASK;
+ writel(IFI_CANFD_TDELAY_EN | IFI_CANFD_TDELAY_ABS | tdc,
+ priv->base + IFI_CANFD_TDELAY);
}
static void ifi_canfd_set_filter(struct net_device *ndev, const u32 id,
diff --git a/drivers/net/ethernet/broadcom/bnx2.c b/drivers/net/ethernet/broadcom/bnx2.c
index 8fc3f3c..505ceaf 100644
--- a/drivers/net/ethernet/broadcom/bnx2.c
+++ b/drivers/net/ethernet/broadcom/bnx2.c
@@ -6356,10 +6356,6 @@
struct bnx2 *bp = netdev_priv(dev);
int rc;
- rc = bnx2_request_firmware(bp);
- if (rc < 0)
- goto out;
-
netif_carrier_off(dev);
bnx2_disable_int(bp);
@@ -6428,7 +6424,6 @@
bnx2_free_irq(bp);
bnx2_free_mem(bp);
bnx2_del_napi(bp);
- bnx2_release_firmware(bp);
goto out;
}
@@ -8575,6 +8570,12 @@
pci_set_drvdata(pdev, dev);
+ rc = bnx2_request_firmware(bp);
+ if (rc < 0)
+ goto error;
+
+
+ bnx2_reset_chip(bp, BNX2_DRV_MSG_CODE_RESET);
memcpy(dev->dev_addr, bp->mac_addr, ETH_ALEN);
dev->hw_features = NETIF_F_IP_CSUM | NETIF_F_SG |
@@ -8607,6 +8608,7 @@
return 0;
error:
+ bnx2_release_firmware(bp);
pci_iounmap(pdev, bp->regview);
pci_release_regions(pdev);
pci_disable_device(pdev);
diff --git a/drivers/net/ethernet/broadcom/genet/bcmgenet.c b/drivers/net/ethernet/broadcom/genet/bcmgenet.c
index 8d4f849..5414563 100644
--- a/drivers/net/ethernet/broadcom/genet/bcmgenet.c
+++ b/drivers/net/ethernet/broadcom/genet/bcmgenet.c
@@ -453,25 +453,29 @@
static int bcmgenet_get_settings(struct net_device *dev,
struct ethtool_cmd *cmd)
{
+ struct bcmgenet_priv *priv = netdev_priv(dev);
+
if (!netif_running(dev))
return -EINVAL;
- if (!dev->phydev)
+ if (!priv->phydev)
return -ENODEV;
- return phy_ethtool_gset(dev->phydev, cmd);
+ return phy_ethtool_gset(priv->phydev, cmd);
}
static int bcmgenet_set_settings(struct net_device *dev,
struct ethtool_cmd *cmd)
{
+ struct bcmgenet_priv *priv = netdev_priv(dev);
+
if (!netif_running(dev))
return -EINVAL;
- if (!dev->phydev)
+ if (!priv->phydev)
return -ENODEV;
- return phy_ethtool_sset(dev->phydev, cmd);
+ return phy_ethtool_sset(priv->phydev, cmd);
}
static int bcmgenet_set_rx_csum(struct net_device *dev,
@@ -937,7 +941,7 @@
e->eee_active = p->eee_active;
e->tx_lpi_timer = bcmgenet_umac_readl(priv, UMAC_EEE_LPI_TIMER);
- return phy_ethtool_get_eee(dev->phydev, e);
+ return phy_ethtool_get_eee(priv->phydev, e);
}
static int bcmgenet_set_eee(struct net_device *dev, struct ethtool_eee *e)
@@ -954,7 +958,7 @@
if (!p->eee_enabled) {
bcmgenet_eee_enable_set(dev, false);
} else {
- ret = phy_init_eee(dev->phydev, 0);
+ ret = phy_init_eee(priv->phydev, 0);
if (ret) {
netif_err(priv, hw, dev, "EEE initialization failed\n");
return ret;
@@ -964,12 +968,14 @@
bcmgenet_eee_enable_set(dev, true);
}
- return phy_ethtool_set_eee(dev->phydev, e);
+ return phy_ethtool_set_eee(priv->phydev, e);
}
static int bcmgenet_nway_reset(struct net_device *dev)
{
- return genphy_restart_aneg(dev->phydev);
+ struct bcmgenet_priv *priv = netdev_priv(dev);
+
+ return genphy_restart_aneg(priv->phydev);
}
/* standard ethtool support functions. */
@@ -996,13 +1002,12 @@
static int bcmgenet_power_down(struct bcmgenet_priv *priv,
enum bcmgenet_power_mode mode)
{
- struct net_device *ndev = priv->dev;
int ret = 0;
u32 reg;
switch (mode) {
case GENET_POWER_CABLE_SENSE:
- phy_detach(ndev->phydev);
+ phy_detach(priv->phydev);
break;
case GENET_POWER_WOL_MAGIC:
@@ -1063,6 +1068,7 @@
/* ioctl handle special commands that are not present in ethtool. */
static int bcmgenet_ioctl(struct net_device *dev, struct ifreq *rq, int cmd)
{
+ struct bcmgenet_priv *priv = netdev_priv(dev);
int val = 0;
if (!netif_running(dev))
@@ -1072,10 +1078,10 @@
case SIOCGMIIPHY:
case SIOCGMIIREG:
case SIOCSMIIREG:
- if (!dev->phydev)
+ if (!priv->phydev)
val = -ENODEV;
else
- val = phy_mii_ioctl(dev->phydev, rq, cmd);
+ val = phy_mii_ioctl(priv->phydev, rq, cmd);
break;
default:
@@ -2458,7 +2464,6 @@
{
struct bcmgenet_priv *priv = container_of(
work, struct bcmgenet_priv, bcmgenet_irq_work);
- struct net_device *ndev = priv->dev;
netif_dbg(priv, intr, priv->dev, "%s\n", __func__);
@@ -2471,7 +2476,7 @@
/* Link UP/DOWN event */
if (priv->irq0_stat & UMAC_IRQ_LINK_EVENT) {
- phy_mac_interrupt(ndev->phydev,
+ phy_mac_interrupt(priv->phydev,
!!(priv->irq0_stat & UMAC_IRQ_LINK_UP));
priv->irq0_stat &= ~UMAC_IRQ_LINK_EVENT;
}
@@ -2833,7 +2838,7 @@
/* Monitor link interrupts now */
bcmgenet_link_intr_enable(priv);
- phy_start(dev->phydev);
+ phy_start(priv->phydev);
}
static int bcmgenet_open(struct net_device *dev)
@@ -2932,7 +2937,7 @@
struct bcmgenet_priv *priv = netdev_priv(dev);
netif_tx_stop_all_queues(dev);
- phy_stop(dev->phydev);
+ phy_stop(priv->phydev);
bcmgenet_intr_disable(priv);
bcmgenet_disable_rx_napi(priv);
bcmgenet_disable_tx_napi(priv);
@@ -2958,7 +2963,7 @@
bcmgenet_netif_stop(dev);
/* Really kill the PHY state machine and disconnect from it */
- phy_disconnect(dev->phydev);
+ phy_disconnect(priv->phydev);
/* Disable MAC receive */
umac_enable_set(priv, CMD_RX_EN, false);
@@ -3517,7 +3522,7 @@
bcmgenet_netif_stop(dev);
- phy_suspend(dev->phydev);
+ phy_suspend(priv->phydev);
netif_device_detach(dev);
@@ -3581,7 +3586,7 @@
if (priv->wolopts)
clk_disable_unprepare(priv->clk_wol);
- phy_init_hw(dev->phydev);
+ phy_init_hw(priv->phydev);
/* Speed settings must be restored */
bcmgenet_mii_config(priv->dev);
@@ -3614,7 +3619,7 @@
netif_device_attach(dev);
- phy_resume(dev->phydev);
+ phy_resume(priv->phydev);
if (priv->eee.eee_enabled)
bcmgenet_eee_enable_set(dev, true);
diff --git a/drivers/net/ethernet/broadcom/genet/bcmgenet.h b/drivers/net/ethernet/broadcom/genet/bcmgenet.h
index 0f0868c..1e2dc34 100644
--- a/drivers/net/ethernet/broadcom/genet/bcmgenet.h
+++ b/drivers/net/ethernet/broadcom/genet/bcmgenet.h
@@ -597,6 +597,7 @@
/* MDIO bus variables */
wait_queue_head_t wq;
+ struct phy_device *phydev;
bool internal_phy;
struct device_node *phy_dn;
struct device_node *mdio_dn;
diff --git a/drivers/net/ethernet/broadcom/genet/bcmmii.c b/drivers/net/ethernet/broadcom/genet/bcmmii.c
index e907acd..457c3bc 100644
--- a/drivers/net/ethernet/broadcom/genet/bcmmii.c
+++ b/drivers/net/ethernet/broadcom/genet/bcmmii.c
@@ -86,7 +86,7 @@
void bcmgenet_mii_setup(struct net_device *dev)
{
struct bcmgenet_priv *priv = netdev_priv(dev);
- struct phy_device *phydev = dev->phydev;
+ struct phy_device *phydev = priv->phydev;
u32 reg, cmd_bits = 0;
bool status_changed = false;
@@ -183,9 +183,9 @@
if (GENET_IS_V4(priv))
return;
- if (dev->phydev) {
- phy_init_hw(dev->phydev);
- phy_start_aneg(dev->phydev);
+ if (priv->phydev) {
+ phy_init_hw(priv->phydev);
+ phy_start_aneg(priv->phydev);
}
}
@@ -236,7 +236,6 @@
static void bcmgenet_moca_phy_setup(struct bcmgenet_priv *priv)
{
- struct net_device *ndev = priv->dev;
u32 reg;
/* Speed settings are set in bcmgenet_mii_setup() */
@@ -245,14 +244,14 @@
bcmgenet_sys_writel(priv, reg, SYS_PORT_CTRL);
if (priv->hw_params->flags & GENET_HAS_MOCA_LINK_DET)
- fixed_phy_set_link_update(ndev->phydev,
+ fixed_phy_set_link_update(priv->phydev,
bcmgenet_fixed_phy_link_update);
}
int bcmgenet_mii_config(struct net_device *dev)
{
struct bcmgenet_priv *priv = netdev_priv(dev);
- struct phy_device *phydev = dev->phydev;
+ struct phy_device *phydev = priv->phydev;
struct device *kdev = &priv->pdev->dev;
const char *phy_name = NULL;
u32 id_mode_dis = 0;
@@ -303,7 +302,7 @@
* capabilities, use that knowledge to also configure the
* Reverse MII interface correctly.
*/
- if ((phydev->supported & PHY_BASIC_FEATURES) ==
+ if ((priv->phydev->supported & PHY_BASIC_FEATURES) ==
PHY_BASIC_FEATURES)
port_ctrl = PORT_MODE_EXT_RVMII_25;
else
@@ -372,7 +371,7 @@
return -ENODEV;
}
} else {
- phydev = dev->phydev;
+ phydev = priv->phydev;
phydev->dev_flags = phy_flags;
ret = phy_connect_direct(dev, phydev, bcmgenet_mii_setup,
@@ -383,6 +382,8 @@
}
}
+ priv->phydev = phydev;
+
/* Configure port multiplexer based on what the probed PHY device since
* reading the 'max-speed' property determines the maximum supported
* PHY speed which is needed for bcmgenet_mii_config() to configure
@@ -390,7 +391,7 @@
*/
ret = bcmgenet_mii_config(dev);
if (ret) {
- phy_disconnect(phydev);
+ phy_disconnect(priv->phydev);
return ret;
}
@@ -400,7 +401,7 @@
* Ethernet MAC ISRs
*/
if (priv->internal_phy)
- phydev->irq = PHY_IGNORE_INTERRUPT;
+ priv->phydev->irq = PHY_IGNORE_INTERRUPT;
return 0;
}
@@ -605,6 +606,7 @@
}
+ priv->phydev = phydev;
priv->phy_interface = pd->phy_interface;
return 0;
diff --git a/drivers/net/ethernet/broadcom/tg3.c b/drivers/net/ethernet/broadcom/tg3.c
index a2551bc..ea967df 100644
--- a/drivers/net/ethernet/broadcom/tg3.c
+++ b/drivers/net/ethernet/broadcom/tg3.c
@@ -18122,14 +18122,14 @@
rtnl_lock();
- /* We needn't recover from permanent error */
- if (state == pci_channel_io_frozen)
- tp->pcierr_recovery = true;
-
/* We probably don't have netdev yet */
if (!netdev || !netif_running(netdev))
goto done;
+ /* We needn't recover from permanent error */
+ if (state == pci_channel_io_frozen)
+ tp->pcierr_recovery = true;
+
tg3_phy_stop(tp);
tg3_netif_stop(tp);
@@ -18226,7 +18226,7 @@
rtnl_lock();
- if (!netif_running(netdev))
+ if (!netdev || !netif_running(netdev))
goto done;
tg3_full_lock(tp, 0);
diff --git a/drivers/net/ethernet/brocade/bna/bnad_ethtool.c b/drivers/net/ethernet/brocade/bna/bnad_ethtool.c
index 0e4fdc3..31f61a7 100644
--- a/drivers/net/ethernet/brocade/bna/bnad_ethtool.c
+++ b/drivers/net/ethernet/brocade/bna/bnad_ethtool.c
@@ -31,15 +31,10 @@
#define BNAD_NUM_TXF_COUNTERS 12
#define BNAD_NUM_RXF_COUNTERS 10
#define BNAD_NUM_CQ_COUNTERS (3 + 5)
-#define BNAD_NUM_RXQ_COUNTERS 6
+#define BNAD_NUM_RXQ_COUNTERS 7
#define BNAD_NUM_TXQ_COUNTERS 5
-#define BNAD_ETHTOOL_STATS_NUM \
- (sizeof(struct rtnl_link_stats64) / sizeof(u64) + \
- sizeof(struct bnad_drv_stats) / sizeof(u64) + \
- offsetof(struct bfi_enet_stats, rxf_stats[0]) / sizeof(u64))
-
-static const char *bnad_net_stats_strings[BNAD_ETHTOOL_STATS_NUM] = {
+static const char *bnad_net_stats_strings[] = {
"rx_packets",
"tx_packets",
"rx_bytes",
@@ -50,22 +45,10 @@
"tx_dropped",
"multicast",
"collisions",
-
"rx_length_errors",
- "rx_over_errors",
"rx_crc_errors",
"rx_frame_errors",
- "rx_fifo_errors",
- "rx_missed_errors",
-
- "tx_aborted_errors",
- "tx_carrier_errors",
"tx_fifo_errors",
- "tx_heartbeat_errors",
- "tx_window_errors",
-
- "rx_compressed",
- "tx_compressed",
"netif_queue_stop",
"netif_queue_wakeup",
@@ -254,6 +237,8 @@
"fc_tx_fid_parity_errors",
};
+#define BNAD_ETHTOOL_STATS_NUM ARRAY_SIZE(bnad_net_stats_strings)
+
static int
bnad_get_settings(struct net_device *netdev, struct ethtool_cmd *cmd)
{
@@ -658,6 +643,8 @@
string += ETH_GSTRING_LEN;
sprintf(string, "rxq%d_allocbuf_failed", q_num);
string += ETH_GSTRING_LEN;
+ sprintf(string, "rxq%d_mapbuf_failed", q_num);
+ string += ETH_GSTRING_LEN;
sprintf(string, "rxq%d_producer_index", q_num);
string += ETH_GSTRING_LEN;
sprintf(string, "rxq%d_consumer_index", q_num);
@@ -678,6 +665,9 @@
sprintf(string, "rxq%d_allocbuf_failed",
q_num);
string += ETH_GSTRING_LEN;
+ sprintf(string, "rxq%d_mapbuf_failed",
+ q_num);
+ string += ETH_GSTRING_LEN;
sprintf(string, "rxq%d_producer_index",
q_num);
string += ETH_GSTRING_LEN;
@@ -854,9 +844,9 @@
u64 *buf)
{
struct bnad *bnad = netdev_priv(netdev);
- int i, j, bi;
+ int i, j, bi = 0;
unsigned long flags;
- struct rtnl_link_stats64 *net_stats64;
+ struct rtnl_link_stats64 net_stats64;
u64 *stats64;
u32 bmap;
@@ -871,14 +861,25 @@
* under the same lock
*/
spin_lock_irqsave(&bnad->bna_lock, flags);
- bi = 0;
- memset(buf, 0, stats->n_stats * sizeof(u64));
- net_stats64 = (struct rtnl_link_stats64 *)buf;
- bnad_netdev_qstats_fill(bnad, net_stats64);
- bnad_netdev_hwstats_fill(bnad, net_stats64);
+ memset(&net_stats64, 0, sizeof(net_stats64));
+ bnad_netdev_qstats_fill(bnad, &net_stats64);
+ bnad_netdev_hwstats_fill(bnad, &net_stats64);
- bi = sizeof(*net_stats64) / sizeof(u64);
+ buf[bi++] = net_stats64.rx_packets;
+ buf[bi++] = net_stats64.tx_packets;
+ buf[bi++] = net_stats64.rx_bytes;
+ buf[bi++] = net_stats64.tx_bytes;
+ buf[bi++] = net_stats64.rx_errors;
+ buf[bi++] = net_stats64.tx_errors;
+ buf[bi++] = net_stats64.rx_dropped;
+ buf[bi++] = net_stats64.tx_dropped;
+ buf[bi++] = net_stats64.multicast;
+ buf[bi++] = net_stats64.collisions;
+ buf[bi++] = net_stats64.rx_length_errors;
+ buf[bi++] = net_stats64.rx_crc_errors;
+ buf[bi++] = net_stats64.rx_frame_errors;
+ buf[bi++] = net_stats64.tx_fifo_errors;
/* Get netif_queue_stopped from stack */
bnad->stats.drv_stats.netif_queue_stopped = netif_queue_stopped(netdev);
diff --git a/drivers/net/ethernet/chelsio/cxgb4/cxgb4.h b/drivers/net/ethernet/chelsio/cxgb4/cxgb4.h
index 2e2aa9f..edd2338 100644
--- a/drivers/net/ethernet/chelsio/cxgb4/cxgb4.h
+++ b/drivers/net/ethernet/chelsio/cxgb4/cxgb4.h
@@ -419,8 +419,8 @@
unsigned short supported; /* link capabilities */
unsigned short advertising; /* advertised capabilities */
unsigned short lp_advertising; /* peer advertised capabilities */
- unsigned short requested_speed; /* speed user has requested */
- unsigned short speed; /* actual link speed */
+ unsigned int requested_speed; /* speed user has requested */
+ unsigned int speed; /* actual link speed */
unsigned char requested_fc; /* flow control user has requested */
unsigned char fc; /* actual link flow control */
unsigned char autoneg; /* autonegotiating? */
diff --git a/drivers/net/ethernet/chelsio/cxgb4/cxgb4_main.c b/drivers/net/ethernet/chelsio/cxgb4/cxgb4_main.c
index c762a8c..3ceafb55 100644
--- a/drivers/net/ethernet/chelsio/cxgb4/cxgb4_main.c
+++ b/drivers/net/ethernet/chelsio/cxgb4/cxgb4_main.c
@@ -4305,10 +4305,17 @@
.resume = eeh_resume,
};
+/* Return true if the Link Configuration supports "High Speeds" (those greater
+ * than 1Gb/s).
+ */
static inline bool is_x_10g_port(const struct link_config *lc)
{
- return (lc->supported & FW_PORT_CAP_SPEED_10G) != 0 ||
- (lc->supported & FW_PORT_CAP_SPEED_40G) != 0;
+ unsigned int speeds, high_speeds;
+
+ speeds = FW_PORT_CAP_SPEED_V(FW_PORT_CAP_SPEED_G(lc->supported));
+ high_speeds = speeds & ~(FW_PORT_CAP_SPEED_100M | FW_PORT_CAP_SPEED_1G);
+
+ return high_speeds != 0;
}
static inline void init_rspq(struct adapter *adap, struct sge_rspq *q,
@@ -4756,8 +4763,12 @@
bufp += sprintf(bufp, "1000/");
if (pi->link_cfg.supported & FW_PORT_CAP_SPEED_10G)
bufp += sprintf(bufp, "10G/");
+ if (pi->link_cfg.supported & FW_PORT_CAP_SPEED_25G)
+ bufp += sprintf(bufp, "25G/");
if (pi->link_cfg.supported & FW_PORT_CAP_SPEED_40G)
bufp += sprintf(bufp, "40G/");
+ if (pi->link_cfg.supported & FW_PORT_CAP_SPEED_100G)
+ bufp += sprintf(bufp, "100G/");
if (bufp != buf)
--bufp;
sprintf(bufp, "BASE-%s", t4_get_port_type_description(pi->port_type));
diff --git a/drivers/net/ethernet/chelsio/cxgb4/t4_hw.c b/drivers/net/ethernet/chelsio/cxgb4/t4_hw.c
index dc92c80..660204b 100644
--- a/drivers/net/ethernet/chelsio/cxgb4/t4_hw.c
+++ b/drivers/net/ethernet/chelsio/cxgb4/t4_hw.c
@@ -3627,7 +3627,8 @@
}
#define ADVERT_MASK (FW_PORT_CAP_SPEED_100M | FW_PORT_CAP_SPEED_1G |\
- FW_PORT_CAP_SPEED_10G | FW_PORT_CAP_SPEED_40G | \
+ FW_PORT_CAP_SPEED_10G | FW_PORT_CAP_SPEED_25G | \
+ FW_PORT_CAP_SPEED_40G | FW_PORT_CAP_SPEED_100G | \
FW_PORT_CAP_ANEG)
/**
@@ -7196,8 +7197,12 @@
speed = 1000;
else if (stat & FW_PORT_CMD_LSPEED_V(FW_PORT_CAP_SPEED_10G))
speed = 10000;
+ else if (stat & FW_PORT_CMD_LSPEED_V(FW_PORT_CAP_SPEED_25G))
+ speed = 25000;
else if (stat & FW_PORT_CMD_LSPEED_V(FW_PORT_CAP_SPEED_40G))
speed = 40000;
+ else if (stat & FW_PORT_CMD_LSPEED_V(FW_PORT_CAP_SPEED_100G))
+ speed = 100000;
lc = &pi->link_cfg;
diff --git a/drivers/net/ethernet/chelsio/cxgb4/t4fw_api.h b/drivers/net/ethernet/chelsio/cxgb4/t4fw_api.h
index a89b307..30507d4 100644
--- a/drivers/net/ethernet/chelsio/cxgb4/t4fw_api.h
+++ b/drivers/net/ethernet/chelsio/cxgb4/t4fw_api.h
@@ -2265,6 +2265,12 @@
FW_PORT_CAP_802_3_ASM_DIR = 0x8000,
};
+#define FW_PORT_CAP_SPEED_S 0
+#define FW_PORT_CAP_SPEED_M 0x3f
+#define FW_PORT_CAP_SPEED_V(x) ((x) << FW_PORT_CAP_SPEED_S)
+#define FW_PORT_CAP_SPEED_G(x) \
+ (((x) >> FW_PORT_CAP_SPEED_S) & FW_PORT_CAP_SPEED_M)
+
enum fw_port_mdi {
FW_PORT_CAP_MDI_UNCHANGED,
FW_PORT_CAP_MDI_AUTO,
diff --git a/drivers/net/ethernet/chelsio/cxgb4vf/t4vf_common.h b/drivers/net/ethernet/chelsio/cxgb4vf/t4vf_common.h
index 8ee5414..17a2bbc 100644
--- a/drivers/net/ethernet/chelsio/cxgb4vf/t4vf_common.h
+++ b/drivers/net/ethernet/chelsio/cxgb4vf/t4vf_common.h
@@ -108,8 +108,8 @@
unsigned int supported; /* link capabilities */
unsigned int advertising; /* advertised capabilities */
unsigned short lp_advertising; /* peer advertised capabilities */
- unsigned short requested_speed; /* speed user has requested */
- unsigned short speed; /* actual link speed */
+ unsigned int requested_speed; /* speed user has requested */
+ unsigned int speed; /* actual link speed */
unsigned char requested_fc; /* flow control user has requested */
unsigned char fc; /* actual link flow control */
unsigned char autoneg; /* autonegotiating? */
@@ -271,10 +271,17 @@
return (lc->supported & FW_PORT_CAP_SPEED_10G) != 0;
}
+/* Return true if the Link Configuration supports "High Speeds" (those greater
+ * than 1Gb/s).
+ */
static inline bool is_x_10g_port(const struct link_config *lc)
{
- return (lc->supported & FW_PORT_CAP_SPEED_10G) != 0 ||
- (lc->supported & FW_PORT_CAP_SPEED_40G) != 0;
+ unsigned int speeds, high_speeds;
+
+ speeds = FW_PORT_CAP_SPEED_V(FW_PORT_CAP_SPEED_G(lc->supported));
+ high_speeds = speeds & ~(FW_PORT_CAP_SPEED_100M | FW_PORT_CAP_SPEED_1G);
+
+ return high_speeds != 0;
}
static inline unsigned int core_ticks_per_usec(const struct adapter *adapter)
diff --git a/drivers/net/ethernet/chelsio/cxgb4vf/t4vf_hw.c b/drivers/net/ethernet/chelsio/cxgb4vf/t4vf_hw.c
index 427bfa7..b5622b1 100644
--- a/drivers/net/ethernet/chelsio/cxgb4vf/t4vf_hw.c
+++ b/drivers/net/ethernet/chelsio/cxgb4vf/t4vf_hw.c
@@ -314,8 +314,9 @@
}
#define ADVERT_MASK (FW_PORT_CAP_SPEED_100M | FW_PORT_CAP_SPEED_1G |\
- FW_PORT_CAP_SPEED_10G | FW_PORT_CAP_SPEED_40G | \
- FW_PORT_CAP_SPEED_100G | FW_PORT_CAP_ANEG)
+ FW_PORT_CAP_SPEED_10G | FW_PORT_CAP_SPEED_25G | \
+ FW_PORT_CAP_SPEED_40G | FW_PORT_CAP_SPEED_100G | \
+ FW_PORT_CAP_ANEG)
/**
* init_link_config - initialize a link's SW state
@@ -1712,8 +1713,12 @@
speed = 1000;
else if (stat & FW_PORT_CMD_LSPEED_V(FW_PORT_CAP_SPEED_10G))
speed = 10000;
+ else if (stat & FW_PORT_CMD_LSPEED_V(FW_PORT_CAP_SPEED_25G))
+ speed = 25000;
else if (stat & FW_PORT_CMD_LSPEED_V(FW_PORT_CAP_SPEED_40G))
speed = 40000;
+ else if (stat & FW_PORT_CMD_LSPEED_V(FW_PORT_CAP_SPEED_100G))
+ speed = 100000;
/*
* Scan all of our "ports" (Virtual Interfaces) looking for
diff --git a/drivers/net/ethernet/freescale/fec_main.c b/drivers/net/ethernet/freescale/fec_main.c
index 01f7e81..692ee24 100644
--- a/drivers/net/ethernet/freescale/fec_main.c
+++ b/drivers/net/ethernet/freescale/fec_main.c
@@ -89,10 +89,10 @@
.driver_data = 0,
}, {
.name = "imx25-fec",
- .driver_data = FEC_QUIRK_USE_GASKET | FEC_QUIRK_HAS_RACC,
+ .driver_data = FEC_QUIRK_USE_GASKET,
}, {
.name = "imx27-fec",
- .driver_data = FEC_QUIRK_HAS_RACC,
+ .driver_data = 0,
}, {
.name = "imx28-fec",
.driver_data = FEC_QUIRK_ENET_MAC | FEC_QUIRK_SWAP_FRAME |
@@ -180,6 +180,7 @@
/* FEC receive acceleration */
#define FEC_RACC_IPDIS (1 << 1)
#define FEC_RACC_PRODIS (1 << 2)
+#define FEC_RACC_SHIFT16 BIT(7)
#define FEC_RACC_OPTIONS (FEC_RACC_IPDIS | FEC_RACC_PRODIS)
/*
@@ -945,9 +946,11 @@
#if !defined(CONFIG_M5272)
if (fep->quirks & FEC_QUIRK_HAS_RACC) {
- /* set RX checksum */
val = readl(fep->hwp + FEC_RACC);
+ /* align IP header */
+ val |= FEC_RACC_SHIFT16;
if (fep->csum_flags & FLAG_RX_CSUM_ENABLED)
+ /* set RX checksum */
val |= FEC_RACC_OPTIONS;
else
val &= ~FEC_RACC_OPTIONS;
@@ -1428,6 +1431,12 @@
prefetch(skb->data - NET_IP_ALIGN);
skb_put(skb, pkt_len - 4);
data = skb->data;
+
+#if !defined(CONFIG_M5272)
+ if (fep->quirks & FEC_QUIRK_HAS_RACC)
+ data = skb_pull_inline(skb, 2);
+#endif
+
if (!is_copybreak && need_swap)
swap_buffer(data, pkt_len);
diff --git a/drivers/net/ethernet/ibm/emac/core.c b/drivers/net/ethernet/ibm/emac/core.c
index 4c9771d..7af09cb 100644
--- a/drivers/net/ethernet/ibm/emac/core.c
+++ b/drivers/net/ethernet/ibm/emac/core.c
@@ -977,7 +977,37 @@
dev->mcast_pending = 1;
return;
}
+
+ mutex_lock(&dev->link_lock);
__emac_set_multicast_list(dev);
+ mutex_unlock(&dev->link_lock);
+}
+
+static int emac_set_mac_address(struct net_device *ndev, void *sa)
+{
+ struct emac_instance *dev = netdev_priv(ndev);
+ struct sockaddr *addr = sa;
+ struct emac_regs __iomem *p = dev->emacp;
+
+ if (!is_valid_ether_addr(addr->sa_data))
+ return -EADDRNOTAVAIL;
+
+ mutex_lock(&dev->link_lock);
+
+ memcpy(ndev->dev_addr, addr->sa_data, ndev->addr_len);
+
+ emac_rx_disable(dev);
+ emac_tx_disable(dev);
+ out_be32(&p->iahr, (ndev->dev_addr[0] << 8) | ndev->dev_addr[1]);
+ out_be32(&p->ialr, (ndev->dev_addr[2] << 24) |
+ (ndev->dev_addr[3] << 16) | (ndev->dev_addr[4] << 8) |
+ ndev->dev_addr[5]);
+ emac_tx_enable(dev);
+ emac_rx_enable(dev);
+
+ mutex_unlock(&dev->link_lock);
+
+ return 0;
}
static int emac_resize_rx_ring(struct emac_instance *dev, int new_mtu)
@@ -2686,7 +2716,7 @@
.ndo_do_ioctl = emac_ioctl,
.ndo_tx_timeout = emac_tx_timeout,
.ndo_validate_addr = eth_validate_addr,
- .ndo_set_mac_address = eth_mac_addr,
+ .ndo_set_mac_address = emac_set_mac_address,
.ndo_start_xmit = emac_start_xmit,
.ndo_change_mtu = eth_change_mtu,
};
@@ -2699,7 +2729,7 @@
.ndo_do_ioctl = emac_ioctl,
.ndo_tx_timeout = emac_tx_timeout,
.ndo_validate_addr = eth_validate_addr,
- .ndo_set_mac_address = eth_mac_addr,
+ .ndo_set_mac_address = emac_set_mac_address,
.ndo_start_xmit = emac_start_xmit_sg,
.ndo_change_mtu = emac_change_mtu,
};
diff --git a/drivers/net/ethernet/mediatek/mtk_eth_soc.c b/drivers/net/ethernet/mediatek/mtk_eth_soc.c
index d919915..3743af8 100644
--- a/drivers/net/ethernet/mediatek/mtk_eth_soc.c
+++ b/drivers/net/ethernet/mediatek/mtk_eth_soc.c
@@ -1923,6 +1923,7 @@
{ .compatible = "mediatek,mt7623-eth" },
{},
};
+MODULE_DEVICE_TABLE(of, of_mtk_match);
static struct platform_driver mtk_driver = {
.probe = mtk_probe,
diff --git a/drivers/net/ethernet/mellanox/mlx4/eq.c b/drivers/net/ethernet/mellanox/mlx4/eq.c
index f613977..cf8f8a7 100644
--- a/drivers/net/ethernet/mellanox/mlx4/eq.c
+++ b/drivers/net/ethernet/mellanox/mlx4/eq.c
@@ -1305,8 +1305,8 @@
return 0;
err_out_unmap:
- while (i >= 0)
- mlx4_free_eq(dev, &priv->eq_table.eq[i--]);
+ while (i > 0)
+ mlx4_free_eq(dev, &priv->eq_table.eq[--i]);
#ifdef CONFIG_RFS_ACCEL
for (i = 1; i <= dev->caps.num_ports; i++) {
if (mlx4_priv(dev)->port[i].rmap) {
diff --git a/drivers/net/ethernet/mellanox/mlx4/main.c b/drivers/net/ethernet/mellanox/mlx4/main.c
index 75dd2e3..7183ac4 100644
--- a/drivers/net/ethernet/mellanox/mlx4/main.c
+++ b/drivers/net/ethernet/mellanox/mlx4/main.c
@@ -2970,6 +2970,7 @@
mlx4_err(dev, "Failed to create mtu file for port %d\n", port);
device_remove_file(&info->dev->persist->pdev->dev,
&info->port_attr);
+ devlink_port_unregister(&info->devlink_port);
info->port = -1;
}
@@ -2984,6 +2985,8 @@
device_remove_file(&info->dev->persist->pdev->dev, &info->port_attr);
device_remove_file(&info->dev->persist->pdev->dev,
&info->port_mtu_attr);
+ devlink_port_unregister(&info->devlink_port);
+
#ifdef CONFIG_RFS_ACCEL
free_irq_cpu_rmap(info->rmap);
info->rmap = NULL;
diff --git a/drivers/net/ethernet/mellanox/mlx5/core/eswitch.c b/drivers/net/ethernet/mellanox/mlx5/core/eswitch.c
index 8b78f15..b247949 100644
--- a/drivers/net/ethernet/mellanox/mlx5/core/eswitch.c
+++ b/drivers/net/ethernet/mellanox/mlx5/core/eswitch.c
@@ -1554,6 +1554,7 @@
abort:
esw_enable_vport(esw, 0, UC_ADDR_CHANGE);
+ esw->mode = SRIOV_NONE;
return err;
}
diff --git a/drivers/net/ethernet/mellanox/mlx5/core/eswitch_offloads.c b/drivers/net/ethernet/mellanox/mlx5/core/eswitch_offloads.c
index 3dc83a9..7de40e6 100644
--- a/drivers/net/ethernet/mellanox/mlx5/core/eswitch_offloads.c
+++ b/drivers/net/ethernet/mellanox/mlx5/core/eswitch_offloads.c
@@ -446,7 +446,7 @@
static int esw_offloads_start(struct mlx5_eswitch *esw)
{
- int err, num_vfs = esw->dev->priv.sriov.num_vfs;
+ int err, err1, num_vfs = esw->dev->priv.sriov.num_vfs;
if (esw->mode != SRIOV_LEGACY) {
esw_warn(esw->dev, "Can't set offloads mode, SRIOV legacy not enabled\n");
@@ -455,8 +455,12 @@
mlx5_eswitch_disable_sriov(esw);
err = mlx5_eswitch_enable_sriov(esw, num_vfs, SRIOV_OFFLOADS);
- if (err)
- esw_warn(esw->dev, "Failed set eswitch to offloads, err %d\n", err);
+ if (err) {
+ esw_warn(esw->dev, "Failed setting eswitch to offloads, err %d\n", err);
+ err1 = mlx5_eswitch_enable_sriov(esw, num_vfs, SRIOV_LEGACY);
+ if (err1)
+ esw_warn(esw->dev, "Failed setting eswitch back to legacy, err %d\n", err);
+ }
return err;
}
@@ -508,12 +512,16 @@
static int esw_offloads_stop(struct mlx5_eswitch *esw)
{
- int err, num_vfs = esw->dev->priv.sriov.num_vfs;
+ int err, err1, num_vfs = esw->dev->priv.sriov.num_vfs;
mlx5_eswitch_disable_sriov(esw);
err = mlx5_eswitch_enable_sriov(esw, num_vfs, SRIOV_LEGACY);
- if (err)
- esw_warn(esw->dev, "Failed set eswitch legacy mode. err %d\n", err);
+ if (err) {
+ esw_warn(esw->dev, "Failed setting eswitch to legacy, err %d\n", err);
+ err1 = mlx5_eswitch_enable_sriov(esw, num_vfs, SRIOV_OFFLOADS);
+ if (err1)
+ esw_warn(esw->dev, "Failed setting eswitch back to offloads, err %d\n", err);
+ }
return err;
}
diff --git a/drivers/net/ethernet/mellanox/mlx5/core/fs_cmd.c b/drivers/net/ethernet/mellanox/mlx5/core/fs_cmd.c
index 9134010..287ade1 100644
--- a/drivers/net/ethernet/mellanox/mlx5/core/fs_cmd.c
+++ b/drivers/net/ethernet/mellanox/mlx5/core/fs_cmd.c
@@ -425,11 +425,11 @@
mlx5_cmd_fc_bulk_alloc(struct mlx5_core_dev *dev, u16 id, int num)
{
struct mlx5_cmd_fc_bulk *b;
- int outlen = sizeof(*b) +
+ int outlen =
MLX5_ST_SZ_BYTES(query_flow_counter_out) +
MLX5_ST_SZ_BYTES(traffic_counter) * num;
- b = kzalloc(outlen, GFP_KERNEL);
+ b = kzalloc(sizeof(*b) + outlen, GFP_KERNEL);
if (!b)
return NULL;
diff --git a/drivers/net/ethernet/netronome/nfp/nfp_net_common.c b/drivers/net/ethernet/netronome/nfp/nfp_net_common.c
index 252e492..39dadfc 100644
--- a/drivers/net/ethernet/netronome/nfp/nfp_net_common.c
+++ b/drivers/net/ethernet/netronome/nfp/nfp_net_common.c
@@ -2044,12 +2044,16 @@
nn->rx_rings = kcalloc(nn->num_rx_rings, sizeof(*nn->rx_rings),
GFP_KERNEL);
- if (!nn->rx_rings)
+ if (!nn->rx_rings) {
+ err = -ENOMEM;
goto err_free_lsc;
+ }
nn->tx_rings = kcalloc(nn->num_tx_rings, sizeof(*nn->tx_rings),
GFP_KERNEL);
- if (!nn->tx_rings)
+ if (!nn->tx_rings) {
+ err = -ENOMEM;
goto err_free_rx_rings;
+ }
for (r = 0; r < nn->num_r_vecs; r++) {
err = nfp_net_prepare_vector(nn, &nn->r_vecs[r], r);
diff --git a/drivers/net/ethernet/qlogic/qed/qed_mcp.c b/drivers/net/ethernet/qlogic/qed/qed_mcp.c
index a240f26..f776a77 100644
--- a/drivers/net/ethernet/qlogic/qed/qed_mcp.c
+++ b/drivers/net/ethernet/qlogic/qed/qed_mcp.c
@@ -1153,8 +1153,8 @@
p_drv_version = &union_data.drv_version;
p_drv_version->version = p_ver->version;
- for (i = 0; i < MCP_DRV_VER_STR_SIZE - 1; i += 4) {
- val = cpu_to_be32(p_ver->name[i]);
+ for (i = 0; i < (MCP_DRV_VER_STR_SIZE - 4) / sizeof(u32); i++) {
+ val = cpu_to_be32(*((u32 *)&p_ver->name[i * sizeof(u32)]));
*(__be32 *)&p_drv_version->name[i * sizeof(u32)] = val;
}
diff --git a/drivers/net/ethernet/stmicro/stmmac/dwmac1000_core.c b/drivers/net/ethernet/stmicro/stmmac/dwmac1000_core.c
index cbefe9e..885a5e6 100644
--- a/drivers/net/ethernet/stmicro/stmmac/dwmac1000_core.c
+++ b/drivers/net/ethernet/stmicro/stmmac/dwmac1000_core.c
@@ -261,7 +261,7 @@
}
if (mode & WAKE_UCAST) {
pr_debug("GMAC: WOL on global unicast\n");
- pmt |= global_unicast;
+ pmt |= power_down | global_unicast | wake_up_frame_en;
}
writel(pmt, ioaddr + GMAC_PMT);
diff --git a/drivers/net/ethernet/stmicro/stmmac/dwmac4_core.c b/drivers/net/ethernet/stmicro/stmmac/dwmac4_core.c
index df5580d..51019b7 100644
--- a/drivers/net/ethernet/stmicro/stmmac/dwmac4_core.c
+++ b/drivers/net/ethernet/stmicro/stmmac/dwmac4_core.c
@@ -102,7 +102,7 @@
}
if (mode & WAKE_UCAST) {
pr_debug("GMAC: WOL on global unicast\n");
- pmt |= global_unicast;
+ pmt |= power_down | global_unicast | wake_up_frame_en;
}
writel(pmt, ioaddr + GMAC_PMT);
diff --git a/drivers/net/phy/mdio-xgene.c b/drivers/net/phy/mdio-xgene.c
index 7756748..92af182 100644
--- a/drivers/net/phy/mdio-xgene.c
+++ b/drivers/net/phy/mdio-xgene.c
@@ -424,10 +424,8 @@
mdiobus_unregister(mdio_bus);
mdiobus_free(mdio_bus);
- if (dev->of_node) {
- if (IS_ERR(pdata->clk))
- clk_disable_unprepare(pdata->clk);
- }
+ if (dev->of_node)
+ clk_disable_unprepare(pdata->clk);
return 0;
}
diff --git a/drivers/net/usb/r8152.c b/drivers/net/usb/r8152.c
index f41a8ad..c254248 100644
--- a/drivers/net/usb/r8152.c
+++ b/drivers/net/usb/r8152.c
@@ -32,7 +32,7 @@
#define NETNEXT_VERSION "08"
/* Information for net */
-#define NET_VERSION "5"
+#define NET_VERSION "6"
#define DRIVER_VERSION "v1." NETNEXT_VERSION "." NET_VERSION
#define DRIVER_AUTHOR "Realtek linux nic maintainers <nic_swsd@realtek.com>"
@@ -2552,6 +2552,77 @@
}
}
+static inline void r8152_mmd_indirect(struct r8152 *tp, u16 dev, u16 reg)
+{
+ ocp_reg_write(tp, OCP_EEE_AR, FUN_ADDR | dev);
+ ocp_reg_write(tp, OCP_EEE_DATA, reg);
+ ocp_reg_write(tp, OCP_EEE_AR, FUN_DATA | dev);
+}
+
+static u16 r8152_mmd_read(struct r8152 *tp, u16 dev, u16 reg)
+{
+ u16 data;
+
+ r8152_mmd_indirect(tp, dev, reg);
+ data = ocp_reg_read(tp, OCP_EEE_DATA);
+ ocp_reg_write(tp, OCP_EEE_AR, 0x0000);
+
+ return data;
+}
+
+static void r8152_mmd_write(struct r8152 *tp, u16 dev, u16 reg, u16 data)
+{
+ r8152_mmd_indirect(tp, dev, reg);
+ ocp_reg_write(tp, OCP_EEE_DATA, data);
+ ocp_reg_write(tp, OCP_EEE_AR, 0x0000);
+}
+
+static void r8152_eee_en(struct r8152 *tp, bool enable)
+{
+ u16 config1, config2, config3;
+ u32 ocp_data;
+
+ ocp_data = ocp_read_word(tp, MCU_TYPE_PLA, PLA_EEE_CR);
+ config1 = ocp_reg_read(tp, OCP_EEE_CONFIG1) & ~sd_rise_time_mask;
+ config2 = ocp_reg_read(tp, OCP_EEE_CONFIG2);
+ config3 = ocp_reg_read(tp, OCP_EEE_CONFIG3) & ~fast_snr_mask;
+
+ if (enable) {
+ ocp_data |= EEE_RX_EN | EEE_TX_EN;
+ config1 |= EEE_10_CAP | EEE_NWAY_EN | TX_QUIET_EN | RX_QUIET_EN;
+ config1 |= sd_rise_time(1);
+ config2 |= RG_DACQUIET_EN | RG_LDVQUIET_EN;
+ config3 |= fast_snr(42);
+ } else {
+ ocp_data &= ~(EEE_RX_EN | EEE_TX_EN);
+ config1 &= ~(EEE_10_CAP | EEE_NWAY_EN | TX_QUIET_EN |
+ RX_QUIET_EN);
+ config1 |= sd_rise_time(7);
+ config2 &= ~(RG_DACQUIET_EN | RG_LDVQUIET_EN);
+ config3 |= fast_snr(511);
+ }
+
+ ocp_write_word(tp, MCU_TYPE_PLA, PLA_EEE_CR, ocp_data);
+ ocp_reg_write(tp, OCP_EEE_CONFIG1, config1);
+ ocp_reg_write(tp, OCP_EEE_CONFIG2, config2);
+ ocp_reg_write(tp, OCP_EEE_CONFIG3, config3);
+}
+
+static void r8152b_enable_eee(struct r8152 *tp)
+{
+ r8152_eee_en(tp, true);
+ r8152_mmd_write(tp, MDIO_MMD_AN, MDIO_AN_EEE_ADV, MDIO_EEE_100TX);
+}
+
+static void r8152b_enable_fc(struct r8152 *tp)
+{
+ u16 anar;
+
+ anar = r8152_mdio_read(tp, MII_ADVERTISE);
+ anar |= ADVERTISE_PAUSE_CAP | ADVERTISE_PAUSE_ASYM;
+ r8152_mdio_write(tp, MII_ADVERTISE, anar);
+}
+
static void rtl8152_disable(struct r8152 *tp)
{
r8152_aldps_en(tp, false);
@@ -2561,13 +2632,9 @@
static void r8152b_hw_phy_cfg(struct r8152 *tp)
{
- u16 data;
-
- data = r8152_mdio_read(tp, MII_BMCR);
- if (data & BMCR_PDOWN) {
- data &= ~BMCR_PDOWN;
- r8152_mdio_write(tp, MII_BMCR, data);
- }
+ r8152b_enable_eee(tp);
+ r8152_aldps_en(tp, true);
+ r8152b_enable_fc(tp);
set_bit(PHY_RESET, &tp->flags);
}
@@ -2701,20 +2768,52 @@
ocp_write_dword(tp, MCU_TYPE_PLA, PLA_RCR, ocp_data);
}
+static void r8153_aldps_en(struct r8152 *tp, bool enable)
+{
+ u16 data;
+
+ data = ocp_reg_read(tp, OCP_POWER_CFG);
+ if (enable) {
+ data |= EN_ALDPS;
+ ocp_reg_write(tp, OCP_POWER_CFG, data);
+ } else {
+ data &= ~EN_ALDPS;
+ ocp_reg_write(tp, OCP_POWER_CFG, data);
+ msleep(20);
+ }
+}
+
+static void r8153_eee_en(struct r8152 *tp, bool enable)
+{
+ u32 ocp_data;
+ u16 config;
+
+ ocp_data = ocp_read_word(tp, MCU_TYPE_PLA, PLA_EEE_CR);
+ config = ocp_reg_read(tp, OCP_EEE_CFG);
+
+ if (enable) {
+ ocp_data |= EEE_RX_EN | EEE_TX_EN;
+ config |= EEE10_EN;
+ } else {
+ ocp_data &= ~(EEE_RX_EN | EEE_TX_EN);
+ config &= ~EEE10_EN;
+ }
+
+ ocp_write_word(tp, MCU_TYPE_PLA, PLA_EEE_CR, ocp_data);
+ ocp_reg_write(tp, OCP_EEE_CFG, config);
+}
+
static void r8153_hw_phy_cfg(struct r8152 *tp)
{
u32 ocp_data;
u16 data;
- if (tp->version == RTL_VER_03 || tp->version == RTL_VER_04 ||
- tp->version == RTL_VER_05)
- ocp_reg_write(tp, OCP_ADC_CFG, CKADSEL_L | ADC_EN | EN_EMI_L);
+ /* disable ALDPS before updating the PHY parameters */
+ r8153_aldps_en(tp, false);
- data = r8152_mdio_read(tp, MII_BMCR);
- if (data & BMCR_PDOWN) {
- data &= ~BMCR_PDOWN;
- r8152_mdio_write(tp, MII_BMCR, data);
- }
+ /* disable EEE before updating the PHY parameters */
+ r8153_eee_en(tp, false);
+ ocp_reg_write(tp, OCP_EEE_ADV, 0);
if (tp->version == RTL_VER_03) {
data = ocp_reg_read(tp, OCP_EEE_CFG);
@@ -2745,6 +2844,12 @@
sram_write(tp, SRAM_10M_AMP1, 0x00af);
sram_write(tp, SRAM_10M_AMP2, 0x0208);
+ r8153_eee_en(tp, true);
+ ocp_reg_write(tp, OCP_EEE_ADV, MDIO_EEE_1000T | MDIO_EEE_100TX);
+
+ r8153_aldps_en(tp, true);
+ r8152b_enable_fc(tp);
+
set_bit(PHY_RESET, &tp->flags);
}
@@ -2866,21 +2971,6 @@
ocp_write_dword(tp, MCU_TYPE_PLA, PLA_RCR, ocp_data);
}
-static void r8153_aldps_en(struct r8152 *tp, bool enable)
-{
- u16 data;
-
- data = ocp_reg_read(tp, OCP_POWER_CFG);
- if (enable) {
- data |= EN_ALDPS;
- ocp_reg_write(tp, OCP_POWER_CFG, data);
- } else {
- data &= ~EN_ALDPS;
- ocp_reg_write(tp, OCP_POWER_CFG, data);
- msleep(20);
- }
-}
-
static void rtl8153_disable(struct r8152 *tp)
{
r8153_aldps_en(tp, false);
@@ -3246,103 +3336,6 @@
return res;
}
-static inline void r8152_mmd_indirect(struct r8152 *tp, u16 dev, u16 reg)
-{
- ocp_reg_write(tp, OCP_EEE_AR, FUN_ADDR | dev);
- ocp_reg_write(tp, OCP_EEE_DATA, reg);
- ocp_reg_write(tp, OCP_EEE_AR, FUN_DATA | dev);
-}
-
-static u16 r8152_mmd_read(struct r8152 *tp, u16 dev, u16 reg)
-{
- u16 data;
-
- r8152_mmd_indirect(tp, dev, reg);
- data = ocp_reg_read(tp, OCP_EEE_DATA);
- ocp_reg_write(tp, OCP_EEE_AR, 0x0000);
-
- return data;
-}
-
-static void r8152_mmd_write(struct r8152 *tp, u16 dev, u16 reg, u16 data)
-{
- r8152_mmd_indirect(tp, dev, reg);
- ocp_reg_write(tp, OCP_EEE_DATA, data);
- ocp_reg_write(tp, OCP_EEE_AR, 0x0000);
-}
-
-static void r8152_eee_en(struct r8152 *tp, bool enable)
-{
- u16 config1, config2, config3;
- u32 ocp_data;
-
- ocp_data = ocp_read_word(tp, MCU_TYPE_PLA, PLA_EEE_CR);
- config1 = ocp_reg_read(tp, OCP_EEE_CONFIG1) & ~sd_rise_time_mask;
- config2 = ocp_reg_read(tp, OCP_EEE_CONFIG2);
- config3 = ocp_reg_read(tp, OCP_EEE_CONFIG3) & ~fast_snr_mask;
-
- if (enable) {
- ocp_data |= EEE_RX_EN | EEE_TX_EN;
- config1 |= EEE_10_CAP | EEE_NWAY_EN | TX_QUIET_EN | RX_QUIET_EN;
- config1 |= sd_rise_time(1);
- config2 |= RG_DACQUIET_EN | RG_LDVQUIET_EN;
- config3 |= fast_snr(42);
- } else {
- ocp_data &= ~(EEE_RX_EN | EEE_TX_EN);
- config1 &= ~(EEE_10_CAP | EEE_NWAY_EN | TX_QUIET_EN |
- RX_QUIET_EN);
- config1 |= sd_rise_time(7);
- config2 &= ~(RG_DACQUIET_EN | RG_LDVQUIET_EN);
- config3 |= fast_snr(511);
- }
-
- ocp_write_word(tp, MCU_TYPE_PLA, PLA_EEE_CR, ocp_data);
- ocp_reg_write(tp, OCP_EEE_CONFIG1, config1);
- ocp_reg_write(tp, OCP_EEE_CONFIG2, config2);
- ocp_reg_write(tp, OCP_EEE_CONFIG3, config3);
-}
-
-static void r8152b_enable_eee(struct r8152 *tp)
-{
- r8152_eee_en(tp, true);
- r8152_mmd_write(tp, MDIO_MMD_AN, MDIO_AN_EEE_ADV, MDIO_EEE_100TX);
-}
-
-static void r8153_eee_en(struct r8152 *tp, bool enable)
-{
- u32 ocp_data;
- u16 config;
-
- ocp_data = ocp_read_word(tp, MCU_TYPE_PLA, PLA_EEE_CR);
- config = ocp_reg_read(tp, OCP_EEE_CFG);
-
- if (enable) {
- ocp_data |= EEE_RX_EN | EEE_TX_EN;
- config |= EEE10_EN;
- } else {
- ocp_data &= ~(EEE_RX_EN | EEE_TX_EN);
- config &= ~EEE10_EN;
- }
-
- ocp_write_word(tp, MCU_TYPE_PLA, PLA_EEE_CR, ocp_data);
- ocp_reg_write(tp, OCP_EEE_CFG, config);
-}
-
-static void r8153_enable_eee(struct r8152 *tp)
-{
- r8153_eee_en(tp, true);
- ocp_reg_write(tp, OCP_EEE_ADV, MDIO_EEE_1000T | MDIO_EEE_100TX);
-}
-
-static void r8152b_enable_fc(struct r8152 *tp)
-{
- u16 anar;
-
- anar = r8152_mdio_read(tp, MII_ADVERTISE);
- anar |= ADVERTISE_PAUSE_CAP | ADVERTISE_PAUSE_ASYM;
- r8152_mdio_write(tp, MII_ADVERTISE, anar);
-}
-
static void rtl_tally_reset(struct r8152 *tp)
{
u32 ocp_data;
@@ -3355,10 +3348,17 @@
static void r8152b_init(struct r8152 *tp)
{
u32 ocp_data;
+ u16 data;
if (test_bit(RTL8152_UNPLUG, &tp->flags))
return;
+ data = r8152_mdio_read(tp, MII_BMCR);
+ if (data & BMCR_PDOWN) {
+ data &= ~BMCR_PDOWN;
+ r8152_mdio_write(tp, MII_BMCR, data);
+ }
+
r8152_aldps_en(tp, false);
if (tp->version == RTL_VER_01) {
@@ -3380,9 +3380,6 @@
SPDWN_RXDV_MSK | SPDWN_LINKCHG_MSK;
ocp_write_word(tp, MCU_TYPE_PLA, PLA_GPHY_INTR_IMR, ocp_data);
- r8152b_enable_eee(tp);
- r8152_aldps_en(tp, true);
- r8152b_enable_fc(tp);
rtl_tally_reset(tp);
/* enable rx aggregation */
@@ -3394,12 +3391,12 @@
static void r8153_init(struct r8152 *tp)
{
u32 ocp_data;
+ u16 data;
int i;
if (test_bit(RTL8152_UNPLUG, &tp->flags))
return;
- r8153_aldps_en(tp, false);
r8153_u1u2en(tp, false);
for (i = 0; i < 500; i++) {
@@ -3416,6 +3413,23 @@
msleep(20);
}
+ if (tp->version == RTL_VER_03 || tp->version == RTL_VER_04 ||
+ tp->version == RTL_VER_05)
+ ocp_reg_write(tp, OCP_ADC_CFG, CKADSEL_L | ADC_EN | EN_EMI_L);
+
+ data = r8152_mdio_read(tp, MII_BMCR);
+ if (data & BMCR_PDOWN) {
+ data &= ~BMCR_PDOWN;
+ r8152_mdio_write(tp, MII_BMCR, data);
+ }
+
+ for (i = 0; i < 500; i++) {
+ ocp_data = ocp_reg_read(tp, OCP_PHY_STATUS) & PHY_STAT_MASK;
+ if (ocp_data == PHY_STAT_LAN_ON)
+ break;
+ msleep(20);
+ }
+
usb_disable_lpm(tp->udev);
r8153_u2p3en(tp, false);
@@ -3483,9 +3497,6 @@
ocp_write_word(tp, MCU_TYPE_PLA, PLA_MAC_PWR_CTRL3, 0);
ocp_write_word(tp, MCU_TYPE_PLA, PLA_MAC_PWR_CTRL4, 0);
- r8153_enable_eee(tp);
- r8153_aldps_en(tp, true);
- r8152b_enable_fc(tp);
rtl_tally_reset(tp);
r8153_u2p3en(tp, true);
}
diff --git a/drivers/net/wireless/intel/iwlwifi/mvm/tx.c b/drivers/net/wireless/intel/iwlwifi/mvm/tx.c
index c6585ab..b3a87a3 100644
--- a/drivers/net/wireless/intel/iwlwifi/mvm/tx.c
+++ b/drivers/net/wireless/intel/iwlwifi/mvm/tx.c
@@ -513,6 +513,15 @@
int hdrlen = ieee80211_hdrlen(hdr->frame_control);
int queue;
+ /* IWL_MVM_OFFCHANNEL_QUEUE is used for ROC packets that can be used
+ * in 2 different types of vifs, P2P & STATION. P2P uses the offchannel
+ * queue. STATION (HS2.0) uses the auxiliary context of the FW,
+ * and hence needs to be sent on the aux queue
+ */
+ if (IEEE80211_SKB_CB(skb)->hw_queue == IWL_MVM_OFFCHANNEL_QUEUE &&
+ skb_info->control.vif->type == NL80211_IFTYPE_STATION)
+ IEEE80211_SKB_CB(skb)->hw_queue = mvm->aux_queue;
+
memcpy(&info, skb->cb, sizeof(info));
if (WARN_ON_ONCE(info.flags & IEEE80211_TX_CTL_AMPDU))
@@ -526,16 +535,6 @@
/* This holds the amsdu headers length */
skb_info->driver_data[0] = (void *)(uintptr_t)0;
- /*
- * IWL_MVM_OFFCHANNEL_QUEUE is used for ROC packets that can be used
- * in 2 different types of vifs, P2P & STATION. P2P uses the offchannel
- * queue. STATION (HS2.0) uses the auxiliary context of the FW,
- * and hence needs to be sent on the aux queue
- */
- if (IEEE80211_SKB_CB(skb)->hw_queue == IWL_MVM_OFFCHANNEL_QUEUE &&
- info.control.vif->type == NL80211_IFTYPE_STATION)
- IEEE80211_SKB_CB(skb)->hw_queue = mvm->aux_queue;
-
queue = info.hw_queue;
/*
diff --git a/drivers/net/xen-netback/xenbus.c b/drivers/net/xen-netback/xenbus.c
index 6a31f26..daf4c78 100644
--- a/drivers/net/xen-netback/xenbus.c
+++ b/drivers/net/xen-netback/xenbus.c
@@ -271,6 +271,11 @@
be->dev = dev;
dev_set_drvdata(&dev->dev, be);
+ be->state = XenbusStateInitialising;
+ err = xenbus_switch_state(dev, XenbusStateInitialising);
+ if (err)
+ goto fail;
+
sg = 1;
do {
@@ -383,11 +388,6 @@
be->hotplug_script = script;
- err = xenbus_switch_state(dev, XenbusStateInitWait);
- if (err)
- goto fail;
-
- be->state = XenbusStateInitWait;
/* This kicks hotplug scripts, so do it immediately. */
err = backend_create_xenvif(be);
@@ -492,20 +492,20 @@
/* Handle backend state transitions:
*
- * The backend state starts in InitWait and the following transitions are
+ * The backend state starts in Initialising and the following transitions are
* allowed.
*
- * InitWait -> Connected
+ * Initialising -> InitWait -> Connected
+ * \
+ * \ ^ \ |
+ * \ | \ |
+ * \ | \ |
+ * \ | \ |
+ * \ | \ |
+ * \ | \ |
+ * V | V V
*
- * ^ \ |
- * | \ |
- * | \ |
- * | \ |
- * | \ |
- * | \ |
- * | V V
- *
- * Closed <-> Closing
+ * Closed <-> Closing
*
* The state argument specifies the eventual state of the backend and the
* function transitions to that state via the shortest path.
@@ -515,6 +515,20 @@
{
while (be->state != state) {
switch (be->state) {
+ case XenbusStateInitialising:
+ switch (state) {
+ case XenbusStateInitWait:
+ case XenbusStateConnected:
+ case XenbusStateClosing:
+ backend_switch_state(be, XenbusStateInitWait);
+ break;
+ case XenbusStateClosed:
+ backend_switch_state(be, XenbusStateClosed);
+ break;
+ default:
+ BUG();
+ }
+ break;
case XenbusStateClosed:
switch (state) {
case XenbusStateInitWait:
diff --git a/drivers/nvdimm/core.c b/drivers/nvdimm/core.c
index 715583f..4d7bbd2 100644
--- a/drivers/nvdimm/core.c
+++ b/drivers/nvdimm/core.c
@@ -99,8 +99,11 @@
nvdimm_map->size = size;
kref_init(&nvdimm_map->kref);
- if (!request_mem_region(offset, size, dev_name(&nvdimm_bus->dev)))
+ if (!request_mem_region(offset, size, dev_name(&nvdimm_bus->dev))) {
+ dev_err(&nvdimm_bus->dev, "failed to request %pa + %zd for %s\n",
+ &offset, size, dev_name(dev));
goto err_request_region;
+ }
if (flags)
nvdimm_map->mem = memremap(offset, size, flags);
@@ -171,6 +174,9 @@
kref_get(&nvdimm_map->kref);
nvdimm_bus_unlock(dev);
+ if (!nvdimm_map)
+ return NULL;
+
if (devm_add_action_or_reset(dev, nvdimm_map_put, nvdimm_map))
return NULL;
diff --git a/drivers/nvdimm/nd.h b/drivers/nvdimm/nd.h
index 8024a0e..0b78a82 100644
--- a/drivers/nvdimm/nd.h
+++ b/drivers/nvdimm/nd.h
@@ -52,10 +52,28 @@
struct nd_region_data {
int ns_count;
int ns_active;
- unsigned int flush_mask;
- void __iomem *flush_wpq[0][0];
+ unsigned int hints_shift;
+ void __iomem *flush_wpq[0];
};
+static inline void __iomem *ndrd_get_flush_wpq(struct nd_region_data *ndrd,
+ int dimm, int hint)
+{
+ unsigned int num = 1 << ndrd->hints_shift;
+ unsigned int mask = num - 1;
+
+ return ndrd->flush_wpq[dimm * num + (hint & mask)];
+}
+
+static inline void ndrd_set_flush_wpq(struct nd_region_data *ndrd, int dimm,
+ int hint, void __iomem *flush)
+{
+ unsigned int num = 1 << ndrd->hints_shift;
+ unsigned int mask = num - 1;
+
+ ndrd->flush_wpq[dimm * num + (hint & mask)] = flush;
+}
+
static inline struct nd_namespace_index *to_namespace_index(
struct nvdimm_drvdata *ndd, int i)
{
diff --git a/drivers/nvdimm/region_devs.c b/drivers/nvdimm/region_devs.c
index e8d5ba7..4c0ac4a 100644
--- a/drivers/nvdimm/region_devs.c
+++ b/drivers/nvdimm/region_devs.c
@@ -38,7 +38,7 @@
dev_dbg(dev, "%s: map %d flush address%s\n", nvdimm_name(nvdimm),
nvdimm->num_flush, nvdimm->num_flush == 1 ? "" : "es");
- for (i = 0; i < nvdimm->num_flush; i++) {
+ for (i = 0; i < (1 << ndrd->hints_shift); i++) {
struct resource *res = &nvdimm->flush_wpq[i];
unsigned long pfn = PHYS_PFN(res->start);
void __iomem *flush_page;
@@ -54,14 +54,15 @@
if (j < i)
flush_page = (void __iomem *) ((unsigned long)
- ndrd->flush_wpq[dimm][j] & PAGE_MASK);
+ ndrd_get_flush_wpq(ndrd, dimm, j)
+ & PAGE_MASK);
else
flush_page = devm_nvdimm_ioremap(dev,
- PHYS_PFN(pfn), PAGE_SIZE);
+ PFN_PHYS(pfn), PAGE_SIZE);
if (!flush_page)
return -ENXIO;
- ndrd->flush_wpq[dimm][i] = flush_page
- + (res->start & ~PAGE_MASK);
+ ndrd_set_flush_wpq(ndrd, dimm, i, flush_page
+ + (res->start & ~PAGE_MASK));
}
return 0;
@@ -93,7 +94,10 @@
return -ENOMEM;
dev_set_drvdata(dev, ndrd);
- ndrd->flush_mask = (1 << ilog2(num_flush)) - 1;
+ if (!num_flush)
+ return 0;
+
+ ndrd->hints_shift = ilog2(num_flush);
for (i = 0; i < nd_region->ndr_mappings; i++) {
struct nd_mapping *nd_mapping = &nd_region->mapping[i];
struct nvdimm *nvdimm = nd_mapping->nvdimm;
@@ -900,8 +904,8 @@
*/
wmb();
for (i = 0; i < nd_region->ndr_mappings; i++)
- if (ndrd->flush_wpq[i][0])
- writeq(1, ndrd->flush_wpq[i][idx & ndrd->flush_mask]);
+ if (ndrd_get_flush_wpq(ndrd, i, 0))
+ writeq(1, ndrd_get_flush_wpq(ndrd, i, idx));
wmb();
}
EXPORT_SYMBOL_GPL(nvdimm_flush);
@@ -925,7 +929,7 @@
for (i = 0; i < nd_region->ndr_mappings; i++)
/* flush hints present, flushing required */
- if (ndrd->flush_wpq[i][0])
+ if (ndrd_get_flush_wpq(ndrd, i, 0))
return 1;
/*
diff --git a/drivers/nvme/host/rdma.c b/drivers/nvme/host/rdma.c
index c2c2c28..fbdb226 100644
--- a/drivers/nvme/host/rdma.c
+++ b/drivers/nvme/host/rdma.c
@@ -561,7 +561,6 @@
queue = &ctrl->queues[idx];
queue->ctrl = ctrl;
- queue->flags = 0;
init_completion(&queue->cm_done);
if (idx > 0)
@@ -595,6 +594,7 @@
goto out_destroy_cm_id;
}
+ clear_bit(NVME_RDMA_Q_DELETING, &queue->flags);
set_bit(NVME_RDMA_Q_CONNECTED, &queue->flags);
return 0;
diff --git a/drivers/of/of_numa.c b/drivers/of/of_numa.c
index ed5a097..f63d4b0d 100644
--- a/drivers/of/of_numa.c
+++ b/drivers/of/of_numa.c
@@ -16,6 +16,8 @@
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
+#define pr_fmt(fmt) "OF: NUMA: " fmt
+
#include <linux/of.h>
#include <linux/of_address.h>
#include <linux/nodemask.h>
@@ -49,10 +51,9 @@
if (r)
continue;
- pr_debug("NUMA: CPU on %u\n", nid);
+ pr_debug("CPU on %u\n", nid);
if (nid >= MAX_NUMNODES)
- pr_warn("NUMA: Node id %u exceeds maximum value\n",
- nid);
+ pr_warn("Node id %u exceeds maximum value\n", nid);
else
node_set(nid, numa_nodes_parsed);
}
@@ -63,13 +64,9 @@
struct device_node *np = NULL;
struct resource rsrc;
u32 nid;
- int r = 0;
+ int i, r;
- for (;;) {
- np = of_find_node_by_type(np, "memory");
- if (!np)
- break;
-
+ for_each_node_by_type(np, "memory") {
r = of_property_read_u32(np, "numa-node-id", &nid);
if (r == -EINVAL)
/*
@@ -78,27 +75,23 @@
* "numa-node-id" property
*/
continue;
- else if (r)
- /* some other error */
- break;
- r = of_address_to_resource(np, 0, &rsrc);
- if (r) {
- pr_err("NUMA: bad reg property in memory node\n");
- break;
+ if (nid >= MAX_NUMNODES) {
+ pr_warn("Node id %u exceeds maximum value\n", nid);
+ r = -EINVAL;
}
- pr_debug("NUMA: base = %llx len = %llx, node = %u\n",
- rsrc.start, rsrc.end - rsrc.start + 1, nid);
+ for (i = 0; !r && !of_address_to_resource(np, i, &rsrc); i++)
+ r = numa_add_memblk(nid, rsrc.start, rsrc.end + 1);
-
- r = numa_add_memblk(nid, rsrc.start, rsrc.end + 1);
- if (r)
- break;
+ if (!i || r) {
+ of_node_put(np);
+ pr_err("bad property in memory node\n");
+ return r ? : -EINVAL;
+ }
}
- of_node_put(np);
- return r;
+ return 0;
}
static int __init of_numa_parse_distance_map_v1(struct device_node *map)
@@ -107,17 +100,17 @@
int entry_count;
int i;
- pr_info("NUMA: parsing numa-distance-map-v1\n");
+ pr_info("parsing numa-distance-map-v1\n");
matrix = of_get_property(map, "distance-matrix", NULL);
if (!matrix) {
- pr_err("NUMA: No distance-matrix property in distance-map\n");
+ pr_err("No distance-matrix property in distance-map\n");
return -EINVAL;
}
entry_count = of_property_count_u32_elems(map, "distance-matrix");
if (entry_count <= 0) {
- pr_err("NUMA: Invalid distance-matrix\n");
+ pr_err("Invalid distance-matrix\n");
return -EINVAL;
}
@@ -132,7 +125,7 @@
matrix++;
numa_set_distance(nodea, nodeb, distance);
- pr_debug("NUMA: distance[node%d -> node%d] = %d\n",
+ pr_debug("distance[node%d -> node%d] = %d\n",
nodea, nodeb, distance);
/* Set default distance of node B->A same as A->B */
@@ -166,8 +159,6 @@
np = of_node_get(device);
while (np) {
- struct device_node *parent;
-
r = of_property_read_u32(np, "numa-node-id", &nid);
/*
* -EINVAL indicates the property was not found, and
@@ -178,22 +169,15 @@
if (r != -EINVAL)
break;
- parent = of_get_parent(np);
- of_node_put(np);
- np = parent;
+ np = of_get_next_parent(np);
}
if (np && r)
- pr_warn("NUMA: Invalid \"numa-node-id\" property in node %s\n",
+ pr_warn("Invalid \"numa-node-id\" property in node %s\n",
np->name);
of_node_put(np);
- if (!r) {
- if (nid >= MAX_NUMNODES)
- pr_warn("NUMA: Node id %u exceeds maximum value\n",
- nid);
- else
- return nid;
- }
+ if (!r)
+ return nid;
return NUMA_NO_NODE;
}
diff --git a/drivers/pci/pci.c b/drivers/pci/pci.c
index aab9d51..415956c 100644
--- a/drivers/pci/pci.c
+++ b/drivers/pci/pci.c
@@ -480,6 +480,30 @@
EXPORT_SYMBOL(pci_find_parent_resource);
/**
+ * pci_find_resource - Return matching PCI device resource
+ * @dev: PCI device to query
+ * @res: Resource to look for
+ *
+ * Goes over standard PCI resources (BARs) and checks if the given resource
+ * is partially or fully contained in any of them. In that case the
+ * matching resource is returned, %NULL otherwise.
+ */
+struct resource *pci_find_resource(struct pci_dev *dev, struct resource *res)
+{
+ int i;
+
+ for (i = 0; i < PCI_ROM_RESOURCE; i++) {
+ struct resource *r = &dev->resource[i];
+
+ if (r->start && resource_contains(r, res))
+ return r;
+ }
+
+ return NULL;
+}
+EXPORT_SYMBOL(pci_find_resource);
+
+/**
* pci_find_pcie_root_port - return PCIe Root Port
* @dev: PCI device to query
*
diff --git a/drivers/perf/arm_pmu.c b/drivers/perf/arm_pmu.c
index f5e1008..3037081 100644
--- a/drivers/perf/arm_pmu.c
+++ b/drivers/perf/arm_pmu.c
@@ -534,6 +534,24 @@
return cpumask_test_cpu(cpu, &armpmu->supported_cpus);
}
+static ssize_t armpmu_cpumask_show(struct device *dev,
+ struct device_attribute *attr, char *buf)
+{
+ struct arm_pmu *armpmu = to_arm_pmu(dev_get_drvdata(dev));
+ return cpumap_print_to_pagebuf(true, buf, &armpmu->supported_cpus);
+}
+
+static DEVICE_ATTR(cpus, S_IRUGO, armpmu_cpumask_show, NULL);
+
+static struct attribute *armpmu_common_attrs[] = {
+ &dev_attr_cpus.attr,
+ NULL,
+};
+
+static struct attribute_group armpmu_common_attr_group = {
+ .attrs = armpmu_common_attrs,
+};
+
static void armpmu_init(struct arm_pmu *armpmu)
{
atomic_set(&armpmu->active_events, 0);
@@ -549,7 +567,10 @@
.stop = armpmu_stop,
.read = armpmu_read,
.filter_match = armpmu_filter_match,
+ .attr_groups = armpmu->attr_groups,
};
+ armpmu->attr_groups[ARMPMU_ATTR_GROUP_COMMON] =
+ &armpmu_common_attr_group;
}
/* Set at runtime when we know what CPU type we are. */
@@ -602,7 +623,7 @@
irqs = min(pmu_device->num_resources, num_possible_cpus());
irq = platform_get_irq(pmu_device, 0);
- if (irq >= 0 && irq_is_percpu(irq)) {
+ if (irq > 0 && irq_is_percpu(irq)) {
on_each_cpu_mask(&cpu_pmu->supported_cpus,
cpu_pmu_disable_percpu_irq, &irq, 1);
free_percpu_irq(irq, &hw_events->percpu_pmu);
@@ -616,7 +637,7 @@
if (!cpumask_test_and_clear_cpu(cpu, &cpu_pmu->active_irqs))
continue;
irq = platform_get_irq(pmu_device, i);
- if (irq >= 0)
+ if (irq > 0)
free_irq(irq, per_cpu_ptr(&hw_events->percpu_pmu, cpu));
}
}
@@ -638,7 +659,7 @@
}
irq = platform_get_irq(pmu_device, 0);
- if (irq >= 0 && irq_is_percpu(irq)) {
+ if (irq > 0 && irq_is_percpu(irq)) {
err = request_percpu_irq(irq, handler, "arm-pmu",
&hw_events->percpu_pmu);
if (err) {
@@ -919,7 +940,7 @@
/* Check the IRQ type and prohibit a mix of PPIs and SPIs */
irq = platform_get_irq(pdev, i);
- if (irq >= 0) {
+ if (irq > 0) {
bool spi = !irq_is_percpu(irq);
if (i > 0 && spi != using_spi) {
@@ -970,7 +991,7 @@
if (cpumask_weight(&pmu->supported_cpus) == 0) {
int irq = platform_get_irq(pdev, 0);
- if (irq >= 0 && irq_is_percpu(irq)) {
+ if (irq > 0 && irq_is_percpu(irq)) {
/* If using PPIs, check the affinity of the partition */
int ret;
@@ -1029,7 +1050,7 @@
ret = of_pmu_irq_cfg(pmu);
if (!ret)
ret = init_fn(pmu);
- } else {
+ } else if (probe_table) {
cpumask_setall(&pmu->supported_cpus);
ret = probe_current_pmu(pmu, probe_table);
}
@@ -1039,6 +1060,7 @@
goto out_free;
}
+
ret = cpu_pmu_init(pmu);
if (ret)
goto out_free;
diff --git a/drivers/platform/x86/intel_pmc_ipc.c b/drivers/platform/x86/intel_pmc_ipc.c
index b86e1bc..a511d51 100644
--- a/drivers/platform/x86/intel_pmc_ipc.c
+++ b/drivers/platform/x86/intel_pmc_ipc.c
@@ -651,11 +651,15 @@
{
int ret;
- ret = ipc_create_tco_device();
- if (ret) {
- dev_err(ipcdev.dev, "Failed to add tco platform device\n");
- return ret;
+ /* If we have ACPI based watchdog use that instead */
+ if (!acpi_has_watchdog()) {
+ ret = ipc_create_tco_device();
+ if (ret) {
+ dev_err(ipcdev.dev, "Failed to add tco platform device\n");
+ return ret;
+ }
}
+
ret = ipc_create_punit_device();
if (ret) {
dev_err(ipcdev.dev, "Failed to add punit platform device\n");
diff --git a/drivers/pnp/isapnp/core.c b/drivers/pnp/isapnp/core.c
index cf88f9b6..d8bf5a1 100644
--- a/drivers/pnp/isapnp/core.c
+++ b/drivers/pnp/isapnp/core.c
@@ -34,7 +34,7 @@
* 2003-08-11 Resource Management Updates - Adam Belay <ambx1@neo.rr.com>
*/
-#include <linux/module.h>
+#include <linux/moduleparam.h>
#include <linux/kernel.h>
#include <linux/errno.h>
#include <linux/delay.h>
@@ -54,8 +54,6 @@
static int isapnp_reset = 1; /* reset all PnP cards (deactivate) */
static int isapnp_verbose = 1; /* verbose mode */
-MODULE_AUTHOR("Jaroslav Kysela <perex@perex.cz>");
-MODULE_DESCRIPTION("Generic ISA Plug & Play support");
module_param(isapnp_disable, int, 0);
MODULE_PARM_DESC(isapnp_disable, "ISA Plug & Play disable");
module_param(isapnp_rdp, int, 0);
@@ -64,7 +62,6 @@
MODULE_PARM_DESC(isapnp_reset, "ISA Plug & Play reset all cards");
module_param(isapnp_verbose, int, 0);
MODULE_PARM_DESC(isapnp_verbose, "ISA Plug & Play verbose mode");
-MODULE_LICENSE("GPL");
#define _PIDXR 0x279
#define _PNPWRP 0xa79
diff --git a/drivers/power/avs/smartreflex.c b/drivers/power/avs/smartreflex.c
index db9973b..fa0f19b 100644
--- a/drivers/power/avs/smartreflex.c
+++ b/drivers/power/avs/smartreflex.c
@@ -136,7 +136,7 @@
if (IS_ERR(fck)) {
dev_err(&sr->pdev->dev, "%s: unable to get fck for device %s\n",
- __func__, dev_name(&sr->pdev->dev));
+ __func__, dev_name(&sr->pdev->dev));
return;
}
@@ -170,8 +170,8 @@
{
if (!sr_class || !(sr_class->enable) || !(sr_class->configure)) {
dev_warn(&sr->pdev->dev,
- "%s: smartreflex class driver not registered\n",
- __func__);
+ "%s: smartreflex class driver not registered\n",
+ __func__);
return;
}
@@ -183,8 +183,8 @@
{
if (!sr_class || !(sr_class->disable)) {
dev_warn(&sr->pdev->dev,
- "%s: smartreflex class driver not registered\n",
- __func__);
+ "%s: smartreflex class driver not registered\n",
+ __func__);
return;
}
@@ -225,9 +225,8 @@
error:
list_del(&sr_info->node);
- dev_err(&sr_info->pdev->dev, "%s: ERROR in registering"
- "interrupt handler. Smartreflex will"
- "not function as desired\n", __func__);
+ dev_err(&sr_info->pdev->dev, "%s: ERROR in registering interrupt handler. Smartreflex will not function as desired\n",
+ __func__);
return ret;
}
@@ -263,7 +262,7 @@
if (timeout >= SR_DISABLE_TIMEOUT)
dev_warn(&sr->pdev->dev, "%s: Smartreflex disable timedout\n",
- __func__);
+ __func__);
/* Disable MCUDisableAcknowledge interrupt & clear pending interrupt */
sr_modify_reg(sr, ERRCONFIG_V1, ERRCONFIG_MCUDISACKINTEN,
@@ -308,7 +307,7 @@
if (timeout >= SR_DISABLE_TIMEOUT)
dev_warn(&sr->pdev->dev, "%s: Smartreflex disable timedout\n",
- __func__);
+ __func__);
/* Disable MCUDisableAcknowledge interrupt & clear pending interrupt */
sr_write_reg(sr, IRQENABLE_CLR, IRQENABLE_MCUDISABLEACKINT);
@@ -322,7 +321,7 @@
if (!sr->nvalue_table) {
dev_warn(&sr->pdev->dev, "%s: Missing ntarget value table\n",
- __func__);
+ __func__);
return NULL;
}
@@ -356,8 +355,8 @@
u8 senp_shift, senn_shift;
if (!sr) {
- pr_warn("%s: NULL omap_sr from %pF\n", __func__,
- (void *)_RET_IP_);
+ pr_warn("%s: NULL omap_sr from %pF\n",
+ __func__, (void *)_RET_IP_);
return -EINVAL;
}
@@ -387,8 +386,8 @@
vpboundint_st = ERRCONFIG_VPBOUNDINTST_V2;
break;
default:
- dev_err(&sr->pdev->dev, "%s: Trying to Configure smartreflex"
- "module without specifying the ip\n", __func__);
+ dev_err(&sr->pdev->dev, "%s: Trying to Configure smartreflex module without specifying the ip\n",
+ __func__);
return -EINVAL;
}
@@ -423,8 +422,8 @@
u32 vpboundint_en, vpboundint_st;
if (!sr) {
- pr_warn("%s: NULL omap_sr from %pF\n", __func__,
- (void *)_RET_IP_);
+ pr_warn("%s: NULL omap_sr from %pF\n",
+ __func__, (void *)_RET_IP_);
return -EINVAL;
}
@@ -440,8 +439,8 @@
vpboundint_st = ERRCONFIG_VPBOUNDINTST_V2;
break;
default:
- dev_err(&sr->pdev->dev, "%s: Trying to Configure smartreflex"
- "module without specifying the ip\n", __func__);
+ dev_err(&sr->pdev->dev, "%s: Trying to Configure smartreflex module without specifying the ip\n",
+ __func__);
return -EINVAL;
}
@@ -478,8 +477,8 @@
u8 senp_shift, senn_shift;
if (!sr) {
- pr_warn("%s: NULL omap_sr from %pF\n", __func__,
- (void *)_RET_IP_);
+ pr_warn("%s: NULL omap_sr from %pF\n",
+ __func__, (void *)_RET_IP_);
return -EINVAL;
}
@@ -504,8 +503,8 @@
senp_shift = SRCONFIG_SENPENABLE_V2_SHIFT;
break;
default:
- dev_err(&sr->pdev->dev, "%s: Trying to Configure smartreflex"
- "module without specifying the ip\n", __func__);
+ dev_err(&sr->pdev->dev, "%s: Trying to Configure smartreflex module without specifying the ip\n",
+ __func__);
return -EINVAL;
}
@@ -537,8 +536,8 @@
IRQENABLE_MCUBOUNDSINT | IRQENABLE_MCUDISABLEACKINT);
break;
default:
- dev_err(&sr->pdev->dev, "%s: Trying to Configure smartreflex"
- "module without specifying the ip\n", __func__);
+ dev_err(&sr->pdev->dev, "%s: Trying to Configure smartreflex module without specifying the ip\n",
+ __func__);
return -EINVAL;
}
@@ -563,16 +562,16 @@
int ret;
if (!sr) {
- pr_warn("%s: NULL omap_sr from %pF\n", __func__,
- (void *)_RET_IP_);
+ pr_warn("%s: NULL omap_sr from %pF\n",
+ __func__, (void *)_RET_IP_);
return -EINVAL;
}
volt_data = omap_voltage_get_voltdata(sr->voltdm, volt);
if (IS_ERR(volt_data)) {
- dev_warn(&sr->pdev->dev, "%s: Unable to get voltage table"
- "for nominal voltage %ld\n", __func__, volt);
+ dev_warn(&sr->pdev->dev, "%s: Unable to get voltage table for nominal voltage %ld\n",
+ __func__, volt);
return PTR_ERR(volt_data);
}
@@ -615,8 +614,8 @@
void sr_disable(struct omap_sr *sr)
{
if (!sr) {
- pr_warn("%s: NULL omap_sr from %pF\n", __func__,
- (void *)_RET_IP_);
+ pr_warn("%s: NULL omap_sr from %pF\n",
+ __func__, (void *)_RET_IP_);
return;
}
@@ -658,13 +657,13 @@
struct omap_sr *sr_info;
if (!class_data) {
- pr_warning("%s:, Smartreflex class data passed is NULL\n",
+ pr_warn("%s:, Smartreflex class data passed is NULL\n",
__func__);
return -EINVAL;
}
if (sr_class) {
- pr_warning("%s: Smartreflex class driver already registered\n",
+ pr_warn("%s: Smartreflex class driver already registered\n",
__func__);
return -EBUSY;
}
@@ -696,7 +695,7 @@
struct omap_sr *sr = _sr_lookup(voltdm);
if (IS_ERR(sr)) {
- pr_warning("%s: omap_sr struct for voltdm not found\n", __func__);
+ pr_warn("%s: omap_sr struct for voltdm not found\n", __func__);
return;
}
@@ -704,8 +703,8 @@
return;
if (!sr_class || !(sr_class->enable) || !(sr_class->configure)) {
- dev_warn(&sr->pdev->dev, "%s: smartreflex class driver not"
- "registered\n", __func__);
+ dev_warn(&sr->pdev->dev, "%s: smartreflex class driver not registered\n",
+ __func__);
return;
}
@@ -728,7 +727,7 @@
struct omap_sr *sr = _sr_lookup(voltdm);
if (IS_ERR(sr)) {
- pr_warning("%s: omap_sr struct for voltdm not found\n", __func__);
+ pr_warn("%s: omap_sr struct for voltdm not found\n", __func__);
return;
}
@@ -736,8 +735,8 @@
return;
if (!sr_class || !(sr_class->disable)) {
- dev_warn(&sr->pdev->dev, "%s: smartreflex class driver not"
- "registered\n", __func__);
+ dev_warn(&sr->pdev->dev, "%s: smartreflex class driver not registered\n",
+ __func__);
return;
}
@@ -760,7 +759,7 @@
struct omap_sr *sr = _sr_lookup(voltdm);
if (IS_ERR(sr)) {
- pr_warning("%s: omap_sr struct for voltdm not found\n", __func__);
+ pr_warn("%s: omap_sr struct for voltdm not found\n", __func__);
return;
}
@@ -768,8 +767,8 @@
return;
if (!sr_class || !(sr_class->disable)) {
- dev_warn(&sr->pdev->dev, "%s: smartreflex class driver not"
- "registered\n", __func__);
+ dev_warn(&sr->pdev->dev, "%s: smartreflex class driver not registered\n",
+ __func__);
return;
}
@@ -787,8 +786,8 @@
void omap_sr_register_pmic(struct omap_sr_pmic_data *pmic_data)
{
if (!pmic_data) {
- pr_warning("%s: Trying to register NULL PMIC data structure"
- "with smartreflex\n", __func__);
+ pr_warn("%s: Trying to register NULL PMIC data structure with smartreflex\n",
+ __func__);
return;
}
@@ -801,7 +800,7 @@
struct omap_sr *sr_info = data;
if (!sr_info) {
- pr_warning("%s: omap_sr struct not found\n", __func__);
+ pr_warn("%s: omap_sr struct not found\n", __func__);
return -EINVAL;
}
@@ -815,13 +814,13 @@
struct omap_sr *sr_info = data;
if (!sr_info) {
- pr_warning("%s: omap_sr struct not found\n", __func__);
+ pr_warn("%s: omap_sr struct not found\n", __func__);
return -EINVAL;
}
/* Sanity check */
if (val > 1) {
- pr_warning("%s: Invalid argument %lld\n", __func__, val);
+ pr_warn("%s: Invalid argument %lld\n", __func__, val);
return -EINVAL;
}
@@ -848,19 +847,13 @@
int i, ret = 0;
sr_info = devm_kzalloc(&pdev->dev, sizeof(struct omap_sr), GFP_KERNEL);
- if (!sr_info) {
- dev_err(&pdev->dev, "%s: unable to allocate sr_info\n",
- __func__);
+ if (!sr_info)
return -ENOMEM;
- }
sr_info->name = devm_kzalloc(&pdev->dev,
SMARTREFLEX_NAME_LEN, GFP_KERNEL);
- if (!sr_info->name) {
- dev_err(&pdev->dev, "%s: unable to allocate SR instance name\n",
- __func__);
+ if (!sr_info->name)
return -ENOMEM;
- }
platform_set_drvdata(pdev, sr_info);
@@ -912,7 +905,7 @@
if (sr_class) {
ret = sr_late_init(sr_info);
if (ret) {
- pr_warning("%s: Error in SR late init\n", __func__);
+ pr_warn("%s: Error in SR late init\n", __func__);
goto err_list_del;
}
}
@@ -923,7 +916,7 @@
if (IS_ERR_OR_NULL(sr_dbg_dir)) {
ret = PTR_ERR(sr_dbg_dir);
pr_err("%s:sr debugfs dir creation failed(%d)\n",
- __func__, ret);
+ __func__, ret);
goto err_list_del;
}
}
@@ -945,8 +938,8 @@
nvalue_dir = debugfs_create_dir("nvalue", sr_info->dbg_dir);
if (IS_ERR_OR_NULL(nvalue_dir)) {
- dev_err(&pdev->dev, "%s: Unable to create debugfs directory"
- "for n-values\n", __func__);
+ dev_err(&pdev->dev, "%s: Unable to create debugfs directory for n-values\n",
+ __func__);
ret = PTR_ERR(nvalue_dir);
goto err_debugfs;
}
@@ -1053,12 +1046,12 @@
if (sr_pmic_data && sr_pmic_data->sr_pmic_init)
sr_pmic_data->sr_pmic_init();
else
- pr_warning("%s: No PMIC hook to init smartreflex\n", __func__);
+ pr_warn("%s: No PMIC hook to init smartreflex\n", __func__);
ret = platform_driver_probe(&smartreflex_driver, omap_sr_probe);
if (ret) {
pr_err("%s: platform driver register failed for SR\n",
- __func__);
+ __func__);
return ret;
}
diff --git a/drivers/rapidio/rio_cm.c b/drivers/rapidio/rio_cm.c
index 3fa17ac..cebc296 100644
--- a/drivers/rapidio/rio_cm.c
+++ b/drivers/rapidio/rio_cm.c
@@ -2247,17 +2247,30 @@
{
struct rio_channel *ch;
unsigned int i;
+ LIST_HEAD(list);
riocm_debug(EXIT, ".");
+ /*
+ * If there are any channels left in connected state send
+ * close notification to the connection partner.
+ * First build a list of channels that require a closing
+ * notification because function riocm_send_close() should
+ * be called outside of spinlock protected code.
+ */
spin_lock_bh(&idr_lock);
idr_for_each_entry(&ch_idr, ch, i) {
- riocm_debug(EXIT, "close ch %d", ch->id);
- if (ch->state == RIO_CM_CONNECTED)
- riocm_send_close(ch);
+ if (ch->state == RIO_CM_CONNECTED) {
+ riocm_debug(EXIT, "close ch %d", ch->id);
+ idr_remove(&ch_idr, ch->id);
+ list_add(&ch->ch_node, &list);
+ }
}
spin_unlock_bh(&idr_lock);
+ list_for_each_entry(ch, &list, ch_node)
+ riocm_send_close(ch);
+
return NOTIFY_DONE;
}
diff --git a/drivers/s390/net/qeth_core.h b/drivers/s390/net/qeth_core.h
index bf40063..6d4b68c4 100644
--- a/drivers/s390/net/qeth_core.h
+++ b/drivers/s390/net/qeth_core.h
@@ -999,6 +999,7 @@
__u16, __u16,
enum qeth_prot_versions);
int qeth_set_features(struct net_device *, netdev_features_t);
+int qeth_recover_features(struct net_device *);
netdev_features_t qeth_fix_features(struct net_device *, netdev_features_t);
/* exports for OSN */
diff --git a/drivers/s390/net/qeth_core_main.c b/drivers/s390/net/qeth_core_main.c
index 7dba6c8..20cf296 100644
--- a/drivers/s390/net/qeth_core_main.c
+++ b/drivers/s390/net/qeth_core_main.c
@@ -3619,7 +3619,8 @@
int e;
e = 0;
- while (buffer->element[e].addr) {
+ while ((e < QDIO_MAX_ELEMENTS_PER_BUFFER) &&
+ buffer->element[e].addr) {
unsigned long phys_aob_addr;
phys_aob_addr = (unsigned long) buffer->element[e].addr;
@@ -6131,6 +6132,35 @@
return rc;
}
+/* try to restore device features on a device after recovery */
+int qeth_recover_features(struct net_device *dev)
+{
+ struct qeth_card *card = dev->ml_priv;
+ netdev_features_t recover = dev->features;
+
+ if (recover & NETIF_F_IP_CSUM) {
+ if (qeth_set_ipa_csum(card, 1, IPA_OUTBOUND_CHECKSUM))
+ recover ^= NETIF_F_IP_CSUM;
+ }
+ if (recover & NETIF_F_RXCSUM) {
+ if (qeth_set_ipa_csum(card, 1, IPA_INBOUND_CHECKSUM))
+ recover ^= NETIF_F_RXCSUM;
+ }
+ if (recover & NETIF_F_TSO) {
+ if (qeth_set_ipa_tso(card, 1))
+ recover ^= NETIF_F_TSO;
+ }
+
+ if (recover == dev->features)
+ return 0;
+
+ dev_warn(&card->gdev->dev,
+ "Device recovery failed to restore all offload features\n");
+ dev->features = recover;
+ return -EIO;
+}
+EXPORT_SYMBOL_GPL(qeth_recover_features);
+
int qeth_set_features(struct net_device *dev, netdev_features_t features)
{
struct qeth_card *card = dev->ml_priv;
diff --git a/drivers/s390/net/qeth_l2_main.c b/drivers/s390/net/qeth_l2_main.c
index 7bc20c5..bb27058 100644
--- a/drivers/s390/net/qeth_l2_main.c
+++ b/drivers/s390/net/qeth_l2_main.c
@@ -1124,14 +1124,11 @@
card->dev->hw_features |= NETIF_F_RXCSUM;
card->dev->vlan_features |= NETIF_F_RXCSUM;
}
- /* Turn on SG per default */
- card->dev->features |= NETIF_F_SG;
}
card->info.broadcast_capable = 1;
qeth_l2_request_initial_mac(card);
card->dev->gso_max_size = (QETH_MAX_BUFFER_ELEMENTS(card) - 1) *
PAGE_SIZE;
- card->dev->gso_max_segs = (QETH_MAX_BUFFER_ELEMENTS(card) - 1);
SET_NETDEV_DEV(card->dev, &card->gdev->dev);
netif_napi_add(card->dev, &card->napi, qeth_l2_poll, QETH_NAPI_WEIGHT);
netif_carrier_off(card->dev);
@@ -1246,6 +1243,9 @@
}
/* this also sets saved unicast addresses */
qeth_l2_set_rx_mode(card->dev);
+ rtnl_lock();
+ qeth_recover_features(card->dev);
+ rtnl_unlock();
}
/* let user_space know that device is online */
kobject_uevent(&gdev->dev.kobj, KOBJ_CHANGE);
diff --git a/drivers/s390/net/qeth_l3_main.c b/drivers/s390/net/qeth_l3_main.c
index 7293466..272d9e7 100644
--- a/drivers/s390/net/qeth_l3_main.c
+++ b/drivers/s390/net/qeth_l3_main.c
@@ -257,6 +257,11 @@
if (addr->in_progress)
return -EINPROGRESS;
+ if (!qeth_card_hw_is_reachable(card)) {
+ addr->disp_flag = QETH_DISP_ADDR_DELETE;
+ return 0;
+ }
+
rc = qeth_l3_deregister_addr_entry(card, addr);
hash_del(&addr->hnode);
@@ -296,6 +301,11 @@
hash_add(card->ip_htable, &addr->hnode,
qeth_l3_ipaddr_hash(addr));
+ if (!qeth_card_hw_is_reachable(card)) {
+ addr->disp_flag = QETH_DISP_ADDR_ADD;
+ return 0;
+ }
+
/* qeth_l3_register_addr_entry can go to sleep
* if we add a IPV4 addr. It is caused by the reason
* that SETIP ipa cmd starts ARP staff for IPV4 addr.
@@ -390,12 +400,16 @@
int i;
int rc;
- QETH_CARD_TEXT(card, 4, "recoverip");
+ QETH_CARD_TEXT(card, 4, "recovrip");
spin_lock_bh(&card->ip_lock);
hash_for_each_safe(card->ip_htable, i, tmp, addr, hnode) {
- if (addr->disp_flag == QETH_DISP_ADDR_ADD) {
+ if (addr->disp_flag == QETH_DISP_ADDR_DELETE) {
+ qeth_l3_deregister_addr_entry(card, addr);
+ hash_del(&addr->hnode);
+ kfree(addr);
+ } else if (addr->disp_flag == QETH_DISP_ADDR_ADD) {
if (addr->proto == QETH_PROT_IPV4) {
addr->in_progress = 1;
spin_unlock_bh(&card->ip_lock);
@@ -407,10 +421,8 @@
if (!rc) {
addr->disp_flag = QETH_DISP_ADDR_DO_NOTHING;
- if (addr->ref_counter < 1) {
+ if (addr->ref_counter < 1)
qeth_l3_delete_ip(card, addr);
- kfree(addr);
- }
} else {
hash_del(&addr->hnode);
kfree(addr);
@@ -689,7 +701,7 @@
spin_lock_bh(&card->ip_lock);
- if (!qeth_l3_ip_from_hash(card, ipaddr))
+ if (qeth_l3_ip_from_hash(card, ipaddr))
rc = -EEXIST;
else
qeth_l3_add_ip(card, ipaddr);
@@ -757,7 +769,7 @@
spin_lock_bh(&card->ip_lock);
- if (!qeth_l3_ip_from_hash(card, ipaddr))
+ if (qeth_l3_ip_from_hash(card, ipaddr))
rc = -EEXIST;
else
qeth_l3_add_ip(card, ipaddr);
@@ -3108,7 +3120,6 @@
card->dev->vlan_features = NETIF_F_SG |
NETIF_F_RXCSUM | NETIF_F_IP_CSUM |
NETIF_F_TSO;
- card->dev->features = NETIF_F_SG;
}
}
} else if (card->info.type == QETH_CARD_TYPE_IQD) {
@@ -3136,7 +3147,6 @@
netif_keep_dst(card->dev);
card->dev->gso_max_size = (QETH_MAX_BUFFER_ELEMENTS(card) - 1) *
PAGE_SIZE;
- card->dev->gso_max_segs = (QETH_MAX_BUFFER_ELEMENTS(card) - 1);
SET_NETDEV_DEV(card->dev, &card->gdev->dev);
netif_napi_add(card->dev, &card->napi, qeth_l3_poll, QETH_NAPI_WEIGHT);
@@ -3269,6 +3279,7 @@
else
dev_open(card->dev);
qeth_l3_set_multicast_list(card->dev);
+ qeth_recover_features(card->dev);
rtnl_unlock();
}
qeth_trace_features(card);
diff --git a/drivers/s390/net/qeth_l3_sys.c b/drivers/s390/net/qeth_l3_sys.c
index 65645b1..0e00a5c 100644
--- a/drivers/s390/net/qeth_l3_sys.c
+++ b/drivers/s390/net/qeth_l3_sys.c
@@ -297,7 +297,9 @@
addr->u.a6.pfxlen = 0;
addr->type = QETH_IP_TYPE_NORMAL;
+ spin_lock_bh(&card->ip_lock);
qeth_l3_delete_ip(card, addr);
+ spin_unlock_bh(&card->ip_lock);
kfree(addr);
}
@@ -329,7 +331,10 @@
addr->type = QETH_IP_TYPE_NORMAL;
} else
return -ENOMEM;
+
+ spin_lock_bh(&card->ip_lock);
qeth_l3_add_ip(card, addr);
+ spin_unlock_bh(&card->ip_lock);
kfree(addr);
return count;
diff --git a/drivers/scsi/hosts.c b/drivers/scsi/hosts.c
index ba9af4a..ec6381e 100644
--- a/drivers/scsi/hosts.c
+++ b/drivers/scsi/hosts.c
@@ -486,6 +486,8 @@
else
shost->dma_boundary = 0xffffffff;
+ shost->use_blk_mq = scsi_use_blk_mq;
+
device_initialize(&shost->shost_gendev);
dev_set_name(&shost->shost_gendev, "host%d", shost->host_no);
shost->shost_gendev.bus = &scsi_bus_type;
diff --git a/drivers/scsi/scsi.c b/drivers/scsi/scsi.c
index 1f36aca..1deb6ad 100644
--- a/drivers/scsi/scsi.c
+++ b/drivers/scsi/scsi.c
@@ -1160,7 +1160,6 @@
bool scsi_use_blk_mq = false;
#endif
module_param_named(use_blk_mq, scsi_use_blk_mq, bool, S_IWUSR | S_IRUGO);
-EXPORT_SYMBOL_GPL(scsi_use_blk_mq);
static int __init init_scsi(void)
{
diff --git a/drivers/scsi/scsi_priv.h b/drivers/scsi/scsi_priv.h
index 57a4b99..85c8a51 100644
--- a/drivers/scsi/scsi_priv.h
+++ b/drivers/scsi/scsi_priv.h
@@ -29,6 +29,7 @@
extern void scsi_exit_hosts(void);
/* scsi.c */
+extern bool scsi_use_blk_mq;
extern int scsi_setup_command_freelist(struct Scsi_Host *shost);
extern void scsi_destroy_command_freelist(struct Scsi_Host *shost);
#ifdef CONFIG_SCSI_LOGGING
diff --git a/drivers/soc/samsung/pm_domains.c b/drivers/soc/samsung/pm_domains.c
index 4822346..7112004 100644
--- a/drivers/soc/samsung/pm_domains.c
+++ b/drivers/soc/samsung/pm_domains.c
@@ -215,29 +215,22 @@
/* Assign the child power domains to their parents */
for_each_matching_node(np, exynos_pm_domain_of_match) {
- struct generic_pm_domain *child_domain, *parent_domain;
- struct of_phandle_args args;
+ struct of_phandle_args child, parent;
- args.np = np;
- args.args_count = 0;
- child_domain = of_genpd_get_from_provider(&args);
- if (IS_ERR(child_domain))
- continue;
+ child.np = np;
+ child.args_count = 0;
if (of_parse_phandle_with_args(np, "power-domains",
- "#power-domain-cells", 0, &args) != 0)
+ "#power-domain-cells", 0,
+ &parent) != 0)
continue;
- parent_domain = of_genpd_get_from_provider(&args);
- if (IS_ERR(parent_domain))
- continue;
-
- if (pm_genpd_add_subdomain(parent_domain, child_domain))
+ if (of_genpd_add_subdomain(&parent, &child))
pr_warn("%s failed to add subdomain: %s\n",
- parent_domain->name, child_domain->name);
+ parent.np->name, child.np->name);
else
pr_info("%s has as child subdomain: %s.\n",
- parent_domain->name, child_domain->name);
+ parent.np->name, child.np->name);
}
return 0;
diff --git a/drivers/staging/board/board.c b/drivers/staging/board/board.c
index 45807d8..86dc411 100644
--- a/drivers/staging/board/board.c
+++ b/drivers/staging/board/board.c
@@ -140,7 +140,6 @@
const char *domain)
{
struct of_phandle_args pd_args;
- struct generic_pm_domain *pd;
struct device_node *np;
np = of_find_node_by_path(domain);
@@ -151,14 +150,8 @@
pd_args.np = np;
pd_args.args_count = 0;
- pd = of_genpd_get_from_provider(&pd_args);
- if (IS_ERR(pd)) {
- pr_err("Cannot find genpd %s (%ld)\n", domain, PTR_ERR(pd));
- return PTR_ERR(pd);
- }
- pr_debug("Found genpd %s for device %s\n", pd->name, pdev->name);
- return pm_genpd_add_device(pd, &pdev->dev);
+ return of_genpd_add_device(&pd_args, &pdev->dev);
}
#else
static inline int board_staging_add_dev_domain(struct platform_device *pdev,
diff --git a/drivers/staging/media/cec/TODO b/drivers/staging/media/cec/TODO
index a10d4f8..1322469 100644
--- a/drivers/staging/media/cec/TODO
+++ b/drivers/staging/media/cec/TODO
@@ -12,6 +12,7 @@
Other TODOs:
+- There are two possible replies to CEC_MSG_INITIATE_ARC. How to handle that?
- Add a flag to inhibit passing CEC RC messages to the rc subsystem.
Applications should be able to choose this when calling S_LOG_ADDRS.
- If the reply field of cec_msg is set then when the reply arrives it
diff --git a/drivers/staging/media/cec/cec-adap.c b/drivers/staging/media/cec/cec-adap.c
index b2393bba..946986f 100644
--- a/drivers/staging/media/cec/cec-adap.c
+++ b/drivers/staging/media/cec/cec-adap.c
@@ -124,10 +124,10 @@
u64 ts = ktime_get_ns();
struct cec_fh *fh;
- mutex_lock(&adap->devnode.fhs_lock);
+ mutex_lock(&adap->devnode.lock);
list_for_each_entry(fh, &adap->devnode.fhs, list)
cec_queue_event_fh(fh, ev, ts);
- mutex_unlock(&adap->devnode.fhs_lock);
+ mutex_unlock(&adap->devnode.lock);
}
/*
@@ -191,12 +191,12 @@
u32 monitor_mode = valid_la ? CEC_MODE_MONITOR :
CEC_MODE_MONITOR_ALL;
- mutex_lock(&adap->devnode.fhs_lock);
+ mutex_lock(&adap->devnode.lock);
list_for_each_entry(fh, &adap->devnode.fhs, list) {
if (fh->mode_follower >= monitor_mode)
cec_queue_msg_fh(fh, msg);
}
- mutex_unlock(&adap->devnode.fhs_lock);
+ mutex_unlock(&adap->devnode.lock);
}
/*
@@ -207,12 +207,12 @@
{
struct cec_fh *fh;
- mutex_lock(&adap->devnode.fhs_lock);
+ mutex_lock(&adap->devnode.lock);
list_for_each_entry(fh, &adap->devnode.fhs, list) {
if (fh->mode_follower == CEC_MODE_FOLLOWER)
cec_queue_msg_fh(fh, msg);
}
- mutex_unlock(&adap->devnode.fhs_lock);
+ mutex_unlock(&adap->devnode.lock);
}
/* Notify userspace of an adapter state change. */
@@ -851,6 +851,9 @@
if (!valid_la || msg->len <= 1)
return;
+ if (adap->log_addrs.log_addr_mask == 0)
+ return;
+
/*
* Process the message on the protocol level. If is_reply is true,
* then cec_receive_notify() won't pass on the reply to the listener(s)
@@ -1047,11 +1050,17 @@
dprintk(1, "could not claim LA %d\n", i);
}
+ if (adap->log_addrs.log_addr_mask == 0 &&
+ !(las->flags & CEC_LOG_ADDRS_FL_ALLOW_UNREG_FALLBACK))
+ goto unconfigure;
+
configured:
if (adap->log_addrs.log_addr_mask == 0) {
/* Fall back to unregistered */
las->log_addr[0] = CEC_LOG_ADDR_UNREGISTERED;
las->log_addr_mask = 1 << las->log_addr[0];
+ for (i = 1; i < las->num_log_addrs; i++)
+ las->log_addr[i] = CEC_LOG_ADDR_INVALID;
}
adap->is_configured = true;
adap->is_configuring = false;
@@ -1070,6 +1079,8 @@
cec_report_features(adap, i);
cec_report_phys_addr(adap, i);
}
+ for (i = las->num_log_addrs; i < CEC_MAX_LOG_ADDRS; i++)
+ las->log_addr[i] = CEC_LOG_ADDR_INVALID;
mutex_lock(&adap->lock);
adap->kthread_config = NULL;
mutex_unlock(&adap->lock);
@@ -1398,7 +1409,6 @@
u8 init_laddr = cec_msg_initiator(msg);
u8 devtype = cec_log_addr2dev(adap, dest_laddr);
int la_idx = cec_log_addr2idx(adap, dest_laddr);
- bool is_directed = la_idx >= 0;
bool from_unregistered = init_laddr == 0xf;
struct cec_msg tx_cec_msg = { };
@@ -1560,7 +1570,7 @@
* Unprocessed messages are aborted if userspace isn't doing
* any processing either.
*/
- if (is_directed && !is_reply && !adap->follower_cnt &&
+ if (!is_broadcast && !is_reply && !adap->follower_cnt &&
!adap->cec_follower && msg->msg[1] != CEC_MSG_FEATURE_ABORT)
return cec_feature_abort(adap, msg);
break;
diff --git a/drivers/staging/media/cec/cec-api.c b/drivers/staging/media/cec/cec-api.c
index 7be7615..e274e2f 100644
--- a/drivers/staging/media/cec/cec-api.c
+++ b/drivers/staging/media/cec/cec-api.c
@@ -162,7 +162,7 @@
return -ENOTTY;
if (copy_from_user(&log_addrs, parg, sizeof(log_addrs)))
return -EFAULT;
- log_addrs.flags = 0;
+ log_addrs.flags &= CEC_LOG_ADDRS_FL_ALLOW_UNREG_FALLBACK;
mutex_lock(&adap->lock);
if (!adap->is_configuring &&
(!log_addrs.num_log_addrs || !adap->is_configured) &&
@@ -435,7 +435,7 @@
void __user *parg = (void __user *)arg;
if (!devnode->registered)
- return -EIO;
+ return -ENODEV;
switch (cmd) {
case CEC_ADAP_G_CAPS:
@@ -508,14 +508,14 @@
filp->private_data = fh;
- mutex_lock(&devnode->fhs_lock);
+ mutex_lock(&devnode->lock);
/* Queue up initial state events */
ev_state.state_change.phys_addr = adap->phys_addr;
ev_state.state_change.log_addr_mask = adap->log_addrs.log_addr_mask;
cec_queue_event_fh(fh, &ev_state, 0);
list_add(&fh->list, &devnode->fhs);
- mutex_unlock(&devnode->fhs_lock);
+ mutex_unlock(&devnode->lock);
return 0;
}
@@ -540,9 +540,9 @@
cec_monitor_all_cnt_dec(adap);
mutex_unlock(&adap->lock);
- mutex_lock(&devnode->fhs_lock);
+ mutex_lock(&devnode->lock);
list_del(&fh->list);
- mutex_unlock(&devnode->fhs_lock);
+ mutex_unlock(&devnode->lock);
/* Unhook pending transmits from this filehandle. */
mutex_lock(&adap->lock);
diff --git a/drivers/staging/media/cec/cec-core.c b/drivers/staging/media/cec/cec-core.c
index 112a5fa..3b1e4d2 100644
--- a/drivers/staging/media/cec/cec-core.c
+++ b/drivers/staging/media/cec/cec-core.c
@@ -51,31 +51,29 @@
{
/*
* Check if the cec device is available. This needs to be done with
- * the cec_devnode_lock held to prevent an open/unregister race:
+ * the devnode->lock held to prevent an open/unregister race:
* without the lock, the device could be unregistered and freed between
* the devnode->registered check and get_device() calls, leading to
* a crash.
*/
- mutex_lock(&cec_devnode_lock);
+ mutex_lock(&devnode->lock);
/*
* return ENXIO if the cec device has been removed
* already or if it is not registered anymore.
*/
if (!devnode->registered) {
- mutex_unlock(&cec_devnode_lock);
+ mutex_unlock(&devnode->lock);
return -ENXIO;
}
/* and increase the device refcount */
get_device(&devnode->dev);
- mutex_unlock(&cec_devnode_lock);
+ mutex_unlock(&devnode->lock);
return 0;
}
void cec_put_device(struct cec_devnode *devnode)
{
- mutex_lock(&cec_devnode_lock);
put_device(&devnode->dev);
- mutex_unlock(&cec_devnode_lock);
}
/* Called when the last user of the cec device exits. */
@@ -84,11 +82,10 @@
struct cec_devnode *devnode = to_cec_devnode(cd);
mutex_lock(&cec_devnode_lock);
-
/* Mark device node number as free */
clear_bit(devnode->minor, cec_devnode_nums);
-
mutex_unlock(&cec_devnode_lock);
+
cec_delete_adapter(to_cec_adapter(devnode));
}
@@ -117,7 +114,7 @@
/* Initialization */
INIT_LIST_HEAD(&devnode->fhs);
- mutex_init(&devnode->fhs_lock);
+ mutex_init(&devnode->lock);
/* Part 1: Find a free minor number */
mutex_lock(&cec_devnode_lock);
@@ -160,7 +157,9 @@
cdev_del:
cdev_del(&devnode->cdev);
clr_bit:
+ mutex_lock(&cec_devnode_lock);
clear_bit(devnode->minor, cec_devnode_nums);
+ mutex_unlock(&cec_devnode_lock);
return ret;
}
@@ -177,17 +176,21 @@
{
struct cec_fh *fh;
- /* Check if devnode was never registered or already unregistered */
- if (!devnode->registered || devnode->unregistered)
- return;
+ mutex_lock(&devnode->lock);
- mutex_lock(&devnode->fhs_lock);
+ /* Check if devnode was never registered or already unregistered */
+ if (!devnode->registered || devnode->unregistered) {
+ mutex_unlock(&devnode->lock);
+ return;
+ }
+
list_for_each_entry(fh, &devnode->fhs, list)
wake_up_interruptible(&fh->wait);
- mutex_unlock(&devnode->fhs_lock);
devnode->registered = false;
devnode->unregistered = true;
+ mutex_unlock(&devnode->lock);
+
device_del(&devnode->dev);
cdev_del(&devnode->cdev);
put_device(&devnode->dev);
diff --git a/drivers/staging/media/pulse8-cec/pulse8-cec.c b/drivers/staging/media/pulse8-cec/pulse8-cec.c
index 94f8590..ed8bd95 100644
--- a/drivers/staging/media/pulse8-cec/pulse8-cec.c
+++ b/drivers/staging/media/pulse8-cec/pulse8-cec.c
@@ -114,14 +114,11 @@
cec_transmit_done(pulse8->adap, CEC_TX_STATUS_OK,
0, 0, 0, 0);
break;
- case MSGCODE_TRANSMIT_FAILED_LINE:
- cec_transmit_done(pulse8->adap, CEC_TX_STATUS_ARB_LOST,
- 1, 0, 0, 0);
- break;
case MSGCODE_TRANSMIT_FAILED_ACK:
cec_transmit_done(pulse8->adap, CEC_TX_STATUS_NACK,
0, 1, 0, 0);
break;
+ case MSGCODE_TRANSMIT_FAILED_LINE:
case MSGCODE_TRANSMIT_FAILED_TIMEOUT_DATA:
case MSGCODE_TRANSMIT_FAILED_TIMEOUT_LINE:
cec_transmit_done(pulse8->adap, CEC_TX_STATUS_ERROR,
@@ -170,6 +167,9 @@
case MSGCODE_TRANSMIT_FAILED_TIMEOUT_LINE:
schedule_work(&pulse8->work);
break;
+ case MSGCODE_HIGH_ERROR:
+ case MSGCODE_LOW_ERROR:
+ case MSGCODE_RECEIVE_FAILED:
case MSGCODE_TIMEOUT_ERROR:
break;
case MSGCODE_COMMAND_ACCEPTED:
@@ -388,7 +388,7 @@
int err;
cmd[0] = MSGCODE_TRANSMIT_IDLETIME;
- cmd[1] = 3;
+ cmd[1] = signal_free_time;
err = pulse8_send_and_wait(pulse8, cmd, 2,
MSGCODE_COMMAND_ACCEPTED, 1);
cmd[0] = MSGCODE_TRANSMIT_ACK_POLARITY;
diff --git a/drivers/tty/serial/8250/8250_dw.c b/drivers/tty/serial/8250/8250_dw.c
index e199696..5c0c123 100644
--- a/drivers/tty/serial/8250/8250_dw.c
+++ b/drivers/tty/serial/8250/8250_dw.c
@@ -298,12 +298,17 @@
p->serial_out = dw8250_serial_out32be;
}
} else if (has_acpi_companion(p->dev)) {
- p->iotype = UPIO_MEM32;
- p->regshift = 2;
- p->serial_in = dw8250_serial_in32;
+ const struct acpi_device_id *id;
+
+ id = acpi_match_device(p->dev->driver->acpi_match_table,
+ p->dev);
+ if (id && !strcmp(id->id, "APMC0D08")) {
+ p->iotype = UPIO_MEM32;
+ p->regshift = 2;
+ p->serial_in = dw8250_serial_in32;
+ data->uart_16550_compatible = true;
+ }
p->set_termios = dw8250_set_termios;
- /* So far none of there implement the Busy Functionality */
- data->uart_16550_compatible = true;
}
/* Platforms with iDMA */
diff --git a/drivers/watchdog/Kconfig b/drivers/watchdog/Kconfig
index 1bffe00..50dbaa8 100644
--- a/drivers/watchdog/Kconfig
+++ b/drivers/watchdog/Kconfig
@@ -152,6 +152,19 @@
This driver can be built as a module. The module name is tangox_wdt.
+config WDAT_WDT
+ tristate "ACPI Watchdog Action Table (WDAT)"
+ depends on ACPI
+ select ACPI_WATCHDOG
+ help
+ This driver adds support for systems with ACPI Watchdog Action
+ Table (WDAT) table. Servers typically have this but it can be
+ found on some desktop machines as well. This driver will take
+ over the native iTCO watchdog driver found on many Intel CPUs.
+
+ To compile this driver as module, choose M here: the module will
+ be called wdat_wdt.
+
config WM831X_WATCHDOG
tristate "WM831x watchdog"
depends on MFD_WM831X
diff --git a/drivers/watchdog/Makefile b/drivers/watchdog/Makefile
index c22ad3e..cba0043 100644
--- a/drivers/watchdog/Makefile
+++ b/drivers/watchdog/Makefile
@@ -202,6 +202,7 @@
obj-$(CONFIG_DA9063_WATCHDOG) += da9063_wdt.o
obj-$(CONFIG_GPIO_WATCHDOG) += gpio_wdt.o
obj-$(CONFIG_TANGOX_WATCHDOG) += tangox_wdt.o
+obj-$(CONFIG_WDAT_WDT) += wdat_wdt.o
obj-$(CONFIG_WM831X_WATCHDOG) += wm831x_wdt.o
obj-$(CONFIG_WM8350_WATCHDOG) += wm8350_wdt.o
obj-$(CONFIG_MAX63XX_WATCHDOG) += max63xx_wdt.o
diff --git a/drivers/watchdog/wdat_wdt.c b/drivers/watchdog/wdat_wdt.c
new file mode 100644
index 0000000..e473e3b
--- /dev/null
+++ b/drivers/watchdog/wdat_wdt.c
@@ -0,0 +1,526 @@
+/*
+ * ACPI Hardware Watchdog (WDAT) driver.
+ *
+ * Copyright (C) 2016, Intel Corporation
+ * Author: Mika Westerberg <mika.westerberg@linux.intel.com>
+ *
+ * This program is free software; you can redistribute it and/or modify
+ * it under the terms of the GNU General Public License version 2 as
+ * published by the Free Software Foundation.
+ */
+
+#include <linux/acpi.h>
+#include <linux/ioport.h>
+#include <linux/module.h>
+#include <linux/platform_device.h>
+#include <linux/pm.h>
+#include <linux/watchdog.h>
+
+#define MAX_WDAT_ACTIONS ACPI_WDAT_ACTION_RESERVED
+
+/**
+ * struct wdat_instruction - Single ACPI WDAT instruction
+ * @entry: Copy of the ACPI table instruction
+ * @reg: Register the instruction is accessing
+ * @node: Next instruction in action sequence
+ */
+struct wdat_instruction {
+ struct acpi_wdat_entry entry;
+ void __iomem *reg;
+ struct list_head node;
+};
+
+/**
+ * struct wdat_wdt - ACPI WDAT watchdog device
+ * @pdev: Parent platform device
+ * @wdd: Watchdog core device
+ * @period: How long is one watchdog period in ms
+ * @stopped_in_sleep: Is this watchdog stopped by the firmware in S1-S5
+ * @stopped: Was the watchdog stopped by the driver in suspend
+ * @actions: An array of instruction lists indexed by an action number from
+ * the WDAT table. There can be %NULL entries for not implemented
+ * actions.
+ */
+struct wdat_wdt {
+ struct platform_device *pdev;
+ struct watchdog_device wdd;
+ unsigned int period;
+ bool stopped_in_sleep;
+ bool stopped;
+ struct list_head *instructions[MAX_WDAT_ACTIONS];
+};
+
+#define to_wdat_wdt(wdd) container_of(wdd, struct wdat_wdt, wdd)
+
+static bool nowayout = WATCHDOG_NOWAYOUT;
+module_param(nowayout, bool, 0);
+MODULE_PARM_DESC(nowayout, "Watchdog cannot be stopped once started (default="
+ __MODULE_STRING(WATCHDOG_NOWAYOUT) ")");
+
+static int wdat_wdt_read(struct wdat_wdt *wdat,
+ const struct wdat_instruction *instr, u32 *value)
+{
+ const struct acpi_generic_address *gas = &instr->entry.register_region;
+
+ switch (gas->access_width) {
+ case 1:
+ *value = ioread8(instr->reg);
+ break;
+ case 2:
+ *value = ioread16(instr->reg);
+ break;
+ case 3:
+ *value = ioread32(instr->reg);
+ break;
+ default:
+ return -EINVAL;
+ }
+
+ dev_dbg(&wdat->pdev->dev, "Read %#x from 0x%08llx\n", *value,
+ gas->address);
+
+ return 0;
+}
+
+static int wdat_wdt_write(struct wdat_wdt *wdat,
+ const struct wdat_instruction *instr, u32 value)
+{
+ const struct acpi_generic_address *gas = &instr->entry.register_region;
+
+ switch (gas->access_width) {
+ case 1:
+ iowrite8((u8)value, instr->reg);
+ break;
+ case 2:
+ iowrite16((u16)value, instr->reg);
+ break;
+ case 3:
+ iowrite32(value, instr->reg);
+ break;
+ default:
+ return -EINVAL;
+ }
+
+ dev_dbg(&wdat->pdev->dev, "Wrote %#x to 0x%08llx\n", value,
+ gas->address);
+
+ return 0;
+}
+
+static int wdat_wdt_run_action(struct wdat_wdt *wdat, unsigned int action,
+ u32 param, u32 *retval)
+{
+ struct wdat_instruction *instr;
+
+ if (action >= ARRAY_SIZE(wdat->instructions))
+ return -EINVAL;
+
+ if (!wdat->instructions[action])
+ return -EOPNOTSUPP;
+
+ dev_dbg(&wdat->pdev->dev, "Running action %#x\n", action);
+
+ /* Run each instruction sequentially */
+ list_for_each_entry(instr, wdat->instructions[action], node) {
+ const struct acpi_wdat_entry *entry = &instr->entry;
+ const struct acpi_generic_address *gas;
+ u32 flags, value, mask, x, y;
+ bool preserve;
+ int ret;
+
+ gas = &entry->register_region;
+
+ preserve = entry->instruction & ACPI_WDAT_PRESERVE_REGISTER;
+ flags = entry->instruction & ~ACPI_WDAT_PRESERVE_REGISTER;
+ value = entry->value;
+ mask = entry->mask;
+
+ switch (flags) {
+ case ACPI_WDAT_READ_VALUE:
+ ret = wdat_wdt_read(wdat, instr, &x);
+ if (ret)
+ return ret;
+ x >>= gas->bit_offset;
+ x &= mask;
+ if (retval)
+ *retval = x == value;
+ break;
+
+ case ACPI_WDAT_READ_COUNTDOWN:
+ ret = wdat_wdt_read(wdat, instr, &x);
+ if (ret)
+ return ret;
+ x >>= gas->bit_offset;
+ x &= mask;
+ if (retval)
+ *retval = x;
+ break;
+
+ case ACPI_WDAT_WRITE_VALUE:
+ x = value & mask;
+ x <<= gas->bit_offset;
+ if (preserve) {
+ ret = wdat_wdt_read(wdat, instr, &y);
+ if (ret)
+ return ret;
+ y = y & ~(mask << gas->bit_offset);
+ x |= y;
+ }
+ ret = wdat_wdt_write(wdat, instr, x);
+ if (ret)
+ return ret;
+ break;
+
+ case ACPI_WDAT_WRITE_COUNTDOWN:
+ x = param;
+ x &= mask;
+ x <<= gas->bit_offset;
+ if (preserve) {
+ ret = wdat_wdt_read(wdat, instr, &y);
+ if (ret)
+ return ret;
+ y = y & ~(mask << gas->bit_offset);
+ x |= y;
+ }
+ ret = wdat_wdt_write(wdat, instr, x);
+ if (ret)
+ return ret;
+ break;
+
+ default:
+ dev_err(&wdat->pdev->dev, "Unknown instruction: %u\n",
+ flags);
+ return -EINVAL;
+ }
+ }
+
+ return 0;
+}
+
+static int wdat_wdt_enable_reboot(struct wdat_wdt *wdat)
+{
+ int ret;
+
+ /*
+ * WDAT specification says that the watchdog is required to reboot
+ * the system when it fires. However, it also states that it is
+ * recommeded to make it configurable through hardware register. We
+ * enable reboot now if it is configrable, just in case.
+ */
+ ret = wdat_wdt_run_action(wdat, ACPI_WDAT_SET_REBOOT, 0, NULL);
+ if (ret && ret != -EOPNOTSUPP) {
+ dev_err(&wdat->pdev->dev,
+ "Failed to enable reboot when watchdog triggers\n");
+ return ret;
+ }
+
+ return 0;
+}
+
+static void wdat_wdt_boot_status(struct wdat_wdt *wdat)
+{
+ u32 boot_status = 0;
+ int ret;
+
+ ret = wdat_wdt_run_action(wdat, ACPI_WDAT_GET_STATUS, 0, &boot_status);
+ if (ret && ret != -EOPNOTSUPP) {
+ dev_err(&wdat->pdev->dev, "Failed to read boot status\n");
+ return;
+ }
+
+ if (boot_status)
+ wdat->wdd.bootstatus = WDIOF_CARDRESET;
+
+ /* Clear the boot status in case BIOS did not do it */
+ ret = wdat_wdt_run_action(wdat, ACPI_WDAT_SET_STATUS, 0, NULL);
+ if (ret && ret != -EOPNOTSUPP)
+ dev_err(&wdat->pdev->dev, "Failed to clear boot status\n");
+}
+
+static void wdat_wdt_set_running(struct wdat_wdt *wdat)
+{
+ u32 running = 0;
+ int ret;
+
+ ret = wdat_wdt_run_action(wdat, ACPI_WDAT_GET_RUNNING_STATE, 0,
+ &running);
+ if (ret && ret != -EOPNOTSUPP)
+ dev_err(&wdat->pdev->dev, "Failed to read running state\n");
+
+ if (running)
+ set_bit(WDOG_HW_RUNNING, &wdat->wdd.status);
+}
+
+static int wdat_wdt_start(struct watchdog_device *wdd)
+{
+ return wdat_wdt_run_action(to_wdat_wdt(wdd),
+ ACPI_WDAT_SET_RUNNING_STATE, 0, NULL);
+}
+
+static int wdat_wdt_stop(struct watchdog_device *wdd)
+{
+ return wdat_wdt_run_action(to_wdat_wdt(wdd),
+ ACPI_WDAT_SET_STOPPED_STATE, 0, NULL);
+}
+
+static int wdat_wdt_ping(struct watchdog_device *wdd)
+{
+ return wdat_wdt_run_action(to_wdat_wdt(wdd), ACPI_WDAT_RESET, 0, NULL);
+}
+
+static int wdat_wdt_set_timeout(struct watchdog_device *wdd,
+ unsigned int timeout)
+{
+ struct wdat_wdt *wdat = to_wdat_wdt(wdd);
+ unsigned int periods;
+ int ret;
+
+ periods = timeout * 1000 / wdat->period;
+ ret = wdat_wdt_run_action(wdat, ACPI_WDAT_SET_COUNTDOWN, periods, NULL);
+ if (!ret)
+ wdd->timeout = timeout;
+ return ret;
+}
+
+static unsigned int wdat_wdt_get_timeleft(struct watchdog_device *wdd)
+{
+ struct wdat_wdt *wdat = to_wdat_wdt(wdd);
+ u32 periods = 0;
+
+ wdat_wdt_run_action(wdat, ACPI_WDAT_GET_COUNTDOWN, 0, &periods);
+ return periods * wdat->period / 1000;
+}
+
+static const struct watchdog_info wdat_wdt_info = {
+ .options = WDIOF_SETTIMEOUT | WDIOF_KEEPALIVEPING | WDIOF_MAGICCLOSE,
+ .firmware_version = 0,
+ .identity = "wdat_wdt",
+};
+
+static const struct watchdog_ops wdat_wdt_ops = {
+ .owner = THIS_MODULE,
+ .start = wdat_wdt_start,
+ .stop = wdat_wdt_stop,
+ .ping = wdat_wdt_ping,
+ .set_timeout = wdat_wdt_set_timeout,
+ .get_timeleft = wdat_wdt_get_timeleft,
+};
+
+static int wdat_wdt_probe(struct platform_device *pdev)
+{
+ const struct acpi_wdat_entry *entries;
+ const struct acpi_table_wdat *tbl;
+ struct wdat_wdt *wdat;
+ struct resource *res;
+ void __iomem **regs;
+ acpi_status status;
+ int i, ret;
+
+ status = acpi_get_table(ACPI_SIG_WDAT, 0,
+ (struct acpi_table_header **)&tbl);
+ if (ACPI_FAILURE(status))
+ return -ENODEV;
+
+ wdat = devm_kzalloc(&pdev->dev, sizeof(*wdat), GFP_KERNEL);
+ if (!wdat)
+ return -ENOMEM;
+
+ regs = devm_kcalloc(&pdev->dev, pdev->num_resources, sizeof(*regs),
+ GFP_KERNEL);
+ if (!regs)
+ return -ENOMEM;
+
+ /* WDAT specification wants to have >= 1ms period */
+ if (tbl->timer_period < 1)
+ return -EINVAL;
+ if (tbl->min_count > tbl->max_count)
+ return -EINVAL;
+
+ wdat->period = tbl->timer_period;
+ wdat->wdd.min_hw_heartbeat_ms = wdat->period * tbl->min_count;
+ wdat->wdd.max_hw_heartbeat_ms = wdat->period * tbl->max_count;
+ wdat->stopped_in_sleep = tbl->flags & ACPI_WDAT_STOPPED;
+ wdat->wdd.info = &wdat_wdt_info;
+ wdat->wdd.ops = &wdat_wdt_ops;
+ wdat->pdev = pdev;
+
+ /* Request and map all resources */
+ for (i = 0; i < pdev->num_resources; i++) {
+ void __iomem *reg;
+
+ res = &pdev->resource[i];
+ if (resource_type(res) == IORESOURCE_MEM) {
+ reg = devm_ioremap_resource(&pdev->dev, res);
+ if (IS_ERR(reg))
+ return PTR_ERR(reg);
+ } else if (resource_type(res) == IORESOURCE_IO) {
+ reg = devm_ioport_map(&pdev->dev, res->start, 1);
+ if (!reg)
+ return -ENOMEM;
+ } else {
+ dev_err(&pdev->dev, "Unsupported resource\n");
+ return -EINVAL;
+ }
+
+ regs[i] = reg;
+ }
+
+ entries = (struct acpi_wdat_entry *)(tbl + 1);
+ for (i = 0; i < tbl->entries; i++) {
+ const struct acpi_generic_address *gas;
+ struct wdat_instruction *instr;
+ struct list_head *instructions;
+ unsigned int action;
+ struct resource r;
+ int j;
+
+ action = entries[i].action;
+ if (action >= MAX_WDAT_ACTIONS) {
+ dev_dbg(&pdev->dev, "Skipping unknown action: %u\n",
+ action);
+ continue;
+ }
+
+ instr = devm_kzalloc(&pdev->dev, sizeof(*instr), GFP_KERNEL);
+ if (!instr)
+ return -ENOMEM;
+
+ INIT_LIST_HEAD(&instr->node);
+ instr->entry = entries[i];
+
+ gas = &entries[i].register_region;
+
+ memset(&r, 0, sizeof(r));
+ r.start = gas->address;
+ r.end = r.start + gas->access_width;
+ if (gas->space_id == ACPI_ADR_SPACE_SYSTEM_MEMORY) {
+ r.flags = IORESOURCE_MEM;
+ } else if (gas->space_id == ACPI_ADR_SPACE_SYSTEM_IO) {
+ r.flags = IORESOURCE_IO;
+ } else {
+ dev_dbg(&pdev->dev, "Unsupported address space: %d\n",
+ gas->space_id);
+ continue;
+ }
+
+ /* Find the matching resource */
+ for (j = 0; j < pdev->num_resources; j++) {
+ res = &pdev->resource[j];
+ if (resource_contains(res, &r)) {
+ instr->reg = regs[j] + r.start - res->start;
+ break;
+ }
+ }
+
+ if (!instr->reg) {
+ dev_err(&pdev->dev, "I/O resource not found\n");
+ return -EINVAL;
+ }
+
+ instructions = wdat->instructions[action];
+ if (!instructions) {
+ instructions = devm_kzalloc(&pdev->dev,
+ sizeof(*instructions), GFP_KERNEL);
+ if (!instructions)
+ return -ENOMEM;
+
+ INIT_LIST_HEAD(instructions);
+ wdat->instructions[action] = instructions;
+ }
+
+ list_add_tail(&instr->node, instructions);
+ }
+
+ wdat_wdt_boot_status(wdat);
+ wdat_wdt_set_running(wdat);
+
+ ret = wdat_wdt_enable_reboot(wdat);
+ if (ret)
+ return ret;
+
+ platform_set_drvdata(pdev, wdat);
+
+ watchdog_set_nowayout(&wdat->wdd, nowayout);
+ return devm_watchdog_register_device(&pdev->dev, &wdat->wdd);
+}
+
+#ifdef CONFIG_PM_SLEEP
+static int wdat_wdt_suspend_noirq(struct device *dev)
+{
+ struct platform_device *pdev = to_platform_device(dev);
+ struct wdat_wdt *wdat = platform_get_drvdata(pdev);
+ int ret;
+
+ if (!watchdog_active(&wdat->wdd))
+ return 0;
+
+ /*
+ * We need to stop the watchdog if firmare is not doing it or if we
+ * are going suspend to idle (where firmware is not involved). If
+ * firmware is stopping the watchdog we kick it here one more time
+ * to give it some time.
+ */
+ wdat->stopped = false;
+ if (acpi_target_system_state() == ACPI_STATE_S0 ||
+ !wdat->stopped_in_sleep) {
+ ret = wdat_wdt_stop(&wdat->wdd);
+ if (!ret)
+ wdat->stopped = true;
+ } else {
+ ret = wdat_wdt_ping(&wdat->wdd);
+ }
+
+ return ret;
+}
+
+static int wdat_wdt_resume_noirq(struct device *dev)
+{
+ struct platform_device *pdev = to_platform_device(dev);
+ struct wdat_wdt *wdat = platform_get_drvdata(pdev);
+ int ret;
+
+ if (!watchdog_active(&wdat->wdd))
+ return 0;
+
+ if (!wdat->stopped) {
+ /*
+ * Looks like the boot firmware reinitializes the watchdog
+ * before it hands off to the OS on resume from sleep so we
+ * stop and reprogram the watchdog here.
+ */
+ ret = wdat_wdt_stop(&wdat->wdd);
+ if (ret)
+ return ret;
+
+ ret = wdat_wdt_set_timeout(&wdat->wdd, wdat->wdd.timeout);
+ if (ret)
+ return ret;
+
+ ret = wdat_wdt_enable_reboot(wdat);
+ if (ret)
+ return ret;
+ }
+
+ return wdat_wdt_start(&wdat->wdd);
+}
+#endif
+
+static const struct dev_pm_ops wdat_wdt_pm_ops = {
+ SET_NOIRQ_SYSTEM_SLEEP_PM_OPS(wdat_wdt_suspend_noirq,
+ wdat_wdt_resume_noirq)
+};
+
+static struct platform_driver wdat_wdt_driver = {
+ .probe = wdat_wdt_probe,
+ .driver = {
+ .name = "wdat_wdt",
+ .pm = &wdat_wdt_pm_ops,
+ },
+};
+
+module_platform_driver(wdat_wdt_driver);
+
+MODULE_AUTHOR("Mika Westerberg <mika.westerberg@linux.intel.com>");
+MODULE_DESCRIPTION("ACPI Hardware Watchdog (WDAT) driver");
+MODULE_LICENSE("GPL v2");
+MODULE_ALIAS("platform:wdat_wdt");
diff --git a/fs/Kconfig b/fs/Kconfig
index 2bc7ad7..3ef62ba 100644
--- a/fs/Kconfig
+++ b/fs/Kconfig
@@ -79,6 +79,7 @@
config FILE_LOCKING
bool "Enable POSIX file locking API" if EXPERT
default y
+ select PERCPU_RWSEM
help
This option enables standard file locking support, required
for filesystems like NFS and for the flock() system
diff --git a/fs/autofs4/expire.c b/fs/autofs4/expire.c
index b493909..d8e6d42 100644
--- a/fs/autofs4/expire.c
+++ b/fs/autofs4/expire.c
@@ -417,6 +417,7 @@
}
return NULL;
}
+
/*
* Find an eligible tree to time-out
* A tree is eligible if :-
@@ -432,6 +433,7 @@
struct dentry *root = sb->s_root;
struct dentry *dentry;
struct dentry *expired;
+ struct dentry *found;
struct autofs_info *ino;
if (!root)
@@ -442,31 +444,46 @@
dentry = NULL;
while ((dentry = get_next_positive_subdir(dentry, root))) {
+ int flags = how;
+
spin_lock(&sbi->fs_lock);
ino = autofs4_dentry_ino(dentry);
- if (ino->flags & AUTOFS_INF_WANT_EXPIRE)
- expired = NULL;
- else
- expired = should_expire(dentry, mnt, timeout, how);
- if (!expired) {
+ if (ino->flags & AUTOFS_INF_WANT_EXPIRE) {
spin_unlock(&sbi->fs_lock);
continue;
}
+ spin_unlock(&sbi->fs_lock);
+
+ expired = should_expire(dentry, mnt, timeout, flags);
+ if (!expired)
+ continue;
+
+ spin_lock(&sbi->fs_lock);
ino = autofs4_dentry_ino(expired);
ino->flags |= AUTOFS_INF_WANT_EXPIRE;
spin_unlock(&sbi->fs_lock);
synchronize_rcu();
- spin_lock(&sbi->fs_lock);
- if (should_expire(expired, mnt, timeout, how)) {
- if (expired != dentry)
- dput(dentry);
- goto found;
- }
+ /* Make sure a reference is not taken on found if
+ * things have changed.
+ */
+ flags &= ~AUTOFS_EXP_LEAVES;
+ found = should_expire(expired, mnt, timeout, how);
+ if (!found || found != expired)
+ /* Something has changed, continue */
+ goto next;
+
+ if (expired != dentry)
+ dput(dentry);
+
+ spin_lock(&sbi->fs_lock);
+ goto found;
+next:
+ spin_lock(&sbi->fs_lock);
ino->flags &= ~AUTOFS_INF_WANT_EXPIRE;
+ spin_unlock(&sbi->fs_lock);
if (expired != dentry)
dput(expired);
- spin_unlock(&sbi->fs_lock);
}
return NULL;
@@ -483,6 +500,7 @@
struct autofs_sb_info *sbi = autofs4_sbi(dentry->d_sb);
struct autofs_info *ino = autofs4_dentry_ino(dentry);
int status;
+ int state;
/* Block on any pending expire */
if (!(ino->flags & AUTOFS_INF_WANT_EXPIRE))
@@ -490,8 +508,19 @@
if (rcu_walk)
return -ECHILD;
+retry:
spin_lock(&sbi->fs_lock);
- if (ino->flags & AUTOFS_INF_EXPIRING) {
+ state = ino->flags & (AUTOFS_INF_WANT_EXPIRE | AUTOFS_INF_EXPIRING);
+ if (state == AUTOFS_INF_WANT_EXPIRE) {
+ spin_unlock(&sbi->fs_lock);
+ /*
+ * Possibly being selected for expire, wait until
+ * it's selected or not.
+ */
+ schedule_timeout_uninterruptible(HZ/10);
+ goto retry;
+ }
+ if (state & AUTOFS_INF_EXPIRING) {
spin_unlock(&sbi->fs_lock);
pr_debug("waiting for expire %p name=%pd\n", dentry, dentry);
diff --git a/fs/btrfs/extent-tree.c b/fs/btrfs/extent-tree.c
index 38c2df8..665da8f 100644
--- a/fs/btrfs/extent-tree.c
+++ b/fs/btrfs/extent-tree.c
@@ -4271,13 +4271,10 @@
if (ret < 0)
return ret;
- /*
- * Use new btrfs_qgroup_reserve_data to reserve precious data space
- *
- * TODO: Find a good method to avoid reserve data space for NOCOW
- * range, but don't impact performance on quota disable case.
- */
+ /* Use new btrfs_qgroup_reserve_data to reserve precious data space. */
ret = btrfs_qgroup_reserve_data(inode, start, len);
+ if (ret)
+ btrfs_free_reserved_data_space_noquota(inode, start, len);
return ret;
}
diff --git a/fs/btrfs/ioctl.c b/fs/btrfs/ioctl.c
index b2a2da5..7fd939b 100644
--- a/fs/btrfs/ioctl.c
+++ b/fs/btrfs/ioctl.c
@@ -1634,6 +1634,9 @@
int namelen;
int ret = 0;
+ if (!S_ISDIR(file_inode(file)->i_mode))
+ return -ENOTDIR;
+
ret = mnt_want_write_file(file);
if (ret)
goto out;
@@ -1691,6 +1694,9 @@
struct btrfs_ioctl_vol_args *vol_args;
int ret;
+ if (!S_ISDIR(file_inode(file)->i_mode))
+ return -ENOTDIR;
+
vol_args = memdup_user(arg, sizeof(*vol_args));
if (IS_ERR(vol_args))
return PTR_ERR(vol_args);
@@ -1714,6 +1720,9 @@
bool readonly = false;
struct btrfs_qgroup_inherit *inherit = NULL;
+ if (!S_ISDIR(file_inode(file)->i_mode))
+ return -ENOTDIR;
+
vol_args = memdup_user(arg, sizeof(*vol_args));
if (IS_ERR(vol_args))
return PTR_ERR(vol_args);
@@ -2357,6 +2366,9 @@
int ret;
int err = 0;
+ if (!S_ISDIR(dir->i_mode))
+ return -ENOTDIR;
+
vol_args = memdup_user(arg, sizeof(*vol_args));
if (IS_ERR(vol_args))
return PTR_ERR(vol_args);
diff --git a/fs/configfs/file.c b/fs/configfs/file.c
index c30cf49..2c6312d 100644
--- a/fs/configfs/file.c
+++ b/fs/configfs/file.c
@@ -333,6 +333,7 @@
if (bin_attr->cb_max_size &&
*ppos + count > bin_attr->cb_max_size) {
len = -EFBIG;
+ goto out;
}
tbuf = vmalloc(*ppos + count);
diff --git a/fs/efivarfs/inode.c b/fs/efivarfs/inode.c
index 1d73fc6..cbb50ca 100644
--- a/fs/efivarfs/inode.c
+++ b/fs/efivarfs/inode.c
@@ -105,7 +105,10 @@
inode->i_private = var;
- efivar_entry_add(var, &efivarfs_list);
+ err = efivar_entry_add(var, &efivarfs_list);
+ if (err)
+ goto out;
+
d_instantiate(dentry, inode);
dget(dentry);
out:
diff --git a/fs/efivarfs/super.c b/fs/efivarfs/super.c
index 688ccc1..d7a7c53 100644
--- a/fs/efivarfs/super.c
+++ b/fs/efivarfs/super.c
@@ -157,12 +157,14 @@
goto fail_inode;
}
+ efivar_entry_size(entry, &size);
+ err = efivar_entry_add(entry, &efivarfs_list);
+ if (err)
+ goto fail_inode;
+
/* copied by the above to local storage in the dentry. */
kfree(name);
- efivar_entry_size(entry, &size);
- efivar_entry_add(entry, &efivarfs_list);
-
inode_lock(inode);
inode->i_private = entry;
i_size_write(inode, size + sizeof(entry->var.Attributes));
@@ -182,7 +184,10 @@
static int efivarfs_destroy(struct efivar_entry *entry, void *data)
{
- efivar_entry_remove(entry);
+ int err = efivar_entry_remove(entry);
+
+ if (err)
+ return err;
kfree(entry);
return 0;
}
diff --git a/fs/locks.c b/fs/locks.c
index ee1b15f..133fb25 100644
--- a/fs/locks.c
+++ b/fs/locks.c
@@ -127,7 +127,6 @@
#include <linux/pid_namespace.h>
#include <linux/hashtable.h>
#include <linux/percpu.h>
-#include <linux/lglock.h>
#define CREATE_TRACE_POINTS
#include <trace/events/filelock.h>
@@ -158,12 +157,18 @@
/*
* The global file_lock_list is only used for displaying /proc/locks, so we
- * keep a list on each CPU, with each list protected by its own spinlock via
- * the file_lock_lglock. Note that alterations to the list also require that
- * the relevant flc_lock is held.
+ * keep a list on each CPU, with each list protected by its own spinlock.
+ * Global serialization is done using file_rwsem.
+ *
+ * Note that alterations to the list also require that the relevant flc_lock is
+ * held.
*/
-DEFINE_STATIC_LGLOCK(file_lock_lglock);
-static DEFINE_PER_CPU(struct hlist_head, file_lock_list);
+struct file_lock_list_struct {
+ spinlock_t lock;
+ struct hlist_head hlist;
+};
+static DEFINE_PER_CPU(struct file_lock_list_struct, file_lock_list);
+DEFINE_STATIC_PERCPU_RWSEM(file_rwsem);
/*
* The blocked_hash is used to find POSIX lock loops for deadlock detection.
@@ -587,15 +592,23 @@
/* Must be called with the flc_lock held! */
static void locks_insert_global_locks(struct file_lock *fl)
{
- lg_local_lock(&file_lock_lglock);
+ struct file_lock_list_struct *fll = this_cpu_ptr(&file_lock_list);
+
+ percpu_rwsem_assert_held(&file_rwsem);
+
+ spin_lock(&fll->lock);
fl->fl_link_cpu = smp_processor_id();
- hlist_add_head(&fl->fl_link, this_cpu_ptr(&file_lock_list));
- lg_local_unlock(&file_lock_lglock);
+ hlist_add_head(&fl->fl_link, &fll->hlist);
+ spin_unlock(&fll->lock);
}
/* Must be called with the flc_lock held! */
static void locks_delete_global_locks(struct file_lock *fl)
{
+ struct file_lock_list_struct *fll;
+
+ percpu_rwsem_assert_held(&file_rwsem);
+
/*
* Avoid taking lock if already unhashed. This is safe since this check
* is done while holding the flc_lock, and new insertions into the list
@@ -603,9 +616,11 @@
*/
if (hlist_unhashed(&fl->fl_link))
return;
- lg_local_lock_cpu(&file_lock_lglock, fl->fl_link_cpu);
+
+ fll = per_cpu_ptr(&file_lock_list, fl->fl_link_cpu);
+ spin_lock(&fll->lock);
hlist_del_init(&fl->fl_link);
- lg_local_unlock_cpu(&file_lock_lglock, fl->fl_link_cpu);
+ spin_unlock(&fll->lock);
}
static unsigned long
@@ -915,6 +930,7 @@
return -ENOMEM;
}
+ percpu_down_read_preempt_disable(&file_rwsem);
spin_lock(&ctx->flc_lock);
if (request->fl_flags & FL_ACCESS)
goto find_conflict;
@@ -955,6 +971,7 @@
out:
spin_unlock(&ctx->flc_lock);
+ percpu_up_read_preempt_enable(&file_rwsem);
if (new_fl)
locks_free_lock(new_fl);
locks_dispose_list(&dispose);
@@ -991,6 +1008,7 @@
new_fl2 = locks_alloc_lock();
}
+ percpu_down_read_preempt_disable(&file_rwsem);
spin_lock(&ctx->flc_lock);
/*
* New lock request. Walk all POSIX locks and look for conflicts. If
@@ -1162,6 +1180,7 @@
}
out:
spin_unlock(&ctx->flc_lock);
+ percpu_up_read_preempt_enable(&file_rwsem);
/*
* Free any unused locks.
*/
@@ -1436,6 +1455,7 @@
return error;
}
+ percpu_down_read_preempt_disable(&file_rwsem);
spin_lock(&ctx->flc_lock);
time_out_leases(inode, &dispose);
@@ -1487,9 +1507,13 @@
locks_insert_block(fl, new_fl);
trace_break_lease_block(inode, new_fl);
spin_unlock(&ctx->flc_lock);
+ percpu_up_read_preempt_enable(&file_rwsem);
+
locks_dispose_list(&dispose);
error = wait_event_interruptible_timeout(new_fl->fl_wait,
!new_fl->fl_next, break_time);
+
+ percpu_down_read_preempt_disable(&file_rwsem);
spin_lock(&ctx->flc_lock);
trace_break_lease_unblock(inode, new_fl);
locks_delete_block(new_fl);
@@ -1506,6 +1530,7 @@
}
out:
spin_unlock(&ctx->flc_lock);
+ percpu_up_read_preempt_enable(&file_rwsem);
locks_dispose_list(&dispose);
locks_free_lock(new_fl);
return error;
@@ -1660,6 +1685,7 @@
return -EINVAL;
}
+ percpu_down_read_preempt_disable(&file_rwsem);
spin_lock(&ctx->flc_lock);
time_out_leases(inode, &dispose);
error = check_conflicting_open(dentry, arg, lease->fl_flags);
@@ -1730,6 +1756,7 @@
lease->fl_lmops->lm_setup(lease, priv);
out:
spin_unlock(&ctx->flc_lock);
+ percpu_up_read_preempt_enable(&file_rwsem);
locks_dispose_list(&dispose);
if (is_deleg)
inode_unlock(inode);
@@ -1752,6 +1779,7 @@
return error;
}
+ percpu_down_read_preempt_disable(&file_rwsem);
spin_lock(&ctx->flc_lock);
list_for_each_entry(fl, &ctx->flc_lease, fl_list) {
if (fl->fl_file == filp &&
@@ -1764,6 +1792,7 @@
if (victim)
error = fl->fl_lmops->lm_change(victim, F_UNLCK, &dispose);
spin_unlock(&ctx->flc_lock);
+ percpu_up_read_preempt_enable(&file_rwsem);
locks_dispose_list(&dispose);
return error;
}
@@ -2703,9 +2732,9 @@
struct locks_iterator *iter = f->private;
iter->li_pos = *pos + 1;
- lg_global_lock(&file_lock_lglock);
+ percpu_down_write(&file_rwsem);
spin_lock(&blocked_lock_lock);
- return seq_hlist_start_percpu(&file_lock_list, &iter->li_cpu, *pos);
+ return seq_hlist_start_percpu(&file_lock_list.hlist, &iter->li_cpu, *pos);
}
static void *locks_next(struct seq_file *f, void *v, loff_t *pos)
@@ -2713,14 +2742,14 @@
struct locks_iterator *iter = f->private;
++iter->li_pos;
- return seq_hlist_next_percpu(v, &file_lock_list, &iter->li_cpu, pos);
+ return seq_hlist_next_percpu(v, &file_lock_list.hlist, &iter->li_cpu, pos);
}
static void locks_stop(struct seq_file *f, void *v)
__releases(&blocked_lock_lock)
{
spin_unlock(&blocked_lock_lock);
- lg_global_unlock(&file_lock_lglock);
+ percpu_up_write(&file_rwsem);
}
static const struct seq_operations locks_seq_operations = {
@@ -2761,10 +2790,13 @@
filelock_cache = kmem_cache_create("file_lock_cache",
sizeof(struct file_lock), 0, SLAB_PANIC, NULL);
- lg_lock_init(&file_lock_lglock, "file_lock_lglock");
- for_each_possible_cpu(i)
- INIT_HLIST_HEAD(per_cpu_ptr(&file_lock_list, i));
+ for_each_possible_cpu(i) {
+ struct file_lock_list_struct *fll = per_cpu_ptr(&file_lock_list, i);
+
+ spin_lock_init(&fll->lock);
+ INIT_HLIST_HEAD(&fll->hlist);
+ }
return 0;
}
diff --git a/fs/notify/fanotify/fanotify.c b/fs/notify/fanotify/fanotify.c
index d2f97ec..e0e5f7c 100644
--- a/fs/notify/fanotify/fanotify.c
+++ b/fs/notify/fanotify/fanotify.c
@@ -67,18 +67,7 @@
pr_debug("%s: group=%p event=%p\n", __func__, group, event);
- wait_event(group->fanotify_data.access_waitq, event->response ||
- atomic_read(&group->fanotify_data.bypass_perm));
-
- if (!event->response) { /* bypass_perm set */
- /*
- * Event was canceled because group is being destroyed. Remove
- * it from group's event list because we are responsible for
- * freeing the permission event.
- */
- fsnotify_remove_event(group, &event->fae.fse);
- return 0;
- }
+ wait_event(group->fanotify_data.access_waitq, event->response);
/* userspace responded, convert to something usable */
switch (event->response) {
diff --git a/fs/notify/fanotify/fanotify_user.c b/fs/notify/fanotify/fanotify_user.c
index 8e8e6bc..a643138 100644
--- a/fs/notify/fanotify/fanotify_user.c
+++ b/fs/notify/fanotify/fanotify_user.c
@@ -358,16 +358,20 @@
#ifdef CONFIG_FANOTIFY_ACCESS_PERMISSIONS
struct fanotify_perm_event_info *event, *next;
+ struct fsnotify_event *fsn_event;
/*
- * There may be still new events arriving in the notification queue
- * but since userspace cannot use fanotify fd anymore, no event can
- * enter or leave access_list by now.
+ * Stop new events from arriving in the notification queue. since
+ * userspace cannot use fanotify fd anymore, no event can enter or
+ * leave access_list by now either.
+ */
+ fsnotify_group_stop_queueing(group);
+
+ /*
+ * Process all permission events on access_list and notification queue
+ * and simulate reply from userspace.
*/
spin_lock(&group->fanotify_data.access_lock);
-
- atomic_inc(&group->fanotify_data.bypass_perm);
-
list_for_each_entry_safe(event, next, &group->fanotify_data.access_list,
fae.fse.list) {
pr_debug("%s: found group=%p event=%p\n", __func__, group,
@@ -379,12 +383,21 @@
spin_unlock(&group->fanotify_data.access_lock);
/*
- * Since bypass_perm is set, newly queued events will not wait for
- * access response. Wake up the already sleeping ones now.
- * synchronize_srcu() in fsnotify_destroy_group() will wait for all
- * processes sleeping in fanotify_handle_event() waiting for access
- * response and thus also for all permission events to be freed.
+ * Destroy all non-permission events. For permission events just
+ * dequeue them and set the response. They will be freed once the
+ * response is consumed and fanotify_get_response() returns.
*/
+ mutex_lock(&group->notification_mutex);
+ while (!fsnotify_notify_queue_is_empty(group)) {
+ fsn_event = fsnotify_remove_first_event(group);
+ if (!(fsn_event->mask & FAN_ALL_PERM_EVENTS))
+ fsnotify_destroy_event(group, fsn_event);
+ else
+ FANOTIFY_PE(fsn_event)->response = FAN_ALLOW;
+ }
+ mutex_unlock(&group->notification_mutex);
+
+ /* Response for all permission events it set, wakeup waiters */
wake_up(&group->fanotify_data.access_waitq);
#endif
@@ -755,7 +768,6 @@
spin_lock_init(&group->fanotify_data.access_lock);
init_waitqueue_head(&group->fanotify_data.access_waitq);
INIT_LIST_HEAD(&group->fanotify_data.access_list);
- atomic_set(&group->fanotify_data.bypass_perm, 0);
#endif
switch (flags & FAN_ALL_CLASS_BITS) {
case FAN_CLASS_NOTIF:
diff --git a/fs/notify/group.c b/fs/notify/group.c
index 3e2dd85..b47f7cf 100644
--- a/fs/notify/group.c
+++ b/fs/notify/group.c
@@ -40,6 +40,17 @@
}
/*
+ * Stop queueing new events for this group. Once this function returns
+ * fsnotify_add_event() will not add any new events to the group's queue.
+ */
+void fsnotify_group_stop_queueing(struct fsnotify_group *group)
+{
+ mutex_lock(&group->notification_mutex);
+ group->shutdown = true;
+ mutex_unlock(&group->notification_mutex);
+}
+
+/*
* Trying to get rid of a group. Remove all marks, flush all events and release
* the group reference.
* Note that another thread calling fsnotify_clear_marks_by_group() may still
@@ -47,6 +58,14 @@
*/
void fsnotify_destroy_group(struct fsnotify_group *group)
{
+ /*
+ * Stop queueing new events. The code below is careful enough to not
+ * require this but fanotify needs to stop queuing events even before
+ * fsnotify_destroy_group() is called and this makes the other callers
+ * of fsnotify_destroy_group() to see the same behavior.
+ */
+ fsnotify_group_stop_queueing(group);
+
/* clear all inode marks for this group, attach them to destroy_list */
fsnotify_detach_group_marks(group);
diff --git a/fs/notify/notification.c b/fs/notify/notification.c
index a95d8e0..e455e83 100644
--- a/fs/notify/notification.c
+++ b/fs/notify/notification.c
@@ -82,7 +82,8 @@
* Add an event to the group notification queue. The group can later pull this
* event off the queue to deal with. The function returns 0 if the event was
* added to the queue, 1 if the event was merged with some other queued event,
- * 2 if the queue of events has overflown.
+ * 2 if the event was not queued - either the queue of events has overflown
+ * or the group is shutting down.
*/
int fsnotify_add_event(struct fsnotify_group *group,
struct fsnotify_event *event,
@@ -96,6 +97,11 @@
mutex_lock(&group->notification_mutex);
+ if (group->shutdown) {
+ mutex_unlock(&group->notification_mutex);
+ return 2;
+ }
+
if (group->q_len >= group->max_events) {
ret = 2;
/* Queue overflow event only if it isn't already queued */
@@ -126,21 +132,6 @@
}
/*
- * Remove @event from group's notification queue. It is the responsibility of
- * the caller to destroy the event.
- */
-void fsnotify_remove_event(struct fsnotify_group *group,
- struct fsnotify_event *event)
-{
- mutex_lock(&group->notification_mutex);
- if (!list_empty(&event->list)) {
- list_del_init(&event->list);
- group->q_len--;
- }
- mutex_unlock(&group->notification_mutex);
-}
-
-/*
* Remove and return the first event from the notification list. It is the
* responsibility of the caller to destroy the obtained event
*/
diff --git a/fs/ocfs2/alloc.c b/fs/ocfs2/alloc.c
index 7dabbc3..f165f86 100644
--- a/fs/ocfs2/alloc.c
+++ b/fs/ocfs2/alloc.c
@@ -5922,7 +5922,6 @@
}
static int ocfs2_replay_truncate_records(struct ocfs2_super *osb,
- handle_t *handle,
struct inode *data_alloc_inode,
struct buffer_head *data_alloc_bh)
{
@@ -5935,11 +5934,19 @@
struct ocfs2_truncate_log *tl;
struct inode *tl_inode = osb->osb_tl_inode;
struct buffer_head *tl_bh = osb->osb_tl_bh;
+ handle_t *handle;
di = (struct ocfs2_dinode *) tl_bh->b_data;
tl = &di->id2.i_dealloc;
i = le16_to_cpu(tl->tl_used) - 1;
while (i >= 0) {
+ handle = ocfs2_start_trans(osb, OCFS2_TRUNCATE_LOG_FLUSH_ONE_REC);
+ if (IS_ERR(handle)) {
+ status = PTR_ERR(handle);
+ mlog_errno(status);
+ goto bail;
+ }
+
/* Caller has given us at least enough credits to
* update the truncate log dinode */
status = ocfs2_journal_access_di(handle, INODE_CACHE(tl_inode), tl_bh,
@@ -5974,12 +5981,7 @@
}
}
- status = ocfs2_extend_trans(handle,
- OCFS2_TRUNCATE_LOG_FLUSH_ONE_REC);
- if (status < 0) {
- mlog_errno(status);
- goto bail;
- }
+ ocfs2_commit_trans(osb, handle);
i--;
}
@@ -5994,7 +5996,6 @@
{
int status;
unsigned int num_to_flush;
- handle_t *handle;
struct inode *tl_inode = osb->osb_tl_inode;
struct inode *data_alloc_inode = NULL;
struct buffer_head *tl_bh = osb->osb_tl_bh;
@@ -6038,21 +6039,11 @@
goto out_mutex;
}
- handle = ocfs2_start_trans(osb, OCFS2_TRUNCATE_LOG_FLUSH_ONE_REC);
- if (IS_ERR(handle)) {
- status = PTR_ERR(handle);
- mlog_errno(status);
- goto out_unlock;
- }
-
- status = ocfs2_replay_truncate_records(osb, handle, data_alloc_inode,
+ status = ocfs2_replay_truncate_records(osb, data_alloc_inode,
data_alloc_bh);
if (status < 0)
mlog_errno(status);
- ocfs2_commit_trans(osb, handle);
-
-out_unlock:
brelse(data_alloc_bh);
ocfs2_inode_unlock(data_alloc_inode, 1);
@@ -6413,43 +6404,34 @@
goto out_mutex;
}
- handle = ocfs2_start_trans(osb, OCFS2_SUBALLOC_FREE);
- if (IS_ERR(handle)) {
- ret = PTR_ERR(handle);
- mlog_errno(ret);
- goto out_unlock;
- }
-
while (head) {
if (head->free_bg)
bg_blkno = head->free_bg;
else
bg_blkno = ocfs2_which_suballoc_group(head->free_blk,
head->free_bit);
+ handle = ocfs2_start_trans(osb, OCFS2_SUBALLOC_FREE);
+ if (IS_ERR(handle)) {
+ ret = PTR_ERR(handle);
+ mlog_errno(ret);
+ goto out_unlock;
+ }
+
trace_ocfs2_free_cached_blocks(
(unsigned long long)head->free_blk, head->free_bit);
ret = ocfs2_free_suballoc_bits(handle, inode, di_bh,
head->free_bit, bg_blkno, 1);
- if (ret) {
+ if (ret)
mlog_errno(ret);
- goto out_journal;
- }
- ret = ocfs2_extend_trans(handle, OCFS2_SUBALLOC_FREE);
- if (ret) {
- mlog_errno(ret);
- goto out_journal;
- }
+ ocfs2_commit_trans(osb, handle);
tmp = head;
head = head->free_next;
kfree(tmp);
}
-out_journal:
- ocfs2_commit_trans(osb, handle);
-
out_unlock:
ocfs2_inode_unlock(inode, 1);
brelse(di_bh);
diff --git a/fs/ocfs2/aops.c b/fs/ocfs2/aops.c
index 98d3654..bbb4b3e 100644
--- a/fs/ocfs2/aops.c
+++ b/fs/ocfs2/aops.c
@@ -1842,6 +1842,16 @@
ocfs2_commit_trans(osb, handle);
out:
+ /*
+ * The mmapped page won't be unlocked in ocfs2_free_write_ctxt(),
+ * even in case of error here like ENOSPC and ENOMEM. So, we need
+ * to unlock the target page manually to prevent deadlocks when
+ * retrying again on ENOSPC, or when returning non-VM_FAULT_LOCKED
+ * to VM code.
+ */
+ if (wc->w_target_locked)
+ unlock_page(mmap_page);
+
ocfs2_free_write_ctxt(inode, wc);
if (data_ac) {
diff --git a/fs/ocfs2/cluster/tcp_internal.h b/fs/ocfs2/cluster/tcp_internal.h
index 94b1836..b95e7df 100644
--- a/fs/ocfs2/cluster/tcp_internal.h
+++ b/fs/ocfs2/cluster/tcp_internal.h
@@ -44,9 +44,6 @@
* version here in tcp_internal.h should not need to be bumped for
* filesystem locking changes.
*
- * New in version 12
- * - Negotiate hb timeout when storage is down.
- *
* New in version 11
* - Negotiation of filesystem locking in the dlm join.
*
@@ -78,7 +75,7 @@
* - full 64 bit i_size in the metadata lock lvbs
* - introduction of "rw" lock and pushing meta/data locking down
*/
-#define O2NET_PROTOCOL_VERSION 12ULL
+#define O2NET_PROTOCOL_VERSION 11ULL
struct o2net_handshake {
__be64 protocol_version;
__be64 connector_id;
diff --git a/fs/ocfs2/dlm/dlmconvert.c b/fs/ocfs2/dlm/dlmconvert.c
index cdeafb4..0bb1286 100644
--- a/fs/ocfs2/dlm/dlmconvert.c
+++ b/fs/ocfs2/dlm/dlmconvert.c
@@ -268,7 +268,6 @@
struct dlm_lock *lock, int flags, int type)
{
enum dlm_status status;
- u8 old_owner = res->owner;
mlog(0, "type=%d, convert_type=%d, busy=%d\n", lock->ml.type,
lock->ml.convert_type, res->state & DLM_LOCK_RES_IN_PROGRESS);
@@ -335,7 +334,6 @@
spin_lock(&res->spinlock);
res->state &= ~DLM_LOCK_RES_IN_PROGRESS;
- lock->convert_pending = 0;
/* if it failed, move it back to granted queue.
* if master returns DLM_NORMAL and then down before sending ast,
* it may have already been moved to granted queue, reset to
@@ -344,12 +342,14 @@
if (status != DLM_NOTQUEUED)
dlm_error(status);
dlm_revert_pending_convert(res, lock);
- } else if ((res->state & DLM_LOCK_RES_RECOVERING) ||
- (old_owner != res->owner)) {
- mlog(0, "res %.*s is in recovering or has been recovered.\n",
- res->lockname.len, res->lockname.name);
+ } else if (!lock->convert_pending) {
+ mlog(0, "%s: res %.*s, owner died and lock has been moved back "
+ "to granted list, retry convert.\n",
+ dlm->name, res->lockname.len, res->lockname.name);
status = DLM_RECOVERING;
}
+
+ lock->convert_pending = 0;
bail:
spin_unlock(&res->spinlock);
diff --git a/fs/ocfs2/file.c b/fs/ocfs2/file.c
index 4e7b0dc..0b055bf 100644
--- a/fs/ocfs2/file.c
+++ b/fs/ocfs2/file.c
@@ -1506,7 +1506,8 @@
u64 start, u64 len)
{
int ret = 0;
- u64 tmpend, end = start + len;
+ u64 tmpend = 0;
+ u64 end = start + len;
struct ocfs2_super *osb = OCFS2_SB(inode->i_sb);
unsigned int csize = osb->s_clustersize;
handle_t *handle;
@@ -1538,18 +1539,31 @@
}
/*
- * We want to get the byte offset of the end of the 1st cluster.
+ * If start is on a cluster boundary and end is somewhere in another
+ * cluster, we have not COWed the cluster starting at start, unless
+ * end is also within the same cluster. So, in this case, we skip this
+ * first call to ocfs2_zero_range_for_truncate() truncate and move on
+ * to the next one.
*/
- tmpend = (u64)osb->s_clustersize + (start & ~(osb->s_clustersize - 1));
- if (tmpend > end)
- tmpend = end;
+ if ((start & (csize - 1)) != 0) {
+ /*
+ * We want to get the byte offset of the end of the 1st
+ * cluster.
+ */
+ tmpend = (u64)osb->s_clustersize +
+ (start & ~(osb->s_clustersize - 1));
+ if (tmpend > end)
+ tmpend = end;
- trace_ocfs2_zero_partial_clusters_range1((unsigned long long)start,
- (unsigned long long)tmpend);
+ trace_ocfs2_zero_partial_clusters_range1(
+ (unsigned long long)start,
+ (unsigned long long)tmpend);
- ret = ocfs2_zero_range_for_truncate(inode, handle, start, tmpend);
- if (ret)
- mlog_errno(ret);
+ ret = ocfs2_zero_range_for_truncate(inode, handle, start,
+ tmpend);
+ if (ret)
+ mlog_errno(ret);
+ }
if (tmpend < end) {
/*
diff --git a/fs/ocfs2/suballoc.c b/fs/ocfs2/suballoc.c
index ea47120..6ad3533 100644
--- a/fs/ocfs2/suballoc.c
+++ b/fs/ocfs2/suballoc.c
@@ -1199,14 +1199,24 @@
inode_unlock((*ac)->ac_inode);
ret = ocfs2_try_to_free_truncate_log(osb, bits_wanted);
- if (ret == 1)
+ if (ret == 1) {
+ iput((*ac)->ac_inode);
+ (*ac)->ac_inode = NULL;
goto retry;
+ }
if (ret < 0)
mlog_errno(ret);
inode_lock((*ac)->ac_inode);
- ocfs2_inode_lock((*ac)->ac_inode, NULL, 1);
+ ret = ocfs2_inode_lock((*ac)->ac_inode, NULL, 1);
+ if (ret < 0) {
+ mlog_errno(ret);
+ inode_unlock((*ac)->ac_inode);
+ iput((*ac)->ac_inode);
+ (*ac)->ac_inode = NULL;
+ goto bail;
+ }
}
if (status < 0) {
if (status != -ENOSPC)
diff --git a/fs/proc/kcore.c b/fs/proc/kcore.c
index a939f5e..5c89a07 100644
--- a/fs/proc/kcore.c
+++ b/fs/proc/kcore.c
@@ -430,6 +430,7 @@
static ssize_t
read_kcore(struct file *file, char __user *buffer, size_t buflen, loff_t *fpos)
{
+ char *buf = file->private_data;
ssize_t acc = 0;
size_t size, tsz;
size_t elf_buflen;
@@ -500,23 +501,20 @@
if (clear_user(buffer, tsz))
return -EFAULT;
} else if (is_vmalloc_or_module_addr((void *)start)) {
- char * elf_buf;
-
- elf_buf = kzalloc(tsz, GFP_KERNEL);
- if (!elf_buf)
- return -ENOMEM;
- vread(elf_buf, (char *)start, tsz);
+ vread(buf, (char *)start, tsz);
/* we have to zero-fill user buffer even if no read */
- if (copy_to_user(buffer, elf_buf, tsz)) {
- kfree(elf_buf);
+ if (copy_to_user(buffer, buf, tsz))
return -EFAULT;
- }
- kfree(elf_buf);
} else {
if (kern_addr_valid(start)) {
unsigned long n;
- n = copy_to_user(buffer, (char *)start, tsz);
+ /*
+ * Using bounce buffer to bypass the
+ * hardened user copy kernel text checks.
+ */
+ memcpy(buf, (char *) start, tsz);
+ n = copy_to_user(buffer, buf, tsz);
/*
* We cannot distinguish between fault on source
* and fault on destination. When this happens
@@ -549,6 +547,11 @@
{
if (!capable(CAP_SYS_RAWIO))
return -EPERM;
+
+ filp->private_data = kmalloc(PAGE_SIZE, GFP_KERNEL);
+ if (!filp->private_data)
+ return -ENOMEM;
+
if (kcore_need_update)
kcore_update_ram();
if (i_size_read(inode) != proc_root_kcore->size) {
@@ -559,10 +562,16 @@
return 0;
}
+static int release_kcore(struct inode *inode, struct file *file)
+{
+ kfree(file->private_data);
+ return 0;
+}
static const struct file_operations proc_kcore_operations = {
.read = read_kcore,
.open = open_kcore,
+ .release = release_kcore,
.llseek = default_llseek,
};
diff --git a/fs/ramfs/file-mmu.c b/fs/ramfs/file-mmu.c
index 183a212..12af049 100644
--- a/fs/ramfs/file-mmu.c
+++ b/fs/ramfs/file-mmu.c
@@ -27,9 +27,17 @@
#include <linux/fs.h>
#include <linux/mm.h>
#include <linux/ramfs.h>
+#include <linux/sched.h>
#include "internal.h"
+static unsigned long ramfs_mmu_get_unmapped_area(struct file *file,
+ unsigned long addr, unsigned long len, unsigned long pgoff,
+ unsigned long flags)
+{
+ return current->mm->get_unmapped_area(file, addr, len, pgoff, flags);
+}
+
const struct file_operations ramfs_file_operations = {
.read_iter = generic_file_read_iter,
.write_iter = generic_file_write_iter,
@@ -38,6 +46,7 @@
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.llseek = generic_file_llseek,
+ .get_unmapped_area = ramfs_mmu_get_unmapped_area,
};
const struct inode_operations ramfs_file_inode_operations = {
diff --git a/include/acpi/acconfig.h b/include/acpi/acconfig.h
index fe2e3ac..12c2882 100644
--- a/include/acpi/acconfig.h
+++ b/include/acpi/acconfig.h
@@ -144,6 +144,10 @@
#define ACPI_ADDRESS_RANGE_MAX 2
+/* Maximum number of While() loops before abort */
+
+#define ACPI_MAX_LOOP_COUNT 0xFFFF
+
/******************************************************************************
*
* ACPI Specification constants (Do not change unless the specification changes)
diff --git a/include/acpi/acoutput.h b/include/acpi/acoutput.h
index 34f601e..48eb4dd 100644
--- a/include/acpi/acoutput.h
+++ b/include/acpi/acoutput.h
@@ -366,7 +366,7 @@
ACPI_TRACE_ENTRY (name, acpi_ut_trace_u32, u32, value)
#define ACPI_FUNCTION_TRACE_STR(name, string) \
- ACPI_TRACE_ENTRY (name, acpi_ut_trace_str, char *, string)
+ ACPI_TRACE_ENTRY (name, acpi_ut_trace_str, const char *, string)
#define ACPI_FUNCTION_ENTRY() \
acpi_ut_track_stack_ptr()
@@ -425,6 +425,9 @@
#define return_PTR(pointer) \
ACPI_TRACE_EXIT (acpi_ut_ptr_exit, void *, pointer)
+#define return_STR(string) \
+ ACPI_TRACE_EXIT (acpi_ut_str_exit, const char *, string)
+
#define return_VALUE(value) \
ACPI_TRACE_EXIT (acpi_ut_value_exit, u64, value)
@@ -478,6 +481,7 @@
#define return_VOID return
#define return_ACPI_STATUS(s) return(s)
#define return_PTR(s) return(s)
+#define return_STR(s) return(s)
#define return_VALUE(s) return(s)
#define return_UINT8(s) return(s)
#define return_UINT32(s) return(s)
diff --git a/include/acpi/acpiosxf.h b/include/acpi/acpiosxf.h
index 562603d..f3414c8 100644
--- a/include/acpi/acpiosxf.h
+++ b/include/acpi/acpiosxf.h
@@ -371,6 +371,12 @@
acpi_status acpi_os_notify_command_complete(void);
#endif
+#ifndef ACPI_USE_ALTERNATE_PROTOTYPE_acpi_os_trace_point
+void
+acpi_os_trace_point(acpi_trace_event_type type,
+ u8 begin, u8 *aml, char *pathname);
+#endif
+
/*
* Obtain ACPI table(s)
*/
@@ -416,41 +422,4 @@
void acpi_os_close_directory(void *dir_handle);
#endif
-/*
- * File I/O and related support
- */
-#ifndef ACPI_USE_ALTERNATE_PROTOTYPE_acpi_os_open_file
-ACPI_FILE acpi_os_open_file(const char *path, u8 modes);
-#endif
-
-#ifndef ACPI_USE_ALTERNATE_PROTOTYPE_acpi_os_close_file
-void acpi_os_close_file(ACPI_FILE file);
-#endif
-
-#ifndef ACPI_USE_ALTERNATE_PROTOTYPE_acpi_os_read_file
-int
-acpi_os_read_file(ACPI_FILE file,
- void *buffer, acpi_size size, acpi_size count);
-#endif
-
-#ifndef ACPI_USE_ALTERNATE_PROTOTYPE_acpi_os_write_file
-int
-acpi_os_write_file(ACPI_FILE file,
- void *buffer, acpi_size size, acpi_size count);
-#endif
-
-#ifndef ACPI_USE_ALTERNATE_PROTOTYPE_acpi_os_get_file_offset
-long acpi_os_get_file_offset(ACPI_FILE file);
-#endif
-
-#ifndef ACPI_USE_ALTERNATE_PROTOTYPE_acpi_os_set_file_offset
-acpi_status acpi_os_set_file_offset(ACPI_FILE file, long offset, u8 from);
-#endif
-
-#ifndef ACPI_USE_ALTERNATE_PROTOTYPE_acpi_os_trace_point
-void
-acpi_os_trace_point(acpi_trace_event_type type,
- u8 begin, u8 *aml, char *pathname);
-#endif
-
#endif /* __ACPIOSXF_H__ */
diff --git a/include/acpi/acpixf.h b/include/acpi/acpixf.h
index 1ff3a76..c7b3a13 100644
--- a/include/acpi/acpixf.h
+++ b/include/acpi/acpixf.h
@@ -46,7 +46,7 @@
/* Current ACPICA subsystem version in YYYYMMDD format */
-#define ACPI_CA_VERSION 0x20160422
+#define ACPI_CA_VERSION 0x20160831
#include <acpi/acconfig.h>
#include <acpi/actypes.h>
@@ -195,6 +195,13 @@
ACPI_INIT_GLOBAL(u8, acpi_gbl_group_module_level_code, TRUE);
/*
+ * Optionally support module level code by parsing the entire table as
+ * a term_list. Default is FALSE, do not execute entire table until some
+ * lock order issues are fixed.
+ */
+ACPI_INIT_GLOBAL(u8, acpi_gbl_parse_table_as_term_list, FALSE);
+
+/*
* Optionally use 32-bit FADT addresses if and when there is a conflict
* (address mismatch) between the 32-bit and 64-bit versions of the
* address. Although ACPICA adheres to the ACPI specification which
@@ -416,18 +423,19 @@
/*
* Initialization
*/
-ACPI_EXTERNAL_RETURN_STATUS(acpi_status __init
+ACPI_EXTERNAL_RETURN_STATUS(acpi_status ACPI_INIT_FUNCTION
acpi_initialize_tables(struct acpi_table_desc
*initial_storage,
u32 initial_table_count,
u8 allow_resize))
-ACPI_EXTERNAL_RETURN_STATUS(acpi_status __init acpi_initialize_subsystem(void))
-
-ACPI_EXTERNAL_RETURN_STATUS(acpi_status __init acpi_enable_subsystem(u32 flags))
-
-ACPI_EXTERNAL_RETURN_STATUS(acpi_status __init
- acpi_initialize_objects(u32 flags))
-ACPI_EXTERNAL_RETURN_STATUS(acpi_status __init acpi_terminate(void))
+ACPI_EXTERNAL_RETURN_STATUS(acpi_status ACPI_INIT_FUNCTION
+ acpi_initialize_subsystem(void))
+ACPI_EXTERNAL_RETURN_STATUS(acpi_status ACPI_INIT_FUNCTION
+ acpi_enable_subsystem(u32 flags))
+ACPI_EXTERNAL_RETURN_STATUS(acpi_status ACPI_INIT_FUNCTION
+ acpi_initialize_objects(u32 flags))
+ACPI_EXTERNAL_RETURN_STATUS(acpi_status ACPI_INIT_FUNCTION
+ acpi_terminate(void))
/*
* Miscellaneous global interfaces
@@ -467,7 +475,7 @@
/*
* ACPI table load/unload interfaces
*/
-ACPI_EXTERNAL_RETURN_STATUS(acpi_status __init
+ACPI_EXTERNAL_RETURN_STATUS(acpi_status ACPI_INIT_FUNCTION
acpi_install_table(acpi_physical_address address,
u8 physical))
@@ -476,14 +484,17 @@
ACPI_EXTERNAL_RETURN_STATUS(acpi_status
acpi_unload_parent_table(acpi_handle object))
-ACPI_EXTERNAL_RETURN_STATUS(acpi_status __init acpi_load_tables(void))
+
+ACPI_EXTERNAL_RETURN_STATUS(acpi_status ACPI_INIT_FUNCTION
+ acpi_load_tables(void))
/*
* ACPI table manipulation interfaces
*/
-ACPI_EXTERNAL_RETURN_STATUS(acpi_status __init acpi_reallocate_root_table(void))
+ACPI_EXTERNAL_RETURN_STATUS(acpi_status ACPI_INIT_FUNCTION
+ acpi_reallocate_root_table(void))
-ACPI_EXTERNAL_RETURN_STATUS(acpi_status __init
+ACPI_EXTERNAL_RETURN_STATUS(acpi_status ACPI_INIT_FUNCTION
acpi_find_root_pointer(acpi_physical_address
*rsdp_address))
ACPI_EXTERNAL_RETURN_STATUS(acpi_status
@@ -732,6 +743,10 @@
u32 gpe_number))
ACPI_HW_DEPENDENT_RETURN_STATUS(acpi_status
+ acpi_mask_gpe(acpi_handle gpe_device,
+ u32 gpe_number, u8 is_masked))
+
+ACPI_HW_DEPENDENT_RETURN_STATUS(acpi_status
acpi_mark_gpe_for_wake(acpi_handle gpe_device,
u32 gpe_number))
@@ -935,9 +950,6 @@
acpi_trace_point(acpi_trace_event_type type,
u8 begin,
u8 *aml, char *pathname))
-ACPI_APP_DEPENDENT_RETURN_VOID(ACPI_PRINTF_LIKE(1)
- void ACPI_INTERNAL_VAR_XFACE
- acpi_log_error(const char *format, ...))
acpi_status acpi_initialize_debugger(void);
diff --git a/include/acpi/actbl.h b/include/acpi/actbl.h
index c19700e..1b949e0 100644
--- a/include/acpi/actbl.h
+++ b/include/acpi/actbl.h
@@ -230,62 +230,72 @@
/* Fields common to all versions of the FADT */
struct acpi_table_fadt {
- struct acpi_table_header header; /* Common ACPI table header */
- u32 facs; /* 32-bit physical address of FACS */
- u32 dsdt; /* 32-bit physical address of DSDT */
- u8 model; /* System Interrupt Model (ACPI 1.0) - not used in ACPI 2.0+ */
- u8 preferred_profile; /* Conveys preferred power management profile to OSPM. */
- u16 sci_interrupt; /* System vector of SCI interrupt */
- u32 smi_command; /* 32-bit Port address of SMI command port */
- u8 acpi_enable; /* Value to write to SMI_CMD to enable ACPI */
- u8 acpi_disable; /* Value to write to SMI_CMD to disable ACPI */
- u8 s4_bios_request; /* Value to write to SMI_CMD to enter S4BIOS state */
- u8 pstate_control; /* Processor performance state control */
- u32 pm1a_event_block; /* 32-bit port address of Power Mgt 1a Event Reg Blk */
- u32 pm1b_event_block; /* 32-bit port address of Power Mgt 1b Event Reg Blk */
- u32 pm1a_control_block; /* 32-bit port address of Power Mgt 1a Control Reg Blk */
- u32 pm1b_control_block; /* 32-bit port address of Power Mgt 1b Control Reg Blk */
- u32 pm2_control_block; /* 32-bit port address of Power Mgt 2 Control Reg Blk */
- u32 pm_timer_block; /* 32-bit port address of Power Mgt Timer Ctrl Reg Blk */
- u32 gpe0_block; /* 32-bit port address of General Purpose Event 0 Reg Blk */
- u32 gpe1_block; /* 32-bit port address of General Purpose Event 1 Reg Blk */
- u8 pm1_event_length; /* Byte Length of ports at pm1x_event_block */
- u8 pm1_control_length; /* Byte Length of ports at pm1x_control_block */
- u8 pm2_control_length; /* Byte Length of ports at pm2_control_block */
- u8 pm_timer_length; /* Byte Length of ports at pm_timer_block */
- u8 gpe0_block_length; /* Byte Length of ports at gpe0_block */
- u8 gpe1_block_length; /* Byte Length of ports at gpe1_block */
- u8 gpe1_base; /* Offset in GPE number space where GPE1 events start */
- u8 cst_control; /* Support for the _CST object and C-States change notification */
- u16 c2_latency; /* Worst case HW latency to enter/exit C2 state */
- u16 c3_latency; /* Worst case HW latency to enter/exit C3 state */
- u16 flush_size; /* Processor memory cache line width, in bytes */
- u16 flush_stride; /* Number of flush strides that need to be read */
- u8 duty_offset; /* Processor duty cycle index in processor P_CNT reg */
- u8 duty_width; /* Processor duty cycle value bit width in P_CNT register */
- u8 day_alarm; /* Index to day-of-month alarm in RTC CMOS RAM */
- u8 month_alarm; /* Index to month-of-year alarm in RTC CMOS RAM */
- u8 century; /* Index to century in RTC CMOS RAM */
- u16 boot_flags; /* IA-PC Boot Architecture Flags (see below for individual flags) */
- u8 reserved; /* Reserved, must be zero */
- u32 flags; /* Miscellaneous flag bits (see below for individual flags) */
- struct acpi_generic_address reset_register; /* 64-bit address of the Reset register */
- u8 reset_value; /* Value to write to the reset_register port to reset the system */
- u16 arm_boot_flags; /* ARM-Specific Boot Flags (see below for individual flags) (ACPI 5.1) */
- u8 minor_revision; /* FADT Minor Revision (ACPI 5.1) */
- u64 Xfacs; /* 64-bit physical address of FACS */
- u64 Xdsdt; /* 64-bit physical address of DSDT */
- struct acpi_generic_address xpm1a_event_block; /* 64-bit Extended Power Mgt 1a Event Reg Blk address */
- struct acpi_generic_address xpm1b_event_block; /* 64-bit Extended Power Mgt 1b Event Reg Blk address */
- struct acpi_generic_address xpm1a_control_block; /* 64-bit Extended Power Mgt 1a Control Reg Blk address */
- struct acpi_generic_address xpm1b_control_block; /* 64-bit Extended Power Mgt 1b Control Reg Blk address */
- struct acpi_generic_address xpm2_control_block; /* 64-bit Extended Power Mgt 2 Control Reg Blk address */
- struct acpi_generic_address xpm_timer_block; /* 64-bit Extended Power Mgt Timer Ctrl Reg Blk address */
- struct acpi_generic_address xgpe0_block; /* 64-bit Extended General Purpose Event 0 Reg Blk address */
- struct acpi_generic_address xgpe1_block; /* 64-bit Extended General Purpose Event 1 Reg Blk address */
- struct acpi_generic_address sleep_control; /* 64-bit Sleep Control register (ACPI 5.0) */
- struct acpi_generic_address sleep_status; /* 64-bit Sleep Status register (ACPI 5.0) */
- u64 hypervisor_id; /* Hypervisor Vendor ID (ACPI 6.0) */
+ struct acpi_table_header header; /* [V1] Common ACPI table header */
+ u32 facs; /* [V1] 32-bit physical address of FACS */
+ u32 dsdt; /* [V1] 32-bit physical address of DSDT */
+ u8 model; /* [V1] System Interrupt Model (ACPI 1.0) - not used in ACPI 2.0+ */
+ u8 preferred_profile; /* [V1] Conveys preferred power management profile to OSPM. */
+ u16 sci_interrupt; /* [V1] System vector of SCI interrupt */
+ u32 smi_command; /* [V1] 32-bit Port address of SMI command port */
+ u8 acpi_enable; /* [V1] Value to write to SMI_CMD to enable ACPI */
+ u8 acpi_disable; /* [V1] Value to write to SMI_CMD to disable ACPI */
+ u8 s4_bios_request; /* [V1] Value to write to SMI_CMD to enter S4BIOS state */
+ u8 pstate_control; /* [V1] Processor performance state control */
+ u32 pm1a_event_block; /* [V1] 32-bit port address of Power Mgt 1a Event Reg Blk */
+ u32 pm1b_event_block; /* [V1] 32-bit port address of Power Mgt 1b Event Reg Blk */
+ u32 pm1a_control_block; /* [V1] 32-bit port address of Power Mgt 1a Control Reg Blk */
+ u32 pm1b_control_block; /* [V1] 32-bit port address of Power Mgt 1b Control Reg Blk */
+ u32 pm2_control_block; /* [V1] 32-bit port address of Power Mgt 2 Control Reg Blk */
+ u32 pm_timer_block; /* [V1] 32-bit port address of Power Mgt Timer Ctrl Reg Blk */
+ u32 gpe0_block; /* [V1] 32-bit port address of General Purpose Event 0 Reg Blk */
+ u32 gpe1_block; /* [V1] 32-bit port address of General Purpose Event 1 Reg Blk */
+ u8 pm1_event_length; /* [V1] Byte Length of ports at pm1x_event_block */
+ u8 pm1_control_length; /* [V1] Byte Length of ports at pm1x_control_block */
+ u8 pm2_control_length; /* [V1] Byte Length of ports at pm2_control_block */
+ u8 pm_timer_length; /* [V1] Byte Length of ports at pm_timer_block */
+ u8 gpe0_block_length; /* [V1] Byte Length of ports at gpe0_block */
+ u8 gpe1_block_length; /* [V1] Byte Length of ports at gpe1_block */
+ u8 gpe1_base; /* [V1] Offset in GPE number space where GPE1 events start */
+ u8 cst_control; /* [V1] Support for the _CST object and C-States change notification */
+ u16 c2_latency; /* [V1] Worst case HW latency to enter/exit C2 state */
+ u16 c3_latency; /* [V1] Worst case HW latency to enter/exit C3 state */
+ u16 flush_size; /* [V1] Processor memory cache line width, in bytes */
+ u16 flush_stride; /* [V1] Number of flush strides that need to be read */
+ u8 duty_offset; /* [V1] Processor duty cycle index in processor P_CNT reg */
+ u8 duty_width; /* [V1] Processor duty cycle value bit width in P_CNT register */
+ u8 day_alarm; /* [V1] Index to day-of-month alarm in RTC CMOS RAM */
+ u8 month_alarm; /* [V1] Index to month-of-year alarm in RTC CMOS RAM */
+ u8 century; /* [V1] Index to century in RTC CMOS RAM */
+ u16 boot_flags; /* [V3] IA-PC Boot Architecture Flags (see below for individual flags) */
+ u8 reserved; /* [V1] Reserved, must be zero */
+ u32 flags; /* [V1] Miscellaneous flag bits (see below for individual flags) */
+ /* End of Version 1 FADT fields (ACPI 1.0) */
+
+ struct acpi_generic_address reset_register; /* [V3] 64-bit address of the Reset register */
+ u8 reset_value; /* [V3] Value to write to the reset_register port to reset the system */
+ u16 arm_boot_flags; /* [V5] ARM-Specific Boot Flags (see below for individual flags) (ACPI 5.1) */
+ u8 minor_revision; /* [V5] FADT Minor Revision (ACPI 5.1) */
+ u64 Xfacs; /* [V3] 64-bit physical address of FACS */
+ u64 Xdsdt; /* [V3] 64-bit physical address of DSDT */
+ struct acpi_generic_address xpm1a_event_block; /* [V3] 64-bit Extended Power Mgt 1a Event Reg Blk address */
+ struct acpi_generic_address xpm1b_event_block; /* [V3] 64-bit Extended Power Mgt 1b Event Reg Blk address */
+ struct acpi_generic_address xpm1a_control_block; /* [V3] 64-bit Extended Power Mgt 1a Control Reg Blk address */
+ struct acpi_generic_address xpm1b_control_block; /* [V3] 64-bit Extended Power Mgt 1b Control Reg Blk address */
+ struct acpi_generic_address xpm2_control_block; /* [V3] 64-bit Extended Power Mgt 2 Control Reg Blk address */
+ struct acpi_generic_address xpm_timer_block; /* [V3] 64-bit Extended Power Mgt Timer Ctrl Reg Blk address */
+ struct acpi_generic_address xgpe0_block; /* [V3] 64-bit Extended General Purpose Event 0 Reg Blk address */
+ struct acpi_generic_address xgpe1_block; /* [V3] 64-bit Extended General Purpose Event 1 Reg Blk address */
+ /* End of Version 3 FADT fields (ACPI 2.0) */
+
+ struct acpi_generic_address sleep_control; /* [V4] 64-bit Sleep Control register (ACPI 5.0) */
+ /* End of Version 4 FADT fields (ACPI 3.0 and ACPI 4.0) (Field was originally reserved in ACPI 3.0) */
+
+ struct acpi_generic_address sleep_status; /* [V5] 64-bit Sleep Status register (ACPI 5.0) */
+ /* End of Version 5 FADT fields (ACPI 5.0) */
+
+ u64 hypervisor_id; /* [V6] Hypervisor Vendor ID (ACPI 6.0) */
+ /* End of Version 6 FADT fields (ACPI 6.0) */
+
};
/* Masks for FADT IA-PC Boot Architecture Flags (boot_flags) [Vx]=Introduced in this FADT revision */
@@ -301,8 +311,8 @@
/* Masks for FADT ARM Boot Architecture Flags (arm_boot_flags) ACPI 5.1 */
-#define ACPI_FADT_PSCI_COMPLIANT (1) /* 00: [V5+] PSCI 0.2+ is implemented */
-#define ACPI_FADT_PSCI_USE_HVC (1<<1) /* 01: [V5+] HVC must be used instead of SMC as the PSCI conduit */
+#define ACPI_FADT_PSCI_COMPLIANT (1) /* 00: [V5] PSCI 0.2+ is implemented */
+#define ACPI_FADT_PSCI_USE_HVC (1<<1) /* 01: [V5] HVC must be used instead of SMC as the PSCI conduit */
/* Masks for FADT flags */
@@ -399,20 +409,34 @@
* match the expected length. In other words, the length of the
* FADT is the bottom line as to what the version really is.
*
- * For reference, the values below are as follows:
- * FADT V1 size: 0x074
- * FADT V2 size: 0x084
- * FADT V3 size: 0x0F4
- * FADT V4 size: 0x0F4
- * FADT V5 size: 0x10C
- * FADT V6 size: 0x114
+ * NOTE: There is no officialy released V2 of the FADT. This
+ * version was used only for prototyping and testing during the
+ * 32-bit to 64-bit transition. V3 was the first official 64-bit
+ * version of the FADT.
+ *
+ * Update this list of defines when a new version of the FADT is
+ * added to the ACPI specification. Note that the FADT version is
+ * only incremented when new fields are appended to the existing
+ * version. Therefore, the FADT version is competely independent
+ * from the version of the ACPI specification where it is
+ * defined.
+ *
+ * For reference, the various FADT lengths are as follows:
+ * FADT V1 size: 0x074 ACPI 1.0
+ * FADT V3 size: 0x0F4 ACPI 2.0
+ * FADT V4 size: 0x100 ACPI 3.0 and ACPI 4.0
+ * FADT V5 size: 0x10C ACPI 5.0
+ * FADT V6 size: 0x114 ACPI 6.0
*/
-#define ACPI_FADT_V1_SIZE (u32) (ACPI_FADT_OFFSET (flags) + 4)
-#define ACPI_FADT_V2_SIZE (u32) (ACPI_FADT_OFFSET (minor_revision) + 1)
-#define ACPI_FADT_V3_SIZE (u32) (ACPI_FADT_OFFSET (sleep_control))
-#define ACPI_FADT_V5_SIZE (u32) (ACPI_FADT_OFFSET (hypervisor_id))
-#define ACPI_FADT_V6_SIZE (u32) (sizeof (struct acpi_table_fadt))
+#define ACPI_FADT_V1_SIZE (u32) (ACPI_FADT_OFFSET (flags) + 4) /* ACPI 1.0 */
+#define ACPI_FADT_V3_SIZE (u32) (ACPI_FADT_OFFSET (sleep_control)) /* ACPI 2.0 */
+#define ACPI_FADT_V4_SIZE (u32) (ACPI_FADT_OFFSET (sleep_status)) /* ACPI 3.0 and ACPI 4.0 */
+#define ACPI_FADT_V5_SIZE (u32) (ACPI_FADT_OFFSET (hypervisor_id)) /* ACPI 5.0 */
+#define ACPI_FADT_V6_SIZE (u32) (sizeof (struct acpi_table_fadt)) /* ACPI 6.0 */
+/* Update these when new FADT versions are added */
+
+#define ACPI_FADT_MAX_VERSION 6
#define ACPI_FADT_CONFORMANCE "ACPI 6.1 (FADT version 6)"
#endif /* __ACTBL_H__ */
diff --git a/include/acpi/actypes.h b/include/acpi/actypes.h
index cb389ef..1d798ab 100644
--- a/include/acpi/actypes.h
+++ b/include/acpi/actypes.h
@@ -732,16 +732,17 @@
* The encoding of acpi_event_status is illustrated below.
* Note that a set bit (1) indicates the property is TRUE
* (e.g. if bit 0 is set then the event is enabled).
- * +-------------+-+-+-+-+-+
- * | Bits 31:5 |4|3|2|1|0|
- * +-------------+-+-+-+-+-+
- * | | | | | |
- * | | | | | +- Enabled?
- * | | | | +--- Enabled for wake?
- * | | | +----- Status bit set?
- * | | +------- Enable bit set?
- * | +--------- Has a handler?
- * +--------------- <Reserved>
+ * +-------------+-+-+-+-+-+-+
+ * | Bits 31:6 |5|4|3|2|1|0|
+ * +-------------+-+-+-+-+-+-+
+ * | | | | | | |
+ * | | | | | | +- Enabled?
+ * | | | | | +--- Enabled for wake?
+ * | | | | +----- Status bit set?
+ * | | | +------- Enable bit set?
+ * | | +--------- Has a handler?
+ * | +----------- Masked?
+ * +----------------- <Reserved>
*/
typedef u32 acpi_event_status;
@@ -751,6 +752,7 @@
#define ACPI_EVENT_FLAG_STATUS_SET (acpi_event_status) 0x04
#define ACPI_EVENT_FLAG_ENABLE_SET (acpi_event_status) 0x08
#define ACPI_EVENT_FLAG_HAS_HANDLER (acpi_event_status) 0x10
+#define ACPI_EVENT_FLAG_MASKED (acpi_event_status) 0x20
#define ACPI_EVENT_FLAG_SET ACPI_EVENT_FLAG_STATUS_SET
/* Actions for acpi_set_gpe, acpi_gpe_wakeup, acpi_hw_low_set_gpe */
@@ -761,14 +763,15 @@
/*
* GPE info flags - Per GPE
- * +-------+-+-+---+
- * | 7:5 |4|3|2:0|
- * +-------+-+-+---+
- * | | | |
- * | | | +-- Type of dispatch:to method, handler, notify, or none
- * | | +----- Interrupt type: edge or level triggered
- * | +------- Is a Wake GPE
- * +------------ <Reserved>
+ * +---+-+-+-+---+
+ * |7:6|5|4|3|2:0|
+ * +---+-+-+-+---+
+ * | | | | |
+ * | | | | +-- Type of dispatch:to method, handler, notify, or none
+ * | | | +----- Interrupt type: edge or level triggered
+ * | | +------- Is a Wake GPE
+ * | +--------- Is GPE masked by the software GPE masking machanism
+ * +------------ <Reserved>
*/
#define ACPI_GPE_DISPATCH_NONE (u8) 0x00
#define ACPI_GPE_DISPATCH_METHOD (u8) 0x01
@@ -1031,12 +1034,6 @@
u32 method_count;
};
-/* Table Event Types */
-
-#define ACPI_TABLE_EVENT_LOAD 0x0
-#define ACPI_TABLE_EVENT_UNLOAD 0x1
-#define ACPI_NUM_TABLE_EVENTS 2
-
/*
* Types specific to the OS service interfaces
*/
@@ -1088,9 +1085,13 @@
typedef
acpi_status (*acpi_table_handler) (u32 event, void *table, void *context);
-#define ACPI_TABLE_LOAD 0x0
-#define ACPI_TABLE_UNLOAD 0x1
-#define ACPI_NUM_TABLE_EVENTS 2
+/* Table Event Types */
+
+#define ACPI_TABLE_EVENT_LOAD 0x0
+#define ACPI_TABLE_EVENT_UNLOAD 0x1
+#define ACPI_TABLE_EVENT_INSTALL 0x2
+#define ACPI_TABLE_EVENT_UNINSTALL 0x3
+#define ACPI_NUM_TABLE_EVENTS 4
/* Address Spaces (For Operation Regions) */
@@ -1285,15 +1286,6 @@
#define ACPI_OSI_WIN_8 0x0C
#define ACPI_OSI_WIN_10 0x0D
-/* Definitions of file IO */
-
-#define ACPI_FILE_READING 0x01
-#define ACPI_FILE_WRITING 0x02
-#define ACPI_FILE_BINARY 0x04
-
-#define ACPI_FILE_BEGIN 0x01
-#define ACPI_FILE_END 0x02
-
/* Definitions of getopt */
#define ACPI_OPT_END -1
diff --git a/include/acpi/cppc_acpi.h b/include/acpi/cppc_acpi.h
index 284965c..427a7c3 100644
--- a/include/acpi/cppc_acpi.h
+++ b/include/acpi/cppc_acpi.h
@@ -24,7 +24,9 @@
#define CPPC_NUM_ENT 21
#define CPPC_REV 2
-#define PCC_CMD_COMPLETE 1
+#define PCC_CMD_COMPLETE_MASK (1 << 0)
+#define PCC_ERROR_MASK (1 << 2)
+
#define MAX_CPC_REG_ENT 19
/* CPPC specific PCC commands. */
@@ -49,6 +51,7 @@
*/
struct cpc_register_resource {
acpi_object_type type;
+ u64 __iomem *sys_mem_vaddr;
union {
struct cpc_reg reg;
u64 int_value;
@@ -60,8 +63,11 @@
int num_entries;
int version;
int cpu_id;
+ int write_cmd_status;
+ int write_cmd_id;
struct cpc_register_resource cpc_regs[MAX_CPC_REG_ENT];
struct acpi_psd_package domain_info;
+ struct kobject kobj;
};
/* These are indexes into the per-cpu cpc_regs[]. Order is important. */
@@ -96,7 +102,6 @@
struct cppc_perf_caps {
u32 highest_perf;
u32 nominal_perf;
- u32 reference_perf;
u32 lowest_perf;
};
@@ -108,13 +113,13 @@
struct cppc_perf_fb_ctrs {
u64 reference;
- u64 prev_reference;
u64 delivered;
- u64 prev_delivered;
+ u64 reference_perf;
+ u64 ctr_wrap_time;
};
/* Per CPU container for runtime CPPC management. */
-struct cpudata {
+struct cppc_cpudata {
int cpu;
struct cppc_perf_caps perf_caps;
struct cppc_perf_ctrls perf_ctrls;
@@ -127,6 +132,7 @@
extern int cppc_get_perf_ctrs(int cpu, struct cppc_perf_fb_ctrs *perf_fb_ctrs);
extern int cppc_set_perf(int cpu, struct cppc_perf_ctrls *perf_ctrls);
extern int cppc_get_perf_caps(int cpu, struct cppc_perf_caps *caps);
-extern int acpi_get_psd_map(struct cpudata **);
+extern int acpi_get_psd_map(struct cppc_cpudata **);
+extern unsigned int cppc_get_transition_latency(int cpu);
#endif /* _CPPC_ACPI_H*/
diff --git a/include/acpi/platform/acenv.h b/include/acpi/platform/acenv.h
index 86b5a84..34cce72 100644
--- a/include/acpi/platform/acenv.h
+++ b/include/acpi/platform/acenv.h
@@ -78,6 +78,7 @@
(defined ACPI_EXAMPLE_APP)
#define ACPI_APPLICATION
#define ACPI_SINGLE_THREADED
+#define USE_NATIVE_ALLOCATE_ZEROED
#endif
/* iASL configuration */
@@ -124,7 +125,6 @@
#ifdef ACPI_DUMP_APP
#define ACPI_USE_NATIVE_MEMORY_MAPPING
-#define USE_NATIVE_ALLOCATE_ZEROED
#endif
/* acpi_names/Example configuration. Hardware disabled */
@@ -149,7 +149,6 @@
/* Common for all ACPICA applications */
#ifdef ACPI_APPLICATION
-#define ACPI_USE_SYSTEM_CLIBRARY
#define ACPI_USE_LOCAL_CACHE
#endif
@@ -167,10 +166,21 @@
/******************************************************************************
*
* Host configuration files. The compiler configuration files are included
- * by the host files.
+ * first.
*
*****************************************************************************/
+#if defined(__GNUC__) && !defined(__INTEL_COMPILER)
+#include <acpi/platform/acgcc.h>
+
+#elif defined(_MSC_VER)
+#include "acmsvc.h"
+
+#elif defined(__INTEL_COMPILER)
+#include "acintel.h"
+
+#endif
+
#if defined(_LINUX) || defined(__linux__)
#include <acpi/platform/aclinux.h>
@@ -210,18 +220,20 @@
#elif defined(__OS2__)
#include "acos2.h"
-#elif defined(_AED_EFI)
-#include "acefi.h"
-
-#elif defined(_GNU_EFI)
-#include "acefi.h"
-
#elif defined(__HAIKU__)
#include "achaiku.h"
#elif defined(__QNX__)
#include "acqnx.h"
+/*
+ * EFI applications can be built with -nostdlib, in this case, it must be
+ * included after including all other host environmental definitions, in
+ * order to override the definitions.
+ */
+#elif defined(_AED_EFI) || defined(_GNU_EFI) || defined(_EDK2_EFI)
+#include "acefi.h"
+
#else
/* Unknown environment */
@@ -326,7 +338,8 @@
* ACPI_USE_SYSTEM_CLIBRARY - Define this if linking to an actual C library.
* Otherwise, local versions of string/memory functions will be used.
* ACPI_USE_STANDARD_HEADERS - Define this if linking to a C library and
- * the standard header files may be used.
+ * the standard header files may be used. Defining this implies that
+ * ACPI_USE_SYSTEM_CLIBRARY has been defined.
*
* The ACPICA subsystem only uses low level C library functions that do not
* call operating system services and may therefore be inlined in the code.
@@ -334,7 +347,6 @@
* It may be necessary to tailor these include files to the target
* generation environment.
*/
-#ifdef ACPI_USE_SYSTEM_CLIBRARY
/* Use the standard C library headers. We want to keep these to a minimum. */
@@ -342,57 +354,20 @@
/* Use the standard headers from the standard locations */
-#include <stdarg.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
+#ifdef ACPI_APPLICATION
+#include <stdio.h>
+#include <fcntl.h>
+#include <errno.h>
+#include <time.h>
+#include <signal.h>
+#endif
#endif /* ACPI_USE_STANDARD_HEADERS */
-/* We will be linking to the standard Clib functions */
-
-#else
-
-/******************************************************************************
- *
- * Not using native C library, use local implementations
- *
- *****************************************************************************/
-
-/*
- * Use local definitions of C library macros and functions. These function
- * implementations may not be as efficient as an inline or assembly code
- * implementation provided by a native C library, but they are functionally
- * equivalent.
- */
-#ifndef va_arg
-
-#ifndef _VALIST
-#define _VALIST
-typedef char *va_list;
-#endif /* _VALIST */
-
-/* Storage alignment properties */
-
-#define _AUPBND (sizeof (acpi_native_int) - 1)
-#define _ADNBND (sizeof (acpi_native_int) - 1)
-
-/* Variable argument list macro definitions */
-
-#define _bnd(X, bnd) (((sizeof (X)) + (bnd)) & (~(bnd)))
-#define va_arg(ap, T) (*(T *)(((ap) += (_bnd (T, _AUPBND))) - (_bnd (T,_ADNBND))))
-#define va_end(ap) (ap = (va_list) NULL)
-#define va_start(ap, A) (void) ((ap) = (((char *) &(A)) + (_bnd (A,_AUPBND))))
-
-#endif /* va_arg */
-
-/* Use the local (ACPICA) definitions of the clib functions */
-
-#endif /* ACPI_USE_SYSTEM_CLIBRARY */
-
-#ifndef ACPI_FILE
#ifdef ACPI_APPLICATION
-#include <stdio.h>
#define ACPI_FILE FILE *
#define ACPI_FILE_OUT stdout
#define ACPI_FILE_ERR stderr
@@ -401,6 +376,9 @@
#define ACPI_FILE_OUT NULL
#define ACPI_FILE_ERR NULL
#endif /* ACPI_APPLICATION */
-#endif /* ACPI_FILE */
+
+#ifndef ACPI_INIT_FUNCTION
+#define ACPI_INIT_FUNCTION
+#endif
#endif /* __ACENV_H__ */
diff --git a/include/acpi/platform/acenvex.h b/include/acpi/platform/acenvex.h
index 4f15c1d..b3171b9 100644
--- a/include/acpi/platform/acenvex.h
+++ b/include/acpi/platform/acenvex.h
@@ -56,18 +56,25 @@
#if defined(_LINUX) || defined(__linux__)
#include <acpi/platform/aclinuxex.h>
-#elif defined(WIN32)
-#include "acwinex.h"
-
-#elif defined(_AED_EFI)
-#include "acefiex.h"
-
-#elif defined(_GNU_EFI)
-#include "acefiex.h"
-
#elif defined(__DragonFly__)
#include "acdragonflyex.h"
+/*
+ * EFI applications can be built with -nostdlib, in this case, it must be
+ * included after including all other host environmental definitions, in
+ * order to override the definitions.
+ */
+#elif defined(_AED_EFI) || defined(_GNU_EFI) || defined(_EDK2_EFI)
+#include "acefiex.h"
+
+#endif
+
+#if defined(__GNUC__) && !defined(__INTEL_COMPILER)
+#include "acgccex.h"
+
+#elif defined(_MSC_VER)
+#include "acmsvcex.h"
+
#endif
/*! [End] no source code translation !*/
diff --git a/include/acpi/platform/acgcc.h b/include/acpi/platform/acgcc.h
index c5a216c9..8f66aaa 100644
--- a/include/acpi/platform/acgcc.h
+++ b/include/acpi/platform/acgcc.h
@@ -44,6 +44,12 @@
#ifndef __ACGCC_H__
#define __ACGCC_H__
+/*
+ * Use compiler specific <stdarg.h> is a good practice for even when
+ * -nostdinc is specified (i.e., ACPI_USE_STANDARD_HEADERS undefined.
+ */
+#include <stdarg.h>
+
#define ACPI_INLINE __inline__
/* Function name is used for debug output. Non-ANSI, compiler-dependent */
@@ -64,17 +70,6 @@
*/
#define ACPI_UNUSED_VAR __attribute__ ((unused))
-/*
- * Some versions of gcc implement strchr() with a buggy macro. So,
- * undef it here. Prevents error messages of this form (usually from the
- * file getopt.c):
- *
- * error: logical '&&' with non-zero constant will always evaluate as true
- */
-#ifdef strchr
-#undef strchr
-#endif
-
/* GCC supports __VA_ARGS__ in macros */
#define COMPILER_VA_MACRO 1
diff --git a/include/acpi/platform/acgccex.h b/include/acpi/platform/acgccex.h
new file mode 100644
index 0000000..46ead2c
--- /dev/null
+++ b/include/acpi/platform/acgccex.h
@@ -0,0 +1,58 @@
+/******************************************************************************
+ *
+ * Name: acgccex.h - Extra GCC specific defines, etc.
+ *
+ *****************************************************************************/
+
+/*
+ * Copyright (C) 2000 - 2016, Intel Corp.
+ * All rights reserved.
+ *
+ * Redistribution and use in source and binary forms, with or without
+ * modification, are permitted provided that the following conditions
+ * are met:
+ * 1. Redistributions of source code must retain the above copyright
+ * notice, this list of conditions, and the following disclaimer,
+ * without modification.
+ * 2. Redistributions in binary form must reproduce at minimum a disclaimer
+ * substantially similar to the "NO WARRANTY" disclaimer below
+ * ("Disclaimer") and any redistribution must be conditioned upon
+ * including a substantially similar Disclaimer requirement for further
+ * binary redistribution.
+ * 3. Neither the names of the above-listed copyright holders nor the names
+ * of any contributors may be used to endorse or promote products derived
+ * from this software without specific prior written permission.
+ *
+ * Alternatively, this software may be distributed under the terms of the
+ * GNU General Public License ("GPL") version 2 as published by the Free
+ * Software Foundation.
+ *
+ * NO WARRANTY
+ * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
+ * "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
+ * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTIBILITY AND FITNESS FOR
+ * A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
+ * HOLDERS OR CONTRIBUTORS BE LIABLE FOR SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+ * DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
+ * OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
+ * HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT,
+ * STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING
+ * IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
+ * POSSIBILITY OF SUCH DAMAGES.
+ */
+
+#ifndef __ACGCCEX_H__
+#define __ACGCCEX_H__
+
+/*
+ * Some versions of gcc implement strchr() with a buggy macro. So,
+ * undef it here. Prevents error messages of this form (usually from the
+ * file getopt.c):
+ *
+ * error: logical '&&' with non-zero constant will always evaluate as true
+ */
+#ifdef strchr
+#undef strchr
+#endif
+
+#endif /* __ACGCCEX_H__ */
diff --git a/include/acpi/platform/aclinux.h b/include/acpi/platform/aclinux.h
index 93b61b1..a5d98d1 100644
--- a/include/acpi/platform/aclinux.h
+++ b/include/acpi/platform/aclinux.h
@@ -92,6 +92,8 @@
#include <asm/acenv.h>
#endif
+#define ACPI_INIT_FUNCTION __init
+
#ifndef CONFIG_ACPI
/* External globals for __KERNEL__, stubs is needed */
@@ -168,13 +170,21 @@
#define ACPI_USE_ALTERNATE_PROTOTYPE_acpi_os_get_next_filename
#define ACPI_USE_ALTERNATE_PROTOTYPE_acpi_os_close_directory
+#define ACPI_MSG_ERROR KERN_ERR "ACPI Error: "
+#define ACPI_MSG_EXCEPTION KERN_ERR "ACPI Exception: "
+#define ACPI_MSG_WARNING KERN_WARNING "ACPI Warning: "
+#define ACPI_MSG_INFO KERN_INFO "ACPI: "
+
+#define ACPI_MSG_BIOS_ERROR KERN_ERR "ACPI BIOS Error (bug): "
+#define ACPI_MSG_BIOS_WARNING KERN_WARNING "ACPI BIOS Warning (bug): "
+
#else /* !__KERNEL__ */
-#include <stdarg.h>
-#include <string.h>
-#include <stdlib.h>
-#include <ctype.h>
+#define ACPI_USE_STANDARD_HEADERS
+
+#ifdef ACPI_USE_STANDARD_HEADERS
#include <unistd.h>
+#endif
/* Define/disable kernel-specific declarators */
@@ -205,8 +215,4 @@
#endif /* __KERNEL__ */
-/* Linux uses GCC */
-
-#include <acpi/platform/acgcc.h>
-
#endif /* __ACLINUX_H__ */
diff --git a/include/acpi/platform/aclinuxex.h b/include/acpi/platform/aclinuxex.h
index f8bb0d8..a5509d8 100644
--- a/include/acpi/platform/aclinuxex.h
+++ b/include/acpi/platform/aclinuxex.h
@@ -71,7 +71,7 @@
/*
* Overrides for in-kernel ACPICA
*/
-acpi_status __init acpi_os_initialize(void);
+acpi_status ACPI_INIT_FUNCTION acpi_os_initialize(void);
acpi_status acpi_os_terminate(void);
diff --git a/include/linux/acpi.h b/include/linux/acpi.h
index c5eaf2f..65932c0 100644
--- a/include/linux/acpi.h
+++ b/include/linux/acpi.h
@@ -85,6 +85,8 @@
return dev_name(&adev->dev);
}
+struct device *acpi_get_first_physical_node(struct acpi_device *adev);
+
enum acpi_irq_model_id {
ACPI_IRQ_MODEL_PIC = 0,
ACPI_IRQ_MODEL_IOAPIC,
@@ -634,6 +636,11 @@
return NULL;
}
+static inline struct device *acpi_get_first_physical_node(struct acpi_device *adev)
+{
+ return NULL;
+}
+
static inline void acpi_early_init(void) { }
static inline void acpi_subsystem_init(void) { }
@@ -1074,4 +1081,10 @@
static inline void acpi_table_upgrade(void) { }
#endif
+#if defined(CONFIG_ACPI) && defined(CONFIG_ACPI_WATCHDOG)
+extern bool acpi_has_watchdog(void);
+#else
+static inline bool acpi_has_watchdog(void) { return false; }
+#endif
+
#endif /*_LINUX_ACPI_H*/
diff --git a/include/linux/can/dev.h b/include/linux/can/dev.h
index 5261751..5f52709 100644
--- a/include/linux/can/dev.h
+++ b/include/linux/can/dev.h
@@ -32,6 +32,7 @@
* CAN common private data
*/
struct can_priv {
+ struct net_device *dev;
struct can_device_stats can_stats;
struct can_bittiming bittiming, data_bittiming;
@@ -47,7 +48,7 @@
u32 ctrlmode_static; /* static enabled options for driver/hardware */
int restart_ms;
- struct timer_list restart_timer;
+ struct delayed_work restart_work;
int (*do_set_bittiming)(struct net_device *dev);
int (*do_set_data_bittiming)(struct net_device *dev);
diff --git a/include/linux/cec-funcs.h b/include/linux/cec-funcs.h
index 82c3d3b..138bbf7 100644
--- a/include/linux/cec-funcs.h
+++ b/include/linux/cec-funcs.h
@@ -162,10 +162,11 @@
/* One Touch Record Feature */
-static inline void cec_msg_record_off(struct cec_msg *msg)
+static inline void cec_msg_record_off(struct cec_msg *msg, bool reply)
{
msg->len = 2;
msg->msg[1] = CEC_MSG_RECORD_OFF;
+ msg->reply = reply ? CEC_MSG_RECORD_STATUS : 0;
}
struct cec_op_arib_data {
@@ -227,7 +228,7 @@
if (digital->service_id_method == CEC_OP_SERVICE_ID_METHOD_BY_CHANNEL) {
*msg++ = (digital->channel.channel_number_fmt << 2) |
(digital->channel.major >> 8);
- *msg++ = digital->channel.major && 0xff;
+ *msg++ = digital->channel.major & 0xff;
*msg++ = digital->channel.minor >> 8;
*msg++ = digital->channel.minor & 0xff;
*msg++ = 0;
@@ -323,6 +324,7 @@
}
static inline void cec_msg_record_on(struct cec_msg *msg,
+ bool reply,
const struct cec_op_record_src *rec_src)
{
switch (rec_src->type) {
@@ -346,6 +348,7 @@
rec_src->ext_phys_addr.phys_addr);
break;
}
+ msg->reply = reply ? CEC_MSG_RECORD_STATUS : 0;
}
static inline void cec_ops_record_on(const struct cec_msg *msg,
@@ -1141,6 +1144,75 @@
msg->reply = reply ? CEC_MSG_DEVICE_VENDOR_ID : 0;
}
+static inline void cec_msg_vendor_command(struct cec_msg *msg,
+ __u8 size, const __u8 *vendor_cmd)
+{
+ if (size > 14)
+ size = 14;
+ msg->len = 2 + size;
+ msg->msg[1] = CEC_MSG_VENDOR_COMMAND;
+ memcpy(msg->msg + 2, vendor_cmd, size);
+}
+
+static inline void cec_ops_vendor_command(const struct cec_msg *msg,
+ __u8 *size,
+ const __u8 **vendor_cmd)
+{
+ *size = msg->len - 2;
+
+ if (*size > 14)
+ *size = 14;
+ *vendor_cmd = msg->msg + 2;
+}
+
+static inline void cec_msg_vendor_command_with_id(struct cec_msg *msg,
+ __u32 vendor_id, __u8 size,
+ const __u8 *vendor_cmd)
+{
+ if (size > 11)
+ size = 11;
+ msg->len = 5 + size;
+ msg->msg[1] = CEC_MSG_VENDOR_COMMAND_WITH_ID;
+ msg->msg[2] = vendor_id >> 16;
+ msg->msg[3] = (vendor_id >> 8) & 0xff;
+ msg->msg[4] = vendor_id & 0xff;
+ memcpy(msg->msg + 5, vendor_cmd, size);
+}
+
+static inline void cec_ops_vendor_command_with_id(const struct cec_msg *msg,
+ __u32 *vendor_id, __u8 *size,
+ const __u8 **vendor_cmd)
+{
+ *size = msg->len - 5;
+
+ if (*size > 11)
+ *size = 11;
+ *vendor_id = (msg->msg[2] << 16) | (msg->msg[3] << 8) | msg->msg[4];
+ *vendor_cmd = msg->msg + 5;
+}
+
+static inline void cec_msg_vendor_remote_button_down(struct cec_msg *msg,
+ __u8 size,
+ const __u8 *rc_code)
+{
+ if (size > 14)
+ size = 14;
+ msg->len = 2 + size;
+ msg->msg[1] = CEC_MSG_VENDOR_REMOTE_BUTTON_DOWN;
+ memcpy(msg->msg + 2, rc_code, size);
+}
+
+static inline void cec_ops_vendor_remote_button_down(const struct cec_msg *msg,
+ __u8 *size,
+ const __u8 **rc_code)
+{
+ *size = msg->len - 2;
+
+ if (*size > 14)
+ *size = 14;
+ *rc_code = msg->msg + 2;
+}
+
static inline void cec_msg_vendor_remote_button_up(struct cec_msg *msg)
{
msg->len = 2;
@@ -1277,7 +1349,7 @@
msg->len += 4;
msg->msg[3] = (ui_cmd->channel_identifier.channel_number_fmt << 2) |
(ui_cmd->channel_identifier.major >> 8);
- msg->msg[4] = ui_cmd->channel_identifier.major && 0xff;
+ msg->msg[4] = ui_cmd->channel_identifier.major & 0xff;
msg->msg[5] = ui_cmd->channel_identifier.minor >> 8;
msg->msg[6] = ui_cmd->channel_identifier.minor & 0xff;
break;
diff --git a/include/linux/cec.h b/include/linux/cec.h
index b3e2289..851968e 100644
--- a/include/linux/cec.h
+++ b/include/linux/cec.h
@@ -364,7 +364,7 @@
* @num_log_addrs: how many logical addresses should be claimed. Set by the
* caller.
* @vendor_id: the vendor ID of the device. Set by the caller.
- * @flags: set to 0.
+ * @flags: flags.
* @osd_name: the OSD name of the device. Set by the caller.
* @primary_device_type: the primary device type for each logical address.
* Set by the caller.
@@ -389,6 +389,9 @@
__u8 features[CEC_MAX_LOG_ADDRS][12];
};
+/* Allow a fallback to unregistered */
+#define CEC_LOG_ADDRS_FL_ALLOW_UNREG_FALLBACK (1 << 0)
+
/* Events */
/* Event that occurs when the adapter state changes */
diff --git a/include/linux/cpu.h b/include/linux/cpu.h
index 797d9c8..ad4f1f3 100644
--- a/include/linux/cpu.h
+++ b/include/linux/cpu.h
@@ -228,7 +228,11 @@
#endif /* CONFIG_HOTPLUG_CPU */
#ifdef CONFIG_PM_SLEEP_SMP
-extern int disable_nonboot_cpus(void);
+extern int freeze_secondary_cpus(int primary);
+static inline int disable_nonboot_cpus(void)
+{
+ return freeze_secondary_cpus(0);
+}
extern void enable_nonboot_cpus(void);
#else /* !CONFIG_PM_SLEEP_SMP */
static inline int disable_nonboot_cpus(void) { return 0; }
diff --git a/include/linux/cpuhotplug.h b/include/linux/cpuhotplug.h
index 34bd805..eb445a4 100644
--- a/include/linux/cpuhotplug.h
+++ b/include/linux/cpuhotplug.h
@@ -47,6 +47,8 @@
CPUHP_AP_PERF_METAG_STARTING,
CPUHP_AP_MIPS_OP_LOONGSON3_STARTING,
CPUHP_AP_ARM_VFP_STARTING,
+ CPUHP_AP_ARM64_DEBUG_MONITORS_STARTING,
+ CPUHP_AP_PERF_ARM_HW_BREAKPOINT_STARTING,
CPUHP_AP_PERF_ARM_STARTING,
CPUHP_AP_ARM_L2X0_STARTING,
CPUHP_AP_ARM_ARCH_TIMER_STARTING,
diff --git a/include/linux/devfreq-event.h b/include/linux/devfreq-event.h
index 0a83a1e..4db00b0 100644
--- a/include/linux/devfreq-event.h
+++ b/include/linux/devfreq-event.h
@@ -148,11 +148,6 @@
return -EINVAL;
}
-static inline void *devfreq_event_get_drvdata(struct devfreq_event_dev *edev)
-{
- return ERR_PTR(-EINVAL);
-}
-
static inline struct devfreq_event_dev *devfreq_event_get_edev_by_phandle(
struct device *dev, int index)
{
diff --git a/include/linux/dma-mapping.h b/include/linux/dma-mapping.h
index 66533e1..dc69df0 100644
--- a/include/linux/dma-mapping.h
+++ b/include/linux/dma-mapping.h
@@ -718,7 +718,7 @@
#define dma_mmap_writecombine dma_mmap_wc
#endif
-#ifdef CONFIG_NEED_DMA_MAP_STATE
+#if defined(CONFIG_NEED_DMA_MAP_STATE) || defined(CONFIG_DMA_API_DEBUG)
#define DEFINE_DMA_UNMAP_ADDR(ADDR_NAME) dma_addr_t ADDR_NAME
#define DEFINE_DMA_UNMAP_LEN(LEN_NAME) __u32 LEN_NAME
#define dma_unmap_addr(PTR, ADDR_NAME) ((PTR)->ADDR_NAME)
diff --git a/include/linux/efi.h b/include/linux/efi.h
index 0148a30..2d08948 100644
--- a/include/linux/efi.h
+++ b/include/linux/efi.h
@@ -20,6 +20,7 @@
#include <linux/ioport.h>
#include <linux/pfn.h>
#include <linux/pstore.h>
+#include <linux/range.h>
#include <linux/reboot.h>
#include <linux/uuid.h>
#include <linux/screen_info.h>
@@ -37,6 +38,7 @@
#define EFI_WRITE_PROTECTED ( 8 | (1UL << (BITS_PER_LONG-1)))
#define EFI_OUT_OF_RESOURCES ( 9 | (1UL << (BITS_PER_LONG-1)))
#define EFI_NOT_FOUND (14 | (1UL << (BITS_PER_LONG-1)))
+#define EFI_ABORTED (21 | (1UL << (BITS_PER_LONG-1)))
#define EFI_SECURITY_VIOLATION (26 | (1UL << (BITS_PER_LONG-1)))
typedef unsigned long efi_status_t;
@@ -678,6 +680,18 @@
unsigned long tables;
} efi_system_table_t;
+/*
+ * Architecture independent structure for describing a memory map for the
+ * benefit of efi_memmap_init_early(), saving us the need to pass four
+ * parameters.
+ */
+struct efi_memory_map_data {
+ phys_addr_t phys_map;
+ unsigned long size;
+ unsigned long desc_version;
+ unsigned long desc_size;
+};
+
struct efi_memory_map {
phys_addr_t phys_map;
void *map;
@@ -685,6 +699,12 @@
int nr_map;
unsigned long desc_version;
unsigned long desc_size;
+ bool late;
+};
+
+struct efi_mem_range {
+ struct range range;
+ u64 attribute;
};
struct efi_fdt_params {
@@ -909,6 +929,16 @@
}
#endif
extern void __iomem *efi_lookup_mapped_addr(u64 phys_addr);
+
+extern int __init efi_memmap_init_early(struct efi_memory_map_data *data);
+extern int __init efi_memmap_init_late(phys_addr_t addr, unsigned long size);
+extern void __init efi_memmap_unmap(void);
+extern int __init efi_memmap_install(phys_addr_t addr, unsigned int nr_map);
+extern int __init efi_memmap_split_count(efi_memory_desc_t *md,
+ struct range *range);
+extern void __init efi_memmap_insert(struct efi_memory_map *old_memmap,
+ void *buf, struct efi_mem_range *mem);
+
extern int efi_config_init(efi_config_table_type_t *arch_tables);
#ifdef CONFIG_EFI_ESRT
extern void __init efi_esrt_init(void);
@@ -924,6 +954,7 @@
extern int __init efi_uart_console_only (void);
extern u64 efi_mem_desc_end(efi_memory_desc_t *md);
extern int efi_mem_desc_lookup(u64 phys_addr, efi_memory_desc_t *out_md);
+extern void efi_mem_reserve(phys_addr_t addr, u64 size);
extern void efi_initialize_iomem_resources(struct resource *code_resource,
struct resource *data_resource, struct resource *bss_resource);
extern void efi_reserve_boot_services(void);
@@ -1136,12 +1167,6 @@
};
struct efivars {
- /*
- * ->lock protects two things:
- * 1) efivarfs_list and efivars_sysfs_list
- * 2) ->ops calls
- */
- spinlock_t lock;
struct kset *kset;
struct kobject *kobject;
const struct efivar_operations *ops;
@@ -1282,8 +1307,8 @@
int efivar_init(int (*func)(efi_char16_t *, efi_guid_t, unsigned long, void *),
void *data, bool duplicates, struct list_head *head);
-void efivar_entry_add(struct efivar_entry *entry, struct list_head *head);
-void efivar_entry_remove(struct efivar_entry *entry);
+int efivar_entry_add(struct efivar_entry *entry, struct list_head *head);
+int efivar_entry_remove(struct efivar_entry *entry);
int __efivar_entry_delete(struct efivar_entry *entry);
int efivar_entry_delete(struct efivar_entry *entry);
@@ -1300,7 +1325,7 @@
int efivar_entry_set_safe(efi_char16_t *name, efi_guid_t vendor, u32 attributes,
bool block, unsigned long size, void *data);
-void efivar_entry_iter_begin(void);
+int efivar_entry_iter_begin(void);
void efivar_entry_iter_end(void);
int __efivar_entry_iter(int (*func)(struct efivar_entry *, void *),
@@ -1336,7 +1361,6 @@
#ifdef CONFIG_EFI_RUNTIME_MAP
int efi_runtime_map_init(struct kobject *);
-void efi_runtime_map_setup(void *, int, u32);
int efi_get_runtime_map_size(void);
int efi_get_runtime_map_desc_size(void);
int efi_runtime_map_copy(void *buf, size_t bufsz);
@@ -1346,9 +1370,6 @@
return 0;
}
-static inline void
-efi_runtime_map_setup(void *map, int nr_entries, u32 desc_size) {}
-
static inline int efi_get_runtime_map_size(void)
{
return 0;
diff --git a/include/linux/fsnotify_backend.h b/include/linux/fsnotify_backend.h
index 58205f3..7268ed0 100644
--- a/include/linux/fsnotify_backend.h
+++ b/include/linux/fsnotify_backend.h
@@ -148,6 +148,7 @@
#define FS_PRIO_1 1 /* fanotify content based access control */
#define FS_PRIO_2 2 /* fanotify pre-content access */
unsigned int priority;
+ bool shutdown; /* group is being shut down, don't queue more events */
/* stores all fastpath marks assoc with this group so they can be cleaned on unregister */
struct mutex mark_mutex; /* protect marks_list */
@@ -179,7 +180,6 @@
spinlock_t access_lock;
struct list_head access_list;
wait_queue_head_t access_waitq;
- atomic_t bypass_perm;
#endif /* CONFIG_FANOTIFY_ACCESS_PERMISSIONS */
int f_flags;
unsigned int max_marks;
@@ -292,6 +292,8 @@
extern void fsnotify_get_group(struct fsnotify_group *group);
/* drop reference on a group from fsnotify_alloc_group */
extern void fsnotify_put_group(struct fsnotify_group *group);
+/* group destruction begins, stop queuing new events */
+extern void fsnotify_group_stop_queueing(struct fsnotify_group *group);
/* destroy group */
extern void fsnotify_destroy_group(struct fsnotify_group *group);
/* fasync handler function */
@@ -304,8 +306,6 @@
struct fsnotify_event *event,
int (*merge)(struct list_head *,
struct fsnotify_event *));
-/* Remove passed event from groups notification queue */
-extern void fsnotify_remove_event(struct fsnotify_group *group, struct fsnotify_event *event);
/* true if the group notification queue is empty */
extern bool fsnotify_notify_queue_is_empty(struct fsnotify_group *group);
/* return, but do not dequeue the first event on the notification queue */
diff --git a/include/linux/hypervisor.h b/include/linux/hypervisor.h
new file mode 100644
index 0000000..3fa5ef2
--- /dev/null
+++ b/include/linux/hypervisor.h
@@ -0,0 +1,17 @@
+#ifndef __LINUX_HYPEVISOR_H
+#define __LINUX_HYPEVISOR_H
+
+/*
+ * Generic Hypervisor support
+ * Juergen Gross <jgross@suse.com>
+ */
+
+#ifdef CONFIG_HYPERVISOR_GUEST
+#include <asm/hypervisor.h>
+#else
+static inline void hypervisor_pin_vcpu(int cpu)
+{
+}
+#endif
+
+#endif /* __LINUX_HYPEVISOR_H */
diff --git a/include/linux/jump_label.h b/include/linux/jump_label.h
index 661af56..a534c7f 100644
--- a/include/linux/jump_label.h
+++ b/include/linux/jump_label.h
@@ -21,6 +21,8 @@
*
* DEFINE_STATIC_KEY_TRUE(key);
* DEFINE_STATIC_KEY_FALSE(key);
+ * DEFINE_STATIC_KEY_ARRAY_TRUE(keys, count);
+ * DEFINE_STATIC_KEY_ARRAY_FALSE(keys, count);
* static_branch_likely()
* static_branch_unlikely()
*
@@ -270,6 +272,16 @@
#define DEFINE_STATIC_KEY_FALSE(name) \
struct static_key_false name = STATIC_KEY_FALSE_INIT
+#define DEFINE_STATIC_KEY_ARRAY_TRUE(name, count) \
+ struct static_key_true name[count] = { \
+ [0 ... (count) - 1] = STATIC_KEY_TRUE_INIT, \
+ }
+
+#define DEFINE_STATIC_KEY_ARRAY_FALSE(name, count) \
+ struct static_key_false name[count] = { \
+ [0 ... (count) - 1] = STATIC_KEY_FALSE_INIT, \
+ }
+
extern bool ____wrong_branch_error(void);
#define static_key_enabled(x) \
diff --git a/include/linux/lglock.h b/include/linux/lglock.h
deleted file mode 100644
index c92ebd1..0000000
--- a/include/linux/lglock.h
+++ /dev/null
@@ -1,81 +0,0 @@
-/*
- * Specialised local-global spinlock. Can only be declared as global variables
- * to avoid overhead and keep things simple (and we don't want to start using
- * these inside dynamically allocated structures).
- *
- * "local/global locks" (lglocks) can be used to:
- *
- * - Provide fast exclusive access to per-CPU data, with exclusive access to
- * another CPU's data allowed but possibly subject to contention, and to
- * provide very slow exclusive access to all per-CPU data.
- * - Or to provide very fast and scalable read serialisation, and to provide
- * very slow exclusive serialisation of data (not necessarily per-CPU data).
- *
- * Brlocks are also implemented as a short-hand notation for the latter use
- * case.
- *
- * Copyright 2009, 2010, Nick Piggin, Novell Inc.
- */
-#ifndef __LINUX_LGLOCK_H
-#define __LINUX_LGLOCK_H
-
-#include <linux/spinlock.h>
-#include <linux/lockdep.h>
-#include <linux/percpu.h>
-#include <linux/cpu.h>
-#include <linux/notifier.h>
-
-#ifdef CONFIG_SMP
-
-#ifdef CONFIG_DEBUG_LOCK_ALLOC
-#define LOCKDEP_INIT_MAP lockdep_init_map
-#else
-#define LOCKDEP_INIT_MAP(a, b, c, d)
-#endif
-
-struct lglock {
- arch_spinlock_t __percpu *lock;
-#ifdef CONFIG_DEBUG_LOCK_ALLOC
- struct lock_class_key lock_key;
- struct lockdep_map lock_dep_map;
-#endif
-};
-
-#define DEFINE_LGLOCK(name) \
- static DEFINE_PER_CPU(arch_spinlock_t, name ## _lock) \
- = __ARCH_SPIN_LOCK_UNLOCKED; \
- struct lglock name = { .lock = &name ## _lock }
-
-#define DEFINE_STATIC_LGLOCK(name) \
- static DEFINE_PER_CPU(arch_spinlock_t, name ## _lock) \
- = __ARCH_SPIN_LOCK_UNLOCKED; \
- static struct lglock name = { .lock = &name ## _lock }
-
-void lg_lock_init(struct lglock *lg, char *name);
-
-void lg_local_lock(struct lglock *lg);
-void lg_local_unlock(struct lglock *lg);
-void lg_local_lock_cpu(struct lglock *lg, int cpu);
-void lg_local_unlock_cpu(struct lglock *lg, int cpu);
-
-void lg_double_lock(struct lglock *lg, int cpu1, int cpu2);
-void lg_double_unlock(struct lglock *lg, int cpu1, int cpu2);
-
-void lg_global_lock(struct lglock *lg);
-void lg_global_unlock(struct lglock *lg);
-
-#else
-/* When !CONFIG_SMP, map lglock to spinlock */
-#define lglock spinlock
-#define DEFINE_LGLOCK(name) DEFINE_SPINLOCK(name)
-#define DEFINE_STATIC_LGLOCK(name) static DEFINE_SPINLOCK(name)
-#define lg_lock_init(lg, name) spin_lock_init(lg)
-#define lg_local_lock spin_lock
-#define lg_local_unlock spin_unlock
-#define lg_local_lock_cpu(lg, cpu) spin_lock(lg)
-#define lg_local_unlock_cpu(lg, cpu) spin_unlock(lg)
-#define lg_global_lock spin_lock
-#define lg_global_unlock spin_unlock
-#endif
-
-#endif
diff --git a/include/linux/list.h b/include/linux/list.h
index 5183138..5809e9a2 100644
--- a/include/linux/list.h
+++ b/include/linux/list.h
@@ -381,8 +381,11 @@
*
* Note that if the list is empty, it returns NULL.
*/
-#define list_first_entry_or_null(ptr, type, member) \
- (!list_empty(ptr) ? list_first_entry(ptr, type, member) : NULL)
+#define list_first_entry_or_null(ptr, type, member) ({ \
+ struct list_head *head__ = (ptr); \
+ struct list_head *pos__ = READ_ONCE(head__->next); \
+ pos__ != head__ ? list_entry(pos__, type, member) : NULL; \
+})
/**
* list_next_entry - get the next element in list
diff --git a/include/linux/mroute.h b/include/linux/mroute.h
index d351fd3..e5fb813 100644
--- a/include/linux/mroute.h
+++ b/include/linux/mroute.h
@@ -120,5 +120,5 @@
struct rtmsg;
int ipmr_get_route(struct net *net, struct sk_buff *skb,
__be32 saddr, __be32 daddr,
- struct rtmsg *rtm, int nowait);
+ struct rtmsg *rtm, int nowait, u32 portid);
#endif
diff --git a/include/linux/mroute6.h b/include/linux/mroute6.h
index 3987b64..19a1c0c 100644
--- a/include/linux/mroute6.h
+++ b/include/linux/mroute6.h
@@ -116,7 +116,7 @@
struct rtmsg;
extern int ip6mr_get_route(struct net *net, struct sk_buff *skb,
- struct rtmsg *rtm, int nowait);
+ struct rtmsg *rtm, int nowait, u32 portid);
#ifdef CONFIG_IPV6_MROUTE
extern struct sock *mroute6_socket(struct net *net, struct sk_buff *skb);
diff --git a/include/linux/pagemap.h b/include/linux/pagemap.h
index 66a1260..01e8443 100644
--- a/include/linux/pagemap.h
+++ b/include/linux/pagemap.h
@@ -571,56 +571,57 @@
*/
static inline int fault_in_multipages_writeable(char __user *uaddr, int size)
{
- int ret = 0;
char __user *end = uaddr + size - 1;
if (unlikely(size == 0))
- return ret;
+ return 0;
+ if (unlikely(uaddr > end))
+ return -EFAULT;
/*
* Writing zeroes into userspace here is OK, because we know that if
* the zero gets there, we'll be overwriting it.
*/
- while (uaddr <= end) {
- ret = __put_user(0, uaddr);
- if (ret != 0)
- return ret;
+ do {
+ if (unlikely(__put_user(0, uaddr) != 0))
+ return -EFAULT;
uaddr += PAGE_SIZE;
- }
+ } while (uaddr <= end);
/* Check whether the range spilled into the next page. */
if (((unsigned long)uaddr & PAGE_MASK) ==
((unsigned long)end & PAGE_MASK))
- ret = __put_user(0, end);
+ return __put_user(0, end);
- return ret;
+ return 0;
}
static inline int fault_in_multipages_readable(const char __user *uaddr,
int size)
{
volatile char c;
- int ret = 0;
const char __user *end = uaddr + size - 1;
if (unlikely(size == 0))
- return ret;
+ return 0;
- while (uaddr <= end) {
- ret = __get_user(c, uaddr);
- if (ret != 0)
- return ret;
+ if (unlikely(uaddr > end))
+ return -EFAULT;
+
+ do {
+ if (unlikely(__get_user(c, uaddr) != 0))
+ return -EFAULT;
uaddr += PAGE_SIZE;
- }
+ } while (uaddr <= end);
/* Check whether the range spilled into the next page. */
if (((unsigned long)uaddr & PAGE_MASK) ==
((unsigned long)end & PAGE_MASK)) {
- ret = __get_user(c, end);
- (void)c;
+ return __get_user(c, end);
}
- return ret;
+ (void)c;
+ return 0;
}
int add_to_page_cache_locked(struct page *page, struct address_space *mapping,
diff --git a/include/linux/pci.h b/include/linux/pci.h
index 0ab8359..a917d4b2 100644
--- a/include/linux/pci.h
+++ b/include/linux/pci.h
@@ -1126,6 +1126,7 @@
int pci_enable_resources(struct pci_dev *, int mask);
void pci_fixup_irqs(u8 (*)(struct pci_dev *, u8 *),
int (*)(const struct pci_dev *, u8, u8));
+struct resource *pci_find_resource(struct pci_dev *dev, struct resource *res);
#define HAVE_PCI_REQ_REGIONS 2
int __must_check pci_request_regions(struct pci_dev *, const char *);
int __must_check pci_request_regions_exclusive(struct pci_dev *, const char *);
@@ -1542,6 +1543,9 @@
int enable)
{ return 0; }
+static inline struct resource *pci_find_resource(struct pci_dev *dev,
+ struct resource *res)
+{ return NULL; }
static inline int pci_request_regions(struct pci_dev *dev, const char *res_name)
{ return -EIO; }
static inline void pci_release_regions(struct pci_dev *dev) { }
diff --git a/include/linux/percpu-rwsem.h b/include/linux/percpu-rwsem.h
index c2fa3ec..5b2e615 100644
--- a/include/linux/percpu-rwsem.h
+++ b/include/linux/percpu-rwsem.h
@@ -10,32 +10,122 @@
struct percpu_rw_semaphore {
struct rcu_sync rss;
- unsigned int __percpu *fast_read_ctr;
+ unsigned int __percpu *read_count;
struct rw_semaphore rw_sem;
- atomic_t slow_read_ctr;
- wait_queue_head_t write_waitq;
+ wait_queue_head_t writer;
+ int readers_block;
};
-extern void percpu_down_read(struct percpu_rw_semaphore *);
-extern int percpu_down_read_trylock(struct percpu_rw_semaphore *);
-extern void percpu_up_read(struct percpu_rw_semaphore *);
+#define DEFINE_STATIC_PERCPU_RWSEM(name) \
+static DEFINE_PER_CPU(unsigned int, __percpu_rwsem_rc_##name); \
+static struct percpu_rw_semaphore name = { \
+ .rss = __RCU_SYNC_INITIALIZER(name.rss, RCU_SCHED_SYNC), \
+ .read_count = &__percpu_rwsem_rc_##name, \
+ .rw_sem = __RWSEM_INITIALIZER(name.rw_sem), \
+ .writer = __WAIT_QUEUE_HEAD_INITIALIZER(name.writer), \
+}
+
+extern int __percpu_down_read(struct percpu_rw_semaphore *, int);
+extern void __percpu_up_read(struct percpu_rw_semaphore *);
+
+static inline void percpu_down_read_preempt_disable(struct percpu_rw_semaphore *sem)
+{
+ might_sleep();
+
+ rwsem_acquire_read(&sem->rw_sem.dep_map, 0, 0, _RET_IP_);
+
+ preempt_disable();
+ /*
+ * We are in an RCU-sched read-side critical section, so the writer
+ * cannot both change sem->state from readers_fast and start checking
+ * counters while we are here. So if we see !sem->state, we know that
+ * the writer won't be checking until we're past the preempt_enable()
+ * and that one the synchronize_sched() is done, the writer will see
+ * anything we did within this RCU-sched read-size critical section.
+ */
+ __this_cpu_inc(*sem->read_count);
+ if (unlikely(!rcu_sync_is_idle(&sem->rss)))
+ __percpu_down_read(sem, false); /* Unconditional memory barrier */
+ barrier();
+ /*
+ * The barrier() prevents the compiler from
+ * bleeding the critical section out.
+ */
+}
+
+static inline void percpu_down_read(struct percpu_rw_semaphore *sem)
+{
+ percpu_down_read_preempt_disable(sem);
+ preempt_enable();
+}
+
+static inline int percpu_down_read_trylock(struct percpu_rw_semaphore *sem)
+{
+ int ret = 1;
+
+ preempt_disable();
+ /*
+ * Same as in percpu_down_read().
+ */
+ __this_cpu_inc(*sem->read_count);
+ if (unlikely(!rcu_sync_is_idle(&sem->rss)))
+ ret = __percpu_down_read(sem, true); /* Unconditional memory barrier */
+ preempt_enable();
+ /*
+ * The barrier() from preempt_enable() prevents the compiler from
+ * bleeding the critical section out.
+ */
+
+ if (ret)
+ rwsem_acquire_read(&sem->rw_sem.dep_map, 0, 1, _RET_IP_);
+
+ return ret;
+}
+
+static inline void percpu_up_read_preempt_enable(struct percpu_rw_semaphore *sem)
+{
+ /*
+ * The barrier() prevents the compiler from
+ * bleeding the critical section out.
+ */
+ barrier();
+ /*
+ * Same as in percpu_down_read().
+ */
+ if (likely(rcu_sync_is_idle(&sem->rss)))
+ __this_cpu_dec(*sem->read_count);
+ else
+ __percpu_up_read(sem); /* Unconditional memory barrier */
+ preempt_enable();
+
+ rwsem_release(&sem->rw_sem.dep_map, 1, _RET_IP_);
+}
+
+static inline void percpu_up_read(struct percpu_rw_semaphore *sem)
+{
+ preempt_disable();
+ percpu_up_read_preempt_enable(sem);
+}
extern void percpu_down_write(struct percpu_rw_semaphore *);
extern void percpu_up_write(struct percpu_rw_semaphore *);
extern int __percpu_init_rwsem(struct percpu_rw_semaphore *,
const char *, struct lock_class_key *);
+
extern void percpu_free_rwsem(struct percpu_rw_semaphore *);
-#define percpu_init_rwsem(brw) \
+#define percpu_init_rwsem(sem) \
({ \
static struct lock_class_key rwsem_key; \
- __percpu_init_rwsem(brw, #brw, &rwsem_key); \
+ __percpu_init_rwsem(sem, #sem, &rwsem_key); \
})
-
#define percpu_rwsem_is_held(sem) lockdep_is_held(&(sem)->rw_sem)
+#define percpu_rwsem_assert_held(sem) \
+ lockdep_assert_held(&(sem)->rw_sem)
+
static inline void percpu_rwsem_release(struct percpu_rw_semaphore *sem,
bool read, unsigned long ip)
{
diff --git a/include/linux/perf/arm_pmu.h b/include/linux/perf/arm_pmu.h
index e188438..9ff07d3 100644
--- a/include/linux/perf/arm_pmu.h
+++ b/include/linux/perf/arm_pmu.h
@@ -14,7 +14,7 @@
#include <linux/interrupt.h>
#include <linux/perf_event.h>
-
+#include <linux/sysfs.h>
#include <asm/cputype.h>
/*
@@ -77,6 +77,13 @@
struct arm_pmu *percpu_pmu;
};
+enum armpmu_attr_groups {
+ ARMPMU_ATTR_GROUP_COMMON,
+ ARMPMU_ATTR_GROUP_EVENTS,
+ ARMPMU_ATTR_GROUP_FORMATS,
+ ARMPMU_NR_ATTR_GROUPS
+};
+
struct arm_pmu {
struct pmu pmu;
cpumask_t active_irqs;
@@ -111,6 +118,8 @@
struct pmu_hw_events __percpu *hw_events;
struct list_head entry;
struct notifier_block cpu_pm_nb;
+ /* the attr_groups array must be NULL-terminated */
+ const struct attribute_group *attr_groups[ARMPMU_NR_ATTR_GROUPS + 1];
};
#define to_arm_pmu(p) (container_of(p, struct arm_pmu, pmu))
@@ -151,6 +160,8 @@
const struct of_device_id *of_table,
const struct pmu_probe_info *probe_table);
+#define ARMV8_PMU_PDEV_NAME "armv8-pmu"
+
#endif /* CONFIG_ARM_PMU */
#endif /* __ARM_PMU_H__ */
diff --git a/include/linux/pm_domain.h b/include/linux/pm_domain.h
index 31fec85..a09fe5c 100644
--- a/include/linux/pm_domain.h
+++ b/include/linux/pm_domain.h
@@ -51,6 +51,8 @@
struct mutex lock;
struct dev_power_governor *gov;
struct work_struct power_off_work;
+ struct fwnode_handle *provider; /* Identity of the domain provider */
+ bool has_provider;
const char *name;
atomic_t sd_count; /* Number of subdomains with power "on" */
enum gpd_status status; /* Current state of the domain */
@@ -116,7 +118,6 @@
return to_gpd_data(dev->power.subsys_data->domain_data);
}
-extern struct generic_pm_domain *pm_genpd_lookup_dev(struct device *dev);
extern int __pm_genpd_add_device(struct generic_pm_domain *genpd,
struct device *dev,
struct gpd_timing_data *td);
@@ -129,6 +130,7 @@
struct generic_pm_domain *target);
extern int pm_genpd_init(struct generic_pm_domain *genpd,
struct dev_power_governor *gov, bool is_off);
+extern int pm_genpd_remove(struct generic_pm_domain *genpd);
extern struct dev_power_governor simple_qos_governor;
extern struct dev_power_governor pm_domain_always_on_gov;
@@ -138,10 +140,6 @@
{
return ERR_PTR(-ENOSYS);
}
-static inline struct generic_pm_domain *pm_genpd_lookup_dev(struct device *dev)
-{
- return NULL;
-}
static inline int __pm_genpd_add_device(struct generic_pm_domain *genpd,
struct device *dev,
struct gpd_timing_data *td)
@@ -168,6 +166,10 @@
{
return -ENOSYS;
}
+static inline int pm_genpd_remove(struct generic_pm_domain *genpd)
+{
+ return -ENOTSUPP;
+}
#endif
static inline int pm_genpd_add_device(struct generic_pm_domain *genpd,
@@ -192,57 +194,57 @@
unsigned int num_domains;
};
-typedef struct generic_pm_domain *(*genpd_xlate_t)(struct of_phandle_args *args,
- void *data);
-
#ifdef CONFIG_PM_GENERIC_DOMAINS_OF
-int __of_genpd_add_provider(struct device_node *np, genpd_xlate_t xlate,
- void *data);
+int of_genpd_add_provider_simple(struct device_node *np,
+ struct generic_pm_domain *genpd);
+int of_genpd_add_provider_onecell(struct device_node *np,
+ struct genpd_onecell_data *data);
void of_genpd_del_provider(struct device_node *np);
-struct generic_pm_domain *of_genpd_get_from_provider(
- struct of_phandle_args *genpdspec);
-
-struct generic_pm_domain *__of_genpd_xlate_simple(
- struct of_phandle_args *genpdspec,
- void *data);
-struct generic_pm_domain *__of_genpd_xlate_onecell(
- struct of_phandle_args *genpdspec,
- void *data);
+extern int of_genpd_add_device(struct of_phandle_args *args,
+ struct device *dev);
+extern int of_genpd_add_subdomain(struct of_phandle_args *parent,
+ struct of_phandle_args *new_subdomain);
+extern struct generic_pm_domain *of_genpd_remove_last(struct device_node *np);
int genpd_dev_pm_attach(struct device *dev);
#else /* !CONFIG_PM_GENERIC_DOMAINS_OF */
-static inline int __of_genpd_add_provider(struct device_node *np,
- genpd_xlate_t xlate, void *data)
+static inline int of_genpd_add_provider_simple(struct device_node *np,
+ struct generic_pm_domain *genpd)
{
- return 0;
+ return -ENOTSUPP;
}
+
+static inline int of_genpd_add_provider_onecell(struct device_node *np,
+ struct genpd_onecell_data *data)
+{
+ return -ENOTSUPP;
+}
+
static inline void of_genpd_del_provider(struct device_node *np) {}
-static inline struct generic_pm_domain *of_genpd_get_from_provider(
- struct of_phandle_args *genpdspec)
+static inline int of_genpd_add_device(struct of_phandle_args *args,
+ struct device *dev)
{
- return NULL;
+ return -ENODEV;
}
-#define __of_genpd_xlate_simple NULL
-#define __of_genpd_xlate_onecell NULL
+static inline int of_genpd_add_subdomain(struct of_phandle_args *parent,
+ struct of_phandle_args *new_subdomain)
+{
+ return -ENODEV;
+}
static inline int genpd_dev_pm_attach(struct device *dev)
{
return -ENODEV;
}
-#endif /* CONFIG_PM_GENERIC_DOMAINS_OF */
-static inline int of_genpd_add_provider_simple(struct device_node *np,
- struct generic_pm_domain *genpd)
+static inline
+struct generic_pm_domain *of_genpd_remove_last(struct device_node *np)
{
- return __of_genpd_add_provider(np, __of_genpd_xlate_simple, genpd);
+ return ERR_PTR(-ENOTSUPP);
}
-static inline int of_genpd_add_provider_onecell(struct device_node *np,
- struct genpd_onecell_data *data)
-{
- return __of_genpd_add_provider(np, __of_genpd_xlate_onecell, data);
-}
+#endif /* CONFIG_PM_GENERIC_DOMAINS_OF */
#ifdef CONFIG_PM
extern int dev_pm_domain_attach(struct device *dev, bool power_on);
diff --git a/include/linux/property.h b/include/linux/property.h
index 3a2f9ae..856e50b 100644
--- a/include/linux/property.h
+++ b/include/linux/property.h
@@ -190,7 +190,7 @@
.length = ARRAY_SIZE(_val_) * sizeof(_type_), \
.is_array = true, \
.is_string = false, \
- { .pointer = { _type_##_data = _val_ } }, \
+ { .pointer = { ._type_##_data = _val_ } }, \
}
#define PROPERTY_ENTRY_U8_ARRAY(_name_, _val_) \
diff --git a/include/linux/rcu_sync.h b/include/linux/rcu_sync.h
index a63a33e..ece7ed9 100644
--- a/include/linux/rcu_sync.h
+++ b/include/linux/rcu_sync.h
@@ -59,6 +59,7 @@
}
extern void rcu_sync_init(struct rcu_sync *, enum rcu_sync_type);
+extern void rcu_sync_enter_start(struct rcu_sync *);
extern void rcu_sync_enter(struct rcu_sync *);
extern void rcu_sync_exit(struct rcu_sync *);
extern void rcu_sync_dtor(struct rcu_sync *);
diff --git a/include/linux/rcupdate.h b/include/linux/rcupdate.h
index 1aa62e1..321f9ed 100644
--- a/include/linux/rcupdate.h
+++ b/include/linux/rcupdate.h
@@ -334,6 +334,7 @@
void rcu_bh_qs(void);
void rcu_check_callbacks(int user);
void rcu_report_dead(unsigned int cpu);
+void rcu_cpu_starting(unsigned int cpu);
#ifndef CONFIG_TINY_RCU
void rcu_end_inkernel_boot(void);
diff --git a/include/linux/sched.h b/include/linux/sched.h
index 62c68e5..98fe95f 100644
--- a/include/linux/sched.h
+++ b/include/linux/sched.h
@@ -3469,15 +3469,20 @@
return task_rlimit_max(current, limit);
}
+#define SCHED_CPUFREQ_RT (1U << 0)
+#define SCHED_CPUFREQ_DL (1U << 1)
+#define SCHED_CPUFREQ_IOWAIT (1U << 2)
+
+#define SCHED_CPUFREQ_RT_DL (SCHED_CPUFREQ_RT | SCHED_CPUFREQ_DL)
+
#ifdef CONFIG_CPU_FREQ
struct update_util_data {
- void (*func)(struct update_util_data *data,
- u64 time, unsigned long util, unsigned long max);
+ void (*func)(struct update_util_data *data, u64 time, unsigned int flags);
};
void cpufreq_add_update_util_hook(int cpu, struct update_util_data *data,
- void (*func)(struct update_util_data *data, u64 time,
- unsigned long util, unsigned long max));
+ void (*func)(struct update_util_data *data, u64 time,
+ unsigned int flags));
void cpufreq_remove_update_util_hook(int cpu);
#endif /* CONFIG_CPU_FREQ */
diff --git a/include/linux/smp.h b/include/linux/smp.h
index eccae469..8e0cb7a 100644
--- a/include/linux/smp.h
+++ b/include/linux/smp.h
@@ -196,6 +196,9 @@
void smp_setup_processor_id(void);
+int smp_call_on_cpu(unsigned int cpu, int (*func)(void *), void *par,
+ bool phys);
+
/* SMP core functions */
int smpcfd_prepare_cpu(unsigned int cpu);
int smpcfd_dead_cpu(unsigned int cpu);
diff --git a/include/linux/suspend.h b/include/linux/suspend.h
index 7693e39..d971837 100644
--- a/include/linux/suspend.h
+++ b/include/linux/suspend.h
@@ -245,6 +245,7 @@
return unlikely(suspend_freeze_state == FREEZE_STATE_ENTER);
}
+extern void __init pm_states_init(void);
extern void freeze_set_ops(const struct platform_freeze_ops *ops);
extern void freeze_wake(void);
@@ -279,6 +280,7 @@
static inline void suspend_set_ops(const struct platform_suspend_ops *ops) {}
static inline int pm_suspend(suspend_state_t state) { return -ENOSYS; }
static inline bool idle_should_freeze(void) { return false; }
+static inline void __init pm_states_init(void) {}
static inline void freeze_set_ops(const struct platform_freeze_ops *ops) {}
static inline void freeze_wake(void) {}
#endif /* !CONFIG_SUSPEND */
diff --git a/include/linux/swap.h b/include/linux/swap.h
index b17cc48..4a529c9 100644
--- a/include/linux/swap.h
+++ b/include/linux/swap.h
@@ -257,6 +257,7 @@
static inline void workingset_node_pages_dec(struct radix_tree_node *node)
{
+ VM_BUG_ON(!workingset_node_pages(node));
node->count--;
}
@@ -272,6 +273,7 @@
static inline void workingset_node_shadows_dec(struct radix_tree_node *node)
{
+ VM_BUG_ON(!workingset_node_shadows(node));
node->count -= 1U << RADIX_TREE_COUNT_SHIFT;
}
diff --git a/include/linux/torture.h b/include/linux/torture.h
index 6685a73..a45702e 100644
--- a/include/linux/torture.h
+++ b/include/linux/torture.h
@@ -43,7 +43,7 @@
#define TORTURE_FLAG "-torture:"
#define TOROUT_STRING(s) \
- pr_alert("%s" TORTURE_FLAG s "\n", torture_type)
+ pr_alert("%s" TORTURE_FLAG " %s\n", torture_type, s)
#define VERBOSE_TOROUT_STRING(s) \
do { if (verbose) pr_alert("%s" TORTURE_FLAG " %s\n", torture_type, s); } while (0)
#define VERBOSE_TOROUT_ERRSTRING(s) \
diff --git a/include/media/cec.h b/include/media/cec.h
index dc7854b..fdb5d60 100644
--- a/include/media/cec.h
+++ b/include/media/cec.h
@@ -57,8 +57,8 @@
int minor;
bool registered;
bool unregistered;
- struct mutex fhs_lock;
struct list_head fhs;
+ struct mutex lock;
};
struct cec_adapter;
diff --git a/include/net/netfilter/nf_conntrack_synproxy.h b/include/net/netfilter/nf_conntrack_synproxy.h
index 6793614..e693731 100644
--- a/include/net/netfilter/nf_conntrack_synproxy.h
+++ b/include/net/netfilter/nf_conntrack_synproxy.h
@@ -27,6 +27,20 @@
#endif
}
+static inline bool nf_ct_add_synproxy(struct nf_conn *ct,
+ const struct nf_conn *tmpl)
+{
+ if (tmpl && nfct_synproxy(tmpl)) {
+ if (!nfct_seqadj_ext_add(ct))
+ return false;
+
+ if (!nfct_synproxy_ext_add(ct))
+ return false;
+ }
+
+ return true;
+}
+
struct synproxy_stats {
unsigned int syn_received;
unsigned int cookie_invalid;
diff --git a/include/net/sctp/sm.h b/include/net/sctp/sm.h
index efc0174..bafe2a0 100644
--- a/include/net/sctp/sm.h
+++ b/include/net/sctp/sm.h
@@ -382,7 +382,7 @@
ADDIP_SERIAL_SIGN_BIT = (1<<31)
};
-static inline int ADDIP_SERIAL_gte(__u16 s, __u16 t)
+static inline int ADDIP_SERIAL_gte(__u32 s, __u32 t)
{
return ((s) == (t)) || (((t) - (s)) & ADDIP_SERIAL_SIGN_BIT);
}
diff --git a/include/net/sctp/structs.h b/include/net/sctp/structs.h
index ce93c4b..ced0df3 100644
--- a/include/net/sctp/structs.h
+++ b/include/net/sctp/structs.h
@@ -554,6 +554,9 @@
atomic_t refcnt;
+ /* How many times this chunk have been sent, for prsctp RTX policy */
+ int sent_count;
+
/* This is our link to the per-transport transmitted list. */
struct list_head transmitted_list;
@@ -603,16 +606,6 @@
/* This needs to be recoverable for SCTP_SEND_FAILED events. */
struct sctp_sndrcvinfo sinfo;
- /* We use this field to record param for prsctp policies,
- * for TTL policy, it is the time_to_drop of this chunk,
- * for RTX policy, it is the max_sent_count of this chunk,
- * for PRIO policy, it is the priority of this chunk.
- */
- unsigned long prsctp_param;
-
- /* How many times this chunk have been sent, for prsctp RTX policy */
- int sent_count;
-
/* Which association does this belong to? */
struct sctp_association *asoc;
diff --git a/include/net/sock.h b/include/net/sock.h
index ff5be7e..8741988 100644
--- a/include/net/sock.h
+++ b/include/net/sock.h
@@ -1332,6 +1332,16 @@
if (!sk_has_account(sk))
return;
sk->sk_forward_alloc += size;
+
+ /* Avoid a possible overflow.
+ * TCP send queues can make this happen, if sk_mem_reclaim()
+ * is not called and more than 2 GBytes are released at once.
+ *
+ * If we reach 2 MBytes, reclaim 1 MBytes right now, there is
+ * no need to hold that much forward allocation anyway.
+ */
+ if (unlikely(sk->sk_forward_alloc >= 1 << 21))
+ __sk_mem_reclaim(sk, 1 << 20);
}
static inline void sk_wmem_free_skb(struct sock *sk, struct sk_buff *skb)
diff --git a/include/net/xfrm.h b/include/net/xfrm.h
index adfebd6..1793431 100644
--- a/include/net/xfrm.h
+++ b/include/net/xfrm.h
@@ -1540,8 +1540,10 @@
void xfrm4_local_error(struct sk_buff *skb, u32 mtu);
int xfrm6_extract_header(struct sk_buff *skb);
int xfrm6_extract_input(struct xfrm_state *x, struct sk_buff *skb);
-int xfrm6_rcv_spi(struct sk_buff *skb, int nexthdr, __be32 spi);
+int xfrm6_rcv_spi(struct sk_buff *skb, int nexthdr, __be32 spi,
+ struct ip6_tnl *t);
int xfrm6_transport_finish(struct sk_buff *skb, int async);
+int xfrm6_rcv_tnl(struct sk_buff *skb, struct ip6_tnl *t);
int xfrm6_rcv(struct sk_buff *skb);
int xfrm6_input_addr(struct sk_buff *skb, xfrm_address_t *daddr,
xfrm_address_t *saddr, u8 proto);
diff --git a/include/scsi/scsi_host.h b/include/scsi/scsi_host.h
index 0dee7af..7e4cd53 100644
--- a/include/scsi/scsi_host.h
+++ b/include/scsi/scsi_host.h
@@ -771,12 +771,9 @@
shost->tmf_in_progress;
}
-extern bool scsi_use_blk_mq;
-
static inline bool shost_use_blk_mq(struct Scsi_Host *shost)
{
- return scsi_use_blk_mq;
-
+ return shost->use_blk_mq;
}
extern int scsi_queue_work(struct Scsi_Host *, struct work_struct *);
diff --git a/include/trace/events/power.h b/include/trace/events/power.h
index 19e5030..54e3aad 100644
--- a/include/trace/events/power.h
+++ b/include/trace/events/power.h
@@ -69,7 +69,8 @@
u64 mperf,
u64 aperf,
u64 tsc,
- u32 freq
+ u32 freq,
+ u32 io_boost
),
TP_ARGS(core_busy,
@@ -79,7 +80,8 @@
mperf,
aperf,
tsc,
- freq
+ freq,
+ io_boost
),
TP_STRUCT__entry(
@@ -91,6 +93,7 @@
__field(u64, aperf)
__field(u64, tsc)
__field(u32, freq)
+ __field(u32, io_boost)
),
TP_fast_assign(
@@ -102,9 +105,10 @@
__entry->aperf = aperf;
__entry->tsc = tsc;
__entry->freq = freq;
+ __entry->io_boost = io_boost;
),
- TP_printk("core_busy=%lu scaled=%lu from=%lu to=%lu mperf=%llu aperf=%llu tsc=%llu freq=%lu ",
+ TP_printk("core_busy=%lu scaled=%lu from=%lu to=%lu mperf=%llu aperf=%llu tsc=%llu freq=%lu io_boost=%lu",
(unsigned long)__entry->core_busy,
(unsigned long)__entry->scaled_busy,
(unsigned long)__entry->from,
@@ -112,7 +116,8 @@
(unsigned long long)__entry->mperf,
(unsigned long long)__entry->aperf,
(unsigned long long)__entry->tsc,
- (unsigned long)__entry->freq
+ (unsigned long)__entry->freq,
+ (unsigned long)__entry->io_boost
)
);
diff --git a/include/xen/interface/sched.h b/include/xen/interface/sched.h
index f184909..a4c4d73 100644
--- a/include/xen/interface/sched.h
+++ b/include/xen/interface/sched.h
@@ -3,6 +3,24 @@
*
* Scheduler state interactions
*
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to
+ * deal in the Software without restriction, including without limitation the
+ * rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
+ * sell copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in
+ * all copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
+ * FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
+ * DEALINGS IN THE SOFTWARE.
+ *
* Copyright (c) 2005, Keir Fraser <keir@xensource.com>
*/
@@ -12,18 +30,30 @@
#include <xen/interface/event_channel.h>
/*
+ * Guest Scheduler Operations
+ *
+ * The SCHEDOP interface provides mechanisms for a guest to interact
+ * with the scheduler, including yield, blocking and shutting itself
+ * down.
+ */
+
+/*
* The prototype for this hypercall is:
- * long sched_op_new(int cmd, void *arg)
+ * long HYPERVISOR_sched_op(enum sched_op cmd, void *arg, ...)
+ *
* @cmd == SCHEDOP_??? (scheduler operation).
* @arg == Operation-specific extra argument(s), as described below.
+ * ... == Additional Operation-specific extra arguments, described below.
*
- * **NOTE**:
- * Versions of Xen prior to 3.0.2 provide only the following legacy version
+ * Versions of Xen prior to 3.0.2 provided only the following legacy version
* of this hypercall, supporting only the commands yield, block and shutdown:
* long sched_op(int cmd, unsigned long arg)
* @cmd == SCHEDOP_??? (scheduler operation).
* @arg == 0 (SCHEDOP_yield and SCHEDOP_block)
* == SHUTDOWN_* code (SCHEDOP_shutdown)
+ *
+ * This legacy version is available to new guests as:
+ * long HYPERVISOR_sched_op_compat(enum sched_op cmd, unsigned long arg)
*/
/*
@@ -44,12 +74,17 @@
/*
* Halt execution of this domain (all VCPUs) and notify the system controller.
* @arg == pointer to sched_shutdown structure.
+ *
+ * If the sched_shutdown_t reason is SHUTDOWN_suspend then
+ * x86 PV guests must also set RDX (EDX for 32-bit guests) to the MFN
+ * of the guest's start info page. RDX/EDX is the third hypercall
+ * argument.
+ *
+ * In addition, which reason is SHUTDOWN_suspend this hypercall
+ * returns 1 if suspend was cancelled or the domain was merely
+ * checkpointed, and 0 if it is resuming in a new domain.
*/
#define SCHEDOP_shutdown 2
-struct sched_shutdown {
- unsigned int reason; /* SHUTDOWN_* */
-};
-DEFINE_GUEST_HANDLE_STRUCT(sched_shutdown);
/*
* Poll a set of event-channel ports. Return when one or more are pending. An
@@ -57,12 +92,6 @@
* @arg == pointer to sched_poll structure.
*/
#define SCHEDOP_poll 3
-struct sched_poll {
- GUEST_HANDLE(evtchn_port_t) ports;
- unsigned int nr_ports;
- uint64_t timeout;
-};
-DEFINE_GUEST_HANDLE_STRUCT(sched_poll);
/*
* Declare a shutdown for another domain. The main use of this function is
@@ -71,15 +100,11 @@
* @arg == pointer to sched_remote_shutdown structure.
*/
#define SCHEDOP_remote_shutdown 4
-struct sched_remote_shutdown {
- domid_t domain_id; /* Remote domain ID */
- unsigned int reason; /* SHUTDOWN_xxx reason */
-};
/*
* Latch a shutdown code, so that when the domain later shuts down it
* reports this code to the control tools.
- * @arg == as for SCHEDOP_shutdown.
+ * @arg == sched_shutdown, as for SCHEDOP_shutdown.
*/
#define SCHEDOP_shutdown_code 5
@@ -92,10 +117,47 @@
* With id != 0 and timeout != 0, poke watchdog timer and set new timeout.
*/
#define SCHEDOP_watchdog 6
+
+/*
+ * Override the current vcpu affinity by pinning it to one physical cpu or
+ * undo this override restoring the previous affinity.
+ * @arg == pointer to sched_pin_override structure.
+ *
+ * A negative pcpu value will undo a previous pin override and restore the
+ * previous cpu affinity.
+ * This call is allowed for the hardware domain only and requires the cpu
+ * to be part of the domain's cpupool.
+ */
+#define SCHEDOP_pin_override 7
+
+struct sched_shutdown {
+ unsigned int reason; /* SHUTDOWN_* => shutdown reason */
+};
+DEFINE_GUEST_HANDLE_STRUCT(sched_shutdown);
+
+struct sched_poll {
+ GUEST_HANDLE(evtchn_port_t) ports;
+ unsigned int nr_ports;
+ uint64_t timeout;
+};
+DEFINE_GUEST_HANDLE_STRUCT(sched_poll);
+
+struct sched_remote_shutdown {
+ domid_t domain_id; /* Remote domain ID */
+ unsigned int reason; /* SHUTDOWN_* => shutdown reason */
+};
+DEFINE_GUEST_HANDLE_STRUCT(sched_remote_shutdown);
+
struct sched_watchdog {
uint32_t id; /* watchdog ID */
uint32_t timeout; /* timeout */
};
+DEFINE_GUEST_HANDLE_STRUCT(sched_watchdog);
+
+struct sched_pin_override {
+ int32_t pcpu;
+};
+DEFINE_GUEST_HANDLE_STRUCT(sched_pin_override);
/*
* Reason codes for SCHEDOP_shutdown. These may be interpreted by control
@@ -107,6 +169,7 @@
#define SHUTDOWN_suspend 2 /* Clean up, save suspend info, kill. */
#define SHUTDOWN_crash 3 /* Tell controller we've crashed. */
#define SHUTDOWN_watchdog 4 /* Restart because watchdog time expired. */
+
/*
* Domain asked to perform 'soft reset' for it. The expected behavior is to
* reset internal Xen state for the domain returning it to the point where it
@@ -115,5 +178,6 @@
* interfaces again.
*/
#define SHUTDOWN_soft_reset 5
+#define SHUTDOWN_MAX 5 /* Maximum valid shutdown reason. */
#endif /* __XEN_PUBLIC_SCHED_H__ */
diff --git a/kernel/cgroup.c b/kernel/cgroup.c
index d1c51b7..9ba28310 100644
--- a/kernel/cgroup.c
+++ b/kernel/cgroup.c
@@ -3446,9 +3446,28 @@
* Except for the root, subtree_control must be zero for a cgroup
* with tasks so that child cgroups don't compete against tasks.
*/
- if (enable && cgroup_parent(cgrp) && !list_empty(&cgrp->cset_links)) {
- ret = -EBUSY;
- goto out_unlock;
+ if (enable && cgroup_parent(cgrp)) {
+ struct cgrp_cset_link *link;
+
+ /*
+ * Because namespaces pin csets too, @cgrp->cset_links
+ * might not be empty even when @cgrp is empty. Walk and
+ * verify each cset.
+ */
+ spin_lock_irq(&css_set_lock);
+
+ ret = 0;
+ list_for_each_entry(link, &cgrp->cset_links, cset_link) {
+ if (css_set_populated(link->cset)) {
+ ret = -EBUSY;
+ break;
+ }
+ }
+
+ spin_unlock_irq(&css_set_lock);
+
+ if (ret)
+ goto out_unlock;
}
/* save and update control masks and prepare csses */
@@ -3899,7 +3918,9 @@
* cgroup_task_count - count the number of tasks in a cgroup.
* @cgrp: the cgroup in question
*
- * Return the number of tasks in the cgroup.
+ * Return the number of tasks in the cgroup. The returned number can be
+ * higher than the actual number of tasks due to css_set references from
+ * namespace roots and temporary usages.
*/
static int cgroup_task_count(const struct cgroup *cgrp)
{
@@ -5606,6 +5627,12 @@
BUG_ON(cgroup_init_cftypes(NULL, cgroup_dfl_base_files));
BUG_ON(cgroup_init_cftypes(NULL, cgroup_legacy_base_files));
+ /*
+ * The latency of the synchronize_sched() is too high for cgroups,
+ * avoid it at the cost of forcing all readers into the slow path.
+ */
+ rcu_sync_enter_start(&cgroup_threadgroup_rwsem.rss);
+
get_user_ns(init_cgroup_ns.user_ns);
mutex_lock(&cgroup_mutex);
@@ -6270,6 +6297,12 @@
if (cgroup_sk_alloc_disabled)
return;
+ /* Socket clone path */
+ if (skcd->val) {
+ cgroup_get(sock_cgroup_ptr(skcd));
+ return;
+ }
+
rcu_read_lock();
while (true) {
diff --git a/kernel/cpu.c b/kernel/cpu.c
index 341bf80..92c2451 100644
--- a/kernel/cpu.c
+++ b/kernel/cpu.c
@@ -889,6 +889,7 @@
struct cpuhp_cpu_state *st = per_cpu_ptr(&cpuhp_state, cpu);
enum cpuhp_state target = min((int)st->target, CPUHP_AP_ONLINE);
+ rcu_cpu_starting(cpu); /* Enables RCU usage on this CPU. */
while (st->state < target) {
struct cpuhp_step *step;
@@ -1024,12 +1025,13 @@
#ifdef CONFIG_PM_SLEEP_SMP
static cpumask_var_t frozen_cpus;
-int disable_nonboot_cpus(void)
+int freeze_secondary_cpus(int primary)
{
- int cpu, first_cpu, error = 0;
+ int cpu, error = 0;
cpu_maps_update_begin();
- first_cpu = cpumask_first(cpu_online_mask);
+ if (!cpu_online(primary))
+ primary = cpumask_first(cpu_online_mask);
/*
* We take down all of the non-boot CPUs in one shot to avoid races
* with the userspace trying to use the CPU hotplug at the same time
@@ -1038,7 +1040,7 @@
pr_info("Disabling non-boot CPUs ...\n");
for_each_online_cpu(cpu) {
- if (cpu == first_cpu)
+ if (cpu == primary)
continue;
trace_suspend_resume(TPS("CPU_OFF"), cpu, true);
error = _cpu_down(cpu, 1, CPUHP_OFFLINE);
diff --git a/kernel/cpuset.c b/kernel/cpuset.c
index c27e533..2b4c20a 100644
--- a/kernel/cpuset.c
+++ b/kernel/cpuset.c
@@ -325,8 +325,7 @@
/*
* Return in pmask the portion of a cpusets's cpus_allowed that
* are online. If none are online, walk up the cpuset hierarchy
- * until we find one that does have some online cpus. The top
- * cpuset always has some cpus online.
+ * until we find one that does have some online cpus.
*
* One way or another, we guarantee to return some non-empty subset
* of cpu_online_mask.
@@ -335,8 +334,20 @@
*/
static void guarantee_online_cpus(struct cpuset *cs, struct cpumask *pmask)
{
- while (!cpumask_intersects(cs->effective_cpus, cpu_online_mask))
+ while (!cpumask_intersects(cs->effective_cpus, cpu_online_mask)) {
cs = parent_cs(cs);
+ if (unlikely(!cs)) {
+ /*
+ * The top cpuset doesn't have any online cpu as a
+ * consequence of a race between cpuset_hotplug_work
+ * and cpu hotplug notifier. But we know the top
+ * cpuset's effective_cpus is on its way to to be
+ * identical to cpu_online_mask.
+ */
+ cpumask_copy(pmask, cpu_online_mask);
+ return;
+ }
+ }
cpumask_and(pmask, cs->effective_cpus, cpu_online_mask);
}
@@ -2074,7 +2085,7 @@
* which could have been changed by cpuset just after it inherits the
* state from the parent and before it sits on the cgroup's task list.
*/
-void cpuset_fork(struct task_struct *task)
+static void cpuset_fork(struct task_struct *task)
{
if (task_css_is_root(task, cpuset_cgrp_id))
return;
diff --git a/kernel/futex.c b/kernel/futex.c
index 46cb3a3..2c4be46 100644
--- a/kernel/futex.c
+++ b/kernel/futex.c
@@ -381,8 +381,12 @@
#endif
}
-/*
- * We hash on the keys returned from get_futex_key (see below).
+/**
+ * hash_futex - Return the hash bucket in the global hash
+ * @key: Pointer to the futex key for which the hash is calculated
+ *
+ * We hash on the keys returned from get_futex_key (see below) and return the
+ * corresponding hash bucket in the global hash.
*/
static struct futex_hash_bucket *hash_futex(union futex_key *key)
{
@@ -392,7 +396,12 @@
return &futex_queues[hash & (futex_hashsize - 1)];
}
-/*
+
+/**
+ * match_futex - Check whether two futex keys are equal
+ * @key1: Pointer to key1
+ * @key2: Pointer to key2
+ *
* Return 1 if two futex_keys are equal, 0 otherwise.
*/
static inline int match_futex(union futex_key *key1, union futex_key *key2)
diff --git a/kernel/hung_task.c b/kernel/hung_task.c
index d234022..432c3d7 100644
--- a/kernel/hung_task.c
+++ b/kernel/hung_task.c
@@ -117,7 +117,7 @@
pr_err("\"echo 0 > /proc/sys/kernel/hung_task_timeout_secs\""
" disables this message.\n");
sched_show_task(t);
- debug_show_held_locks(t);
+ debug_show_all_locks();
touch_nmi_watchdog();
diff --git a/kernel/irq/chip.c b/kernel/irq/chip.c
index 6373890..26ba565 100644
--- a/kernel/irq/chip.c
+++ b/kernel/irq/chip.c
@@ -820,6 +820,8 @@
desc->name = name;
if (handle != handle_bad_irq && is_chained) {
+ unsigned int type = irqd_get_trigger_type(&desc->irq_data);
+
/*
* We're about to start this interrupt immediately,
* hence the need to set the trigger configuration.
@@ -828,8 +830,10 @@
* chained interrupt. Reset it immediately because we
* do know better.
*/
- __irq_set_trigger(desc, irqd_get_trigger_type(&desc->irq_data));
- desc->handle_irq = handle;
+ if (type != IRQ_TYPE_NONE) {
+ __irq_set_trigger(desc, type);
+ desc->handle_irq = handle;
+ }
irq_settings_set_noprobe(desc);
irq_settings_set_norequest(desc);
diff --git a/kernel/locking/Makefile b/kernel/locking/Makefile
index 31322a4..6f88e35 100644
--- a/kernel/locking/Makefile
+++ b/kernel/locking/Makefile
@@ -18,7 +18,6 @@
endif
obj-$(CONFIG_SMP) += spinlock.o
obj-$(CONFIG_LOCK_SPIN_ON_OWNER) += osq_lock.o
-obj-$(CONFIG_SMP) += lglock.o
obj-$(CONFIG_PROVE_LOCKING) += spinlock.o
obj-$(CONFIG_QUEUED_SPINLOCKS) += qspinlock.o
obj-$(CONFIG_RT_MUTEXES) += rtmutex.o
diff --git a/kernel/locking/lglock.c b/kernel/locking/lglock.c
deleted file mode 100644
index 951cfcd..0000000
--- a/kernel/locking/lglock.c
+++ /dev/null
@@ -1,111 +0,0 @@
-/* See include/linux/lglock.h for description */
-#include <linux/module.h>
-#include <linux/lglock.h>
-#include <linux/cpu.h>
-#include <linux/string.h>
-
-/*
- * Note there is no uninit, so lglocks cannot be defined in
- * modules (but it's fine to use them from there)
- * Could be added though, just undo lg_lock_init
- */
-
-void lg_lock_init(struct lglock *lg, char *name)
-{
- LOCKDEP_INIT_MAP(&lg->lock_dep_map, name, &lg->lock_key, 0);
-}
-EXPORT_SYMBOL(lg_lock_init);
-
-void lg_local_lock(struct lglock *lg)
-{
- arch_spinlock_t *lock;
-
- preempt_disable();
- lock_acquire_shared(&lg->lock_dep_map, 0, 0, NULL, _RET_IP_);
- lock = this_cpu_ptr(lg->lock);
- arch_spin_lock(lock);
-}
-EXPORT_SYMBOL(lg_local_lock);
-
-void lg_local_unlock(struct lglock *lg)
-{
- arch_spinlock_t *lock;
-
- lock_release(&lg->lock_dep_map, 1, _RET_IP_);
- lock = this_cpu_ptr(lg->lock);
- arch_spin_unlock(lock);
- preempt_enable();
-}
-EXPORT_SYMBOL(lg_local_unlock);
-
-void lg_local_lock_cpu(struct lglock *lg, int cpu)
-{
- arch_spinlock_t *lock;
-
- preempt_disable();
- lock_acquire_shared(&lg->lock_dep_map, 0, 0, NULL, _RET_IP_);
- lock = per_cpu_ptr(lg->lock, cpu);
- arch_spin_lock(lock);
-}
-EXPORT_SYMBOL(lg_local_lock_cpu);
-
-void lg_local_unlock_cpu(struct lglock *lg, int cpu)
-{
- arch_spinlock_t *lock;
-
- lock_release(&lg->lock_dep_map, 1, _RET_IP_);
- lock = per_cpu_ptr(lg->lock, cpu);
- arch_spin_unlock(lock);
- preempt_enable();
-}
-EXPORT_SYMBOL(lg_local_unlock_cpu);
-
-void lg_double_lock(struct lglock *lg, int cpu1, int cpu2)
-{
- BUG_ON(cpu1 == cpu2);
-
- /* lock in cpu order, just like lg_global_lock */
- if (cpu2 < cpu1)
- swap(cpu1, cpu2);
-
- preempt_disable();
- lock_acquire_shared(&lg->lock_dep_map, 0, 0, NULL, _RET_IP_);
- arch_spin_lock(per_cpu_ptr(lg->lock, cpu1));
- arch_spin_lock(per_cpu_ptr(lg->lock, cpu2));
-}
-
-void lg_double_unlock(struct lglock *lg, int cpu1, int cpu2)
-{
- lock_release(&lg->lock_dep_map, 1, _RET_IP_);
- arch_spin_unlock(per_cpu_ptr(lg->lock, cpu1));
- arch_spin_unlock(per_cpu_ptr(lg->lock, cpu2));
- preempt_enable();
-}
-
-void lg_global_lock(struct lglock *lg)
-{
- int i;
-
- preempt_disable();
- lock_acquire_exclusive(&lg->lock_dep_map, 0, 0, NULL, _RET_IP_);
- for_each_possible_cpu(i) {
- arch_spinlock_t *lock;
- lock = per_cpu_ptr(lg->lock, i);
- arch_spin_lock(lock);
- }
-}
-EXPORT_SYMBOL(lg_global_lock);
-
-void lg_global_unlock(struct lglock *lg)
-{
- int i;
-
- lock_release(&lg->lock_dep_map, 1, _RET_IP_);
- for_each_possible_cpu(i) {
- arch_spinlock_t *lock;
- lock = per_cpu_ptr(lg->lock, i);
- arch_spin_unlock(lock);
- }
- preempt_enable();
-}
-EXPORT_SYMBOL(lg_global_unlock);
diff --git a/kernel/locking/percpu-rwsem.c b/kernel/locking/percpu-rwsem.c
index bec0b64..ce18259 100644
--- a/kernel/locking/percpu-rwsem.c
+++ b/kernel/locking/percpu-rwsem.c
@@ -8,152 +8,186 @@
#include <linux/sched.h>
#include <linux/errno.h>
-int __percpu_init_rwsem(struct percpu_rw_semaphore *brw,
+int __percpu_init_rwsem(struct percpu_rw_semaphore *sem,
const char *name, struct lock_class_key *rwsem_key)
{
- brw->fast_read_ctr = alloc_percpu(int);
- if (unlikely(!brw->fast_read_ctr))
+ sem->read_count = alloc_percpu(int);
+ if (unlikely(!sem->read_count))
return -ENOMEM;
/* ->rw_sem represents the whole percpu_rw_semaphore for lockdep */
- __init_rwsem(&brw->rw_sem, name, rwsem_key);
- rcu_sync_init(&brw->rss, RCU_SCHED_SYNC);
- atomic_set(&brw->slow_read_ctr, 0);
- init_waitqueue_head(&brw->write_waitq);
+ rcu_sync_init(&sem->rss, RCU_SCHED_SYNC);
+ __init_rwsem(&sem->rw_sem, name, rwsem_key);
+ init_waitqueue_head(&sem->writer);
+ sem->readers_block = 0;
return 0;
}
EXPORT_SYMBOL_GPL(__percpu_init_rwsem);
-void percpu_free_rwsem(struct percpu_rw_semaphore *brw)
+void percpu_free_rwsem(struct percpu_rw_semaphore *sem)
{
/*
* XXX: temporary kludge. The error path in alloc_super()
* assumes that percpu_free_rwsem() is safe after kzalloc().
*/
- if (!brw->fast_read_ctr)
+ if (!sem->read_count)
return;
- rcu_sync_dtor(&brw->rss);
- free_percpu(brw->fast_read_ctr);
- brw->fast_read_ctr = NULL; /* catch use after free bugs */
+ rcu_sync_dtor(&sem->rss);
+ free_percpu(sem->read_count);
+ sem->read_count = NULL; /* catch use after free bugs */
}
EXPORT_SYMBOL_GPL(percpu_free_rwsem);
-/*
- * This is the fast-path for down_read/up_read. If it succeeds we rely
- * on the barriers provided by rcu_sync_enter/exit; see the comments in
- * percpu_down_write() and percpu_up_write().
- *
- * If this helper fails the callers rely on the normal rw_semaphore and
- * atomic_dec_and_test(), so in this case we have the necessary barriers.
- */
-static bool update_fast_ctr(struct percpu_rw_semaphore *brw, unsigned int val)
-{
- bool success;
-
- preempt_disable();
- success = rcu_sync_is_idle(&brw->rss);
- if (likely(success))
- __this_cpu_add(*brw->fast_read_ctr, val);
- preempt_enable();
-
- return success;
-}
-
-/*
- * Like the normal down_read() this is not recursive, the writer can
- * come after the first percpu_down_read() and create the deadlock.
- *
- * Note: returns with lock_is_held(brw->rw_sem) == T for lockdep,
- * percpu_up_read() does rwsem_release(). This pairs with the usage
- * of ->rw_sem in percpu_down/up_write().
- */
-void percpu_down_read(struct percpu_rw_semaphore *brw)
-{
- might_sleep();
- rwsem_acquire_read(&brw->rw_sem.dep_map, 0, 0, _RET_IP_);
-
- if (likely(update_fast_ctr(brw, +1)))
- return;
-
- /* Avoid rwsem_acquire_read() and rwsem_release() */
- __down_read(&brw->rw_sem);
- atomic_inc(&brw->slow_read_ctr);
- __up_read(&brw->rw_sem);
-}
-EXPORT_SYMBOL_GPL(percpu_down_read);
-
-int percpu_down_read_trylock(struct percpu_rw_semaphore *brw)
-{
- if (unlikely(!update_fast_ctr(brw, +1))) {
- if (!__down_read_trylock(&brw->rw_sem))
- return 0;
- atomic_inc(&brw->slow_read_ctr);
- __up_read(&brw->rw_sem);
- }
-
- rwsem_acquire_read(&brw->rw_sem.dep_map, 0, 1, _RET_IP_);
- return 1;
-}
-
-void percpu_up_read(struct percpu_rw_semaphore *brw)
-{
- rwsem_release(&brw->rw_sem.dep_map, 1, _RET_IP_);
-
- if (likely(update_fast_ctr(brw, -1)))
- return;
-
- /* false-positive is possible but harmless */
- if (atomic_dec_and_test(&brw->slow_read_ctr))
- wake_up_all(&brw->write_waitq);
-}
-EXPORT_SYMBOL_GPL(percpu_up_read);
-
-static int clear_fast_ctr(struct percpu_rw_semaphore *brw)
-{
- unsigned int sum = 0;
- int cpu;
-
- for_each_possible_cpu(cpu) {
- sum += per_cpu(*brw->fast_read_ctr, cpu);
- per_cpu(*brw->fast_read_ctr, cpu) = 0;
- }
-
- return sum;
-}
-
-void percpu_down_write(struct percpu_rw_semaphore *brw)
+int __percpu_down_read(struct percpu_rw_semaphore *sem, int try)
{
/*
- * Make rcu_sync_is_idle() == F and thus disable the fast-path in
- * percpu_down_read() and percpu_up_read(), and wait for gp pass.
+ * Due to having preemption disabled the decrement happens on
+ * the same CPU as the increment, avoiding the
+ * increment-on-one-CPU-and-decrement-on-another problem.
*
- * The latter synchronises us with the preceding readers which used
- * the fast-past, so we can not miss the result of __this_cpu_add()
- * or anything else inside their criticial sections.
+ * If the reader misses the writer's assignment of readers_block, then
+ * the writer is guaranteed to see the reader's increment.
+ *
+ * Conversely, any readers that increment their sem->read_count after
+ * the writer looks are guaranteed to see the readers_block value,
+ * which in turn means that they are guaranteed to immediately
+ * decrement their sem->read_count, so that it doesn't matter that the
+ * writer missed them.
*/
- rcu_sync_enter(&brw->rss);
- /* exclude other writers, and block the new readers completely */
- down_write(&brw->rw_sem);
+ smp_mb(); /* A matches D */
- /* nobody can use fast_read_ctr, move its sum into slow_read_ctr */
- atomic_add(clear_fast_ctr(brw), &brw->slow_read_ctr);
+ /*
+ * If !readers_block the critical section starts here, matched by the
+ * release in percpu_up_write().
+ */
+ if (likely(!smp_load_acquire(&sem->readers_block)))
+ return 1;
- /* wait for all readers to complete their percpu_up_read() */
- wait_event(brw->write_waitq, !atomic_read(&brw->slow_read_ctr));
+ /*
+ * Per the above comment; we still have preemption disabled and
+ * will thus decrement on the same CPU as we incremented.
+ */
+ __percpu_up_read(sem);
+
+ if (try)
+ return 0;
+
+ /*
+ * We either call schedule() in the wait, or we'll fall through
+ * and reschedule on the preempt_enable() in percpu_down_read().
+ */
+ preempt_enable_no_resched();
+
+ /*
+ * Avoid lockdep for the down/up_read() we already have them.
+ */
+ __down_read(&sem->rw_sem);
+ this_cpu_inc(*sem->read_count);
+ __up_read(&sem->rw_sem);
+
+ preempt_disable();
+ return 1;
+}
+EXPORT_SYMBOL_GPL(__percpu_down_read);
+
+void __percpu_up_read(struct percpu_rw_semaphore *sem)
+{
+ smp_mb(); /* B matches C */
+ /*
+ * In other words, if they see our decrement (presumably to aggregate
+ * zero, as that is the only time it matters) they will also see our
+ * critical section.
+ */
+ __this_cpu_dec(*sem->read_count);
+
+ /* Prod writer to recheck readers_active */
+ wake_up(&sem->writer);
+}
+EXPORT_SYMBOL_GPL(__percpu_up_read);
+
+#define per_cpu_sum(var) \
+({ \
+ typeof(var) __sum = 0; \
+ int cpu; \
+ compiletime_assert_atomic_type(__sum); \
+ for_each_possible_cpu(cpu) \
+ __sum += per_cpu(var, cpu); \
+ __sum; \
+})
+
+/*
+ * Return true if the modular sum of the sem->read_count per-CPU variable is
+ * zero. If this sum is zero, then it is stable due to the fact that if any
+ * newly arriving readers increment a given counter, they will immediately
+ * decrement that same counter.
+ */
+static bool readers_active_check(struct percpu_rw_semaphore *sem)
+{
+ if (per_cpu_sum(*sem->read_count) != 0)
+ return false;
+
+ /*
+ * If we observed the decrement; ensure we see the entire critical
+ * section.
+ */
+
+ smp_mb(); /* C matches B */
+
+ return true;
+}
+
+void percpu_down_write(struct percpu_rw_semaphore *sem)
+{
+ /* Notify readers to take the slow path. */
+ rcu_sync_enter(&sem->rss);
+
+ down_write(&sem->rw_sem);
+
+ /*
+ * Notify new readers to block; up until now, and thus throughout the
+ * longish rcu_sync_enter() above, new readers could still come in.
+ */
+ WRITE_ONCE(sem->readers_block, 1);
+
+ smp_mb(); /* D matches A */
+
+ /*
+ * If they don't see our writer of readers_block, then we are
+ * guaranteed to see their sem->read_count increment, and therefore
+ * will wait for them.
+ */
+
+ /* Wait for all now active readers to complete. */
+ wait_event(sem->writer, readers_active_check(sem));
}
EXPORT_SYMBOL_GPL(percpu_down_write);
-void percpu_up_write(struct percpu_rw_semaphore *brw)
+void percpu_up_write(struct percpu_rw_semaphore *sem)
{
- /* release the lock, but the readers can't use the fast-path */
- up_write(&brw->rw_sem);
/*
- * Enable the fast-path in percpu_down_read() and percpu_up_read()
- * but only after another gp pass; this adds the necessary barrier
- * to ensure the reader can't miss the changes done by us.
+ * Signal the writer is done, no fast path yet.
+ *
+ * One reason that we cannot just immediately flip to readers_fast is
+ * that new readers might fail to see the results of this writer's
+ * critical section.
+ *
+ * Therefore we force it through the slow path which guarantees an
+ * acquire and thereby guarantees the critical section's consistency.
*/
- rcu_sync_exit(&brw->rss);
+ smp_store_release(&sem->readers_block, 0);
+
+ /*
+ * Release the write lock, this will allow readers back in the game.
+ */
+ up_write(&sem->rw_sem);
+
+ /*
+ * Once this completes (at least one RCU-sched grace period hence) the
+ * reader fast path will be available again. Safe to use outside the
+ * exclusive write lock because its counting.
+ */
+ rcu_sync_exit(&sem->rss);
}
EXPORT_SYMBOL_GPL(percpu_up_write);
diff --git a/kernel/locking/qspinlock_paravirt.h b/kernel/locking/qspinlock_paravirt.h
index 8a99abf..e3b5520 100644
--- a/kernel/locking/qspinlock_paravirt.h
+++ b/kernel/locking/qspinlock_paravirt.h
@@ -70,11 +70,14 @@
static inline bool pv_queued_spin_steal_lock(struct qspinlock *lock)
{
struct __qspinlock *l = (void *)lock;
- int ret = !(atomic_read(&lock->val) & _Q_LOCKED_PENDING_MASK) &&
- (cmpxchg(&l->locked, 0, _Q_LOCKED_VAL) == 0);
- qstat_inc(qstat_pv_lock_stealing, ret);
- return ret;
+ if (!(atomic_read(&lock->val) & _Q_LOCKED_PENDING_MASK) &&
+ (cmpxchg(&l->locked, 0, _Q_LOCKED_VAL) == 0)) {
+ qstat_inc(qstat_pv_lock_stealing, true);
+ return true;
+ }
+
+ return false;
}
/*
@@ -257,7 +260,6 @@
static inline bool
pv_wait_early(struct pv_node *prev, int loop)
{
-
if ((loop & PV_PREV_CHECK_MASK) != 0)
return false;
@@ -286,12 +288,10 @@
{
struct pv_node *pn = (struct pv_node *)node;
struct pv_node *pp = (struct pv_node *)prev;
- int waitcnt = 0;
int loop;
bool wait_early;
- /* waitcnt processing will be compiled out if !QUEUED_LOCK_STAT */
- for (;; waitcnt++) {
+ for (;;) {
for (wait_early = false, loop = SPIN_THRESHOLD; loop; loop--) {
if (READ_ONCE(node->locked))
return;
@@ -315,7 +315,6 @@
if (!READ_ONCE(node->locked)) {
qstat_inc(qstat_pv_wait_node, true);
- qstat_inc(qstat_pv_wait_again, waitcnt);
qstat_inc(qstat_pv_wait_early, wait_early);
pv_wait(&pn->state, vcpu_halted);
}
@@ -456,12 +455,9 @@
pv_wait(&l->locked, _Q_SLOW_VAL);
/*
- * The unlocker should have freed the lock before kicking the
- * CPU. So if the lock is still not free, it is a spurious
- * wakeup or another vCPU has stolen the lock. The current
- * vCPU should spin again.
+ * Because of lock stealing, the queue head vCPU may not be
+ * able to acquire the lock before it has to wait again.
*/
- qstat_inc(qstat_pv_spurious_wakeup, READ_ONCE(l->locked));
}
/*
@@ -544,7 +540,7 @@
* unhash. Otherwise it would be possible to have multiple @lock
* entries, which would be BAD.
*/
- locked = cmpxchg(&l->locked, _Q_LOCKED_VAL, 0);
+ locked = cmpxchg_release(&l->locked, _Q_LOCKED_VAL, 0);
if (likely(locked == _Q_LOCKED_VAL))
return;
diff --git a/kernel/locking/qspinlock_stat.h b/kernel/locking/qspinlock_stat.h
index b9d0315..eb0a599 100644
--- a/kernel/locking/qspinlock_stat.h
+++ b/kernel/locking/qspinlock_stat.h
@@ -24,8 +24,8 @@
* pv_latency_wake - average latency (ns) from vCPU kick to wakeup
* pv_lock_slowpath - # of locking operations via the slowpath
* pv_lock_stealing - # of lock stealing operations
- * pv_spurious_wakeup - # of spurious wakeups
- * pv_wait_again - # of vCPU wait's that happened after a vCPU kick
+ * pv_spurious_wakeup - # of spurious wakeups in non-head vCPUs
+ * pv_wait_again - # of wait's after a queue head vCPU kick
* pv_wait_early - # of early vCPU wait's
* pv_wait_head - # of vCPU wait's at the queue head
* pv_wait_node - # of vCPU wait's at a non-head queue node
diff --git a/kernel/locking/rwsem-xadd.c b/kernel/locking/rwsem-xadd.c
index 447e08d..2337b4b 100644
--- a/kernel/locking/rwsem-xadd.c
+++ b/kernel/locking/rwsem-xadd.c
@@ -121,16 +121,19 @@
* - woken process blocks are discarded from the list after having task zeroed
* - writers are only marked woken if downgrading is false
*/
-static struct rw_semaphore *
-__rwsem_mark_wake(struct rw_semaphore *sem,
- enum rwsem_wake_type wake_type, struct wake_q_head *wake_q)
+static void __rwsem_mark_wake(struct rw_semaphore *sem,
+ enum rwsem_wake_type wake_type,
+ struct wake_q_head *wake_q)
{
- struct rwsem_waiter *waiter;
- struct task_struct *tsk;
- struct list_head *next;
- long oldcount, woken, loop, adjustment;
+ struct rwsem_waiter *waiter, *tmp;
+ long oldcount, woken = 0, adjustment = 0;
- waiter = list_entry(sem->wait_list.next, struct rwsem_waiter, list);
+ /*
+ * Take a peek at the queue head waiter such that we can determine
+ * the wakeup(s) to perform.
+ */
+ waiter = list_first_entry(&sem->wait_list, struct rwsem_waiter, list);
+
if (waiter->type == RWSEM_WAITING_FOR_WRITE) {
if (wake_type == RWSEM_WAKE_ANY) {
/*
@@ -142,19 +145,19 @@
*/
wake_q_add(wake_q, waiter->task);
}
- goto out;
+
+ return;
}
- /* Writers might steal the lock before we grant it to the next reader.
+ /*
+ * Writers might steal the lock before we grant it to the next reader.
* We prefer to do the first reader grant before counting readers
* so we can bail out early if a writer stole the lock.
*/
- adjustment = 0;
if (wake_type != RWSEM_WAKE_READ_OWNED) {
adjustment = RWSEM_ACTIVE_READ_BIAS;
try_reader_grant:
oldcount = atomic_long_fetch_add(adjustment, &sem->count);
-
if (unlikely(oldcount < RWSEM_WAITING_BIAS)) {
/*
* If the count is still less than RWSEM_WAITING_BIAS
@@ -164,7 +167,8 @@
*/
if (atomic_long_add_return(-adjustment, &sem->count) <
RWSEM_WAITING_BIAS)
- goto out;
+ return;
+
/* Last active locker left. Retry waking readers. */
goto try_reader_grant;
}
@@ -176,38 +180,23 @@
rwsem_set_reader_owned(sem);
}
- /* Grant an infinite number of read locks to the readers at the front
- * of the queue. Note we increment the 'active part' of the count by
- * the number of readers before waking any processes up.
+ /*
+ * Grant an infinite number of read locks to the readers at the front
+ * of the queue. We know that woken will be at least 1 as we accounted
+ * for above. Note we increment the 'active part' of the count by the
+ * number of readers before waking any processes up.
*/
- woken = 0;
- do {
- woken++;
+ list_for_each_entry_safe(waiter, tmp, &sem->wait_list, list) {
+ struct task_struct *tsk;
- if (waiter->list.next == &sem->wait_list)
+ if (waiter->type == RWSEM_WAITING_FOR_WRITE)
break;
- waiter = list_entry(waiter->list.next,
- struct rwsem_waiter, list);
-
- } while (waiter->type != RWSEM_WAITING_FOR_WRITE);
-
- adjustment = woken * RWSEM_ACTIVE_READ_BIAS - adjustment;
- if (waiter->type != RWSEM_WAITING_FOR_WRITE)
- /* hit end of list above */
- adjustment -= RWSEM_WAITING_BIAS;
-
- if (adjustment)
- atomic_long_add(adjustment, &sem->count);
-
- next = sem->wait_list.next;
- loop = woken;
- do {
- waiter = list_entry(next, struct rwsem_waiter, list);
- next = waiter->list.next;
+ woken++;
tsk = waiter->task;
wake_q_add(wake_q, tsk);
+ list_del(&waiter->list);
/*
* Ensure that the last operation is setting the reader
* waiter to nil such that rwsem_down_read_failed() cannot
@@ -215,13 +204,16 @@
* to the task to wakeup.
*/
smp_store_release(&waiter->task, NULL);
- } while (--loop);
+ }
- sem->wait_list.next = next;
- next->prev = &sem->wait_list;
+ adjustment = woken * RWSEM_ACTIVE_READ_BIAS - adjustment;
+ if (list_empty(&sem->wait_list)) {
+ /* hit end of list above */
+ adjustment -= RWSEM_WAITING_BIAS;
+ }
- out:
- return sem;
+ if (adjustment)
+ atomic_long_add(adjustment, &sem->count);
}
/*
@@ -235,7 +227,6 @@
struct task_struct *tsk = current;
WAKE_Q(wake_q);
- /* set up my own style of waitqueue */
waiter.task = tsk;
waiter.type = RWSEM_WAITING_FOR_READ;
@@ -247,7 +238,8 @@
/* we're now waiting on the lock, but no longer actively locking */
count = atomic_long_add_return(adjustment, &sem->count);
- /* If there are no active locks, wake the front queued process(es).
+ /*
+ * If there are no active locks, wake the front queued process(es).
*
* If there are no writers and we are first in the queue,
* wake our own waiter to join the existing active readers !
@@ -255,7 +247,7 @@
if (count == RWSEM_WAITING_BIAS ||
(count > RWSEM_WAITING_BIAS &&
adjustment != -RWSEM_ACTIVE_READ_BIAS))
- sem = __rwsem_mark_wake(sem, RWSEM_WAKE_ANY, &wake_q);
+ __rwsem_mark_wake(sem, RWSEM_WAKE_ANY, &wake_q);
raw_spin_unlock_irq(&sem->wait_lock);
wake_up_q(&wake_q);
@@ -505,7 +497,7 @@
if (count > RWSEM_WAITING_BIAS) {
WAKE_Q(wake_q);
- sem = __rwsem_mark_wake(sem, RWSEM_WAKE_READERS, &wake_q);
+ __rwsem_mark_wake(sem, RWSEM_WAKE_READERS, &wake_q);
/*
* The wakeup is normally called _after_ the wait_lock
* is released, but given that we are proactively waking
@@ -614,9 +606,8 @@
raw_spin_lock_irqsave(&sem->wait_lock, flags);
locked:
- /* do nothing if list empty */
if (!list_empty(&sem->wait_list))
- sem = __rwsem_mark_wake(sem, RWSEM_WAKE_ANY, &wake_q);
+ __rwsem_mark_wake(sem, RWSEM_WAKE_ANY, &wake_q);
raw_spin_unlock_irqrestore(&sem->wait_lock, flags);
wake_up_q(&wake_q);
@@ -638,9 +629,8 @@
raw_spin_lock_irqsave(&sem->wait_lock, flags);
- /* do nothing if list empty */
if (!list_empty(&sem->wait_list))
- sem = __rwsem_mark_wake(sem, RWSEM_WAKE_READ_OWNED, &wake_q);
+ __rwsem_mark_wake(sem, RWSEM_WAKE_READ_OWNED, &wake_q);
raw_spin_unlock_irqrestore(&sem->wait_lock, flags);
wake_up_q(&wake_q);
diff --git a/kernel/power/Kconfig b/kernel/power/Kconfig
index 68d3ebc..e8517b6 100644
--- a/kernel/power/Kconfig
+++ b/kernel/power/Kconfig
@@ -186,7 +186,7 @@
config DPM_WATCHDOG
bool "Device suspend/resume watchdog"
- depends on PM_DEBUG && PSTORE
+ depends on PM_DEBUG && PSTORE && EXPERT
---help---
Sets up a watchdog timer to capture drivers that are
locked up attempting to suspend/resume a device.
@@ -197,7 +197,7 @@
config DPM_WATCHDOG_TIMEOUT
int "Watchdog timeout in seconds"
range 1 120
- default 60
+ default 120
depends on DPM_WATCHDOG
config PM_TRACE
diff --git a/kernel/power/hibernate.c b/kernel/power/hibernate.c
index 33c79b6..b26dbc4 100644
--- a/kernel/power/hibernate.c
+++ b/kernel/power/hibernate.c
@@ -306,8 +306,10 @@
if (error)
printk(KERN_ERR "PM: Error %d creating hibernation image\n",
error);
- if (!in_suspend)
+ if (!in_suspend) {
events_check_enabled = false;
+ clear_free_pages();
+ }
platform_leave(platform_mode);
@@ -1189,22 +1191,6 @@
return 1;
}
-static int __init page_poison_nohibernate_setup(char *str)
-{
-#ifdef CONFIG_PAGE_POISONING_ZERO
- /*
- * The zeroing option for page poison skips the checks on alloc.
- * since hibernation doesn't save free pages there's no way to
- * guarantee the pages will still be zeroed.
- */
- if (!strcmp(str, "on")) {
- pr_info("Disabling hibernation due to page poisoning\n");
- return nohibernate_setup(str);
- }
-#endif
- return 1;
-}
-
__setup("noresume", noresume_setup);
__setup("resume_offset=", resume_offset_setup);
__setup("resume=", resume_setup);
@@ -1212,4 +1198,3 @@
__setup("resumewait", resumewait_setup);
__setup("resumedelay=", resumedelay_setup);
__setup("nohibernate", nohibernate_setup);
-__setup("page_poison=", page_poison_nohibernate_setup);
diff --git a/kernel/power/main.c b/kernel/power/main.c
index 5ea50b1..281a697 100644
--- a/kernel/power/main.c
+++ b/kernel/power/main.c
@@ -644,6 +644,7 @@
return error;
hibernate_image_size_init();
hibernate_reserved_size_init();
+ pm_states_init();
power_kobj = kobject_create_and_add("power", NULL);
if (!power_kobj)
return -ENOMEM;
diff --git a/kernel/power/power.h b/kernel/power/power.h
index 242d8b8..56d1d0d 100644
--- a/kernel/power/power.h
+++ b/kernel/power/power.h
@@ -110,6 +110,8 @@
extern void free_basic_memory_bitmaps(void);
extern int hibernate_preallocate_memory(void);
+extern void clear_free_pages(void);
+
/**
* Auxiliary structure used for reading the snapshot image data and
* metadata from and writing them to the list of page backup entries
diff --git a/kernel/power/snapshot.c b/kernel/power/snapshot.c
index b022284..4f0f060 100644
--- a/kernel/power/snapshot.c
+++ b/kernel/power/snapshot.c
@@ -1132,6 +1132,28 @@
pr_debug("PM: Basic memory bitmaps freed\n");
}
+void clear_free_pages(void)
+{
+#ifdef CONFIG_PAGE_POISONING_ZERO
+ struct memory_bitmap *bm = free_pages_map;
+ unsigned long pfn;
+
+ if (WARN_ON(!(free_pages_map)))
+ return;
+
+ memory_bm_position_reset(bm);
+ pfn = memory_bm_next_pfn(bm);
+ while (pfn != BM_END_OF_MAP) {
+ if (pfn_valid(pfn))
+ clear_highpage(pfn_to_page(pfn));
+
+ pfn = memory_bm_next_pfn(bm);
+ }
+ memory_bm_position_reset(bm);
+ pr_info("PM: free pages cleared after restore\n");
+#endif /* PAGE_POISONING_ZERO */
+}
+
/**
* snapshot_additional_pages - Estimate the number of extra pages needed.
* @zone: Memory zone to carry out the computation for.
diff --git a/kernel/power/suspend.c b/kernel/power/suspend.c
index 0acab9d..1e7f5da 100644
--- a/kernel/power/suspend.c
+++ b/kernel/power/suspend.c
@@ -118,10 +118,18 @@
*/
static bool relative_states;
+void __init pm_states_init(void)
+{
+ /*
+ * freeze state should be supported even without any suspend_ops,
+ * initialize pm_states accordingly here
+ */
+ pm_states[PM_SUSPEND_FREEZE] = pm_labels[relative_states ? 0 : 2];
+}
+
static int __init sleep_states_setup(char *str)
{
relative_states = !strncmp(str, "1", 1);
- pm_states[PM_SUSPEND_FREEZE] = pm_labels[relative_states ? 0 : 2];
return 1;
}
@@ -211,7 +219,7 @@
{
if (state == PM_SUSPEND_FREEZE && freeze_ops && freeze_ops->begin)
return freeze_ops->begin();
- else if (suspend_ops->begin)
+ else if (suspend_ops && suspend_ops->begin)
return suspend_ops->begin(state);
else
return 0;
@@ -221,7 +229,7 @@
{
if (state == PM_SUSPEND_FREEZE && freeze_ops && freeze_ops->end)
freeze_ops->end();
- else if (suspend_ops->end)
+ else if (suspend_ops && suspend_ops->end)
suspend_ops->end();
}
diff --git a/kernel/rcu/rcuperf.c b/kernel/rcu/rcuperf.c
index d38ab08..123ccbd 100644
--- a/kernel/rcu/rcuperf.c
+++ b/kernel/rcu/rcuperf.c
@@ -52,7 +52,7 @@
#define PERF_FLAG "-perf:"
#define PERFOUT_STRING(s) \
- pr_alert("%s" PERF_FLAG s "\n", perf_type)
+ pr_alert("%s" PERF_FLAG " %s\n", perf_type, s)
#define VERBOSE_PERFOUT_STRING(s) \
do { if (verbose) pr_alert("%s" PERF_FLAG " %s\n", perf_type, s); } while (0)
#define VERBOSE_PERFOUT_ERRSTRING(s) \
@@ -400,9 +400,8 @@
sp.sched_priority = 0;
sched_setscheduler_nocheck(current,
SCHED_NORMAL, &sp);
- pr_alert("%s" PERF_FLAG
- "rcu_perf_writer %ld has %d measurements\n",
- perf_type, me, MIN_MEAS);
+ pr_alert("%s%s rcu_perf_writer %ld has %d measurements\n",
+ perf_type, PERF_FLAG, me, MIN_MEAS);
if (atomic_inc_return(&n_rcu_perf_writer_finished) >=
nrealwriters) {
schedule_timeout_interruptible(10);
diff --git a/kernel/rcu/rcutorture.c b/kernel/rcu/rcutorture.c
index 971e2b1..bf08fee 100644
--- a/kernel/rcu/rcutorture.c
+++ b/kernel/rcu/rcutorture.c
@@ -1238,6 +1238,7 @@
long pipesummary[RCU_TORTURE_PIPE_LEN + 1] = { 0 };
long batchsummary[RCU_TORTURE_PIPE_LEN + 1] = { 0 };
static unsigned long rtcv_snap = ULONG_MAX;
+ struct task_struct *wtp;
for_each_possible_cpu(cpu) {
for (i = 0; i < RCU_TORTURE_PIPE_LEN + 1; i++) {
@@ -1258,8 +1259,9 @@
atomic_read(&n_rcu_torture_alloc),
atomic_read(&n_rcu_torture_alloc_fail),
atomic_read(&n_rcu_torture_free));
- pr_cont("rtmbe: %d rtbke: %ld rtbre: %ld ",
+ pr_cont("rtmbe: %d rtbe: %ld rtbke: %ld rtbre: %ld ",
atomic_read(&n_rcu_torture_mberror),
+ n_rcu_torture_barrier_error,
n_rcu_torture_boost_ktrerror,
n_rcu_torture_boost_rterror);
pr_cont("rtbf: %ld rtb: %ld nt: %ld ",
@@ -1312,10 +1314,12 @@
rcutorture_get_gp_data(cur_ops->ttype,
&flags, &gpnum, &completed);
- pr_alert("??? Writer stall state %s(%d) g%lu c%lu f%#x\n",
+ wtp = READ_ONCE(writer_task);
+ pr_alert("??? Writer stall state %s(%d) g%lu c%lu f%#x ->state %#lx\n",
rcu_torture_writer_state_getname(),
rcu_torture_writer_state,
- gpnum, completed, flags);
+ gpnum, completed, flags,
+ wtp == NULL ? ~0UL : wtp->state);
show_rcu_gp_kthreads();
rcu_ftrace_dump(DUMP_ALL);
}
@@ -1362,12 +1366,12 @@
onoff_interval, onoff_holdoff);
}
-static void rcutorture_booster_cleanup(int cpu)
+static int rcutorture_booster_cleanup(unsigned int cpu)
{
struct task_struct *t;
if (boost_tasks[cpu] == NULL)
- return;
+ return 0;
mutex_lock(&boost_mutex);
t = boost_tasks[cpu];
boost_tasks[cpu] = NULL;
@@ -1375,9 +1379,10 @@
/* This must be outside of the mutex, otherwise deadlock! */
torture_stop_kthread(rcu_torture_boost, t);
+ return 0;
}
-static int rcutorture_booster_init(int cpu)
+static int rcutorture_booster_init(unsigned int cpu)
{
int retval;
@@ -1577,28 +1582,7 @@
}
}
-static int rcutorture_cpu_notify(struct notifier_block *self,
- unsigned long action, void *hcpu)
-{
- long cpu = (long)hcpu;
-
- switch (action & ~CPU_TASKS_FROZEN) {
- case CPU_ONLINE:
- case CPU_DOWN_FAILED:
- (void)rcutorture_booster_init(cpu);
- break;
- case CPU_DOWN_PREPARE:
- rcutorture_booster_cleanup(cpu);
- break;
- default:
- break;
- }
- return NOTIFY_OK;
-}
-
-static struct notifier_block rcutorture_cpu_nb = {
- .notifier_call = rcutorture_cpu_notify,
-};
+static enum cpuhp_state rcutor_hp;
static void
rcu_torture_cleanup(void)
@@ -1638,11 +1622,8 @@
for (i = 0; i < ncbflooders; i++)
torture_stop_kthread(rcu_torture_cbflood, cbflood_task[i]);
if ((test_boost == 1 && cur_ops->can_boost) ||
- test_boost == 2) {
- unregister_cpu_notifier(&rcutorture_cpu_nb);
- for_each_possible_cpu(i)
- rcutorture_booster_cleanup(i);
- }
+ test_boost == 2)
+ cpuhp_remove_state(rcutor_hp);
/*
* Wait for all RCU callbacks to fire, then do flavor-specific
@@ -1869,14 +1850,13 @@
test_boost == 2) {
boost_starttime = jiffies + test_boost_interval * HZ;
- register_cpu_notifier(&rcutorture_cpu_nb);
- for_each_possible_cpu(i) {
- if (cpu_is_offline(i))
- continue; /* Heuristic: CPU can go offline. */
- firsterr = rcutorture_booster_init(i);
- if (firsterr)
- goto unwind;
- }
+
+ firsterr = cpuhp_setup_state(CPUHP_AP_ONLINE_DYN, "RCU_TORTURE",
+ rcutorture_booster_init,
+ rcutorture_booster_cleanup);
+ if (firsterr < 0)
+ goto unwind;
+ rcutor_hp = firsterr;
}
firsterr = torture_shutdown_init(shutdown_secs, rcu_torture_cleanup);
if (firsterr)
diff --git a/kernel/rcu/sync.c b/kernel/rcu/sync.c
index be922c9..50d1861 100644
--- a/kernel/rcu/sync.c
+++ b/kernel/rcu/sync.c
@@ -68,6 +68,8 @@
RCU_LOCKDEP_WARN(!gp_ops[rsp->gp_type].held(),
"suspicious rcu_sync_is_idle() usage");
}
+
+EXPORT_SYMBOL_GPL(rcu_sync_lockdep_assert);
#endif
/**
@@ -83,6 +85,18 @@
}
/**
+ * Must be called after rcu_sync_init() and before first use.
+ *
+ * Ensures rcu_sync_is_idle() returns false and rcu_sync_{enter,exit}()
+ * pairs turn into NO-OPs.
+ */
+void rcu_sync_enter_start(struct rcu_sync *rsp)
+{
+ rsp->gp_count++;
+ rsp->gp_state = GP_PASSED;
+}
+
+/**
* rcu_sync_enter() - Force readers onto slowpath
* @rsp: Pointer to rcu_sync structure to use for synchronization
*
diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
index 5d80925..7e2e038 100644
--- a/kernel/rcu/tree.c
+++ b/kernel/rcu/tree.c
@@ -41,7 +41,6 @@
#include <linux/export.h>
#include <linux/completion.h>
#include <linux/moduleparam.h>
-#include <linux/module.h>
#include <linux/percpu.h>
#include <linux/notifier.h>
#include <linux/cpu.h>
@@ -60,7 +59,6 @@
#include "tree.h"
#include "rcu.h"
-MODULE_ALIAS("rcutree");
#ifdef MODULE_PARAM_PREFIX
#undef MODULE_PARAM_PREFIX
#endif
@@ -1848,6 +1846,7 @@
struct rcu_data *rdp)
{
bool ret;
+ bool need_gp;
/* Handle the ends of any preceding grace periods first. */
if (rdp->completed == rnp->completed &&
@@ -1874,9 +1873,10 @@
*/
rdp->gpnum = rnp->gpnum;
trace_rcu_grace_period(rsp->name, rdp->gpnum, TPS("cpustart"));
- rdp->cpu_no_qs.b.norm = true;
+ need_gp = !!(rnp->qsmask & rdp->grpmask);
+ rdp->cpu_no_qs.b.norm = need_gp;
rdp->rcu_qs_ctr_snap = __this_cpu_read(rcu_qs_ctr);
- rdp->core_needs_qs = !!(rnp->qsmask & rdp->grpmask);
+ rdp->core_needs_qs = need_gp;
zero_cpu_stall_ticks(rdp);
WRITE_ONCE(rdp->gpwrap, false);
}
@@ -2344,7 +2344,7 @@
WARN_ON_ONCE(!rcu_gp_in_progress(rsp));
WRITE_ONCE(rsp->gp_flags, READ_ONCE(rsp->gp_flags) | RCU_GP_FLAG_FQS);
raw_spin_unlock_irqrestore_rcu_node(rcu_get_root(rsp), flags);
- swake_up(&rsp->gp_wq); /* Memory barrier implied by swake_up() path. */
+ rcu_gp_kthread_wake(rsp);
}
/*
@@ -2970,7 +2970,7 @@
}
WRITE_ONCE(rsp->gp_flags, READ_ONCE(rsp->gp_flags) | RCU_GP_FLAG_FQS);
raw_spin_unlock_irqrestore_rcu_node(rnp_old, flags);
- swake_up(&rsp->gp_wq); /* Memory barrier implied by swake_up() path. */
+ rcu_gp_kthread_wake(rsp);
}
/*
@@ -3792,8 +3792,6 @@
rnp = rdp->mynode;
mask = rdp->grpmask;
raw_spin_lock_rcu_node(rnp); /* irqs already disabled. */
- rnp->qsmaskinitnext |= mask;
- rnp->expmaskinitnext |= mask;
if (!rdp->beenonline)
WRITE_ONCE(rsp->ncpus, READ_ONCE(rsp->ncpus) + 1);
rdp->beenonline = true; /* We have now been online. */
@@ -3860,6 +3858,32 @@
return 0;
}
+/*
+ * Mark the specified CPU as being online so that subsequent grace periods
+ * (both expedited and normal) will wait on it. Note that this means that
+ * incoming CPUs are not allowed to use RCU read-side critical sections
+ * until this function is called. Failing to observe this restriction
+ * will result in lockdep splats.
+ */
+void rcu_cpu_starting(unsigned int cpu)
+{
+ unsigned long flags;
+ unsigned long mask;
+ struct rcu_data *rdp;
+ struct rcu_node *rnp;
+ struct rcu_state *rsp;
+
+ for_each_rcu_flavor(rsp) {
+ rdp = this_cpu_ptr(rsp->rda);
+ rnp = rdp->mynode;
+ mask = rdp->grpmask;
+ raw_spin_lock_irqsave_rcu_node(rnp, flags);
+ rnp->qsmaskinitnext |= mask;
+ rnp->expmaskinitnext |= mask;
+ raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
+ }
+}
+
#ifdef CONFIG_HOTPLUG_CPU
/*
* The CPU is exiting the idle loop into the arch_cpu_idle_dead()
@@ -4209,8 +4233,10 @@
* or the scheduler are operational.
*/
pm_notifier(rcu_pm_notify, 0);
- for_each_online_cpu(cpu)
+ for_each_online_cpu(cpu) {
rcutree_prepare_cpu(cpu);
+ rcu_cpu_starting(cpu);
+ }
}
#include "tree_exp.h"
diff --git a/kernel/rcu/tree.h b/kernel/rcu/tree.h
index f714f87..e99a523 100644
--- a/kernel/rcu/tree.h
+++ b/kernel/rcu/tree.h
@@ -400,6 +400,7 @@
#ifdef CONFIG_RCU_FAST_NO_HZ
struct rcu_head oom_head;
#endif /* #ifdef CONFIG_RCU_FAST_NO_HZ */
+ atomic_long_t exp_workdone0; /* # done by workqueue. */
atomic_long_t exp_workdone1; /* # done by others #1. */
atomic_long_t exp_workdone2; /* # done by others #2. */
atomic_long_t exp_workdone3; /* # done by others #3. */
diff --git a/kernel/rcu/tree_exp.h b/kernel/rcu/tree_exp.h
index 6d86ab6..24343eb 100644
--- a/kernel/rcu/tree_exp.h
+++ b/kernel/rcu/tree_exp.h
@@ -359,7 +359,8 @@
struct rcu_dynticks *rdtp = &per_cpu(rcu_dynticks, cpu);
if (raw_smp_processor_id() == cpu ||
- !(atomic_add_return(0, &rdtp->dynticks) & 0x1))
+ !(atomic_add_return(0, &rdtp->dynticks) & 0x1) ||
+ !(rnp->qsmaskinitnext & rdp->grpmask))
mask_ofl_test |= rdp->grpmask;
}
mask_ofl_ipi = rnp->expmask & ~mask_ofl_test;
@@ -384,17 +385,16 @@
mask_ofl_ipi &= ~mask;
continue;
}
- /* Failed, raced with offline. */
+ /* Failed, raced with CPU hotplug operation. */
raw_spin_lock_irqsave_rcu_node(rnp, flags);
- if (cpu_online(cpu) &&
+ if ((rnp->qsmaskinitnext & mask) &&
(rnp->expmask & mask)) {
+ /* Online, so delay for a bit and try again. */
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
schedule_timeout_uninterruptible(1);
- if (cpu_online(cpu) &&
- (rnp->expmask & mask))
- goto retry_ipi;
- raw_spin_lock_irqsave_rcu_node(rnp, flags);
+ goto retry_ipi;
}
+ /* CPU really is offline, so we can ignore it. */
if (!(rnp->expmask & mask))
mask_ofl_ipi &= ~mask;
raw_spin_unlock_irqrestore_rcu_node(rnp, flags);
@@ -427,12 +427,10 @@
jiffies_stall);
if (ret > 0 || sync_rcu_preempt_exp_done(rnp_root))
return;
- if (ret < 0) {
- /* Hit a signal, disable CPU stall warnings. */
- swait_event(rsp->expedited_wq,
- sync_rcu_preempt_exp_done(rnp_root));
- return;
- }
+ WARN_ON(ret < 0); /* workqueues should not be signaled. */
+ if (rcu_cpu_stall_suppress)
+ continue;
+ panic_on_rcu_stall();
pr_err("INFO: %s detected expedited stalls on CPUs/tasks: {",
rsp->name);
ndetected = 0;
@@ -500,7 +498,6 @@
* next GP, to proceed.
*/
mutex_lock(&rsp->exp_wake_mutex);
- mutex_unlock(&rsp->exp_mutex);
rcu_for_each_node_breadth_first(rsp, rnp) {
if (ULONG_CMP_LT(READ_ONCE(rnp->exp_seq_rq), s)) {
@@ -516,6 +513,70 @@
mutex_unlock(&rsp->exp_wake_mutex);
}
+/* Let the workqueue handler know what it is supposed to do. */
+struct rcu_exp_work {
+ smp_call_func_t rew_func;
+ struct rcu_state *rew_rsp;
+ unsigned long rew_s;
+ struct work_struct rew_work;
+};
+
+/*
+ * Work-queue handler to drive an expedited grace period forward.
+ */
+static void wait_rcu_exp_gp(struct work_struct *wp)
+{
+ struct rcu_exp_work *rewp;
+
+ /* Initialize the rcu_node tree in preparation for the wait. */
+ rewp = container_of(wp, struct rcu_exp_work, rew_work);
+ sync_rcu_exp_select_cpus(rewp->rew_rsp, rewp->rew_func);
+
+ /* Wait and clean up, including waking everyone. */
+ rcu_exp_wait_wake(rewp->rew_rsp, rewp->rew_s);
+}
+
+/*
+ * Given an rcu_state pointer and a smp_call_function() handler, kick
+ * off the specified flavor of expedited grace period.
+ */
+static void _synchronize_rcu_expedited(struct rcu_state *rsp,
+ smp_call_func_t func)
+{
+ struct rcu_data *rdp;
+ struct rcu_exp_work rew;
+ struct rcu_node *rnp;
+ unsigned long s;
+
+ /* If expedited grace periods are prohibited, fall back to normal. */
+ if (rcu_gp_is_normal()) {
+ wait_rcu_gp(rsp->call);
+ return;
+ }
+
+ /* Take a snapshot of the sequence number. */
+ s = rcu_exp_gp_seq_snap(rsp);
+ if (exp_funnel_lock(rsp, s))
+ return; /* Someone else did our work for us. */
+
+ /* Marshall arguments and schedule the expedited grace period. */
+ rew.rew_func = func;
+ rew.rew_rsp = rsp;
+ rew.rew_s = s;
+ INIT_WORK_ONSTACK(&rew.rew_work, wait_rcu_exp_gp);
+ schedule_work(&rew.rew_work);
+
+ /* Wait for expedited grace period to complete. */
+ rdp = per_cpu_ptr(rsp->rda, raw_smp_processor_id());
+ rnp = rcu_get_root(rsp);
+ wait_event(rnp->exp_wq[(s >> 1) & 0x3],
+ sync_exp_work_done(rsp,
+ &rdp->exp_workdone0, s));
+
+ /* Let the next expedited grace period start. */
+ mutex_unlock(&rsp->exp_mutex);
+}
+
/**
* synchronize_sched_expedited - Brute-force RCU-sched grace period
*
@@ -534,29 +595,13 @@
*/
void synchronize_sched_expedited(void)
{
- unsigned long s;
struct rcu_state *rsp = &rcu_sched_state;
/* If only one CPU, this is automatically a grace period. */
if (rcu_blocking_is_gp())
return;
- /* If expedited grace periods are prohibited, fall back to normal. */
- if (rcu_gp_is_normal()) {
- wait_rcu_gp(call_rcu_sched);
- return;
- }
-
- /* Take a snapshot of the sequence number. */
- s = rcu_exp_gp_seq_snap(rsp);
- if (exp_funnel_lock(rsp, s))
- return; /* Someone else did our work for us. */
-
- /* Initialize the rcu_node tree in preparation for the wait. */
- sync_rcu_exp_select_cpus(rsp, sync_sched_exp_handler);
-
- /* Wait and clean up, including waking everyone. */
- rcu_exp_wait_wake(rsp, s);
+ _synchronize_rcu_expedited(rsp, sync_sched_exp_handler);
}
EXPORT_SYMBOL_GPL(synchronize_sched_expedited);
@@ -620,23 +665,8 @@
void synchronize_rcu_expedited(void)
{
struct rcu_state *rsp = rcu_state_p;
- unsigned long s;
- /* If expedited grace periods are prohibited, fall back to normal. */
- if (rcu_gp_is_normal()) {
- wait_rcu_gp(call_rcu);
- return;
- }
-
- s = rcu_exp_gp_seq_snap(rsp);
- if (exp_funnel_lock(rsp, s))
- return; /* Someone else did our work for us. */
-
- /* Initialize the rcu_node tree in preparation for the wait. */
- sync_rcu_exp_select_cpus(rsp, sync_rcu_exp_handler);
-
- /* Wait for ->blkd_tasks lists to drain, then wake everyone up. */
- rcu_exp_wait_wake(rsp, s);
+ _synchronize_rcu_expedited(rsp, sync_rcu_exp_handler);
}
EXPORT_SYMBOL_GPL(synchronize_rcu_expedited);
diff --git a/kernel/rcu/tree_plugin.h b/kernel/rcu/tree_plugin.h
index 0082fce..85c5a88 100644
--- a/kernel/rcu/tree_plugin.h
+++ b/kernel/rcu/tree_plugin.h
@@ -2173,6 +2173,7 @@
cl++;
c++;
local_bh_enable();
+ cond_resched_rcu_qs();
list = next;
}
trace_rcu_batch_end(rdp->rsp->name, c, !!list, 0, 0, 1);
diff --git a/kernel/rcu/tree_trace.c b/kernel/rcu/tree_trace.c
index 86782f9a..b1f2897 100644
--- a/kernel/rcu/tree_trace.c
+++ b/kernel/rcu/tree_trace.c
@@ -185,16 +185,17 @@
int cpu;
struct rcu_state *rsp = (struct rcu_state *)m->private;
struct rcu_data *rdp;
- unsigned long s1 = 0, s2 = 0, s3 = 0;
+ unsigned long s0 = 0, s1 = 0, s2 = 0, s3 = 0;
for_each_possible_cpu(cpu) {
rdp = per_cpu_ptr(rsp->rda, cpu);
+ s0 += atomic_long_read(&rdp->exp_workdone0);
s1 += atomic_long_read(&rdp->exp_workdone1);
s2 += atomic_long_read(&rdp->exp_workdone2);
s3 += atomic_long_read(&rdp->exp_workdone3);
}
- seq_printf(m, "s=%lu wd1=%lu wd2=%lu wd3=%lu n=%lu enq=%d sc=%lu\n",
- rsp->expedited_sequence, s1, s2, s3,
+ seq_printf(m, "s=%lu wd0=%lu wd1=%lu wd2=%lu wd3=%lu n=%lu enq=%d sc=%lu\n",
+ rsp->expedited_sequence, s0, s1, s2, s3,
atomic_long_read(&rsp->expedited_normal),
atomic_read(&rsp->expedited_need_qs),
rsp->expedited_sequence / 2);
diff --git a/kernel/rcu/update.c b/kernel/rcu/update.c
index f0d8322..f19271d 100644
--- a/kernel/rcu/update.c
+++ b/kernel/rcu/update.c
@@ -46,7 +46,7 @@
#include <linux/export.h>
#include <linux/hardirq.h>
#include <linux/delay.h>
-#include <linux/module.h>
+#include <linux/moduleparam.h>
#include <linux/kthread.h>
#include <linux/tick.h>
@@ -54,7 +54,6 @@
#include "rcu.h"
-MODULE_ALIAS("rcupdate");
#ifdef MODULE_PARAM_PREFIX
#undef MODULE_PARAM_PREFIX
#endif
diff --git a/kernel/sched/core.c b/kernel/sched/core.c
index 44817c6..0a6a13c2 100644
--- a/kernel/sched/core.c
+++ b/kernel/sched/core.c
@@ -581,6 +581,8 @@
* If needed we can still optimize that later with an
* empty IRQ.
*/
+ if (cpu_is_offline(cpu))
+ return true; /* Don't try to wake offline CPUs. */
if (tick_nohz_full_cpu(cpu)) {
if (cpu != smp_processor_id() ||
tick_nohz_tick_stopped())
@@ -591,6 +593,11 @@
return false;
}
+/*
+ * Wake up the specified CPU. If the CPU is going offline, it is the
+ * caller's responsibility to deal with the lost wakeup, for example,
+ * by hooking into the CPU_DEAD notifier like timers and hrtimers do.
+ */
void wake_up_nohz_cpu(int cpu)
{
if (!wake_up_full_nohz_cpu(cpu))
diff --git a/kernel/sched/cpufreq.c b/kernel/sched/cpufreq.c
index 1141954..dbc5144 100644
--- a/kernel/sched/cpufreq.c
+++ b/kernel/sched/cpufreq.c
@@ -33,7 +33,7 @@
*/
void cpufreq_add_update_util_hook(int cpu, struct update_util_data *data,
void (*func)(struct update_util_data *data, u64 time,
- unsigned long util, unsigned long max))
+ unsigned int flags))
{
if (WARN_ON(!data || !func))
return;
diff --git a/kernel/sched/cpufreq_schedutil.c b/kernel/sched/cpufreq_schedutil.c
index a84641b..69e0689 100644
--- a/kernel/sched/cpufreq_schedutil.c
+++ b/kernel/sched/cpufreq_schedutil.c
@@ -12,7 +12,6 @@
#define pr_fmt(fmt) KBUILD_MODNAME ": " fmt
#include <linux/cpufreq.h>
-#include <linux/module.h>
#include <linux/slab.h>
#include <trace/events/power.h>
@@ -48,11 +47,14 @@
struct sugov_policy *sg_policy;
unsigned int cached_raw_freq;
+ unsigned long iowait_boost;
+ unsigned long iowait_boost_max;
+ u64 last_update;
/* The fields below are only needed when sharing a policy. */
unsigned long util;
unsigned long max;
- u64 last_update;
+ unsigned int flags;
};
static DEFINE_PER_CPU(struct sugov_cpu, sugov_cpu);
@@ -144,24 +146,75 @@
return cpufreq_driver_resolve_freq(policy, freq);
}
+static void sugov_get_util(unsigned long *util, unsigned long *max)
+{
+ struct rq *rq = this_rq();
+ unsigned long cfs_max;
+
+ cfs_max = arch_scale_cpu_capacity(NULL, smp_processor_id());
+
+ *util = min(rq->cfs.avg.util_avg, cfs_max);
+ *max = cfs_max;
+}
+
+static void sugov_set_iowait_boost(struct sugov_cpu *sg_cpu, u64 time,
+ unsigned int flags)
+{
+ if (flags & SCHED_CPUFREQ_IOWAIT) {
+ sg_cpu->iowait_boost = sg_cpu->iowait_boost_max;
+ } else if (sg_cpu->iowait_boost) {
+ s64 delta_ns = time - sg_cpu->last_update;
+
+ /* Clear iowait_boost if the CPU apprears to have been idle. */
+ if (delta_ns > TICK_NSEC)
+ sg_cpu->iowait_boost = 0;
+ }
+}
+
+static void sugov_iowait_boost(struct sugov_cpu *sg_cpu, unsigned long *util,
+ unsigned long *max)
+{
+ unsigned long boost_util = sg_cpu->iowait_boost;
+ unsigned long boost_max = sg_cpu->iowait_boost_max;
+
+ if (!boost_util)
+ return;
+
+ if (*util * boost_max < *max * boost_util) {
+ *util = boost_util;
+ *max = boost_max;
+ }
+ sg_cpu->iowait_boost >>= 1;
+}
+
static void sugov_update_single(struct update_util_data *hook, u64 time,
- unsigned long util, unsigned long max)
+ unsigned int flags)
{
struct sugov_cpu *sg_cpu = container_of(hook, struct sugov_cpu, update_util);
struct sugov_policy *sg_policy = sg_cpu->sg_policy;
struct cpufreq_policy *policy = sg_policy->policy;
+ unsigned long util, max;
unsigned int next_f;
+ sugov_set_iowait_boost(sg_cpu, time, flags);
+ sg_cpu->last_update = time;
+
if (!sugov_should_update_freq(sg_policy, time))
return;
- next_f = util == ULONG_MAX ? policy->cpuinfo.max_freq :
- get_next_freq(sg_cpu, util, max);
+ if (flags & SCHED_CPUFREQ_RT_DL) {
+ next_f = policy->cpuinfo.max_freq;
+ } else {
+ sugov_get_util(&util, &max);
+ sugov_iowait_boost(sg_cpu, &util, &max);
+ next_f = get_next_freq(sg_cpu, util, max);
+ }
sugov_update_commit(sg_policy, time, next_f);
}
static unsigned int sugov_next_freq_shared(struct sugov_cpu *sg_cpu,
- unsigned long util, unsigned long max)
+ unsigned long util, unsigned long max,
+ unsigned int flags)
{
struct sugov_policy *sg_policy = sg_cpu->sg_policy;
struct cpufreq_policy *policy = sg_policy->policy;
@@ -169,9 +222,11 @@
u64 last_freq_update_time = sg_policy->last_freq_update_time;
unsigned int j;
- if (util == ULONG_MAX)
+ if (flags & SCHED_CPUFREQ_RT_DL)
return max_f;
+ sugov_iowait_boost(sg_cpu, &util, &max);
+
for_each_cpu(j, policy->cpus) {
struct sugov_cpu *j_sg_cpu;
unsigned long j_util, j_max;
@@ -186,41 +241,50 @@
* frequency update and the time elapsed between the last update
* of the CPU utilization and the last frequency update is long
* enough, don't take the CPU into account as it probably is
- * idle now.
+ * idle now (and clear iowait_boost for it).
*/
delta_ns = last_freq_update_time - j_sg_cpu->last_update;
- if (delta_ns > TICK_NSEC)
+ if (delta_ns > TICK_NSEC) {
+ j_sg_cpu->iowait_boost = 0;
continue;
-
- j_util = j_sg_cpu->util;
- if (j_util == ULONG_MAX)
+ }
+ if (j_sg_cpu->flags & SCHED_CPUFREQ_RT_DL)
return max_f;
+ j_util = j_sg_cpu->util;
j_max = j_sg_cpu->max;
if (j_util * max > j_max * util) {
util = j_util;
max = j_max;
}
+
+ sugov_iowait_boost(j_sg_cpu, &util, &max);
}
return get_next_freq(sg_cpu, util, max);
}
static void sugov_update_shared(struct update_util_data *hook, u64 time,
- unsigned long util, unsigned long max)
+ unsigned int flags)
{
struct sugov_cpu *sg_cpu = container_of(hook, struct sugov_cpu, update_util);
struct sugov_policy *sg_policy = sg_cpu->sg_policy;
+ unsigned long util, max;
unsigned int next_f;
+ sugov_get_util(&util, &max);
+
raw_spin_lock(&sg_policy->update_lock);
sg_cpu->util = util;
sg_cpu->max = max;
+ sg_cpu->flags = flags;
+
+ sugov_set_iowait_boost(sg_cpu, time, flags);
sg_cpu->last_update = time;
if (sugov_should_update_freq(sg_policy, time)) {
- next_f = sugov_next_freq_shared(sg_cpu, util, max);
+ next_f = sugov_next_freq_shared(sg_cpu, util, max, flags);
sugov_update_commit(sg_policy, time, next_f);
}
@@ -444,10 +508,13 @@
sg_cpu->sg_policy = sg_policy;
if (policy_is_shared(policy)) {
- sg_cpu->util = ULONG_MAX;
+ sg_cpu->util = 0;
sg_cpu->max = 0;
+ sg_cpu->flags = SCHED_CPUFREQ_RT;
sg_cpu->last_update = 0;
sg_cpu->cached_raw_freq = 0;
+ sg_cpu->iowait_boost = 0;
+ sg_cpu->iowait_boost_max = policy->cpuinfo.max_freq;
cpufreq_add_update_util_hook(cpu, &sg_cpu->update_util,
sugov_update_shared);
} else {
@@ -495,28 +562,15 @@
.limits = sugov_limits,
};
-static int __init sugov_module_init(void)
-{
- return cpufreq_register_governor(&schedutil_gov);
-}
-
-static void __exit sugov_module_exit(void)
-{
- cpufreq_unregister_governor(&schedutil_gov);
-}
-
-MODULE_AUTHOR("Rafael J. Wysocki <rafael.j.wysocki@intel.com>");
-MODULE_DESCRIPTION("Utilization-based CPU frequency selection");
-MODULE_LICENSE("GPL");
-
#ifdef CONFIG_CPU_FREQ_DEFAULT_GOV_SCHEDUTIL
struct cpufreq_governor *cpufreq_default_governor(void)
{
return &schedutil_gov;
}
-
-fs_initcall(sugov_module_init);
-#else
-module_init(sugov_module_init);
#endif
-module_exit(sugov_module_exit);
+
+static int __init sugov_register(void)
+{
+ return cpufreq_register_governor(&schedutil_gov);
+}
+fs_initcall(sugov_register);
diff --git a/kernel/sched/deadline.c b/kernel/sched/deadline.c
index 1ce8867..9747796 100644
--- a/kernel/sched/deadline.c
+++ b/kernel/sched/deadline.c
@@ -735,9 +735,8 @@
return;
}
- /* kick cpufreq (see the comment in linux/cpufreq.h). */
- if (cpu_of(rq) == smp_processor_id())
- cpufreq_trigger_update(rq_clock(rq));
+ /* kick cpufreq (see the comment in kernel/sched/sched.h). */
+ cpufreq_update_this_cpu(rq, SCHED_CPUFREQ_DL);
schedstat_set(curr->se.statistics.exec_max,
max(curr->se.statistics.exec_max, delta_exec));
diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c
index 039de34..a5cd07b 100644
--- a/kernel/sched/fair.c
+++ b/kernel/sched/fair.c
@@ -2875,12 +2875,7 @@
static inline void cfs_rq_util_change(struct cfs_rq *cfs_rq)
{
- struct rq *rq = rq_of(cfs_rq);
- int cpu = cpu_of(rq);
-
- if (cpu == smp_processor_id() && &rq->cfs == cfs_rq) {
- unsigned long max = rq->cpu_capacity_orig;
-
+ if (&this_rq()->cfs == cfs_rq) {
/*
* There are a few boundary cases this might miss but it should
* get called often enough that that should (hopefully) not be
@@ -2897,8 +2892,7 @@
*
* See cpu_util().
*/
- cpufreq_update_util(rq_clock(rq),
- min(cfs_rq->avg.util_avg, max), max);
+ cpufreq_update_util(rq_of(cfs_rq), 0);
}
}
@@ -3159,10 +3153,7 @@
static inline void update_load_avg(struct sched_entity *se, int not_used)
{
- struct cfs_rq *cfs_rq = cfs_rq_of(se);
- struct rq *rq = rq_of(cfs_rq);
-
- cpufreq_trigger_update(rq_clock(rq));
+ cpufreq_update_util(rq_of(cfs_rq_of(se)), 0);
}
static inline void
@@ -4509,6 +4500,14 @@
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
+ /*
+ * If in_iowait is set, the code below may not trigger any cpufreq
+ * utilization updates, so do it here explicitly with the IOWAIT flag
+ * passed.
+ */
+ if (p->in_iowait)
+ cpufreq_update_this_cpu(rq, SCHED_CPUFREQ_IOWAIT);
+
for_each_sched_entity(se) {
if (se->on_rq)
break;
diff --git a/kernel/sched/rt.c b/kernel/sched/rt.c
index d5690b7..2516b8d 100644
--- a/kernel/sched/rt.c
+++ b/kernel/sched/rt.c
@@ -957,9 +957,8 @@
if (unlikely((s64)delta_exec <= 0))
return;
- /* Kick cpufreq (see the comment in linux/cpufreq.h). */
- if (cpu_of(rq) == smp_processor_id())
- cpufreq_trigger_update(rq_clock(rq));
+ /* Kick cpufreq (see the comment in kernel/sched/sched.h). */
+ cpufreq_update_this_cpu(rq, SCHED_CPUFREQ_RT);
schedstat_set(curr->se.statistics.exec_max,
max(curr->se.statistics.exec_max, delta_exec));
diff --git a/kernel/sched/sched.h b/kernel/sched/sched.h
index c64fc51..b7fc1ce 100644
--- a/kernel/sched/sched.h
+++ b/kernel/sched/sched.h
@@ -1763,27 +1763,13 @@
/**
* cpufreq_update_util - Take a note about CPU utilization changes.
- * @time: Current time.
- * @util: Current utilization.
- * @max: Utilization ceiling.
+ * @rq: Runqueue to carry out the update for.
+ * @flags: Update reason flags.
*
- * This function is called by the scheduler on every invocation of
- * update_load_avg() on the CPU whose utilization is being updated.
+ * This function is called by the scheduler on the CPU whose utilization is
+ * being updated.
*
* It can only be called from RCU-sched read-side critical sections.
- */
-static inline void cpufreq_update_util(u64 time, unsigned long util, unsigned long max)
-{
- struct update_util_data *data;
-
- data = rcu_dereference_sched(*this_cpu_ptr(&cpufreq_update_util_data));
- if (data)
- data->func(data, time, util, max);
-}
-
-/**
- * cpufreq_trigger_update - Trigger CPU performance state evaluation if needed.
- * @time: Current time.
*
* The way cpufreq is currently arranged requires it to evaluate the CPU
* performance state (frequency/voltage) on a regular basis to prevent it from
@@ -1797,13 +1783,23 @@
* but that really is a band-aid. Going forward it should be replaced with
* solutions targeted more specifically at RT and DL tasks.
*/
-static inline void cpufreq_trigger_update(u64 time)
+static inline void cpufreq_update_util(struct rq *rq, unsigned int flags)
{
- cpufreq_update_util(time, ULONG_MAX, 0);
+ struct update_util_data *data;
+
+ data = rcu_dereference_sched(*this_cpu_ptr(&cpufreq_update_util_data));
+ if (data)
+ data->func(data, rq_clock(rq), flags);
+}
+
+static inline void cpufreq_update_this_cpu(struct rq *rq, unsigned int flags)
+{
+ if (cpu_of(rq) == smp_processor_id())
+ cpufreq_update_util(rq, flags);
}
#else
-static inline void cpufreq_update_util(u64 time, unsigned long util, unsigned long max) {}
-static inline void cpufreq_trigger_update(u64 time) {}
+static inline void cpufreq_update_util(struct rq *rq, unsigned int flags) {}
+static inline void cpufreq_update_this_cpu(struct rq *rq, unsigned int flags) {}
#endif /* CONFIG_CPU_FREQ */
#ifdef arch_scale_freq_capacity
diff --git a/kernel/smp.c b/kernel/smp.c
index 3aa642d..bba3b20 100644
--- a/kernel/smp.c
+++ b/kernel/smp.c
@@ -14,6 +14,7 @@
#include <linux/smp.h>
#include <linux/cpu.h>
#include <linux/sched.h>
+#include <linux/hypervisor.h>
#include "smpboot.h"
@@ -724,3 +725,54 @@
preempt_enable();
}
EXPORT_SYMBOL_GPL(wake_up_all_idle_cpus);
+
+/**
+ * smp_call_on_cpu - Call a function on a specific cpu
+ *
+ * Used to call a function on a specific cpu and wait for it to return.
+ * Optionally make sure the call is done on a specified physical cpu via vcpu
+ * pinning in order to support virtualized environments.
+ */
+struct smp_call_on_cpu_struct {
+ struct work_struct work;
+ struct completion done;
+ int (*func)(void *);
+ void *data;
+ int ret;
+ int cpu;
+};
+
+static void smp_call_on_cpu_callback(struct work_struct *work)
+{
+ struct smp_call_on_cpu_struct *sscs;
+
+ sscs = container_of(work, struct smp_call_on_cpu_struct, work);
+ if (sscs->cpu >= 0)
+ hypervisor_pin_vcpu(sscs->cpu);
+ sscs->ret = sscs->func(sscs->data);
+ if (sscs->cpu >= 0)
+ hypervisor_pin_vcpu(-1);
+
+ complete(&sscs->done);
+}
+
+int smp_call_on_cpu(unsigned int cpu, int (*func)(void *), void *par, bool phys)
+{
+ struct smp_call_on_cpu_struct sscs = {
+ .done = COMPLETION_INITIALIZER_ONSTACK(sscs.done),
+ .func = func,
+ .data = par,
+ .cpu = phys ? cpu : -1,
+ };
+
+ INIT_WORK_ONSTACK(&sscs.work, smp_call_on_cpu_callback);
+
+ if (cpu >= nr_cpu_ids || !cpu_online(cpu))
+ return -ENXIO;
+
+ queue_work_on(cpu, system_wq, &sscs.work);
+ wait_for_completion(&sscs.done);
+
+ return sscs.ret;
+}
+EXPORT_SYMBOL_GPL(smp_call_on_cpu);
diff --git a/kernel/stop_machine.c b/kernel/stop_machine.c
index 4a1ca5f..ae6f41f 100644
--- a/kernel/stop_machine.c
+++ b/kernel/stop_machine.c
@@ -20,7 +20,6 @@
#include <linux/kallsyms.h>
#include <linux/smpboot.h>
#include <linux/atomic.h>
-#include <linux/lglock.h>
#include <linux/nmi.h>
/*
@@ -47,13 +46,9 @@
static DEFINE_PER_CPU(struct cpu_stopper, cpu_stopper);
static bool stop_machine_initialized = false;
-/*
- * Avoids a race between stop_two_cpus and global stop_cpus, where
- * the stoppers could get queued up in reverse order, leading to
- * system deadlock. Using an lglock means stop_two_cpus remains
- * relatively cheap.
- */
-DEFINE_STATIC_LGLOCK(stop_cpus_lock);
+/* static data for stop_cpus */
+static DEFINE_MUTEX(stop_cpus_mutex);
+static bool stop_cpus_in_progress;
static void cpu_stop_init_done(struct cpu_stop_done *done, unsigned int nr_todo)
{
@@ -230,14 +225,26 @@
struct cpu_stopper *stopper1 = per_cpu_ptr(&cpu_stopper, cpu1);
struct cpu_stopper *stopper2 = per_cpu_ptr(&cpu_stopper, cpu2);
int err;
-
- lg_double_lock(&stop_cpus_lock, cpu1, cpu2);
+retry:
spin_lock_irq(&stopper1->lock);
spin_lock_nested(&stopper2->lock, SINGLE_DEPTH_NESTING);
err = -ENOENT;
if (!stopper1->enabled || !stopper2->enabled)
goto unlock;
+ /*
+ * Ensure that if we race with __stop_cpus() the stoppers won't get
+ * queued up in reverse order leading to system deadlock.
+ *
+ * We can't miss stop_cpus_in_progress if queue_stop_cpus_work() has
+ * queued a work on cpu1 but not on cpu2, we hold both locks.
+ *
+ * It can be falsely true but it is safe to spin until it is cleared,
+ * queue_stop_cpus_work() does everything under preempt_disable().
+ */
+ err = -EDEADLK;
+ if (unlikely(stop_cpus_in_progress))
+ goto unlock;
err = 0;
__cpu_stop_queue_work(stopper1, work1);
@@ -245,8 +252,12 @@
unlock:
spin_unlock(&stopper2->lock);
spin_unlock_irq(&stopper1->lock);
- lg_double_unlock(&stop_cpus_lock, cpu1, cpu2);
+ if (unlikely(err == -EDEADLK)) {
+ while (stop_cpus_in_progress)
+ cpu_relax();
+ goto retry;
+ }
return err;
}
/**
@@ -316,9 +327,6 @@
return cpu_stop_queue_work(cpu, work_buf);
}
-/* static data for stop_cpus */
-static DEFINE_MUTEX(stop_cpus_mutex);
-
static bool queue_stop_cpus_work(const struct cpumask *cpumask,
cpu_stop_fn_t fn, void *arg,
struct cpu_stop_done *done)
@@ -332,7 +340,8 @@
* preempted by a stopper which might wait for other stoppers
* to enter @fn which can lead to deadlock.
*/
- lg_global_lock(&stop_cpus_lock);
+ preempt_disable();
+ stop_cpus_in_progress = true;
for_each_cpu(cpu, cpumask) {
work = &per_cpu(cpu_stopper.stop_work, cpu);
work->fn = fn;
@@ -341,7 +350,8 @@
if (cpu_stop_queue_work(cpu, work))
queued = true;
}
- lg_global_unlock(&stop_cpus_lock);
+ stop_cpus_in_progress = false;
+ preempt_enable();
return queued;
}
diff --git a/kernel/torture.c b/kernel/torture.c
index 75961b3..0d887eb 100644
--- a/kernel/torture.c
+++ b/kernel/torture.c
@@ -43,6 +43,7 @@
#include <linux/stat.h>
#include <linux/slab.h>
#include <linux/trace_clock.h>
+#include <linux/ktime.h>
#include <asm/byteorder.h>
#include <linux/torture.h>
@@ -446,9 +447,8 @@
* Variables for auto-shutdown. This allows "lights out" torture runs
* to be fully scripted.
*/
-static int shutdown_secs; /* desired test duration in seconds. */
static struct task_struct *shutdown_task;
-static unsigned long shutdown_time; /* jiffies to system shutdown. */
+static ktime_t shutdown_time; /* time to system shutdown. */
static void (*torture_shutdown_hook)(void);
/*
@@ -471,20 +471,20 @@
*/
static int torture_shutdown(void *arg)
{
- long delta;
- unsigned long jiffies_snap;
+ ktime_t ktime_snap;
VERBOSE_TOROUT_STRING("torture_shutdown task started");
- jiffies_snap = jiffies;
- while (ULONG_CMP_LT(jiffies_snap, shutdown_time) &&
+ ktime_snap = ktime_get();
+ while (ktime_before(ktime_snap, shutdown_time) &&
!torture_must_stop()) {
- delta = shutdown_time - jiffies_snap;
if (verbose)
pr_alert("%s" TORTURE_FLAG
- "torture_shutdown task: %lu jiffies remaining\n",
- torture_type, delta);
- schedule_timeout_interruptible(delta);
- jiffies_snap = jiffies;
+ "torture_shutdown task: %llu ms remaining\n",
+ torture_type,
+ ktime_ms_delta(shutdown_time, ktime_snap));
+ set_current_state(TASK_INTERRUPTIBLE);
+ schedule_hrtimeout(&shutdown_time, HRTIMER_MODE_ABS);
+ ktime_snap = ktime_get();
}
if (torture_must_stop()) {
torture_kthread_stopping("torture_shutdown");
@@ -511,10 +511,9 @@
{
int ret = 0;
- shutdown_secs = ssecs;
torture_shutdown_hook = cleanup;
- if (shutdown_secs > 0) {
- shutdown_time = jiffies + shutdown_secs * HZ;
+ if (ssecs > 0) {
+ shutdown_time = ktime_add(ktime_get(), ktime_set(ssecs, 0));
ret = torture_create_kthread(torture_shutdown, NULL,
shutdown_task);
}
diff --git a/kernel/trace/trace.c b/kernel/trace/trace.c
index 1e2ce3b..37824d9 100644
--- a/kernel/trace/trace.c
+++ b/kernel/trace/trace.c
@@ -5148,19 +5148,20 @@
struct trace_iterator *iter = filp->private_data;
ssize_t sret;
- /* return any leftover data */
- sret = trace_seq_to_user(&iter->seq, ubuf, cnt);
- if (sret != -EBUSY)
- return sret;
-
- trace_seq_init(&iter->seq);
-
/*
* Avoid more than one consumer on a single file descriptor
* This is just a matter of traces coherency, the ring buffer itself
* is protected.
*/
mutex_lock(&iter->mutex);
+
+ /* return any leftover data */
+ sret = trace_seq_to_user(&iter->seq, ubuf, cnt);
+ if (sret != -EBUSY)
+ goto out;
+
+ trace_seq_init(&iter->seq);
+
if (iter->trace->read) {
sret = iter->trace->read(iter, filp, ubuf, cnt, ppos);
if (sret)
@@ -6187,9 +6188,6 @@
return -EBUSY;
#endif
- if (splice_grow_spd(pipe, &spd))
- return -ENOMEM;
-
if (*ppos & (PAGE_SIZE - 1))
return -EINVAL;
@@ -6199,6 +6197,9 @@
len &= PAGE_MASK;
}
+ if (splice_grow_spd(pipe, &spd))
+ return -ENOMEM;
+
again:
trace_access_lock(iter->cpu_file);
entries = ring_buffer_entries_cpu(iter->trace_buffer->buffer, iter->cpu_file);
@@ -6256,19 +6257,21 @@
/* did we read anything? */
if (!spd.nr_pages) {
if (ret)
- return ret;
+ goto out;
+ ret = -EAGAIN;
if ((file->f_flags & O_NONBLOCK) || (flags & SPLICE_F_NONBLOCK))
- return -EAGAIN;
+ goto out;
ret = wait_on_pipe(iter, true);
if (ret)
- return ret;
+ goto out;
goto again;
}
ret = splice_to_pipe(pipe, &spd);
+out:
splice_shrink_spd(&spd);
return ret;
diff --git a/kernel/up.c b/kernel/up.c
index 1760bf3..ee81ac9 100644
--- a/kernel/up.c
+++ b/kernel/up.c
@@ -6,6 +6,7 @@
#include <linux/kernel.h>
#include <linux/export.h>
#include <linux/smp.h>
+#include <linux/hypervisor.h>
int smp_call_function_single(int cpu, void (*func) (void *info), void *info,
int wait)
@@ -82,3 +83,20 @@
preempt_enable();
}
EXPORT_SYMBOL(on_each_cpu_cond);
+
+int smp_call_on_cpu(unsigned int cpu, int (*func)(void *), void *par, bool phys)
+{
+ int ret;
+
+ if (cpu != 0)
+ return -ENXIO;
+
+ if (phys)
+ hypervisor_pin_vcpu(0);
+ ret = func(par);
+ if (phys)
+ hypervisor_pin_vcpu(-1);
+
+ return ret;
+}
+EXPORT_SYMBOL_GPL(smp_call_on_cpu);
diff --git a/lib/Kconfig.debug b/lib/Kconfig.debug
index 2e2cca5..cab7405 100644
--- a/lib/Kconfig.debug
+++ b/lib/Kconfig.debug
@@ -821,7 +821,7 @@
help
Say Y here to enable the kernel to detect "hung tasks",
which are bugs that cause the task to be stuck in
- uninterruptible "D" state indefinitiley.
+ uninterruptible "D" state indefinitely.
When a hung task is detected, the kernel will print the
current stack trace (which you should report), but the
diff --git a/lib/radix-tree.c b/lib/radix-tree.c
index 1b7bf73..91f0727 100644
--- a/lib/radix-tree.c
+++ b/lib/radix-tree.c
@@ -105,10 +105,10 @@
#ifdef CONFIG_RADIX_TREE_MULTIORDER
if (radix_tree_is_internal_node(entry)) {
- unsigned long siboff = get_slot_offset(parent, entry);
- if (siboff < RADIX_TREE_MAP_SIZE) {
- offset = siboff;
- entry = rcu_dereference_raw(parent->slots[offset]);
+ if (is_sibling_entry(parent, entry)) {
+ void **sibentry = (void **) entry_to_node(entry);
+ offset = get_slot_offset(parent, sibentry);
+ entry = rcu_dereference_raw(*sibentry);
}
}
#endif
diff --git a/lib/ucs2_string.c b/lib/ucs2_string.c
index f0b323a..ae8d249 100644
--- a/lib/ucs2_string.c
+++ b/lib/ucs2_string.c
@@ -56,7 +56,7 @@
unsigned long i;
unsigned long j = 0;
- for (i = 0; i < ucs2_strlen(src); i++) {
+ for (i = 0; src[i]; i++) {
u16 c = src[i];
if (c >= 0x800)
diff --git a/mm/Kconfig.debug b/mm/Kconfig.debug
index 22f4cd9..afcc550 100644
--- a/mm/Kconfig.debug
+++ b/mm/Kconfig.debug
@@ -76,8 +76,6 @@
no longer necessary to write zeros when GFP_ZERO is used on
allocation.
- Enabling page poisoning with this option will disable hibernation
-
If unsure, say N
bool
diff --git a/mm/debug.c b/mm/debug.c
index 8865bfb..74c7cae 100644
--- a/mm/debug.c
+++ b/mm/debug.c
@@ -42,9 +42,11 @@
void __dump_page(struct page *page, const char *reason)
{
+ int mapcount = PageSlab(page) ? 0 : page_mapcount(page);
+
pr_emerg("page:%p count:%d mapcount:%d mapping:%p index:%#lx",
- page, page_ref_count(page), page_mapcount(page),
- page->mapping, page->index);
+ page, page_ref_count(page), mapcount,
+ page->mapping, page_to_pgoff(page));
if (PageCompound(page))
pr_cont(" compound_mapcount: %d", compound_mapcount(page));
pr_cont("\n");
diff --git a/mm/filemap.c b/mm/filemap.c
index 8a287df..2d0986a 100644
--- a/mm/filemap.c
+++ b/mm/filemap.c
@@ -110,6 +110,62 @@
* ->tasklist_lock (memory_failure, collect_procs_ao)
*/
+static int page_cache_tree_insert(struct address_space *mapping,
+ struct page *page, void **shadowp)
+{
+ struct radix_tree_node *node;
+ void **slot;
+ int error;
+
+ error = __radix_tree_create(&mapping->page_tree, page->index, 0,
+ &node, &slot);
+ if (error)
+ return error;
+ if (*slot) {
+ void *p;
+
+ p = radix_tree_deref_slot_protected(slot, &mapping->tree_lock);
+ if (!radix_tree_exceptional_entry(p))
+ return -EEXIST;
+
+ mapping->nrexceptional--;
+ if (!dax_mapping(mapping)) {
+ if (shadowp)
+ *shadowp = p;
+ if (node)
+ workingset_node_shadows_dec(node);
+ } else {
+ /* DAX can replace empty locked entry with a hole */
+ WARN_ON_ONCE(p !=
+ (void *)(RADIX_TREE_EXCEPTIONAL_ENTRY |
+ RADIX_DAX_ENTRY_LOCK));
+ /* DAX accounts exceptional entries as normal pages */
+ if (node)
+ workingset_node_pages_dec(node);
+ /* Wakeup waiters for exceptional entry lock */
+ dax_wake_mapping_entry_waiter(mapping, page->index,
+ false);
+ }
+ }
+ radix_tree_replace_slot(slot, page);
+ mapping->nrpages++;
+ if (node) {
+ workingset_node_pages_inc(node);
+ /*
+ * Don't track node that contains actual pages.
+ *
+ * Avoid acquiring the list_lru lock if already
+ * untracked. The list_empty() test is safe as
+ * node->private_list is protected by
+ * mapping->tree_lock.
+ */
+ if (!list_empty(&node->private_list))
+ list_lru_del(&workingset_shadow_nodes,
+ &node->private_list);
+ }
+ return 0;
+}
+
static void page_cache_tree_delete(struct address_space *mapping,
struct page *page, void *shadow)
{
@@ -561,7 +617,7 @@
spin_lock_irqsave(&mapping->tree_lock, flags);
__delete_from_page_cache(old, NULL);
- error = radix_tree_insert(&mapping->page_tree, offset, new);
+ error = page_cache_tree_insert(mapping, new, NULL);
BUG_ON(error);
mapping->nrpages++;
@@ -584,62 +640,6 @@
}
EXPORT_SYMBOL_GPL(replace_page_cache_page);
-static int page_cache_tree_insert(struct address_space *mapping,
- struct page *page, void **shadowp)
-{
- struct radix_tree_node *node;
- void **slot;
- int error;
-
- error = __radix_tree_create(&mapping->page_tree, page->index, 0,
- &node, &slot);
- if (error)
- return error;
- if (*slot) {
- void *p;
-
- p = radix_tree_deref_slot_protected(slot, &mapping->tree_lock);
- if (!radix_tree_exceptional_entry(p))
- return -EEXIST;
-
- mapping->nrexceptional--;
- if (!dax_mapping(mapping)) {
- if (shadowp)
- *shadowp = p;
- if (node)
- workingset_node_shadows_dec(node);
- } else {
- /* DAX can replace empty locked entry with a hole */
- WARN_ON_ONCE(p !=
- (void *)(RADIX_TREE_EXCEPTIONAL_ENTRY |
- RADIX_DAX_ENTRY_LOCK));
- /* DAX accounts exceptional entries as normal pages */
- if (node)
- workingset_node_pages_dec(node);
- /* Wakeup waiters for exceptional entry lock */
- dax_wake_mapping_entry_waiter(mapping, page->index,
- false);
- }
- }
- radix_tree_replace_slot(slot, page);
- mapping->nrpages++;
- if (node) {
- workingset_node_pages_inc(node);
- /*
- * Don't track node that contains actual pages.
- *
- * Avoid acquiring the list_lru lock if already
- * untracked. The list_empty() test is safe as
- * node->private_list is protected by
- * mapping->tree_lock.
- */
- if (!list_empty(&node->private_list))
- list_lru_del(&workingset_shadow_nodes,
- &node->private_list);
- }
- return 0;
-}
-
static int __add_to_page_cache_locked(struct page *page,
struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask,
diff --git a/mm/huge_memory.c b/mm/huge_memory.c
index a6abd76..53ae6d0 100644
--- a/mm/huge_memory.c
+++ b/mm/huge_memory.c
@@ -1138,9 +1138,6 @@
bool was_writable;
int flags = 0;
- /* A PROT_NONE fault should not end up here */
- BUG_ON(!(vma->vm_flags & (VM_READ | VM_EXEC | VM_WRITE)));
-
fe->ptl = pmd_lock(vma->vm_mm, fe->pmd);
if (unlikely(!pmd_same(pmd, *fe->pmd)))
goto out_unlock;
diff --git a/mm/khugepaged.c b/mm/khugepaged.c
index 79c52d0..728d779 100644
--- a/mm/khugepaged.c
+++ b/mm/khugepaged.c
@@ -838,7 +838,8 @@
* value (scan code).
*/
-static int hugepage_vma_revalidate(struct mm_struct *mm, unsigned long address)
+static int hugepage_vma_revalidate(struct mm_struct *mm, unsigned long address,
+ struct vm_area_struct **vmap)
{
struct vm_area_struct *vma;
unsigned long hstart, hend;
@@ -846,7 +847,7 @@
if (unlikely(khugepaged_test_exit(mm)))
return SCAN_ANY_PROCESS;
- vma = find_vma(mm, address);
+ *vmap = vma = find_vma(mm, address);
if (!vma)
return SCAN_VMA_NULL;
@@ -881,6 +882,11 @@
.pmd = pmd,
};
+ /* we only decide to swapin, if there is enough young ptes */
+ if (referenced < HPAGE_PMD_NR/2) {
+ trace_mm_collapse_huge_page_swapin(mm, swapped_in, referenced, 0);
+ return false;
+ }
fe.pte = pte_offset_map(pmd, address);
for (; fe.address < address + HPAGE_PMD_NR*PAGE_SIZE;
fe.pte++, fe.address += PAGE_SIZE) {
@@ -888,17 +894,12 @@
if (!is_swap_pte(pteval))
continue;
swapped_in++;
- /* we only decide to swapin, if there is enough young ptes */
- if (referenced < HPAGE_PMD_NR/2) {
- trace_mm_collapse_huge_page_swapin(mm, swapped_in, referenced, 0);
- return false;
- }
ret = do_swap_page(&fe, pteval);
/* do_swap_page returns VM_FAULT_RETRY with released mmap_sem */
if (ret & VM_FAULT_RETRY) {
down_read(&mm->mmap_sem);
- if (hugepage_vma_revalidate(mm, address)) {
+ if (hugepage_vma_revalidate(mm, address, &fe.vma)) {
/* vma is no longer available, don't continue to swapin */
trace_mm_collapse_huge_page_swapin(mm, swapped_in, referenced, 0);
return false;
@@ -923,7 +924,6 @@
static void collapse_huge_page(struct mm_struct *mm,
unsigned long address,
struct page **hpage,
- struct vm_area_struct *vma,
int node, int referenced)
{
pmd_t *pmd, _pmd;
@@ -933,6 +933,7 @@
spinlock_t *pmd_ptl, *pte_ptl;
int isolated = 0, result = 0;
struct mem_cgroup *memcg;
+ struct vm_area_struct *vma;
unsigned long mmun_start; /* For mmu_notifiers */
unsigned long mmun_end; /* For mmu_notifiers */
gfp_t gfp;
@@ -961,7 +962,7 @@
}
down_read(&mm->mmap_sem);
- result = hugepage_vma_revalidate(mm, address);
+ result = hugepage_vma_revalidate(mm, address, &vma);
if (result) {
mem_cgroup_cancel_charge(new_page, memcg, true);
up_read(&mm->mmap_sem);
@@ -994,7 +995,7 @@
* handled by the anon_vma lock + PG_lock.
*/
down_write(&mm->mmap_sem);
- result = hugepage_vma_revalidate(mm, address);
+ result = hugepage_vma_revalidate(mm, address, &vma);
if (result)
goto out;
/* check if the pmd is still valid */
@@ -1202,7 +1203,7 @@
if (ret) {
node = khugepaged_find_target_node();
/* collapse_huge_page will return with the mmap_sem released */
- collapse_huge_page(mm, address, hpage, vma, node, referenced);
+ collapse_huge_page(mm, address, hpage, node, referenced);
}
out:
trace_mm_khugepaged_scan_pmd(mm, page, writable, referenced,
diff --git a/mm/ksm.c b/mm/ksm.c
index 73d43ba..5048083 100644
--- a/mm/ksm.c
+++ b/mm/ksm.c
@@ -283,7 +283,8 @@
{
struct rmap_item *rmap_item;
- rmap_item = kmem_cache_zalloc(rmap_item_cache, GFP_KERNEL);
+ rmap_item = kmem_cache_zalloc(rmap_item_cache, GFP_KERNEL |
+ __GFP_NORETRY | __GFP_NOWARN);
if (rmap_item)
ksm_rmap_items++;
return rmap_item;
diff --git a/mm/memcontrol.c b/mm/memcontrol.c
index 9a6a51a..4be518d 100644
--- a/mm/memcontrol.c
+++ b/mm/memcontrol.c
@@ -1740,17 +1740,22 @@
static bool consume_stock(struct mem_cgroup *memcg, unsigned int nr_pages)
{
struct memcg_stock_pcp *stock;
+ unsigned long flags;
bool ret = false;
if (nr_pages > CHARGE_BATCH)
return ret;
- stock = &get_cpu_var(memcg_stock);
+ local_irq_save(flags);
+
+ stock = this_cpu_ptr(&memcg_stock);
if (memcg == stock->cached && stock->nr_pages >= nr_pages) {
stock->nr_pages -= nr_pages;
ret = true;
}
- put_cpu_var(memcg_stock);
+
+ local_irq_restore(flags);
+
return ret;
}
@@ -1771,15 +1776,18 @@
stock->cached = NULL;
}
-/*
- * This must be called under preempt disabled or must be called by
- * a thread which is pinned to local cpu.
- */
static void drain_local_stock(struct work_struct *dummy)
{
- struct memcg_stock_pcp *stock = this_cpu_ptr(&memcg_stock);
+ struct memcg_stock_pcp *stock;
+ unsigned long flags;
+
+ local_irq_save(flags);
+
+ stock = this_cpu_ptr(&memcg_stock);
drain_stock(stock);
clear_bit(FLUSHING_CACHED_CHARGE, &stock->flags);
+
+ local_irq_restore(flags);
}
/*
@@ -1788,14 +1796,19 @@
*/
static void refill_stock(struct mem_cgroup *memcg, unsigned int nr_pages)
{
- struct memcg_stock_pcp *stock = &get_cpu_var(memcg_stock);
+ struct memcg_stock_pcp *stock;
+ unsigned long flags;
+ local_irq_save(flags);
+
+ stock = this_cpu_ptr(&memcg_stock);
if (stock->cached != memcg) { /* reset if necessary */
drain_stock(stock);
stock->cached = memcg;
}
stock->nr_pages += nr_pages;
- put_cpu_var(memcg_stock);
+
+ local_irq_restore(flags);
}
/*
diff --git a/mm/memory.c b/mm/memory.c
index 83be99d..793fe0f 100644
--- a/mm/memory.c
+++ b/mm/memory.c
@@ -3351,9 +3351,6 @@
bool was_writable = pte_write(pte);
int flags = 0;
- /* A PROT_NONE fault should not end up here */
- BUG_ON(!(vma->vm_flags & (VM_READ | VM_EXEC | VM_WRITE)));
-
/*
* The "pte" at this point cannot be used safely without
* validation through pte_unmap_same(). It's of NUMA type but
@@ -3458,6 +3455,11 @@
return VM_FAULT_FALLBACK;
}
+static inline bool vma_is_accessible(struct vm_area_struct *vma)
+{
+ return vma->vm_flags & (VM_READ | VM_EXEC | VM_WRITE);
+}
+
/*
* These routines also need to handle stuff like marking pages dirty
* and/or accessed for architectures that don't do it in hardware (most
@@ -3524,7 +3526,7 @@
if (!pte_present(entry))
return do_swap_page(fe, entry);
- if (pte_protnone(entry))
+ if (pte_protnone(entry) && vma_is_accessible(fe->vma))
return do_numa_page(fe, entry);
fe->ptl = pte_lockptr(fe->vma->vm_mm, fe->pmd);
@@ -3590,7 +3592,7 @@
barrier();
if (pmd_trans_huge(orig_pmd) || pmd_devmap(orig_pmd)) {
- if (pmd_protnone(orig_pmd))
+ if (pmd_protnone(orig_pmd) && vma_is_accessible(vma))
return do_huge_pmd_numa_page(&fe, orig_pmd);
if ((fe.flags & FAULT_FLAG_WRITE) &&
diff --git a/mm/memory_hotplug.c b/mm/memory_hotplug.c
index 41266dc..9d29ba0 100644
--- a/mm/memory_hotplug.c
+++ b/mm/memory_hotplug.c
@@ -1555,8 +1555,8 @@
{
gfp_t gfp_mask = GFP_USER | __GFP_MOVABLE;
int nid = page_to_nid(page);
- nodemask_t nmask = node_online_map;
- struct page *new_page;
+ nodemask_t nmask = node_states[N_MEMORY];
+ struct page *new_page = NULL;
/*
* TODO: allocate a destination hugepage from a nearest neighbor node,
@@ -1568,11 +1568,13 @@
next_node_in(nid, nmask));
node_clear(nid, nmask);
+
if (PageHighMem(page)
|| (zone_idx(page_zone(page)) == ZONE_MOVABLE))
gfp_mask |= __GFP_HIGHMEM;
- new_page = __alloc_pages_nodemask(gfp_mask, 0,
+ if (!nodes_empty(nmask))
+ new_page = __alloc_pages_nodemask(gfp_mask, 0,
node_zonelist(nid, gfp_mask), &nmask);
if (!new_page)
new_page = __alloc_pages(gfp_mask, 0,
diff --git a/mm/mmap.c b/mm/mmap.c
index ca9d91b..69cad56 100644
--- a/mm/mmap.c
+++ b/mm/mmap.c
@@ -88,6 +88,11 @@
* w: (no) no w: (no) no w: (copy) copy w: (no) no
* x: (no) no x: (no) yes x: (no) yes x: (yes) yes
*
+ * On arm64, PROT_EXEC has the following behaviour for both MAP_SHARED and
+ * MAP_PRIVATE:
+ * r: (no) no
+ * w: (no) no
+ * x: (yes) yes
*/
pgprot_t protection_map[16] = {
__P000, __P001, __P010, __P011, __P100, __P101, __P110, __P111,
diff --git a/mm/page_io.c b/mm/page_io.c
index 16bd82fa..eafe5dd 100644
--- a/mm/page_io.c
+++ b/mm/page_io.c
@@ -264,6 +264,7 @@
int ret;
struct swap_info_struct *sis = page_swap_info(page);
+ BUG_ON(!PageSwapCache(page));
if (sis->flags & SWP_FILE) {
struct kiocb kiocb;
struct file *swap_file = sis->swap_file;
@@ -337,6 +338,7 @@
int ret = 0;
struct swap_info_struct *sis = page_swap_info(page);
+ BUG_ON(!PageSwapCache(page));
VM_BUG_ON_PAGE(!PageLocked(page), page);
VM_BUG_ON_PAGE(PageUptodate(page), page);
if (frontswap_load(page) == 0) {
@@ -386,6 +388,7 @@
if (sis->flags & SWP_FILE) {
struct address_space *mapping = sis->swap_file->f_mapping;
+ BUG_ON(!PageSwapCache(page));
return mapping->a_ops->set_page_dirty(page);
} else {
return __set_page_dirty_no_writeback(page);
diff --git a/mm/shmem.c b/mm/shmem.c
index fd8b2b5..971fc83 100644
--- a/mm/shmem.c
+++ b/mm/shmem.c
@@ -270,7 +270,7 @@
info->alloced -= pages;
shmem_recalc_inode(inode);
spin_unlock_irqrestore(&info->lock, flags);
-
+ shmem_unacct_blocks(info->flags, pages);
return false;
}
percpu_counter_add(&sbinfo->used_blocks, pages);
@@ -291,6 +291,7 @@
if (sbinfo->max_blocks)
percpu_counter_sub(&sbinfo->used_blocks, pages);
+ shmem_unacct_blocks(info->flags, pages);
}
/*
@@ -1980,7 +1981,7 @@
return addr;
sb = shm_mnt->mnt_sb;
}
- if (SHMEM_SB(sb)->huge != SHMEM_HUGE_NEVER)
+ if (SHMEM_SB(sb)->huge == SHMEM_HUGE_NEVER)
return addr;
}
diff --git a/mm/swapfile.c b/mm/swapfile.c
index 78cfa29..2657acc 100644
--- a/mm/swapfile.c
+++ b/mm/swapfile.c
@@ -2724,7 +2724,6 @@
struct swap_info_struct *page_swap_info(struct page *page)
{
swp_entry_t swap = { .val = page_private(page) };
- BUG_ON(!PageSwapCache(page));
return swap_info[swp_type(swap)];
}
diff --git a/mm/usercopy.c b/mm/usercopy.c
index 089328f..3c8da0a 100644
--- a/mm/usercopy.c
+++ b/mm/usercopy.c
@@ -207,8 +207,11 @@
* Some architectures (arm64) return true for virt_addr_valid() on
* vmalloced addresses. Work around this by checking for vmalloc
* first.
+ *
+ * We also need to check for module addresses explicitly since we
+ * may copy static data from modules to userspace
*/
- if (is_vmalloc_addr(ptr))
+ if (is_vmalloc_or_module_addr(ptr))
return NULL;
if (!virt_addr_valid(ptr))
diff --git a/mm/vmscan.c b/mm/vmscan.c
index b1e12a1..0fe8b71 100644
--- a/mm/vmscan.c
+++ b/mm/vmscan.c
@@ -2303,23 +2303,6 @@
}
}
-#ifdef CONFIG_ARCH_WANT_BATCHED_UNMAP_TLB_FLUSH
-static void init_tlb_ubc(void)
-{
- /*
- * This deliberately does not clear the cpumask as it's expensive
- * and unnecessary. If there happens to be data in there then the
- * first SWAP_CLUSTER_MAX pages will send an unnecessary IPI and
- * then will be cleared.
- */
- current->tlb_ubc.flush_required = false;
-}
-#else
-static inline void init_tlb_ubc(void)
-{
-}
-#endif /* CONFIG_ARCH_WANT_BATCHED_UNMAP_TLB_FLUSH */
-
/*
* This is a basic per-node page freer. Used by both kswapd and direct reclaim.
*/
@@ -2355,8 +2338,6 @@
scan_adjusted = (global_reclaim(sc) && !current_is_kswapd() &&
sc->priority == DEF_PRIORITY);
- init_tlb_ubc();
-
blk_start_plug(&plug);
while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] ||
nr[LRU_INACTIVE_FILE]) {
diff --git a/mm/workingset.c b/mm/workingset.c
index 69551cf..617475f 100644
--- a/mm/workingset.c
+++ b/mm/workingset.c
@@ -418,21 +418,19 @@
* no pages, so we expect to be able to remove them all and
* delete and free the empty node afterwards.
*/
-
- BUG_ON(!node->count);
- BUG_ON(node->count & RADIX_TREE_COUNT_MASK);
+ BUG_ON(!workingset_node_shadows(node));
+ BUG_ON(workingset_node_pages(node));
for (i = 0; i < RADIX_TREE_MAP_SIZE; i++) {
if (node->slots[i]) {
BUG_ON(!radix_tree_exceptional_entry(node->slots[i]));
node->slots[i] = NULL;
- BUG_ON(node->count < (1U << RADIX_TREE_COUNT_SHIFT));
- node->count -= 1U << RADIX_TREE_COUNT_SHIFT;
+ workingset_node_shadows_dec(node);
BUG_ON(!mapping->nrexceptional);
mapping->nrexceptional--;
}
}
- BUG_ON(node->count);
+ BUG_ON(workingset_node_shadows(node));
inc_node_state(page_pgdat(virt_to_page(node)), WORKINGSET_NODERECLAIM);
if (!__radix_tree_delete_node(&mapping->page_tree, node))
BUG();
diff --git a/net/batman-adv/bat_v_elp.c b/net/batman-adv/bat_v_elp.c
index 7d170010..ee08540 100644
--- a/net/batman-adv/bat_v_elp.c
+++ b/net/batman-adv/bat_v_elp.c
@@ -335,7 +335,7 @@
goto out;
skb_reserve(hard_iface->bat_v.elp_skb, ETH_HLEN + NET_IP_ALIGN);
- elp_buff = skb_push(hard_iface->bat_v.elp_skb, BATADV_ELP_HLEN);
+ elp_buff = skb_put(hard_iface->bat_v.elp_skb, BATADV_ELP_HLEN);
elp_packet = (struct batadv_elp_packet *)elp_buff;
memset(elp_packet, 0, BATADV_ELP_HLEN);
diff --git a/net/batman-adv/routing.c b/net/batman-adv/routing.c
index 7602c00..3d19947 100644
--- a/net/batman-adv/routing.c
+++ b/net/batman-adv/routing.c
@@ -470,6 +470,29 @@
}
/**
+ * batadv_last_bonding_get - Get last_bonding_candidate of orig_node
+ * @orig_node: originator node whose last bonding candidate should be retrieved
+ *
+ * Return: last bonding candidate of router or NULL if not found
+ *
+ * The object is returned with refcounter increased by 1.
+ */
+static struct batadv_orig_ifinfo *
+batadv_last_bonding_get(struct batadv_orig_node *orig_node)
+{
+ struct batadv_orig_ifinfo *last_bonding_candidate;
+
+ spin_lock_bh(&orig_node->neigh_list_lock);
+ last_bonding_candidate = orig_node->last_bonding_candidate;
+
+ if (last_bonding_candidate)
+ kref_get(&last_bonding_candidate->refcount);
+ spin_unlock_bh(&orig_node->neigh_list_lock);
+
+ return last_bonding_candidate;
+}
+
+/**
* batadv_last_bonding_replace - Replace last_bonding_candidate of orig_node
* @orig_node: originator node whose bonding candidates should be replaced
* @new_candidate: new bonding candidate or NULL
@@ -539,7 +562,7 @@
* router - obviously there are no other candidates.
*/
rcu_read_lock();
- last_candidate = orig_node->last_bonding_candidate;
+ last_candidate = batadv_last_bonding_get(orig_node);
if (last_candidate)
last_cand_router = rcu_dereference(last_candidate->router);
@@ -631,6 +654,9 @@
batadv_orig_ifinfo_put(next_candidate);
}
+ if (last_candidate)
+ batadv_orig_ifinfo_put(last_candidate);
+
return router;
}
diff --git a/net/core/sock.c b/net/core/sock.c
index 25dab8b..fd7b41e 100644
--- a/net/core/sock.c
+++ b/net/core/sock.c
@@ -1362,7 +1362,6 @@
if (!try_module_get(prot->owner))
goto out_free_sec;
sk_tx_queue_clear(sk);
- cgroup_sk_alloc(&sk->sk_cgrp_data);
}
return sk;
@@ -1422,6 +1421,7 @@
sock_net_set(sk, net);
atomic_set(&sk->sk_wmem_alloc, 1);
+ cgroup_sk_alloc(&sk->sk_cgrp_data);
sock_update_classid(&sk->sk_cgrp_data);
sock_update_netprioidx(&sk->sk_cgrp_data);
}
@@ -1566,6 +1566,9 @@
newsk->sk_priority = 0;
newsk->sk_incoming_cpu = raw_smp_processor_id();
atomic64_set(&newsk->sk_cookie, 0);
+
+ cgroup_sk_alloc(&newsk->sk_cgrp_data);
+
/*
* Before updating sk_refcnt, we must commit prior changes to memory
* (Documentation/RCU/rculist_nulls.txt for details)
diff --git a/net/ipv4/ip_input.c b/net/ipv4/ip_input.c
index 4b351af..d6feabb 100644
--- a/net/ipv4/ip_input.c
+++ b/net/ipv4/ip_input.c
@@ -312,6 +312,7 @@
{
const struct iphdr *iph = ip_hdr(skb);
struct rtable *rt;
+ struct net_device *dev = skb->dev;
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
@@ -341,7 +342,7 @@
*/
if (!skb_valid_dst(skb)) {
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
- iph->tos, skb->dev);
+ iph->tos, dev);
if (unlikely(err)) {
if (err == -EXDEV)
__NET_INC_STATS(net, LINUX_MIB_IPRPFILTER);
@@ -370,7 +371,7 @@
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INBCAST, skb->len);
} else if (skb->pkt_type == PACKET_BROADCAST ||
skb->pkt_type == PACKET_MULTICAST) {
- struct in_device *in_dev = __in_dev_get_rcu(skb->dev);
+ struct in_device *in_dev = __in_dev_get_rcu(dev);
/* RFC 1122 3.3.6:
*
diff --git a/net/ipv4/ip_vti.c b/net/ipv4/ip_vti.c
index cc701fa..5d7944f 100644
--- a/net/ipv4/ip_vti.c
+++ b/net/ipv4/ip_vti.c
@@ -88,6 +88,7 @@
struct net_device *dev;
struct pcpu_sw_netstats *tstats;
struct xfrm_state *x;
+ struct xfrm_mode *inner_mode;
struct ip_tunnel *tunnel = XFRM_TUNNEL_SKB_CB(skb)->tunnel.ip4;
u32 orig_mark = skb->mark;
int ret;
@@ -105,7 +106,19 @@
}
x = xfrm_input_state(skb);
- family = x->inner_mode->afinfo->family;
+
+ inner_mode = x->inner_mode;
+
+ if (x->sel.family == AF_UNSPEC) {
+ inner_mode = xfrm_ip2inner_mode(x, XFRM_MODE_SKB_CB(skb)->protocol);
+ if (inner_mode == NULL) {
+ XFRM_INC_STATS(dev_net(skb->dev),
+ LINUX_MIB_XFRMINSTATEMODEERROR);
+ return -EINVAL;
+ }
+ }
+
+ family = inner_mode->afinfo->family;
skb->mark = be32_to_cpu(tunnel->parms.i_key);
ret = xfrm_policy_check(NULL, XFRM_POLICY_IN, skb, family);
diff --git a/net/ipv4/ipmr.c b/net/ipv4/ipmr.c
index 2625332..5f006e1 100644
--- a/net/ipv4/ipmr.c
+++ b/net/ipv4/ipmr.c
@@ -2076,6 +2076,7 @@
struct rta_mfc_stats mfcs;
struct nlattr *mp_attr;
struct rtnexthop *nhp;
+ unsigned long lastuse;
int ct;
/* If cache is unresolved, don't try to parse IIF and OIF */
@@ -2105,12 +2106,14 @@
nla_nest_end(skb, mp_attr);
+ lastuse = READ_ONCE(c->mfc_un.res.lastuse);
+ lastuse = time_after_eq(jiffies, lastuse) ? jiffies - lastuse : 0;
+
mfcs.mfcs_packets = c->mfc_un.res.pkt;
mfcs.mfcs_bytes = c->mfc_un.res.bytes;
mfcs.mfcs_wrong_if = c->mfc_un.res.wrong_if;
if (nla_put_64bit(skb, RTA_MFC_STATS, sizeof(mfcs), &mfcs, RTA_PAD) ||
- nla_put_u64_64bit(skb, RTA_EXPIRES,
- jiffies_to_clock_t(c->mfc_un.res.lastuse),
+ nla_put_u64_64bit(skb, RTA_EXPIRES, jiffies_to_clock_t(lastuse),
RTA_PAD))
return -EMSGSIZE;
@@ -2120,7 +2123,7 @@
int ipmr_get_route(struct net *net, struct sk_buff *skb,
__be32 saddr, __be32 daddr,
- struct rtmsg *rtm, int nowait)
+ struct rtmsg *rtm, int nowait, u32 portid)
{
struct mfc_cache *cache;
struct mr_table *mrt;
@@ -2165,6 +2168,7 @@
return -ENOMEM;
}
+ NETLINK_CB(skb2).portid = portid;
skb_push(skb2, sizeof(struct iphdr));
skb_reset_network_header(skb2);
iph = ip_hdr(skb2);
diff --git a/net/ipv4/netfilter/nft_chain_route_ipv4.c b/net/ipv4/netfilter/nft_chain_route_ipv4.c
index 2375b0a..30493be 100644
--- a/net/ipv4/netfilter/nft_chain_route_ipv4.c
+++ b/net/ipv4/netfilter/nft_chain_route_ipv4.c
@@ -31,6 +31,7 @@
__be32 saddr, daddr;
u_int8_t tos;
const struct iphdr *iph;
+ int err;
/* root is playing with raw sockets. */
if (skb->len < sizeof(struct iphdr) ||
@@ -46,15 +47,17 @@
tos = iph->tos;
ret = nft_do_chain(&pkt, priv);
- if (ret != NF_DROP && ret != NF_QUEUE) {
+ if (ret != NF_DROP && ret != NF_STOLEN) {
iph = ip_hdr(skb);
if (iph->saddr != saddr ||
iph->daddr != daddr ||
skb->mark != mark ||
- iph->tos != tos)
- if (ip_route_me_harder(state->net, skb, RTN_UNSPEC))
- ret = NF_DROP;
+ iph->tos != tos) {
+ err = ip_route_me_harder(state->net, skb, RTN_UNSPEC);
+ if (err < 0)
+ ret = NF_DROP_ERR(err);
+ }
}
return ret;
}
diff --git a/net/ipv4/route.c b/net/ipv4/route.c
index a1f2830..62c3ed0 100644
--- a/net/ipv4/route.c
+++ b/net/ipv4/route.c
@@ -476,12 +476,18 @@
atomic_t *p_id = ip_idents + hash % IP_IDENTS_SZ;
u32 old = ACCESS_ONCE(*p_tstamp);
u32 now = (u32)jiffies;
- u32 delta = 0;
+ u32 new, delta = 0;
if (old != now && cmpxchg(p_tstamp, old, now) == old)
delta = prandom_u32_max(now - old);
- return atomic_add_return(segs + delta, p_id) - segs;
+ /* Do not use atomic_add_return() as it makes UBSAN unhappy */
+ do {
+ old = (u32)atomic_read(p_id);
+ new = old + delta + segs;
+ } while (atomic_cmpxchg(p_id, old, new) != old);
+
+ return new - segs;
}
EXPORT_SYMBOL(ip_idents_reserve);
@@ -2497,7 +2503,8 @@
IPV4_DEVCONF_ALL(net, MC_FORWARDING)) {
int err = ipmr_get_route(net, skb,
fl4->saddr, fl4->daddr,
- r, nowait);
+ r, nowait, portid);
+
if (err <= 0) {
if (!nowait) {
if (err == 0)
diff --git a/net/ipv4/tcp_input.c b/net/ipv4/tcp_input.c
index 3ebf45b..a756b87 100644
--- a/net/ipv4/tcp_input.c
+++ b/net/ipv4/tcp_input.c
@@ -2329,10 +2329,9 @@
}
#if IS_ENABLED(CONFIG_IPV6)
else if (sk->sk_family == AF_INET6) {
- struct ipv6_pinfo *np = inet6_sk(sk);
pr_debug("Undo %s %pI6/%u c%u l%u ss%u/%u p%u\n",
msg,
- &np->daddr, ntohs(inet->inet_dport),
+ &sk->sk_v6_daddr, ntohs(inet->inet_dport),
tp->snd_cwnd, tcp_left_out(tp),
tp->snd_ssthresh, tp->prior_ssthresh,
tp->packets_out);
@@ -5885,7 +5884,7 @@
* so release it.
*/
if (req) {
- tp->total_retrans = req->num_retrans;
+ inet_csk(sk)->icsk_retransmits = 0;
reqsk_fastopen_remove(sk, req, false);
} else {
/* Make sure socket is routed, for correct metrics. */
diff --git a/net/ipv4/tcp_output.c b/net/ipv4/tcp_output.c
index bdaef7f..d48d557 100644
--- a/net/ipv4/tcp_output.c
+++ b/net/ipv4/tcp_output.c
@@ -1966,12 +1966,14 @@
len = 0;
tcp_for_write_queue_from_safe(skb, next, sk) {
copy = min_t(int, skb->len, probe_size - len);
- if (nskb->ip_summed)
+ if (nskb->ip_summed) {
skb_copy_bits(skb, 0, skb_put(nskb, copy), copy);
- else
- nskb->csum = skb_copy_and_csum_bits(skb, 0,
- skb_put(nskb, copy),
- copy, nskb->csum);
+ } else {
+ __wsum csum = skb_copy_and_csum_bits(skb, 0,
+ skb_put(nskb, copy),
+ copy, 0);
+ nskb->csum = csum_block_add(nskb->csum, csum, len);
+ }
if (skb->len <= copy) {
/* We've eaten all the data from this skb.
@@ -2605,7 +2607,8 @@
* copying overhead: fragmentation, tunneling, mangling etc.
*/
if (atomic_read(&sk->sk_wmem_alloc) >
- min(sk->sk_wmem_queued + (sk->sk_wmem_queued >> 2), sk->sk_sndbuf))
+ min_t(u32, sk->sk_wmem_queued + (sk->sk_wmem_queued >> 2),
+ sk->sk_sndbuf))
return -EAGAIN;
if (skb_still_in_host_queue(sk, skb))
@@ -2830,7 +2833,7 @@
if (tcp_retransmit_skb(sk, skb, segs))
return;
- NET_INC_STATS(sock_net(sk), mib_idx);
+ NET_ADD_STATS(sock_net(sk), mib_idx, tcp_skb_pcount(skb));
if (tcp_in_cwnd_reduction(sk))
tp->prr_out += tcp_skb_pcount(skb);
@@ -3567,6 +3570,8 @@
if (!res) {
__TCP_INC_STATS(sock_net(sk), TCP_MIB_RETRANSSEGS);
__NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPSYNRETRANS);
+ if (unlikely(tcp_passive_fastopen(sk)))
+ tcp_sk(sk)->total_retrans++;
}
return res;
}
diff --git a/net/ipv4/tcp_timer.c b/net/ipv4/tcp_timer.c
index d84930b..f712b41 100644
--- a/net/ipv4/tcp_timer.c
+++ b/net/ipv4/tcp_timer.c
@@ -384,6 +384,7 @@
*/
inet_rtx_syn_ack(sk, req);
req->num_timeout++;
+ icsk->icsk_retransmits++;
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
TCP_TIMEOUT_INIT << req->num_timeout, TCP_RTO_MAX);
}
diff --git a/net/ipv6/ip6_gre.c b/net/ipv6/ip6_gre.c
index 704274c..edc3daa 100644
--- a/net/ipv6/ip6_gre.c
+++ b/net/ipv6/ip6_gre.c
@@ -648,7 +648,6 @@
encap_limit = t->parms.encap_limit;
memcpy(&fl6, &t->fl.u.ip6, sizeof(fl6));
- fl6.flowi6_proto = skb->protocol;
err = gre_handle_offloads(skb, !!(t->parms.o_flags & TUNNEL_CSUM));
if (err)
diff --git a/net/ipv6/ip6_vti.c b/net/ipv6/ip6_vti.c
index d90a11f..5bd3afd 100644
--- a/net/ipv6/ip6_vti.c
+++ b/net/ipv6/ip6_vti.c
@@ -321,11 +321,9 @@
goto discard;
}
- XFRM_TUNNEL_SKB_CB(skb)->tunnel.ip6 = t;
-
rcu_read_unlock();
- return xfrm6_rcv(skb);
+ return xfrm6_rcv_tnl(skb, t);
}
rcu_read_unlock();
return -EINVAL;
@@ -340,6 +338,7 @@
struct net_device *dev;
struct pcpu_sw_netstats *tstats;
struct xfrm_state *x;
+ struct xfrm_mode *inner_mode;
struct ip6_tnl *t = XFRM_TUNNEL_SKB_CB(skb)->tunnel.ip6;
u32 orig_mark = skb->mark;
int ret;
@@ -357,7 +356,19 @@
}
x = xfrm_input_state(skb);
- family = x->inner_mode->afinfo->family;
+
+ inner_mode = x->inner_mode;
+
+ if (x->sel.family == AF_UNSPEC) {
+ inner_mode = xfrm_ip2inner_mode(x, XFRM_MODE_SKB_CB(skb)->protocol);
+ if (inner_mode == NULL) {
+ XFRM_INC_STATS(dev_net(skb->dev),
+ LINUX_MIB_XFRMINSTATEMODEERROR);
+ return -EINVAL;
+ }
+ }
+
+ family = inner_mode->afinfo->family;
skb->mark = be32_to_cpu(t->parms.i_key);
ret = xfrm_policy_check(NULL, XFRM_POLICY_IN, skb, family);
diff --git a/net/ipv6/ip6mr.c b/net/ipv6/ip6mr.c
index 6122f9c..7f4265b 100644
--- a/net/ipv6/ip6mr.c
+++ b/net/ipv6/ip6mr.c
@@ -2239,6 +2239,7 @@
struct rta_mfc_stats mfcs;
struct nlattr *mp_attr;
struct rtnexthop *nhp;
+ unsigned long lastuse;
int ct;
/* If cache is unresolved, don't try to parse IIF and OIF */
@@ -2269,12 +2270,14 @@
nla_nest_end(skb, mp_attr);
+ lastuse = READ_ONCE(c->mfc_un.res.lastuse);
+ lastuse = time_after_eq(jiffies, lastuse) ? jiffies - lastuse : 0;
+
mfcs.mfcs_packets = c->mfc_un.res.pkt;
mfcs.mfcs_bytes = c->mfc_un.res.bytes;
mfcs.mfcs_wrong_if = c->mfc_un.res.wrong_if;
if (nla_put_64bit(skb, RTA_MFC_STATS, sizeof(mfcs), &mfcs, RTA_PAD) ||
- nla_put_u64_64bit(skb, RTA_EXPIRES,
- jiffies_to_clock_t(c->mfc_un.res.lastuse),
+ nla_put_u64_64bit(skb, RTA_EXPIRES, jiffies_to_clock_t(lastuse),
RTA_PAD))
return -EMSGSIZE;
@@ -2282,8 +2285,8 @@
return 1;
}
-int ip6mr_get_route(struct net *net,
- struct sk_buff *skb, struct rtmsg *rtm, int nowait)
+int ip6mr_get_route(struct net *net, struct sk_buff *skb, struct rtmsg *rtm,
+ int nowait, u32 portid)
{
int err;
struct mr6_table *mrt;
@@ -2328,6 +2331,7 @@
return -ENOMEM;
}
+ NETLINK_CB(skb2).portid = portid;
skb_reset_transport_header(skb2);
skb_put(skb2, sizeof(struct ipv6hdr));
diff --git a/net/ipv6/netfilter/nft_chain_route_ipv6.c b/net/ipv6/netfilter/nft_chain_route_ipv6.c
index 71d995f..2535223 100644
--- a/net/ipv6/netfilter/nft_chain_route_ipv6.c
+++ b/net/ipv6/netfilter/nft_chain_route_ipv6.c
@@ -31,6 +31,7 @@
struct in6_addr saddr, daddr;
u_int8_t hop_limit;
u32 mark, flowlabel;
+ int err;
/* malformed packet, drop it */
if (nft_set_pktinfo_ipv6(&pkt, skb, state) < 0)
@@ -46,13 +47,16 @@
flowlabel = *((u32 *)ipv6_hdr(skb));
ret = nft_do_chain(&pkt, priv);
- if (ret != NF_DROP && ret != NF_QUEUE &&
+ if (ret != NF_DROP && ret != NF_STOLEN &&
(memcmp(&ipv6_hdr(skb)->saddr, &saddr, sizeof(saddr)) ||
memcmp(&ipv6_hdr(skb)->daddr, &daddr, sizeof(daddr)) ||
skb->mark != mark ||
ipv6_hdr(skb)->hop_limit != hop_limit ||
- flowlabel != *((u_int32_t *)ipv6_hdr(skb))))
- return ip6_route_me_harder(state->net, skb) == 0 ? ret : NF_DROP;
+ flowlabel != *((u_int32_t *)ipv6_hdr(skb)))) {
+ err = ip6_route_me_harder(state->net, skb);
+ if (err < 0)
+ ret = NF_DROP_ERR(err);
+ }
return ret;
}
diff --git a/net/ipv6/route.c b/net/ipv6/route.c
index 4981755..269218a 100644
--- a/net/ipv6/route.c
+++ b/net/ipv6/route.c
@@ -1986,9 +1986,18 @@
if (!(gwa_type & IPV6_ADDR_UNICAST))
goto out;
- if (cfg->fc_table)
+ if (cfg->fc_table) {
grt = ip6_nh_lookup_table(net, cfg, gw_addr);
+ if (grt) {
+ if (grt->rt6i_flags & RTF_GATEWAY ||
+ (dev && dev != grt->dst.dev)) {
+ ip6_rt_put(grt);
+ grt = NULL;
+ }
+ }
+ }
+
if (!grt)
grt = rt6_lookup(net, gw_addr, NULL,
cfg->fc_ifindex, 1);
@@ -3193,7 +3202,9 @@
if (iif) {
#ifdef CONFIG_IPV6_MROUTE
if (ipv6_addr_is_multicast(&rt->rt6i_dst.addr)) {
- int err = ip6mr_get_route(net, skb, rtm, nowait);
+ int err = ip6mr_get_route(net, skb, rtm, nowait,
+ portid);
+
if (err <= 0) {
if (!nowait) {
if (err == 0)
diff --git a/net/ipv6/xfrm6_input.c b/net/ipv6/xfrm6_input.c
index 00a2d40..b578956 100644
--- a/net/ipv6/xfrm6_input.c
+++ b/net/ipv6/xfrm6_input.c
@@ -21,9 +21,10 @@
return xfrm6_extract_header(skb);
}
-int xfrm6_rcv_spi(struct sk_buff *skb, int nexthdr, __be32 spi)
+int xfrm6_rcv_spi(struct sk_buff *skb, int nexthdr, __be32 spi,
+ struct ip6_tnl *t)
{
- XFRM_TUNNEL_SKB_CB(skb)->tunnel.ip6 = NULL;
+ XFRM_TUNNEL_SKB_CB(skb)->tunnel.ip6 = t;
XFRM_SPI_SKB_CB(skb)->family = AF_INET6;
XFRM_SPI_SKB_CB(skb)->daddroff = offsetof(struct ipv6hdr, daddr);
return xfrm_input(skb, nexthdr, spi, 0);
@@ -49,13 +50,18 @@
return -1;
}
-int xfrm6_rcv(struct sk_buff *skb)
+int xfrm6_rcv_tnl(struct sk_buff *skb, struct ip6_tnl *t)
{
return xfrm6_rcv_spi(skb, skb_network_header(skb)[IP6CB(skb)->nhoff],
- 0);
+ 0, t);
+}
+EXPORT_SYMBOL(xfrm6_rcv_tnl);
+
+int xfrm6_rcv(struct sk_buff *skb)
+{
+ return xfrm6_rcv_tnl(skb, NULL);
}
EXPORT_SYMBOL(xfrm6_rcv);
-
int xfrm6_input_addr(struct sk_buff *skb, xfrm_address_t *daddr,
xfrm_address_t *saddr, u8 proto)
{
diff --git a/net/ipv6/xfrm6_tunnel.c b/net/ipv6/xfrm6_tunnel.c
index 5743044..e1c0bbe 100644
--- a/net/ipv6/xfrm6_tunnel.c
+++ b/net/ipv6/xfrm6_tunnel.c
@@ -236,7 +236,7 @@
__be32 spi;
spi = xfrm6_tunnel_spi_lookup(net, (const xfrm_address_t *)&iph->saddr);
- return xfrm6_rcv_spi(skb, IPPROTO_IPV6, spi);
+ return xfrm6_rcv_spi(skb, IPPROTO_IPV6, spi, NULL);
}
static int xfrm6_tunnel_err(struct sk_buff *skb, struct inet6_skb_parm *opt,
diff --git a/net/irda/af_irda.c b/net/irda/af_irda.c
index 8d2f7c9..ccc2444 100644
--- a/net/irda/af_irda.c
+++ b/net/irda/af_irda.c
@@ -832,7 +832,7 @@
struct sock *sk = sock->sk;
struct irda_sock *new, *self = irda_sk(sk);
struct sock *newsk;
- struct sk_buff *skb;
+ struct sk_buff *skb = NULL;
int err;
err = irda_create(sock_net(sk), newsock, sk->sk_protocol, 0);
@@ -900,7 +900,6 @@
err = -EPERM; /* value does not seem to make sense. -arnd */
if (!new->tsap) {
pr_debug("%s(), dup failed!\n", __func__);
- kfree_skb(skb);
goto out;
}
@@ -919,7 +918,6 @@
/* Clean up the original one to keep it in listen state */
irttp_listen(self->tsap);
- kfree_skb(skb);
sk->sk_ack_backlog--;
newsock->state = SS_CONNECTED;
@@ -927,6 +925,7 @@
irda_connect_response(new);
err = 0;
out:
+ kfree_skb(skb);
release_sock(sk);
return err;
}
diff --git a/net/mac80211/agg-rx.c b/net/mac80211/agg-rx.c
index a9aff60..afa9468 100644
--- a/net/mac80211/agg-rx.c
+++ b/net/mac80211/agg-rx.c
@@ -261,10 +261,16 @@
.timeout = timeout,
.ssn = start_seq_num,
};
-
int i, ret = -EOPNOTSUPP;
u16 status = WLAN_STATUS_REQUEST_DECLINED;
+ if (tid >= IEEE80211_FIRST_TSPEC_TSID) {
+ ht_dbg(sta->sdata,
+ "STA %pM requests BA session on unsupported tid %d\n",
+ sta->sta.addr, tid);
+ goto end_no_lock;
+ }
+
if (!sta->sta.ht_cap.ht_supported) {
ht_dbg(sta->sdata,
"STA %pM erroneously requests BA session on tid %d w/o QoS\n",
diff --git a/net/mac80211/agg-tx.c b/net/mac80211/agg-tx.c
index 5650c46..45319cc 100644
--- a/net/mac80211/agg-tx.c
+++ b/net/mac80211/agg-tx.c
@@ -584,6 +584,9 @@
ieee80211_hw_check(&local->hw, TX_AMPDU_SETUP_IN_HW))
return -EINVAL;
+ if (WARN_ON(tid >= IEEE80211_FIRST_TSPEC_TSID))
+ return -EINVAL;
+
ht_dbg(sdata, "Open BA session requested for %pM tid %u\n",
pubsta->addr, tid);
diff --git a/net/mac80211/mesh_hwmp.c b/net/mac80211/mesh_hwmp.c
index 8f9c3bd..faccef9 100644
--- a/net/mac80211/mesh_hwmp.c
+++ b/net/mac80211/mesh_hwmp.c
@@ -746,6 +746,7 @@
sta = next_hop_deref_protected(mpath);
if (mpath->flags & MESH_PATH_ACTIVE &&
ether_addr_equal(ta, sta->sta.addr) &&
+ !(mpath->flags & MESH_PATH_FIXED) &&
(!(mpath->flags & MESH_PATH_SN_VALID) ||
SN_GT(target_sn, mpath->sn) || target_sn == 0)) {
mpath->flags &= ~MESH_PATH_ACTIVE;
@@ -1012,7 +1013,7 @@
goto enddiscovery;
spin_lock_bh(&mpath->state_lock);
- if (mpath->flags & MESH_PATH_DELETED) {
+ if (mpath->flags & (MESH_PATH_DELETED | MESH_PATH_FIXED)) {
spin_unlock_bh(&mpath->state_lock);
goto enddiscovery;
}
diff --git a/net/mac80211/mesh_pathtbl.c b/net/mac80211/mesh_pathtbl.c
index 6db2ddf..f0e6175 100644
--- a/net/mac80211/mesh_pathtbl.c
+++ b/net/mac80211/mesh_pathtbl.c
@@ -826,7 +826,7 @@
mpath->metric = 0;
mpath->hop_count = 0;
mpath->exp_time = 0;
- mpath->flags |= MESH_PATH_FIXED;
+ mpath->flags = MESH_PATH_FIXED | MESH_PATH_SN_VALID;
mesh_path_activate(mpath);
spin_unlock_bh(&mpath->state_lock);
mesh_path_tx_pending(mpath);
diff --git a/net/mac80211/sta_info.c b/net/mac80211/sta_info.c
index 76b737d..aa58df8 100644
--- a/net/mac80211/sta_info.c
+++ b/net/mac80211/sta_info.c
@@ -1616,7 +1616,6 @@
sta_info_recalc_tim(sta);
} else {
- unsigned long tids = sta->txq_buffered_tids & driver_release_tids;
int tid;
/*
@@ -1648,7 +1647,8 @@
for (tid = 0; tid < ARRAY_SIZE(sta->sta.txq); tid++) {
struct txq_info *txqi = to_txq_info(sta->sta.txq[tid]);
- if (!(tids & BIT(tid)) || txqi->tin.backlog_packets)
+ if (!(driver_release_tids & BIT(tid)) ||
+ txqi->tin.backlog_packets)
continue;
sta_info_recalc_tim(sta);
diff --git a/net/mac80211/tx.c b/net/mac80211/tx.c
index 5023966..18b285e 100644
--- a/net/mac80211/tx.c
+++ b/net/mac80211/tx.c
@@ -796,6 +796,36 @@
return ret;
}
+static struct txq_info *ieee80211_get_txq(struct ieee80211_local *local,
+ struct ieee80211_vif *vif,
+ struct ieee80211_sta *pubsta,
+ struct sk_buff *skb)
+{
+ struct ieee80211_hdr *hdr = (struct ieee80211_hdr *) skb->data;
+ struct ieee80211_tx_info *info = IEEE80211_SKB_CB(skb);
+ struct ieee80211_txq *txq = NULL;
+
+ if ((info->flags & IEEE80211_TX_CTL_SEND_AFTER_DTIM) ||
+ (info->control.flags & IEEE80211_TX_CTRL_PS_RESPONSE))
+ return NULL;
+
+ if (!ieee80211_is_data(hdr->frame_control))
+ return NULL;
+
+ if (pubsta) {
+ u8 tid = skb->priority & IEEE80211_QOS_CTL_TID_MASK;
+
+ txq = pubsta->txq[tid];
+ } else if (vif) {
+ txq = vif->txq;
+ }
+
+ if (!txq)
+ return NULL;
+
+ return to_txq_info(txq);
+}
+
static ieee80211_tx_result debug_noinline
ieee80211_tx_h_sequence(struct ieee80211_tx_data *tx)
{
@@ -853,7 +883,8 @@
tid = *qc & IEEE80211_QOS_CTL_TID_MASK;
tx->sta->tx_stats.msdu[tid]++;
- if (!tx->sta->sta.txq[0])
+ if (!ieee80211_get_txq(tx->local, info->control.vif, &tx->sta->sta,
+ tx->skb))
hdr->seq_ctrl = ieee80211_tx_next_seq(tx->sta, tid);
return TX_CONTINUE;
@@ -1243,36 +1274,6 @@
return TX_CONTINUE;
}
-static struct txq_info *ieee80211_get_txq(struct ieee80211_local *local,
- struct ieee80211_vif *vif,
- struct ieee80211_sta *pubsta,
- struct sk_buff *skb)
-{
- struct ieee80211_hdr *hdr = (struct ieee80211_hdr *) skb->data;
- struct ieee80211_tx_info *info = IEEE80211_SKB_CB(skb);
- struct ieee80211_txq *txq = NULL;
-
- if ((info->flags & IEEE80211_TX_CTL_SEND_AFTER_DTIM) ||
- (info->control.flags & IEEE80211_TX_CTRL_PS_RESPONSE))
- return NULL;
-
- if (!ieee80211_is_data(hdr->frame_control))
- return NULL;
-
- if (pubsta) {
- u8 tid = skb->priority & IEEE80211_QOS_CTL_TID_MASK;
-
- txq = pubsta->txq[tid];
- } else if (vif) {
- txq = vif->txq;
- }
-
- if (!txq)
- return NULL;
-
- return to_txq_info(txq);
-}
-
static void ieee80211_set_skb_enqueue_time(struct sk_buff *skb)
{
IEEE80211_SKB_CB(skb)->control.enqueue_time = codel_get_time();
@@ -1514,8 +1515,12 @@
spin_unlock_bh(&fq->lock);
if (skb && skb_has_frag_list(skb) &&
- !ieee80211_hw_check(&local->hw, TX_FRAG_LIST))
- skb_linearize(skb);
+ !ieee80211_hw_check(&local->hw, TX_FRAG_LIST)) {
+ if (skb_linearize(skb)) {
+ ieee80211_free_txskb(&local->hw, skb);
+ return NULL;
+ }
+ }
return skb;
}
@@ -3264,7 +3269,7 @@
if (hdr->frame_control & cpu_to_le16(IEEE80211_STYPE_QOS_DATA)) {
*ieee80211_get_qos_ctl(hdr) = tid;
- if (!sta->sta.txq[0])
+ if (!ieee80211_get_txq(local, &sdata->vif, &sta->sta, skb))
hdr->seq_ctrl = ieee80211_tx_next_seq(sta, tid);
} else {
info->flags |= IEEE80211_TX_CTL_ASSIGN_SEQ;
diff --git a/net/netfilter/nf_conntrack_core.c b/net/netfilter/nf_conntrack_core.c
index dd2c43ab..9934b0c 100644
--- a/net/netfilter/nf_conntrack_core.c
+++ b/net/netfilter/nf_conntrack_core.c
@@ -1035,9 +1035,9 @@
if (IS_ERR(ct))
return (struct nf_conntrack_tuple_hash *)ct;
- if (tmpl && nfct_synproxy(tmpl)) {
- nfct_seqadj_ext_add(ct);
- nfct_synproxy_ext_add(ct);
+ if (!nf_ct_add_synproxy(ct, tmpl)) {
+ nf_conntrack_free(ct);
+ return ERR_PTR(-ENOMEM);
}
timeout_ext = tmpl ? nf_ct_timeout_find(tmpl) : NULL;
diff --git a/net/netfilter/nf_nat_core.c b/net/netfilter/nf_nat_core.c
index de31818..ecee105 100644
--- a/net/netfilter/nf_nat_core.c
+++ b/net/netfilter/nf_nat_core.c
@@ -441,7 +441,8 @@
ct->status |= IPS_DST_NAT;
if (nfct_help(ct))
- nfct_seqadj_ext_add(ct);
+ if (!nfct_seqadj_ext_add(ct))
+ return NF_DROP;
}
if (maniptype == NF_NAT_MANIP_SRC) {
@@ -807,7 +808,7 @@
if (err < 0)
return err;
- return nf_nat_setup_info(ct, &range, manip);
+ return nf_nat_setup_info(ct, &range, manip) == NF_DROP ? -ENOMEM : 0;
}
#else
static int
diff --git a/net/netfilter/nf_tables_trace.c b/net/netfilter/nf_tables_trace.c
index 39eb1cc..fa24a5b 100644
--- a/net/netfilter/nf_tables_trace.c
+++ b/net/netfilter/nf_tables_trace.c
@@ -237,7 +237,7 @@
break;
case NFT_TRACETYPE_POLICY:
if (nla_put_be32(skb, NFTA_TRACE_POLICY,
- info->basechain->policy))
+ htonl(info->basechain->policy)))
goto nla_put_failure;
break;
}
diff --git a/net/sched/act_ife.c b/net/sched/act_ife.c
index e87cd81..4a60cd5 100644
--- a/net/sched/act_ife.c
+++ b/net/sched/act_ife.c
@@ -53,7 +53,7 @@
u32 *tlv = (u32 *)(skbdata);
u16 totlen = nla_total_size(dlen); /*alignment + hdr */
char *dptr = (char *)tlv + NLA_HDRLEN;
- u32 htlv = attrtype << 16 | dlen;
+ u32 htlv = attrtype << 16 | (dlen + NLA_HDRLEN);
*tlv = htonl(htlv);
memset(dptr, 0, totlen - NLA_HDRLEN);
@@ -627,7 +627,7 @@
struct tcf_ife_info *ife = to_ife(a);
int action = ife->tcf_action;
struct ifeheadr *ifehdr = (struct ifeheadr *)skb->data;
- u16 ifehdrln = ifehdr->metalen;
+ int ifehdrln = (int)ifehdr->metalen;
struct meta_tlvhdr *tlv = (struct meta_tlvhdr *)(ifehdr->tlv_data);
spin_lock(&ife->tcf_lock);
@@ -740,8 +740,6 @@
return TC_ACT_SHOT;
}
- iethh = eth_hdr(skb);
-
err = skb_cow_head(skb, hdrm);
if (unlikely(err)) {
ife->tcf_qstats.drops++;
@@ -752,6 +750,7 @@
if (!(at & AT_EGRESS))
skb_push(skb, skb->dev->hard_header_len);
+ iethh = (struct ethhdr *)skb->data;
__skb_push(skb, hdrm);
memcpy(skb->data, iethh, skb->mac_len);
skb_reset_mac_header(skb);
diff --git a/net/sched/sch_qfq.c b/net/sched/sch_qfq.c
index f27ffee..ca0516e 100644
--- a/net/sched/sch_qfq.c
+++ b/net/sched/sch_qfq.c
@@ -1153,6 +1153,7 @@
if (!skb)
return NULL;
+ qdisc_qstats_backlog_dec(sch, skb);
sch->q.qlen--;
qdisc_bstats_update(sch, skb);
@@ -1256,6 +1257,7 @@
}
bstats_update(&cl->bstats, skb);
+ qdisc_qstats_backlog_inc(sch, skb);
++sch->q.qlen;
agg = cl->agg;
@@ -1476,6 +1478,7 @@
qdisc_reset(cl->qdisc);
}
}
+ sch->qstats.backlog = 0;
sch->q.qlen = 0;
}
diff --git a/net/sched/sch_sfb.c b/net/sched/sch_sfb.c
index add3cc7..20a350b 100644
--- a/net/sched/sch_sfb.c
+++ b/net/sched/sch_sfb.c
@@ -400,6 +400,7 @@
enqueue:
ret = qdisc_enqueue(skb, child, to_free);
if (likely(ret == NET_XMIT_SUCCESS)) {
+ qdisc_qstats_backlog_inc(sch, skb);
sch->q.qlen++;
increment_qlen(skb, q);
} else if (net_xmit_drop_count(ret)) {
@@ -428,6 +429,7 @@
if (skb) {
qdisc_bstats_update(sch, skb);
+ qdisc_qstats_backlog_dec(sch, skb);
sch->q.qlen--;
decrement_qlen(skb, q);
}
@@ -450,6 +452,7 @@
struct sfb_sched_data *q = qdisc_priv(sch);
qdisc_reset(q->qdisc);
+ sch->qstats.backlog = 0;
sch->q.qlen = 0;
q->slot = 0;
q->double_buffering = false;
diff --git a/net/sctp/chunk.c b/net/sctp/chunk.c
index a55e547..0a3dbec 100644
--- a/net/sctp/chunk.c
+++ b/net/sctp/chunk.c
@@ -179,6 +179,11 @@
msg, msg->expires_at, jiffies);
}
+ if (asoc->peer.prsctp_capable &&
+ SCTP_PR_TTL_ENABLED(sinfo->sinfo_flags))
+ msg->expires_at =
+ jiffies + msecs_to_jiffies(sinfo->sinfo_timetolive);
+
/* This is the biggest possible DATA chunk that can fit into
* the packet
*/
@@ -335,7 +340,7 @@
/* Check whether this message has expired. */
int sctp_chunk_abandoned(struct sctp_chunk *chunk)
{
- if (!chunk->asoc->prsctp_enable ||
+ if (!chunk->asoc->peer.prsctp_capable ||
!SCTP_PR_POLICY(chunk->sinfo.sinfo_flags)) {
struct sctp_datamsg *msg = chunk->msg;
@@ -349,14 +354,14 @@
}
if (SCTP_PR_TTL_ENABLED(chunk->sinfo.sinfo_flags) &&
- time_after(jiffies, chunk->prsctp_param)) {
+ time_after(jiffies, chunk->msg->expires_at)) {
if (chunk->sent_count)
chunk->asoc->abandoned_sent[SCTP_PR_INDEX(TTL)]++;
else
chunk->asoc->abandoned_unsent[SCTP_PR_INDEX(TTL)]++;
return 1;
} else if (SCTP_PR_RTX_ENABLED(chunk->sinfo.sinfo_flags) &&
- chunk->sent_count > chunk->prsctp_param) {
+ chunk->sent_count > chunk->sinfo.sinfo_timetolive) {
chunk->asoc->abandoned_sent[SCTP_PR_INDEX(RTX)]++;
return 1;
}
diff --git a/net/sctp/input.c b/net/sctp/input.c
index 69444d3..1555fb8 100644
--- a/net/sctp/input.c
+++ b/net/sctp/input.c
@@ -796,27 +796,34 @@
static inline int sctp_hash_cmp(struct rhashtable_compare_arg *arg,
const void *ptr)
{
+ struct sctp_transport *t = (struct sctp_transport *)ptr;
const struct sctp_hash_cmp_arg *x = arg->key;
- const struct sctp_transport *t = ptr;
- struct sctp_association *asoc = t->asoc;
- const struct net *net = x->net;
+ struct sctp_association *asoc;
+ int err = 1;
if (!sctp_cmp_addr_exact(&t->ipaddr, x->paddr))
- return 1;
- if (!net_eq(sock_net(asoc->base.sk), net))
- return 1;
+ return err;
+ if (!sctp_transport_hold(t))
+ return err;
+
+ asoc = t->asoc;
+ if (!net_eq(sock_net(asoc->base.sk), x->net))
+ goto out;
if (x->ep) {
if (x->ep != asoc->ep)
- return 1;
+ goto out;
} else {
if (x->laddr->v4.sin_port != htons(asoc->base.bind_addr.port))
- return 1;
+ goto out;
if (!sctp_bind_addr_match(&asoc->base.bind_addr,
x->laddr, sctp_sk(asoc->base.sk)))
- return 1;
+ goto out;
}
- return 0;
+ err = 0;
+out:
+ sctp_transport_put(t);
+ return err;
}
static inline u32 sctp_hash_obj(const void *data, u32 len, u32 seed)
diff --git a/net/sctp/outqueue.c b/net/sctp/outqueue.c
index 72e54a4..107233d 100644
--- a/net/sctp/outqueue.c
+++ b/net/sctp/outqueue.c
@@ -326,7 +326,7 @@
sctp_chunk_hold(chunk);
sctp_outq_tail_data(q, chunk);
- if (chunk->asoc->prsctp_enable &&
+ if (chunk->asoc->peer.prsctp_capable &&
SCTP_PR_PRIO_ENABLED(chunk->sinfo.sinfo_flags))
chunk->asoc->sent_cnt_removable++;
if (chunk->chunk_hdr->flags & SCTP_DATA_UNORDERED)
@@ -383,7 +383,7 @@
list_for_each_entry_safe(chk, temp, queue, transmitted_list) {
if (!SCTP_PR_PRIO_ENABLED(chk->sinfo.sinfo_flags) ||
- chk->prsctp_param <= sinfo->sinfo_timetolive)
+ chk->sinfo.sinfo_timetolive <= sinfo->sinfo_timetolive)
continue;
list_del_init(&chk->transmitted_list);
@@ -418,7 +418,7 @@
list_for_each_entry_safe(chk, temp, queue, list) {
if (!SCTP_PR_PRIO_ENABLED(chk->sinfo.sinfo_flags) ||
- chk->prsctp_param <= sinfo->sinfo_timetolive)
+ chk->sinfo.sinfo_timetolive <= sinfo->sinfo_timetolive)
continue;
list_del_init(&chk->list);
@@ -442,7 +442,7 @@
{
struct sctp_transport *transport;
- if (!asoc->prsctp_enable || !asoc->sent_cnt_removable)
+ if (!asoc->peer.prsctp_capable || !asoc->sent_cnt_removable)
return;
msg_len = sctp_prsctp_prune_sent(asoc, sinfo,
@@ -1055,7 +1055,7 @@
/* Mark as failed send. */
sctp_chunk_fail(chunk, SCTP_ERROR_INV_STRM);
- if (asoc->prsctp_enable &&
+ if (asoc->peer.prsctp_capable &&
SCTP_PR_PRIO_ENABLED(chunk->sinfo.sinfo_flags))
asoc->sent_cnt_removable--;
sctp_chunk_free(chunk);
@@ -1347,7 +1347,7 @@
tsn = ntohl(tchunk->subh.data_hdr->tsn);
if (TSN_lte(tsn, ctsn)) {
list_del_init(&tchunk->transmitted_list);
- if (asoc->prsctp_enable &&
+ if (asoc->peer.prsctp_capable &&
SCTP_PR_PRIO_ENABLED(chunk->sinfo.sinfo_flags))
asoc->sent_cnt_removable--;
sctp_chunk_free(tchunk);
diff --git a/net/sctp/sctp_diag.c b/net/sctp/sctp_diag.c
index f3508aa..cef0cee 100644
--- a/net/sctp/sctp_diag.c
+++ b/net/sctp/sctp_diag.c
@@ -272,28 +272,17 @@
return err;
}
-static int sctp_tsp_dump(struct sctp_transport *tsp, void *p)
+static int sctp_sock_dump(struct sock *sk, void *p)
{
- struct sctp_endpoint *ep = tsp->asoc->ep;
+ struct sctp_endpoint *ep = sctp_sk(sk)->ep;
struct sctp_comm_param *commp = p;
- struct sock *sk = ep->base.sk;
struct sk_buff *skb = commp->skb;
struct netlink_callback *cb = commp->cb;
const struct inet_diag_req_v2 *r = commp->r;
- struct sctp_association *assoc =
- list_entry(ep->asocs.next, struct sctp_association, asocs);
+ struct sctp_association *assoc;
int err = 0;
- /* find the ep only once through the transports by this condition */
- if (tsp->asoc != assoc)
- goto out;
-
- if (r->sdiag_family != AF_UNSPEC && sk->sk_family != r->sdiag_family)
- goto out;
-
lock_sock(sk);
- if (sk != assoc->base.sk)
- goto release;
list_for_each_entry(assoc, &ep->asocs, asocs) {
if (cb->args[4] < cb->args[1])
goto next;
@@ -312,7 +301,7 @@
cb->nlh->nlmsg_seq,
NLM_F_MULTI, cb->nlh) < 0) {
cb->args[3] = 1;
- err = 2;
+ err = 1;
goto release;
}
cb->args[3] = 1;
@@ -321,7 +310,7 @@
sk_user_ns(NETLINK_CB(cb->skb).sk),
NETLINK_CB(cb->skb).portid,
cb->nlh->nlmsg_seq, 0, cb->nlh) < 0) {
- err = 2;
+ err = 1;
goto release;
}
next:
@@ -333,10 +322,35 @@
cb->args[4] = 0;
release:
release_sock(sk);
+ sock_put(sk);
return err;
+}
+
+static int sctp_get_sock(struct sctp_transport *tsp, void *p)
+{
+ struct sctp_endpoint *ep = tsp->asoc->ep;
+ struct sctp_comm_param *commp = p;
+ struct sock *sk = ep->base.sk;
+ struct netlink_callback *cb = commp->cb;
+ const struct inet_diag_req_v2 *r = commp->r;
+ struct sctp_association *assoc =
+ list_entry(ep->asocs.next, struct sctp_association, asocs);
+
+ /* find the ep only once through the transports by this condition */
+ if (tsp->asoc != assoc)
+ goto out;
+
+ if (r->sdiag_family != AF_UNSPEC && sk->sk_family != r->sdiag_family)
+ goto out;
+
+ sock_hold(sk);
+ cb->args[5] = (long)sk;
+
+ return 1;
+
out:
cb->args[2]++;
- return err;
+ return 0;
}
static int sctp_ep_dump(struct sctp_endpoint *ep, void *p)
@@ -472,10 +486,18 @@
* 2 : to record the transport pos of this time's traversal
* 3 : to mark if we have dumped the ep info of the current asoc
* 4 : to work as a temporary variable to traversal list
+ * 5 : to save the sk we get from travelsing the tsp list.
*/
if (!(idiag_states & ~(TCPF_LISTEN | TCPF_CLOSE)))
goto done;
- sctp_for_each_transport(sctp_tsp_dump, net, cb->args[2], &commp);
+
+next:
+ cb->args[5] = 0;
+ sctp_for_each_transport(sctp_get_sock, net, cb->args[2], &commp);
+
+ if (cb->args[5] && !sctp_sock_dump((struct sock *)cb->args[5], &commp))
+ goto next;
+
done:
cb->args[1] = cb->args[4];
cb->args[4] = 0;
diff --git a/net/sctp/sm_make_chunk.c b/net/sctp/sm_make_chunk.c
index 8c77b87..46ffecc 100644
--- a/net/sctp/sm_make_chunk.c
+++ b/net/sctp/sm_make_chunk.c
@@ -706,20 +706,6 @@
return retval;
}
-static void sctp_set_prsctp_policy(struct sctp_chunk *chunk,
- const struct sctp_sndrcvinfo *sinfo)
-{
- if (!chunk->asoc->prsctp_enable)
- return;
-
- if (SCTP_PR_TTL_ENABLED(sinfo->sinfo_flags))
- chunk->prsctp_param =
- jiffies + msecs_to_jiffies(sinfo->sinfo_timetolive);
- else if (SCTP_PR_RTX_ENABLED(sinfo->sinfo_flags) ||
- SCTP_PR_PRIO_ENABLED(sinfo->sinfo_flags))
- chunk->prsctp_param = sinfo->sinfo_timetolive;
-}
-
/* Make a DATA chunk for the given association from the provided
* parameters. However, do not populate the data payload.
*/
@@ -753,7 +739,6 @@
retval->subh.data_hdr = sctp_addto_chunk(retval, sizeof(dp), &dp);
memcpy(&retval->sinfo, sinfo, sizeof(struct sctp_sndrcvinfo));
- sctp_set_prsctp_policy(retval, sinfo);
nodata:
return retval;
diff --git a/net/sctp/socket.c b/net/sctp/socket.c
index 9fc417a..8ed2d99 100644
--- a/net/sctp/socket.c
+++ b/net/sctp/socket.c
@@ -4469,17 +4469,21 @@
const union sctp_addr *paddr, void *p)
{
struct sctp_transport *transport;
- int err = 0;
+ int err = -ENOENT;
rcu_read_lock();
transport = sctp_addrs_lookup_transport(net, laddr, paddr);
if (!transport || !sctp_transport_hold(transport))
goto out;
- err = cb(transport, p);
+
+ sctp_association_hold(transport->asoc);
sctp_transport_put(transport);
-out:
rcu_read_unlock();
+ err = cb(transport, p);
+ sctp_association_put(transport->asoc);
+
+out:
return err;
}
EXPORT_SYMBOL_GPL(sctp_transport_lookup_process);
diff --git a/net/vmw_vsock/af_vsock.c b/net/vmw_vsock/af_vsock.c
index 17dbbe6..8a398b3 100644
--- a/net/vmw_vsock/af_vsock.c
+++ b/net/vmw_vsock/af_vsock.c
@@ -465,6 +465,8 @@
if (vsock_is_pending(sk)) {
vsock_remove_pending(listener, sk);
+
+ listener->sk_ack_backlog--;
} else if (!vsk->rejected) {
/* We are not on the pending list and accept() did not reject
* us, so we must have been accepted by our user process. We
@@ -475,8 +477,6 @@
goto out;
}
- listener->sk_ack_backlog--;
-
/* We need to remove ourself from the global connected sockets list so
* incoming packets can't find this socket, and to reduce the reference
* count.
@@ -2010,5 +2010,5 @@
MODULE_AUTHOR("VMware, Inc.");
MODULE_DESCRIPTION("VMware Virtual Socket Family");
-MODULE_VERSION("1.0.1.0-k");
+MODULE_VERSION("1.0.2.0-k");
MODULE_LICENSE("GPL v2");
diff --git a/net/wireless/nl80211.c b/net/wireless/nl80211.c
index f02653a..4809f4d 100644
--- a/net/wireless/nl80211.c
+++ b/net/wireless/nl80211.c
@@ -6978,7 +6978,7 @@
params.n_counter_offsets_presp = len / sizeof(u16);
if (rdev->wiphy.max_num_csa_counters &&
- (params.n_counter_offsets_beacon >
+ (params.n_counter_offsets_presp >
rdev->wiphy.max_num_csa_counters))
return -EINVAL;
diff --git a/net/xfrm/xfrm_state.c b/net/xfrm/xfrm_state.c
index 9895a8c..a30f898d 100644
--- a/net/xfrm/xfrm_state.c
+++ b/net/xfrm/xfrm_state.c
@@ -332,6 +332,7 @@
{
tasklet_hrtimer_cancel(&x->mtimer);
del_timer_sync(&x->rtimer);
+ kfree(x->aead);
kfree(x->aalg);
kfree(x->ealg);
kfree(x->calg);
diff --git a/net/xfrm/xfrm_user.c b/net/xfrm/xfrm_user.c
index cb65d91..0889209 100644
--- a/net/xfrm/xfrm_user.c
+++ b/net/xfrm/xfrm_user.c
@@ -581,9 +581,12 @@
if (err)
goto error;
- if (attrs[XFRMA_SEC_CTX] &&
- security_xfrm_state_alloc(x, nla_data(attrs[XFRMA_SEC_CTX])))
- goto error;
+ if (attrs[XFRMA_SEC_CTX]) {
+ err = security_xfrm_state_alloc(x,
+ nla_data(attrs[XFRMA_SEC_CTX]));
+ if (err)
+ goto error;
+ }
if ((err = xfrm_alloc_replay_state_esn(&x->replay_esn, &x->preplay_esn,
attrs[XFRMA_REPLAY_ESN_VAL])))
diff --git a/scripts/faddr2line b/scripts/faddr2line
new file mode 100755
index 0000000..450b332
--- /dev/null
+++ b/scripts/faddr2line
@@ -0,0 +1,177 @@
+#!/bin/bash
+#
+# Translate stack dump function offsets.
+#
+# addr2line doesn't work with KASLR addresses. This works similarly to
+# addr2line, but instead takes the 'func+0x123' format as input:
+#
+# $ ./scripts/faddr2line ~/k/vmlinux meminfo_proc_show+0x5/0x568
+# meminfo_proc_show+0x5/0x568:
+# meminfo_proc_show at fs/proc/meminfo.c:27
+#
+# If the address is part of an inlined function, the full inline call chain is
+# printed:
+#
+# $ ./scripts/faddr2line ~/k/vmlinux native_write_msr+0x6/0x27
+# native_write_msr+0x6/0x27:
+# arch_static_branch at arch/x86/include/asm/msr.h:121
+# (inlined by) static_key_false at include/linux/jump_label.h:125
+# (inlined by) native_write_msr at arch/x86/include/asm/msr.h:125
+#
+# The function size after the '/' in the input is optional, but recommended.
+# It's used to help disambiguate any duplicate symbol names, which can occur
+# rarely. If the size is omitted for a duplicate symbol then it's possible for
+# multiple code sites to be printed:
+#
+# $ ./scripts/faddr2line ~/k/vmlinux raw_ioctl+0x5
+# raw_ioctl+0x5/0x20:
+# raw_ioctl at drivers/char/raw.c:122
+#
+# raw_ioctl+0x5/0xb1:
+# raw_ioctl at net/ipv4/raw.c:876
+#
+# Multiple addresses can be specified on a single command line:
+#
+# $ ./scripts/faddr2line ~/k/vmlinux type_show+0x10/45 free_reserved_area+0x90
+# type_show+0x10/0x2d:
+# type_show at drivers/video/backlight/backlight.c:213
+#
+# free_reserved_area+0x90/0x123:
+# free_reserved_area at mm/page_alloc.c:6429 (discriminator 2)
+
+
+set -o errexit
+set -o nounset
+
+command -v awk >/dev/null 2>&1 || die "awk isn't installed"
+command -v readelf >/dev/null 2>&1 || die "readelf isn't installed"
+command -v addr2line >/dev/null 2>&1 || die "addr2line isn't installed"
+
+usage() {
+ echo "usage: faddr2line <object file> <func+offset> <func+offset>..." >&2
+ exit 1
+}
+
+warn() {
+ echo "$1" >&2
+}
+
+die() {
+ echo "ERROR: $1" >&2
+ exit 1
+}
+
+# Try to figure out the source directory prefix so we can remove it from the
+# addr2line output. HACK ALERT: This assumes that start_kernel() is in
+# kernel/init.c! This only works for vmlinux. Otherwise it falls back to
+# printing the absolute path.
+find_dir_prefix() {
+ local objfile=$1
+
+ local start_kernel_addr=$(readelf -sW $objfile | awk '$8 == "start_kernel" {printf "0x%s", $2}')
+ [[ -z $start_kernel_addr ]] && return
+
+ local file_line=$(addr2line -e $objfile $start_kernel_addr)
+ [[ -z $file_line ]] && return
+
+ local prefix=${file_line%init/main.c:*}
+ if [[ -z $prefix ]] || [[ $prefix = $file_line ]]; then
+ return
+ fi
+
+ DIR_PREFIX=$prefix
+ return 0
+}
+
+__faddr2line() {
+ local objfile=$1
+ local func_addr=$2
+ local dir_prefix=$3
+ local print_warnings=$4
+
+ local func=${func_addr%+*}
+ local offset=${func_addr#*+}
+ offset=${offset%/*}
+ local size=
+ [[ $func_addr =~ "/" ]] && size=${func_addr#*/}
+
+ if [[ -z $func ]] || [[ -z $offset ]] || [[ $func = $func_addr ]]; then
+ warn "bad func+offset $func_addr"
+ DONE=1
+ return
+ fi
+
+ # Go through each of the object's symbols which match the func name.
+ # In rare cases there might be duplicates.
+ while read symbol; do
+ local fields=($symbol)
+ local sym_base=0x${fields[1]}
+ local sym_size=${fields[2]}
+ local sym_type=${fields[3]}
+
+ # calculate the address
+ local addr=$(($sym_base + $offset))
+ if [[ -z $addr ]] || [[ $addr = 0 ]]; then
+ warn "bad address: $sym_base + $offset"
+ DONE=1
+ return
+ fi
+ local hexaddr=0x$(printf %x $addr)
+
+ # weed out non-function symbols
+ if [[ $sym_type != "FUNC" ]]; then
+ [[ $print_warnings = 1 ]] &&
+ echo "skipping $func address at $hexaddr due to non-function symbol"
+ continue
+ fi
+
+ # if the user provided a size, make sure it matches the symbol's size
+ if [[ -n $size ]] && [[ $size -ne $sym_size ]]; then
+ [[ $print_warnings = 1 ]] &&
+ echo "skipping $func address at $hexaddr due to size mismatch ($size != $sym_size)"
+ continue;
+ fi
+
+ # make sure the provided offset is within the symbol's range
+ if [[ $offset -gt $sym_size ]]; then
+ [[ $print_warnings = 1 ]] &&
+ echo "skipping $func address at $hexaddr due to size mismatch ($offset > $sym_size)"
+ continue
+ fi
+
+ # separate multiple entries with a blank line
+ [[ $FIRST = 0 ]] && echo
+ FIRST=0
+
+ local hexsize=0x$(printf %x $sym_size)
+ echo "$func+$offset/$hexsize:"
+ addr2line -fpie $objfile $hexaddr | sed "s; $dir_prefix\(\./\)*; ;"
+ DONE=1
+
+ done < <(readelf -sW $objfile | awk -v f=$func '$8 == f {print}')
+}
+
+[[ $# -lt 2 ]] && usage
+
+objfile=$1
+[[ ! -f $objfile ]] && die "can't find objfile $objfile"
+shift
+
+DIR_PREFIX=supercalifragilisticexpialidocious
+find_dir_prefix $objfile
+
+FIRST=1
+while [[ $# -gt 0 ]]; do
+ func_addr=$1
+ shift
+
+ # print any matches found
+ DONE=0
+ __faddr2line $objfile $func_addr $DIR_PREFIX 0
+
+ # if no match was found, print warnings
+ if [[ $DONE = 0 ]]; then
+ __faddr2line $objfile $func_addr $DIR_PREFIX 1
+ warn "no match for $func_addr"
+ fi
+done
diff --git a/scripts/recordmcount.c b/scripts/recordmcount.c
index 42396a7..a68f031 100644
--- a/scripts/recordmcount.c
+++ b/scripts/recordmcount.c
@@ -363,6 +363,7 @@
strcmp(".sched.text", txtname) == 0 ||
strcmp(".spinlock.text", txtname) == 0 ||
strcmp(".irqentry.text", txtname) == 0 ||
+ strcmp(".softirqentry.text", txtname) == 0 ||
strcmp(".kprobes.text", txtname) == 0 ||
strcmp(".text.unlikely", txtname) == 0;
}
diff --git a/scripts/recordmcount.pl b/scripts/recordmcount.pl
index 96e2486..2d48011 100755
--- a/scripts/recordmcount.pl
+++ b/scripts/recordmcount.pl
@@ -134,6 +134,7 @@
".sched.text" => 1,
".spinlock.text" => 1,
".irqentry.text" => 1,
+ ".softirqentry.text" => 1,
".kprobes.text" => 1,
".text.unlikely" => 1,
);
diff --git a/security/keys/encrypted-keys/encrypted.c b/security/keys/encrypted-keys/encrypted.c
index 5adbfc3..17a0610 100644
--- a/security/keys/encrypted-keys/encrypted.c
+++ b/security/keys/encrypted-keys/encrypted.c
@@ -29,6 +29,7 @@
#include <linux/rcupdate.h>
#include <linux/scatterlist.h>
#include <linux/ctype.h>
+#include <crypto/aes.h>
#include <crypto/hash.h>
#include <crypto/sha.h>
#include <crypto/skcipher.h>
@@ -478,6 +479,7 @@
struct crypto_skcipher *tfm;
struct skcipher_request *req;
unsigned int encrypted_datalen;
+ u8 iv[AES_BLOCK_SIZE];
unsigned int padlen;
char pad[16];
int ret;
@@ -500,8 +502,8 @@
sg_init_table(sg_out, 1);
sg_set_buf(sg_out, epayload->encrypted_data, encrypted_datalen);
- skcipher_request_set_crypt(req, sg_in, sg_out, encrypted_datalen,
- epayload->iv);
+ memcpy(iv, epayload->iv, sizeof(iv));
+ skcipher_request_set_crypt(req, sg_in, sg_out, encrypted_datalen, iv);
ret = crypto_skcipher_encrypt(req);
tfm = crypto_skcipher_reqtfm(req);
skcipher_request_free(req);
@@ -581,6 +583,7 @@
struct crypto_skcipher *tfm;
struct skcipher_request *req;
unsigned int encrypted_datalen;
+ u8 iv[AES_BLOCK_SIZE];
char pad[16];
int ret;
@@ -599,8 +602,8 @@
epayload->decrypted_datalen);
sg_set_buf(&sg_out[1], pad, sizeof pad);
- skcipher_request_set_crypt(req, sg_in, sg_out, encrypted_datalen,
- epayload->iv);
+ memcpy(iv, epayload->iv, sizeof(iv));
+ skcipher_request_set_crypt(req, sg_in, sg_out, encrypted_datalen, iv);
ret = crypto_skcipher_decrypt(req);
tfm = crypto_skcipher_reqtfm(req);
skcipher_request_free(req);
diff --git a/tools/power/acpi/common/cmfsize.c b/tools/power/acpi/common/cmfsize.c
index e73a79f..bc82596 100644
--- a/tools/power/acpi/common/cmfsize.c
+++ b/tools/power/acpi/common/cmfsize.c
@@ -44,7 +44,6 @@
#include <acpi/acpi.h>
#include "accommon.h"
#include "acapps.h"
-#include <stdio.h>
#define _COMPONENT ACPI_TOOLS
ACPI_MODULE_NAME("cmfsize")
@@ -69,24 +68,24 @@
/* Save the current file pointer, seek to EOF to obtain file size */
- current_offset = acpi_os_get_file_offset(file);
+ current_offset = ftell(file);
if (current_offset < 0) {
goto offset_error;
}
- status = acpi_os_set_file_offset(file, 0, ACPI_FILE_END);
+ status = fseek(file, 0, SEEK_END);
if (ACPI_FAILURE(status)) {
goto seek_error;
}
- file_size = acpi_os_get_file_offset(file);
+ file_size = ftell(file);
if (file_size < 0) {
goto offset_error;
}
/* Restore original file pointer */
- status = acpi_os_set_file_offset(file, current_offset, ACPI_FILE_BEGIN);
+ status = fseek(file, current_offset, SEEK_SET);
if (ACPI_FAILURE(status)) {
goto seek_error;
}
@@ -94,10 +93,10 @@
return ((u32)file_size);
offset_error:
- acpi_log_error("Could not get file offset");
+ fprintf(stderr, "Could not get file offset\n");
return (ACPI_UINT32_MAX);
seek_error:
- acpi_log_error("Could not set file offset");
+ fprintf(stderr, "Could not set file offset\n");
return (ACPI_UINT32_MAX);
}
diff --git a/tools/power/acpi/common/getopt.c b/tools/power/acpi/common/getopt.c
index 0bd343f..3919970 100644
--- a/tools/power/acpi/common/getopt.c
+++ b/tools/power/acpi/common/getopt.c
@@ -57,7 +57,7 @@
#include "acapps.h"
#define ACPI_OPTION_ERROR(msg, badchar) \
- if (acpi_gbl_opterr) {acpi_log_error ("%s%c\n", msg, badchar);}
+ if (acpi_gbl_opterr) {fprintf (stderr, "%s%c\n", msg, badchar);}
int acpi_gbl_opterr = 1;
int acpi_gbl_optind = 1;
@@ -94,7 +94,7 @@
acpi_gbl_optarg =
&argv[acpi_gbl_optind++][(int)(current_char_ptr + 1)];
} else if (++acpi_gbl_optind >= argc) {
- ACPI_OPTION_ERROR("Option requires an argument: -", 'v');
+ ACPI_OPTION_ERROR("\nOption requires an argument", 0);
current_char_ptr = 1;
return (-1);
diff --git a/tools/power/acpi/os_specific/service_layers/oslibcfs.c b/tools/power/acpi/os_specific/service_layers/oslibcfs.c
deleted file mode 100644
index 11f4aba..0000000
--- a/tools/power/acpi/os_specific/service_layers/oslibcfs.c
+++ /dev/null
@@ -1,217 +0,0 @@
-/******************************************************************************
- *
- * Module Name: oslibcfs - C library OSL for file I/O
- *
- *****************************************************************************/
-
-/*
- * Copyright (C) 2000 - 2016, Intel Corp.
- * All rights reserved.
- *
- * Redistribution and use in source and binary forms, with or without
- * modification, are permitted provided that the following conditions
- * are met:
- * 1. Redistributions of source code must retain the above copyright
- * notice, this list of conditions, and the following disclaimer,
- * without modification.
- * 2. Redistributions in binary form must reproduce at minimum a disclaimer
- * substantially similar to the "NO WARRANTY" disclaimer below
- * ("Disclaimer") and any redistribution must be conditioned upon
- * including a substantially similar Disclaimer requirement for further
- * binary redistribution.
- * 3. Neither the names of the above-listed copyright holders nor the names
- * of any contributors may be used to endorse or promote products derived
- * from this software without specific prior written permission.
- *
- * Alternatively, this software may be distributed under the terms of the
- * GNU General Public License ("GPL") version 2 as published by the Free
- * Software Foundation.
- *
- * NO WARRANTY
- * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
- * "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
- * LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTIBILITY AND FITNESS FOR
- * A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
- * HOLDERS OR CONTRIBUTORS BE LIABLE FOR SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
- * DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
- * OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
- * HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT,
- * STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING
- * IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
- * POSSIBILITY OF SUCH DAMAGES.
- */
-
-#include <acpi/acpi.h>
-#include <stdio.h>
-#include <stdarg.h>
-
-#define _COMPONENT ACPI_OS_SERVICES
-ACPI_MODULE_NAME("oslibcfs")
-
-/*******************************************************************************
- *
- * FUNCTION: acpi_os_open_file
- *
- * PARAMETERS: path - File path
- * modes - File operation type
- *
- * RETURN: File descriptor.
- *
- * DESCRIPTION: Open a file for reading (ACPI_FILE_READING) or/and writing
- * (ACPI_FILE_WRITING).
- *
- ******************************************************************************/
-ACPI_FILE acpi_os_open_file(const char *path, u8 modes)
-{
- ACPI_FILE file;
- u32 i = 0;
- char modes_str[4];
-
- if (modes & ACPI_FILE_READING) {
- modes_str[i++] = 'r';
- }
- if (modes & ACPI_FILE_WRITING) {
- modes_str[i++] = 'w';
- }
-
- if (modes & ACPI_FILE_BINARY) {
- modes_str[i++] = 'b';
- }
-
- modes_str[i++] = '\0';
-
- file = fopen(path, modes_str);
- if (!file) {
- perror("Could not open file");
- }
-
- return (file);
-}
-
-/*******************************************************************************
- *
- * FUNCTION: acpi_os_close_file
- *
- * PARAMETERS: file - An open file descriptor
- *
- * RETURN: None.
- *
- * DESCRIPTION: Close a file opened via acpi_os_open_file.
- *
- ******************************************************************************/
-
-void acpi_os_close_file(ACPI_FILE file)
-{
-
- fclose(file);
-}
-
-/*******************************************************************************
- *
- * FUNCTION: acpi_os_read_file
- *
- * PARAMETERS: file - An open file descriptor
- * buffer - Data buffer
- * size - Data block size
- * count - Number of data blocks
- *
- * RETURN: Number of bytes actually read.
- *
- * DESCRIPTION: Read from a file.
- *
- ******************************************************************************/
-
-int
-acpi_os_read_file(ACPI_FILE file, void *buffer, acpi_size size, acpi_size count)
-{
- int length;
-
- length = fread(buffer, size, count, file);
- if (length < 0) {
- perror("Error reading file");
- }
-
- return (length);
-}
-
-/*******************************************************************************
- *
- * FUNCTION: acpi_os_write_file
- *
- * PARAMETERS: file - An open file descriptor
- * buffer - Data buffer
- * size - Data block size
- * count - Number of data blocks
- *
- * RETURN: Number of bytes actually written.
- *
- * DESCRIPTION: Write to a file.
- *
- ******************************************************************************/
-
-int
-acpi_os_write_file(ACPI_FILE file,
- void *buffer, acpi_size size, acpi_size count)
-{
- int length;
-
- length = fwrite(buffer, size, count, file);
- if (length < 0) {
- perror("Error writing file");
- }
-
- return (length);
-}
-
-/*******************************************************************************
- *
- * FUNCTION: acpi_os_get_file_offset
- *
- * PARAMETERS: file - An open file descriptor
- *
- * RETURN: Current file pointer position.
- *
- * DESCRIPTION: Get current file offset.
- *
- ******************************************************************************/
-
-long acpi_os_get_file_offset(ACPI_FILE file)
-{
- long offset;
-
- offset = ftell(file);
- return (offset);
-}
-
-/*******************************************************************************
- *
- * FUNCTION: acpi_os_set_file_offset
- *
- * PARAMETERS: file - An open file descriptor
- * offset - New file offset
- * from - From begin/end of file
- *
- * RETURN: Status
- *
- * DESCRIPTION: Set current file offset.
- *
- ******************************************************************************/
-
-acpi_status acpi_os_set_file_offset(ACPI_FILE file, long offset, u8 from)
-{
- int ret = 0;
-
- if (from == ACPI_FILE_BEGIN) {
- ret = fseek(file, offset, SEEK_SET);
- }
-
- if (from == ACPI_FILE_END) {
- ret = fseek(file, offset, SEEK_END);
- }
-
- if (ret < 0) {
- return (AE_ERROR);
- } else {
- return (AE_OK);
- }
-}
diff --git a/tools/power/acpi/os_specific/service_layers/osunixxf.c b/tools/power/acpi/os_specific/service_layers/osunixxf.c
index 88aa66e..8d8003c 100644
--- a/tools/power/acpi/os_specific/service_layers/osunixxf.c
+++ b/tools/power/acpi/os_specific/service_layers/osunixxf.c
@@ -63,10 +63,7 @@
#define _COMPONENT ACPI_OS_SERVICES
ACPI_MODULE_NAME("osunixxf")
-u8 acpi_gbl_debug_timeout = FALSE;
-
/* Upcalls to acpi_exec */
-
void
ae_table_override(struct acpi_table_header *existing_table,
struct acpi_table_header **new_table);
diff --git a/tools/power/acpi/tools/acpidump/Makefile b/tools/power/acpi/tools/acpidump/Makefile
index 2942cdc..04b5db7 100644
--- a/tools/power/acpi/tools/acpidump/Makefile
+++ b/tools/power/acpi/tools/acpidump/Makefile
@@ -36,12 +36,13 @@
utdebug.o\
utexcep.o\
utglobal.o\
+ uthex.o\
utmath.o\
utnonansi.o\
utprint.o\
utstring.o\
+ utstrtoul64.o\
utxferror.o\
- oslibcfs.o\
oslinuxtbl.o\
cmfsize.o\
getopt.o
diff --git a/tools/power/acpi/tools/acpidump/acpidump.h b/tools/power/acpi/tools/acpidump/acpidump.h
index 025c232..00423fc 100644
--- a/tools/power/acpi/tools/acpidump/acpidump.h
+++ b/tools/power/acpi/tools/acpidump/acpidump.h
@@ -55,11 +55,7 @@
#include <acpi/acpi.h>
#include "accommon.h"
#include "actables.h"
-
-#include <stdio.h>
-#include <fcntl.h>
-#include <errno.h>
-#include <sys/stat.h>
+#include "acapps.h"
/* Globals */
@@ -72,12 +68,6 @@
EXTERN char INIT_GLOBAL(*gbl_output_filename, NULL);
EXTERN u64 INIT_GLOBAL(gbl_rsdp_base, 0);
-/* Globals required for use with ACPICA modules */
-
-#ifdef _DECLARE_GLOBALS
-u8 acpi_gbl_integer_byte_width = 8;
-#endif
-
/* Action table used to defer requested options */
struct ap_dump_action {
diff --git a/tools/power/acpi/tools/acpidump/apdump.c b/tools/power/acpi/tools/acpidump/apdump.c
index fb8f1d9..9031be1 100644
--- a/tools/power/acpi/tools/acpidump/apdump.c
+++ b/tools/power/acpi/tools/acpidump/apdump.c
@@ -69,16 +69,17 @@
/* Make sure signature is all ASCII and a valid ACPI name */
if (!acpi_ut_valid_nameseg(table->signature)) {
- acpi_log_error("Table signature (0x%8.8X) is invalid\n",
- *(u32 *)table->signature);
+ fprintf(stderr,
+ "Table signature (0x%8.8X) is invalid\n",
+ *(u32 *)table->signature);
return (FALSE);
}
/* Check for minimum table length */
if (table->length < sizeof(struct acpi_table_header)) {
- acpi_log_error("Table length (0x%8.8X) is invalid\n",
- table->length);
+ fprintf(stderr, "Table length (0x%8.8X) is invalid\n",
+ table->length);
return (FALSE);
}
}
@@ -115,8 +116,8 @@
}
if (ACPI_FAILURE(status)) {
- acpi_log_error("%4.4s: Warning: wrong checksum in table\n",
- table->signature);
+ fprintf(stderr, "%4.4s: Warning: wrong checksum in table\n",
+ table->signature);
}
return (AE_OK);
@@ -195,13 +196,13 @@
* Note: simplest to just always emit a 64-bit address. acpi_xtract
* utility can handle this.
*/
- acpi_ut_file_printf(gbl_output_file, "%4.4s @ 0x%8.8X%8.8X\n",
- table->signature, ACPI_FORMAT_UINT64(address));
+ fprintf(gbl_output_file, "%4.4s @ 0x%8.8X%8.8X\n",
+ table->signature, ACPI_FORMAT_UINT64(address));
acpi_ut_dump_buffer_to_file(gbl_output_file,
ACPI_CAST_PTR(u8, table), table_length,
DB_BYTE_DISPLAY, 0);
- acpi_ut_file_printf(gbl_output_file, "\n");
+ fprintf(gbl_output_file, "\n");
return (0);
}
@@ -239,14 +240,14 @@
if (status == AE_LIMIT) {
return (0);
} else if (i == 0) {
- acpi_log_error
- ("Could not get ACPI tables, %s\n",
- acpi_format_exception(status));
+ fprintf(stderr,
+ "Could not get ACPI tables, %s\n",
+ acpi_format_exception(status));
return (-1);
} else {
- acpi_log_error
- ("Could not get ACPI table at index %u, %s\n",
- i, acpi_format_exception(status));
+ fprintf(stderr,
+ "Could not get ACPI table at index %u, %s\n",
+ i, acpi_format_exception(status));
continue;
}
}
@@ -286,20 +287,20 @@
/* Convert argument to an integer physical address */
- status = acpi_ut_strtoul64(ascii_address, ACPI_ANY_BASE,
- ACPI_MAX64_BYTE_WIDTH, &long_address);
+ status = acpi_ut_strtoul64(ascii_address, ACPI_STRTOUL_64BIT,
+ &long_address);
if (ACPI_FAILURE(status)) {
- acpi_log_error("%s: Could not convert to a physical address\n",
- ascii_address);
+ fprintf(stderr, "%s: Could not convert to a physical address\n",
+ ascii_address);
return (-1);
}
address = (acpi_physical_address)long_address;
status = acpi_os_get_table_by_address(address, &table);
if (ACPI_FAILURE(status)) {
- acpi_log_error("Could not get table at 0x%8.8X%8.8X, %s\n",
- ACPI_FORMAT_UINT64(address),
- acpi_format_exception(status));
+ fprintf(stderr, "Could not get table at 0x%8.8X%8.8X, %s\n",
+ ACPI_FORMAT_UINT64(address),
+ acpi_format_exception(status));
return (-1);
}
@@ -331,9 +332,9 @@
int table_status;
if (strlen(signature) != ACPI_NAME_SIZE) {
- acpi_log_error
- ("Invalid table signature [%s]: must be exactly 4 characters\n",
- signature);
+ fprintf(stderr,
+ "Invalid table signature [%s]: must be exactly 4 characters\n",
+ signature);
return (-1);
}
@@ -363,9 +364,9 @@
return (0);
}
- acpi_log_error
- ("Could not get ACPI table with signature [%s], %s\n",
- local_signature, acpi_format_exception(status));
+ fprintf(stderr,
+ "Could not get ACPI table with signature [%s], %s\n",
+ local_signature, acpi_format_exception(status));
return (-1);
}
@@ -408,24 +409,24 @@
}
if (!acpi_ut_valid_nameseg(table->signature)) {
- acpi_log_error
- ("No valid ACPI signature was found in input file %s\n",
- pathname);
+ fprintf(stderr,
+ "No valid ACPI signature was found in input file %s\n",
+ pathname);
}
/* File must be at least as long as the table length */
if (table->length > file_size) {
- acpi_log_error
- ("Table length (0x%X) is too large for input file (0x%X) %s\n",
- table->length, file_size, pathname);
+ fprintf(stderr,
+ "Table length (0x%X) is too large for input file (0x%X) %s\n",
+ table->length, file_size, pathname);
goto exit;
}
if (gbl_verbose_mode) {
- acpi_log_error
- ("Input file: %s contains table [%4.4s], 0x%X (%u) bytes\n",
- pathname, table->signature, file_size, file_size);
+ fprintf(stderr,
+ "Input file: %s contains table [%4.4s], 0x%X (%u) bytes\n",
+ pathname, table->signature, file_size, file_size);
}
table_status = ap_dump_table_buffer(table, 0, 0);
diff --git a/tools/power/acpi/tools/acpidump/apfiles.c b/tools/power/acpi/tools/acpidump/apfiles.c
index 5fcd970..dd5b861 100644
--- a/tools/power/acpi/tools/acpidump/apfiles.c
+++ b/tools/power/acpi/tools/acpidump/apfiles.c
@@ -42,7 +42,6 @@
*/
#include "acpidump.h"
-#include "acapps.h"
/* Local prototypes */
@@ -66,7 +65,8 @@
struct stat stat_info;
if (!stat(pathname, &stat_info)) {
- acpi_log_error("Target path already exists, overwrite? [y|n] ");
+ fprintf(stderr,
+ "Target path already exists, overwrite? [y|n] ");
if (getchar() != 'y') {
return (-1);
@@ -102,9 +102,9 @@
/* Point stdout to the file */
- file = acpi_os_open_file(pathname, ACPI_FILE_WRITING);
+ file = fopen(pathname, "w");
if (!file) {
- acpi_log_error("Could not open output file: %s\n", pathname);
+ fprintf(stderr, "Could not open output file: %s\n", pathname);
return (-1);
}
@@ -134,7 +134,7 @@
char filename[ACPI_NAME_SIZE + 16];
char instance_str[16];
ACPI_FILE file;
- size_t actual;
+ acpi_size actual;
u32 table_length;
/* Obtain table length */
@@ -158,37 +158,36 @@
/* Handle multiple SSDts - create different filenames for each */
if (instance > 0) {
- acpi_ut_snprintf(instance_str, sizeof(instance_str), "%u",
- instance);
+ snprintf(instance_str, sizeof(instance_str), "%u", instance);
strcat(filename, instance_str);
}
strcat(filename, FILE_SUFFIX_BINARY_TABLE);
if (gbl_verbose_mode) {
- acpi_log_error
- ("Writing [%4.4s] to binary file: %s 0x%X (%u) bytes\n",
- table->signature, filename, table->length, table->length);
+ fprintf(stderr,
+ "Writing [%4.4s] to binary file: %s 0x%X (%u) bytes\n",
+ table->signature, filename, table->length,
+ table->length);
}
/* Open the file and dump the entire table in binary mode */
- file = acpi_os_open_file(filename,
- ACPI_FILE_WRITING | ACPI_FILE_BINARY);
+ file = fopen(filename, "wb");
if (!file) {
- acpi_log_error("Could not open output file: %s\n", filename);
+ fprintf(stderr, "Could not open output file: %s\n", filename);
return (-1);
}
- actual = acpi_os_write_file(file, table, 1, table_length);
+ actual = fwrite(table, 1, table_length, file);
if (actual != table_length) {
- acpi_log_error("Error writing binary output file: %s\n",
- filename);
- acpi_os_close_file(file);
+ fprintf(stderr, "Error writing binary output file: %s\n",
+ filename);
+ fclose(file);
return (-1);
}
- acpi_os_close_file(file);
+ fclose(file);
return (0);
}
@@ -211,14 +210,13 @@
struct acpi_table_header *buffer = NULL;
ACPI_FILE file;
u32 file_size;
- size_t actual;
+ acpi_size actual;
/* Must use binary mode */
- file =
- acpi_os_open_file(pathname, ACPI_FILE_READING | ACPI_FILE_BINARY);
+ file = fopen(pathname, "rb");
if (!file) {
- acpi_log_error("Could not open input file: %s\n", pathname);
+ fprintf(stderr, "Could not open input file: %s\n", pathname);
return (NULL);
}
@@ -226,7 +224,8 @@
file_size = cm_get_file_size(file);
if (file_size == ACPI_UINT32_MAX) {
- acpi_log_error("Could not get input file size: %s\n", pathname);
+ fprintf(stderr,
+ "Could not get input file size: %s\n", pathname);
goto cleanup;
}
@@ -234,16 +233,17 @@
buffer = ACPI_ALLOCATE_ZEROED(file_size);
if (!buffer) {
- acpi_log_error("Could not allocate file buffer of size: %u\n",
- file_size);
+ fprintf(stderr,
+ "Could not allocate file buffer of size: %u\n",
+ file_size);
goto cleanup;
}
/* Read the entire file */
- actual = acpi_os_read_file(file, buffer, 1, file_size);
+ actual = fread(buffer, 1, file_size, file);
if (actual != file_size) {
- acpi_log_error("Could not read input file: %s\n", pathname);
+ fprintf(stderr, "Could not read input file: %s\n", pathname);
ACPI_FREE(buffer);
buffer = NULL;
goto cleanup;
@@ -252,6 +252,6 @@
*out_file_size = file_size;
cleanup:
- acpi_os_close_file(file);
+ fclose(file);
return (buffer);
}
diff --git a/tools/power/acpi/tools/acpidump/apmain.c b/tools/power/acpi/tools/acpidump/apmain.c
index 7692e6b..7ff46be 100644
--- a/tools/power/acpi/tools/acpidump/apmain.c
+++ b/tools/power/acpi/tools/acpidump/apmain.c
@@ -43,7 +43,6 @@
#define _DECLARE_GLOBALS
#include "acpidump.h"
-#include "acapps.h"
/*
* acpidump - A portable utility for obtaining system ACPI tables and dumping
@@ -140,8 +139,8 @@
current_action++;
if (current_action > AP_MAX_ACTIONS) {
- acpi_log_error("Too many table options (max %u)\n",
- AP_MAX_ACTIONS);
+ fprintf(stderr, "Too many table options (max %u)\n",
+ AP_MAX_ACTIONS);
return (-1);
}
@@ -186,9 +185,9 @@
} else if (!strcmp(acpi_gbl_optarg, "off")) {
gbl_dump_customized_tables = FALSE;
} else {
- acpi_log_error
- ("%s: Cannot handle this switch, please use on|off\n",
- acpi_gbl_optarg);
+ fprintf(stderr,
+ "%s: Cannot handle this switch, please use on|off\n",
+ acpi_gbl_optarg);
return (-1);
}
continue;
@@ -209,13 +208,13 @@
case 'r': /* Dump tables from specified RSDP */
status =
- acpi_ut_strtoul64(acpi_gbl_optarg, ACPI_ANY_BASE,
- ACPI_MAX64_BYTE_WIDTH,
+ acpi_ut_strtoul64(acpi_gbl_optarg,
+ ACPI_STRTOUL_64BIT,
&gbl_rsdp_base);
if (ACPI_FAILURE(status)) {
- acpi_log_error
- ("%s: Could not convert to a physical address\n",
- acpi_gbl_optarg);
+ fprintf(stderr,
+ "%s: Could not convert to a physical address\n",
+ acpi_gbl_optarg);
return (-1);
}
continue;
@@ -242,7 +241,7 @@
case 'z': /* Verbose mode */
gbl_verbose_mode = TRUE;
- acpi_log_error(ACPI_COMMON_SIGNON(AP_UTILITY_NAME));
+ fprintf(stderr, ACPI_COMMON_SIGNON(AP_UTILITY_NAME));
continue;
/*
@@ -315,6 +314,7 @@
ACPI_DEBUG_INITIALIZE(); /* For debug version only */
acpi_os_initialize();
gbl_output_file = ACPI_FILE_OUT;
+ acpi_gbl_integer_byte_width = 8;
/* Process command line options */
@@ -353,8 +353,9 @@
default:
- acpi_log_error("Internal error, invalid action: 0x%X\n",
- action->to_be_done);
+ fprintf(stderr,
+ "Internal error, invalid action: 0x%X\n",
+ action->to_be_done);
return (-1);
}
@@ -369,12 +370,12 @@
/* Summary for the output file */
file_size = cm_get_file_size(gbl_output_file);
- acpi_log_error
- ("Output file %s contains 0x%X (%u) bytes\n\n",
- gbl_output_filename, file_size, file_size);
+ fprintf(stderr,
+ "Output file %s contains 0x%X (%u) bytes\n\n",
+ gbl_output_filename, file_size, file_size);
}
- acpi_os_close_file(gbl_output_file);
+ fclose(gbl_output_file);
}
return (status);
diff --git a/tools/testing/nvdimm/test/nfit.c b/tools/testing/nvdimm/test/nfit.c
index dd48f42..f64c57b 100644
--- a/tools/testing/nvdimm/test/nfit.c
+++ b/tools/testing/nvdimm/test/nfit.c
@@ -603,7 +603,8 @@
return -ENOMEM;
sprintf(t->label[i], "label%d", i);
- t->flush[i] = test_alloc(t, sizeof(u64) * NUM_HINTS,
+ t->flush[i] = test_alloc(t, max(PAGE_SIZE,
+ sizeof(u64) * NUM_HINTS),
&t->flush_dma[i]);
if (!t->flush[i])
return -ENOMEM;
diff --git a/tools/testing/radix-tree/Makefile b/tools/testing/radix-tree/Makefile
index 3b53046..9d0919ed 100644
--- a/tools/testing/radix-tree/Makefile
+++ b/tools/testing/radix-tree/Makefile
@@ -1,5 +1,5 @@
-CFLAGS += -I. -g -Wall -D_LGPL_SOURCE
+CFLAGS += -I. -g -O2 -Wall -D_LGPL_SOURCE
LDFLAGS += -lpthread -lurcu
TARGETS = main
OFILES = main.o radix-tree.o linux.o test.o tag_check.o find_next_bit.o \
diff --git a/tools/testing/radix-tree/multiorder.c b/tools/testing/radix-tree/multiorder.c
index 39d9b95..05d7bc4 100644
--- a/tools/testing/radix-tree/multiorder.c
+++ b/tools/testing/radix-tree/multiorder.c
@@ -124,6 +124,8 @@
unsigned long i;
unsigned long min = index & ~((1UL << order) - 1);
unsigned long max = min + (1UL << order);
+ void **slot;
+ struct item *item2 = item_create(min);
RADIX_TREE(tree, GFP_KERNEL);
printf("Multiorder index %ld, order %d\n", index, order);
@@ -139,13 +141,19 @@
item_check_absent(&tree, i);
for (i = max; i < 2*max; i++)
item_check_absent(&tree, i);
+ for (i = min; i < max; i++)
+ assert(radix_tree_insert(&tree, i, item2) == -EEXIST);
+
+ slot = radix_tree_lookup_slot(&tree, index);
+ free(*slot);
+ radix_tree_replace_slot(slot, item2);
for (i = min; i < max; i++) {
- static void *entry = (void *)
- (0xA0 | RADIX_TREE_EXCEPTIONAL_ENTRY);
- assert(radix_tree_insert(&tree, i, entry) == -EEXIST);
+ struct item *item = item_lookup(&tree, i);
+ assert(item != 0);
+ assert(item->index == min);
}
- assert(item_delete(&tree, index) != 0);
+ assert(item_delete(&tree, min) != 0);
for (i = 0; i < 2*max; i++)
item_check_absent(&tree, i);
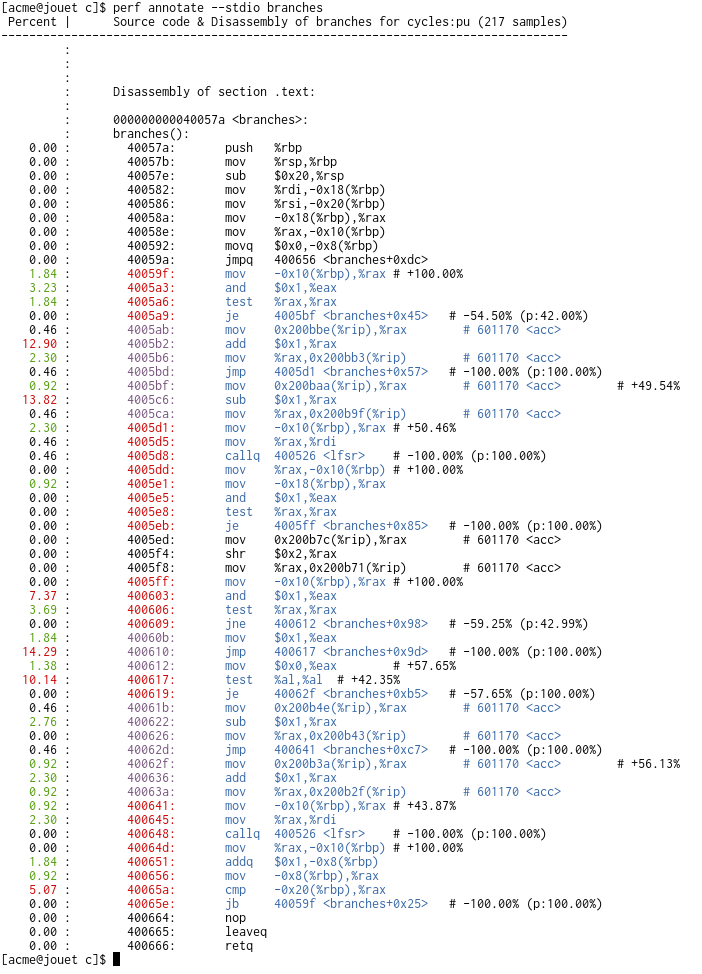{kind=link}